
머신러닝을 이용한 주식시장 예측 [단계적 구현]
게시 됨: 2021-02-26목차
소개
주식 시장의 예측과 분석은 가장 복잡한 작업 중 일부입니다. 여기에는 시장 변동성 및 시장에서 특정 주식의 가치를 결정하는 기타 종속적이고 독립적인 요인과 같은 몇 가지 이유가 있습니다. 이러한 요인으로 인해 주식 시장 분석가는 상승과 하락을 높은 정확도로 예측하기가 매우 어렵습니다.
그러나 기계 학습 및 강력한 알고리즘의 출현으로 최신 시장 분석 및 주식 시장 예측 개발은 주식 시장 데이터를 이해하는 데 이러한 기술을 통합하기 시작했습니다.
요컨대, 머신 러닝 알고리즘은 주식 가치를 분석하고 예측하는 데 많은 조직에서 널리 사용되고 있습니다. 이 기사에서는 Python의 여러 기계 학습 알고리즘을 사용하여 Popular Worldwide Online Retail Store의 주식 가치를 분석하고 예측하는 간단한 구현을 살펴봅니다.
문제 설명
주식 시장 가치를 예측하기 위해 프로그램을 구현하기 전에 작업할 데이터를 시각화해 보겠습니다. 여기서는 나스닥(National Association of Securities Dealers Automated Quotations)에서 Microsoft Corporation(MSFT)의 주식 가치를 분석합니다. 주가 데이터는 Excel 또는 스프레드시트를 사용하여 열고 볼 수 있는 쉼표로 구분된 파일(.csv) 형식으로 표시됩니다.
MSFT는 NASDAQ에 등록된 주식을 보유하고 있으며 주식 시장의 모든 영업일 동안 가치를 업데이트합니다. 시장은 토요일과 일요일에 거래를 허용하지 않습니다. 따라서 두 날짜 사이에 간격이 있습니다. 각 날짜에 대해 주식의 시작 가치, 같은 날 해당 주식의 최고가 및 최저 가치가 하루가 끝날 때의 종가와 함께 기록됩니다.
조정된 종가는 배당금이 게시된 후의 주식 가치를 보여줍니다(너무 기술적입니다!). 또한 시장에 있는 주식의 총량도 제공됩니다. 이러한 데이터를 사용하여 데이터를 연구하고 Microsoft Corporation 주식의 과거 주식에서 패턴을 추출할 수 있는 여러 알고리즘을 구현하는 것은 기계 학습/데이터 과학자의 작업에 달려 있습니다. 데이터.

장기 단기 기억
Microsoft Corporation의 주가를 예측하는 기계 학습 모델을 개발하기 위해 LSTM(Long Short-Term Memory) 기술을 사용할 것입니다. 곱셈과 덧셈을 통해 정보를 약간 수정하는 데 사용됩니다. 정의에 따르면 LSTM(장기 기억)은 딥 러닝에 사용되는 인공 순환 신경망(RNN) 아키텍처입니다.
표준 피드포워드 신경망과 달리 LSTM에는 피드백 연결이 있습니다. 단일 데이터 포인트(예: 이미지)와 전체 데이터 시퀀스(예: 음성 또는 비디오)를 처리할 수 있습니다. LSTM의 개념을 이해하기 위해 휴대전화에 대한 온라인 고객 리뷰의 간단한 예를 들어보겠습니다.
휴대폰을 구매하려고 한다고 가정할 때 일반적으로 인증된 사용자의 순 리뷰를 참조합니다. 그들의 생각과 입력에 따라 우리는 모바일이 좋은지 나쁜지 결정하고 구매합니다. 리뷰를 계속 읽으면서 "놀라운", "좋은 카메라", "최고의 배터리 백업"과 같은 키워드 및 기타 휴대 전화와 관련된 많은 용어를 찾습니다.
우리는 '그것', '주다', '이것' 등과 같은 일반적인 영어 단어를 무시하는 경향이 있습니다. 그래서 우리는 휴대폰을 살지 말지를 결정할 때 위에서 정의한 이러한 키워드만 기억합니다. 아마도 우리는 다른 단어를 잊어 버립니다.
이것은 장단기 기억 알고리즘이 작동하는 것과 같은 방식입니다. 관련 정보만 기억하고 관련 없는 데이터는 무시하고 예측하는 데 사용합니다. 이런 식으로 우리는 기본적으로 해당 주식에 대한 필수 데이터만 인식하고 이상치를 제외하는 LSTM 모델을 구축해야 합니다.
