
Konfigurowanie interfejsu API za pomocą Flask, Google Cloud SQL i App Engine
Opublikowany: 2022-03-10Do tworzenia interfejsów API można użyć kilku frameworków Pythona, z których dwa to Flask i Django. Frameworks zawiera funkcjonalność, która ułatwia programistom implementację funkcji potrzebnych użytkownikom do interakcji z ich aplikacjami. Złożoność aplikacji internetowej może być decydującym czynnikiem przy wyborze frameworka do pracy.
Django
Django to solidny framework, który ma predefiniowaną strukturę z wbudowaną funkcjonalnością. Wadą jego solidności jest jednak to, że może sprawić, że struktura będzie zbyt skomplikowana dla niektórych projektów. Najlepiej nadaje się do złożonych aplikacji internetowych, które muszą wykorzystywać zaawansowaną funkcjonalność Django.
Kolba
Z drugiej strony Flask to lekka platforma do tworzenia interfejsów API. Rozpoczęcie pracy z nim jest łatwe, a dostępne są pakiety, które zapewniają jego niezawodność na bieżąco. W tym artykule skupimy się na zdefiniowaniu funkcji widoku i kontrolera oraz na połączeniu z bazą danych w Google Cloud i wdrożeniu w Google Cloud.
W celu nauki stworzymy Flask API z kilkoma punktami końcowymi do zarządzania kolekcją naszych ulubionych piosenek. Punktami końcowymi będą żądania GET i POST : pobieranie i tworzenie zasobów. Oprócz tego będziemy korzystać z pakietu usług na platformie Google Cloud. Skonfigurujemy Google Cloud SQL dla naszej bazy danych i uruchomimy naszą aplikację, wdrażając ją w App Engine. Ten samouczek jest skierowany do początkujących, którzy po raz pierwszy zaczynają używać Google Cloud w swojej aplikacji.
Konfigurowanie projektu kolby
W tym samouczku założono, że masz zainstalowany Python 3.x. Jeśli nie, przejdź na oficjalną stronę internetową, aby ją pobrać i zainstalować.
Aby sprawdzić, czy Python jest zainstalowany, uruchom interfejs wiersza poleceń (CLI) i uruchom poniższe polecenie:
python -V Naszym pierwszym krokiem jest stworzenie katalogu, w którym będzie żył nasz projekt. Nazwiemy to flask-app :
mkdir flask-app && cd flask-appPierwszą rzeczą do zrobienia podczas uruchamiania projektu w Pythonie jest stworzenie środowiska wirtualnego. Środowiska wirtualne izolują Twój działający rozwój Pythona. Oznacza to, że ten projekt może mieć własne zależności, różne od innych projektów na twoich maszynach. venv to moduł dostarczany z Pythonem 3.
Stwórzmy wirtualne środowisko w naszym katalogu flask-app :
python3 -m venv env To polecenie tworzy folder env w naszym katalogu. Nazwa (w tym przypadku env ) jest aliasem środowiska wirtualnego i może mieć dowolną nazwę.
Teraz, gdy stworzyliśmy środowisko wirtualne, musimy powiedzieć naszemu projektowi, aby z niego korzystał. Aby aktywować nasze środowisko wirtualne, użyj następującego polecenia:
source env/bin/activate Zobaczysz, że twój monit CLI ma teraz env na początku, wskazując, że nasze środowisko jest aktywne.

(env) pojawia się przed monitem (duży podgląd)Teraz zainstalujmy nasz pakiet Flask:
pip install flask Utwórz katalog o nazwie api w naszym bieżącym katalogu. Tworzymy ten katalog, aby mieć folder, w którym będą znajdować się inne foldery naszej aplikacji.
mkdir api && cd api Następnie utwórz plik main.py , który posłuży jako punkt wejścia do naszej aplikacji:
touch main.py Otwórz main.py i wprowadź następujący kod:
#main.py from flask import Flask app = Flask(__name__) @app.route('/') def home(): return 'Hello World' if __name__ == '__main__': app.run() Zrozummy, co tutaj zrobiliśmy. Najpierw zaimportowaliśmy klasę Flask z pakietu Flask. Następnie utworzyliśmy instancję klasy i przypisaliśmy ją do app . Następnie utworzyliśmy nasz pierwszy punkt końcowy, który wskazuje na katalog główny naszej aplikacji. Podsumowując, jest to funkcja widoku, która wywołuje / route — zwraca Hello World .
