
Apache Kafka Architecture: kompleksowy przewodnik dla początkujących [2022]
Opublikowany: 2021-12-23Zanim zagłębimy się w szczegóły architektury Apache Kafka, warto rzucić trochę światła na to, dlaczego Kafka trafia na pierwsze strony gazet. Po pierwsze, Apache Kafka znajduje zastosowanie głównie w architekturach przesyłania strumieniowego danych w czasie rzeczywistym do dostarczania analiz w czasie rzeczywistym. Trwały, szybki, skalowalny i odporny na błędy system przesyłania wiadomości publikuj-subskrybuj Kafki ma przypadki użycia do takich rzeczy, jak śledzenie danych z czujników IoT lub śledzenie połączeń usług.
Firmy takie jak LinkedIn, Netflix, Microsoft, Uber, Spotify, Goldman Sachs, Cisco, PayPal i wiele innych wykorzystują Apache Kafka do przetwarzania danych strumieniowych w czasie rzeczywistym. Na przykład LinkedIn, z którego pochodzi Kafka, używa go do śledzenia wskaźników operacyjnych i danych o aktywności. Podobnie w przypadku Netflix Apache Kafka jest de facto standardem w zakresie obsługi wiadomości, obsługi zdarzeń i przetwarzania strumieniowego.
Dowiedz się Szkolenie w zakresie tworzenia oprogramowania online na najlepszych światowych uniwersytetach. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.
Użyteczność Apache Kafka jest lepiej doceniana dzięki zrozumieniu architektury Apache Kafka i jej podstawowych komponentów. Przyjrzyjmy się więc szczegółom architektury Kafki.
Spis treści
Podstawowe koncepcje architektury Kafki
Poniższe koncepcje są podstawą zrozumienia architektury Apache Kafka:
1. Tematy
Tematy Kafki określają kanały, którymi przesyłane są dane. W ten sposób producenci publikują wiadomości do tematów, a konsumenci czytają wiadomości z tematów, które subskrybują. Nie ma ograniczeń co do liczby tematów tworzonych w ramach klastra Kafki, a każdy temat identyfikuje unikalna nazwa.

2. Brokerzy
Brokerzy to serwery w klastrze Kafka, które działają jako kontenery i przechowują wiele tematów z odrębnymi partycjami. Unikalny identyfikator liczby całkowitej identyfikuje brokerów w klastrze Kafka, a połączenie z dowolnym z tych brokerów oznacza połączenie z całym klastrem.
3. Przegrody
Tematy Kafki podzielone są na wiele części, zwanych partycjami. Partycje są oddzielone w kolejności i umożliwiają wielu konsumentom równoległe odczytywanie danych z określonego tematu. Partycje tematu są rozmieszczone na kilku serwerach w klastrze Kafka, a każdy serwer zarządza danymi i żądaniami dotyczącymi jego partii partycji. Komunikaty docierają do brokera i klucza, a klucz określa partycję, do której trafi konkretna wiadomość. Dlatego wiadomości z tym samym kluczem trafiają do tej samej partycji. W przypadku, gdy klucz jest nieokreślony, podział jest ustalany zgodnie z podejściem round-robin.
4. Repliki
W Kafce repliki są jak kopie zapasowe partycji, aby zapewnić brak utraty danych w przypadku planowanego zamknięcia lub awarii. Innymi słowy, repliki są kopiami partycji.
5. Przesunięcia partycji
Ponieważ komunikaty lub rekordy w Kafce są przypisane do partycji, każdy rekord jest opatrzony offsetem, aby określić jego pozycję w partycji. W ten sposób wartość przesunięcia skojarzona z rekordem pomaga w jego łatwej identyfikacji w obrębie partycji. Przesunięcie partycji ma znaczenie tylko w obrębie tej konkretnej partycji, a ponieważ rekordy są dodawane na końcach partycji, starsze rekordy będą miały niższe wartości przesunięcia.
6. Producenci
Producenci Kafki publikują komunikaty na jeden lub więcej tematów i przesyłają dane do klastra Kafka. Gdy tylko producent opublikuje komunikat w temacie Kafki, broker otrzymuje komunikat i dodaje go do określonej partycji. Następnie producenci mogą wybrać partycję, na której chcą opublikować swoją wiadomość.
7. Konsumenci i grupy konsumenckie
Konsumenci czytają wiadomości z klastra Kafka. Gdy konsument jest gotowy do odebrania komunikatu, dane są pobierane z brokera. Konsumenci należą do grupy konsumentów, a każdy konsument w danej grupie jest odpowiedzialny za odczytanie podzbioru partycji każdego subskrybowanego tematu.
