
Alternatywny interfejs głosowy dla asystentów głosowych
Opublikowany: 2022-03-10Większości ludzi pierwsze, co przychodzi na myśl, gdy myśli się o głosowych interfejsach użytkownika, to asystenci głosowi, tacy jak Siri, Amazon Alexa czy Google Assistant. W rzeczywistości asystenci są jedynym kontekstem, w którym większość ludzi kiedykolwiek używała głosu do interakcji z systemem komputerowym.
Podczas gdy asystenci głosowi wprowadzili głosowe interfejsy użytkownika do głównego nurtu, paradygmat asystenta nie jest jedynym ani nawet najlepszym sposobem używania, projektowania i tworzenia głosowych interfejsów użytkownika.
W tym artykule omówię problemy, z jakimi borykają się asystenci głosowi i przedstawię nowe podejście do głosowych interfejsów użytkownika, które nazywam bezpośrednimi interakcjami głosowymi.
Asystenci głosowi to chatboty oparte na głosie
Asystent głosowy to oprogramowanie, które jako interfejs użytkownika wykorzystuje język naturalny zamiast ikon i menu. Asystenci zazwyczaj odpowiadają na pytania i często proaktywnie starają się pomóc użytkownikowi.
Zamiast prostych transakcji i poleceń, asystenci naśladują ludzką rozmowę i używają języka naturalnego dwukierunkowo jako modalności interakcji, co oznacza, że zarówno przyjmuje dane wejściowe od użytkownika, jak i odpowiada mu za pomocą języka naturalnego.
Pierwszymi asystentami były oparte na dialogu systemy odpowiedzi na pytania. Jednym z wczesnych przykładów jest Clippy firmy Microsoft, który niesławnie próbował pomóc użytkownikom pakietu Microsoft Office, udzielając im instrukcji opartych na tym, co według niego użytkownik próbował osiągnąć. W dzisiejszych czasach typowym przypadkiem użycia paradygmatu asystenta są chatboty, często używane do obsługi klienta w dyskusji na czacie.
Z kolei asystenci głosowi to chatboty, które używają głosu zamiast pisania i tekstu . Wprowadzane przez użytkownika nie są wybory ani tekst, ale mowa, a odpowiedź systemu jest również wypowiadana na głos. Asystenci ci mogą być asystentami ogólnymi, takimi jak Asystent Google lub Alexa, którzy potrafią odpowiedzieć na wiele pytań w rozsądny sposób, lub niestandardowi asystenci stworzeni do specjalnego celu, takiego jak zamawianie fast foodów.
Chociaż często dane wejściowe użytkownika to tylko słowo lub dwa i mogą być prezentowane jako selekcje zamiast rzeczywistego tekstu, w miarę rozwoju technologii rozmowy będą bardziej otwarte i złożone . Pierwszą cechą charakterystyczną chatbotów i asystentów jest użycie języka naturalnego i stylu konwersacji zamiast ikon, menu i stylu transakcyjnego, który definiuje typową obsługę aplikacji mobilnej lub strony internetowej.
Zalecana literatura : Budowa prostego chatbota AI za pomocą Web Speech API i Node.js
Drugą cechą charakterystyczną, która wywodzi się z odpowiedzi w języku naturalnym, jest iluzja persony. Ton, jakość i język, którym posługuje się system, definiują zarówno doświadczenie asystenta, iluzję empatii i podatności na służbę, jak i jego osobowość. Pomysł dobrego doświadczenia z asystentem jest jak bycie zaangażowanym z prawdziwą osobą .
Ponieważ głos jest dla nas najbardziej naturalnym sposobem komunikowania się, może to brzmieć niesamowicie, ale są dwa główne problemy z używaniem odpowiedzi w języku naturalnym. Jeden z tych problemów, związany z tym, jak dobrze komputery mogą naśladować ludzi, może zostać rozwiązany w przyszłości wraz z rozwojem konwersacyjnych technologii sztucznej inteligencji , ale problem sposobu, w jaki ludzkie mózgi przetwarzają informacje, jest problemem ludzkim, którego nie da się naprawić w przewidywalnej przyszłości. Przyjrzyjmy się teraz tym problemom.
