
Zaawansowane wykorzystanie GraphQL w witrynach Gatsby
Opublikowany: 2022-03-10Przed wydaniem GraphQL w 2015 roku, Representational State Transfer (REST) był głównym sposobem komunikowania się z API. Wprowadzenie GraphQL było zatem poważną zmianą w rozwoju oprogramowania.
Jako nowoczesny generator witryn statycznych Gatsby wykorzystuje GraphQL, aby zapewnić zwięzłą metodologię wprowadzania i manipulowania danymi w ramach struktury. W tym artykule przyjrzymy się bliżej GraphQL i temu, jak możemy zintegrować go z witryną Gatsby, tworząc i wdrażając zaawansowane pozyskiwanie i transformację danych w Gatsby. Rezultatem jest blog wydawcy, który może być wykorzystany przez dowolną firmę wydawniczą do udostępniania treści ich autorów.
Co to jest GraphQL?
GraphQL to język zapytań w swojej nazwie, który jest językiem zapytań połączonym z zestawem narzędzi stworzonych w celu zapewnienia elastyczności i wydajności w sposobie, w jaki pobieramy dane ze źródła. Dzięki GraphQL klient/konsument może zażądać dokładnie tych danych, których potrzebuje. Serwer/dostawca odpowiada podpisem odpowiedzi JSON zgodnym z wymaganiami określonymi w zapytaniu. Pozwala nam to deklaratywnie wyrazić nasze potrzeby dotyczące danych.
Dlaczego warto korzystać z GraphQL?
Jako generator witryn statycznych Gatsby przechowuje pliki statyczne, co sprawia, że zapytania o dane są prawie niemożliwe. Często istnieją komponenty strony, które muszą być dynamiczne, jak pojedyncza strona postów na blogu, więc pojawiłaby się potrzeba pobrania danych ze źródła i przekształcenia ich do wymaganego formatu, podobnie jak w przypadku postów na blogu przechowywanych w plikach przecen. Niektóre wtyczki dostarczają dane z różnych źródeł, co pozostawia Ci możliwość odpytywania i przekształcania wymaganych danych ze źródła.
Zgodnie z listą na gatsby.org, GraphQL jest przydatny w Gatsby do:
- Wyeliminuj kotłownię
- Wstawiaj złożoność frontendu do zapytań
- Zapewnij idealne rozwiązanie dla zawsze skomplikowanych danych współczesnej aplikacji
- Wreszcie, aby usunąć rozdęcie kodu, poprawiając w ten sposób wydajność.
Koncepcje GraphQL
Gatsby podtrzymuje te same idee GraphQL, które są powszechnie używane; niektóre z tych pojęć to:
Język definicji schematu
GraphQL SDL to system typów wbudowany w GraphQL i możesz go używać do tworzenia nowych typów dla swoich danych.
Możemy zadeklarować typ dla kraju, a jego atrybuty mogą obejmować nazwę, kontynent, populację, PKB i liczbę stanów.
Jako przykład poniżej stworzyliśmy nowy typ o nazwie Aleem . Ma hobbies , które są ciągami i nie są wymagane, ale kraj, stan cywilny i stanowiska są potrzebne ze względu na ! obejmują one również odnośniki do postów innego typu, Post .
type Author { name: String!, hobbies: [String] country: String! married: Boolean! posts: [Post!] } type Post { title: String! body: String! } type Query { author: Author } schema { query: Query }Zapytania
Możemy użyć zapytań do pobrania danych ze źródła GraphQL.
