Przewodnik dla początkujących dla splotowych sieci neuronowych (CNN)
Opublikowany: 2021-07-05Ostatnia dekada przyniosła ogromny rozwój sztucznej inteligencji i inteligentniejszych maszyn. Dziedzina ta dała początek wielu subdyscyplinom, które specjalizują się w różnych aspektach ludzkiej inteligencji. Na przykład przetwarzanie języka naturalnego próbuje zrozumieć i modelować ludzką mowę, podczas gdy wizja komputerowa ma na celu zapewnienie maszynom wizji podobnej do człowieka.
Ponieważ będziemy mówić o splotowych sieciach neuronowych, skupimy się głównie na wizji komputerowej. Wizja komputerowa ma na celu umożliwienie maszynom patrzenia na świat tak jak my i rozwiązywanie problemów związanych z rozpoznawaniem obrazów, klasyfikacją obrazów i nie tylko. Splotowe sieci neuronowe służą do realizacji różnych zadań wizji komputerowej. Znane również jako CNN lub ConvNet, podążają za architekturą, która przypomina wzorce i połączenia neuronów w ludzkim mózgu i są inspirowane różnymi procesami biologicznymi zachodzącymi w mózgu, aby umożliwić komunikację.
Spis treści
Biologiczne znaczenie zawiłej sieci neuronowej
CNN są inspirowane naszą korą wzrokową. Jest to obszar kory mózgowej, który bierze udział w przetwarzaniu wzrokowym w naszym mózgu. Kora wzrokowa ma różne małe regiony komórkowe, które są wrażliwe na bodźce wzrokowe.
Pomysł ten został rozwinięty w 1962 roku przez Hubela i Wiesela w eksperymencie, w którym odkryto, że różne odrębne komórki neuronalne reagują (są wystrzeliwane) na obecność wyraźnych krawędzi o określonej orientacji. Na przykład, niektóre neurony wystrzeliłyby po wykryciu krawędzi poziomych, inne po wykryciu krawędzi ukośnych, a jeszcze inne po wykryciu krawędzi pionowych. Poprzez ten eksperyment. Hubel i Wiesel odkryli, że neurony są zorganizowane w sposób modułowy, a wszystkie moduły razem są wymagane do wytworzenia percepcji wzrokowej.
To modułowe podejście – idea, że wyspecjalizowane komponenty wewnątrz systemu mają określone zadania – stanowi podstawę CNN.
Po ustaleniu tego przejdźmy do tego, jak stacje CNN uczą się postrzegać sygnały wizualne.

Splotowe uczenie się sieci neuronowych
Obrazy składają się z pojedynczych pikseli, które reprezentują liczby od 0 do 255. Tak więc każdy obraz, który widzisz, można przekonwertować na odpowiednią cyfrową reprezentację za pomocą tych liczb – i tak też działają komputery z obrazami.
Oto kilka głównych operacji, które wymagają uczenia CNN w celu wykrywania lub klasyfikacji obrazów. To da ci wyobrażenie o tym, jak odbywa się nauka w CNN.
1. Konwolucja
Splot może być matematycznie rozumiany jako połączona integracja dwóch różnych funkcji, aby dowiedzieć się, jak różne funkcje mają wpływ lub modyfikują się nawzajem. Oto jak można to zdefiniować w kategoriach matematycznych:
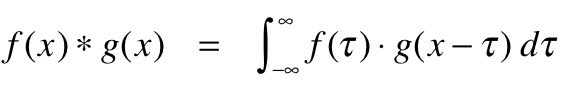
Celem splotu jest wykrycie różnych cech wizualnych na obrazach, takich jak linie, krawędzie, kolory, cienie i inne. Jest to bardzo przydatna właściwość, ponieważ gdy CNN pozna cechy określonej cechy obrazu, może później rozpoznać tę cechę w dowolnej innej części obrazu.
Sieci CNN wykorzystują jądra lub filtry do wykrywania różnych funkcji obecnych na każdym obrazie. Jądra to tylko macierz odrębnych wartości (znanych jako wagi w świecie sztucznych sieci neuronowych) wyszkolonych do wykrywania określonych cech. Filtr przesuwa się po całym obrazie, aby sprawdzić, czy wykryto jakąkolwiek funkcję, czy nie. Filtr wykonuje operację splotu, aby zapewnić ostateczną wartość, która reprezentuje stopień pewności, że dana funkcja jest obecna.