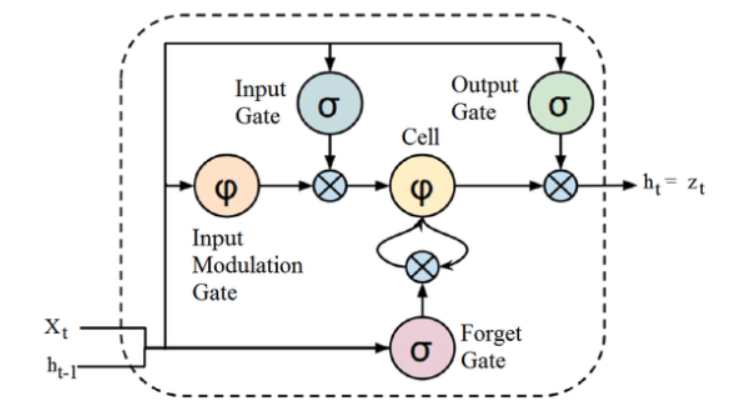
원천
위에서 설명한 LSTM 아키텍처의 구조가 처음에는 흥미롭게 보일 수 있지만 LSTM은 데이터 시퀀스를 처리하기 위해 메모리를 유지하는 순환 신경망의 고급 버전이라는 것을 기억하는 것으로 충분합니다. 게이트라고 하는 구조에 의해 신중하게 조절되는 세포 상태에 정보를 제거하거나 추가할 수 있습니다.
LSTM 장치는 셀, 입력 게이트, 출력 게이트 및 망각 게이트로 구성됩니다. 세포는 임의의 시간 간격에 걸쳐 값을 기억하고 세 개의 게이트는 세포 안팎으로 정보의 흐름을 조절합니다.
프로그램 구현
Python에서 Machine Learning을 사용하여 주가를 예측할 때 LSTM을 사용하는 부분으로 넘어가겠습니다.
1단계 – 라이브러리 가져오기
우리 모두 알고 있듯이 첫 번째 단계는 Microsoft Corporation의 스톡 데이터를 사전 처리하는 데 필요한 라이브러리와 LSTM 모델의 출력을 빌드하고 시각화하는 데 필요한 기타 라이브러리를 가져오는 것입니다. 이를 위해 TensorFlow 프레임워크에서 Keras 라이브러리를 사용합니다. 필요한 모듈은 Keras 라이브러리에서 개별적으로 가져옵니다.
#라이브러리 가져오기
팬더를 PD로 가져오기
NumPy를 np로 가져오기
%matplotlib 인라인
matplotlib를 가져옵니다. plt로 pyplot
가져오기 matplotlib
스켈런에서. 가져오기 MinMaxScaler 전처리
케라스에서. 레이어 가져오기 LSTM, Dense, Dropout
sklearn.model_selection에서 가져오기 TimeSeriesSplit
sklearn.metrics에서 mean_squared_error, r2_score 가져오기
matplotlib를 가져옵니다. 명령으로 날짜
스켈런에서. 가져오기 MinMaxScaler 전처리
sklearn에서 linear_model 가져오기
케라스에서. 모델 가져오기 순차
케라스에서. 레이어 가져오기 밀도
케라스를 수입합니다. K로 백엔드
케라스에서. 콜백 가져오기 EarlyStopping
케라스에서. 옵티마이저는 Adam을 가져옵니다.
케라스에서. 모델 가져오기 load_model
케라스에서. 레이어 가져오기 LSTM
케라스에서. utils.vis_utils 가져오기 plot_model
2단계 – 데이터 시각화 얻기
Pandas Data 리더 라이브러리를 사용하여 로컬 시스템의 주식 데이터를 쉼표로 구분된 값(.csv) 파일로 업로드하고 pandas DataFrame에 저장합니다. 마지막으로 데이터도 살펴보겠습니다.
#데이터세트 가져오기
df = pd.read_csv("MicrosoftStockData.csv",na_values=['null'],index_col='날짜',parse_dates=True,infer_datetime_format=True)
df.head()
세계 최고의 대학에서 온라인으로 AI 인증 을 받으십시오 . 석사, 중역 대학원 프로그램, ML 및 AI 고급 인증 프로그램을 통해 경력을 빠르게 추적할 수 있습니다.
3단계 – DataFrame 모양을 인쇄하고 Null 값을 확인합니다.