Biorąc pod uwagę zestaw danych taki jak poniżej
{ data: { author: [ { hobbies: ["travelling", "reading"], married: false, country: "Nigeria", name: "Aleem Isiaka", posts: [ { title: "Learn more about how to improve your Gatsby website", }, { title: "The ultimate guide to GatsbyJS", }, { title: "How to start a blog with only GatsbyJS", }, ], }, ], }, };Możemy mieć zapytanie, które do pobrania kraju i postów z danych:
query { authors { country, posts { title } } }Odpowiedź, którą otrzymamy, powinna zawierać dane JSON postów na blogu z samym tytułem i niczym więcej:
[ { country: “Nigeria”, posts: [{...}, {...}, {...}] }, { country: “Tunisia”, posts: [] }, { title: “Ghana”, posts: []}, ]Możemy również użyć argumentów jako warunków zapytania:
query { authors (country: “Nigeria”) { country, posts { title } } }Który powinien wrócić
[ { country: “Nigeria”, posts: [{...}, {...}, {...}] } ]Można również sprawdzać pola zagnieżdżone, tak jak posty z typem Post, możesz poprosić tylko o tytuły:
query { authors(country: 'Nigeria') { country, posts { title } } }Powinna też zwrócić dowolny typ Author pasujący do Nigerii , zwracając tablicę country i posts zawierającą obiekty zawierające tylko pole title.
Gatsby z GraphQL
Aby uniknąć obciążenia związanego z posiadaniem serwera/usługi, która obsługuje dane, które może przekształcić GraphQL, Gatsby wykonuje zapytania GraphQL w czasie kompilacji. Dane są dostarczane do komponentów podczas procesu kompilacji, dzięki czemu są łatwo dostępne w przeglądarce bez serwera.
Mimo to Gatsby może działać jako serwer, do którego mogą odpytywać inne klienty GraphQL, takie jak GraphiQL, w przeglądarce.
Gatsby Sposoby interakcji z GraphQL
Istnieją dwa miejsca, w których Gatsby może wchodzić w interakcje z GraphQL, za pośrednictwem pliku API gatsby-node.js i składników strony.
gatsby-node.js
API createPage może być skonfigurowane jako funkcja, która otrzyma helper graphql jako część pozycji w pierwszym argumencie przekazanym do funkcji.
// gatsby-node.js source: https://www.gatsbyjs.org/docs/node-apis/#createPages exports.createPages = async ({ graphql, actions }) => { const result = await graphql(` query loadPagesQuery ($limit: Int!) { allMarkdownRemark(limit: $limit) { edges { node { frontmatter { slug } } } } }`) }W powyższym kodzie użyliśmy helpera GraphQL do pobrania plików przecen z warstwy danych Gatsby'ego. Możemy to wstrzyknąć, aby utworzyć stronę i zmodyfikować istniejące dane w warstwie danych Gatsby.
Składniki strony
Komponenty strony w katalogu /pages lub szablony renderowane przez createPage API mogą importować graphql z modułu gatsby i eksportować pageQuery . Z kolei Gatsby wstrzykiwał nowe data właściwości do właściwości komponentu strony zawierającego rozwiązane dane.
import React from "react"; import { graphql } from "gatsby"; const Page = props => { return{JSON.stringify(props.data)}; }; eksportuj const pageQuery = graphql` zapytanie { ... } `; eksportuj domyślną stronę;
W innych komponentach
Inne komponenty mogą importować komponenty graphql i StaticQuery z modułu gatsby , renderować właściwości zapytania <StaticQuery/> przekazujące zapytania, które implementują pomocnik Graphql i renderować w celu uzyskania zwróconych danych.
import React from "react"; import { StaticQuery, graphql } from "gatsby"; const Brand = props => { return ( <div> <h1>{data.site.siteMetadata.title}</h1> </div> ); }; const Navbar = props => { return ( <StaticQuery query={graphql` query { site { siteMetadata { title } } } `} render={data => <Brand data={data} {...props} />} /> ); }; export default Navbar;Tworzenie nowoczesnego i zaawansowanego bloga wydawniczego Gatsby
W tej sekcji przejdziemy przez proces tworzenia bloga obsługującego tagowanie, kategoryzację, paginację i grupowanie artykułów według autorów. Użyjemy wtyczek ekosystemu Gatsby, aby wprowadzić niektóre funkcje i użyjemy logiki w zapytaniach GraphQL, aby blog wydawcy był gotowy na publikacje wielu autorów.
