
Google Assistant 및 Amazon Alexa용 음성 기술 생성
게시 됨: 2022-03-10지난 10년 동안 대화형 인터페이스로의 급격한 변화가 있었습니다. 사람들이 '최대 화면'에 도달하고 심지어 대부분의 운영 체제에 적용된 디지털 웰빙 기능으로 기기 사용을 축소하기 시작합니다.
화면 피로를 방지하기 위해 음성 비서는 시장에 진입하여 정보를 빠르게 검색하는 데 선호되는 옵션이 되었습니다. 반복되는 통계에 따르면 2020년에는 검색의 50%가 음성으로 수행될 것이라고 합니다. 또한 채택이 증가함에 따라 "대화형 인터페이스" 및 "음성 도우미"를 도구 벨트에 추가하는 것은 개발자의 몫입니다.
보이지 않는 것을 디자인하다
많은 사람들에게 VUI(음성 UI) 프로젝트를 시작하는 것은 Unknown에 들어가는 것과 약간 비슷할 수 있습니다. 음성을 디자인할 때 William Merrill이 배운 교훈에 대해 자세히 알아보십시오. 관련 기사 읽기 →
대화형 인터페이스란 무엇입니까?
대화형 인터페이스(CUI로 축약되기도 함)는 인간 언어로 된 모든 인터페이스입니다. 프론트 엔드 개발자가 구축하는 데 익숙한 그래픽 사용자 인터페이스 GUI보다 일반 대중에게 더 자연스러운 인터페이스가 될 것으로 예상됩니다. GUI에는 인간이 필요합니다 인터페이스의 특정 구문을 배우기 위해(버튼, 슬라이더 및 드롭다운을 생각하십시오).
인간 언어 사용의 이러한 주요 차이점은 CUI를 사람들에게 더 자연스럽게 만듭니다. 지식이 거의 필요하지 않으며 장치에 대한 이해의 부담을 줍니다.
일반적으로 CUI는 Chatbot과 Voice Assistant의 두 가지 형태로 제공됩니다. 둘 다 NLP(자연어 처리)의 발전 덕분에 지난 10년 동안 사용이 크게 증가했습니다.
음성 전문 용어 이해

| 예어 | 의미 |
|---|---|
| 스킬/액션 | 일련의 의도를 수행할 수 있는 음성 애플리케이션 |
| 의지 | 스킬이 수행할 의도된 작업, 사용자가 말한 내용에 대한 응답으로 스킬이 수행하기를 원하는 것입니다. |
| 말 | 사용자가 말하거나 발화하는 문장. |
| 웨이크 워드 | 음성 도우미 듣기를 시작하는 데 사용되는 단어 또는 구(예: 'Hey google', 'Alexa' 또는 'Hey Siri') |
| 문맥 | '오늘', '지금', '집에 도착할 때'와 같이 기술이 의도를 충족하는 데 도움이 되는 발화 내의 상황 정보 조각. |
음성 비서란 무엇입니까?
음성 비서는 NLP(자연어 처리)가 가능한 소프트웨어입니다. 음성 명령을 수신하고 오디오 형식으로 응답을 반환합니다. 최근 몇 년 동안 어시스턴트와 소통할 수 있는 방법의 범위가 확장되고 진화하고 있지만 기술의 핵심은 자연어 입력, 많은 계산, 자연어 출력입니다.
조금 더 자세한 내용을 찾는 사람들을 위해:
- 소프트웨어는 사용자로부터 오디오 요청을 수신하고 소리를 언어의 구성 요소인 음소로 처리합니다.
- AI(특히 Speech-To-Text)의 마법으로 이러한 음소는 대략적인 요청의 문자열로 변환되며, 이는 사용자, 요청 및 세션에 대한 추가 정보도 포함하는 JSON 파일 내에 보관됩니다.
- 그런 다음 JSON이 처리되어(일반적으로 클라우드에서) 요청의 컨텍스트와 의도를 파악합니다.
- 의도를 기반으로 더 큰 JSON 응답 내에서 문자열 또는 SSML(나중에 자세히 설명)로 응답이 반환됩니다.