이 또 다른 중요한 단계에서는 먼저 데이터 세트의 모양을 인쇄합니다. 데이터 프레임에 null 값이 없는지 확인하기 위해 확인합니다. 데이터 세트에 null 값이 있으면 훈련 과정에서 큰 편차를 일으키는 이상치로 작용하기 때문에 훈련 중에 문제를 일으키는 경향이 있습니다.
# 데이터 프레임 모양 인쇄 및 Null 값 확인
print("데이터 프레임 모양: ", df. 모양)
print("널 값 존재: ", df.IsNull().values.any())
>> 데이터 프레임 모양: (7334, 6)
>>널 값 존재: False
| 날짜 | 열려있는 | 높은 | 낮은 | 닫기 | 닫기 조정 | 용량 |
| 1990-01-02 | 0.605903 | 0.616319 | 0.598090 | 0.616319 | 0.447268 | 53033600 |
| 1990-01-03 | 0.621528 | 0.626736 | 0.614583 | 0.619792 | 0.449788 | 113772800 |
| 1990-01-04 | 0.619792 | 0.638889 | 0.616319 | 0.638021 | 0.463017 | 125740800 |
| 1990-01-05 | 0.635417 | 0.638889 | 0.621528 | 0.622396 | 0.451678 | 69564800 |
| 1990-01-08 | 0.621528 | 0.631944 | 0.614583 | 0.631944 | 0.458607 | 58982400 |
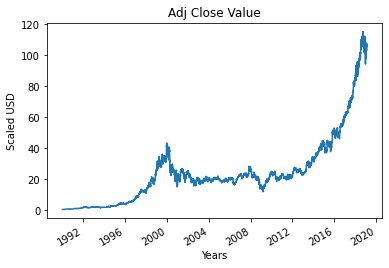
4단계 – 실제 조정된 종가 표시
기계 학습 모델을 사용하여 예측할 최종 출력 값은 조정된 닫기 값입니다. 이 값은 주식 시장 거래의 특정 날짜에 주식의 종가를 나타냅니다.
#진정한 조정 닫기 값을 플로팅합니다.
df['닫기 조정'].plot()
5단계 – 대상 변수 설정 및 기능 선택
다음 단계에서는 출력 열을 대상 변수에 할당합니다. 이 경우 Microsoft Stock의 조정된 상대 가치입니다. 또한 대상 변수(종속 변수)에 대한 독립 변수 역할을 하는 기능도 선택합니다. 교육 목적을 설명하기 위해 다음과 같은 네 가지 특성을 선택합니다.
- 열려있는
- 높은
- 낮은
- 용량
#목표변수 설정
output_var = PD.DataFrame(df['닫기 조정'])
#기능 선택

기능 = ['열림', '높음', '낮음', '볼륨']
6단계 – 확장
테이블에서 데이터의 계산 비용을 줄이기 위해 스톡 값을 0과 1 사이의 값으로 축소합니다. 이러한 방식으로 큰 숫자의 모든 데이터가 줄어들어 메모리 사용량이 줄어듭니다. 또한 데이터가 엄청난 값으로 퍼져 있지 않기 때문에 축소하여 더 많은 정확도를 얻을 수 있습니다. 이것은 sci-kit-learn 라이브러리의 MinMaxScaler 클래스에 의해 수행됩니다.
#스케일링
스케일러 = MinMaxScaler()
feature_transform = scaler.fit_transform(df[기능])
feature_transform= pd.DataFrame(columns=features, data=feature_transform, index=df.index)
feature_transform.head()
| 날짜 | 열려있는 | 높은 | 낮은 | 용량 |
| 1990-01-02 | 0.000129 | 0.000105 | 0.000129 | 0.064837 |
| 1990-01-03 | 0.000265 | 0.000195 | 0.000273 | 0.144673 |
| 1990-01-04 | 0.000249 | 0.000300 | 0.000288 | 0.160404 |
| 1990-01-05 | 0.000386 | 0.000300 | 0.000334 | 0.086566 |
| 1990-01-08 | 0.000265 | 0.000240 | 0.000273 | 0.072656 |
위에서 언급했듯이 특성 변수의 값이 위에 제공된 실제 값에 비해 더 작은 값으로 축소되었음을 알 수 있습니다.
7단계 – 훈련 세트와 테스트 세트로 분할.
데이터를 훈련 모델에 공급하기 전에 전체 데이터 세트를 훈련 및 테스트 세트로 분할해야 합니다. Machine Learning LSTM 모델은 훈련 세트에 있는 데이터에 대해 훈련되고 정확도 및 역전파에 대해 테스트 세트에서 테스트됩니다.
