
Poza przeglądarką: Pierwsze kroki z bezserwerowym WebAssembly
Opublikowany: 2022-03-10Teraz, gdy WebAssembly jest obsługiwany przez wszystkie główne przeglądarki i ponad 85% użytkowników na całym świecie, JavaScript nie jest już jedynym językiem przeglądarki w mieście. Jeśli nie słyszałeś, WebAssembly to nowy język niskiego poziomu, który działa w przeglądarce. Jest to również cel kompilacji, co oznacza, że możesz kompilować istniejące programy napisane w językach takich jak C, C++ i Rust do WebAssembly i uruchamiać te programy w przeglądarce. Do tej pory WebAssembly był używany do przenoszenia wszelkiego rodzaju aplikacji do sieci, w tym aplikacji komputerowych, narzędzi wiersza poleceń, gier i narzędzi do analizy danych.
Uwaga: Aby uzyskać szczegółowe studium przypadku, w jaki sposób WebAssembly może być używany w przeglądarce w celu przyspieszenia aplikacji internetowych, zapoznaj się z moim poprzednim artykułem.
WebAssembly poza siecią?
Chociaż większość dzisiejszych aplikacji WebAssembly jest zorientowana na przeglądarkę, sam WebAssembly nie był pierwotnie zaprojektowany tylko dla sieci, ale tak naprawdę dla dowolnego środowiska piaskownicy. W rzeczywistości ostatnio było duże zainteresowanie badaniem, w jaki sposób WebAssembly może być użyteczny poza przeglądarką, jako ogólne podejście do uruchamiania plików binarnych w dowolnym systemie operacyjnym lub architekturze komputera, o ile istnieje środowisko uruchomieniowe WebAssembly, które obsługuje ten system. W tym artykule przyjrzymy się, jak WebAssembly można uruchomić poza przeglądarką, w sposób bezserwerowy/funkcja jako usługa (FaaS).
WebAssembly dla aplikacji bezserwerowych
Krótko mówiąc, funkcje bezserwerowe to model obliczeniowy, w którym przekazujesz swój kod dostawcy chmury i pozwalasz mu wykonywać i skalować ten kod za Ciebie. Na przykład możesz poprosić, aby funkcja bezserwerowa była wykonywana za każdym razem, gdy wywołasz punkt końcowy interfejsu API lub aby była sterowana zdarzeniami, takimi jak przesyłanie pliku do zasobnika w chmurze. Chociaż termin „bezserwerowy” może wydawać się mylący, ponieważ serwery są wyraźnie zaangażowane gdzieś po drodze, z naszego punktu widzenia jest to bezserwerowe, ponieważ nie musimy się martwić o to, jak nimi zarządzać, wdrażać ani skalować.
Chociaż te funkcje są zwykle napisane w językach takich jak Python i JavaScript (Node.js), istnieje wiele powodów, dla których możesz zamiast tego użyć WebAssembly:
- Szybsze czasy inicjalizacji
Dostawcy bezserwerowi, którzy obsługują WebAssembly (w tym Cloudflare i Fastly zgłaszają, że mogą uruchamiać funkcje co najmniej o rząd wielkości szybciej niż większość dostawców usług w chmurze w przypadku innych języków. Osiągają to, uruchamiając dziesiątki tysięcy modułów WebAssembly w tym samym procesie, co jest jest to możliwe, ponieważ piaskownica WebAssembly zapewnia bardziej wydajny sposób uzyskiwania izolacji, do której tradycyjnie używane są kontenery. - Nie potrzeba przepisywania
Jedną z głównych zalet WebAssembly w przeglądarce jest możliwość przeniesienia istniejącego kodu do sieci bez konieczności przepisywania wszystkiego do JavaScript. Ta korzyść jest nadal prawdziwa w przypadku użycia bezserwerowego, ponieważ dostawcy chmury ograniczają języki, w których można pisać funkcje bezserwerowe. Zazwyczaj będą obsługiwać Python, Node.js i być może kilka innych, ale na pewno nie C, C++ lub Rust . Dzięki obsłudze WebAssembly dostawcy bezserwerowi mogą pośrednio obsługiwać znacznie więcej języków. - Bardziej lekki
Podczas uruchamiania WebAssembly w przeglądarce polegamy na komputerze użytkownika końcowego do wykonywania naszych obliczeń. Jeśli te obliczenia będą zbyt intensywne, nasi użytkownicy nie będą zadowoleni, gdy ich komputerowy wentylator zacznie warczeć. Uruchamianie WebAssembly poza przeglądarką daje nam korzyści związane z szybkością i przenośnością WebAssembly, jednocześnie zachowując lekkość naszej aplikacji. Ponadto, ponieważ uruchamiamy nasz kod WebAssembly w bardziej przewidywalnym środowisku, możemy potencjalnie wykonywać bardziej intensywne obliczenia.