Uruchommy aplikację:
python main.py To uruchamia nasz lokalny serwer i obsługuje naszą aplikację na https://127.0.0.1:5000/ . Wprowadź adres URL w przeglądarce, a zobaczysz odpowiedź Hello World wydrukowaną na ekranie.
I voila! Nasza aplikacja działa. Kolejnym zadaniem jest uczynienie go funkcjonalnym.
Do wywoływania naszych punktów końcowych użyjemy Postmana, który jest usługą pomagającą programistom testować punkty końcowe. Możesz go pobrać z oficjalnej strony internetowej.
Sprawmy, aby main.py zwrócił jakieś dane:
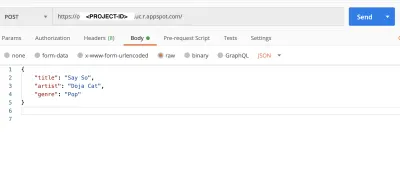
#main.py from flask import Flask, jsonify app = Flask(__name__) songs = [ { "title": "Rockstar", "artist": "Dababy", "genre": "rap", }, { "title": "Say So", "artist": "Doja Cat", "genre": "Hiphop", }, { "title": "Panini", "artist": "Lil Nas X", "genre": "Hiphop" } ] @app.route('/songs') def home(): return jsonify(songs) if __name__ == '__main__': app.run() Tutaj zamieściliśmy listę utworów, w tym tytuł utworu i nazwę wykonawcy. Następnie zmieniliśmy katalog główny / route na /songs . Ta trasa zwraca określoną przez nas tablicę utworów. Aby otrzymać naszą listę jako wartość JSON, zmodyfikowaliśmy ją w JSON, przekazując ją przez jsonify . Teraz zamiast prostego Hello world , widzimy listę wykonawców, gdy uzyskujemy dostęp do punktu końcowego https://127.0.0.1:5000/songs .
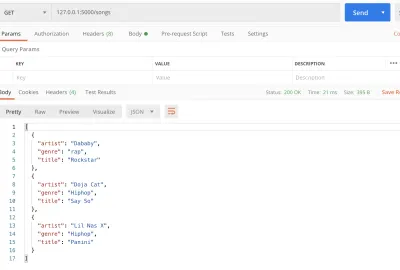
get odpowiedź od listonosza (duży podgląd) Być może zauważyłeś, że po każdej zmianie musieliśmy ponownie uruchamiać nasz serwer. Aby włączyć automatyczne ładowanie w przypadku zmiany kodu, włącz opcję debugowania. Aby to zrobić, zmień app.run na to:
app.run(debug=True) Następnie dodajmy piosenkę za pomocą żądania posta do naszej tablicy. Najpierw zaimportuj obiekt request , abyśmy mogli przetwarzać żądania przychodzące od naszych użytkowników. Później użyjemy obiektu request w funkcji widoku, aby uzyskać dane wejściowe użytkownika w formacie JSON.
#main.py from flask import Flask, jsonify, request app = Flask(__name__) songs = [ { "title": "Rockstar", "artist": "Dababy", "genre": "rap", }, { "title": "Say So", "artist": "Doja Cat", "genre": "Hiphop", }, { "title": "Panini", "artist": "Lil Nas X", "genre": "Hiphop" } ] @app.route('/songs') def home(): return jsonify(songs) @app.route('/songs', methods=['POST']) def add_songs(): song = request.get_json() songs.append(song) return jsonify(songs) if __name__ == '__main__': app.run(debug=True) Nasza funkcja widoku add_songs pobiera utwór przesłany przez użytkownika i dołącza go do naszej istniejącej listy utworów.
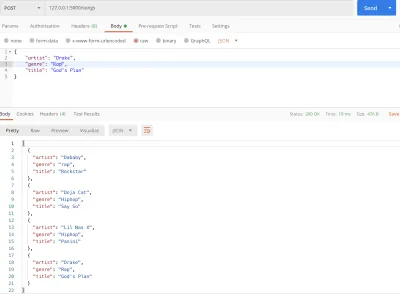
Do tej pory zwracaliśmy nasze dane z listy Pythona. To jest tylko eksperymentalne, ponieważ w bardziej niezawodnym środowisku nasze nowo dodane dane zostałyby utracone, gdybyśmy zrestartowali serwer. Nie jest to możliwe, więc będziemy potrzebować działającej bazy danych do przechowywania i pobierania danych. Wchodzi Cloud SQL.
Dlaczego warto korzystać z instancji Cloud SQL?
