
Przewodnik po regresji liniowej za pomocą Scikit [z przykładami]
Opublikowany: 2021-06-18Algorytmy uczenia nadzorowanego są generalnie dwojakiego rodzaju: regresja i klasyfikacja z przewidywaniem wyników ciągłych i dyskretnych.
Poniższy artykuł omówi regresję liniową i jej implementację przy użyciu jednej z najpopularniejszych bibliotek uczenia maszynowego Pythona, biblioteki Scikit-learn. Narzędzia do uczenia maszynowego i modele statystyczne są dostępne w bibliotece Pythona do klasyfikacji, regresji, grupowania i redukcji wymiarów. Napisana w języku programowania Python biblioteka jest zbudowana na bibliotekach Pythona NumPy, SciPy i Matplotlib.
Spis treści
Regresja liniowa
Regresja liniowa wykonuje zadanie regresji w ramach metody nadzorowanego uczenia się. Na podstawie zmiennych niezależnych prognozowana jest wartość docelowa. Metodę stosuje się głównie do prognozowania i identyfikowania relacji między zmiennymi.
W algebrze termin liniowość oznacza liniową zależność między zmiennymi. Wyprowadza się linię prostą między zmiennymi w przestrzeni dwuwymiarowej.
Jeśli linia jest wykresem między zmiennymi niezależnymi na osi X a zmiennymi zależnymi na osi Y, linię prostą uzyskuje się poprzez regresję liniową, która najlepiej pasuje do punktów danych.
Równanie prostej ma postać

Y = mx + b
Gdzie, b= przecięcie
m= nachylenie linii
Dlatego poprzez regresję liniową
- Najbardziej optymalne wartości punktu przecięcia i nachylenia określane są w dwóch wymiarach.
- Nie ma zmian w zmiennych x i y, ponieważ są one cechami danych, a zatem pozostają takie same.
- Można sterować tylko przecięciem i wartościami nachylenia.
- Może istnieć wiele linii prostych opartych na wartościach nachylenia i przecięcia, jednak za pomocą algorytmu regresji liniowej do punktów danych dopasowuje się wiele linii i zwracana jest linia z najmniejszym błędem.
Regresja liniowa w Pythonie
Aby zaimplementować regresję liniową w Pythonie, należy zastosować odpowiednie pakiety wraz z jego funkcjami i klasami. Pakiet NumPy w Pythonie jest oprogramowaniem typu open source i umożliwia wykonywanie kilku operacji na tablicach, zarówno pojedynczych, jak i wielowymiarowych.
Inną szeroko używaną biblioteką w Pythonie jest Scikit-learn, która jest używana do rozwiązywania problemów z uczeniem maszynowym.
Nauka scikitN
Biblioteka Scikit-learn oferuje programistom algorytmy oparte zarówno na uczeniu nadzorowanym, jak i nienadzorowanym. Biblioteka Pythona o otwartym kodzie źródłowym jest przeznaczona do zadań uczenia maszynowego.
Analitycy danych mogą importować dane, wstępnie je przetwarzać, wykreślać i przewidywać dane za pomocą scikit-learn.
David Cournapeau po raz pierwszy opracował scikit-learn w 2007 roku, a biblioteka rozwija się od dziesięcioleci.
Narzędzia dostarczane przez scikit-learn to:
- Regresja: Obejmuje regresję logistyczną i regresję liniową
- Klasyfikacja: Obejmuje metodę K-Nearest Neighbors
- Wybór modelu
- Grupowanie: obejmuje zarówno K-Means++, jak i K-Means
- Przetwarzanie wstępne
Zaletami biblioteki są:
- Nauka i wdrażanie biblioteki są łatwe.
- Jest to biblioteka typu open source, a zatem bezpłatna.
- Aspekty uczenia maszynowego można ukryć, w tym głębokie uczenie.
- To potężny i wszechstronny pakiet.
- Biblioteka posiada szczegółową dokumentację.
- Jeden z najczęściej używanych zestawów narzędzi do uczenia maszynowego.
Importowanie scikit-learning
Scikit-learn musi być zainstalowany najpierw przez pip lub przez conda.
- Wymagania: 64-bitowa wersja Pythona 3 z zainstalowanymi bibliotekami NumPy i Scipy. Również do wizualizacji wykresów danych wymagany jest program matplotlib.