8. Przywódca i naśladowca
Każda partycja Kafki posiada jeden serwer pełniący rolę lidera. Lider wykonuje wszystkie zadania odczytu i zapisu dla tej partycji. Z drugiej strony zadaniem obserwatora jest replikowanie danych lidera. Kiedy lider w określonej partycji ulegnie awarii, jeden z węzłów zwolenników przejmuje rolę lidera. Partycja może mieć żadnego lub wielu obserwujących.
Poniższy diagram jest uproszczoną prezentacją wzajemnych zależności między omówionymi powyżej komponentami architektury Apache Kafka.
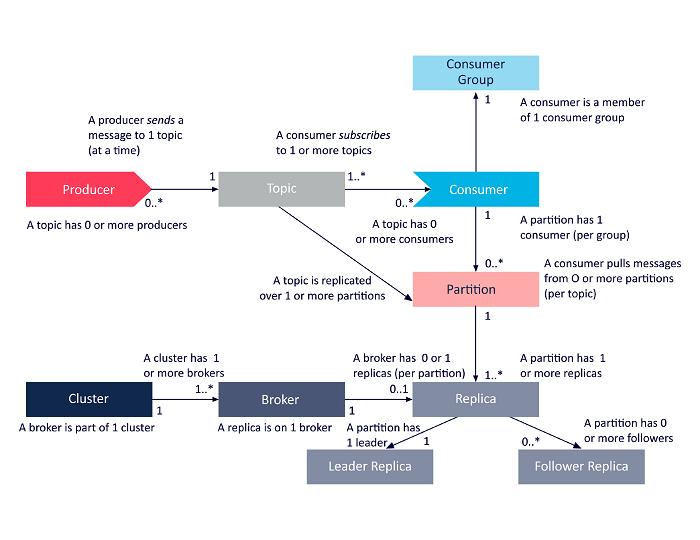
Źródło
Architektura klastra Apache Kafka
Oto szczegółowe spojrzenie na główne elementy architektoniczne Kafki:

1. Brokerzy Kafki
Klastry Kafka zazwyczaj zawierają wiele węzłów zwanych brokerami. Brokerzy utrzymują równowagę obciążenia. Każdy broker Kafka może obsłużyć setki i tysiące odczytów i zapisów na sekundę. Broker pełni rolę lidera dla jednej partycji. Lider ma jednego lub kilku obserwujących, a dane lidera są replikowane w obserwujących tej partycji.
Obserwatorzy muszą być na bieżąco z danymi lidera. Lider z kolei śledzi, którzy są z nim zsynchronizowani. Jeśli obserwujący nie dogoni lidera lub już nie żyje, jest usuwany z listy replik zsynchronizowanych powiązanych z danym liderem. Nowy lider jest wybierany spośród zwolenników po śmierci lidera, a ZooKeeper nadzoruje wybory. Ponieważ brokerzy są bezstanowi, ZooKeeper utrzymuje stan klastra. Węzły w klastrze wysyłają komunikaty pulsu do ZooKeepera, aby poinformować go, że działają.
2. Producenci Kafki
Producenci Kafki bezpośrednio przesyłają dane do brokerów pełniących rolę lidera dla danej partycji. Brokerzy lub węzły klastrów Kafka pomagają producentom wysyłać bezpośrednie wiadomości. Robią to, odpowiadając na prośby o metadane, na których działają serwery, oraz status aktywności liderów partycji w temacie, umożliwiając producentowi odpowiednie kierowanie żądań. Producent decyduje, na której partycji chce publikować komunikaty. Wiadomości w Kafce są wysyłane partiami, zwanymi partiami rekordów. Producenci gromadzą wiadomości w pamięci i wysyłają je w partiach po upływie określonego czasu lub po zgromadzeniu określonej liczby wiadomości.
3. Konsumenci Kafki
Konsumenci Kafki wysyłają żądania do brokerów wskazujące partycje, które chcą wykorzystać. Konsument określa przesunięcie partycji w swoim żądaniu i otrzymuje fragment dziennika (począwszy od pozycji przesunięcia) od brokera. Dziennik zawiera rekordy z konfigurowalnego okresu zwanego okresem przechowywania.
Konsumenci mogą również ponownie wykorzystywać dane, o ile dziennik zawiera dane. Konsumenci Kafki pracują na zasadzie pull-based, co oznacza, że brokerzy nie wysyłają od razu danych do konsumentów. Zamiast tego konsumenci najpierw wysyłają żądania do brokerów, sygnalizując, że są gotowi do korzystania z danych. W związku z tym system oparty na ściąganiu zapewnia, że konsumenci nie są przytłoczeni wiadomościami i mogą nadrobić zaległości, jeśli zostaną w tyle.