Dwa problemy z odpowiedziami w języku naturalnym
Głosowe interfejsy użytkownika to oczywiście interfejsy użytkownika wykorzystujące głos jako modalność. Ale modalność głosowa może być używana w obu kierunkach: do wprowadzania informacji od użytkownika i wysyłania informacji z systemu z powrotem do użytkownika. Na przykład, niektóre windy wykorzystują syntezę mowy do potwierdzania wyboru użytkownika po naciśnięciu przez użytkownika przycisku. Później omówimy głosowe interfejsy użytkownika, które używają głosu tylko do wprowadzania informacji i używają tradycyjnych graficznych interfejsów użytkownika do wyświetlania informacji użytkownikowi.
Z drugiej strony asystenci głosowi używają głosu zarówno do wprowadzania, jak i wyprowadzania . Takie podejście ma dwa główne problemy:
Problem nr 1: naśladowanie człowieka zawodzi
Jako ludzie mamy wrodzoną skłonność do przypisywania cech podobnych do ludzi obiektom innym niż ludzie. Widzimy rysy przepływającego człowieka w chmurze albo patrzymy na kanapkę i wydaje się, że się do nas uśmiecha. Nazywa się to antropomorfizmem .

Zjawisko to dotyczy również asystentów i jest wywoływane przez ich naturalne reakcje językowe. Chociaż graficzny interfejs użytkownika może być zbudowany w pewnym stopniu neutralnie, nie ma mowy, aby człowiek nie mógł zacząć myśleć o tym, czy głos kogoś należy do młodej czy starszej osoby, czy jest to mężczyzna czy kobieta. Z tego powodu użytkownik prawie zaczyna myśleć, że asystent rzeczywiście jest człowiekiem.
Jednak my, ludzie, jesteśmy bardzo dobrzy w wykrywaniu podróbek . O dziwo, im bardziej coś zbliża się do człowieka, tym bardziej zaczynają nam przeszkadzać drobne odchylenia. Pojawia się uczucie przerażenia w stosunku do czegoś, co próbuje być podobne do człowieka, ale nie do końca mu odpowiada. W robotyce i animacjach komputerowych określa się to mianem „doliny niesamowitości”.

Im lepszy i bardziej ludzki staramy się stworzyć asystenta, tym bardziej przerażające i rozczarowujące może być doświadczenie użytkownika, gdy coś pójdzie nie tak. Każdy, kto próbował asystentów, prawdopodobnie natknął się na problem odpowiedzi na coś, co wydaje się idiotyczne, a nawet niegrzeczne.
Niesamowita dolina asystentów głosowych stwarza trudny do przezwyciężenia problem jakości w obsłudze asystenta. W rzeczywistości test Turinga (nazwany na cześć słynnego matematyka Alana Turinga) jest zdany, gdy osoba oceniająca, która prowadzi rozmowę między dwoma agentami, nie może odróżnić, który z nich jest maszyną, a który człowiekiem. Jak dotąd nigdy nie przeszedł.
Oznacza to, że paradygmat asystenta daje obietnicę usług podobnych do ludzkich , których nigdy nie można spełnić, a użytkownik na pewno się zawiedzie. Udane doświadczenia tylko budują ostateczne rozczarowanie, ponieważ użytkownik zaczyna ufać swojemu ludzkiemu asystentowi.
Problem 2: Sekwencyjne i wolne interakcje
Drugim problemem asystentów głosowych jest to, że turowy charakter odpowiedzi w języku naturalnym powoduje opóźnienia w interakcji. Wynika to z tego, jak nasze mózgi przetwarzają informacje.
