
TypeScript 제네릭 이해
게시 됨: 2022-03-10이 기사에서는 TypeScript에서 Generics의 개념을 배우고 Generics를 사용하여 모듈식, 분리형 및 재사용 가능한 코드를 작성하는 방법을 살펴보겠습니다. 그 과정에서 더 나은 테스트 패턴, 오류 처리에 대한 접근 방식 및 도메인/데이터 액세스 분리에 어떻게 적용되는지 간략하게 논의할 것입니다.
실제 사례
Generics가 무엇 인지 설명하기보다는 Generics가 왜 유용한지에 대한 직관적인 예를 제공함으로써 Generics의 세계로 들어가고 싶습니다. 기능이 풍부한 동적 목록을 작성하는 임무를 받았다고 가정합니다. 언어 배경에 따라 배열, ArrayList , List , std::vector 또는 무엇이든 부를 수 있습니다. 아마도 이 데이터 구조에는 내장 또는 교체 가능한 버퍼 시스템도 있어야 합니다(예: 순환 버퍼 삽입 옵션). 일반 배열 대신 구조로 작업할 수 있도록 일반 JavaScript 배열을 감싸는 래퍼가 됩니다.
직면하게 될 즉각적인 문제는 유형 시스템에 의해 부과되는 제약 조건입니다. 이 시점에서 당신은 당신이 원하는 어떤 타입도 함수나 메소드에 아주 깔끔한 방식으로 받아들일 수 없습니다(이 문장은 나중에 다시 다루겠습니다).
유일한 확실한 해결책은 모든 다른 유형에 대한 데이터 구조를 복제하는 것입니다.
const intList = IntegerList.create(); intList.add(4); const stringList = StringList.create(); stringList.add('hello'); const userList = UserList.create(); userList.add(new User('Jamie')); 여기에서 .create() 구문은 임의적으로 보일 수 있으며 실제로 newSomethingList( new SomethingList() 가 더 간단하지만 나중에 이 정적 팩토리 메서드를 사용하는 이유를 알게 될 것입니다. 내부적으로 create 메소드는 생성자를 호출합니다.
이것은 끔찍합니다. 이 컬렉션 구조에는 많은 논리가 있으며 다양한 사용 사례를 지원하기 위해 이를 노골적으로 복제하여 프로세스에서 DRY 원칙을 완전히 깨고 있습니다. 구현을 변경하기로 결정하면 위의 후자의 예에서와 같이 사용자 정의 유형을 포함하여 지원하는 모든 구조 및 유형에 이러한 변경 사항을 수동으로 전파/반영해야 합니다. 컬렉션 구조 자체의 길이가 100줄이라고 가정합니다. 여러 구현을 유지하는 것은 악몽일 것입니다. 구현 간의 유일한 차이점은 유형뿐입니다.
특히 OOP 사고 방식을 가지고 있는 경우 마음에 떠오르는 즉각적인 해결책은 원할 경우 루트 "수퍼타입"을 고려하는 것입니다. 예를 들어 C#에는 object 라는 이름으로 형식이 구성되어 있으며 object 는 System.Object 클래스의 별칭입니다. C#의 유형 시스템에서 모든 유형은 사전 정의되거나 사용자 정의되고 참조 유형 또는 값 유형이든지 System.Object 에서 직접 또는 간접적으로 상속됩니다. 이것은 어떤 값도 object 유형의 변수에 할당될 수 있음을 의미합니다(스택/힙 및 boxing/unboxing 의미 체계에 들어가지 않고).
이 경우 문제가 해결된 것으로 보입니다. 우리는 any 것과 같은 유형을 사용할 수 있으며 구조를 복제하지 않고도 컬렉션 내에 원하는 모든 것을 저장할 수 있으며 실제로 매우 그렇습니다.
const intList = AnyList.create(); intList.add(4); const stringList = AnyList.create(); stringList.add('hello'); const userList = AnyList.create(); userList.add(new User('Jamie')); any 를 사용하여 목록의 실제 구현을 살펴보겠습니다.
class AnyList { private values: any[] = []; private constructor (values: any[]) { this.values = values; // Some more construction work. } public add(value: any): void { this.values.push(value); } public where(predicate: (value: any) => boolean): AnyList { return AnyList.from(this.values.filter(predicate)); } public select(selector: (value: any) => any): AnyList { return AnyList.from(this.values.map(selector)); } public toArray(): any[] { return this.values; } public static from(values: any[]): AnyList { // Perhaps we perform some logic here. // ... return new AnyList(values); } public static create(values?: any[]): AnyList { return new AnyList(values ?? []); } // Other collection functions. // ... }모든 방법은 비교적 간단하지만 생성자부터 시작하겠습니다. 목록이 복잡하고 임의 구성을 허용하지 않기를 원하기 때문에 가시성은 비공개입니다. 우리는 또한 생성 전에 로직을 수행하기를 원할 수 있으므로 이러한 이유로 생성자를 순수하게 유지하기 위해 이러한 문제를 정적 팩토리/헬퍼 메소드에 위임합니다. 이는 모범 사례로 간주됩니다.
from 및 create 의 정적 메서드가 제공됩니다. from 메서드는 값 배열을 수락하고 사용자 지정 논리를 수행한 다음 이를 사용하여 목록을 구성합니다. create static 메소드는 초기 데이터로 목록을 시드하려는 경우에 대한 선택적 값 배열을 사용합니다. "nullish coalescing operator"( ?? )는 제공되지 않은 경우 빈 배열로 목록을 구성하는 데 사용됩니다. 피연산자의 왼쪽이 null 또는 undefined 인 경우 오른쪽으로 대체합니다. 이 경우 values 은 선택 사항이므로 undefined 일 수 있습니다. 관련 TypeScript 문서 페이지에서 nullish 병합에 대해 자세히 알아볼 수 있습니다.
또한 select 및 where 메소드를 추가했습니다. 이 메서드는 JavaScript의 map 과 filter 각각 래핑합니다. select 를 사용하면 제공된 선택기 기능을 기반으로 요소 배열을 새 형식으로 투영할 수 있으며, where 제공된 술어 기능을 기반으로 특정 요소를 필터링할 수 있습니다. toArray 메서드는 내부적으로 보유하고 있는 배열 참조를 반환하여 단순히 목록을 배열로 변환합니다.
마지막으로 User 클래스에 이름을 반환하고 이름을 첫 번째이자 유일한 생성자 인수로 받아들이는 getName 메서드가 포함되어 있다고 가정합니다.
참고: 일부 독자는 C#의 LINQ에서Where및Select를 인식할 수 있지만 저는 이것을 단순하게 유지하려고 하므로 게으름이나 지연된 실행에 대해 걱정하지 않습니다. 실생활에서 할 수 있고 해야 하는 최적화입니다.
또한 흥미로운 메모로 "술어"의 의미에 대해 논의하고 싶습니다. 이산 수학 및 명제 논리학에서는 "명제"라는 개념이 있습니다. 명제는 "4는 2로 나눌 수 있다"와 같이 참 또는 거짓으로 간주될 수 있는 일부 진술입니다. "술어"는 하나 이상의 변수를 포함하는 명제이므로 명제의 진실성은 이러한 변수의 진실성에 달려 있습니다.P(x) = x is divisible by two것과 같은 함수처럼 생각할 수 있습니다. 왜냐하면 문이 참인지 거짓인지 결정하기 위해x의 값을 알아야 하기 때문입니다. 여기에서 술어 논리에 대해 자세히 알아볼 수 있습니다.
any 를 사용하면 몇 가지 문제가 발생합니다. TypeScript 컴파일러는 목록/내부 배열 내부의 요소에 대해 아무것도 알지 못하므로 where 또는 select 또는 요소를 추가할 때 내부에 도움을 제공하지 않습니다.
// Providing seed data. const userList = AnyList.create([new User('Jamie')]); // This is fine and expected. userList.add(new User('Tom')); userList.add(new User('Alice')); // This is an acceptable input to the TS Compiler, // but it's not what we want. We'll definitely // be surprised later to find strings in a list // of users. userList.add('Hello, World!'); // Also acceptable. We have a large tuple // at this point rather than a homogeneous array. userList.add(0); // This compiles just fine despite the spelling mistake (extra 's'): // The type of `users` is any. const users = userList.where(user => user.getNames() === 'Jamie'); // Property `ssn` doesn't even exist on a `user`, yet it compiles. users.toArray()[0].ssn = '000000000'; // `usersWithId` is, again, just `any`. const usersWithId = userList.select(user => ({ id: newUuid(), name: user.getName() })); // Oops, it's "id" not "ID", but TS doesn't help us. // We compile just fine. console.log(usersWithId.toArray()[0].ID); TypeScript는 모든 배열 요소의 유형이 any 라는 것만 알고 있기 때문에 존재하지 않는 속성이나 존재하지도 않는 getNames 함수를 사용하여 컴파일 타임에 도움이 되지 않습니다. 따라서 이 코드는 여러 예기치 않은 런타임 오류를 초래할 것입니다. .