이를 위해 sci-kit-learn 라이브러리의 TimeSeriesSplit 클래스를 사용할 것입니다. 분할 수를 10으로 설정했습니다. 이는 데이터의 10%가 테스트 세트로 사용되고 데이터의 90%가 LSTM 모델 학습에 사용됨을 나타냅니다. 이 시계열 분할을 사용하면 분할 시계열 데이터 샘플이 고정된 시간 간격으로 관찰된다는 장점이 있습니다.
# 훈련 세트와 테스트 세트로 분할
timesplit= TimeSeriesSplit(n_splits=10)
train_index의 경우 timesplit.split(feature_transform)의 test_index:
X_train, X_test = feature_transform[:len(train_index)], feature_transform[len(train_index): (len(train_index)+len(test_index))]
y_train, y_test = output_var[:len(train_index)].values.ravel(), output_var[len(train_index): (len(train_index)+len(test_index))].values.ravel()
8단계 – LSTM용 데이터 처리
훈련 및 테스트 세트가 준비되면 LSTM 모델이 구축되면 데이터를 LSTM 모델에 공급할 수 있습니다. 그 전에 훈련 및 테스트 세트 데이터를 LSTM 모델이 허용하는 데이터 유형으로 변환해야 합니다. 먼저 훈련 데이터와 테스트 데이터를 NumPy 배열로 변환한 다음 LSTM에서 데이터를 3D 형식으로 제공해야 하므로 형식(샘플 수, 1, 기능 수)으로 재구성합니다. 우리가 알고 있듯이 훈련 세트의 샘플 수는 7334개 중 90%인 6667개이고 기능의 수는 4개이며 훈련 세트는 (6667, 1, 4)로 재구성됩니다. 마찬가지로 테스트 세트도 재구성됩니다.
#LSTM에 대한 데이터 처리
trainX =np.array(X_train)
testX =np.array(X_test)
X_train = trainX.reshape(X_train.shape[0], 1, X_train.shape[1])
X_test = testX.reshape(X_test.shape[0], 1, X_test.shape[1])
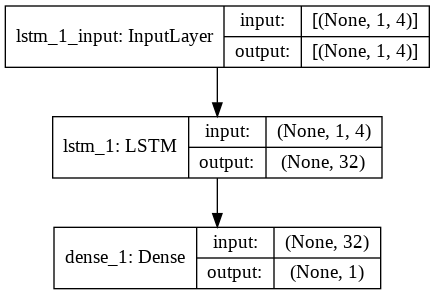
9단계 – LSTM 모델 구축
마지막으로 LSTM 모델을 구축하는 단계에 이르렀습니다. 여기에서 하나의 LSTM 레이어가 있는 Sequential Keras 모델을 만듭니다. LSTM 계층은 32개의 단위를 가지며, 그 다음에는 1개의 뉴런으로 구성된 1개의 Dense Layer가 있습니다.
모델 컴파일을 위한 손실 함수로 Adam Optimizer와 Mean Squared Error를 사용합니다. 이 두 가지는 LSTM 모델에서 가장 선호되는 조합입니다. 또한 모델도 플롯되어 아래에 표시됩니다.
#LSTM 모델 구축
lstm = 순차()
lstm.add(LSTM(32, input_shape=(1, trainX.shape[1]), 활성화='relu', return_sequences=False))
lstm.add(밀도(1))
lstm.compile(loss='mean_squared_error', 옵티마이저='adam')
plot_model(lstm, show_shapes=True, show_layer_names=True)
10단계 – 모델 훈련
마지막으로, 우리는 fit 함수를 사용하여 배치 크기가 8인 100 Epoch에 대한 훈련 데이터에 대해 위에서 설계된 LSTM 모델을 훈련합니다.
#모델 트레이닝
history = lstm.fit(X_train, y_train, epochs=100, batch_size=8, verbose=1, shuffle=False)
에포크 1/100
834/834 [===============================] – 3초 2ms/단계 – 손실: 67.1211
신기원 2/100
834/834 [==============================] – 1초 2ms/단계 – 손실: 70.4911
신기원 3/100
834/834 [==============================] – 1초 2ms/단계 – 손실: 48.8155
에포크 4/100
834/834 [===============================] – 1초 2ms/단계 – 손실: 21.5447
에포크 5/100
834/834 [===============================] – 1초 2ms/단계 – 손실: 6.1709
에포크 6/100
834/834 [===============================] – 1초 2ms/단계 – 손실: 1.8726
신기원 7/100
834/834 [==============================] – 1초 2ms/단계 – 손실: 0.9380
에포크 8/100
834/834 [===============================] – 2초 2ms/단계 – 손실: 0.6566
신기원 9/100
834/834 [==============================] – 1초 2ms/단계 – 손실: 0.5369
신기원 10/100
834/834 [===============================] – 2초 2ms/단계 – 손실: 0.4761
.