Polecenie instalacji: pip install -U scikit-learn
Następnie sprawdź, czy instalacja została zakończona
Instalacja Numpy, Scipy i matplotlib
Instalację można potwierdzić poprzez:
Źródło
Regresja liniowa przez Scikit-learn
Implementacja regresji liniowej za pomocą pakietu scikit-learn obejmuje następujące kroki.
- Wymagane pakiety i klasy należy zaimportować.
- Dane są wymagane do pracy i przeprowadzania odpowiednich przekształceń.
- Należy stworzyć model regresji i dopasować go do istniejących danych.
- Dane dopasowania modelu należy sprawdzić, aby przeanalizować, czy utworzony model jest zadowalający.
- Prognozy należy wykonać poprzez zastosowanie modelu.
Pakiet NumPy i klasa LinearRegression mają zostać zaimportowane z modelu sklearn.linear_model.

Źródło
Wszystkie funkcje wymagane do regresji liniowej Sklearna są obecne, aby ostatecznie wdrożyć regresję liniową. Klasa sklearn.linear_model.LinearRegression służy do przeprowadzania analizy regresji (zarówno liniowej, jak i wielomianowej) oraz przeprowadzania prognoz.
W przypadku dowolnych algorytmów uczenia maszynowego i nauki regresji liniowej scikit zestaw danych należy najpierw zaimportować. W Scikit-naucz się, aby uzyskać dane dostępne są trzy opcje:
- Zestawy danych, takie jak klasyfikacja tęczówki lub zestaw regresji cen mieszkań w Bostonie.
- Zestawy danych ze świata rzeczywistego można pobrać z Internetu bezpośrednio za pomocą predefiniowanych funkcji Scikit-learn.
- Zestaw danych można wygenerować losowo w celu dopasowania do określonego wzorca za pomocą generatora danych uczenia się Scikit.
Niezależnie od wybranej opcji, zestawy danych modułu muszą zostać zaimportowane.

importuj sklearn.datasets jako zestawy danych
1. Zestaw klasyfikacyjny tęczówki
tęczówka = zestawy danych.load_iris()
Przesłona zestawu danych jest przechowywana jako pole danych tablicy 2D n_samples * n_features. Jego import odbywa się jako obiekt słownika. Zawiera wszystkie niezbędne dane wraz z metadanymi.
Funkcje DESCR, shape i _names mogą służyć do pobierania opisów i formatowania danych. Wydruk wyników funkcji wyświetli informacje o zestawie danych, które mogą być potrzebne podczas pracy na zestawie danych tęczówki.
Poniższy kod załaduje informacje z zestawu danych tęczówki.
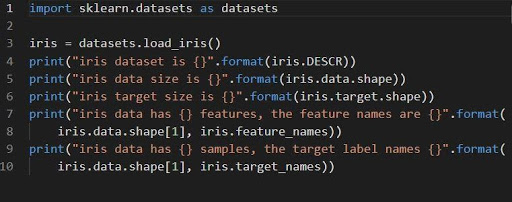
Źródło
2. Generowanie danych regresji
Jeśli nie ma wymagań dotyczących danych wbudowanych, dane można wygenerować za pomocą rozkładu, który można wybrać.
Generowanie danych regresji za pomocą zestawu 1 cechy informacyjnej i 1 cechy.
X , Y = zestawy danych.make_regression(n_features=1, n_informative=1)
Wygenerowane dane są zapisywane w zestawie danych 2D z obiektami x i y. Charakterystykę generowanych danych można zmienić poprzez zmianę parametrów funkcji make_regresja.
W tym przykładzie parametry funkcji informacyjnych i funkcji zostały zmienione z wartości domyślnej 10 na 1.
Inne brane pod uwagę parametry to próbki i wartości docelowe , w przypadku których kontrolowana jest liczba śledzonych zmiennych docelowych i próbek.
- Funkcje, które dostarczają przydatnych informacji algorytmom ML, są określane jako funkcje informacyjne, podczas gdy te, które są nieprzydatne, są określane jako funkcje informacyjne.
3. Wykreślanie danych
Dane są wykreślane przy użyciu biblioteki matplotlib. Najpierw należy zaimportować bibliotekę matplotlib.
