
Java를 사용한 머신 러닝이란 무엇입니까? 그것을 구현하는 방법?
게시 됨: 2021-03-10목차
머신 러닝이란 무엇입니까?
머신 러닝은 인간의 행동과 지능을 모방하기 위해 사용 가능한 데이터, 예제 및 경험을 학습하는 인공 지능의 한 부문입니다. 기계 학습을 사용하여 만든 프로그램은 사람이 수동으로 코드를 작성할 필요 없이 자체적으로 논리를 빌드할 수 있습니다.
이 모든 것은 1950년대 초 Alan Turning이 컴퓨터가 실제 지능을 가지려면 인간도 인간임을 조작하거나 설득해야 한다고 결론을 내린 튜링 테스트에서 시작되었습니다. 머신 러닝은 비교적 오래된 개념이지만 컴퓨터가 이제 복잡한 알고리즘을 처리할 수 있기 때문에 이 새로운 분야가 실현될 수 있는 것은 오늘날에서야 알 수 있습니다. 머신 러닝 알고리즘은 복잡한 계산 기술을 포함하도록 지난 10년 동안 진화했으며, 이는 차례로 모방 기능의 향상으로 이어졌습니다.
머신 러닝 애플리케이션도 놀라운 속도로 증가했습니다. 의료, 금융, 분석 및 교육에서 제조, 마케팅 및 정부 운영에 이르기까지 모든 산업에서 기계 학습 기술을 구현한 후 품질과 효율성이 크게 향상되었습니다. 전 세계적으로 질적 향상이 광범위하게 진행되어 머신 러닝 전문가에 대한 수요가 증가하고 있습니다.
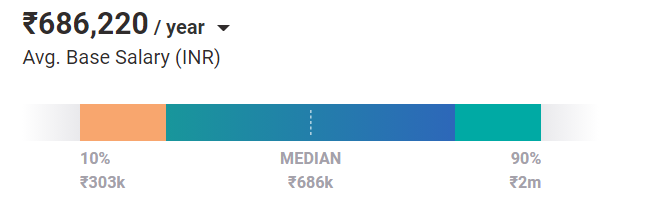
평균적으로 기계 학습 엔지니어의 현재 급여 는 686,220루피입니다. 엔트리 레벨 포지션의 경우도 마찬가지입니다. 경험과 기술을 바탕으로 인도에서 연간 최대 200만 루피를 벌 수 있습니다.
기계 학습 알고리즘의 유형
기계 학습 알고리즘에는 세 가지 유형이 있습니다.
1. 지도 학습(Supervised Learning ): 이 유형의 학습에서 학습 데이터 세트는 정확한 예측이나 분석적 결정을 내리기 위해 알고리즘을 안내합니다. 새로운 데이터를 처리하기 위해 과거 훈련 데이터 세트에서 학습을 사용합니다. 다음은 지도 학습 기계 학습 모델의 몇 가지 예입니다.

- 선형 회귀
- 로지스틱 회귀
- 의사결정나무
2. 비지도 학습 : 이 유형의 학습에서 기계 학습 모델은 레이블이 지정되지 않은 정보에서 학습합니다. 개체를 그룹화하거나 개체 간의 관계를 이해하거나 통계 속성을 활용하여 분석을 수행하여 데이터 클러스터링을 사용합니다. 비지도 학습 알고리즘의 예는 다음과 같습니다.
- K-평균 클러스터링
- 계층적 클러스터링
3. 강화 학습 : 이 프로세스는 히트 및 시도를 기반으로 합니다. 공간이나 환경과 상호작용하면서 배우는 것입니다. RL 알고리즘은 환경과 상호 작용하고 최상의 조치를 결정함으로써 과거 경험에서 학습합니다.
Java로 기계 학습을 구현하는 방법?
Java는 기계 학습 알고리즘을 구현하는 데 사용되는 최고의 프로그래밍 언어 중 하나입니다. 대부분의 라이브러리는 오픈 소스이며 광범위한 문서 지원, 쉬운 유지 관리, 시장성 및 쉬운 가독성을 제공합니다.
인기도에 따라 다음은 Java에서 기계 학습을 구현하는 데 사용되는 상위 10개 기계 학습 라이브러리입니다.