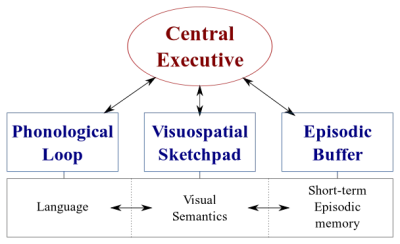
W naszych mózgach istnieją dwa rodzaje systemów przetwarzania danych:
- System językowy przetwarzający mowę;
- System wizualno-przestrzenny specjalizujący się w przetwarzaniu informacji wizualnej i przestrzennej.
Te dwa systemy mogą działać równolegle, ale oba systemy przetwarzają tylko jedną rzecz na raz . Dlatego możesz mówić i prowadzić samochód w tym samym czasie, ale nie możesz pisać SMS-ów i prowadzić, ponieważ obie te czynności miałyby miejsce w systemie wzrokowo-przestrzennym.

Podobnie, gdy rozmawiasz z asystentem głosowym, asystent musi zachować ciszę i na odwrót. Tworzy to rozmowę turową , w której druga część jest zawsze w pełni pasywna.
Zastanów się jednak nad trudnym tematem, o którym chcesz porozmawiać ze swoim przyjacielem. Prawdopodobnie rozmawiałbyś twarzą w twarz, a nie przez telefon, prawda? Dzieje się tak, ponieważ w rozmowie twarzą w twarz używamy komunikacji niewerbalnej, aby przekazać wizualną informację zwrotną w czasie rzeczywistym naszemu rozmówcy. Tworzy to dwukierunkową pętlę wymiany informacji i umożliwia obu stronom jednoczesne aktywne uczestnictwo w rozmowie.
Asystenci nie przekazują wizualnych informacji zwrotnych w czasie rzeczywistym. Opierają się na technologii zwanej wskazywaniem końcowym, aby decydować, kiedy użytkownik przestał mówić i odpowiada dopiero po tym. A kiedy odpowiadają, nie pobierają jednocześnie żadnych danych od użytkownika. Doświadczenie jest w pełni jednokierunkowe i turowe.
W dwukierunkowej rozmowie twarzą w twarz w czasie rzeczywistym obie strony mogą natychmiast reagować na sygnały wizualne i językowe. Wykorzystuje to różne systemy przetwarzania informacji w ludzkim mózgu, a rozmowa staje się płynniejsza i bardziej efektywna.
Asystenci głosowi utknęli w trybie jednokierunkowym, ponieważ używają języka naturalnego zarówno jako kanału wejściowego, jak i wyjściowego. Chociaż głos jest do czterech razy szybszy niż pisanie, jest znacznie wolniejszy do strawienia niż czytanie. Ponieważ informacje muszą być przetwarzane sekwencyjnie , to podejście sprawdza się tylko w przypadku prostych poleceń, takich jak „wyłącz światła”, które nie wymagają dużej ilości danych wyjściowych od asystenta.

Wcześniej obiecałem omówić głosowe interfejsy użytkownika, które wykorzystują głos tylko do wprowadzania danych od użytkownika. Ten rodzaj głosowych interfejsów użytkownika korzysta z najlepszych części głosowych interfejsów użytkownika — naturalności, szybkości i łatwości użytkowania — ale nie cierpi z powodu złych części — niesamowita dolina i sekwencyjne interakcje
Rozważmy tę alternatywę.
Lepsza alternatywa dla asystenta głosowego
Rozwiązaniem tych problemów w asystentach głosowych jest rezygnacja z odpowiedzi w języku naturalnym i zastąpienie ich wizualnymi informacjami zwrotnymi w czasie rzeczywistym. Przełączenie informacji zwrotnej na wizualną umożliwi użytkownikowi jednoczesne dawanie i otrzymywanie informacji zwrotnych. Umożliwi to aplikacji reagowanie bez przerywania użytkownikowi i umożliwienie dwukierunkowego przepływu informacji. Ponieważ przepływ informacji jest dwukierunkowy, jego przepustowość jest większa.