Importuj matplotlib.pyplot jako plt
Powyższy wykres jest wykreślany przez matplotlib za pomocą kodu
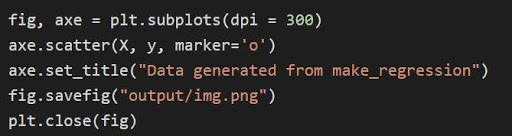
Źródło
W powyższym kodzie:
- Zmienne krotek są rozpakowywane i zapisywane jako osobne zmienne w pierwszym wierszu kodu. W związku z tym można manipulować i zapisywać poszczególne atrybuty.
- Zestaw danych x, y służy do generowania wykresu punktowego w linii 2. Dzięki dostępności parametru markera w matplotlib, wizualizacje są ulepszane poprzez oznaczenie punktów danych kropką (o).
- Tytuł wygenerowanej fabuły jest ustawiony w linii 3.
- Figurę można zapisać jako plik obrazu .png i wtedy bieżąca figura jest zamykana.
Wykres regresji wygenerowany przez powyższy kod to
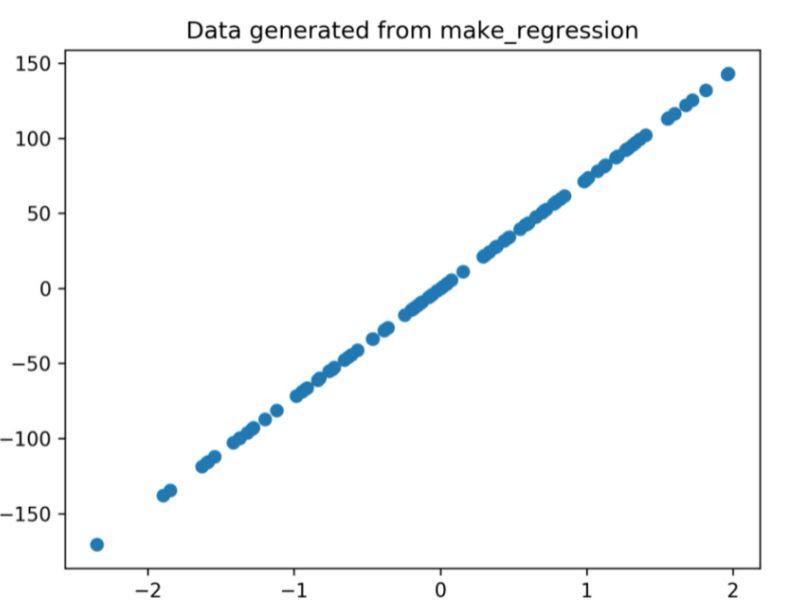
Rysunek 1: Wykres regresji wygenerowany z powyższego kodu.
4. Implementacja algorytmu regresji liniowej
Wykorzystując przykładowe dane dotyczące ceny mieszkań w Bostonie, w poniższym przykładzie zaimplementowano algorytm regresji liniowej typu Scikit-learn . Podobnie jak inne algorytmy ML, zestaw danych jest importowany, a następnie trenowany przy użyciu poprzednich danych.
Regresja liniowa jest wykorzystywana przez firmy, ponieważ jest to model predykcyjny, który przewiduje związek między wielkością liczbową i jej zmiennymi a wartością wyjściową, mający znaczenie mające wartość w rzeczywistości.
Gdy obecny jest dziennik wcześniejszych danych, model można najlepiej zastosować, ponieważ może on przewidzieć przyszłe wyniki tego, co wydarzy się w przyszłości, jeśli będzie kontynuacja wzorca.
Matematycznie dane można dopasować w celu zminimalizowania sumy wszystkich reszt istniejących między punktami danych a przewidywaną wartością.