1. 아담스
고급 데이터 마이닝 및 기계 학습 시스템(ADAMS)은 새롭고 유연한 워크플로 시스템을 구축하고 복잡한 실제 프로세스를 관리하는 것과 관련이 있습니다. ADAMS는 수동 입력-출력 연결을 만드는 대신 데이터 흐름을 관리하기 위해 트리와 같은 아키텍처를 사용합니다.
명시적 연결이 필요하지 않습니다. "적을수록 좋다"는 원칙을 기반으로 하며 검색, 시각화 및 데이터 기반 시각화를 수행합니다. ADAMS는 데이터 처리, 데이터 스트리밍, 데이터베이스 관리, 스크립팅 및 문서화에 능숙합니다.
2. 자바ML
JavaML은 소프트웨어 엔지니어, 프로그래머, 데이터 과학자 및 연구원을 지원하기 위해 Java용으로 작성된 다양한 ML 및 데이터 마이닝 알고리즘을 제공합니다. 모든 알고리즘에는 GUI가 없더라도 사용하기 쉽고 광범위한 문서 지원이 있는 공통 인터페이스가 있습니다.
다른 클러스터링 알고리즘과 비교하여 구현하는 것이 다소 간단하고 간단합니다. 핵심 기능에는 데이터 조작, 문서화, 데이터베이스 관리, 데이터 분류, 클러스터링, 기능 선택 등이 있습니다.
세계 최고의 대학(석사, 대학원 대학원 과정, ML 및 AI 고급 인증 프로그램) 의 기계 학습 과정 에 온라인으로 참여 하여 경력을 빠르게 추적하십시오.
3. 위카
Weka는 또한 딥 러닝을 지원하는 Java용으로 작성된 오픈 소스 머신 러닝 라이브러리입니다. 일련의 기계 학습 알고리즘을 제공하고 다른 데이터 작업 중에서 데이터 마이닝, 데이터 준비, 데이터 클러스터링, 데이터 시각화 및 회귀에서 광범위하게 사용됩니다.
예: 우리는 작은 당뇨병 데이터 세트를 사용하여 이것을 시연할 것입니다.
1단계 : Weka를 사용하여 데이터 로드
| weka.core.Instances 가져오기; weka.core.converters.ConverterUtils.DataSource 가져오기; 공개 클래스 메인 { public static void main(String[] args) 예외 발생 { // 데이터 소스 지정 데이터 소스 데이터 소스 = 새로운 데이터 소스("data.arff"); // 데이터셋 불러오기 인스턴스 dataInstances = dataSource.getDataSet(); // 인스턴스 수 표시 log.info("로드된 인스턴스 수: " + dataInstances.numInstances()); log.info("데이터:" + dataInstances.toString()); } } |
2단계: 데이터 세트에는 768개의 인스턴스가 있습니다. 속성 수, 즉 9에 액세스해야 합니다.
| log.info("데이터 세트의 속성(기능) 수: " + dataInstances.numAttributes()); |
3단계 : 모델을 빌드하고 클래스 수를 찾기 전에 대상 열을 결정해야 합니다.
| // 레이블 인덱스 식별 dataInstances.setClassIndex(dataInstances.numAttributes() – 1); // 갯수 구하기 log.info("클래스 수: " + dataInstances.numClasses()); |
4단계 : 이제 간단한 트리 분류기 J48을 사용하여 모델을 빌드합니다.
| // 결정 트리 분류기 생성 J48 treeClassifier = new J48(); treeClassifier.setOptions(새로운 문자열[] { "-U" }); treeClassifier.buildClassifier(dataInstances); |
위의 코드는 모델 훈련에 필요한 데이터 인스턴스로 구성된 정리되지 않은 트리를 만드는 방법을 강조합니다. 모델 교육 후 트리 구조가 인쇄되면 규칙이 내부적으로 어떻게 구축되었는지 확인할 수 있습니다.