솔직히 말해서 상황이 상당히 암담해 보이기 시작합니다. 우리는 지원하고자 하는 각각의 구체적인 유형에 대한 데이터 구조를 구현하려고 시도했지만 어떤 식으로든 유지 관리할 수 없다는 것을 빨리 깨달았습니다. 그런 다음 우리는 모든 유형이 파생되는 상속 체인의 루트 상위 유형에 의존하는 것과 유사한 any 를 사용하여 어딘가에 도달하고 있다고 생각했지만 해당 방법으로 유형 안전성을 상실한다는 결론을 내렸습니다. 해결책은 무엇입니까?
기사 시작 부분에서 내가 거짓말을 한 것으로 밝혀졌습니다.
"이 시점에서 원하는 모든 유형을 함수나 메서드에 깔끔하게 받아들일 수 없습니다."
당신은 실제로 할 수 있고 그것이 Generics가 들어오는 곳입니다. 내가 "이 시점에서"라고 말했음을 주목하십시오. 왜냐하면 나는 우리가 기사의 그 시점에서 Generics에 대해 알지 못한다고 가정했기 때문입니다.
Generics를 사용하여 List 구조의 전체 구현을 보여 주는 것으로 시작한 다음, 한 걸음 물러서서 Generics가 실제로 무엇인지 논의하고 구문을 보다 형식적으로 결정하겠습니다. 이전 AnyList 와 구별하기 위해 TypedList 라는 이름을 지정했습니다.
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T): void { this.values.push(value); } public where(predicate: (value: T) => boolean): TypedList<T> { return TypedList.from<T>(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U): TypedList<U> { return TypedList.from<U>(this.values.map(selector)); } public toArray(): T[] { return this.values; } public static from<U>(values: U[]): TypedList<U> { // Perhaps we perform some logic here. // ... return new TypedList<U>(values); } public static create<U>(values?: U[]): TypedList<U> { return new TypedList<U>(values ?? []); } // Other collection functions. // .. }다시 한 번 이전과 같은 실수를 시도해 보겠습니다.
// Here's the magic. `TypedList` will operate on objects // of type `User` due to the `<User>` syntax. const userList = TypedList.create<User>([new User('Jamie')]); // The compiler expects this. userList.add(new User('Tom')); userList.add(new User('Alice')); // Argument of type '0' is not assignable to parameter // of type 'User'. ts(2345) userList.add(0); // Property 'getNames' does not exist on type 'User'. // Did you mean 'getName'? ts(2551) // Note: TypeScript infers the type of `users` to be // `TypedList<User>` const users = userList.where(user => user.getNames() === 'Jamie'); // Property 'ssn' does not exist on type 'User'. ts(2339) users.toArray()[0].ssn = '000000000'; // TypeScript infers `usersWithId` to be of type // `TypedList<`{ id: string, name: string }> const usersWithId = userList.select(user => ({ id: newUuid(), name: user.getName() })); // Property 'ID' does not exist on type '{ id: string; name: string; }'. // Did you mean 'id'? ts(2551) console.log(usersWithId.toArray()[0].ID)보시다시피 TypeScript 컴파일러는 형식 안전성을 적극적으로 지원하고 있습니다. 이러한 모든 주석은 이 코드를 컴파일하려고 할 때 컴파일러에서 받는 오류입니다. 제네릭을 사용하면 목록이 작동하도록 허용하려는 유형을 지정할 수 있으며, 그로부터 TypeScript는 배열 내의 개별 객체 속성에 이르기까지 모든 유형을 말할 수 있습니다.
우리가 제공하는 유형은 원하는 만큼 간단하거나 복잡할 수 있습니다. 여기에서 기본 인터페이스와 복잡한 인터페이스를 모두 전달할 수 있음을 알 수 있습니다. 우리는 또한 다른 배열이나 클래스, 또는 무엇이든 전달할 수 있습니다:
const numberList = TypedList.create<number>(); numberList.add(4); const stringList = TypedList.create<string>(); stringList.add('Hello, World'); // Example of a complex type interface IAircraft { apuStatus: ApuStatus; inboardOneRPM: number; altimeter: number; tcasAlert: boolean; pushBackAndStart(): Promise<void>; ilsCaptureGlidescope(): boolean; getFuelStats(): IFuelStats; getTCASHistory(): ITCASHistory; } const aircraftList = TypedList.create<IAircraft>(); aircraftList.add(/* ... */); // Aggregate and generate report: const stats = aircraftList.select(a => ({ ...a.getFuelStats(), ...a.getTCASHistory() })); TypedList<T> 구현에서 T 와 U , <T> 와 <U> 의 독특한 사용은 제네릭이 작동하는 예입니다. 형식이 안전한 컬렉션 구조를 구성하라는 지침을 수행한 후 지금은 이 예제를 뒤로 하고 Generics가 실제로 무엇인지, 어떻게 작동하는지, 구문을 이해하면 이 예제로 돌아갑니다. 나는 새로운 개념을 배울 때 항상 사용 중인 개념의 복잡한 예를 보는 것부터 시작하는 것을 좋아합니다. 그래서 기초를 배우기 시작할 때 기본 주제와 내 책에 있는 기존 예를 연결할 수 있습니다. 머리.
제네릭이란 무엇입니까?
제네릭을 이해하는 간단한 방법은 제네릭을 플레이스홀더나 변수와 비교적 유사하지만 유형에 대해 고려하는 것입니다. 제네릭 형식 자리 표시자에 대해 변수와 동일한 작업을 수행할 수 있다는 것은 아니지만 제네릭 형식 변수는 미래에 사용될 구체적인 형식을 나타내는 자리 표시자로 생각할 수 있습니다. 즉, Generics를 사용하는 것은 나중에 지정해야 할 유형으로 프로그램을 작성하는 방법입니다. 이것이 유용한 이유는 작동하는 다양한 유형(또는 유형에 구애받지 않음)에서 재사용 가능한 데이터 구조를 구축할 수 있기 때문입니다.
그것은 특히 최고의 설명이 아니므로 보다 간단한 용어로 설명하자면 우리가 보았듯이 프로그래밍에서 특정 유형에서 작동하는 함수/클래스/데이터 구조를 빌드해야 할 수도 있지만 일반적입니다. 이러한 데이터 구조는 다양한 유형에서도 작동해야 하는 것이 일반적입니다. 데이터 구조를 설계할 때(컴파일 시간에) 데이터 구조가 작동할 구체적인 유형을 정적으로 선언해야 하는 위치에 갇힌 경우 해당 유형을 다시 빌드해야 함을 매우 빨리 찾을 수 있습니다. 위의 예에서 보았듯이 지원하고자 하는 모든 유형에 대해 거의 정확히 동일한 방식으로 구조를 제공합니다.
Generics는 실제로 알려질 때까지 구체적인 유형에 대한 요구 사항을 연기할 수 있도록 하여 이 문제를 해결하는 데 도움이 됩니다.
TypeScript의 제네릭
이제 Generics가 유용한 이유에 대해 어느 정도 유기적인 아이디어를 얻었고 실제로 약간 복잡한 예를 보았습니다. 대부분의 경우 TypedList<T> 구현은 특히 정적으로 유형이 지정된 언어 배경에서 온 경우 이미 많은 의미가 있을 수 있지만 처음 배울 때 개념을 이해하는 데 어려움을 겪었던 기억이 있습니다. 간단한 기능으로 시작하여 해당 예제를 구축하십시오. 소프트웨어에서 추상화와 관련된 개념은 내부화하기가 매우 어려울 수 있습니다. 따라서 Generics의 개념이 아직 제대로 이해되지 않았다면 완전히 문제가 되지 않으며, 이 기사를 마칠 때쯤이면 그 아이디어가 적어도 어느 정도 직관적일 수 있기를 바랍니다.
이 예제를 이해할 수 있도록 빌드하기 위해 간단한 함수부터 시작해 보겠습니다. TypeScript 문서 자체를 포함하여 대부분의 기사에서 즐겨 사용하는 "Identity Function"부터 시작하겠습니다.
수학에서 "식별 함수"는 f(x) = x 와 같이 입력을 출력에 직접 매핑하는 함수입니다. 당신이 넣은 것이 당신이 나가는 것입니다. JavaScript에서 다음과 같이 나타낼 수 있습니다.
function identity(input) { return input; }또는 더 간결하게:
const identity = input => input; 이것을 TypeScript로 이식하려고 하면 이전에 본 것과 동일한 유형 시스템 문제가 다시 나타납니다. 해결책은 거의 좋은 생각이 아닌 것으로 알려진 any 로 입력하거나 각 유형에 대한 함수를 복제/오버로드(DRY 중단)하거나 Generics를 사용하는 것입니다.
