
Twierdzenie Bayesa w uczeniu maszynowym: wprowadzenie, zastosowanie i przykład
Opublikowany: 2021-02-04Spis treści
Wprowadzenie: Co to jest twierdzenie Bayesa?
Twierdzenie Bayesa zostało nazwane na cześć angielskiego matematyka Thomasa Bayesa, który intensywnie pracował w teorii decyzji, dziedzinie matematyki obejmującej prawdopodobieństwa. Twierdzenie Bayesa jest również szeroko stosowane w uczeniu maszynowym, gdzie jest prostym, skutecznym sposobem przewidywania klas z precyzją i dokładnością. Bayesowska metoda obliczania prawdopodobieństw warunkowych jest używana w aplikacjach uczenia maszynowego, które obejmują zadania klasyfikacyjne.
Uproszczona wersja twierdzenia Bayesa, znana jako naiwna klasyfikacja Bayesa, służy do skrócenia czasu i kosztów obliczeń. W tym artykule przeprowadzimy Cię przez te koncepcje i omówimy zastosowania twierdzenia Bayesa w uczeniu maszynowym.
Dołącz do kursu uczenia maszynowego online z najlepszych światowych uniwersytetów — studiów magisterskich, programów podyplomowych dla kadry kierowniczej i zaawansowanego programu certyfikacji w zakresie uczenia się maszynowego i sztucznej inteligencji, aby przyspieszyć swoją karierę.
Dlaczego warto korzystać z twierdzenia Bayesa w uczeniu maszynowym?
Twierdzenie Bayesa to metoda wyznaczania prawdopodobieństw warunkowych – czyli prawdopodobieństwa wystąpienia jednego zdarzenia, biorąc pod uwagę, że już zaszło inne zdarzenie. Ponieważ prawdopodobieństwo warunkowe zawiera dodatkowe warunki – innymi słowy więcej danych – może przyczynić się do dokładniejszych wyników.
Zatem prawdopodobieństwa warunkowe są niezbędne do określenia dokładnych prognoz i prawdopodobieństw w uczeniu maszynowym. Biorąc pod uwagę, że dziedzina ta staje się coraz bardziej wszechobecna w różnych dziedzinach, ważne jest zrozumienie roli algorytmów i metod, takich jak twierdzenie Bayesa w uczeniu maszynowym.
Zanim przejdziemy do samego twierdzenia, zrozummy kilka terminów na przykładzie. Załóżmy, że kierownik księgarni ma informacje o wieku i dochodach swoich klientów. Chce wiedzieć, jak sprzedaż książek rozkłada się na trzy grupy wiekowe klientów: młodzież (18-35 lat), osoby w średnim wieku (35-60) i seniorzy (60+).

Nazwijmy nasze dane X. W terminologii bayesowskiej X nazywamy dowodem. Mamy pewną hipotezę H, gdzie mamy trochę X, który należy do pewnej klasy C.
Naszym celem jest wyznaczenie warunkowego prawdopodobieństwa naszej hipotezy H przy danej X, tj. P(H | X).
W uproszczeniu, wyznaczając P(H | X), otrzymujemy prawdopodobieństwo przynależności X do klasy C przy założeniu, że X. X ma atrybuty wieku i dochodu – powiedzmy na przykład 26 lat z dochodem 2000 zł. H to nasza hipoteza, że klient kupi książkę.
Zwróć szczególną uwagę na następujące cztery terminy:
- Dowód – jak omówiono wcześniej, P(X) jest znany jako dowód. Jest to po prostu prawdopodobieństwo, że klient w tym przypadku będzie miał 26 lat i zarobi 2000 USD.
- Prawdopodobieństwo a priori – P(H), znane jako prawdopodobieństwo a priori, jest prostym prawdopodobieństwem naszej hipotezy – mianowicie, że klient kupi książkę. To prawdopodobieństwo nie zostanie podane z dodatkowymi danymi wejściowymi opartymi na wieku i dochodach. Ponieważ obliczenia są wykonywane z mniejszą ilością informacji, wynik jest mniej dokładny.