Ostateczną wersję bloga, który zbudujemy, można znaleźć tutaj, a kod jest hostowany na Github.
Inicjowanie projektu
Jak każda witryna Gatsby, inicjujemy od startera, tutaj będziemy używać zaawansowanego startera, ale zmodyfikowanego w celu zaspokojenia naszego przypadku użycia.
Najpierw sklonuj to repozytorium Github, zmień gałąź roboczą na dev-init, a następnie uruchom npm run develop development z folderu projektu, aby uruchomić serwer deweloperski udostępniający witrynę pod adresem https://localhost:8000.
git clone [email protected]:limistah/modern-gatsby-starter.git cd modern-gatsby-starter git checkout dev-init npm install npm run developOdwiedzenie https://localhost:8000 pokaże domyślną stronę główną dla tej gałęzi.
Tworzenie treści postów na blogu
Dostęp do niektórych treści postów zawartych w repozytorium projektu można uzyskać w gałęzi dev-blog-content. Organizacja katalogu treści wygląda następująco /content/YYYY_MM/DD.md , które grupują posty według utworzonego miesiąca roku.
Treść posta na blogu ma title , date , author , category , tags jako swoją główną rolę, których użyjemy do odróżnienia posta i dalszego przetwarzania, podczas gdy reszta treści to treść posta.
title: "Bold Mage" date: "2020-07-12" author: "Tunde Isiaka" category: "tech" tags: - programming - stuff - Ice cream - other --- # Donut I love macaroon chocolate bar Oat cake marshmallow lollipop fruitcake I love jelly-o. Gummi bears cake wafer chocolate bar pie. Marshmallow pastry powder chocolate cake candy chupa chups. Jelly beans powder souffle biscuit pie macaroon chocolate cake. Marzipan lemon drops chupa chups sweet cookie sesame snaps jelly halvah.Wyświetlanie treści posta
Zanim będziemy mogli renderować nasze posty Markdown w HTML, musimy wykonać pewne przetwarzanie. Najpierw ładowanie plików do pamięci Gatsby, parsowanie MD do HTML, łączenie zależności obrazu i polubień. Aby to ułatwić, użyjemy wielu wtyczek ekosystemu Gatsby.
Możemy użyć tych wtyczek, aktualizując plik gatsby-config.js w katalogu głównym projektu, aby wyglądał tak:
module.exports = { siteMetadata: {}, plugins: [ { resolve: "gatsby-source-filesystem", options: { name: "assets", path: `${__dirname}/static/`, }, }, { resolve: "gatsby-source-filesystem", options: { name: "posts", path: `${__dirname}/content/`, }, }, { resolve: "gatsby-transformer-remark", options: { plugins: [ { resolve: `gatsby-remark-relative-images`, }, { resolve: "gatsby-remark-images", options: { maxWidth: 690, }, }, { resolve: "gatsby-remark-responsive-iframe", }, "gatsby-remark-copy-linked-files", "gatsby-remark-autolink-headers", "gatsby-remark-prismjs", ], }, }, ], };Poinstruowaliśmy gatsby, aby dołączył wtyczki, które pomogą nam w wykonywaniu niektórych działań, w szczególności pobierania plików z folderu /static dla plików statycznych i /content dla naszych postów na blogu. Dodaliśmy również wtyczkę transformatora uwag, aby przekształcić wszystkie pliki kończące się na .md lub .markdown w węzeł ze wszystkimi polami uwag do renderowania znaczników jako HTML.
Na koniec uwzględniliśmy wtyczki działające na węzłach generowanych przez gatsby-transformer-remark .
Implementacja pliku API gatsby-config.js
Idąc dalej, wewnątrz gatsby-node.js w katalogu głównym projektu, możemy wyeksportować funkcję o nazwie createPage i mieć zawartość funkcji, aby użyć helpera graphQL do wyciągnięcia węzłów z warstwy zawartości GatsbyJS.