Konkretny przykład
W moim poprzednim artykule na Smashing Magazine omawialiśmy, w jaki sposób przyspieszyliśmy aplikację internetową, zastępując wolne obliczenia JavaScript kodem C skompilowanym do WebAssembly. Wspomniana aplikacja internetowa to fastq.bio, narzędzie do podglądu jakości danych sekwencjonowania DNA.
Jako konkretny przykład przepiszmy fastq.bio jako aplikację, która korzysta z bezserwerowego WebAssembly zamiast uruchamiać WebAssembly w przeglądarce. W tym artykule użyjemy Cloudflare Workers, dostawcy bezserwerowego, który obsługuje WebAssembly i jest zbudowany na silniku przeglądarki V8. Inny dostawca chmury, Fastly, pracuje nad podobną ofertą, ale w oparciu o środowisko uruchomieniowe Lucet.

Najpierw napiszmy kod Rust, aby przeanalizować jakość danych danych sekwencjonowania DNA. Dla wygody możemy wykorzystać bibliotekę bioinformatyczną Rust-Bio do obsługi parsowania danych wejściowych oraz bibliotekę wasm-bindgen, aby pomóc nam skompilować nasz kod Rust do WebAssembly.
Oto fragment kodu, który odczytuje dane sekwencjonowania DNA i generuje kod JSON z podsumowaniem wskaźników jakości:
// Import packages extern crate wasm_bindgen; use bio::seq_analysis::gc; use bio::io::fastq; ... // This "wasm_bindgen" tag lets us denote the functions // we want to expose in our WebAssembly module #[wasm_bindgen] pub fn fastq_metrics(seq: String) -> String { ... // Loop through lines in the file let reader = fastq::Reader::new(seq.as_bytes()); for result in reader.records() { let record = result.unwrap(); let sequence = record.seq(); // Calculate simple statistics on each record n_reads += 1.0; let read_length = sequence.len(); let read_gc = gc::gc_content(sequence); // We want to draw histograms of these values // so we store their values for later plotting hist_gc.push(read_gc * 100.0); hist_len.push(read_length); ... } // Return statistics as a JSON blob json!({ "n": n_reads, "hist": { "gc": hist_gc, "len": hist_len }, ... }).to_string() }Następnie użyliśmy narzędzia wiersza poleceń Cloudflare wrangler, aby wykonać kompilację do WebAssembly i wdrożenie w chmurze. Po zakończeniu otrzymujemy punkt końcowy API, który pobiera dane sekwencjonowania jako dane wejściowe i zwraca JSON z metrykami jakości danych. Możemy teraz zintegrować to API z naszą aplikacją.