- Prawdopodobieństwo a posteriori – P(H | X) jest znane jako prawdopodobieństwo a posteriori. Tutaj P(H | X) to prawdopodobieństwo, że klient kupi książkę (H), biorąc pod uwagę X (że ma 26 lat i zarabia 2000 USD).
- Prawdopodobieństwo – P(X | H) to prawdopodobieństwo prawdopodobieństwa. W tym przypadku, zakładając, że wiemy, że klient kupi książkę, prawdopodobieństwo prawdopodobieństwa to prawdopodobieństwo, że klient ma 26 lat i dochód w wysokości 2000 USD.
Biorąc to pod uwagę, twierdzenie Bayesa stwierdza:
P(H | X) = [ P(X | H) * P(H) ] / P(X)
Zwróć uwagę na pojawienie się czterech powyższych terminów w twierdzeniu – prawdopodobieństwo a posteriori, prawdopodobieństwo prawdopodobieństwa, prawdopodobieństwo a priori i dowody.
Przeczytaj: Wyjaśnienie naiwnego Bayesa
Jak zastosować twierdzenie Bayesa w uczeniu maszynowym
Naive Bayes Classifier, uproszczona wersja twierdzenia Bayesa, jest używany jako algorytm klasyfikacji do klasyfikacji danych na różne klasy z dokładnością i szybkością.
Zobaczmy, jak naiwny klasyfikator Bayesa można zastosować jako algorytm klasyfikacji.
- Rozważmy ogólny przykład: X jest wektorem składającym się z „n” atrybutów, to znaczy X = {x1, x2, x3, …, xn}.
- Powiedzmy, że mamy klasy „m” {C1, C2, …, Cm}. Nasz klasyfikator będzie musiał przewidzieć, że X należy do określonej klasy. Klasa dająca najwyższe prawdopodobieństwo a posteriori zostanie wybrana jako najlepsza klasa. Tak więc z matematycznego punktu widzenia klasyfikator przewidzi klasę Ci, jeśli P(Ci | X) > P(Cj | X). Stosowanie twierdzenia Bayesa:
P(Ci | X) = [ P(X | Ci) * P(Ci) ] / P(X)
- P(X), będąc niezależnym od warunków, jest stałe dla każdej klasy. Zatem aby zmaksymalizować P(Ci | X), musimy zmaksymalizować [P(X | Ci) * P(Ci)]. Biorąc pod uwagę, że każda klasa jest równie prawdopodobna, mamy P(C1) = P(C2) = P(C3) … = P(Cn). Więc ostatecznie musimy zmaksymalizować tylko P(X | Ci).
- Ponieważ typowy duży zbiór danych może mieć kilka atrybutów, wykonanie operacji P(X | Ci) dla każdego atrybutu jest obliczeniowo kosztowne. W tym miejscu pojawia się niezależność od warunków klasowych, aby uprościć problem i zmniejszyć koszty obliczeń. Przez niezależność warunkową klasową rozumiemy, że uważamy wartości atrybutu za niezależne od siebie warunkowo. To jest naiwna klasyfikacja Bayesa.
P(Xi | C) = P(x1 | C) * P(x2 | C) *… * P(xn | C)
Teraz można łatwo obliczyć mniejsze prawdopodobieństwa. Należy tutaj zwrócić uwagę na jedną ważną rzecz: ponieważ xk należy do każdego atrybutu, musimy również sprawdzić, czy mamy do czynienia z atrybutem kategorycznym, czy ciągłym .
- Jeśli mamy atrybut kategoryczny , sprawa jest prostsza. Możemy po prostu policzyć liczbę wystąpień klasy Ci składających się z wartości xk dla atrybutu k, a następnie podzielić ją przez liczbę wystąpień klasy Ci.