- 응답은 AI(자연스럽게 역-Text-To-Speech)를 사용하여 다시 처리된 다음 사용자에게 반환됩니다.
거기에는 많은 일이 일어나고 있으며 대부분은 다시 생각할 필요가 없습니다. 그러나 플랫폼마다 이 작업을 다르게 수행하며 조금 더 이해가 필요한 것은 플랫폼의 뉘앙스입니다.

음성 지원 장치
음성 비서를 내장할 수 있는 장치에 대한 요구 사항은 상당히 낮습니다. 마이크, 인터넷 연결 및 스피커가 필요합니다. Nest Mini 및 Echo Dot과 같은 스마트 스피커는 이러한 종류의 로우파이 음성 제어를 제공합니다.
다음 순위는 음성 + 화면으로 '다중 모드' 장치(나중에 자세히 설명)로 알려져 있으며 Nest Hub 및 Echo Show와 같은 장치입니다. 스마트폰에는 이러한 기능이 있으므로 일종의 다중 모드 음성 지원 장치로 간주할 수도 있습니다.
보이스 스킬
먼저, 모든 플랫폼은 '음성 기술'에 대해 다른 이름을 가지고 있습니다. Amazon은 기술을 사용합니다. 저는 보편적으로 이해되는 용어로 계속 사용하겠습니다. Google은 '액션'을 선택하고 삼성은 '캡슐'을 선택합니다.
각 플랫폼에는 시간, 날씨 및 스포츠 게임을 묻는 것과 같은 고유한 기본 기술이 있습니다. 개발자가 만든(타사) 기술은 특정 구문으로 호출하거나 플랫폼이 좋아하는 경우 핵심 구문 없이 암시적으로 호출할 수 있습니다.
명시적 호출 : "Hey Google, <앱 이름>과 대화하세요."
어떤 기술이 요구되는지 명시적으로 명시되어 있습니다.
암시적 호출 : "Hey Google, 오늘 날씨는 어떤가요?"
사용자가 원하는 서비스를 요청하는 컨텍스트에 의해 암시됩니다.
어떤 음성 도우미가 있습니까?
서부 시장에서 음성 비서는 세 마리의 말 경주에 가깝습니다. Apple, Google 및 Amazon은 비서에 대한 접근 방식이 매우 다르기 때문에 다양한 유형의 개발자와 고객에게 호소합니다.
애플의 시리
장치 이름 : "Siri"
깨우기 구문 : "Hey Siri"
Siri는 3억 7,500만 명이 넘는 활성 사용자를 보유하고 있지만 간결함을 위해 Siri에 대해 너무 자세히 설명하지는 않겠습니다. 전 세계적으로 잘 채택되고 대부분의 Apple 기기에 적용되지만, 개발자는 이미 Apple 플랫폼 중 하나에 앱이 있어야 하고 swift로 작성되어야 합니다(반면 나머지는 모두가 좋아하는 Javascript로 작성할 수 있음). 앱의 제공을 확장하려는 앱 개발자가 아닌 한 현재 Apple이 플랫폼을 열 때까지 과거를 건너뛸 수 있습니다.
구글 어시스턴트
기기명 : '구글 홈, 네스트'
깨우기 문구 : "Hey Google"
Google은 전 세계적으로 10억 개 이상의 기기를 보유하고 있는 3대 기기 중 가장 많은 기기를 보유하고 있습니다. 이는 주로 Google Assistant가 내장된 Android 기기의 대량 때문이며 전용 스마트 스피커와 관련하여 숫자는 약간 적습니다. 어시스턴트를 통한 Google의 전반적인 임무는 사용자를 즐겁게 하는 것이며 항상 가볍고 직관적인 인터페이스를 제공하는 데 매우 능숙합니다.
플랫폼에서 그들의 주요 목표는 시간을 사용하는 것입니다. 고객의 일상적인 일상의 일부가 된다는 아이디어입니다. 따라서 그들은 주로 유용성, 가족의 즐거움 및 즐거운 경험에 중점을 둡니다.