후자의 옵션을 사용하면 다음과 같이 함수를 나타낼 수 있습니다.
// ES5 Function function identity<T>(input: T): T { return input; } // Arrow Function const identity = <T>(input: T): T => input; console.log(identity<number>(5)); // 5 console.log(identity<string>('hello')); // hello 여기서 <T> 구문은 이 함수를 일반으로 선언합니다. 함수를 사용하여 인수 목록에 임의의 입력 매개변수를 전달할 수 있는 것처럼 일반 함수를 사용하여 임의의 유형 매개변수도 전달할 수 있습니다.
identity<T>(input: T): T 및 <T>(input: T): T 서명의 <T> 부분은 두 경우 모두 해당 함수가 T 라는 하나의 제네릭 형식 매개 변수를 수락한다고 선언합니다. 변수의 이름과 마찬가지로 일반 자리 표시자도 마찬가지이지만 대문자 "T"("유형"의 경우 "T")를 사용하고 필요에 따라 알파벳 아래로 이동하는 것이 관례입니다. T 는 유형이므로 T 유형의 이름 input 에 대한 하나의 함수 인수를 수락하고 우리 함수가 T 유형을 반환할 것이라고 명시합니다. 그것이 서명이 말하는 전부입니다. T = string 을 머릿속에 넣어두세요. 모든 T 를 해당 서명의 string 으로 바꾸세요. 그 마법 같은 일이 어떻게 진행되고 있지 않습니까? 당신이 매일 함수를 사용하는 비일반적인 방식과 얼마나 유사한지 보시겠습니까?
TypeScript 및 함수 서명에 대해 이미 알고 있는 내용을 염두에 두십시오. input 이 사용자가 함수를 호출할 때 제공할 임의의 값인 것처럼 T 는 함수를 호출할 때 사용자가 제공할 임의의 유형입니다. 이 경우 입력은 미래 에 함수가 호출될 때 T 유형이 무엇이든 간에 input 되어야 합니다.
다음으로 "미래"에서 두 개의 로그 문에서 변수를 사용하는 것처럼 사용하려는 구체적인 유형을 "전달"합니다. 여기에서 <T> signature 의 초기 형식에서 우리의 기능을 선언할 때 제네릭입니다. 즉, 제네릭 유형 또는 나중에 지정될 유형에서 작동합니다. 그것은 우리가 실제로 함수를 작성할 때 호출자가 어떤 유형을 사용하기를 원하는지 알 수 없기 때문입니다. 그러나 호출자는 함수를 호출할 때 작업하려는 유형(이 경우 string 과 number )을 정확히 알고 있습니다.
타사 라이브러리에서 이러한 방식으로 로그 함수를 선언하는 아이디어를 상상할 수 있습니다. 라이브러리 작성자는 lib를 사용하는 개발자가 어떤 유형을 사용하기를 원하는지 전혀 알지 못하므로 기본적으로 필요를 연기하고 함수를 일반화합니다. 그들이 실제로 알려질 때까지 구체적인 유형을 위해.
보다 직관적인 이해를 위해 함수에 변수를 전달하는 개념을 수행하는 것과 유사한 방식으로 이 프로세스를 생각 해야 한다는 점을 강조하고 싶습니다. 우리가 지금 하고 있는 것은 유형도 전달하는 것뿐입니다.
number 매개변수를 사용하여 함수를 호출한 시점에서 원래 서명은 모든 의도와 목적에 대해 identity(input: number): number 로 생각할 수 있습니다. 그리고 string 매개변수를 사용하여 함수를 호출한 지점에서 다시 원래 서명은 identity(input: string): string 이었을 수 있습니다. 호출할 때 모든 일반 T 가 그 순간에 제공하는 구체적인 유형으로 대체된다고 상상할 수 있습니다.
일반 구문 탐색
ES5 함수, 화살표 함수, 유형 별칭, 인터페이스 및 클래스의 컨텍스트에서 제네릭을 지정하기 위한 다양한 구문과 의미가 있습니다. 이 섹션에서 이러한 차이점을 살펴보겠습니다.
일반 구문 탐색 — 함수
지금까지 제네릭 함수의 몇 가지 예를 보았지만 제네릭 함수는 변수와 마찬가지로 둘 이상의 제네릭 형식 매개 변수를 받아들일 수 있다는 점에 유의해야 합니다. 하나, 둘, 세 개 또는 원하는 만큼 많은 유형을 요청할 수 있으며 모두 쉼표로 구분됩니다(입력 인수와 마찬가지로).
이 함수는 세 가지 입력 유형을 수락하고 그 중 하나를 무작위로 반환합니다.
function randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V { // This is a tuple if you're not familiar. const options: [T, U, V] = [ one, two, three ]; const rndNum = getRndNumInInclusiveRange(0, 2); return options[rndNum]; } // Calling the function. // `value` has type `string | number | IAircraft` const value = randomValue< string, number, IAircraft >( myString, myNumber, myAircraft );ES5 함수를 사용하는지 화살표 함수를 사용하는지에 따라 구문이 약간 다르지만 둘 다 서명에서 유형 매개변수를 선언한다는 것을 알 수 있습니다.
const randomValue = <T, U, V>( one: T, two: U, three: V ): T | U | V => { // This is a tuple if you're not familiar. const options: [T, U, V] = [ one, two, three ]; const rndNum = getRndNumInInclusiveRange(0, 2); return options[rndNum]; } 유형에 강제되는 "고유성 제약"이 없음을 명심하십시오. 예를 들어 두 개의 string 과 a number 와 같이 원하는 모든 조합을 전달할 수 있습니다. 또한 입력 인수가 함수 본문의 "범위 내에" 있는 것처럼 제네릭 형식 매개 변수도 마찬가지입니다. 앞의 예는 함수 본문 내에서 T , U 및 V 에 대한 전체 액세스 권한이 있고 이를 사용하여 로컬 3-튜플을 선언한다는 것을 보여줍니다.
이러한 제네릭이 특정 "컨텍스트" 또는 특정 "수명" 내에서 작동하고 선언된 위치에 따라 다르다고 상상할 수 있습니다. 함수에 대한 제네릭은 함수 시그니처 및 본문(중첩 함수에 의해 생성된 클로저) 내의 범위에 있는 반면 클래스 또는 인터페이스 또는 유형 별칭에 선언된 제네릭은 클래스 또는 인터페이스 또는 유형 별칭의 모든 멤버에 대한 범위에 있습니다.
함수에 대한 제네릭의 개념은 "자유 함수" 또는 "부동 함수"(객체나 클래스에 연결되지 않은 함수, C++ 용어)에 국한되지 않고 다른 구조에 연결된 함수에도 사용할 수 있습니다.
그 randomValue 를 클래스에 배치하고 똑같이 부를 수 있습니다.
class Utils { public randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V { // ... } // Or, as an arrow function: public randomValue = <T, U, V>( one: T, two: U, three: V ): T | U | V => { // ... } }인터페이스 내에 정의를 배치할 수도 있습니다.
interface IUtils { randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V; }또는 유형 별칭 내에서:
type Utils = { randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V; }이전과 마찬가지로 이러한 제네릭 유형 매개변수는 해당 특정 기능의 "범위 내"입니다. 클래스나 인터페이스 또는 유형 별칭 전체가 아닙니다. 그것들은 그들이 지정된 특정 기능 내에서만 삽니다. 구조의 모든 멤버에서 제네릭 유형을 공유하려면 아래에서 볼 수 있듯이 구조 이름 자체에 주석을 달아야 합니다.
일반 구문 탐색 — 별칭 유형
유형 별칭을 사용하면 별칭 이름에 일반 구문이 사용됩니다.
예를 들어, 값을 허용하는 일부 "액션" 함수는 해당 값을 변경할 수 있지만 void를 반환하는 함수는 다음과 같이 작성할 수 있습니다.
type Action<T> = (val: T) => void;참고 : 이것은 Action<T> 대리자를 이해하는 C# 개발자에게 익숙해야 합니다.