Pierwsza aktualizacja tej strony obejmowałaby upewnienie się, że mamy ustawiony slug w węzłach uwag MarkDown. Zanim zaktualizujemy węzeł tak, aby zawierał informacje i datę, będziemy nasłuchiwać interfejsu API onCreateNode i utworzyć węzeł, aby określić, czy jest to typ MarkdownRemark.
const path = require("path"); const _ = require("lodash"); const moment = require("moment"); const config = require("./config"); // Called each time a new node is created exports.onCreateNode = ({ node, actions, getNode }) => { // A Gatsby API action to add a new field to a node const { createNodeField } = actions; // The field that would be included let slug; // The currently created node is a MarkdownRemark type if (node.internal.type === "MarkdownRemark") { // Recall, we are using gatsby-source-filesystem? // This pulls the parent(File) node, // instead of the current MarkdownRemark node const fileNode = getNode(node.parent); const parsedFilePath = path.parse(fileNode.relativePath); if ( Object.prototype.hasOwnProperty.call(node, "frontmatter") && Object.prototype.hasOwnProperty.call(node.frontmatter, "title") ) { // The node is a valid remark type and has a title, // Use the title as the slug for the node. slug = `/${_.kebabCase(node.frontmatter.title)}`; } else if (parsedFilePath.name !== "index" && parsedFilePath.dir !== "") { // File is in a directory and the name is not index // eg content/2020_02/learner/post.md slug = `/${parsedFilePath.dir}/${parsedFilePath.name}/`; } else if (parsedFilePath.dir === "") { // File is not in a subdirectory slug = `/${parsedFilePath.name}/`; } else { // File is in a subdirectory, and name of the file is index // eg content/2020_02/learner/index.md slug = `/${parsedFilePath.dir}/`; } if (Object.prototype.hasOwnProperty.call(node, "frontmatter")) { if (Object.prototype.hasOwnProperty.call(node.frontmatter, "slug")) slug = `/${_.kebabCase(node.frontmatter.slug)}`; if (Object.prototype.hasOwnProperty.call(node.frontmatter, "date")) { const date = moment(new Date(node.frontmatter.date), "DD/MM/YYYY"); if (!date.isValid) console.warn(`WARNING: Invalid date.`, node.frontmatter); // MarkdownRemark does not include date by default createNodeField({ node, name: "date", value: date.toISOString() }); } } createNodeField({ node, name: "slug", value: slug }); } };Lista wpisów
W tym momencie możemy zaimplementować interfejs API createPages do zapytań o wszystkie przeceny i utworzyć stronę ze ścieżką jako slug, który stworzyliśmy powyżej. Zobacz to na Github.
//gatsby-node.js // previous code // Create Pages Programatically! exports.createPages = async ({ graphql, actions }) => { // Pulls the createPage action from the Actions API const { createPage } = actions; // Template to use to render the post converted HTML const postPage = path.resolve("./src/templates/singlePost/index.js"); // Get all the markdown parsed through the help of gatsby-source-filesystem and gatsby-transformer-remark const allMarkdownResult = await graphql(` { allMarkdownRemark { edges { node { fields { slug } frontmatter { title tags category date author } } } } } `); // Throws if any error occur while fetching the markdown files if (allMarkdownResult.errors) { console.error(allMarkdownResult.errors); throw allMarkdownResult.errors; } // Items/Details are stored inside of edges const postsEdges = allMarkdownResult.data.allMarkdownRemark.edges; // Sort posts postsEdges.sort((postA, postB) => { const dateA = moment( postA.node.frontmatter.date, siteConfig.dateFromFormat ); const dateB = moment( postB.node.frontmatter.date, siteConfig.dateFromFormat ); if (dateA.isBefore(dateB)) return 1; if (dateB.isBefore(dateA)) return -1; return 0; }); // Pagination Support for posts const paginatedListingTemplate = path.resolve( "./src/templates/paginatedListing/index.js" ); const { postsPerPage } = config; if (postsPerPage) { // Get the number of pages that can be accommodated const pageCount = Math.ceil(postsEdges.length / postsPerPage); // Creates an empty array Array.from({ length: pageCount }).forEach((__value__, index) => { const pageNumber = index + 1; createPage({ path: index === 0 ? `/posts` : `/posts/${pageNumber}/`, component: paginatedListingTemplate, context: { limit: postsPerPage, skip: index * postsPerPage, pageCount, currentPageNumber: pageNumber, }, }); }); } else { // Load the landing page instead createPage({ path: `/`, component: landingPage, }); } }; W funkcji createPages używamy helpera graphql dostarczonego przez Gatsby do zapytania danych z warstwy treści. Użyliśmy do tego standardowego zapytania Graphql i przekazaliśmy zapytanie, aby pobrać zawartość z typu allMarkdownRemark . Następnie przejdź do przodu, aby posortować posty według daty utworzenia.