Google을 위해 구축된 기술은 주로 가족 친화적인 재미에 중점을 둔 참여 작품과 게임일 때 가장 좋습니다. 최근 게임용 캔버스를 추가한 것은 이러한 접근 방식에 대한 증거입니다. Google 플랫폼은 기술 제출에 대해 훨씬 더 엄격하므로 해당 디렉토리가 훨씬 작습니다.
아마존 알렉사
장치 이름 : "Amazon Fire, Amazon Echo"
깨우기 문구 : "Alexa"
Amazon은 2019년에 1억 대의 기기를 넘어섰으며, 이는 주로 스마트 스피커와 스마트 디스플레이, '화재' 제품 또는 태블릿 및 스트리밍 기기 판매에서 비롯됩니다.
Amazon을 위해 구축된 기술은 기술 구매를 목표로 하는 경향이 있습니다. 전자 상거래/서비스를 확장하거나 구독을 제공할 플랫폼을 찾고 있다면 Amazon이 적합합니다. 즉, ISP는 Alexa Skills의 요구 사항이 아니며 모든 종류의 사용을 지원하며 제출에 훨씬 더 개방적입니다.
다른 사람
삼성의 빅스비(Bixby), 마이크로소프트의 코타나(Cortana), 인기 있는 오픈 소스 음성 비서인 마이크로프트(Mycroft)와 같은 훨씬 더 많은 음성 비서가 있습니다. 세 가지 모두 합리적인 추종자를 가지고 있지만 아마존, 구글, 애플의 세 골리앗에 비하면 여전히 소수에 불과하다.
Amazon Alexa 기반 구축
음성용 Amazons 에코시스템은 개발자가 Alexa 콘솔 내에서 모든 기술을 구축할 수 있도록 진화했으므로 간단한 예를 들어 내장 기능을 사용하겠습니다.
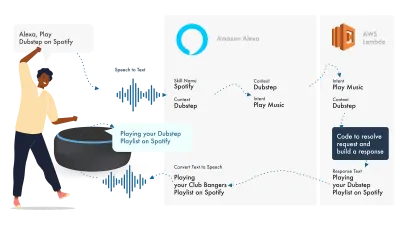
Alexa는 자연어 처리(Natural Language Processing)를 처리한 다음 적절한 인텐트를 찾고, 이는 로직을 처리하기 위해 Lambda 함수에 전달됩니다. 이렇게 하면 일부 대화 비트(SSML, 텍스트, 카드 등)가 Alexa에 반환되고, Alexa는 이러한 비트를 오디오 및 영상으로 변환하여 장치에 표시합니다.
Amazon에서 작업하는 것은 Alexa Developer Console 내에서 기술의 모든 부분을 생성할 수 있기 때문에 비교적 간단합니다. AWS 또는 HTTPS 엔드포인트를 사용할 수 있는 유연성이 있지만 간단한 기술의 경우 Dev 콘솔 내에서 모든 것을 실행하는 것으로 충분해야 합니다.
간단한 Alexa 기술을 만들어 봅시다.
Amazon Alexa 콘솔로 이동하여 계정이 없으면 생성하고 로그인합니다.
Create Skill 를 클릭한 다음 이름을 지정하고,
custom 를 모델로 선택하고,
백엔드 리소스로 Alexa-Hosted (Node.js) 를 선택합니다.
프로비저닝이 완료되면 기본 Alexa 기술이 제공되며, 사용자를 위해 구축된 의도와 시작하기 위한 일부 백엔드 코드가 제공됩니다.
Intents에서 HelloWorldIntent 를 클릭하면 이미 설정되어 있는 몇 가지 샘플 발화를 볼 수 있습니다. 맨 위에 새 발화를 추가하겠습니다. 우리의 스킬을 hello world라고 하므로 Hello World를 샘플 발화로 추가합니다. 아이디어는 사용자가 이 의도를 트리거하기 위해 말할 수 있는 모든 것을 캡처하는 것입니다. "Hi World", "Howdy World" 등이 될 수 있습니다.
Fulfillment JS에서 무슨 일이 일어나고 있습니까?