Według oficjalnej strony internetowej:
„Google Cloud SQL to w pełni zarządzana usługa baz danych, która ułatwia konfigurowanie, utrzymywanie, zarządzanie i administrowanie relacyjnymi bazami danych MySQL i PostgreSQL w chmurze. Cloud SQL, hostowany na platformie Google Cloud Platform, zapewnia infrastrukturę bazy danych dla aplikacji działających w dowolnym miejscu”.
Oznacza to, że możemy zlecić zarządzanie infrastrukturą bazy danych całkowicie firmie Google, po elastycznych cenach.
Różnica między Cloud SQL a samozarządzającym się silnikiem obliczeniowym
W Google Cloud możemy uruchomić maszynę wirtualną w infrastrukturze Compute Engine Google i zainstalować naszą instancję SQL. Oznacza to, że będziemy odpowiedzialni za skalowalność pionową, replikację i wiele innych konfiguracji. Dzięki Cloud SQL otrzymujemy wiele konfiguracji od razu po wyjęciu z pudełka, dzięki czemu możemy poświęcić więcej czasu na kod, a mniej na konfigurację.
Zanim zaczniemy:
- Zarejestruj się w Google Cloud. Google oferuje nowym użytkownikom bezpłatny kredyt w wysokości 300 USD.
- Utwórz projekt. Jest to całkiem proste i można to zrobić bezpośrednio z konsoli.
Utwórz instancję Cloud SQL
Po zarejestrowaniu się w Google Cloud, w lewym panelu przewiń do zakładki „SQL” i kliknij na nią.
Najpierw musimy wybrać silnik SQL. W tym artykule omówimy MySQL.
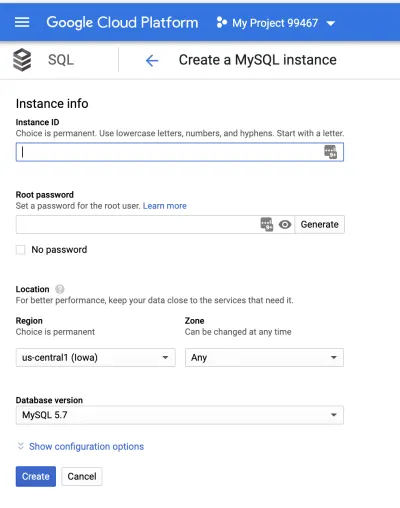
Następnie utworzymy instancję. Domyślnie nasza instancja zostanie utworzona w USA, a strefa zostanie automatycznie wybrana dla nas.
Ustaw hasło roota i nadaj instancji nazwę, a następnie kliknij przycisk "Utwórz". Możesz dalej skonfigurować instancję, klikając menu „Pokaż opcje konfiguracji”. Ustawienia pozwalają skonfigurować rozmiar instancji, pojemność pamięci, zabezpieczenia, dostępność, kopie zapasowe i nie tylko. W tym artykule przejdziemy do ustawień domyślnych. Nie martw się, te zmienne można później zmienić.
Proces może potrwać kilka minut. Będziesz wiedział, że instancja jest gotowa, gdy zobaczysz zielony znacznik wyboru. Kliknij nazwę swojej instancji, aby przejść do strony szczegółów.
Teraz, gdy już działamy, zrobimy kilka rzeczy:
- Utwórz bazę danych.
- Utwórz nowego użytkownika.
- Dodaj nasz adres IP do białej listy.
Utwórz bazę danych
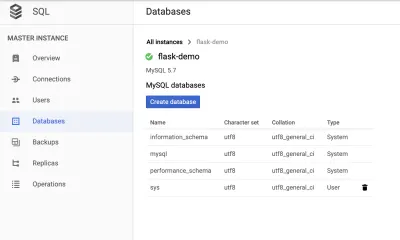
Przejdź do zakładki „Baza danych”, aby utworzyć bazę danych.
Utwórz nowego użytkownika
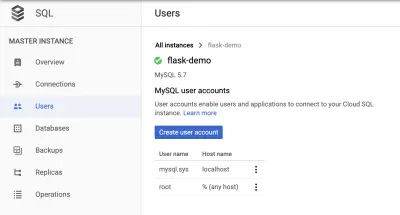
W sekcji „Nazwa hosta” ustaw ją tak, aby zezwalała na „% (dowolny host)”.