Następnie ściągnęliśmy właściwość postPerPage z zaimportowanego obiektu konfiguracyjnego, która służy do podzielenia wszystkich postów na określoną liczbę postów na jednej stronie.
Aby utworzyć stronę listy, która obsługuje paginację, musimy przekazać limit, numer strony i liczbę stron, aby przejść do komponentu, który renderowałby listę. Osiągamy to za pomocą właściwości context obiektu konfiguracyjnego createPage . Będziemy uzyskiwać dostęp do tych właściwości ze strony, aby wykonać kolejne zapytanie graphql w celu pobrania postów w ramach limitu.
Możemy również zauważyć, że używamy tego samego komponentu szablonu dla listingu i tylko ścieżka zmienia się przy użyciu indeksu tablicy porcji, którą zdefiniowaliśmy wcześniej. Gatsby przekaże niezbędne dane dla danego adresu URL pasującego do /{chunkIndex} , więc możemy mieć / dla pierwszych dziesięciu postów i /2 dla następnych dziesięciu postów.
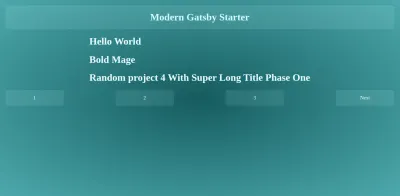
Renderowanie aukcji postów
Komponent renderujący te strony można znaleźć w src/templates/singlePost/index.js w folderze projektu. Eksportuje również helper graphql , który pobiera limit i parametr zapytania strony otrzymane z procesu createPages w celu zapytania gatsby o posty w zakresie bieżącej strony.
import React from "react"; import { graphql, Link } from "gatsby"; import Layout from "../../layout"; import PostListing from "../../components/PostListing"; import "./index.css"; const Pagination = ({ currentPageNum, pageCount }) => { const prevPage = currentPageNum - 1 === 1 ? "/" : `/${currentPageNum - 1}/`; const nextPage = `/${currentPageNum + 1}/`; const isFirstPage = currentPageNum === 1; const isLastPage = currentPageNum === pageCount; return ( <div className="paging-container"> {!isFirstPage && <Link to={prevPage}>Previous</Link>} {[...Array(pageCount)].map((_val, index) => { const pageNum = index + 1; return ( <Link key={`listing-page-${pageNum}`} to={pageNum === 1 ? "/" : `/${pageNum}/`} > {pageNum} </Link> ); })} {!isLastPage && <Link to={nextPage}>Next</Link>} </div> ); }; export default (props) => { const { data, pageContext } = props; const postEdges = data.allMarkdownRemark.edges; const { currentPageNum, pageCount } = pageContext; return ( <Layout> <div className="listing-container"> <div className="posts-container"> <PostListing postEdges={postEdges} /> </div> <Pagination pageCount={pageCount} currentPageNum={currentPageNum} /> </div> </Layout> ); }; /* eslint no-undef: "off" */ export const pageQuery = graphql` query ListingQuery($skip: Int!, $limit: Int!) { allMarkdownRemark( sort: { fields: [fields___date], order: DESC } limit: $limit skip: $skip ) { edges { node { fields { slug date } excerpt timeToRead frontmatter { title tags author category date } } } } } `;Strona posta
Aby wyświetlić zawartość strony, musimy programowo utworzyć stronę w pliku API gatsby-node.js . Najpierw musimy zdefiniować nowy komponent do renderowania zawartości, w tym celu mamy src/templates/singlePost/index.jsx .