또는 오류와 값을 모두 허용하는 콜백 함수를 다음과 같이 선언할 수 있습니다.
type CallbackFunction<T> = (err: Error, data: T) => void; const usersApi = { get(uri: string, cb: CallbackFunction<User>) { /// ... } }함수 제네릭에 대한 지식을 바탕으로 더 나아가 API 객체의 함수도 제네릭으로 만들 수 있습니다.
type CallbackFunction<T> = (err: Error, data: T) => void; const api = { // `T` is available for use within this function. get<T>(uri: string, cb: CallbackFunction<T>) { /// ... } } 이제 get 함수가 일부 일반 유형 매개변수를 수락하고 그것이 무엇이든 CallbackFunction 이 이를 받습니다. 우리는 본질적으로 CallbackFunction 에 대한 T 로 get 에 들어가는 T 를 "전달"했습니다. 이름을 변경하면 아마도 이것이 더 이해가 될 것입니다.
type CallbackFunction<TData> = (err: Error, data: TData) => void; const api = { get<TResponse>(uri: string, cb: CallbackFunction<TResponse>) { // ... } } 형식 매개변수에 T 를 접두사로 지정하는 것은 인터페이스에 I 또는 멤버 변수에 _ 를 접두사로 지정하는 것과 같은 규칙일 뿐입니다. 여기서 볼 수 있는 것은 CallbackFunction 은 함수에 사용 가능한 데이터 페이로드를 나타내는 일부 유형( TData )을 허용하는 반면 get 은 HTTP 응답 데이터 유형/형태( TResponse )를 나타내는 유형 매개변수를 허용한다는 것입니다. Axios와 유사한 HTTP 클라이언트( api )는 해당 TResponse 가 무엇이든 CallbackFunction 에 대한 TData 로 사용합니다. 이를 통해 API 호출자는 API에서 다시 수신할 데이터 유형을 선택할 수 있습니다(JSON을 DTO로 구문 분석하는 미들웨어가 파이프라인의 다른 곳에 있다고 가정).
이것을 조금 더 발전시키고 싶다면 CallbackFunction 의 일반 유형 매개변수를 수정하여 사용자 정의 오류 유형도 허용할 수 있습니다.
type CallbackFunction<TData, TError> = (err: TError, data: TData) => void;그리고 함수 인수를 선택 사항으로 만들 수 있는 것처럼 유형 매개 변수도 사용할 수 있습니다. 사용자가 오류 유형을 제공하지 않는 경우 기본적으로 오류 생성자로 설정합니다.
type CallbackFunction<TData, TError = Error> = (err: TError, data: TData) => void;이를 통해 이제 여러 가지 방법으로 콜백 함수 유형을 지정할 수 있습니다.
const apiOne = { // `Error` is used by default for `CallbackFunction`. get<TResponse>(uri: string, cb: CallbackFunction<TResponse>) { // ... } }; apiOne.get<string>('uri', (err: Error, data: string) => { // ... }); const apiTwo = { // Override the default and use `HttpError` instead. get<TResponse>(uri: string, cb: CallbackFunction<TResponse, HttpError>) { // ... } }; apiTwo.get<string>('uri', (err: HttpError, data: string) => { // ... });기본 매개변수에 대한 이러한 아이디어는 함수, 클래스, 인터페이스 등에서 허용됩니다. 이는 유형 별칭에만 국한되지 않습니다. 지금까지 본 모든 예에서 우리는 원하는 모든 유형 매개변수를 기본값에 할당할 수 있었습니다. 유형 별칭은 함수와 마찬가지로 원하는 만큼 제네릭 유형 매개변수를 사용할 수 있습니다.
일반 구문 탐색 — 인터페이스
본 것처럼 인터페이스의 함수에 제네릭 형식 매개변수를 제공할 수 있습니다.
interface IUselessFunctions { // Not generic printHelloWorld(); // Generic identity<T>(t: T): T; } 이 경우 T 는 입력 및 반환 유형으로 identity 함수에 대해서만 존재합니다.
인터페이스 자체가 제네릭을 허용하도록 지정하여 클래스 및 유형 별칭과 마찬가지로 인터페이스의 모든 구성원이 유형 매개변수를 사용할 수 있도록 할 수도 있습니다. 좀 더 복잡한 제네릭 사용 사례를 논의할 때 리포지토리 패턴에 대해 이야기할 것이므로 들어본 적이 없더라도 괜찮습니다. 리포지토리 패턴을 사용하면 비즈니스 로직을 지속성 불가지론적으로 만들기 위해 데이터 스토리지를 추상화할 수 있습니다. 알 수 없는 엔티티 유형에서 작동하는 일반 리포지토리 인터페이스를 생성하려는 경우 다음과 같이 입력할 수 있습니다.
interface IRepository<T> { add(entity: T): Promise<void>; findById(id: string): Promise<T>; updateById(id: string, updated: T): Promise<void>; removeById(id: string): Promise<void>; }참고 : Martin Fowler의 정의에서 DDD Aggregate 정의에 이르기까지 Repositories에 대한 다양한 생각이 있습니다. 나는 단지 제네릭에 대한 사용 사례를 보여주려고 할 뿐이므로 구현 측면에서 완전히 올바른지 여부에는 그다지 관심이 없습니다. 제네릭 리포지토리를 사용하지 않는 것에 대해서는 분명히 할 말이 있지만 나중에 그것에 대해 이야기하겠습니다.
여기에서 볼 수 있듯이 IRepository 는 데이터를 저장하고 검색하는 메서드가 포함된 인터페이스입니다. T 라는 일반 유형 매개변수에서 작동하고 T 는 findById 의 약속 확인 결과뿐만 아니라 add 및 updateById 에 대한 입력으로 사용됩니다.
각 함수 자체가 제네릭 유형 매개변수를 수락하도록 허용하는 것과 대조적으로 인터페이스 이름에서 제네릭 유형 매개변수를 수락하는 것 사이에는 매우 큰 차이가 있음을 명심하십시오. 전자는 여기에서 한 것처럼 인터페이스 내의 각 기능이 동일한 유형 T 에서 작동하도록 합니다. 즉, IRepository<User> 의 경우 인터페이스에서 T 를 사용하는 모든 메서드가 이제 User 개체에서 작동합니다. 후자의 방법을 사용하면 각 기능이 원하는 유형과 함께 작동할 수 있습니다. 예를 들어 User 를 저장소에 추가할 수만 있고 Policies 이나 Orders 을 다시 받을 수 있다는 것은 매우 특이할 것입니다. 모든 방법에 걸쳐 균일합니다.
주어진 인터페이스에는 공유 유형뿐만 아니라 해당 구성원에 고유한 유형도 포함될 수 있습니다. 예를 들어 배열을 모방하려면 다음과 같은 인터페이스를 입력할 수 있습니다.
interface IArray<T> { forEach(func: (elem: T, index: number) => void): this; map<U>(func: (elem: T, index: number) => U): IArray<U>; } 이 경우 forEach 와 map 모두 인터페이스 이름에서 T 에 액세스할 수 있습니다. 언급했듯이 T 는 인터페이스의 모든 구성원에 대한 범위에 있다고 상상할 수 있습니다. 그럼에도 불구하고 내부의 개별 함수가 자체 유형 매개 변수를 받아들이는 것을 막는 것은 없습니다. map 함수는 U 를 사용하여 수행합니다. 이제 map 은 T 와 U 모두에 액세스할 수 있습니다. T 는 이미 사용되었고 명명 충돌을 원하지 않기 때문에 매개변수의 이름을 U 와 같은 다른 문자로 지정해야 했습니다. 이름과 마찬가지로 map 은 배열 내의 T 유형 요소를 U 유형의 새 요소에 "매핑"합니다. T s를 U 로 매핑합니다. 이 함수의 반환 값은 이제 새로운 유형 U 에서 작동하는 인터페이스 자체이므로 배열에 대한 JavaScript의 유창한 연결 가능한 구문을 어느 정도 모방할 수 있습니다.
리포지토리 패턴을 구현하고 종속성 주입에 대해 논의할 때 Generics 및 Interfaces의 힘에 대한 예를 곧 보게 될 것입니다. 다시 한 번, 우리는 인터페이스 끝에 쌓인 하나 이상의 기본 매개변수를 선택할 뿐만 아니라 많은 일반 매개변수를 받아들일 수 있습니다.
일반 구문 탐색 — 클래스
제네릭 형식 매개변수를 형식 별칭, 함수 또는 인터페이스에 전달할 수 있는 것과 마찬가지로 클래스에도 하나 이상을 전달할 수 있습니다. 그렇게 하면 해당 유형 매개변수는 해당 클래스의 모든 멤버와 확장 기본 클래스 또는 구현된 인터페이스에서 액세스할 수 있습니다.
제네릭 형식, 인터페이스 및 멤버 간의 상호 운용성을 볼 수 있도록 위의 TypedList 보다 조금 더 간단한 다른 컬렉션 클래스를 빌드해 보겠습니다. 잠시 후에 기본 클래스와 인터페이스 상속에 유형을 전달하는 예를 볼 것입니다.