Adres IP na białej liście
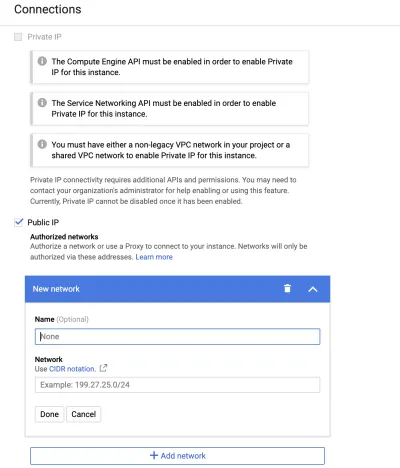
Możesz połączyć się z instancją bazy danych na dwa sposoby. Prywatny adres IP wymaga wirtualnej chmury prywatnej (VPC). Jeśli wybierzesz tę opcję, Google Cloud utworzy zarządzany przez Google VPC i umieści w nim Twoją instancję. W tym artykule użyjemy publicznego adresu IP , który jest domyślny. Jest publiczny w tym sensie, że tylko osoby, których adresy IP zostały umieszczone na białej liście, mogą uzyskać dostęp do bazy danych.
Aby umieścić swój adres IP na białej liście, wpisz my ip w wyszukiwarce Google, aby uzyskać swój adres IP. Następnie przejdź do zakładki „Połączenia” i „Dodaj sieć”.
Połącz się z instancją
Następnie przejdź do panelu „Przegląd” i połącz się za pomocą powłoki chmury.
Polecenie połączenia z naszą instancją Cloud SQL zostanie wstępnie wpisane w konsoli.
Możesz użyć użytkownika root lub użytkownika, który został utworzony wcześniej. W poniższym poleceniu mówimy: Połącz się z instancją flask-demo jako użytkownik USERNAME . Zostaniesz poproszony o wprowadzenie hasła użytkownika.
gcloud sql connect flask-demo --user=USERNAMEJeśli pojawi się błąd mówiący, że nie masz identyfikatora projektu, możesz uzyskać identyfikator swojego projektu, uruchamiając to:
gcloud projects list Weź identyfikator projektu, który został wyprowadzony z powyższego polecenia i wprowadź go do poniższego polecenia, zastępując nim PROJECT_ID .
gcloud config set project PROJECT_ID Następnie uruchom polecenie gcloud sql connect i zostaniemy połączeni.
Uruchom to polecenie, aby zobaczyć aktywne bazy danych:
> show databases; 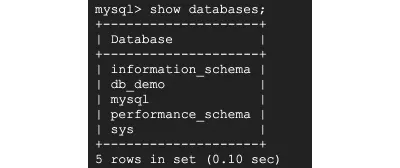
Moja baza danych nazywa się db_demo i uruchomię poniższe polecenie, aby użyć bazy danych db_demo . Możesz zobaczyć inne bazy danych, takie jak information_schema i performance_schema . Są tam do przechowywania metadanych tabeli.
> use db_demo;Następnie utwórz tabelę, która odzwierciedla listę z naszej aplikacji Flask. Wpisz poniższy kod w notatniku i wklej go w swojej chmurze:
create table songs( song_id INT NOT NULL AUTO_INCREMENT, title VARCHAR(255), artist VARCHAR(255), genre VARCHAR(255), PRIMARY KEY(song_id) ); Ten kod jest poleceniem SQL, które tworzy tabelę o nazwie songs , z czterema kolumnami ( song_id , title , artist i genre ). Poinstruowaliśmy również, że tabela powinna definiować song_id jako klucz podstawowy i automatycznie zwiększać od 1.
Teraz uruchom show tables; aby potwierdzić, że tabela została utworzona.
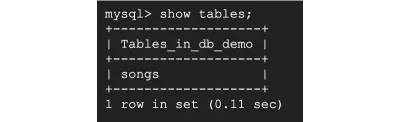
I tak po prostu stworzyliśmy bazę danych i naszą tabelę songs .
Naszym kolejnym zadaniem jest skonfigurowanie Google App Engine, abyśmy mogli wdrożyć naszą aplikację.
Silnik Aplikacji Google
App Engine to w pełni zarządzana platforma do tworzenia i hostowania aplikacji internetowych na dużą skalę. Zaletą wdrożenia w App Engine jest możliwość automatycznego skalowania aplikacji w celu obsługi ruchu przychodzącego.
Witryna App Engine mówi:
„Dzięki zerowemu zarządzaniu serwerem i zerowym wdrożeniom konfiguracji programiści mogą skupić się tylko na tworzeniu doskonałych aplikacji bez narzutów na zarządzanie”.