import React from "react"; import { graphql, Link } from "gatsby"; import _ from "lodash"; import Layout from "../../layout"; import "./b16-tomorrow-dark.css"; import "./index.css"; import PostTags from "../../components/PostTags"; export default class PostTemplate extends React.Component { render() { const { data, pageContext } = this.props; const { slug } = pageContext; const postNode = data.markdownRemark; const post = postNode.frontmatter; if (!post.id) { post.id = slug; } return ( <Layout> <div> <div> <h1>{post.title}</h1> <div className="category"> Posted to{" "} <em> <Link key={post.category} style={{ textDecoration: "none" }} to={`/category/${_.kebabCase(post.category)}`} > <a>{post.category}</a> </Link> </em> </div> <PostTags tags={post.tags} /> <div dangerouslySetInnerHTML={{ __html: postNode.html }} /> </div> </div> </Layout> ); } } /* eslint no-undef: "off" */ export const pageQuery = graphql` query BlogPostBySlug($slug: String!) { markdownRemark(fields: { slug: { eq: $slug } }) { html timeToRead excerpt frontmatter { title date category tags } fields { slug date } } } `;Ponownie, używamy helpera graphQL do wyciągnięcia strony za pomocą zapytania o informacje, które zostanie wysłane do strony za pośrednictwem interfejsu API createPages.
Następnie powinniśmy dodać poniższy kod do gatsby-node.js na końcu funkcji API createPages .
// Template to use to render the post converted HTML const postPage = path.resolve("./src/templates/singlePost/index.jsx"); // Loops through all the post nodes postsEdges.forEach((edge, index) => { // Create post pages createPage({ path: edge.node.fields.slug, component: postPage, context: { slug: edge.node.fields.slug, }, }); }); I moglibyśmy odwiedzić '/{pageSlug}' i zlecić renderowanie zawartości pliku Markdown dla tej strony jako HTML. Na przykład https://localhost:8000/the-butterfly-of-the-edge powinien załadować przekonwertowany kod HTML dla przecen pod adresem: content/2020_05/01.md , podobnie do wszystkich prawidłowych slugów. Świetnie!

Kategorie renderowania i tagi
Komponent szablonu pojedynczego posta zawiera link do strony w formacie /categories/{categoryName} , aby wyświetlić listę postów z podobnymi kategoriami.
Możemy najpierw przechwycić wszystkie kategorie i tagi, budując stronę pojedynczego posta w pliku gatsby-node.js , a następnie tworzyć strony dla każdej przechwyconej kategorii/tagu, przekazując nazwę kategorii/tagu.
Modyfikacja sekcji tworzenia strony pojedynczego posta w gatsby-node.js wygląda tak:
const categorySet = new Set(); const tagSet = new Set(); const categoriesListing = path.resolve( "./src/templates/categoriesListing/index.jsx" ); // Template to use to render posts based on categories const tagsListingPage = path.resolve("./src/templates/tagsListing/index.jsx"); // Loops through all the post nodes postsEdges.forEach((edge, index) => { // Generate a list of categories if (edge.node.frontmatter.category) { categorySet.add(edge.node.frontmatter.category); } // Generate a list of tags if (edge.node.frontmatter.tags) { edge.node.frontmatter.tags.forEach((tag) => { tagSet.add(tag); }); } // Create post pages createPage({ path: edge.node.fields.slug, component: postPage, context: { slug: edge.node.fields.slug, }, }); }); A wewnątrz komponentu do wyświetlania postów według tagów, możemy mieć pageQuery zapytania eksportu pageQuery dla postów, włączając ten tag do swojej listy tagów. Aby to osiągnąć, użyjemy funkcji filter graphql i operatora $in:
// src/templates/tagsListing/ import React from "react"; import { graphql } from "gatsby"; import Layout from "../../layout"; import PostListing from "../../components/PostListing"; export default ({ pageContext, data }) => { const { tag } = pageContext; const postEdges = data.allMarkdownRemark.edges; return ( <Layout> <div className="tag-container"> <div>Posts posted with {tag}</div> <PostListing postEdges={postEdges} /> </div> </Layout> ); }; /* eslint no-undef: "off" */ export const pageQuery = graphql` query TagPage($tag: String) { allMarkdownRemark( limit: 1000 sort: { fields: [fields___date], order: DESC } filter: { frontmatter: { tags: { in: [$tag] } } } ) { totalCount edges { node { fields { slug date } excerpt timeToRead frontmatter { title tags author date } } } } } `;I mamy ten sam proces w komponencie listy kategorii, a różnica polega na tym, że musimy tylko znaleźć, gdzie kategorie dokładnie pasują do tego, co do nich przekazujemy.