우리 컬렉션은 map 과 forEach 메소드 외에 기본 CRUD 기능만 지원할 것입니다.
class Collection<T> { private elements: T[] = []; constructor (elements: T[] = []) { this.elements = elements; } add(elem: T): void { this.elements.push(elem); } contains(elem: T): boolean { return this.elements.includes(elem); } remove(elem: T): void { this.elements = this.elements.filter(existing => existing !== elem); } forEach(func: (elem: T, index: number) => void): void { return this.elements.forEach(func); } map<U>(func: (elem: T, index: number) => U): Collection<U> { return new Collection<U>(this.elements.map(func)); } } const stringCollection = new Collection<string>(); stringCollection.add('Hello, World!'); const numberCollection = new Collection<number>(); numberCollection.add(3.14159); const aircraftCollection = new Collection<IAircraft>(); aircraftCollection.add(myAircraft); 무슨 일이 일어나고 있는지 논의합시다. Collection 클래스는 T 라는 하나의 제네릭 형식 매개 변수를 허용합니다. 해당 유형은 클래스의 모든 구성원이 액세스할 수 있습니다. T[] 유형의 개인 배열을 정의하는 데 사용합니다. 이 배열은 Array<T> 형식으로도 표시할 수 있습니다(일반 TS 배열 유형에 대해서는 Generics를 다시 참조하세요). 또한, 대부분의 멤버 함수는 추가 및 제거되는 유형을 제어하거나 컬렉션에 요소가 포함되어 있는지 확인하는 등의 방식으로 해당 T 를 활용합니다.
마지막으로, 이전에 보았듯이 map 메소드에는 고유한 일반 유형 매개변수가 필요합니다. We need to define in the signature of map that some type T is mapped to some type U through a callback function, thus we need a U . That U is unique to that function in particular, which means we could have another function in that class that also accepts some type named U , and that'd be fine, because those types are only “in scope” for their functions and not shared across them, thus there are no naming collisions. What we can't do is have another function that accepts a generic parameter named T , for that'd conflict with the T from the class signature.
You can see that when we call the constructor, we pass in the type we want to work with (that is, what type each element of the internal array will be). In the calling code at the bottom of the example, we work with string s, number s, and IAircraft s.
How could we make this work with an interface? What if we have different collection interfaces that we might want to swap out or inject into calling code? To get that level of reduced coupling (low coupling and high cohesion is what we should always aim for), we'll need to depend on an abstraction. Generally, that abstraction will be an interface, but it could also be an abstract class.
Our collection interface will need to be generic, so let's define it:

interface ICollection<T> { add(t: T): void; contains(t: T): boolean; remove(t: T): void; forEach(func: (elem: T, index: number) => void): void; map<U>(func: (elem: T, index: number) => U): ICollection<U>; }Now, let's suppose we have different kinds of collections. We could have an in-memory collection, one that stores data on disk, one that uses a database, and so on. By having an interface, the dependent code can depend upon the abstraction, permitting us to swap out different implementations without affecting the existing code. Here is the in-memory collection.
class InMemoryCollection<T> implements ICollection<T> { private elements: T[] = []; constructor (elements: T[] = []) { this.elements = elements; } add(elem: T): void { this.elements.push(elem); } contains(elem: T): boolean { return this.elements.includes(elem); } remove(elem: T): void { this.elements = this.elements.filter(existing => existing !== elem); } forEach(func: (elem: T, index: number) => void): void { return this.elements.forEach(func); } map<U>(func: (elem: T, index: number) => U): ICollection<U> { return new InMemoryCollection<U>(this.elements.map(func)); } } The interface describes the public-facing methods and properties that our class is required to implement, expecting you to pass in a concrete type that those methods will operate upon. However, at the time of defining the class, we still don't know what type the API caller will wish to use. Thus, we make the class generic too — that is, InMemoryCollection expects to receive some generic type T , and whatever it is, it's immediately passed to the interface, and the interface methods are implemented using that type.
Calling code can now depend on the interface:
// Using type annotation to be explicit for the purposes of the // tutorial. const userCollection: ICollection<User> = new InMemoryCollection<User>(); function manageUsers(userCollection: ICollection<User>) { userCollection.add(new User()); } With this, any kind of collection can be passed into the manageUsers function as long as it satisfies the interface. This is useful for testing scenarios — rather than dealing with over-the-top mocking libraries, in unit and integration test scenarios, I can replace my SqlServerCollection<T> (for example) with InMemoryCollection<T> instead and perform state-based assertions instead of interaction-based assertions. This setup makes my tests agnostic to implementation details, which means they are, in turn, less likely to break when refactoring the SUT.
At this point, we should have worked up to the point where we can understand that first TypedList<T> example. Here it is again:
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T): void { this.values.push(value); } public where(predicate: (value: T) => boolean): TypedList<T> { return TypedList.from<T>(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U): TypedList<U> { return TypedList.from<U>(this.values.map(selector)); } public toArray(): T[] { return this.values; } public static from<U>(values: U[]): TypedList<U> { // Perhaps we perform some logic here. // ... return new TypedList<U>(values); } public static create<U>(values?: U[]): TypedList<U> { return new TypedList<U>(values ?? []); } // Other collection functions. // .. } The class itself accepts a generic type parameter named T , and all members of the class are provided access to it. The instance method select and the two static methods from and create , which are factories, accept their own generic type parameter named U .
The create static method permits the construction of a list with optional seed data. It accepts some type named U to be the type of every element in the list as well as an optional array of U elements, typed as U[] . When it calls the list's constructor with new , it passes that type U as the generic parameter to TypedList . This creates a new list where the type of every element is U . It is exactly the same as how we could call the constructor of our collection class earlier with new Collection<SomeType>() . The only difference is that the generic type is now passing through the create method rather than being provided and used at the top-level.
I want to make sure this is really, really clear. I've stated a few times that we can think about passing around types in a similar way that we do variables. It should already be quite intuitive that we can pass a variable through as many layers of indirection as we please. Forget generics and types for a moment and think about an example of the form:
class MyClass { private constructor (t: number) {} public static create(u: number) { return new MyClass(u); } } const myClass = MyClass.create(2.17); This is very similar to what is happening with the more-involved example, the difference being that we're working on generic type parameters, not variables. Here, 2.17 becomes the u in create , which ultimately becomes the t in the private constructor.
In the case of generics:
class MyClass<T> { private constructor () {} public static create<U>() { return new MyClass<U>(); } } const myClass = MyClass.create<number>(); The U passed to create is ultimately passed in as the T for MyClass<T> . When calling create , we provided number as U , thus now U = number . We put that U (which, again, is just number ) into the T for MyClass<T> , so that MyClass<T> effectively becomes MyClass<number> . The benefit of generics is that we're opened up to be able to work with types in this abstract and high-level fashion, similar to how we can normal variables.
The from method constructs a new list that operates on an array of elements of type U . It uses that type U , just like create , to construct a new instance of the TypedList class, now passing in that type U for T .
The where instance method performs a filtering operation based upon a predicate function. There's no mapping happening, thus the types of all elements remain the same throughout. The filter method available on JavaScript's array returns a new array of values, which we pass into the from method. So, to be clear, after we filter out the values that don't satisfy the predicate function, we get an array back containing the elements that do. All those elements are still of type T , which is the original type that the caller passed to create when the list was first created. Those filtered elements get given to the from method, which in turn creates a new list containing all those values, still using that original type T . The reason why we return a new instance of the TypedList class is to be able to chain new method calls onto the return result. This adds an element of “immutability” to our list.
Hopefully, this all provides you with a more intuitive example of generics in practice, and their reason for existence. Next, we'll look at a few of the more advanced topics.
Generic Type Inference
Throughout this article, in all cases where we've used generics, we've explicitly defined the type we're operating on. It's important to note that in most cases, we do not have to explicitly define the type parameter we pass in, for TypeScript can infer the type based on usage.
If I have some function that returns a random number, and I pass the return result of that function to identity from earlier without specifying the type parameter, it will be inferred automatically as number :
// `value` is inferred as type `number`. const value = identity(getRandomNumber()); 유형 유추를 보여주기 위해 이전에 TypedList 구조에서 기술적으로 관련 없는 모든 유형 주석을 제거했으며 아래 그림에서 TSC가 여전히 모든 유형을 올바르게 유추하는 것을 볼 수 있습니다.
외부 유형 선언이 없는 TypedList :
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T) { this.values.push(value); } public where(predicate: (value: T) => boolean) { return TypedList.from(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U) { return TypedList.from(this.values.map(selector)); } public toArray() { return this.values; } public static from<U>(values: U[]) { // Perhaps we perform some logic here. // ... return new TypedList(values); } public static create<U>(values?: U[]) { return new TypedList(values ?? []); } // Other collection functions. // .. } 함수 반환 값과 from 및 생성자에 전달된 입력 유형을 기반으로 TSC는 모든 유형 정보를 이해합니다. 아래 이미지에서 모든 유형을 유추하는 Visual Studio의 Code TypeScript의 언어 확장(및 따라서 컴파일러)을 보여주는 여러 이미지를 함께 연결했습니다.