Oto GIF aplikacji w akcji:
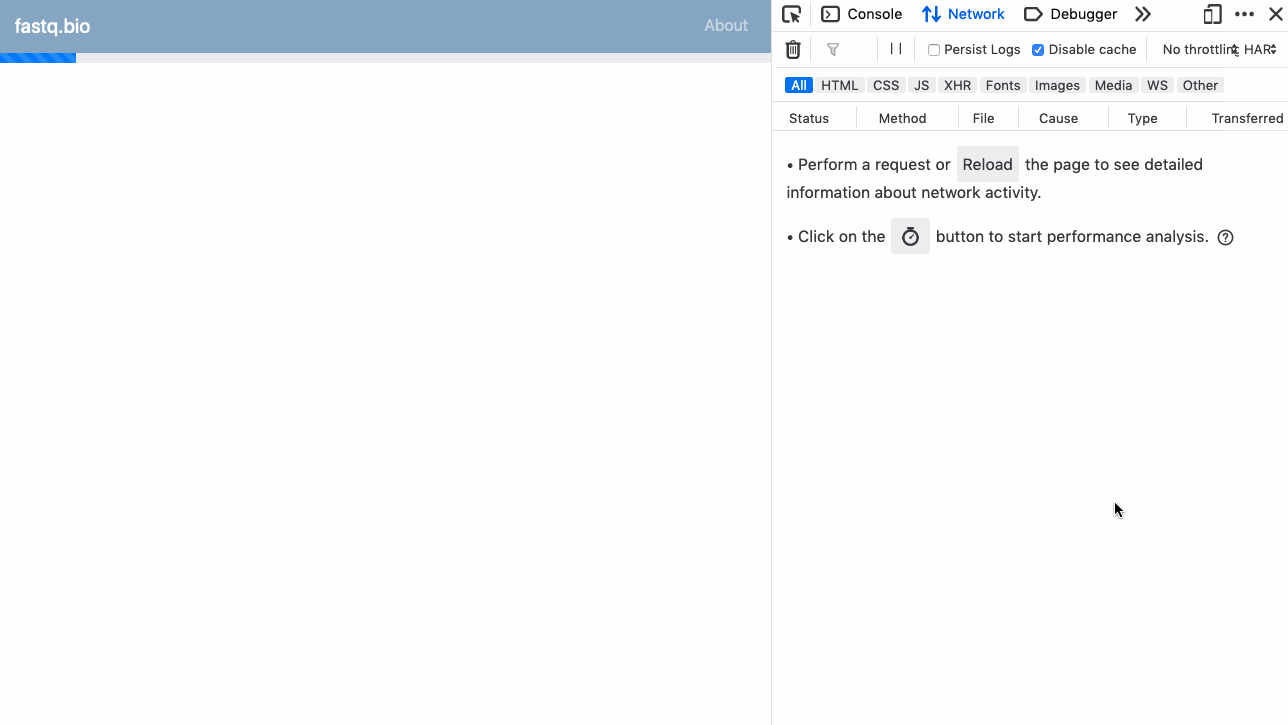