
6 zmieniających grę funkcji Apache Spark w 2022 r. [Jak należy używać]
Opublikowany: 2021-01-07Odkąd Big Data szturmem podbiło świat technologii i biznesu, nastąpił ogromny wzrost liczby narzędzi i platform Big Data, w szczególności Apache Hadoop i Apache Spark. Dzisiaj skupimy się wyłącznie na Apache Spark i szczegółowo omówimy jego korzyści biznesowe i aplikacje.
Apache Spark pojawił się w centrum uwagi w 2009 roku i od tego czasu stopniowo wyrobił sobie niszę w branży. Według Apache org. Spark to „błyskawiczny, ujednolicony silnik analityczny” zaprojektowany do przetwarzania ogromnych ilości Big Data. Dzięki aktywnej społeczności Spark jest dziś jedną z największych platform Big Data typu open source na świecie.
Spis treści
Co to jest Apache Spark?
Pierwotnie opracowany w laboratorium AMPLab Uniwersytetu Kalifornijskiego (Berkeley), Spark został zaprojektowany jako solidny silnik przetwarzania danych Hadoop, ze szczególnym naciskiem na szybkość i łatwość użytkowania. Jest to alternatywa typu open source dla MapReduce firmy Hadoop. Zasadniczo Spark jest strukturą równoległego przetwarzania danych, która może współpracować z Apache Hadoop, aby ułatwić płynne i szybkie tworzenie zaawansowanych aplikacji Big Data na Hadoop.
Spark jest dostarczany z szeroką gamą bibliotek do algorytmów uczenia maszynowego (ML) i algorytmów wykresów. Nie tylko to, obsługuje również strumieniowanie w czasie rzeczywistym i aplikacje SQL za pośrednictwem odpowiednio Spark Streaming i Shark. Najlepsze w korzystaniu z Spark jest to, że możesz pisać aplikacje Spark w Java, Scala, a nawet Python, a te aplikacje będą działać prawie dziesięć razy szybciej (na dysku) i 100 razy szybciej (w pamięci) niż aplikacje MapReduce.
Apache Spark jest dość wszechstronny, ponieważ można go wdrożyć na wiele sposobów, a także oferuje natywne powiązania dla języków programowania Java, Scala, Python i R. Obsługuje SQL, przetwarzanie wykresów, przesyłanie strumieniowe danych i uczenie maszynowe. Właśnie dlatego Spark jest szeroko stosowany w różnych sektorach przemysłu, w tym w bankach, firmach telekomunikacyjnych, firmach zajmujących się tworzeniem gier, agencjach rządowych i oczywiście we wszystkich czołowych firmach świata technologii – Apple, Facebook, IBM i Microsoft.
6 najlepszych funkcji Apache Spark
Funkcje, które sprawiają, że Spark jest jedną z najszerzej używanych platform Big Data to:

1. Błyskawiczna prędkość przetwarzania
Przetwarzanie Big Data polega na przetwarzaniu dużych ilości złożonych danych. Dlatego też, jeśli chodzi o przetwarzanie Big Data, organizacje i przedsiębiorstwa chcą takich platform, które mogą przetwarzać ogromne ilości danych z dużą prędkością. Jak wspomnieliśmy wcześniej, aplikacje Spark mogą działać do 100 razy szybciej w pamięci i 10 razy szybciej na dysku w klastrach Hadoop.
Opiera się na Resilient Distributed Dataset (RDD), który umożliwia Sparkowi przejrzyste przechowywanie danych w pamięci i odczytywanie/zapisywanie ich na dysku tylko w razie potrzeby. Pomaga to skrócić większość czasu odczytu i zapisu dysku podczas przetwarzania danych.
2. Łatwość użytkowania
Spark umożliwia pisanie skalowalnych aplikacji w językach Java, Scala, Python i R. Dzięki temu programiści uzyskują możliwość tworzenia i uruchamiania aplikacji Spark w preferowanych przez siebie językach programowania. Ponadto Spark jest wyposażony we wbudowany zestaw ponad 80 operatorów wysokiego poziomu. Możesz używać platformy Spark interaktywnie do wykonywania zapytań o dane z powłok Scala, Python, R i SQL.
