
Scrapy로 확장 가능한 웹 스크레이퍼를 구축하기 위한 궁극적인 가이드
게시 됨: 2022-03-10웹 스크래핑은 API나 웹사이트의 데이터베이스에 액세스할 필요 없이 웹사이트에서 데이터를 가져오는 방법입니다. 사이트 데이터에만 액세스하면 됩니다. 브라우저가 데이터에 액세스할 수 있는 한 스크랩할 수 있습니다.
현실적으로 대부분의 경우 수동으로 웹 사이트를 방문하여 복사 및 붙여넣기를 사용하여 '손으로' 데이터를 가져올 수 있지만 많은 경우 수동 작업에 많은 시간이 소요되어 결국 비용이 많이 들 수 있습니다. 데이터보다 훨씬 더 많은 가치가 있습니다. 특히 작업을 수행할 사람을 고용한 경우에는 더욱 그렇습니다. 프로그램이 몇 초마다 자동으로 쿼리를 수행하도록 할 수 있는데 쿼리당 1-2분씩 일하도록 누군가를 고용해야 하는 이유는 무엇입니까?
예를 들어 감독, 주연 배우, 출시 날짜 및 실행 시간과 함께 최우수 작품으로 오스카상 수상자 목록을 작성하려고 한다고 가정해 보겠습니다. Google을 사용하면 이러한 영화의 이름과 추가 정보를 나열하는 사이트가 여러 개 있다는 것을 알 수 있지만 일반적으로 원하는 모든 정보를 캡처하려면 링크를 따라가야 합니다.
분명히, 1927년부터 오늘날까지 모든 링크를 살펴보고 수동으로 각 페이지를 통해 정보를 찾으려고 시도하는 것은 비현실적이고 시간 소모적일 것입니다. 웹 스크래핑을 사용하면 이 모든 정보가 있는 페이지가 있는 웹사이트를 찾은 다음 올바른 지침에 따라 프로그램을 올바른 방향으로 안내하기만 하면 됩니다.
이 자습서에서는 필요한 모든 정보가 포함된 Wikipedia를 웹 사이트로 사용하고 Scrapy on Python을 도구로 사용하여 정보를 스크랩합니다.
시작하기 전에 몇 가지 주의 사항:
데이터 스크래핑에는 스크래핑하는 사이트의 서버 부하가 증가하므로 사이트를 호스팅하는 회사에 비용이 더 많이 들고 해당 사이트의 다른 사용자에게 더 낮은 품질의 경험을 제공합니다. 웹 사이트를 실행하는 서버의 품질, 얻으려는 데이터의 양, 서버에 요청을 보내는 속도는 서버에 미치는 영향을 조절합니다. 이를 염두에 두고 몇 가지 규칙을 준수해야 합니다.
대부분의 사이트는 기본 디렉토리에 robots.txt 라는 파일도 있습니다. 이 파일은 사이트에서 스크레이퍼가 액세스하지 못하도록 하는 디렉토리에 대한 규칙을 설정합니다. 웹 사이트의 이용 약관 페이지는 일반적으로 데이터 스크래핑에 대한 정책을 알려줍니다. 예를 들어 IMDB의 조건 페이지에는 다음 절이 있습니다.
로봇 및 화면 스크래핑: 아래에 명시된 바와 같이 명시적인 서면 동의가 있는 경우를 제외하고 이 사이트에서 데이터 마이닝, 로봇, 화면 스크래핑 또는 유사한 데이터 수집 및 추출 도구를 사용할 수 없습니다.
웹사이트의 데이터를 얻으려고 하기 전에 항상 웹사이트의 약관과 robots.txt 를 확인하여 법적 데이터를 얻고 있는지 확인해야 합니다. 스크레이퍼를 구축할 때 처리할 수 없는 요청으로 서버를 압도하지 않도록 해야 합니다.
운 좋게도 많은 웹 사이트는 사용자가 데이터를 얻을 필요성을 인식하고 API를 통해 데이터를 사용할 수 있도록 합니다. 사용 가능한 경우 일반적으로 스크래핑보다 API를 통해 데이터를 얻는 것이 훨씬 더 쉽습니다.