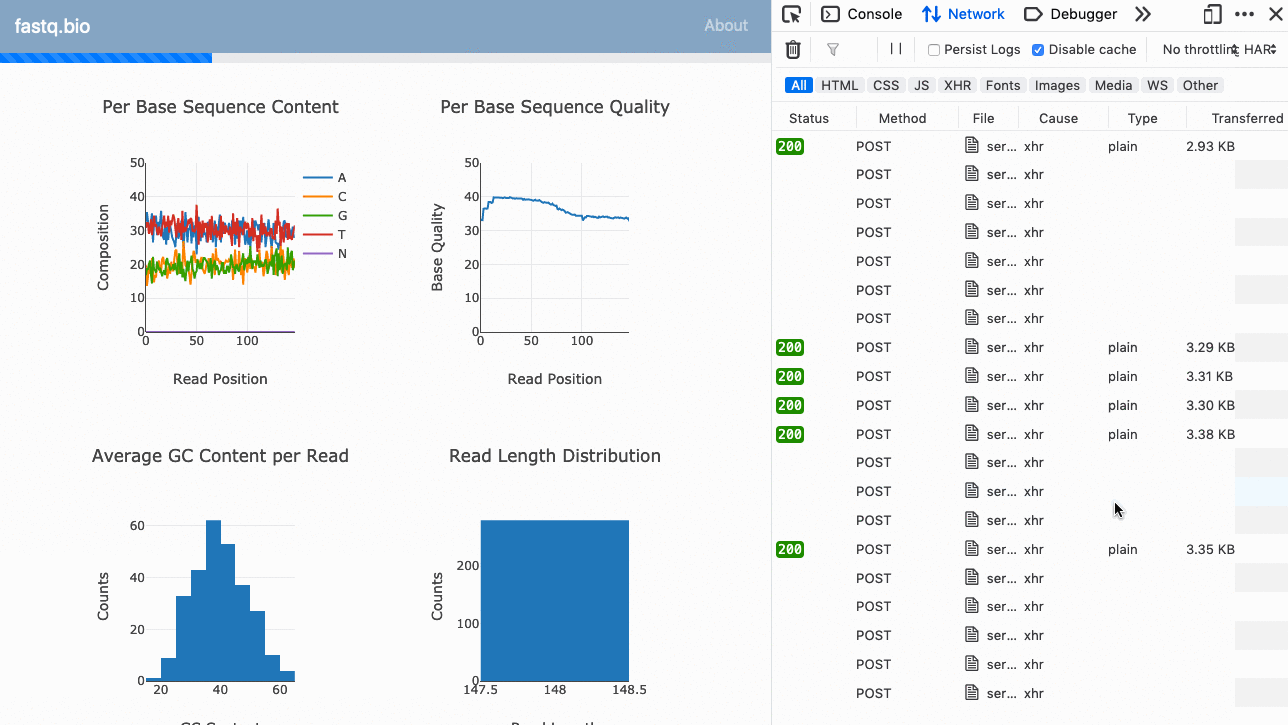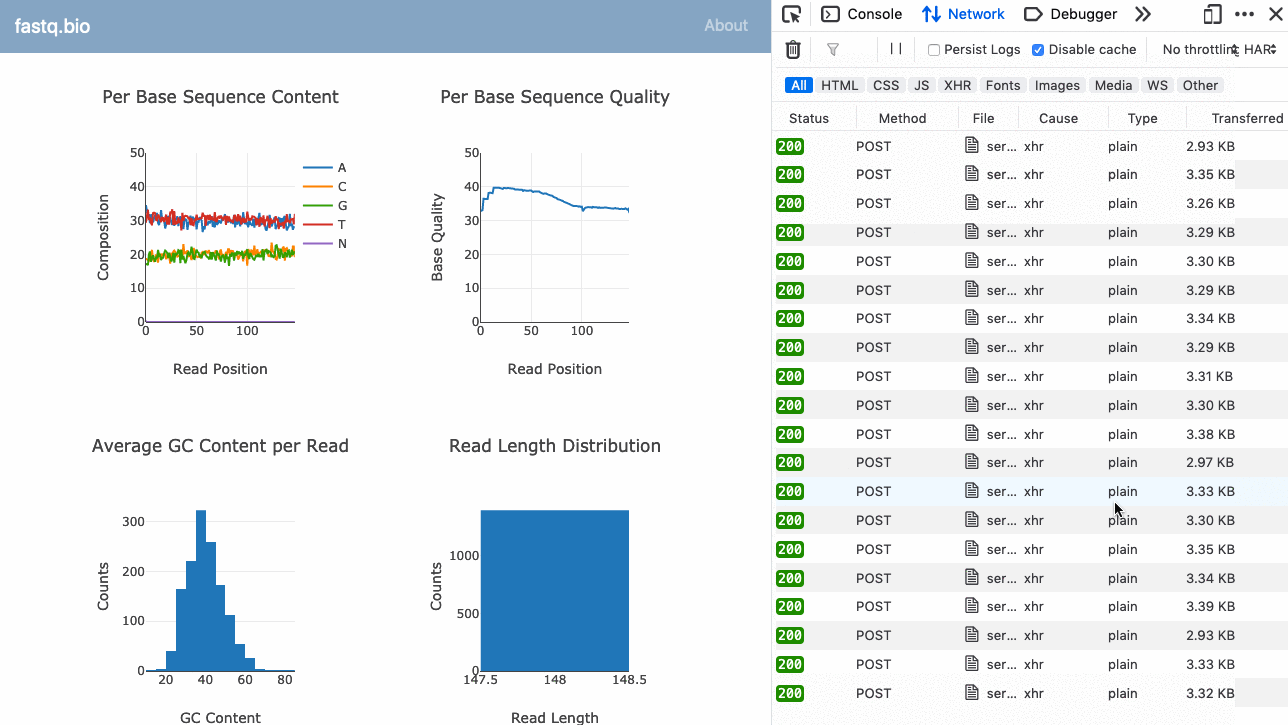