
2022년 상위 15가지 Hadoop 인터뷰 질문과 답변
게시 됨: 2021-01-09데이터 분석이 본격화되면서 빅데이터를 잘 다루는 인재에 대한 수요가 급증했다. 데이터 분석가에서 데이터 과학자에 이르기까지 빅 데이터는 오늘날 다양한 직업 프로필을 만들고 있습니다. 가장 먼저 실습해야 하는 것은 Hadoop입니다.
직무/프로파일이 무엇이든 간에 여러분은 아마도 어떤 방식으로든 Hadoop에서 작업하고 있을 것입니다. 따라서 면접관이 원하는 방식으로 몇 가지 Hadoop 질문을 던질 것으로 예상할 수 있습니다.
그 이상을 위해, 당신이 앉아 있는 모든 인터뷰에서 예상할 수 있는 상위 15가지 Hadoop 인터뷰 질문을 살펴보겠습니다.
하둡이란? Hadoop의 주요 구성 요소는 무엇입니까?
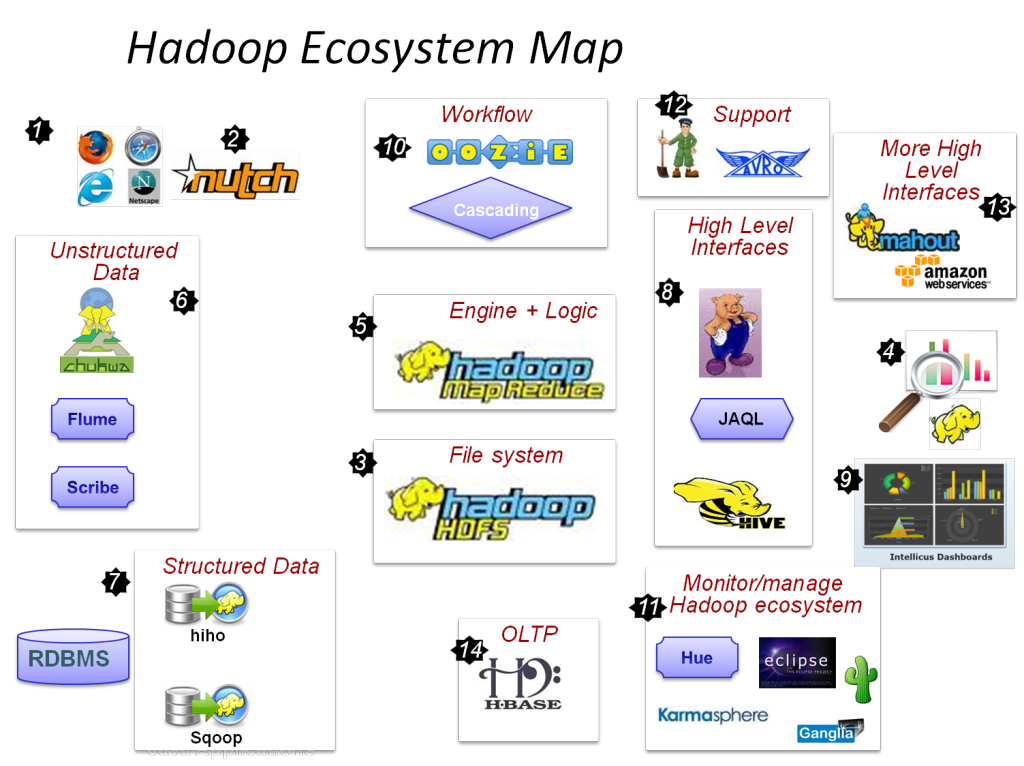
Hadoop은 빅 데이터를 처리하고 저장하는 데 필요한 관련 도구와 서비스를 갖춘 인프라입니다. 정확히 말하면 Hadoop은 모든 빅 데이터 문제에 대한 '솔루션'입니다. 또한 Hadoop 프레임워크는 조직이 빅 데이터를 분석하고 더 나은 비즈니스 결정을 내리는 데 도움이 됩니다.
Hadoop의 주요 구성 요소는 다음과 같습니다.
- HDFS
- 하둡 맵리듀스
- 하둡 커먼
- 실
- PIG 및 HIVE – 데이터 액세스 구성 요소.
- HBase – 데이터 저장용
- Ambari, Oozie 및 ZooKeeper – 데이터 관리 및 모니터링 구성 요소
- Thrift and Avro – 데이터 직렬화 구성 요소
- Apache Flume, Sqoop, Chukwa – 데이터 통합 구성 요소
- Apache Mahout 및 Drill – 데이터 인텔리전스 구성 요소
Hadoop 프레임워크의 핵심 개념은 무엇입니까?