Skonfiguruj silnik aplikacji
Istnieje kilka sposobów konfiguracji App Engine: za pomocą interfejsu użytkownika Google Cloud Console lub za pomocą Google Cloud SDK. W tej sekcji użyjemy SDK. Umożliwia nam wdrażanie, zarządzanie i monitorowanie naszej instancji Google Cloud z naszego komputera lokalnego.
Zainstaluj pakiet SDK Google Cloud
Postępuj zgodnie z instrukcjami, aby pobrać i zainstalować pakiet SDK dla komputerów Mac lub Windows. Poradnik pokaże Ci również, jak zainicjować SDK w swoim CLI i jak wybrać projekt Google Cloud.
Teraz, gdy pakiet SDK został zainstalowany, zaktualizujemy nasz skrypt Pythona o poświadczenia naszej bazy danych i wdrożymy go w App Engine.
Konfiguracja lokalna
W naszym lokalnym środowisku zamierzamy zaktualizować konfigurację, aby pasowała do naszej nowej architektury, która obejmuje Cloud SQL i App Engine.
Najpierw dodaj plik app.yaml do naszego folderu głównego. Jest to plik konfiguracyjny wymagany przez App Engine do hostowania i uruchamiania naszej aplikacji. Informuje App Engine o naszym środowisku wykonawczym i innych zmiennych, które mogą być wymagane. W przypadku naszej aplikacji będziemy musieli dodać poświadczenia naszej bazy danych jako zmienne środowiskowe, aby App Engine rozpoznał instancję naszej bazy danych.
W pliku app.yaml dodaj poniższy fragment kodu. Zmienne wykonawcze i zmienne bazy danych otrzymasz po skonfigurowaniu bazy danych. Zastąp wartości nazwą użytkownika, hasłem, nazwą bazy danych i nazwą połączenia, których użyłeś podczas konfigurowania Cloud SQL.
#app.yaml runtime: python37 env_variables: CLOUD_SQL_USERNAME: YOUR-DB-USERNAME CLOUD_SQL_PASSWORD: YOUR-DB-PASSWORD CLOUD_SQL_DATABASE_NAME: YOUR-DB-NAME CLOUD_SQL_CONNECTION_NAME: YOUR-CONN-NAMETeraz zainstalujemy PyMySQL. Jest to pakiet Python MySQL, który łączy i wykonuje zapytania w bazie danych MySQL. Zainstaluj pakiet PyMySQL, uruchamiając ten wiersz w swoim CLI:
pip install pymysqlW tym momencie jesteśmy gotowi do użycia PyMySQL, aby połączyć się z naszą bazą danych Cloud SQL z poziomu aplikacji. Umożliwi nam to pobieranie i wstawianie zapytań do naszej bazy danych.
Zainicjuj złącze bazy danych
Najpierw utwórz plik db.py w naszym folderze głównym i dodaj poniższy kod:
#db.py import os import pymysql from flask import jsonify db_user = os.environ.get('CLOUD_SQL_USERNAME') db_password = os.environ.get('CLOUD_SQL_PASSWORD') db_name = os.environ.get('CLOUD_SQL_DATABASE_NAME') db_connection_name = os.environ.get('CLOUD_SQL_CONNECTION_NAME') def open_connection(): unix_socket = '/cloudsql/{}'.format(db_connection_name) try: if os.environ.get('GAE_ENV') == 'standard': conn = pymysql.connect(user=db_user, password=db_password, unix_socket=unix_socket, db=db_name, cursorclass=pymysql.cursors.DictCursor ) except pymysql.MySQLError as e: print(e) return conn def get_songs(): conn = open_connection() with conn.cursor() as cursor: result = cursor.execute('SELECT * FROM songs;') songs = cursor.fetchall() if result > 0: got_songs = jsonify(songs) else: got_songs = 'No Songs in DB' conn.close() return got_songs def add_songs(song): conn = open_connection() with conn.cursor() as cursor: cursor.execute('INSERT INTO songs (title, artist, genre) VALUES(%s, %s, %s)', (song["title"], song["artist"], song["genre"])) conn.commit() conn.close()Zrobiliśmy tutaj kilka rzeczy.
Najpierw pobraliśmy poświadczenia naszej bazy danych z pliku app.yaml za pomocą metody os.environ.get . App Engine może udostępnić zmienne środowiskowe zdefiniowane w app.yaml w aplikacji.