Poniżej znajduje się uproszczony diagram architektury Apache Kafka:
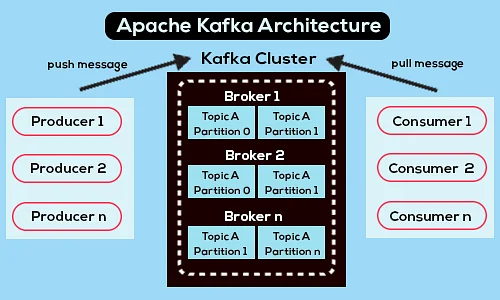
Źródło
Dowiedz się więcej o Apache Kafka.
Architektura Apache Kafka API
Apache Kafka ma cztery kluczowe interfejsy API — Streams API, Connector API, Producer API i Consumer API. Zobaczmy, jaką rolę każdy z nich ma do odegrania w zwiększaniu możliwości Apache Kafka:
1. Strumienie API
Streams API firmy Kafka umożliwia aplikacji przetwarzanie danych za pomocą algorytmu przetwarzania strumieni. Korzystając z interfejsu API Streams, aplikacje mogą wykorzystywać strumienie wejściowe z jednego lub kilku tematów, przetwarzać je za pomocą operacji strumieniowych, tworzyć strumienie wyjściowe i ostatecznie wysyłać je do jednego lub większej liczby tematów. W ten sposób interfejs API Streams ułatwia przekształcanie strumieni wejściowych w strumienie wyjściowe.
2. Interfejs API
Interfejs API programu Kafka jest pomocny przy tworzeniu, uruchamianiu i zarządzaniu producentami i konsumentami wielokrotnego użytku, którzy łączą tematy Kafki z istniejącymi systemami danych lub aplikacjami. Na przykład łącznik do relacyjnej bazy danych może przechwycić wszystkie aktualizacje i upewnić się, że zmiany są dostępne w ramach tematu Kafki.

3. API producenta
Interfejs Producer API Kafki umożliwia aplikacjom publikowanie strumienia rekordów w tematach Kafki.
4. Konsumenckie API
Consumer API of Kafka Zezwala aplikacjom na subskrybowanie tematów Kafki. Umożliwia także aplikacjom przetwarzanie strumieni rekordów, które są tworzone dla tych tematów Kafki.
Droga naprzód
Architektura Apache Kafka to tylko niewielka część ogromnego repertuaru narzędzi i języków, którymi zajmują się programiści. Załóżmy, że jesteś początkującym programistą, który ma skłonność do Big Data. W takim przypadku możesz zrobić pierwszy krok w kierunku swoich celów, korzystając z programu Executive PG w rozwoju oprogramowania – specjalizacja w Big Data .
Oto przegląd programu z kilkoma najważniejszymi punktami:
- Executive PGP z IIIT Bangalore z certyfikatami w dziedzinie Data Science i infrastruktury chmurowej
- Sesje online i wykłady na żywo z ponad 400 godzinami treści
- 7+ studiów przypadku i projektów
- Ponad 14 języków programowania i narzędzi
- Wsparcie kariery 360 stopni
- Sieci równorzędne i branżowe
Zarejestruj się, aby uzyskać więcej informacji o kursie!
Do czego służy Kafka?
Apache Kafka jest używany głównie do budowania potoków danych strumieniowych w czasie rzeczywistym i aplikacji dostosowujących się do tych strumieni danych. Umożliwia zarówno przechowywanie, jak i analizę danych w czasie rzeczywistym i danych historycznych poprzez połączenie przesyłania wiadomości, przechowywania i przetwarzania strumieniowego.
Czy Kafka to framework?
Apache Kafka to oprogramowanie typu open source, które zapewnia platformę do przechowywania, odczytywania i analizowania danych przesyłanych strumieniowo. Ponieważ jest to oprogramowanie typu open source, Kafka może być używana bezpłatnie z wieloma programistami i użytkownikami, którzy przyczyniają się do tworzenia nowych funkcji, aktualizacji i wsparcia dla nowych użytkowników.
Dlaczego potrzebujemy streamów Kafki?
Kafka Streams to biblioteka kliencka do tworzenia mikrousług i aplikacji strumieniowych, w której dane wejściowe i dane wyjściowe są przechowywane w klastrze Apache Kafka. Z jednej strony oferuje zalety technologii klastrów po stronie serwera Apache Kafka. Z drugiej strony upraszcza pisanie i wdrażanie standardowych aplikacji Scala i Java po stronie klienta.