| 플라스 <= 127 | 질량 <= 26.4 | | preg <= 7: test_negative(117.0/1.0) | | 임신 > 7 | | | 질량 <= 0: test_positive(2.0) | | | 질량 > 0: test_negative(13.0) | 질량 > 26.4 | | 나이 <= 28: test_negative (180.0/22.0) | | 나이 > 28 | | | plas <= 99: 테스트된_음성(55.0/10.0) | | | 플라스 > 99 | | | | pedi <= 0.56: 테스트됨_음성(84.0/34.0) | | | | 페디 > 0.56 | | | | | 프레그 <= 6 | | | | | | 나이 <= 30: test_positive(4.0) | | | | | | 나이 > 30 | | | | | | | 나이 <= 34: test_negative (7.0/1.0) | | | | | | | 나이 > 34 | | | | | | | | 질량 <= 33.1: test_positive(6.0) | | | | | | | | 질량 > 33.1: test_negative(4.0/1.0) | | | | | preg > 6: test_positive(13.0) 플라스 > 127 | 질량 <= 29.9 | | plas <= 145: 테스트된_음성(41.0/6.0) | | 플라스 > 145 | | | 나이 <= 25: test_negative(4.0) | | | 나이 > 25 | | | | 나이 <= 61 | | | | | 질량 <= 27.1: 테스트된_양성(12.0/1.0) | | | | | 질량 > 27.1 | | | | | | <= 82를 누르십시오.  | | | | | | | pedi <= 0.396: 테스트됨_양성(8.0/1.0) | | | | | | | pedi > 0.396: 테스트됨_음성(3.0) | | | | | | 언론 > 82: 테스트된_음성(4.0) | | | | 나이 > 61: test_negative (4.0) | 질량 > 29.9 | | 플라스 <= 157 | | | 프레스 <= 61: 테스트 포지티브(15.0/1.0) | | | 프레스 > 61 | | | | 나이 <= 30: test_negative (40.0/13.0) | | | | 나이 > 30: 테스트됨_양성(60.0/17.0) | | plas > 157: 테스트됨_양성(92.0/12.0) 잎 수 : 22 나무의 크기 : 43 |
4. 아파치 마하우트
Mahaut는 Java를 사용하여 기계 학습을 구현하는 데 도움이 되는 알고리즘 모음입니다. 개발자가 수학, 통계 분석을 수행할 수 있는 확장 가능한 선형 대수 프레임워크입니다. 일반적으로 데이터 과학자, 연구 엔지니어 및 분석 전문가가 엔터프라이즈 지원 애플리케이션을 구축하는 데 사용합니다. 확장성과 유연성을 통해 사용자는 데이터 클러스터링, 추천 시스템을 구현하고 고성능 머신 러닝 앱을 빠르고 쉽게 만들 수 있습니다.
5. 딥러닝4j
Deeplearning4j는 Java로 작성된 프로그래밍 라이브러리이며 딥 러닝에 대한 광범위한 지원을 제공합니다. 심층 신경망과 심층 강화 학습을 결합하여 비즈니스 운영을 지원하는 오픈 소스 프레임워크입니다. Scala, Kotlin, Apache Spark, Hadoop 및 기타 JVM 언어 및 빅 데이터 컴퓨팅 프레임워크와 호환됩니다.
일반적으로 음성, 음성 및 서면 텍스트의 패턴과 감정을 감지하는 데 사용됩니다. 거래의 불일치를 발견하고 여러 작업을 처리할 수 있는 DIY 도구 역할을 합니다. 오픈 소스 특성으로 인해 자세한 API 문서가 있는 상용 등급의 분산 라이브러리입니다.
다음은 Deeplearning4j를 사용하여 기계 학습을 구현하는 방법의 예입니다.
예 : Deeplearning4j를 사용하여 MNIST 라이브러리의 도움으로 필기 숫자를 분류하는 CNN(Convolution Neural Network) 모델을 구축합니다.
1단계 : 데이터세트를 로드하여 크기를 표시합니다.
| DataSetIterator MNISTTrain = 새로운 MnistDataSetIterator(batchSize,true,seed); DataSetIterator MNISTTest = 새로운 MnistDataSetIterator(batchSize,false,seed); |
2단계 : 데이터세트가 10개의 고유한 레이블을 제공하는지 확인합니다.
| log.info("훈련 데이터 세트에서 발견된 총 레이블 수 " + MNISTTrain.totalOutcomes()); log.info("테스트 데이터 세트에서 찾은 총 레이블 수 " + MNISTTest.totalOutcomes()); |
3단계 : 이제 출력을 표시하기 위해 평평한 레이어와 함께 두 개의 컨볼루션 레이어를 사용하여 모델 아키텍처를 구성합니다.
