
Apache Kafka: architektura, koncepcje, funkcje i aplikacje
Opublikowany: 2021-03-09Kafka powstała w 2011 roku, wszystko dzięki LinkedIn. Od tego czasu firma była świadkiem niesamowitego rozwoju do tego stopnia, że większość firm z listy Fortune 500 używa go teraz. Jest to wysoce skalowalny, trwały i wydajny produkt, który może obsługiwać duże ilości danych przesyłanych strumieniowo. Ale czy to jedyny powód jego ogromnej popularności? Więc nie. Nie zaczęliśmy nawet od jego funkcji, jakości, jaką zapewnia, i łatwości, jaką zapewnia użytkownikom.
Zagłębimy się w to później. Najpierw zrozummy, czym jest Kafka i gdzie jest używana.
Spis treści
Co to jest Apache Kafka?
Apache Kafka to oprogramowanie do przetwarzania strumieni typu open source, które ma na celu zapewnienie wysokiej przepustowości i małych opóźnień przy jednoczesnym zarządzaniu danymi w czasie rzeczywistym. Kafka, napisany w Javie i Scali, zapewnia trwałość dzięki mikrousługom w pamięci i odgrywa integralną rolę w utrzymywaniu zdarzeń dostaw do złożonych usług przesyłania strumieniowego zdarzeń, zwanych inaczej CEP lub systemami automatyzacji.
Jest to wyjątkowo wszechstronny, odporny na uszkodzenia system rozproszony, który umożliwia firmom takim jak Uber zarządzanie dopasowywaniem pasażerów i kierowców. Zapewnia również dane w czasie rzeczywistym i proaktywną konserwację inteligentnych produktów domowych British Gas, a także pomaga LinkedIn w śledzeniu wielu usług w czasie rzeczywistym.
Kafka, często stosowany w architekturze strumieniowania danych w czasie rzeczywistym w celu dostarczania analiz w czasie rzeczywistym, jest szybkim, wytrzymałym, skalowalnym systemem przesyłania wiadomości typu publikuj-subskrybuj. Apache Kafka może być używany jako substytut tradycyjnej MOM ze względu na doskonałą kompatybilność i elastyczną architekturę, która umożliwia śledzenie połączeń serwisowych lub danych z czujników IoT.
Kafka doskonale współpracuje z Apache Flume/Flafka, Apache Spark Streaming, Apache Storm, HBase, Apache Flink i Apache Spark w celu pozyskiwania, badania, analizy i przetwarzania danych strumieniowych w czasie rzeczywistym. Pośrednicy Kafki ułatwiają również raporty follow-up o niskim opóźnieniu w Hadoop lub Spark. Kafka ma również projekt pomocniczy o nazwie Kafka Stream, który działa jako skuteczne narzędzie do analizy w czasie rzeczywistym.

Architektura i komponenty Kafki
Kafka służy do strumieniowego przesyłania danych w czasie rzeczywistym do wielu systemów odbiorców. Kafka działa jako warstwa centralna do oddzielania potoków danych w czasie rzeczywistym. Nie znajduje większego zastosowania w obliczeniach bezpośrednich. Jest najbardziej kompatybilny z systemami szybkiego podawania, opartymi na danych operacyjnych lub w czasie rzeczywistym, aby przesyłać strumieniowo znaczną ilość danych do analizy danych wsadowych.
Struktury Storm, Flink, Spark i CEP to kilka systemów danych, z którymi współpracuje Kafka, aby wykonywać analizy w czasie rzeczywistym, tworzyć kopie zapasowe, audyty i nie tylko. Można go również zintegrować z platformami Big Data lub systemami baz danych, takimi jak RDBMS i Cassandra, Spark itp., w celu analizy danych, raportowania itp.
Poniższy diagram ilustruje ekosystem Kafki:
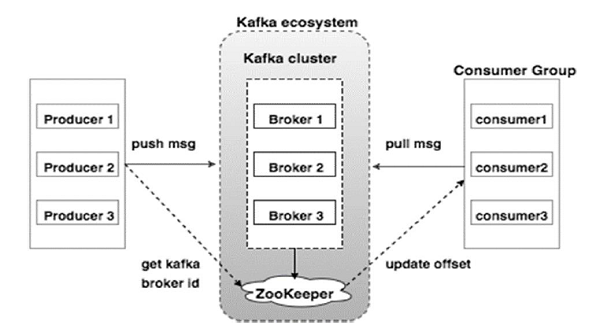
Źródło
Oto różne elementy ekosystemu Kafka, jak pokazano na diagramie architektury Kafka:
1. Broker Kafki
Kafka emuluje klaster składający się z wielu serwerów, z których każdy nazywany jest „brokerem”. Wszelka komunikacja między klientami i serwerami jest zgodna z wysokowydajnym protokołem TCP. Obejmuje więcej niż jednego bezpaństwowego brokera do obsługi dużych obciążeń. Pojedynczy broker Kafka jest w stanie zarządzać kilkoma opóźnieniami odczytów i zapisów w każdej sekundzie bez uszczerbku dla wydajności. Używają ZooKeeper do utrzymania klastrów i wyboru lidera brokera.
2. Kafka ZooKeeper
Jak wspomniano powyżej, ZooKeeper jest odpowiedzialny za zarządzanie brokerami Kafka. Każdy nowy dodatek lub awaria brokera w ekosystemie Kafka jest zgłaszana producentowi lub konsumentowi za pośrednictwem ZooKeeper.
3. Producenci Kafki
Odpowiadają za wysyłanie danych do brokerów. Producenci nie polegają na brokerach w celu potwierdzenia otrzymania wiadomości. Zamiast tego określają, ile broker może odpowiednio obsłużyć i wysłać komunikaty.