코드는 무엇을 하고 있습니까? 기본 코드는 다음과 같습니다.
const HelloWorldIntentHandler = { canHandle(handlerInput) { return Alexa.getRequestType(handlerInput.requestEnvelope) === 'IntentRequest' && Alexa.getIntentName(handlerInput.requestEnvelope) === 'HelloWorldIntent'; }, handle(handlerInput) { const speakOutput = 'Hello World!'; return handlerInput.responseBuilder .speak(speakOutput) .getResponse(); } }; 이것은 ask-sdk-core 를 활용하고 있으며 본질적으로 우리를 위해 JSON을 구축하고 있습니다. canHandle 은 인텐트, 특히 'HelloWorldIntent'를 처리할 수 있음을 Ask에 알립니다. handle 은 입력을 받아 응답을 빌드합니다. 이것이 생성하는 것은 다음과 같습니다.
{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }
우리는 speak 가 json에서 ssml을 출력하는 것을 볼 수 있습니다. 이것은 Alexa가 말한 대로 사용자가 듣게 될 것입니다.

Google 어시스턴트용 빌드
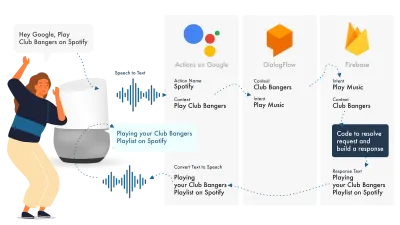
Actions on Google을 구축하는 가장 간단한 방법은 AoG 콘솔을 Dialogflow와 함께 사용하는 것입니다. Firebase로 기술을 확장할 수 있지만 Amazon Alexa 자습서와 마찬가지로 간단하게 유지하겠습니다.
Google Assistant는 NLP를 처리하는 AoG, 의도를 처리하는 Dialogflow, 요청을 이행하고 AoG로 다시 보낼 응답을 생성하는 Firebase의 세 가지 기본 부분을 사용합니다.
Alexa와 마찬가지로 Dialogflow를 사용하면 플랫폼 내에서 직접 기능을 빌드할 수 있습니다.
Google에서 액션을 만들어 봅시다.
세 가지 다른 콘솔에서 액세스할 수 있는 Google 솔루션으로 한 번에 세 가지 플랫폼을 사용할 수 있으므로 탭하세요!
Dialogflow 설정
Dialogflow 콘솔에 로그인하여 시작하겠습니다. 로그인한 후 Dialogflow 로고 바로 아래의 드롭다운에서 새 에이전트를 만듭니다.
에이전트에 이름을 지정하고 '새 Google 프로젝트 만들기'를 선택한 상태에서 'Google 프로젝트 드롭다운'에 추가합니다.
만들기 버튼을 클릭하고 마법을 부리게 하십시오. 에이전트를 설정하는 데 약간의 시간이 걸리므로 인내심을 가지십시오.
Firebase 기능 설정
자, 이제 Fulfillment 로직을 연결할 수 있습니다.
Fulfillment 탭으로 이동합니다. 인라인 편집기를 활성화하려면 체크하고 아래의 JS 스니펫을 사용하세요.
index.js
'use strict'; // So that you have access to the dialogflow and conversation object const { dialogflow } = require('actions-on-google'); // So you have access to the request response stuff >> functions.https.onRequest(app) const functions = require('firebase-functions'); // Create an instance of dialogflow for your app const app = dialogflow({debug: true}); // Build an intent to be fulfilled by firebase, // the name is the name of the intent that dialogflow passes over app.intent('Default Welcome Intent', (conv) => { // Any extra logic goes here for the intent, before returning a response for firebase to deal with return conv.ask(`Welcome to a firebase fulfillment`); }); // Finally we export as dialogflowFirebaseFulfillment so the inline editor knows to use it exports.dialogflowFirebaseFulfillment = functions.https.onRequest(app);패키지.json
{ "name": "functions", "description": "Cloud Functions for Firebase", "scripts": { "lint": "eslint .", "serve": "firebase serve --only functions", "shell": "firebase functions:shell", "start": "npm run shell", "deploy": "firebase deploy --only functions", "logs": "firebase functions:log" }, "engines": { "node": "10" }, "dependencies": { "actions-on-google": "^2.12.0", "firebase-admin": "~7.0.0", "firebase-functions": "^3.3.0" }, "devDependencies": { "eslint": "^5.12.0", "eslint-plugin-promise": "^4.0.1", "firebase-functions-test": "^0.1.6" }, "private": true }이제 의도로 돌아가서 기본 시작 의도로 이동하여 이행까지 아래로 스크롤하고 자바스크립트로 이행하려는 의도에 대해 '이 의도에 대해 웹훅 호출 활성화'가 선택되어 있는지 확인합니다. 저장을 누르십시오.