Obecnie najpopularniejsze przypadki użycia asystentów głosowych to ustawianie alarmów, odtwarzanie muzyki, sprawdzanie pogody i zadawanie prostych pytań. Wszystko to są zadania o niskiej stawce , które nie frustrują zbytnio użytkownika w przypadku niepowodzenia.
Jak napisał kiedyś David Pierce z Wall Street Journal :
„Nie wyobrażam sobie rezerwacji lotu, zarządzania budżetem za pomocą asystenta głosowego lub śledzenia mojej diety, wykrzykując składniki do mojego głośnika”.
— David Pierce z Wall Street Journal
Są to zadania wymagające dużej ilości informacji, które muszą przebiegać prawidłowo.
Jednak w końcu interfejs użytkownika głosowego zawiedzie. Kluczem jest jak najszybsze omówienie tego. Podczas pisania na klawiaturze lub nawet podczas rozmowy twarzą w twarz zdarza się wiele błędów. Jednak nie jest to wcale frustrujące, ponieważ użytkownik może odzyskać dane, klikając cofnięcie i próbując ponownie lub prosząc o wyjaśnienie.
To szybkie usuwanie błędów pozwala użytkownikowi być bardziej wydajnym i nie zmusza go do dziwnej rozmowy z asystentem.
Bezpośrednie interakcje głosowe
W większości aplikacji akcje są wykonywane poprzez manipulowanie elementami graficznymi na ekranie, poprzez szturchanie lub przesuwanie (na ekranach dotykowych), klikanie myszą i/lub naciskanie przycisków na klawiaturze. Wprowadzanie głosowe można dodać jako dodatkową opcję lub sposób manipulowania tymi elementami graficznymi. Ten rodzaj interakcji można nazwać bezpośrednią interakcją głosową .
Różnica między bezpośrednimi interakcjami głosowymi a asystentami polega na tym, że zamiast prosić awatara, asystenta, o wykonanie zadania, użytkownik bezpośrednio manipuluje głosem graficznym interfejsem użytkownika.
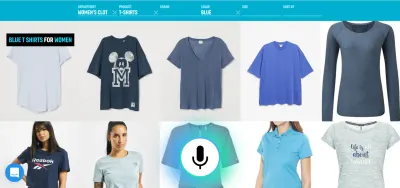
„Czy to nie semantyka?”, możesz zapytać. Jeśli masz zamiar rozmawiać z komputerem, czy to naprawdę ma znaczenie, czy rozmawiasz bezpośrednio z komputerem, czy przez wirtualną personę? W obu przypadkach po prostu rozmawiasz z komputerem!
Tak, różnica jest subtelna, ale krytyczna. Po kliknięciu przycisku lub elementu menu w GUI (interfejs graficzny użytkownika) jest rażąco oczywiste , że obsługujemy maszynę. Nie ma iluzji osoby. Zastępując to kliknięcie poleceniem głosowym, poprawiamy interakcję człowiek-komputer. Z drugiej strony, za pomocą paradygmatu asystenta tworzymy zdegradowaną wersję interakcji między ludźmi , a tym samym podróżujemy w dolinę niesamowitości.
Połączenie funkcji głosowych z graficznym interfejsem użytkownika daje również możliwość wykorzystania mocy różnych modalności. Chociaż użytkownik może używać głosu do obsługi aplikacji, ma również możliwość korzystania z tradycyjnego interfejsu graficznego. Dzięki temu użytkownik może płynnie przełączać się między dotykiem a głosem i wybrać najlepszą opcję w oparciu o kontekst i zadanie.
Na przykład głos jest bardzo wydajną metodą wprowadzania bogatych informacji. Wybór pomiędzy kilkoma poprawnymi alternatywami, dotknięcie lub kliknięcie jest prawdopodobnie lepsze. Użytkownik może następnie zastąpić pisanie i przeglądanie, mówiąc na przykład „Pokaż mi loty z Londynu do Nowego Jorku odlatujące jutro” i wybierając najlepszą opcję z listy za pomocą dotyku.