Po drugie, stworzyliśmy funkcję open_connection . Łączy się z naszą bazą danych MySQL za pomocą poświadczeń.
Po trzecie, dodaliśmy dwie funkcje: get_songs i add_songs . Pierwsza inicjuje połączenie z bazą danych, wywołując funkcję open_connection . Następnie wysyła zapytanie do tabeli songs dla każdego wiersza i, jeśli jest pusta, zwraca „Brak utworów w DB”. Funkcja add_songs wstawia nowy rekord do tabeli songs .
W końcu wracamy do miejsca, w którym zaczęliśmy, naszego pliku main.py Teraz, zamiast pobierać nasze utwory z obiektu, jak to zrobiliśmy wcześniej, wywołujemy funkcję add_songs , aby wstawić rekord, i funkcję get_songs , aby pobrać rekordy z bazy danych.
main.py :
#main.py from flask import Flask, jsonify, request from db import get_songs, add_songs app = Flask(__name__) @app.route('/', methods=['POST', 'GET']) def songs(): if request.method == 'POST': if not request.is_json: return jsonify({"msg": "Missing JSON in request"}), 400 add_songs(request.get_json()) return 'Song Added' return get_songs() if __name__ == '__main__': app.run() Zaimportowaliśmy funkcje get_songs i add_songs i wywołaliśmy je w naszej funkcji widoku Songs songs() . Jeśli wysyłamy żądanie post , wywołujemy funkcję add_songs , a jeśli wysyłamy żądanie get , wywołujemy funkcję get_songs .
I nasza aplikacja jest gotowa.
Następnym krokiem jest dodanie pliku requirements.txt . Ten plik zawiera listę pakietów niezbędnych do uruchomienia aplikacji. App Engine sprawdza ten plik i instaluje wymienione pakiety.
pip freeze | grep "Flask\|PyMySQL" > requirements.txt Ten wiersz pobiera dwa pakiety, których używamy dla aplikacji (Flask i requirements.txt ), tworzy plik Requirements.txt i dołącza pakiety i ich wersje do pliku.
W tym momencie dodaliśmy trzy nowe pliki: db.py , app.yaml i requirements.txt .
Wdróż w Google App Engine
Uruchom następujące polecenie, aby wdrożyć swoją aplikację:
gcloud app deployJeśli wszystko poszło dobrze, konsola wyświetli to:
Twoja aplikacja działa teraz w App Engine. Aby zobaczyć go w przeglądarce, uruchom gcloud app browse w swoim CLI.
Możemy uruchomić Postmana, aby przetestować nasz post i get prośby.
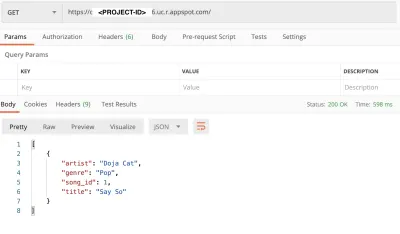
get (duży podgląd)Nasza aplikacja jest teraz hostowana w infrastrukturze Google i możemy dostosować konfigurację, aby uzyskać wszystkie korzyści architektury bezserwerowej. W przyszłości możesz oprzeć się na tym artykule, aby Twoja aplikacja bezserwerowa była bardziej niezawodna.
Wniosek
Korzystanie z infrastruktury platformy jako usługi (PaaS), takiej jak App Engine i Cloud SQL, zasadniczo oddziela poziom infrastruktury i umożliwia nam szybsze tworzenie. Jako programiści nie musimy się martwić konfiguracją, tworzeniem kopii zapasowych i przywracaniem, systemem operacyjnym, automatycznym skalowaniem, zaporami ogniowymi, migracją ruchu i tak dalej. Jeśli jednak potrzebujesz kontroli nad podstawową konfiguracją, lepiej użyć usługi zbudowanej na zamówienie.
Bibliografia
- „Pobierz Pythona”
- „venv — tworzenie środowisk wirtualnych”, Python (dokumentacja)
- „Pobierz listonosz”
- „Cloud SQL”, Google Cloud
- Google Cloud
- „Bezpłatna warstwa Google Cloud”, Google Cloud
- „Tworzenie i zarządzanie projektami”, Google Cloud
- „Przegląd VPC” (wirtualna chmura prywatna), Google Cloud
- „App Engine”, Google Cloud
- „Szybkie starty” (pobierz pakiet Google Cloud SDK), Google Cloud
- Dokumentacja PyMySQL