Jeśli na obrazie występuje cecha, wynikiem operacji splotu jest liczba dodatnia o dużej wartości. Jeśli funkcja jest nieobecna, operacja splotu daje w wyniku 0 lub liczbę o bardzo niskiej wartości.
Zrozummy to lepiej na przykładzie. Na poniższym obrazku filtr został przeszkolony do wykrywania znaku plus. Następnie filtr jest przepuszczany przez oryginalny obraz. Ponieważ część oryginalnego obrazu zawiera te same funkcje, do których jest wyszkolony filtr, wartości w każdej komórce, w której istnieje funkcja, są liczbą dodatnią. Podobnie wynik operacji splotu również spowoduje dużą liczbę.
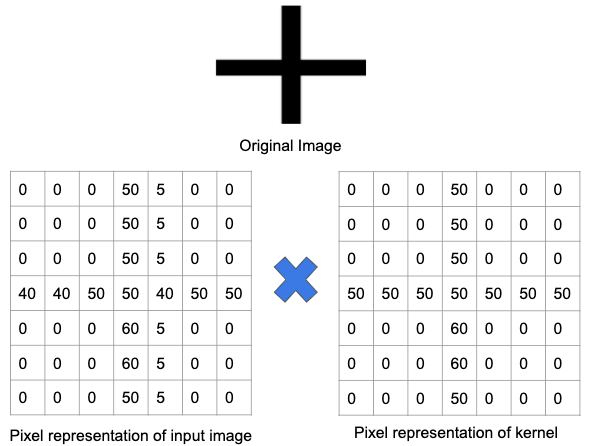
Jednak gdy ten sam filtr zostanie przepuszczony przez obraz z innym zestawem cech i krawędzi, wynik operacji splotu będzie niższy – co oznacza, że na obrazie nie było wyraźnego znaku plus.
Tak więc w przypadku złożonych obrazów o różnych cechach, takich jak krzywe, krawędzie, kolory itd., będziemy potrzebować N takich detektorów cech.
Kiedy ten filtr jest przepuszczany przez obraz, generowana jest mapa cech, która jest w zasadzie macierzą wyjściową, która przechowuje sploty tego filtra w różnych częściach obrazu. W przypadku wielu filtrów otrzymamy wynik 3D. Aby operacja splotu miała miejsce, filtr ten powinien mieć taką samą liczbę kanałów jak obraz wejściowy.
Ponadto filtr można przesuwać po obrazie wejściowym w różnych odstępach czasu, używając wartości kroku. Wartość kroku informuje o tym, jak bardzo filtr powinien się przesunąć na każdym kroku.
Liczbę warstw wyjściowych danego bloku splotowego można zatem określić za pomocą następującego wzoru:

2. Wypełnienie
Jednym z problemów podczas pracy z warstwami splotowymi jest to, że niektóre piksele są tracone na obwodzie oryginalnego obrazu. Ponieważ ogólnie używane filtry są małe, liczba utraconych pikseli na filtr może wynosić kilka, ale to się sumuje, gdy stosujemy różne warstwy splotowe, co powoduje utratę wielu pikseli.
Koncepcja dopełnienia polega na dodawaniu dodatkowych pikseli do obrazu podczas przetwarzania go przez filtr CNN. Jest to jedno z rozwiązań, które pomaga filtrowi w przetwarzaniu obrazu – dopełniając obraz zerami, aby zapewnić więcej miejsca dla jądra na pokrycie całego obrazu. Dzięki dodaniu zerowych wypełnień do filtrów przetwarzanie obrazu przez CNN jest znacznie dokładniejsze i dokładniejsze.
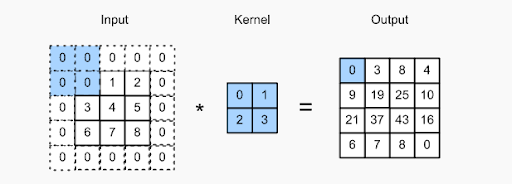

Sprawdź powyższy obrazek – wypełnienie zostało wykonane przez dodanie dodatkowych zer na granicy obrazu wejściowego. Umożliwia to uchwycenie wszystkich charakterystycznych funkcji bez utraty pikseli.