Teraz możesz zapytać „OK, to wygląda świetnie, dlaczego więc nie widzieliśmy wcześniej przykładów takich głosowych interfejsów użytkownika? Dlaczego największe firmy technologiczne nie tworzą narzędzi do czegoś takiego?” Cóż, prawdopodobnie jest wiele powodów. Jednym z powodów jest to, że obecny paradygmat asystenta głosowego jest prawdopodobnie najlepszym sposobem na wykorzystanie danych, które otrzymują od użytkowników końcowych. Kolejny powód ma związek ze sposobem budowy technologii głosowej.
Dobrze działający głosowy interfejs użytkownika wymaga dwóch odrębnych części:
- Rozpoznawanie mowy , które zamienia mowę w tekst;
- Składniki rozumienia języka naturalnego, które wydobywają znaczenie z tego tekstu.
Druga część to magia, która zamienia wypowiedzi „Wyłącz światła w salonie” i „Proszę wyłączyć światło w salonie” w tę samą akcję.
Zalecana lektura : Jak zbudować własną akcję dla Google Home za pomocą API.AI
Jeśli kiedykolwiek korzystałeś z asystenta z wyświetlaczem (takiego jak Siri lub Asystent Google), prawdopodobnie zauważyłeś, że otrzymujesz transkrypcję w czasie zbliżonym do rzeczywistego, ale gdy przestaniesz mówić, system zajmuje kilka sekund faktycznie wykonuje żądaną akcję. Wynika to zarówno z sekwencyjnego rozpoznawania mowy, jak i rozumienia języka naturalnego.
Zobaczmy, jak można to zmienić.
Zrozumienie języka mówionego w czasie rzeczywistym: sekretny sos do wydajniejszych poleceń głosowych
Szybkość reakcji aplikacji na dane wejściowe użytkownika jest głównym czynnikiem wpływającym na ogólne wrażenia użytkownika aplikacji. Najważniejszą innowacją oryginalnego iPhone'a był niezwykle responsywny i reaktywny ekran dotykowy. Równie ważna jest zdolność głosowego interfejsu użytkownika do natychmiastowej reakcji na wprowadzanie głosowe .
Aby ustanowić szybką dwukierunkową pętlę wymiany informacji między użytkownikiem a interfejsem użytkownika, graficzny interfejs użytkownika z obsługą głosową powinien być w stanie natychmiast reagować — nawet w połowie zdania — za każdym razem, gdy użytkownik powie coś, co można zrobić. Wymaga to techniki zwanej strumieniowym rozumieniem języka mówionego .
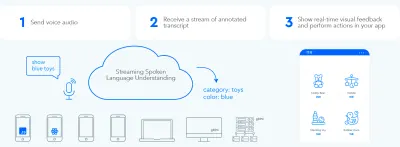
W przeciwieństwie do tradycyjnych turowych systemów asystentów głosowych, które czekają, aż użytkownik przestanie mówić przed przetworzeniem żądania użytkownika, systemy wykorzystujące strumieniowe rozumienie języka mówionego aktywnie próbują zrozumieć intencje użytkownika od momentu, gdy użytkownik zaczyna mówić. Gdy tylko użytkownik powie coś, co można zrobić, interfejs użytkownika natychmiast na to zareaguje.
Natychmiastowa odpowiedź natychmiast potwierdza, że system rozumie użytkownika i zachęca go do kontynuowania. Jest to analogiczne do skinienia głową lub krótkiego „a-ha” w komunikacji międzyludzkiej. Skutkuje to obsługą dłuższych i bardziej złożonych wypowiedzi. Odpowiednio, jeśli system nie rozumie użytkownika lub użytkownik błędnie mówi, natychmiastowa informacja zwrotna umożliwia szybkie odzyskanie . Użytkownik może natychmiast poprawić i kontynuować, a nawet poprawić się werbalnie: „Chcę tego, nie miałem na myśli, chcę tamtego”. Możesz samodzielnie wypróbować ten rodzaj aplikacji w naszym demo wyszukiwania głosowego.