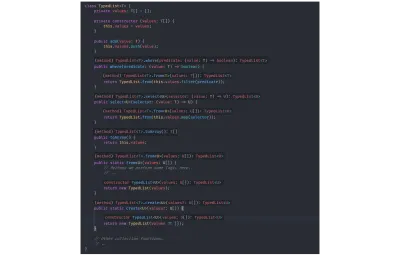
일반 제약 조건
때때로 우리는 제네릭 유형에 제약을 가하고 싶을 때가 있습니다. 존재하는 모든 유형을 지원할 수는 없지만 그 중 일부는 지원할 수 있습니다. 어떤 컬렉션의 길이를 반환하는 함수를 만들고 싶다고 가정해 봅시다. 위에서 볼 수 있듯이 기본 JavaScript Array 에서 사용자 정의 배열에 이르기까지 다양한 유형의 배열/컬렉션을 가질 수 있습니다. 일부 제네릭 유형에 length 속성이 첨부되어 있음을 함수에 알리려면 어떻게 해야 합니까? 마찬가지로, 함수에 전달하는 구체적인 유형을 필요한 데이터가 포함된 유형으로 제한하는 방법은 무엇입니까? 예를 들어 다음과 같은 예는 작동하지 않습니다.
function getLength<T>(collection: T): number { // Error. TS does not know that a type T contains a `length` property. return collection.length; }대답은 Generic Constraints를 활용하는 것입니다. 필요한 속성을 설명하는 인터페이스를 정의할 수 있습니다.
interface IHasLength { length: number; }이제 제네릭 함수를 정의할 때 제네릭 형식을 해당 인터페이스를 확장하는 형식으로 제한할 수 있습니다.
function getLength<T extends IHasLength>(collection: T): number { // Restricting `collection` to be a type that contains // everything within the `IHasLength` interface. return collection.length; }실제 사례
다음 두 섹션에서는 보다 우아하고 추론하기 쉬운 코드를 생성하는 실제 제네릭 예제에 대해 논의할 것입니다. 우리는 사소한 예를 많이 보았지만 오류 처리, 데이터 액세스 패턴 및 프론트 엔드 React 상태/소품에 대한 몇 가지 접근 방식에 대해 논의하고 싶습니다.
실제 사례 — 오류 처리에 대한 접근 방식
JavaScript에는 대부분의 프로그래밍 언어와 마찬가지로 오류 처리를 위한 일급 메커니즘인 try / catch 가 포함되어 있습니다. 그럼에도 불구하고, 나는 사용했을 때 그것이 어떻게 보이는지 그다지 좋아하지 않습니다. 그 메커니즘을 사용하지 않는다는 것은 아니지만, 최대한 숨기려고 노력하는 편입니다. try / catch away를 추상화하여 실패할 가능성이 있는 작업에서 오류 처리 논리를 재사용할 수도 있습니다.
데이터 액세스 계층을 구축한다고 가정합니다. 이것은 데이터 저장 방법을 다루기 위한 지속성 로직을 래핑하는 애플리케이션의 계층입니다. 데이터베이스 작업을 수행 중이고 해당 데이터베이스가 네트워크를 통해 사용되는 경우 특정 DB 관련 오류 및 일시적인 예외가 발생할 수 있습니다. 전용 데이터 액세스 계층을 갖는 이유 중 일부는 비즈니스 로직에서 데이터베이스를 추상화하기 위한 것입니다. 그로 인해 이러한 DB 관련 오류가 스택 위로 던져지고 이 계층 밖으로 나갈 수 없습니다. 먼저 포장해야 합니다.
try / catch 를 사용하는 일반적인 구현을 살펴보겠습니다.
async function queryUser(userID: string): Promise<User> { try { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(dbUser); } catch (e) { switch (true) { case e instanceof DbErrorOne: return Promise.reject(new WrapperErrorOne()); case e instanceof DbErrorTwo: return Promise.reject(new WrapperErrorTwo()); case e instanceof NetworkError: return Promise.reject(new TransientException()); default: return Promise.reject(new UnknownError()); } } } true 로 전환하는 것은 if/else if 체인을 선언해야 하는 것과는 대조적으로 내 오류 검사 논리에 대해 switch case 문을 사용할 수 있는 방법일 뿐입니다. @Jeffijoe에게서 처음 들은 트릭입니다.
이러한 기능이 여러 개 있는 경우 이 오류 래핑 논리를 복제해야 하며 이는 매우 나쁜 습관입니다. 하나의 기능에는 꽤 괜찮아 보이지만 많은 기능에는 악몽이 될 것입니다. 이 논리를 추상화하기 위해 결과를 통과하는 사용자 지정 오류 처리 함수로 래핑할 수 있지만 오류가 발생하면 catch하고 래핑합니다.
async function withErrorHandling<T>( dalOperation: () => Promise<T> ): Promise<T> { try { // This unwraps the promise and returns the type `T`. return await dalOperation(); } catch (e) { switch (true) { case e instanceof DbErrorOne: return Promise.reject(new WrapperErrorOne()); case e instanceof DbErrorTwo: return Promise.reject(new WrapperErrorTwo()); case e instanceof NetworkError: return Promise.reject(new TransientException()); default: return Promise.reject(new UnknownError()); } } } 이것이 의미가 있는지 확인하기 위해 일부 일반 유형 매개변수 T 를 허용하는 withErrorHandling 이라는 이름의 함수가 있습니다. 이 T 는 dalOperation 콜백 함수에서 반환될 것으로 예상되는 Promise의 성공적인 해결 값 유형을 나타냅니다. 일반적으로 우리는 async dalOperation 함수의 반환 결과를 반환하기 때문에 함수를 두 번째 관련 없는 약속으로 래핑할 것이기 때문에 await 필요가 없으며 호출 코드에 await 를 남겨둘 수 있습니다. 이 경우 오류를 잡아야 하므로 await 가 필요합니다.
이제 이 함수를 사용하여 이전의 DAL 작업을 래핑할 수 있습니다.
async function queryUser(userID: string) { return withErrorHandling<User>(async () => { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(dbUser); }); }그리고 우리는 간다. 유형 안전 및 오류 안전 기능 사용자 쿼리 기능이 있습니다.
또한 앞서 보았듯이 TypeScript 컴파일러에 암시적으로 유형을 유추할 수 있는 충분한 정보가 있으면 명시적으로 전달할 필요가 없습니다. 이 경우 TSC는 함수의 반환 결과가 제네릭 유형임을 알고 있습니다. 따라서 mapper.toDomain(user) 이 User 유형을 반환하면 유형을 전혀 전달할 필요가 없습니다.
async function queryUser(userID: string) { return withErrorHandling(async () => { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(user); }); } 내가 좋아하는 오류 처리에 대한 또 다른 접근 방식은 모나딕 유형의 접근 방식입니다. 어느 쪽 모나드(Ione Monad)는 쌍 Either<T, U> 형식의 대수적 데이터 유형이며, 여기서 T 는 오류 유형을 나타내고 U 는 실패 유형을 나타낼 수 있습니다. 모나딕 유형을 사용하면 함수형 프로그래밍에 귀를 기울이고, 주요 이점은 오류가 유형 안전하다는 것입니다. 일반 함수 서명은 해당 함수가 던질 수 있는 오류에 대해 API 호출자에게 아무 것도 알려주지 않습니다. queryUser 내부에서 NotFound 오류가 발생했다고 가정합니다. queryUser(userID: string): Promise<User> 의 서명은 이에 대해 아무 것도 알려주지 않습니다. 그러나 queryUser(userID: string): Promise<Either<NotFound, User>> 와 같은 서명은 절대적으로 그렇습니다. 이 기사에서는 Each Monad와 같은 모나드가 어떻게 작동하는지 설명하지 않을 것입니다. 왜냐하면 매우 복잡할 수 있고 매핑/바인딩과 같이 모나드로 간주되어야 하는 다양한 방법이 있기 때문입니다. 그들에 대해 더 알고 싶다면 여기와 여기에서 Scott Wlaschin의 NDC 강연 두 개와 Daniel Chamber의 강연을 추천합니다. 이 사이트와 이 블로그 게시물도 유용할 수 있습니다.
실제 사례 — 리포지토리 패턴
Generics가 도움이 될 수 있는 또 다른 사용 사례를 살펴보겠습니다. 대부분의 백엔드 시스템은 어떤 방식으로든 데이터베이스와 인터페이스해야 합니다. PostgreSQL과 같은 관계형 데이터베이스, MongoDB와 같은 문서 데이터베이스 또는 Neo4j와 같은 그래프 데이터베이스일 수도 있습니다.