- Jeśli mamy atrybut ciągły, biorąc pod uwagę, że mamy rozkład normalny, stosujemy następujący wzór, ze średnią ? i odchylenie standardowe ?:
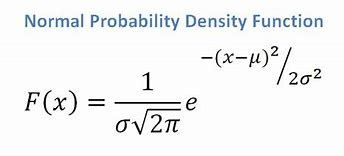

Źródło
Ostatecznie będziemy mieli P(x | Ci) = F(xk, ?k, ?k).
- Teraz mamy wszystkie wartości, których potrzebujemy, aby użyć twierdzenia Bayesa dla każdej klasy Ci. Nasza przewidywana klasa będzie klasą osiągającą najwyższe prawdopodobieństwo P(X | Ci) * P(Ci).
Przykład: Predykcyjne klasyfikowanie klientów księgarni
Mamy następujący zbiór danych z księgarni:
| Wiek | Dochód | Student | Credit_Rating | Kupuje_książkę |
| Młodzież | Wysoka | Nie | Sprawiedliwy | Nie |
| Młodzież | Wysoka | Nie | Doskonały | Nie |
| W średnim wieku | Wysoka | Nie | Sprawiedliwy | TAk |
| Senior | Średni | Nie | Sprawiedliwy | TAk |
| Senior | Niski | TAk | Sprawiedliwy | TAk |
| Senior | Niski | TAk | Doskonały | Nie |
| W średnim wieku | Niski | TAk | Doskonały | TAk |
| Młodzież | Średni | Nie | Sprawiedliwy | Nie |
| Młodzież | Niski | TAk | Sprawiedliwy | TAk |
| Senior | Średni | TAk | Sprawiedliwy | TAk |
| Młodzież | Średni | TAk | Doskonały | TAk |
| W średnim wieku | Średni | Nie | Doskonały | TAk |
| W średnim wieku | Wysoka | TAk | Sprawiedliwy | TAk |
| Senior | Średni | Nie | Doskonały | Nie |
Mamy atrybuty takie jak wiek, dochód, student i zdolność kredytowa. Nasza klasa buys_book ma dwa wyniki: Tak lub Nie.
Naszym celem jest klasyfikacja na podstawie następujących atrybutów:
X = {wiek = młodzież, student = tak, dochód = średni, credit_rating = sprawiedliwy}.
Jak pokazaliśmy wcześniej, aby zmaksymalizować P(Ci | X), musimy zmaksymalizować [ P(X | Ci) * P(Ci) ] dla i = 1 oraz i = 2.
Stąd P(buys_book = tak) = 9/14 = 0,643
P(książka_zakupów = nie) = 5/14 = 0,357
P(wiek = młodzież | książka_zakupów = tak) = 2/9 = 0,222
P(wiek = młodzież | książka_zakupów = nie) = 3/5 = 0,600
P(dochód = średni | zakup_książki = tak) = 4/9 = 0,444
P(dochód = średni | buys_book = nie) = 2/5 = 0,400
P(student = tak | kupuje_książkę = tak) = 6/9 = 0,667
P(student = tak | kupuje_książkę = nie) = 1/5 = 0,200
P(ocena_kredytu = uczciwa | książka_zakupów = tak) = 6/9 = 0,667
P(credit_rating = uczciwy | buys_book = nie) = 2/5 = 0,400
Korzystając z obliczonych powyżej prawdopodobieństw, mamy
P(X | buys_book = tak) = 0,222 x 0,444 x 0,667 x 0,667 = 0,044
Podobnie,
P(X | książka_zakupów = nie) = 0,600 x 0,400 x 0,200 x 0,400 = 0,019
Która klasa Ci zapewnia maksymalne P(X|Ci)*P(Ci)? Obliczamy:
P(X | książka_zakupów = tak)* P(książka_zakupów = tak) = 0,044 x 0,643 = 0,028
P(X | książka_zakupów = nie)* P(książka_zakupów = nie) = 0,019 x 0,357 = 0,007
Porównując powyższe dwa, ponieważ 0,028 > 0,007 Naive Bayes Classifier przewiduje, że klient o ww. atrybutach kupi książkę.