Hadoop은 기본적으로 두 가지 핵심 개념을 기반으로 합니다. 그들은:
- HDFS: HDFS 또는 Hadoop 분산 파일 시스템은 블록 형식으로 방대한 데이터 세트를 저장하는 데 사용되는 안정적인 Java 기반 파일 시스템입니다. 마스터-슬레이브 아키텍처가 이를 지원합니다.
- MapReduce: MapReduce는 대규모 데이터 세트를 처리하는 데 도움이 되는 프로그래밍 구조입니다. 이 기능은 두 부분으로 더 세분화됩니다. 'map'은 데이터 세트를 튜플로 분리하고 'reduce'는 맵 튜플을 사용하고 더 작은 튜플 청크의 조합을 생성합니다.
Hadoop에서 가장 일반적인 입력 형식의 이름은 무엇입니까?
Hadoop에는 세 가지 일반적인 입력 형식이 있습니다.
- 텍스트 입력 형식: Hadoop의 기본 입력 형식입니다.
- 시퀀스 파일 입력 형식: 이 입력 형식은 파일을 순서대로 읽는 데 사용됩니다.
- 키 값 입력 형식: 일반 텍스트 파일을 읽는 데 사용됩니다.
YARN이란 무엇입니까?
YARN은 Yet Another Resource Negotiator의 약자입니다. 데이터 자원을 관리하고 성공적인 처리를 위한 환경을 조성하는 것은 Hadoop의 데이터 처리 프레임워크입니다. 
"랙 인식"이란 무엇입니까?
"Rack Awareness"는 NameNode가 데이터 블록과 해당 복제본이 Hadoop 클러스터에 저장되는 패턴을 결정하는 데 사용하는 알고리즘입니다. 이는 동일한 랙에 포함된 데이터 노드 간의 혼잡을 줄이는 랙 정의의 도움으로 달성됩니다.

액티브 및 패시브 네임노드란 무엇입니까?
고가용성 Hadoop 시스템에는 일반적으로 Active NameNode와 Passive NameNode라는 두 개의 NameNode가 있습니다.
Hadoop 클러스터를 실행하는 NameNode를 Active NameNode라고 하고 Active NameNode의 데이터를 저장하는 Standby NameNode를 Passive NameNode라고 합니다.
두 개의 NameNode를 갖는 목적은 Active NameNode가 충돌하는 경우 Passive NameNode가 주도할 수 있다는 것입니다. 따라서 NameNode는 항상 클러스터에서 실행되고 시스템은 절대 실패하지 않습니다.
Hadoop 프레임워크의 다양한 스케줄러는 무엇입니까?
Hadoop 프레임워크에는 세 가지 다른 스케줄러가 있습니다.
- COSHH – COSHH는 이질성과 결합된 클러스터 및 워크로드를 검토하여 의사 결정을 예약하는 데 도움이 됩니다.
- FIFO 스케줄러 – FIFO는 이질성을 사용하지 않고 도착 시간을 기준으로 대기열에 작업을 정렬합니다.
- 공정한 공유 – 공정한 공유는 특정 작업을 실행하는 데 사용할 수 있는 리소스의 여러 맵과 축소 슬롯을 포함하는 개별 사용자를 위한 풀을 만듭니다.
투기적 실행이란 무엇입니까?
종종 Hadoop 프레임워크에서 일부 노드는 나머지 노드보다 느리게 실행될 수 있습니다. 이것은 전체 프로그램을 제한하는 경향이 있습니다. 이를 극복하기 위해 Hadoop은 작업이 평소보다 느리게 실행될 때 먼저 감지하거나 '추측'한 다음 해당 작업에 대해 동등한 백업을 시작합니다. 따라서 이 과정에서 마스터 노드는 두 작업을 동시에 실행하고 먼저 완료된 작업이 수락되고 다른 작업이 종료됩니다. Hadoop의 이 백업 기능을 Speculative Execution이라고 합니다.

Apache HBase의 주요 구성 요소의 이름을 지정하시겠습니까?
Apache HBase는 세 가지 구성 요소로 구성됩니다.
- 지역 서버: 테이블이 여러 지역으로 분할된 후 이러한 지역의 클러스터는 지역 서버를 통해 클라이언트에 전달됩니다.
- HMaster: 지역 서버를 관리하고 조정하는 데 도움이 되는 도구입니다.
- ZooKeeper: ZooKeeper는 HBase 분산 환경 내의 코디네이터입니다. 세션 내 통신을 통해 클러스터 내부의 서버 상태를 유지하는 데 도움이 됩니다.