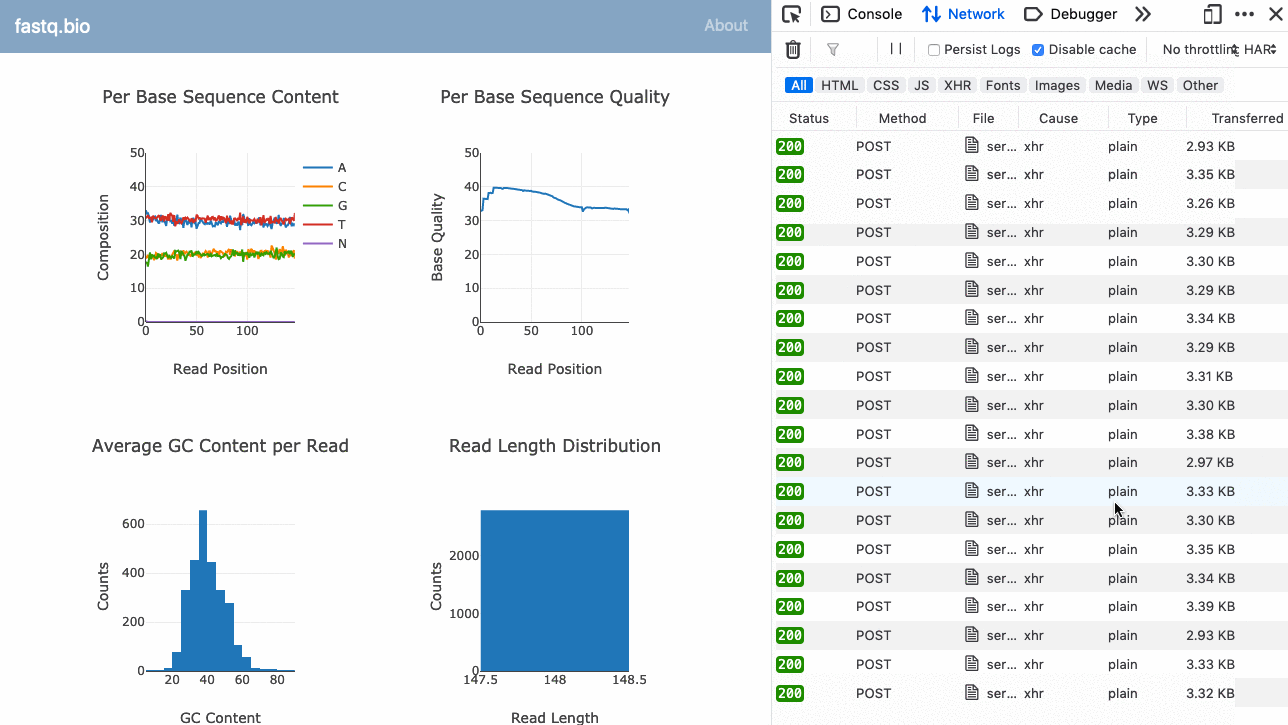
Pełny kod jest dostępny na GitHub (open source).