Deeplearning4j에는 가중치 체계를 초기화할 수 있는 옵션이 있습니다.
| // CNN 모델 구축 MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder() .seed(seed) // 임의의 시드 .l2(0.0005) // 정규화 .weightInit(WeightInit.XAVIER) // 가중치 체계 초기화 .updater(new Adam(1e-3)) // 최적화 알고리즘 설정 .목록() .layer(new ConvolutionLayer.Builder(5, 5) //보폭, 커널 크기 및 활성화 함수를 설정합니다. .nIn(n채널) .스트라이드(1,1) .n아웃(20) .활성화(활성화.IDENTITY) .짓다()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // 컨볼루션 다운샘플링 .kernel크기(2,2) .스트라이드(2,2) .짓다()) .layer(new ConvolutionLayer.Builder(5, 5) // 보폭, 커널 크기, 활성화 함수를 설정합니다. .스트라이드(1,1) .n아웃(50) .활성화(활성화.IDENTITY) .짓다()) .layer(new SubsamplingLayer.Builder(PoolingType.MAX) // 컨볼루션 다운샘플링 .kernel크기(2,2) .스트라이드(2,2) .짓다()) .layer(new DenseLayer.Builder().activation(Activation.RELU) .nOut(500).build()) .layer(새로운 OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD) .nOut(출력 번호) .활성화(활성화.SOFTMAX) .짓다()) // 최종 출력 레이어는 깊이가 1인 28×28입니다. .setInputType(InputType.convolutionalFlat(28,28,1)) .짓다(); |
4단계 : 아키텍처를 구성한 후 모드와 교육 데이터 세트를 초기화하고 모델 교육을 시작합니다.
| MultiLayerNetwork 모델 = 새로운 MultiLayerNetwork(conf); // 모델 가중치를 초기화합니다. model.init(); log.info("2단계: 모델 학습 시작"); // 10회 반복마다 리스너를 설정하고 모든 Epoch에서 테스트 세트를 평가합니다. model.setListeners(new ScoreIterationListener(10), new EvaluativeListener(MNISTTest, 1, InvocationType.EPOCH_END)); // 모델 훈련 model.fit(MNISTTrain, nEpochs); |
모델 훈련이 시작되면 분류 정확도의 혼동 행렬이 생깁니다.
10번의 훈련 에포크 후 모델의 정확도는 다음과 같습니다.
| ======================================================================================== == 0 1 2 3 4 5 6 7 8 9 —————————————————— 977 0 0 0 0 0 1 1 1 0 | 0 = 0 0 1131 0 1 0 1 2 0 0 0 | 1 = 1 1 2 1019 3 0 0 0 3 4 0 | 2 = 2 0 0 1 1004 0 1 0 1 3 0 | 3 = 3 0 0 0 0 977 0 2 0 1 2 | 4 = 4 1 0 0 9 0 879 1 0 1 1 | 5 = 5 4 2 0 0 1 1 949 0 1 0 | 6 = 6 0 4 2 1 1 0 0 1018 1 1 | 7 = 7 2 0 3 1 0 1 1 2 962 2 | 8 = 8 0 2 0 2 11 2 0 3 2 987 | 9 = 9 |
6. 엘키
인덱스 구조 또는 ELKI에서 지원하는 KDD 응용 프로그램 개발을 위한 환경은 데이터 마이닝에 사용되는 기본 제공 알고리즘 및 프로그램 모음입니다. Java로 작성되었으며 알고리즘에서 고도로 구성 가능한 매개변수로 구성된 오픈 소스 라이브러리입니다. 일반적으로 연구 과학자와 학생이 데이터 세트에 대한 통찰력을 얻는 데 사용합니다. 이름에서 알 수 있듯이 인덱스 구조를 사용하여 정교한 데이터 마이닝 프로그램과 데이터베이스를 개발할 수 있는 환경을 제공합니다.
7. 수능
Java Statistical Analysis Tool 또는 JSAT는 객체 지향 프레임워크를 사용하여 사용자가 Java로 기계 학습을 구현할 수 있도록 도와주는 GPL3 라이브러리입니다. 일반적으로 학생과 개발자의 자가 교육 목적으로 사용됩니다. 다른 AI 구현 라이브러리에 비해 JSAT는 ML 알고리즘 수가 가장 많고 모든 프레임워크 중 가장 빠릅니다. 외부 종속성이 없어 매우 유연하고 효율적이며 고성능을 제공합니다.