Wikipedia는 robots.txt 에 지정된 대로 봇이 '너무 빨리' 진행되지 않는 한 데이터 스크래핑을 허용합니다. 또한 사람들이 자신의 컴퓨터에서 데이터를 처리할 수 있도록 다운로드 가능한 데이터 세트를 제공합니다. 너무 빨리 진행하면 서버가 자동으로 IP를 차단하므로 규칙을 유지하기 위해 타이머를 구현할 것입니다.
시작하기, Pip를 사용하여 관련 라이브러리 설치하기
먼저 Scrapy를 설치해 보겠습니다.
창
https://www.python.org/downloads/windows/에서 최신 버전의 Python을 설치합니다.
참고: Windows 사용자는 Microsoft Visual C++ 14.0도 필요하며 여기의 "Microsoft Visual C++ 빌드 도구"에서 가져올 수 있습니다.
또한 최신 버전의 pip가 있는지 확인해야 합니다.
cmd.exe 에서 다음을 입력합니다.
python -m pip install --upgrade pip pip install pypiwin32 pip install scrapy그러면 Scrapy와 모든 종속성이 자동으로 설치됩니다.
리눅스
먼저 모든 종속성을 설치해야 합니다.
터미널에 다음을 입력합니다.
sudo apt-get install python3 python3-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev모든 것이 설치되면 다음을 입력하십시오.
pip install --upgrade pippip가 업데이트되었는지 확인한 다음:
pip install scrapy모든 작업이 완료되었습니다.
맥
먼저 시스템에 c 컴파일러가 있는지 확인해야 합니다. 터미널에 다음을 입력합니다.
xcode-select --install그런 다음 https://brew.sh/에서 homebrew를 설치합니다.
homebrew 패키지가 시스템 패키지보다 먼저 사용되도록 PATH 변수를 업데이트하십시오.
echo "export PATH=/usr/local/bin:/usr/local/sbin:$PATH" >> ~/.bashrc source ~/.bashrc파이썬 설치:
brew install python그런 다음 모든 것이 업데이트되었는지 확인합니다.
brew update; brew upgrade python완료되면 pip를 사용하여 Scrapy를 설치합니다.
pip install Scrapy > ## Scrapy의 개요, 조각이 어떻게 결합되는지, 파서, 스파이더 등Scrapy가 실행되도록 'Spider'라는 스크립트를 작성하게 되지만 걱정하지 마십시오. Scrapy 거미는 이름에도 불구하고 전혀 무섭지 않습니다. Scrapy 거미와 실제 거미의 유일한 유사점은 웹에서 기어 다니는 것을 좋아한다는 것입니다.
스파이더 내부에는 Scrapy에게 무엇을 해야 하는지 알려주는 class 가 정의되어 있습니다. 예를 들어 크롤링을 시작하는 위치, 요청 유형, 페이지의 링크를 따라가는 방법, 데이터를 구문 분석하는 방법 등이 있습니다. 파일로 다시 출력하기 전에 데이터를 처리하기 위해 사용자 정의 함수를 추가할 수도 있습니다.
첫 번째 스파이더를 시작하려면 먼저 Scrapy 프로젝트를 만들어야 합니다. 이렇게 하려면 명령줄에 다음을 입력합니다.
scrapy startproject oscars그러면 프로젝트가 있는 폴더가 생성됩니다.
기본적인 거미부터 시작하겠습니다. 다음 코드는 python 스크립트에 입력됩니다. /oscars/spiders 에서 새 python 스크립트를 열고 이름을 oscars_spider.py 로 지정합니다.
Scrapy를 가져올 것입니다.
import scrapy그런 다음 Spider 클래스를 정의하기 시작합니다. 먼저 이름을 설정한 다음 스파이더가 스크래핑할 수 있는 도메인을 설정합니다. 마지막으로 거미에게 긁기 시작하는 위치를 알려줍니다.
class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ['https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture']다음으로 원하는 정보를 캡처하는 함수가 필요합니다. 지금은 페이지 제목만 가져오겠습니다. CSS를 사용하여 제목 텍스트를 포함하는 태그를 찾은 다음 추출합니다. 마지막으로 정보를 다시 Scrapy에 반환하여 파일에 기록하거나 기록합니다.
def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data 이제 코드를 /oscars/spiders/oscars_spider.py 에 저장합니다.