Zamówienie: pomysły i tematy projektów uczenia maszynowego
Czy klasyfikator bayesowski jest dobrą metodą?
Algorytmy oparte na twierdzeniu Bayesa w uczeniu maszynowym zapewniają wyniki porównywalne z innymi algorytmami, a klasyfikatory bayesowskie są ogólnie uważane za proste metody o wysokiej dokładności. Należy jednak pamiętać, że klasyfikatory bayesowskie są szczególnie odpowiednie tam, gdzie założenie o niezależności warunkowej klas jest ważne, a nie we wszystkich przypadkach. Innym praktycznym problemem jest to, że uzyskanie wszystkich danych prawdopodobieństwa może nie zawsze być wykonalne.
Wniosek
Twierdzenie Bayesa ma wiele zastosowań w uczeniu maszynowym, szczególnie w problemach opartych na klasyfikacji. Zastosowanie tej rodziny algorytmów w uczeniu maszynowym wymaga znajomości takich terminów, jak prawdopodobieństwo a priori i prawdopodobieństwo a posteriori. W tym artykule omówiliśmy podstawy twierdzenia Bayesa, jego zastosowanie w problemach z uczeniem maszynowym i omówiliśmy przykład klasyfikacji.
Ponieważ twierdzenie Bayesa stanowi kluczową część algorytmów opartych na klasyfikacji w uczeniu maszynowym, możesz dowiedzieć się więcej o zaawansowanym programie certyfikacji upGrad w uczeniu maszynowym i NLP . Ten kurs został stworzony z myślą o różnych rodzajach uczniów zainteresowanych uczeniem maszynowym, oferując mentoring 1-1 i wiele więcej.
Dlaczego używamy twierdzenia Bayesa w uczeniu maszynowym?
Twierdzenie Bayesa to metoda obliczania prawdopodobieństw warunkowych lub prawdopodobieństwa wystąpienia jednego zdarzenia, jeśli poprzednio wystąpiło inne. Prawdopodobieństwo warunkowe może prowadzić do dokładniejszych wyników, uwzględniając dodatkowe warunki — innymi słowy, więcej danych. Aby uzyskać poprawne oszacowania i prawdopodobieństwa w uczeniu maszynowym, wymagane są prawdopodobieństwa warunkowe. Biorąc pod uwagę rosnącą popularność tej dziedziny w wielu różnych dziedzinach, niezwykle ważne jest zrozumienie znaczenia algorytmów i podejść, takich jak twierdzenie Bayesa w uczeniu maszynowym.
Czy klasyfikator bayesowski to dobry wybór?
W uczeniu maszynowym algorytmy oparte na twierdzeniu Bayesa dają wyniki porównywalne z wynikami innych metod, a klasyfikatory bayesowskie są powszechnie uważane za proste podejścia o wysokiej dokładności. Należy jednak pamiętać, że klasyfikatorów bayesowskich najlepiej używać, gdy warunek niezależności warunkowej klasy jest poprawny, nie we wszystkich okolicznościach. Inną kwestią jest to, że uzyskanie wszystkich danych dotyczących prawdopodobieństwa może nie zawsze być możliwe.
Jak można praktycznie zastosować twierdzenie Bayesa?
Twierdzenie Bayesa oblicza prawdopodobieństwo wystąpienia na podstawie nowych dowodów, które są lub mogą być z nim powiązane. Metodę można również wykorzystać do sprawdzenia, jak hipotetyczne nowe informacje wpływają na prawdopodobieństwo zdarzenia, zakładając, że nowe informacje są prawdziwe. Weźmy na przykład pojedynczą kartę wybraną z talii 52 kart. Prawdopodobieństwo, że karta zostanie królem, wynosi 4 podzielone przez 52, czyli 1/13, czyli około 7,69 procent. Pamiętaj, że talia zawiera czterech królów. Powiedzmy, że ujawniono, że wybrana karta to figura. Ponieważ w talii jest 12 figur, prawdopodobieństwo, że wybrana karta jest królem, wynosi 4 podzielone przez 12, czyli około 33,3 procent.