"체크포인트"란 무엇입니까? 그것의 이점은 무엇입니까?
체크포인트는 FsImage 및 편집 로그가 결합되어 새로운 FsImage를 형성하는 절차를 나타냅니다. 따라서 편집 로그를 재생하는 대신 NameNode는 FsImage에서 최종 메모리 내 상태를 직접 로드할 수 있습니다. 보조 NameNode는 이 프로세스를 담당합니다.
Checkpointing이 제공하는 이점은 NameNode의 시작 시간을 최소화하여 전체 프로세스를 보다 효율적으로 만든다는 것입니다.
대중 문화의 빅 데이터 응용
Hadoop 코드를 디버깅하는 방법은 무엇입니까?
Hadoop 코드를 디버그하려면 먼저 현재 실행 중인 MapReduce 작업 목록을 확인해야 합니다. 그런 다음 고아 작업이 동시에 실행 중인지 여부를 확인해야 합니다. 그렇다면 다음의 간단한 단계에 따라 Resource Manager 로그의 위치를 찾아야 합니다.
"ps -ef | grep –I ResourceManager”를 입력하고 표시된 결과에서 특정 작업 ID와 관련된 오류가 있는지 찾아보십시오.
이제 작업을 실행하는 데 사용된 작업자 노드를 식별합니다. 노드에 로그인하고 "ps -ef | grep –iNodeManager.”
마지막으로 노드 관리자 로그를 자세히 조사하십시오. 대부분의 오류는 각 맵 축소 작업에 대한 사용자 수준 로그에서 생성됩니다.
Hadoop에서 RecordReader의 목적은 무엇입니까?
Hadoop은 데이터를 블록 형식으로 나눕니다. RecordReader는 이러한 데이터 블록을 읽을 수 있는 단일 레코드로 통합하는 데 도움이 됩니다. 예를 들어, 입력 데이터가 두 개의 블록으로 분할되는 경우 –
행 1 – 에 오신 것을 환영합니다
행 2 – UpGrad
RecordReader는 이것을 "UpG rad에 오신 것을 환영합니다." 로 읽습니다.
Hadoop을 실행할 수 있는 모드는 무엇입니까?
Hadoop을 실행할 수 있는 모드는 다음과 같습니다.
- 독립 실행형 모드 – 디버깅 목적으로 사용되는 기본 Hadoop 모드입니다. HDFS를 지원하지 않습니다.
- 의사 분산 모드 – 이 모드에서는 mapred-site.xml, core-site.xml 및 hdfs-site.xml 파일의 구성이 필요했습니다. 여기서 마스터 노드와 슬레이브 노드는 모두 동일합니다.
- 완전 분산 모드 – 완전 분산 모드는 데이터가 Hadoop 클러스터의 다양한 노드에 분산되는 Hadoop의 프로덕션 단계입니다. 여기서 Master Node와 Slave Node는 별도로 할당된다.
Hadoop의 몇 가지 실용적인 응용 프로그램의 이름을 지정하십시오.
다음은 Hadoop이 변화를 만들고 있는 몇 가지 실제 사례입니다.
- 거리 교통 관리
- 사기 탐지 및 예방
- 고객 데이터를 실시간으로 분석하여 고객 서비스 개선
- 의료 서비스를 개선하기 위해 의사, HCP 등의 비정형 의료 데이터에 액세스합니다.
빅 데이터의 성능을 향상시킬 수 있는 중요한 Hadoop 도구는 무엇입니까?
빅 데이터 성능을 크게 향상시키는 Hadoop 도구는 다음과 같습니다.

• 하이브
• HDFS
• HBase
• SQL
• NoSQL
• 오지
• 구름
• 아브로
• 수로
• 주키퍼
빅 데이터 엔지니어: 신화 대 현실
결론
이 Hadoop 인터뷰 질문은 다음 인터뷰에서 큰 도움이 될 것입니다. 때때로 면접관이 일부 Hadoop 인터뷰 질문을 왜곡하는 경향이 있지만 기본 사항을 정렬하면 문제가 되지 않습니다.
빅 데이터에 대해 더 알고 싶다면 PG 디플로마 빅 데이터 소프트웨어 개발 전문화 프로그램을 확인하십시오. 이 프로그램은 실무 전문가를 위해 설계되었으며 7개 이상의 사례 연구 및 프로젝트를 제공하고 14개 프로그래밍 언어 및 도구, 실용적인 실습을 다룹니다. 워크샵, 400시간 이상의 엄격한 학습 및 최고의 기업과의 취업 지원.