AoG 설정
이제 결승선에 가까워지고 있습니다. 통합 탭으로 이동하여 상단의 Google 어시스턴트 옵션에서 통합 설정을 클릭합니다. 그러면 모달이 열리므로 테스트를 클릭하여 Dialogflow를 Google과 통합하고 Actions on Google에서 테스트 창을 엽니다.
테스트 창에서 Talk to my test app(우리는 이것을 잠시 후에 변경할 것입니다)을 클릭할 수 있습니다. 짜잔, 우리는 Google 어시스턴트 테스트에 표시되는 자바스크립트의 메시지를 가지고 있습니다.
상단의 개발 탭에서 어시스턴트의 이름을 변경할 수 있습니다.
Fulfillment JS에서 무슨 일이 일어나고 있습니까?
먼저, AoG와 Dialogflow 모두에 필요한 모든 이행을 제공하는 actions-on-google의 두 가지 npm 패키지를 사용하고 있습니다.
그런 다음 모든 의도를 포함하는 객체인 '앱'을 만듭니다.
생성된 각 인텐트는 Actions On Google에서 보내는 대화 개체인 'conv'를 전달합니다. 우리는 conv의 콘텐츠를 사용하여 사용자와의 이전 상호 작용에 대한 정보(예: ID 및 세션에 대한 정보)를 감지할 수 있습니다.
사용자에 대한 반환 메시지가 포함된 'conv.ask 개체'를 반환하여 사용자가 다른 의도로 응답할 수 있도록 합니다. 대화를 끝내고 싶다면 'conv.close'를 사용하여 대화를 끝낼 수 있습니다.
마지막으로 서버 측 요청-응답 로직을 처리하는 Firebase HTTPS 기능으로 모든 것을 마무리합니다.
다시 생성된 응답을 보면 다음과 같습니다.
{ "payload": { "google": { "expectUserResponse": true, "richResponse": { "items": [ { "simpleResponse": { "textToSpeech": "Welcome to a firebase fulfillment" } } ] } } } } conv.ask 의 텍스트가 textToSpeech 영역에 삽입되었음을 알 수 있습니다. conv.close 를 선택하면 expectUserResponse 가 false 로 설정되고 메시지가 전달된 후 대화가 닫힙니다.
타사 음성 빌더
앱 업계와 마찬가지로 음성이 인기를 얻으면서 개발자의 부담을 줄이기 위해 타사 도구가 등장하기 시작하여 개발자가 한 번 구축하면 두 번 배포할 수 있습니다.
Jovo와 Voiceflow는 특히 Apple이 PullString을 인수한 이후 가장 인기 있는 두 가지입니다. 각 플랫폼은 서로 다른 수준의 추상화를 제공하므로 인터페이스가 얼마나 단순화되었는지에 달려 있습니다.
기술 확장
이제 기본 'Hello World' 기술을 구축하는 데 머리를 맞췄으므로 기술에 추가할 수 있는 다양한 기능이 있습니다. 이들은 Voice Assistant 케이크 위에 있는 체리이며 사용자에게 많은 추가 가치를 제공하여 반복적인 사용자 지정 및 잠재적인 상업적 기회로 이어집니다.
SSML
SSML은 음성 합성 마크업 언어를 나타내며 HTML과 유사한 구문으로 작동합니다. 주요 차이점은 웹 페이지의 콘텐츠가 아니라 음성 응답을 구축한다는 것입니다.
'SSML'이라는 용어는 약간 오해의 소지가 있습니다. 음성 합성보다 훨씬 더 많은 일을 할 수 있습니다! 음성을 병렬로 사용할 수 있고, 분위기 소음, Speechcon(그 자체로 들을 가치가 있고, 유명한 문구에 대한 이모티콘을 생각할 가치가 있음) 및 음악을 포함할 수 있습니다.