이 스파이더를 실행하려면 명령줄로 이동하여 다음을 입력하세요.
scrapy crawl oscars다음과 같은 출력이 표시되어야 합니다.
2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)
축하합니다. 첫 번째 기본 Scrapy 스크레이퍼를 만들었습니다!

전체 코드:
import scrapy class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data분명히 우리는 더 많은 작업을 수행하기를 원하므로 Scrapy를 사용하여 데이터를 구문 분석하는 방법을 살펴보겠습니다.
먼저 Scrapy 셸에 대해 알아보겠습니다. Scrapy 셸을 사용하면 코드를 테스트하여 Scrapy가 원하는 데이터를 가져오는지 확인할 수 있습니다.
셸에 액세스하려면 명령줄에 다음을 입력합니다.
scrapy shell “https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture”이렇게 하면 기본적으로 지정한 페이지가 열리고 한 줄의 코드를 실행할 수 있습니다. 예를 들어 다음을 입력하여 페이지의 원시 HTML을 볼 수 있습니다.
print(response.text)또는 다음을 입력하여 기본 브라우저에서 페이지를 엽니다.
view(response)여기서 우리의 목표는 우리가 원하는 정보가 포함된 코드를 찾는 것입니다. 지금은 영화 제목만 가져오도록 합시다.
필요한 코드를 찾는 가장 쉬운 방법은 브라우저에서 페이지를 열고 코드를 검사하는 것입니다. 이 예에서는 Chrome DevTools를 사용하고 있습니다. 영화 제목을 마우스 오른쪽 버튼으로 클릭하고 '검사'를 선택하기만 하면 됩니다.
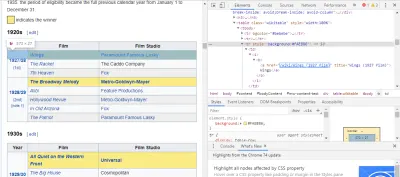
보시다시피 오스카 수상자는 노란색 배경을 가지고 있고 후보자는 평범한 배경을 가지고 있습니다. 영화 제목에 대한 기사에 대한 링크도 있으며 영화에 대한 링크는 영화로 끝납니다 film) . 이제 우리는 이것을 알았으므로 CSS 선택기를 사용하여 데이터를 가져올 수 있습니다. Scrapy 셸에 다음을 입력합니다.
response.css(r"tr[] a[href*='film)']").extract()보시다시피, 이제 모든 Oscar Best Picture 수상자 목록이 있습니다!
> response.css(r"tr[] a[href*='film']").extract() ['<a href="/wiki/Wings_(1927_film)" title="Wings (1927 film)">Wings</a>', ... '<a href="/wiki/Green_Book_(film)" title="Green Book (film)">Green Book</a>', '<a href="/wiki/Jim_Burke_(film_producer)" title="Jim Burke (film producer)">Jim Burke</a>']우리의 주요 목표로 돌아가서, 우리는 감독, 주연 배우, 출시 날짜 및 실행 시간과 함께 최우수 작품에 대한 오스카 수상자 목록을 원합니다. 이렇게 하려면 각 영화 페이지에서 데이터를 가져오기 위해 Scrapy가 필요합니다.
몇 가지를 다시 작성하고 새 기능을 추가해야 하지만 걱정하지 마십시오. 매우 간단합니다.
이전과 같은 방식으로 스크레이퍼를 시작하여 시작하겠습니다.