3. Mapa aktywacji
Mapy obiektów muszą być przekazywane przez funkcję mapowania, która ma charakter nieliniowy. Mapy cech są dołączane do terminu odchylenia, a następnie przekazywane przez funkcję aktywacji (ReLu), która jest nieliniowa. Ta funkcja ma na celu wprowadzenie pewnej dozy nieliniowości do CNN, ponieważ obrazy, które są wykrywane i badane, są również z natury nieliniowe, ponieważ składają się z różnych obiektów.
4. Etap łączenia
Po zakończeniu fazy aktywacji przechodzimy do etapu łączenia, w którym CNN dokonuje próbkowania w dół splątanych funkcji, co pomaga skrócić czas przetwarzania. Pomaga to również w zmniejszeniu ogólnego rozmiaru obrazu, nadmiernego dopasowania i innych problemów, które mogłyby wystąpić, gdyby zawiłe sieci neuronowe były zasilane dużą ilością informacji – zwłaszcza jeśli te informacje nie są zbyt istotne w klasyfikacji lub wykrywaniu obrazu.
Pooling jest zasadniczo dwojakiego rodzaju – łączenie maksymalne i łączenie minimalne. W pierwszym przypadku okno jest przesuwane nad obrazem zgodnie z ustaloną wartością kroku, a na każdym kroku maksymalna wartość zawarta w oknie jest gromadzona w macierzy wyjściowej. W puli minimalnej wartości minimalne są gromadzone w macierzy wyjściowej.
Nowa macierz utworzona w wyniku danych wyjściowych nosi nazwę połączonej mapy funkcji.
Jedną z korzyści z puli minimalnej i maksymalnej jest to, że CNN może skupić się na kilku neuronach, które mają wysokie wartości, zamiast skupiać się na wszystkich neuronach. Takie podejście sprawia, że jest bardzo mniej prawdopodobne przepełnienie danych treningowych i sprawia, że ogólne przewidywanie i uogólnianie przebiegają dobrze.
5. Spłaszczanie
Po zakończeniu łączenia reprezentacja 3D obrazu została teraz przekształcona w wektor cech. Jest on następnie przekazywany do wielowarstwowego perceptronu w celu wytworzenia danych wyjściowych. Sprawdź poniższy obraz, aby lepiej zrozumieć operację spłaszczania:
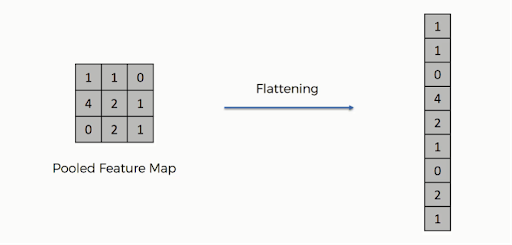
Jak widać, wiersze macierzy są połączone w pojedynczy wektor cech. Jeśli istnieje wiele warstw wejściowych, wszystkie wiersze są połączone, tworząc dłuższy spłaszczony wektor cech.
6. W pełni połączona warstwa (FCL)
Na tym etapie spłaszczona mapa jest przesyłana do sieci neuronowej. Kompletne połączenie sieci neuronowej obejmuje warstwę wejściową, FCL i końcową warstwę wyjściową. W pełni połączoną warstwę można rozumieć jako ukryte warstwy w sztucznych sieciach neuronowych, z wyjątkiem tego, że w przeciwieństwie do warstw ukrytych warstwy te są w pełni połączone. Informacja przechodzi przez całą sieć i obliczany jest błąd przewidywania. Ten błąd jest następnie przesyłany jako informacja zwrotna (propagacja wsteczna) przez systemy w celu dostosowania wag i poprawy końcowego wyniku, aby był bardziej dokładny.
Ostateczny wynik uzyskany z powyższej warstwy sieci neuronowej generalnie nie sumuje się do jednego. Te wyniki muszą być sprowadzone do liczb z zakresu [0,1] – które będą wtedy reprezentować prawdopodobieństwa każdej klasy. W tym celu używana jest funkcja Softmax.