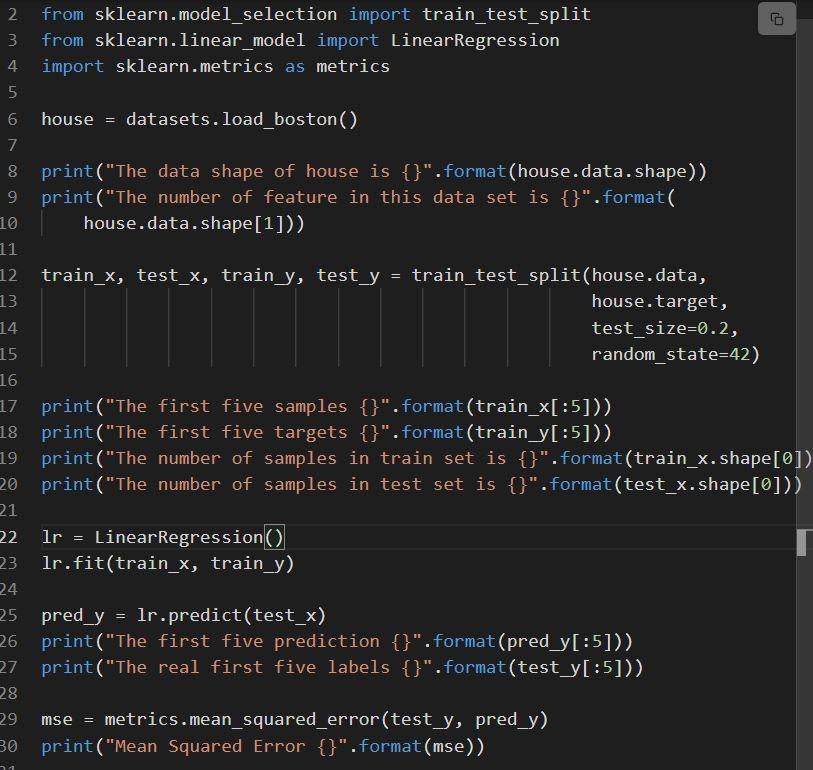
Poniższy fragment przedstawia implementację regresji liniowej Sklearna.
Źródło
Kod jest wyjaśniony jako:
- Linia 6 ładuje zestaw danych o nazwie load_boston.
- Zbiór danych jest podzielony w linii 12, tj. zbiór uczący zawierający 80% danych oraz zbiór testowy zawierający 20% danych.
- Stworzenie modelu regresji liniowej w linii 23, a następnie przeszkolenie w.
- Wydajność modelu jest oceniana na poziomie 29 poprzez wywołanie mean_squared_error.
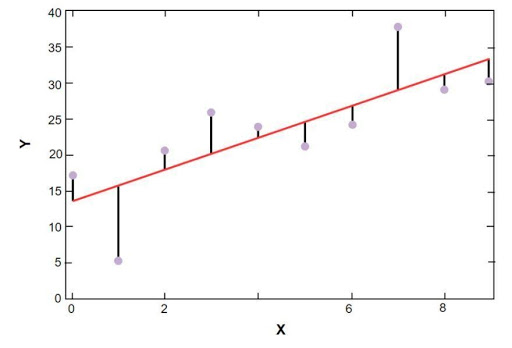
Wykres regresji liniowej Sklearna pokazano poniżej:
Model regresji liniowej danych z próby cen mieszkań w Bostonie
Źródło
Na powyższym rysunku czerwona linia reprezentuje model liniowy, który został rozwiązany dla przykładowych danych cen mieszkań w Bostonie. Niebieskie punkty reprezentują oryginalne dane, a odległość między czerwoną linią a niebieskimi punktami reprezentuje sumę reszt. Celem modelu regresji liniowej typu scikit-learn jest zmniejszenie sumy reszt.
Wniosek
W artykule omówiono regresję liniową i jej implementację za pomocą pakietu Pythona o otwartym kodzie źródłowym o nazwie scikit-learn. Do tej pory jesteś w stanie zrozumieć, jak zaimplementować regresję liniową za pomocą tego pakietu. Warto nauczyć się wykorzystywać bibliotekę do analizy danych.
Jeśli jesteś zainteresowany dalszą eksploracją tematu, na przykład implementacją pakietów Pythona w uczeniu maszynowym i problemach związanych z AI, możesz sprawdzić kurs Master of Science in Machine Learning & AI oferowany przez upGrad . Kurs przeznaczony dla początkujących profesjonalistów w wieku od 21 do 45 lat ma na celu przeszkolenie studentów w zakresie uczenia maszynowego poprzez ponad 650 godzin szkolenia online, ponad 25 studiów przypadków i zadania. Certyfikowany przez LJMU kurs oferuje doskonałe wskazówki i pomoc w znalezieniu pracy. Jeśli masz jakieś pytania lub wątpliwości, zostaw nam wiadomość, chętnie się z Tobą skontaktujemy.