언제 SSML을 사용해야 합니까?
SSML은 훌륭합니다. 사용자에게 훨씬 더 매력적인 경험을 제공하지만 오디오 출력의 유연성도 감소합니다. 더 정적 인 연설 영역에 사용하는 것이 좋습니다. 이름 등에 변수를 사용할 수 있지만 SSML 생성기를 구축하려는 경우가 아니면 대부분의 SSML은 상당히 정적일 것입니다.
기술에서 간단한 말하기로 시작하고 완료되면 SSML로 더 정적인 영역을 향상하지만 종소리와 휘파람으로 이동하기 직전에 핵심을 얻으십시오. 하지만 최근 보고서에 따르면 사용자의 71%는 합성된 음성보다 사람의(실제) 음성을 선호하므로 그렇게 할 수 있는 시설이 있다면 나가서 사용하십시오!

스킬 구매 시
기술 내 구매(또는 ISP)는 앱 내 구매의 개념과 유사합니다. 기술은 무료인 경향이 있지만 일부는 앱 내에서 '프리미엄' 콘텐츠/구독을 구매할 수 있도록 하며 사용자의 경험을 향상시키거나 게임의 새로운 수준을 잠금 해제하거나 유료 콘텐츠에 대한 액세스를 허용할 수 있습니다.
멀티모달
다중 모드 응답은 음성보다 훨씬 더 많은 것을 다루며, 여기에서 음성 비서가 지원하는 장치에서 보완적인 시각 효과로 실제로 빛을 발할 수 있습니다. 다중 모드 경험의 정의는 훨씬 더 광범위하며 본질적으로 다중 입력(키보드, 마우스, 터치스크린, 음성 등)을 의미합니다.
다중 모드 기술은 핵심 음성 경험을 보완하기 위한 것이며 UX를 향상시키기 위한 추가 보완 정보를 제공합니다. 다중 모드 경험을 구축할 때 음성이 정보의 주요 전달자임을 기억하십시오. 많은 장치에 화면이 없으므로 기술은 여전히 화면 없이 작동해야 하므로 여러 장치 유형으로 테스트해야 합니다. 실제 또는 시뮬레이터에서.

다국어
다국어 기술은 여러 언어로 작동하고 기술을 여러 시장에 개방하는 기술입니다.
기술을 다국어로 만드는 복잡성은 응답이 얼마나 역동적인지에 달려 있습니다. 매번 같은 문구를 반환하거나 작은 양동이의 문구만 사용하는 것과 같이 상대적으로 정적 응답이 있는 기술은 광범위한 동적 기술보다 다국어를 만드는 것이 훨씬 쉽습니다.
다국어 사용의 비결은 대행사를 통하든 Fiverr의 번역가를 통하든 신뢰할 수 있는 번역 파트너를 확보하는 것입니다. 특히 번역되는 언어를 이해하지 못하는 경우 제공된 번역을 신뢰할 수 있어야 합니다. Google 번역은 여기에서 겨자를 자르지 않습니다!
결론
음성 산업에 뛰어들 때가 있었다면 지금이었을 것입니다. 전성기 및 초기 단계와 빅 9 모두에서 수십억 달러를 투자하여 성장시키고 음성 비서를 모든 사람의 가정과 일상에 도입하고 있습니다.
사용할 플랫폼을 선택하는 것은 까다로울 수 있지만 구축하려는 대상에 따라 사용할 플랫폼이 빛을 발해야 하며, 그렇지 않은 경우 타사 도구를 활용하여 베팅을 헤지하고 여러 플랫폼에서 구축해야 합니다. 움직이는 부품이 적어 덜 복잡합니다.
나는 음성이 유비쿼터스화됨에 따라 음성의 미래에 대해 흥분합니다. 화면 의존도가 줄어들고 고객은 비서와 자연스럽게 상호 작용할 수 있습니다. 그러나 먼저 사람들이 조수에게서 원하는 기술을 구축하는 것은 우리에게 달려 있습니다.