개발자로서 우리는 결합도가 낮고 응집력이 높은 디자인을 목표로 해야 하므로 데이터베이스 시스템 마이그레이션의 결과를 고려하는 것이 타당합니다. 다른 데이터 액세스 요구 사항이 다른 데이터 액세스 접근 방식을 선호할 수 있다는 점을 고려하는 것도 공정할 것입니다(이는 읽기와 쓰기를 분리하기 위한 패턴인 CQRS에 약간 들어가기 시작합니다. 원하는 경우 Martin Fowler의 게시물 및 MSDN 목록 참조) Vaughn Vernon의 "Implementing Domain Driven Design" 책과 Scott Millet의 "Patterns, Principles, and Practices of Domain-Driven Design"도 좋은 읽을거리입니다. 우리는 또한 자동화된 테스트를 고려해야 합니다. Node.js를 사용하여 백엔드 시스템을 구축하는 방법을 설명하는 대부분의 자습서에서는 라우팅이 있는 비즈니스 로직과 데이터 액세스 코드를 혼합합니다. 즉, 그들은 Mongoose ODM과 함께 MongoDB를 사용하는 경향이 있으며 Active Record 접근 방식을 취하고 문제를 명확하게 분리하지 않습니다. 이러한 기술은 대규모 응용 프로그램에서 눈살을 찌푸리게 합니다. 한 데이터베이스 시스템을 다른 데이터베이스 시스템으로 마이그레이션하기로 결정한 순간 또는 데이터 액세스에 대해 다른 접근 방식을 선호한다는 것을 깨닫는 순간, 기존 데이터 액세스 코드를 제거하고 새 코드로 교체해야 합니다. 그리고 그 과정에서 라우팅과 비즈니스 로직에 어떤 버그도 도입하지 않기를 바랍니다.
물론, 단위 및 통합 테스트가 회귀를 방지할 것이라고 주장할 수 있지만, 이러한 테스트가 자체적으로 결합되어 불가지론적이어야 하는 구현 세부 사항에 종속되어 있는 경우 프로세스에서 중단될 가능성이 높습니다.
이 문제를 해결하기 위한 일반적인 접근 방식은 리포지토리 패턴입니다. 코드를 호출하려면 데이터 액세스 계층이 개체 또는 도메인 엔터티의 메모리 내 컬렉션을 모방하도록 허용해야 합니다. 이러한 방식으로 우리는 데이터베이스(데이터 모델)보다 비즈니스가 디자인을 주도하도록 할 수 있습니다. 대규모 애플리케이션의 경우 Domain-Driven Design이라는 아키텍처 패턴이 유용합니다. 리포지토리 패턴에서 리포지토리는 데이터 소스에 액세스하기 위해 내부의 모든 논리를 캡슐화하고 유지하는 가장 일반적으로 클래스인 구성 요소입니다. 이를 통해 데이터 액세스 코드를 하나의 레이어로 중앙 집중화하여 쉽게 테스트하고 쉽게 재사용할 수 있습니다. 또한, 매핑 레이어를 사이에 배치하여 데이터베이스에 구애받지 않는 도메인 모델을 일련의 일대일 테이블 매핑에 매핑할 수 있습니다. 리포지토리에서 사용할 수 있는 각 기능은 원하는 경우 다른 데이터 액세스 방법을 선택적으로 사용할 수 있습니다.
리포지토리, 작업 단위, 테이블 간 데이터베이스 트랜잭션 등에 대한 다양한 접근 방식과 의미 체계가 있습니다. 이것은 Generics에 대한 기사이기 때문에 잡초에 너무 깊이 들어가고 싶지 않습니다. 따라서 여기에서 간단한 예를 설명할 것이지만 응용 프로그램마다 요구 사항이 다릅니다. 예를 들어, DDD Aggregates용 리포지토리는 여기에서 수행하는 작업과 상당히 다릅니다. 여기서 리포지토리 구현을 설명하는 방법은 실제 프로젝트에서 구현하는 방법이 아닙니다. 사용 중인 기능이 누락되고 원하지 않는 아키텍처 방식이 많이 사용되기 때문입니다.
도메인 모델로 Users 와 Tasks 이 있다고 가정해 보겠습니다. 이것들은 POTO(Plain-Old TypeScript Objects)일 수 있습니다. 데이터베이스에 구운 것이라는 개념이 없으므로 예를 들어 Mongoose를 사용하는 것처럼 User.save() 를 호출하지 않습니다. 리포지토리 패턴을 사용하여 다음과 같이 사용자를 유지하거나 비즈니스 로직에서 작업을 삭제할 수 있습니다.
// Querying the DB for a User by their ID. const user: User = await userRepository.findById(userID); // Deleting a Task by its ID. await taskRepository.deleteById(taskID); // Deleting a Task by its owner's ID. await taskRepository.deleteByUserId(userID);분명히, 모든 지저분하고 일시적인 데이터 액세스 논리가 이 저장소 외관/추상화 뒤에 어떻게 숨겨져 비즈니스 논리가 지속성 문제에 종속되지 않는지 알 수 있습니다.
몇 가지 간단한 도메인 모델을 구축하는 것으로 시작하겠습니다. 애플리케이션 코드가 상호 작용할 모델입니다. 여기에서는 빈약하지만 실제 세계에서 비즈니스 불변성을 만족시키기 위해 고유한 논리를 가지고 있습니다. 즉, 단순한 데이터 백이 아닙니다.
interface IHasIdentity { id: string; } class User implements IHasIdentity { public constructor ( private readonly _id: string, private readonly _username: string ) {} public get id() { return this._id; } public get username() { return this._username; } } class Task implements IHasIdentity { public constructor ( private readonly _id: string, private readonly _title: string ) {} public get id() { return this._id; } public get title() { return this._title; } } 우리가 인터페이스에 대한 ID 입력 정보를 추출하는 이유를 잠시 후에 알게 될 것입니다. 도메인 모델을 정의하고 생성자를 통해 모든 것을 전달하는 이 방법은 실제 세계에서 하는 방법이 아닙니다. 또한 추상 도메인 모델 클래스에 의존하는 것이 id 구현을 무료로 얻기 위해 인터페이스보다 더 선호되었을 것입니다.
Repository의 경우 이 경우 동일한 지속성 메커니즘 중 많은 부분이 서로 다른 도메인 모델에서 공유될 것으로 예상하므로 Repository 메서드를 일반 인터페이스로 추상화할 수 있습니다.
interface IRepository<T> { add(entity: T): Promise<void>; findById(id: string): Promise<T>; updateById(id: string, updated: T): Promise<void>; deleteById(id: string): Promise<void>; existsById(id: string): Promise<boolean>; }더 나아가 복제를 줄이기 위해 Generic Repository도 만들 수 있습니다. 간결함을 위해 여기서는 그렇게 하지 않겠습니다. 이 인터페이스와 Generic Repositories와 같은 Generic Repository 인터페이스는 일반적으로 읽기 전용이거나 쓰기 전용인 특정 엔터티가 있을 수 있으므로 눈살을 찌푸리게 하는 경향이 있다는 점에 유의해야 합니다. - 전용 또는 삭제할 수 없는 것 또는 이와 유사한 것. 응용 프로그램에 따라 다릅니다. 또한 실제 세계에서 구현할 기능인 테이블 간에 트랜잭션을 공유하기 위한 "작업 단위"에 대한 개념이 없지만 다시 말하지만 이것은 작은 데모이기 때문에 너무 테크니컬해지고 싶다.
먼저 UserRepository 를 구현해 보겠습니다. 사용자에 특정한 메서드를 보유하는 IUserRepository 인터페이스를 정의하여 구체적인 구현을 종속성 주입할 때 호출 코드가 해당 추상화에 종속되도록 허용합니다.
interface IUserRepository extends IRepository<User> { existsByUsername(username: string): Promise<boolean>; } class UserRepository implements IUserRepository { // There are 6 methods to implement here all using the // concrete type of `User` - Five from IRepository<User> // and the one above. }Task Repository는 비슷하지만 응용 프로그램이 적합하다고 생각하는 다른 방법을 포함합니다.
여기에서는 일반 인터페이스를 확장하는 인터페이스를 정의하고 있으므로 작업 중인 구체적인 유형을 전달해야 합니다. 두 인터페이스에서 볼 수 있듯이 우리는 이러한 POTO 도메인 모델을 보내고 내보내는 개념을 가지고 있습니다. 호출 코드는 기본 지속성 메커니즘이 무엇인지 전혀 알지 못하며 이것이 요점입니다.
다음으로 고려해야 할 사항은 선택한 데이터 액세스 방법에 따라 데이터베이스 관련 오류를 처리해야 한다는 것입니다. 예를 들어 이 리포지토리 뒤에 Mongoose 또는 Knex Query Builder를 배치할 수 있으며 이 경우 특정 오류를 처리해야 합니다. 문제의 분리를 깨뜨릴 비즈니스 로직에 버블링이 발생하는 것을 원하지 않습니다. 더 큰 정도의 결합을 도입하십시오.