3. Oferuje wsparcie dla zaawansowanych analiz
Spark nie tylko obsługuje proste operacje „mapowania” i „redukowania”, ale także obsługuje zapytania SQL, przesyłanie strumieniowe danych i zaawansowane analizy, w tym algorytmy ML i wykresów. Zawiera potężny zestaw bibliotek, takich jak SQL i DataFrames oraz MLlib (dla ML), GraphX i Spark Streaming. Fascynujące jest to, że Spark pozwala połączyć możliwości wszystkich tych bibliotek w ramach jednego przepływu pracy/aplikacji.
4. Przetwarzanie strumienia w czasie rzeczywistym
Spark został zaprojektowany do obsługi przesyłania strumieniowego danych w czasie rzeczywistym. Chociaż MapReduce jest zbudowany do obsługi i przetwarzania danych, które są już przechowywane w klastrach Hadoop, Spark może wykonywać obie te czynności, a także manipulować danymi w czasie rzeczywistym za pośrednictwem Spark Streaming.
W przeciwieństwie do innych rozwiązań do przesyłania strumieniowego, Spark Streaming może odzyskać utraconą pracę i dostarczyć dokładną semantykę natychmiast po wyjęciu z pudełka, bez konieczności stosowania dodatkowego kodu lub konfiguracji. Co więcej, umożliwia również ponowne użycie tego samego kodu do przetwarzania wsadowego i strumieniowego, a nawet do łączenia danych strumieniowych z danymi historycznymi.
5. Jest elastyczny
Spark może działać niezależnie w trybie klastra, a także może działać na Hadoop YARN, Apache Mesos, Kubernetes, a nawet w chmurze. Ponadto może uzyskać dostęp do różnych źródeł danych. Na przykład Spark może działać w menedżerze klastra YARN i odczytywać wszelkie istniejące dane Hadoop. Może odczytywać z dowolnych źródeł danych Hadoop, takich jak HBase, HDFS, Hive i Cassandra. Ten aspekt Sparka sprawia, że jest to idealne narzędzie do migracji czystych aplikacji Hadoop, pod warunkiem, że przypadek użycia aplikacji jest przyjazny dla Sparka.
6. Aktywna i rozwijająca się społeczność
Deweloperzy z ponad 300 firm przyczynili się do zaprojektowania i zbudowania Apache Spark. Od 2009 roku ponad 1200 programistów aktywnie przyczyniło się do uczynienia Sparka tym, czym jest dzisiaj! Oczywiście Spark jest wspierany przez aktywną społeczność programistów, którzy nieustannie pracują nad ulepszaniem jego funkcji i wydajności. Aby dotrzeć do społeczności Spark, możesz skorzystać z list mailingowych dla dowolnych zapytań, a także możesz uczestniczyć w spotkaniach i konferencjach Spark.
Anatomia aplikacji Spark
Każda aplikacja Spark składa się z dwóch podstawowych procesów – podstawowego procesu sterownika i zbioru procesów executora .
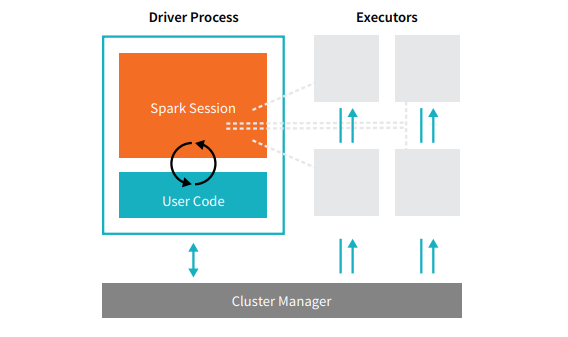

Źródło
Proces sterownika, który znajduje się w węźle w klastrze, jest odpowiedzialny za uruchomienie funkcji main(). Obsługuje również trzy inne zadania — utrzymywanie informacji o aplikacji Spark, reagowanie na kod lub dane wejściowe użytkownika oraz analizowanie, dystrybucję i planowanie pracy w wykonawcach. Proces sterownika stanowi serce aplikacji Spark — zawiera i przechowuje wszystkie krytyczne informacje obejmujące okres istnienia aplikacji Spark.