// src/templates/categoriesListing/index.jsx import React from "react"; import { graphql } from "gatsby"; import Layout from "../../layout"; import PostListing from "../../components/PostListing"; export default ({ pageContext, data }) => { const { category } = pageContext; const postEdges = data.allMarkdownRemark.edges; return ( <Layout> <div className="category-container"> <div>Posts posted to {category}</div> <PostListing postEdges={postEdges} /> </div> </Layout> ); }; /* eslint no-undef: "off" */ export const pageQuery = graphql` query CategoryPage($category: String) { allMarkdownRemark( limit: 1000 sort: { fields: [fields___date], order: DESC } filter: { frontmatter: { category: { eq: $category } } } ) { totalCount edges { node { fields { slug date } excerpt timeToRead frontmatter { title tags author date } } } } } `;Zauważalne, że zarówno wewnątrz elementów tagów, jak i kategorii, renderujemy linki do strony pojedynczego posta w celu dalszego czytania treści posta.
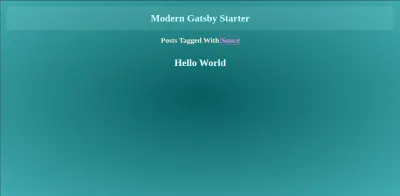
Dodawanie wsparcia dla autorów
Aby wspierać wielu autorów, musimy wprowadzić pewne modyfikacje w treści naszego posta i wprowadzić nowe koncepcje.
Załaduj pliki JSON
Po pierwsze, powinniśmy być w stanie przechowywać zawartość autorów w pliku JSON w następujący sposób:
{ "mdField": "aleem", "name": "Aleem Isiaka", "email": "[email protected]", "location": "Lagos, Nigeria", "avatar": "https://api.adorable.io/avatars/55/[email protected]", "description": "Yeah, I like animals better than people sometimes... Especially dogs. Dogs are the best. Every time you come home, they act like they haven't seen you in a year. And the good thing about dogs... is they got different dogs for different people.", "userLinks": [ { "label": "GitHub", "url": "https://github.com/limistah/modern-gatsby-starter", "iconClassName": "fa fa-github" }, { "label": "Twitter", "url": "https://twitter.com/limistah", "iconClassName": "fa fa-twitter" }, { "label": "Email", "url": "mailto:[email protected]", "iconClassName": "fa fa-envelope" } ] } Przechowywalibyśmy je w katalogu autora w katalogu głównym naszego projektu jako /authors . Zwróć uwagę, że JSON autora ma mdField , który byłby unikalnym identyfikatorem pola autora, który wprowadzimy do treści bloga przecen; zapewnia to, że autorzy mogą mieć wiele profili.
Następnie musimy zaktualizować wtyczki gatsby-config.js instruując gatsby gatsby-source-filesystem , aby ładował zawartość z katalogu authors/ do węzła Pliki.