8. Encog 기계 학습 프레임워크
Encog는 Java 및 C#으로 작성되었으며 기계 학습 알고리즘을 구현하는 데 도움이 되는 라이브러리로 구성됩니다. 유전 알고리즘, 베이지안 네트워크, 은닉 마르코프 모델과 같은 통계 모델 등을 구축하는 데 사용됩니다.
9. 망치
Language Toolkit 또는 Mallet용 기계 학습은 NLP(자연어 처리)에서 사용됩니다. 대부분의 다른 ML 구현 프레임워크와 마찬가지로 Mallet은 데이터 모델링, 데이터 클러스터링, 문서 처리, 문서 분류 등도 지원합니다.
10. 스파크 MLlib
Spark MLlib는 기업에서 워크플로 관리의 효율성과 확장성을 향상시키는 데 사용됩니다. 방대한 양의 데이터를 처리하고 부하가 큰 ML 알고리즘을 지원합니다.
확인: 기계 학습 프로젝트 아이디어
결론
이것은 우리를 기사의 끝으로 이끕니다. 기계 학습 개념에 대한 자세한 내용은 upGrad의 기계 학습 및 AI 과학 석사 프로그램을 통해 IIT Bangalore 및 리버풀 John Moores University의 최고 교수진에게 문의하십시오.
기계 학습과 함께 Java를 사용해야 하는 이유는 무엇입니까?
기계 학습 전문가는 프로젝트의 프로그래밍 언어로 Java를 선택하면 현재 코드 저장소와 더 쉽게 인터페이스할 수 있습니다. 사용 용이성, 패키지 서비스, 더 나은 사용자 상호 작용, 빠른 디버깅 및 데이터의 그래픽 그림과 같은 기능으로 인해 선호되는 기계 학습 언어입니다. Java를 사용하면 Machine Learning 개발자가 시스템을 쉽게 확장할 수 있으므로 처음부터 크고 정교한 Machine Learning 애플리케이션을 구축하는 데 탁월한 선택이 됩니다. JVM(Java Virtual Machine)은 기계 학습자가 새로운 도구를 빠르게 설계할 수 있도록 하는 여러 통합 개발 환경(IDE)을 지원합니다.
자바 배우기가 쉽나요?
Java는 고급 언어이므로 이해하기 쉽습니다. 학습자는 초보자가 이해할 수 있을 만큼 간단하고 잘 구조화된 객체 지향 언어이므로 자세히 설명할 필요가 없습니다. 자동으로 작동하는 절차가 많기 때문에 빠르게 마스터할 수 있습니다. 그곳에서 작동하는 방식에 대해 자세히 설명할 필요는 없습니다. Java는 플랫폼 독립적인 프로그래밍 언어입니다. 이를 통해 프로그래머는 모든 장치에서 사용할 수 있는 모바일 애플리케이션을 만들 수 있습니다. 이는 사물 인터넷이 선호하는 언어일 뿐만 아니라 엔터프라이즈 수준의 응용 프로그램을 개발하기 위한 최고의 도구입니다.
ADAMS는 무엇이며 기계 학습에 어떻게 도움이 됩니까?
ADAMS(Advanced Data Mining And Machine Learning System)는 비즈니스 프로세스에 쉽게 통합될 수 있는 데이터 기반의 반응형 워크플로를 빠르게 생성 및 관리하기 위한 GPLv3 라이선스 워크플로 엔진입니다. 적으면 많을수록 좋다는 원칙을 따르는 워크플로 엔진은 ADAMS의 핵심입니다. ADAMS는 사용자가 캔버스에 운영자(또는 ADAMS 전문 용어로 액터)를 정렬한 다음 입력과 출력을 수동으로 연결할 수 있도록 하는 대신 트리와 같은 구조를 사용합니다. 이 구조와 제어 행위자가 프로세스에서 데이터 흐름 방식을 결정하기 때문에 명시적 연결이 필요하지 않습니다. 연산자 핸들러 내에서 내부 개체 표현과 하위 연산자 중첩으로 인해 트리와 같은 구조가 생성됩니다. ADAMS는 데이터 검색, 처리, 마이닝 및 표시를 위한 다양한 에이전트 세트를 제공합니다.