Jak widać w wersji demonstracyjnej, wizualne informacje zwrotne w czasie rzeczywistym umożliwiają użytkownikowi naturalną korektę i zachęcają do kontynuowania wrażeń głosowych. Ponieważ nie są zdezorientowani wirtualną personą, mogą odnosić się do ewentualnych błędów w podobny sposób do literówek, a nie jako osobiste obelgi. Doświadczenie jest szybsze i bardziej naturalne , ponieważ informacje podawane użytkownikowi nie są ograniczone typową szybkością mowy około 150 słów na minutę.
Zalecana literatura : Projektowanie doświadczeń głosowych autorstwa Lyndona Cerejo
Wnioski
Chociaż asystenci głosowi byli jak dotąd najpowszechniejszym zastosowaniem interfejsów głosowych użytkownika, korzystanie z odpowiedzi w języku naturalnym sprawia, że są one nieefektywne i nienaturalne. Głos to świetna metoda wprowadzania informacji, ale słuchanie mówiącej maszyny nie jest zbyt inspirujące. To jest duży problem asystentów głosowych.
Przyszłość głosu nie powinna zatem leżeć w rozmowach z komputerem, ale w zastępowaniu żmudnych zadań użytkownika najbardziej naturalnym sposobem komunikowania się: mową . Bezpośrednie interakcje głosowe mogą służyć do usprawnienia wypełniania formularzy w aplikacjach internetowych lub mobilnych, tworzenia lepszych doświadczeń wyszukiwania oraz umożliwienia bardziej wydajnego sterowania lub nawigacji w aplikacji.
Projektanci i twórcy aplikacji nieustannie szukają sposobów na zmniejszenie tarcia w swoich aplikacjach lub witrynach internetowych. Ulepszenie obecnego graficznego interfejsu użytkownika za pomocą modalności głosowej umożliwiłoby wielokrotnie szybszą interakcję użytkownika, zwłaszcza w pewnych sytuacjach, na przykład gdy użytkownik końcowy korzysta z telefonu komórkowego i jest w ruchu, a pisanie jest trudne. W rzeczywistości wyszukiwanie głosowe może być nawet pięć razy szybsze niż tradycyjny interfejs użytkownika z filtrowaniem wyszukiwania, nawet na komputerze stacjonarnym.
Następnym razem, gdy zastanawiasz się, jak sprawić, by określone zadanie użytkownika w Twojej aplikacji było łatwiejsze w użyciu, przyjemniejsze w użyciu lub chcesz zwiększyć konwersję, zastanów się, czy to zadanie użytkownika można dokładnie opisać w języku naturalnym. Jeśli tak, uzupełnij interfejs użytkownika głosem, ale nie zmuszaj użytkowników do rozmowy z komputerem.
Zasoby
- „Voice First a multimodalne interfejsy użytkownika przyszłości”, Joan Palmiter Bajorek, UXmatters
- „Wytyczne dotyczące tworzenia produktywnych aplikacji obsługujących głos”, Hannes Heikinheimo, Speechly
- „6 powodów, dla których Twoje aplikacje z ekranem dotykowym powinny mieć funkcje głosowe”, Ottomatias Peura, UXmatters
- Mieszanie namacalnych i niematerialnych: projektowanie interfejsów multimodalnych za pomocą Adobe XD, Nick Babich, Smashing Magazine
( Adobe XD może służyć do prototypowania czegoś podobnego ) - „Wydajność z prędkością dźwięku: obietnica operacji głosowych”, Eric Turkington, RAIN
- Demo prezentujące wizualne informacje zwrotne w czasie rzeczywistym w filtrowaniu wyszukiwania głosowego eCommerce (wersja wideo)
- Speechly zapewnia narzędzia programistyczne dla tego rodzaju interfejsów użytkownika
- Alternatywa open source: voice2json