Executory lub procesy executorów to elementy drugorzędne, które muszą wykonać zadanie przypisane im przez sterownik. Zasadniczo każdy executor wykonuje dwie kluczowe funkcje – uruchamia kod przypisany mu przez drajwer i zgłasza stan obliczeń (na tym executorze) do węzła drajwera. Użytkownicy mogą decydować i konfigurować, ile executorów powinien mieć każdy węzeł.
W aplikacji Spark menedżer klastra kontroluje wszystkie maszyny i przydziela zasoby do aplikacji. W tym przypadku menedżerem klastra może być dowolny z głównych menedżerów klastra Spark, w tym YARN (samodzielny menedżer klastra Spark) lub Mesos. Oznacza to, że klaster może jednocześnie uruchamiać wiele aplikacji Spark.
Rzeczywiste aplikacje Apache Spark
Spark to najwyżej oceniana i szeroko stosowana platforma Big Dara w nowoczesnym przemyśle. Oto niektóre z najbardziej uznanych, rzeczywistych przykładów aplikacji Apache Spark:
Spark do uczenia maszynowego
Apache Spark może pochwalić się skalowalną biblioteką Machine Learning – MLlib. Ta biblioteka została wyraźnie zaprojektowana z myślą o prostocie, skalowalności i ułatwianiu bezproblemowej integracji z innymi narzędziami. MLlib nie tylko posiada skalowalność, kompatybilność językową i szybkość Sparka, ale może również wykonywać szereg zaawansowanych zadań analitycznych, takich jak klasyfikacja, klastrowanie, redukcja wymiarów. Dzięki MLlib Spark może być używany do analizy predykcyjnej, analizy sentymentu, segmentacji klientów i inteligencji predykcyjnej.
Kolejna imponująca cecha Apache Spark leży w domenie bezpieczeństwa sieci. Spark Streaming umożliwia użytkownikom monitorowanie pakietów danych w czasie rzeczywistym przed przekazaniem ich do pamięci masowej. Podczas tego procesu może z powodzeniem zidentyfikować wszelkie podejrzane lub złośliwe działania, które wynikają ze znanych źródeł zagrożeń. Nawet po wysłaniu pakietów danych do magazynu Spark używa biblioteki MLlib do dalszej analizy danych i identyfikowania potencjalnych zagrożeń dla sieci. Ta funkcja może być również używana do wykrywania oszustw i zdarzeń.
Spark do przetwarzania mgły
Apache Spark to doskonałe narzędzie do obliczeń mgły, szczególnie jeśli dotyczy Internetu rzeczy (IoT). IoT w dużym stopniu opiera się na koncepcji przetwarzania równoległego na dużą skalę. Ponieważ sieć IoT składa się z tysięcy i milionów podłączonych urządzeń, dane generowane przez tę sieć w każdej sekundzie są niezrozumiałe.
Oczywiście do przetwarzania tak dużych ilości danych generowanych przez urządzenia IoT potrzebna jest skalowalna platforma obsługująca przetwarzanie równoległe. A co jest lepszego niż solidna architektura Sparka i możliwości przetwarzania mgły, aby obsłużyć tak ogromne ilości danych!
Przetwarzanie we mgle decentralizuje dane i przechowywanie, a zamiast przetwarzania w chmurze wykonuje funkcję przetwarzania danych na brzegu sieci (głównie osadzone w urządzeniach IoT).
Aby to zrobić, obliczenia mgły wymagają trzech możliwości, a mianowicie niskiego opóźnienia, równoległego przetwarzania ML i złożonych algorytmów analizy wykresów – z których każdy jest obecny w Spark. Co więcej, obecność Spark Streaming, Shark (interaktywne narzędzie do zapytań, które może działać w czasie rzeczywistym), MLlib i GraphX (silnik analizy wykresów) dodatkowo zwiększa zdolność Spark do obliczania mgły.