// gatsby-config.js { resolve: `gatsby-source-filesystem`, options: { name: "authors", path: `${__dirname}/authors/`, }, } Na koniec zainstalujemy gatsby-transform-json , aby przekształcić pliki JSON utworzone w celu łatwej obsługi i prawidłowego przetwarzania.
npm install gatsby-transformer-json --save I dołącz go do wtyczek gatsby-config.js ,
module.exports = { plugins: [ // ...other plugins `gatsby-transformer-json` ], };Strona z zapytaniami i tworzeniem autorów
Na początek musimy wysłać zapytanie do wszystkich autorów w naszym katalogu authors/ wewnątrz gatsby-config.js , którzy zostali załadowani do warstwy danych, powinniśmy dołączyć poniższy kod do funkcji API createPages
const authorsListingPage = path.resolve( "./src/templates/authorsListing/index.jsx" ); const allAuthorsJson = await graphql(` { allAuthorsJson { edges { node { id avatar mdField location name email description userLinks { iconClassName label url } } } } } `); const authorsEdges = allAuthorsJson.data.allAuthorsJson.edges; authorsEdges.forEach((author) => { createPage({ path: `/authors/${_.kebabCase(author.node.mdField)}/`, component: authorsListingPage, context: { authorMdField: author.node.mdField, authorDetails: author.node, }, }); }); W tym fragmencie pobieramy wszystkich autorów z typu allAuthorsJson, a następnie wywołujemy forEach na węzłach w celu utworzenia strony, na której przekazujemy mdField w celu rozróżnienia autora i authorDetails w celu uzyskania pełnych informacji o autorze.
Renderowanie postów autora
W komponencie renderującym stronę, który można znaleźć pod adresem src/templates/authorsListing/index.jsx , mamy poniższą zawartość pliku
import React from "react"; import { graphql } from "gatsby"; import Layout from "../../layout"; import PostListing from "../../components/PostListing"; import AuthorInfo from "../../components/AuthorInfo"; export default ({ pageContext, data }) => { const { authorDetails } = pageContext; const postEdges = data.allMarkdownRemark.edges; return ( <Layout> <div> <h1 style={{ textAlign: "center" }}>Author Roll</h1> <div className="category-container"> <AuthorInfo author={authorDetails} /> <PostListing postEdges={postEdges} /> </div> </div> </Layout> ); }; /* eslint no-undef: "off" */ export const pageQuery = graphql` query AuthorPage($authorMdField: String) { allMarkdownRemark( limit: 1000 sort: { fields: [fields___date], order: DESC } filter: { frontmatter: { author: { eq: $authorMdField } } } ) { totalCount edges { node { fields { slug date } excerpt timeToRead frontmatter { title tags author date } } } } } `; W powyższym kodzie wyeksportowaliśmy pageQuery tak jak to robimy, aby utworzyć zapytanie GraphQL w celu pobrania postów dopasowanych przez autora, używamy operatora $eq , aby to osiągnąć, generując linki do pojedynczej strony posta do dalszego czytania.

Wniosek
W Gatsby możemy odpytywać dowolne dane znajdujące się w jego warstwie dostępu do danych za pomocą zapytania GraphQL i przekazywać zmienne za pomocą konstrukcji zdefiniowanych przez architekturę Gatsby. widzieliśmy, jak możemy użyć pomocnika graphql w różnych miejscach i zrozumieć powszechnie stosowane wzorce zapytań o dane w witrynach Gatsby'ego za pomocą GraphQL.
GraphQL jest bardzo potężny i może robić inne rzeczy, takie jak mutacja danych na serwerze. Gatsby nie musi aktualizować swoich danych w czasie wykonywania, więc nie obsługuje funkcji mutacji GraphQL.
GraphQL to świetna technologia, a Gatsby sprawia, że jest bardzo interesujący do wykorzystania w ich ramach.
Bibliografia
- Wsparcie Gatsby dla GraphQL
- Dlaczego Gatsby używa GraphQL
- Koncepcje GraphQL w Gatsby
- Jak GraphQL: Podstawowe pojęcia
- Język definicji schematu w GraphQL
- Wprowadzenie do GraphQL
- Gatsby Advanced Starter