4. Konsumenci Kafki
Obowiązkiem konsumentów Kafki jest prowadzenie rejestru liczby wiadomości zużywanych przez przesunięcie partycji. Potwierdzenie wiadomości oznacza, że wiadomości wysłane, zanim zostały wykorzystane. Aby upewnić się, że broker ma bufor bajtów gotowy do wysłania do konsumenta, konsument inicjuje asynchroniczne żądanie ściągnięcia. ZooKeeper ma do odegrania rolę w utrzymaniu wartości przesunięcia przy pomijaniu lub przewijaniu wiadomości.
Mechanizm Kafki polega na przesyłaniu komunikatów pomiędzy aplikacjami w systemach rozproszonych. Kafka wykorzystuje dziennik zatwierdzania, który po zasubskrybowaniu publikuje dane obecne w różnych aplikacjach do przesyłania strumieniowego. Nadawca wysyła wiadomości do Kafki, podczas gdy odbiorca otrzymuje wiadomości ze strumienia dystrybuowanego przez Kafkę.
Komunikaty układane są w tematy — efektowna deliberacja Kafki. Dany temat reprezentuje zorganizowaną parę danych w oparciu o określony typ lub klasyfikację. Producent pisze wiadomości do przeczytania dla konsumentów, które są oparte na temacie.
Każdemu tematowi nadaje się unikalną nazwę. Każda wiadomość z danego tematu wysłana przez nadawcę jest odbierana przez wszystkich użytkowników, którzy dostrajają się do tego tematu. Po opublikowaniu danych w temacie nie można aktualizować ani modyfikować.
Cechy Kafki
- Kafka składa się z dziennika wieczystego zatwierdzania, który umożliwia subskrybowanie go, a następnie publikowanie danych w wielu systemach lub aplikacjach czasu rzeczywistego.
- Daje aplikacjom możliwość kontrolowania tych danych w miarę ich pojawiania się. Interfejs API Streams w Apache Kafka to potężna, lekka biblioteka, która ułatwia przetwarzanie danych w locie.
- Jest to aplikacja Java, która pozwala regulować przepływ pracy i znacznie zmniejsza wymagania dotyczące konserwacji.
- Kafka działa jako „magazyn prawdy” dystrybuujący dane do wielu węzłów, umożliwiając wdrażanie danych za pośrednictwem wielu systemów danych.
- Dziennik zobowiązań Kafki sprawia, że jest to niezawodny system przechowywania. Kafka tworzy repliki/kopie zapasowe partycji, które pomagają zapobiegać utracie danych (właściwe konfiguracje mogą skutkować zerową utratą danych). Zapobiega to również awariom serwera i zwiększa trwałość Kafki.
- Tematy w Kafce mają tysiące partycji, dzięki czemu jest w stanie obsłużyć dowolną ilość danych i duże obciążenie.
- Kafka polega na jądrze systemu operacyjnego, aby szybko przenosić dane. Te klastry informacji są szyfrowane od końca do końca, od producenta do systemu plików do końcowego konsumenta.
- Grupowanie w Kafce zwiększa wydajność kompresji danych i zmniejsza opóźnienia we/wy.
Zastosowania Kafki
Z Kafki korzysta wiele firm, które na co dzień mają do czynienia z dużymi ilościami danych.

- LinkedIn używa Kafki do śledzenia aktywności użytkowników i wskaźników wydajności. Twitter łączy go ze Stormem, aby umożliwić strukturę przetwarzania strumieniowego.
- Square korzysta z Kafki, aby ułatwić przenoszenie wszystkich zdarzeń systemowych do innych centrów danych Square. Obejmuje to dzienniki, zdarzenia niestandardowe i dane.
- Inne popularne firmy, które korzystają z zalet Kafki, to Netflix, Spotify, Uber, Tumblr, CloudFlare i PayPal.
Dlaczego powinieneś uczyć się Apache Kafka?
Kafka to doskonała platforma do strumieniowego przesyłania wydarzeń, która może wydajnie obsługiwać, śledzić i monitorować dane w czasie rzeczywistym. Odporna na błędy i skalowalna architektura umożliwia integrację danych z małymi opóźnieniami, co skutkuje wysoką przepustowością transmisji strumieniowych. Kafka znacznie skraca „time-to-value” dla danych.
Działa jako podstawowy system generujący informacje dla organizacji, eliminując „logi” wokół danych. Pozwala to analitykom danych i specjalistom na łatwy dostęp do informacji w dowolnym momencie.
Z tych powodów jest to najlepsza platforma streamingowa dla wielu czołowych firm, dlatego kandydaci z kwalifikacjami w Apache Kafka są bardzo poszukiwani.
Jeśli chcesz dowiedzieć się więcej o Kafce, Big Data, powinieneś zapoznać się z dyplomem PG upGrad w specjalizacji programistycznej w Big Data , który oferuje ponad 7 studiów przypadków i projektów oraz mentoring od światowej klasy ekspertów wydziałowych i branżowych. 13-miesięczny program obejmuje 14 języków programowania i uczy m.in. Przetwarzania Danych, MapReduce, Magazynowania Danych, Przetwarzania w Czasie Rzeczywistym, Przetwarzania Big Data w Chmurze.
Sprawdź nasze inne kursy inżynierii oprogramowania w upGrad.