Spark do analizy interaktywnej
W przeciwieństwie do MapReduce, Hive lub Pig, które mają stosunkowo niską prędkość przetwarzania, Spark może pochwalić się szybką interaktywną analizą. Jest w stanie obsługiwać zapytania eksploracyjne bez konieczności próbkowania danych. Ponadto Spark jest kompatybilny z prawie wszystkimi popularnymi językami programistycznymi, w tym R, Python, SQL, Java i Scala.
Najnowsza wersja Spark — Spark 2.0 — zawiera nową funkcjonalność znaną jako Strumieniowanie Strukturyzowane. Dzięki tej funkcji użytkownicy mogą uruchamiać ustrukturyzowane i interaktywne zapytania dotyczące danych przesyłanych strumieniowo w czasie rzeczywistym.
Użytkownicy Spark
Teraz, gdy dobrze znasz funkcje i możliwości Sparka, porozmawiajmy o czterech wybitnych użytkownikach Sparka!
1. Yahoo!
Yahoo używa Sparka do dwóch swoich projektów, jednego do personalizowania stron z wiadomościami dla odwiedzających, a drugiego do prowadzenia analiz reklamowych. Aby dostosować strony z wiadomościami, Yahoo korzysta z zaawansowanych algorytmów ML działających na platformie Spark, aby zrozumieć zainteresowania, preferencje i potrzeby poszczególnych użytkowników oraz odpowiednio kategoryzować artykuły.
W drugim przypadku Yahoo wykorzystuje interaktywne możliwości platformy Hive on Spark (do integracji z dowolnym narzędziem, które można podłączyć do Hive), aby przeglądać i przeszukiwać dane analityczne Yahoo zebrane w Hadoop.
2. Uber
Uber używa Spark Streaming w połączeniu z Kafką i HDFS do ETL (wyodrębniania, przekształcania i ładowania) ogromnych ilości danych w czasie rzeczywistym dotyczących dyskretnych zdarzeń w ustrukturyzowane i użyteczne dane do dalszej analizy. Dane te pomagają Uberowi opracowywać lepsze rozwiązania dla klientów.

3. Conviva
Jako firma zajmująca się streamingiem wideo, Conviva uzyskuje średnio ponad 4 miliony kanałów wideo każdego miesiąca, co prowadzi do ogromnego odpływu klientów. To wyzwanie jest dodatkowo potęgowane przez problem zarządzania ruchem wideo na żywo. Aby skutecznie stawić czoła tym wyzwaniom, Conviva wykorzystuje Spark Streaming do poznawania warunków sieciowych w czasie rzeczywistym i odpowiedniej optymalizacji ruchu wideo. Dzięki temu Conviva może zapewnić użytkownikom spójne i wysokiej jakości wrażenia wizualne.
4. Pinterest
Na Pintereście użytkownicy mogą przypinać swoje ulubione tematy, kiedy tylko chcą, podczas surfowania w Internecie i mediach społecznościowych. Aby zaoferować spersonalizowane i ulepszone wrażenia klientów, Pinterest wykorzystuje możliwości ETL Spark do identyfikowania unikalnych potrzeb i zainteresowań poszczególnych użytkowników oraz dostarczania im odpowiednich rekomendacji na Pintereście.
Wniosek
Podsumowując, Spark to niezwykle wszechstronna platforma Big Data z funkcjami, które mają za zadanie imponować. Ponieważ jest to platforma typu open source, stale się poprawia i ewoluuje, dodając do niej nowe funkcje i funkcjonalności. W miarę jak zastosowania Big Data stają się coraz bardziej zróżnicowane i ekspansywne, tak samo będą się działy przypadki użycia Apache Spark.
Jeśli chcesz dowiedzieć się więcej o Big Data, sprawdź nasz program PG Diploma in Software Development Specialization in Big Data, który jest przeznaczony dla pracujących profesjonalistów i zawiera ponad 7 studiów przypadków i projektów, obejmuje 14 języków programowania i narzędzi, praktyczne praktyczne warsztaty, ponad 400 godzin rygorystycznej pomocy w nauce i pośrednictwie pracy w najlepszych firmach.
Sprawdź nasze inne kursy inżynierii oprogramowania w upGrad.