Wyjście uzyskane z gęstej warstwy jest podawane do funkcji aktywacji Softmax. Dzięki temu wszystkie końcowe dane wyjściowe są mapowane na wektor, w którym suma wszystkich elementów jest jednym.
W pełni połączona warstwa działa na podstawie wyników poprzedniej warstwy, a następnie określa, która funkcja jest najbardziej skorelowana z określoną klasą. Tak więc, jeśli program przewiduje, czy obraz zawiera kota, czy nie, będzie miał wysokie wartości na mapach aktywacji, które reprezentują cechy, takie jak cztery nogi, łapy, ogon i tak dalej. Podobnie, jeśli program przewiduje coś innego, będzie miał różne typy map aktywacji. W pełni połączona warstwa zajmuje się różnymi cechami, które silnie korelują z poszczególnymi klasami i wagami, dzięki czemu obliczenia między wagami a poprzednią warstwą są dokładne i otrzymujesz prawidłowe prawdopodobieństwa dla różnych klas wyników.
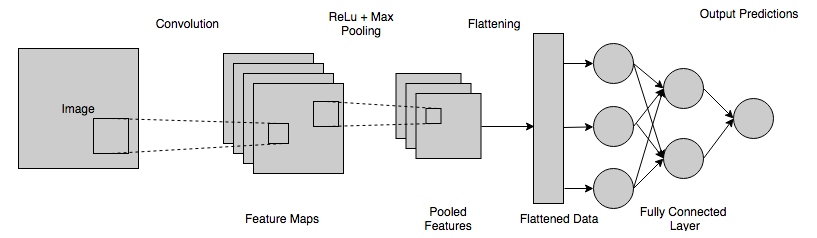
Krótkie podsumowanie działania CNN
Oto krótkie podsumowanie całego procesu działania CNN i pomocy w wizji komputerowej:
- Różne piksele z obrazu są podawane do warstwy splotowej, gdzie wykonywana jest operacja splotu.
- Wynikiem poprzedniego kroku jest mapa zawikłana.
- Ta mapa jest przekazywana przez funkcję prostowniczą, aby dać początek skorygowanej mapie.
- Obraz jest przetwarzany z różnymi zwojami i funkcjami aktywacji w celu lokalizowania i wykrywania różnych cech.
- Warstwy zbiorcze służą do identyfikowania określonych, odrębnych części obrazu.
- Połączona warstwa jest spłaszczana i używana jako dane wejściowe do w pełni połączonej warstwy.
- Warstwa w pełni połączona oblicza prawdopodobieństwa i daje wynik w zakresie [0,1].
Na zakończenie
Wewnętrzne funkcjonowanie CNN jest bardzo ekscytujące i otwiera wiele możliwości innowacji i tworzenia. Podobnie inne technologie pod parasolem sztucznej inteligencji są fascynujące i próbują współpracować między ludzkimi możliwościami a inteligencją maszyn. Dzięki temu ludzie z całego świata, należący do różnych dziedzin, realizują swoje zainteresowanie tą dziedziną i stawiają pierwsze kroki.
Na szczęście branża AI jest wyjątkowo przyjazna i nie wyróżnia się na podstawie twojego wykształcenia. Wystarczy praktyczna znajomość technologii wraz z podstawowymi kwalifikacjami i gotowe!
Jeśli chcesz opanować sedno ML i AI, idealnym rozwiązaniem byłoby zapisanie się do profesjonalnego programu AI/ML. Na przykład nasz program wykonawczy w zakresie uczenia maszynowego i sztucznej inteligencji jest idealnym kursem dla aspirujących do nauki o danych. Program obejmuje takie tematy, jak statystyka i eksploracyjna analiza danych, uczenie maszynowe i przetwarzanie języka naturalnego. Ponadto zawiera ponad 13 projektów branżowych, ponad 25 sesji na żywo i 6 projektów zwieńczenia. Najlepsze w tym kursie jest to, że możesz wchodzić w interakcje z rówieśnikami z całego świata. Ułatwia wymianę pomysłów i pomaga uczącym się budować trwałe relacje z ludźmi z różnych środowisk. Nasza 360-stopniowa pomoc w karierze jest właśnie tym, czego potrzebujesz, aby osiągnąć sukces w swojej podróży ML i AI!
Poprowadź rewolucję technologiczną napędzaną sztuczną inteligencją