Umieszczanie wszystkiego w kontekście
Aby umieścić bezserwerowe podejście WebAssembly w kontekście, rozważmy cztery główne sposoby, w jakie możemy budować aplikacje internetowe do przetwarzania danych (tj. aplikacje internetowe, w których przeprowadzamy analizę danych dostarczonych przez użytkownika):
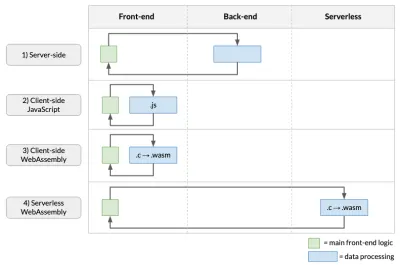
Jak pokazano powyżej, przetwarzanie danych może odbywać się w kilku miejscach:
- Po stronie serwera
Jest to podejście stosowane przez większość aplikacji internetowych, w których wywołania API wykonane na froncie uruchamiają przetwarzanie danych na zapleczu. - JavaScript po stronie klienta
W tym podejściu kod przetwarzania danych jest pisany w JavaScript i uruchamiany w przeglądarce. Minusem jest to, że twoja wydajność spadnie, a jeśli oryginalny kod nie był w JavaScript, będziesz musiał przepisać go od zera! - Zespół WWW po stronie klienta
Wiąże się to z kompilacją kodu analizy danych do WebAssembly i uruchomieniem go w przeglądarce. Jeśli kod analizy został napisany w językach takich jak C, C++ lub Rust (jak to często bywa w mojej dziedzinie genomiki), eliminuje to potrzebę przepisywania złożonych algorytmów w JavaScript. Daje również możliwość przyspieszenia naszej aplikacji (np. jak omówiono w poprzednim artykule). - Bezserwerowy zestaw WWW
Wiąże się to z uruchomieniem skompilowanego WebAssembly w chmurze przy użyciu modelu typu FaaS (np. ten artykuł).
Dlaczego więc wybrać podejście bezserwerowe zamiast innych? Z jednej strony, w porównaniu z pierwszym podejściem, ma zalety, które wiążą się z używaniem WebAssembly, zwłaszcza możliwość przenoszenia istniejącego kodu bez konieczności przepisywania go do JavaScript. W porównaniu z trzecim podejściem, bezserwerowy WebAssembly oznacza również, że nasza aplikacja jest lżejsza, ponieważ nie wykorzystujemy zasobów użytkownika do przetwarzania liczb. W szczególności, jeśli obliczenia są dość skomplikowane lub jeśli dane znajdują się już w chmurze, to podejście ma więcej sensu.
Z drugiej jednak strony aplikacja musi teraz nawiązywać połączenia sieciowe, więc prawdopodobnie będzie wolniejsza. Ponadto, w zależności od skali obliczeń i tego, czy można je podzielić na mniejsze fragmenty analizy, podejście to może nie być odpowiednie ze względu na ograniczenia narzucone przez dostawców chmury bezserwerowej w zakresie wykorzystania czasu wykonywania, procesora i pamięci RAM.
Wniosek
Jak widzieliśmy, możliwe jest teraz uruchamianie kodu WebAssembly w sposób bezserwerowy i czerpanie korzyści zarówno z WebAssembly (przenośność i szybkość), jak i architektur typu „funkcja jako usługa” (automatyczne skalowanie i ceny za użycie ). Niektóre typy aplikacji — takie jak analiza danych i przetwarzanie obrazów, żeby wymienić tylko kilka — mogą w dużym stopniu skorzystać na takim podejściu. Chociaż środowisko wykonawcze cierpi z powodu dodatkowych połączeń w obie strony do sieci, to podejście pozwala nam przetwarzać więcej danych naraz i nie obciążać zasobów użytkowników.