오류를 처리할 수 있는 사용하려는 데이터 액세스 방법에 대한 기본 저장소를 정의해 보겠습니다.
class BaseKnexRepository { // A constructor. /** * Wraps a likely to fail database operation within a function that handles errors by catching * them and wrapping them in a domain-safe error. * * @param dalOp The operation to perform upon the database. */ public async withErrorHandling<T>(dalOp: () => Promise<T>) { try { return await dalOp(); } catch (e) { // Use a proper logger: console.error(e); // Handle errors properly here. } } }이제 리포지토리에서 이 기본 클래스를 확장하고 해당 Generic 메서드에 액세스할 수 있습니다.
interface IUserRepository extends IRepository<User> { existsByUsername(username: string): Promise<boolean>; } class UserRepository extends BaseKnexRepository implements IUserRepository { private readonly dbContext: Knex | Knex.Transaction; public constructor (private knexInstance: Knex | Knex.Transaction) { super(); this.dbContext = knexInstance; } // Example `findById` implementation: public async findById(id: string): Promise<User> { return this.withErrorHandling<User>(async () => { const dbUser = await this.dbContext<DbUser>() .select() .where({ user_id: id }) .first(); // Maps type DbUser to User return mapper.toDomain(dbUser); }); } // There are 5 methods to implement here all using the // concrete type of `User`. } 우리 함수는 데이터베이스에서 DbUser 를 검색하고 이를 반환하기 전에 User 도메인 모델에 매핑합니다. 이것은 Data Mapper 패턴이며 관심사의 분리를 유지하는 데 중요합니다. DbUser 는 리포지토리가 작동하는 데이터 모델인 데이터베이스 테이블에 대한 일대일 매핑이므로 사용되는 데이터 저장 기술에 크게 의존합니다. 이러한 이유로 DbUser 는 리포지토리를 떠나지 않으며 반환되기 전에 User 도메인 모델에 매핑됩니다. DbUser 구현은 보여주지 않았지만 단순한 클래스나 인터페이스일 수 있습니다.
지금까지 Generics에서 제공하는 리포지토리 패턴을 사용하여 데이터 액세스 문제를 작은 단위로 추상화하고 유형 안전성 및 재사용성을 유지 관리했습니다.
마지막으로 단위 및 통합 테스트를 위해 메모리 내 저장소 구현을 유지하여 테스트 환경에서 해당 저장소를 주입할 수 있고 디스크에서 상태 기반 어설션을 수행할 수 있습니다. 조롱 프레임워크. 이 방법은 테스트가 구현 세부 사항에 결합되는 것을 허용하지 않고 모든 것이 공개 인터페이스에 의존하도록 합니다. 각 리포지토리 간의 유일한 차이점은 ISomethingRepository 인터페이스 아래에 추가하기로 선택한 메서드이므로 일반 메모리 내 리포지토리를 구축하고 유형별 구현 내에서 확장할 수 있습니다.
class InMemoryRepository<T extends IHasIdentity> implements IRepository<T> { protected entities: T[] = []; public findById(id: string): Promise<T> { const entityOrNone = this.entities.find(entity => entity.id === id); return entityOrNone ? Promise.resolve(entityOrNone) : Promise.reject(new NotFound()); } // Implement the rest of the IRepository<T> methods here. } 이 기본 클래스의 목적은 메모리 내 저장소를 처리하기 위한 모든 논리를 수행하여 메모리 내 테스트 저장소 내에서 이를 복제할 필요가 없도록 하는 것입니다. findById 와 같은 메서드로 인해 이 저장소는 엔터티에 id 필드가 포함되어 있다는 사실을 이해해야 합니다. IHasIdentity 인터페이스에 대한 일반 제약 조건이 필요한 이유입니다. 우리는 이 인터페이스를 전에 본 적이 있습니다. 이것이 우리 도메인 모델이 구현한 것입니다.
이를 통해 메모리 내 사용자 또는 작업 저장소를 구축할 때 이 클래스를 확장하고 대부분의 메서드를 자동으로 구현할 수 있습니다.
class InMemoryUserRepository extends InMemoryRepository<User> { public async existsByUsername(username: string): Promise<boolean> { const userOrNone = this.entities.find(entity => entity.username === username); return Boolean(userOrNone); // or, return !!userOrNone; } // And that's it here. InMemoryRepository implements the rest. } 여기서 InMemoryRepository 는 엔터티에 id 및 username 과 같은 필드가 있음을 알아야 하므로 User 를 일반 매개변수로 전달합니다. User 는 이미 IHasIdentity 를 구현하므로 일반 제약 조건이 충족되며 username 속성도 있다고 명시합니다.
이제 Business Logic Layer에서 이러한 리포지토리를 사용하려는 경우 매우 간단합니다.
class UserService { public constructor ( private readonly userRepository: IUserRepository, private readonly emailService: IEmailService ) {} public async createUser(dto: ICreateUserDTO) { // Validate the DTO: // ... // Create a User Domain Model from the DTO const user = userFactory(dto); // Persist the Entity await this.userRepository.add(user); // Send a welcome email await this.emailService.sendWelcomeEmail(user); } } (실제 애플리케이션에서는 요청에 대기 시간을 추가하지 않고 실패 시 멱등원 재시도를 수행할 수 있기를 희망하기 위해 emailService 에 대한 호출을 작업 대기열로 이동할 것입니다(- 이메일 전송이 특히 처음에는 멱등원). 게다가, 전체 사용자 개체를 서비스에 전달하는 것도 의심스럽습니다. 주목해야 할 다른 문제는 사용자가 유지된 후 이메일이 전송되기 전에 서버가 충돌하는 위치에 있을 수 있다는 것입니다. 이를 방지하기 위한 완화 패턴이 있지만 실용주의를 위해 적절한 로깅을 통한 사람의 개입은 아마도 잘 작동할 것입니다.
Generics의 기능과 함께 리포지토리 패턴을 사용하여 BLL에서 DAL을 완전히 분리하고 유형이 안전한 방식으로 리포지토리와 인터페이스할 수 있습니다. 우리는 또한 단위 및 통합 테스트를 위해 동등하게 유형이 안전한 메모리 내 리포지토리를 신속하게 구성하는 방법을 개발하여 진정한 블랙박스 및 구현에 구애받지 않는 테스트를 허용합니다. 이 중 어느 것도 Generic 형식이 없었다면 불가능했을 것입니다.
면책 조항으로, 이 Repository 구현이 많이 부족하다는 점을 다시 한 번 말씀드리고 싶습니다. 제네릭의 활용이 초점이기 때문에 예제를 단순하게 유지하고 싶었습니다. 그래서 중복을 처리하거나 트랜잭션에 대해 걱정하지 않았습니다. 괜찮은 리포지토리 구현은 기사 자체로 완전하고 정확하게 설명해야 하며 구현 세부 사항은 N-Tier 아키텍처를 수행하는지 DDD를 수행하는지에 따라 달라집니다. 즉, 리포지토리 패턴을 사용하려는 경우 여기에서 내 구현을 모범 사례로 보면 안 됩니다.
실제 사례 — React State 및 Props
React Functional Components의 state, ref 및 나머지 후크도 Generic입니다. Task 에 대한 속성이 포함된 인터페이스가 있고 React 구성 요소에 컬렉션을 보유하고 싶다면 다음과 같이 할 수 있습니다.
import React, { useState } from 'react'; export const MyComponent: React.FC = () => { // An empty array of tasks as the initial state: const [tasks, setTasks] = useState<Task[]>([]); // A counter: // Notice, type of `number` is inferred automatically. const [counter, setCounter] = useState(0); return ( <div> <h3>Counter Value: {counter}</h3> <ul> { tasks.map(task => ( <li key={task.id}> <TaskItem {...task} /> </li> )) } </ul> </div> ); }; 또한, 일련의 props를 함수에 전달하려는 경우 일반 React.FC<T> 유형을 사용하고 props 에 액세스할 수 있습니다.
import React from 'react'; interface IProps { id: string; title: string; description: string; } export const TaskItem: React.FC<IProps> = (props) => { return ( <div> <h3>{props.title}</h3> <p>{props.description}</p> </div> ); }; props 유형은 TS 컴파일러에 의해 자동으로 IProps 로 유추됩니다.
결론
이 기사에서 우리는 단순 컬렉션에서 오류 처리 접근 방식, 데이터 액세스 계층 격리 등에 이르기까지 Generics 및 해당 사용 사례의 다양한 예를 보았습니다. 가장 간단한 용어로 Generics를 사용하면 컴파일 타임에 작동할 구체적인 시간을 알 필요 없이 데이터 구조를 구축할 수 있습니다. 바라건대, 이것은 주제를 조금 더 열고 Generics의 개념을 조금 더 직관적으로 만들고 진정한 힘을 가져오는 데 도움이 됩니다.