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] 하지만 이번에는 두 가지가 바뀔 것입니다. 먼저 봇이 긁는 속도를 제한하는 타이머를 만들고 scrapy 때문에 스크레이피와 함께 time 을 가져옵니다. 또한 페이지를 처음으로 구문 분석할 때 각 제목에 대한 링크 목록만 가져오기를 원하므로 대신 해당 페이지에서 정보를 가져올 수 있습니다.
def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req 여기에서 우리는 페이지에서 노란색 배경으로 끝나는 모든 링크를 찾는 루프를 만든 다음 해당 링크를 URL 목록으로 결합합니다. 이 링크를 film) 함수에 parse_titles 추가로 전달합니다. 또한 5초마다 페이지만 요청하도록 타이머를 설정합니다. Scrapy 셸을 사용하여 올바른 데이터를 얻고 있는지 확인하기 위해 response.css 필드를 테스트할 수 있음을 기억하십시오!
def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data 실제 작업은 parse_data 함수에서 수행됩니다. 여기서 data 라는 사전을 만든 다음 각 키를 원하는 정보로 채웁니다. 다시 말하지만, 이러한 모든 선택기는 이전에 설명한 대로 Chrome DevTools를 사용하여 찾은 다음 Scrapy 셸로 테스트했습니다.
마지막 줄은 데이터 사전을 다시 Scrapy에 반환하여 저장합니다.
완전한 코드:
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data때때로 웹사이트가 스크래핑 시도를 차단하려고 할 때 프록시를 사용하고 싶을 것입니다.
이렇게 하려면 몇 가지만 변경하면 됩니다. 예제를 사용하여 def parse() 에서 다음과 같이 변경해야 합니다.
def parse(self, response): for href in (r"tr[] a[href*='film)']::attr(href)").extract() : url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) req.meta['proxy'] = "https://yourproxy.com:80" yield req그러면 프록시 서버를 통해 요청이 라우팅됩니다.
배포 및 로깅, 프로덕션에서 실제로 스파이더를 관리하는 방법을 보여줍니다
이제 거미를 실행할 시간입니다. Scrapy가 스크래핑을 시작한 다음 CSV 파일로 출력하도록 하려면 명령 프롬프트에 다음을 입력합니다.
scrapy crawl oscars -o oscars.csv큰 출력이 표시되고 몇 분 후에 완료되고 프로젝트 폴더에 CSV 파일이 저장됩니다.
컴파일 결과, 이전 단계에서 컴파일된 결과 사용 방법 표시
CSV 파일을 열면 원하는 모든 정보가 표시됩니다(제목이 있는 열별로 정렬됨). 정말 간단합니다.
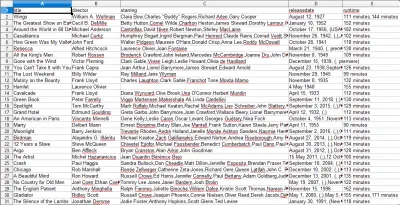
데이터 스크래핑을 사용하면 정보가 공개적으로 사용 가능한 한 원하는 거의 모든 사용자 지정 데이터 세트를 얻을 수 있습니다. 이 데이터로 무엇을 하고 싶은지는 귀하에게 달려 있습니다. 이 기술은 시장 조사를 수행하고 웹사이트의 정보를 업데이트하는 등의 여러 가지 작업에 매우 유용합니다.
사용자 정의 데이터 세트를 얻기 위해 자체 웹 스크레이퍼를 설정하는 것은 매우 쉽지만 필요한 데이터를 얻는 다른 방법이 있을 수 있음을 항상 기억하십시오. 기업은 사용자가 원하는 데이터를 제공하기 위해 많은 투자를 하기 때문에 우리가 그들의 이용 약관을 존중하는 것은 공정합니다.
일반적으로 스크래피 및 웹 스크래핑에 대해 자세히 알아보기 위한 추가 리소스
- 공식 Scrapy 웹사이트
- Scrapy의 GitHub 페이지
- "10가지 최고의 데이터 스크래핑 도구 및 웹 스크래핑 도구", Scraper API
- "차단되거나 차단되지 않는 웹 스크래핑을 위한 5가지 팁", Scraper API
- Parsel은 정규 표현식을 사용하여 HTML에서 데이터를 추출하는 Python 라이브러리입니다.