.
.
.
신기원 95/100
834/834 [===============================] – 1초 2ms/단계 – 손실: 0.4542
신기원 96/100
834/834 [===============================] – 2초 2ms/단계 – 손실: 0.4553
신기원 97/100
834/834 [===============================] – 1초 2ms/단계 – 손실: 0.4565
신기원 98/100
834/834 [===============================] – 1초 2ms/단계 – 손실: 0.4576
신기원 99/100
834/834 [===============================] – 1초 2ms/단계 – 손실: 0.4588
에포크 100/100
834/834 [===============================] – 1초 2ms/단계 – 손실: 0.4599
마지막으로 손실 값이 100 Epoch의 훈련 과정에서 시간이 지남에 따라 기하급수적으로 감소하여 0.4599 값에 도달했음을 알 수 있습니다.
11단계 – LSTM 예측
모델이 준비되면 테스트 세트에서 LSTM 네트워크를 사용하여 훈련된 모델을 사용하고 Microsoft 주식의 인접 종가를 예측할 차례입니다. 이것은 구축된 lstm 모델에 대한 predict의 단순 기능을 사용하여 수행됩니다.
#LSTM 예측
y_pred= lstm.predict(X_test)
12단계 – 참 대 예측된 조정 종가 – LSTM
마지막으로 테스트 세트의 값을 예측했으므로 LSTM 기계 학습 모델에 의해 Adj Close의 실제 값과 Adj Close의 예측 값을 모두 비교하기 위해 그래프를 그릴 수 있습니다.
#True vs Predicted Adj 닫기 값 – LSTM
plt.plot(y_test, label='실제 값')
plt.plot(y_pred, 레이블='LSTM 값')
plt.title("LSTM의 예측")
plt.xlabel('시간 척도')
plt.ylabel('조정된 USD')
plt.legend()
plt.show()
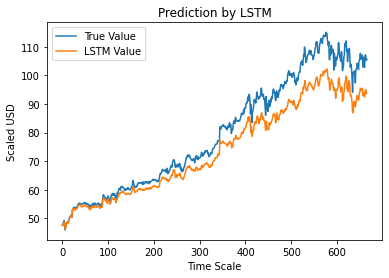
위의 그래프는 위에서 구축한 매우 기본적인 단일 LSTM 네트워크 모델에 의해 일부 패턴이 감지되었음을 보여줍니다. 여러 매개변수를 미세 조정하고 모델에 더 많은 LSTM 레이어를 추가함으로써 주어진 회사의 주식 가치를 보다 정확하게 표현할 수 있습니다.
결론
인공 지능 예제, 기계 학습에 대해 자세히 알아보려면 작업 전문가를 위해 설계되었으며 450시간 이상의 엄격한 교육, 30개 이상의 사례 연구를 제공하는 IIIT-B & upGrad의 기계 학습 및 AI 경영자 PG 프로그램을 확인하십시오. 및 과제, IIIT-B 동문 자격, 5개 이상의 실용적인 실습 캡스톤 프로젝트 및 최고의 기업과의 취업 지원.
기계 학습을 사용하여 주식 시장을 예측할 수 있습니까?
오늘날 우리는 시장 동향을 예측하는 데 도움이 되는 여러 지표를 보유하고 있습니다. 그러나 우리는 주식 시장에 대한 가장 정확한 지표를 찾기 위해 고성능 컴퓨터 이상을 볼 필요가 없습니다. 주식 시장은 개방형 시스템이며 복잡한 네트워크로 볼 수 있습니다. 네트워크는 주식, 회사, 투자자 및 거래량 간의 관계로 구성됩니다. 서포트 벡터 머신과 같은 데이터 마이닝 알고리즘을 사용하면 수학 공식을 적용하여 이러한 변수 간의 관계를 추출할 수 있습니다. 주식 시장은 이제 인간의 예측을 초월합니다.
주식 시장 예측에 가장 적합한 알고리즘은 무엇입니까?
최상의 결과를 얻으려면 선형 회귀를 사용해야 합니다. 선형 회귀는 두 개의 서로 다른 변수 간의 관계를 결정하는 데 사용되는 통계적 접근 방식입니다. 이 예에서 변수는 가격과 시간입니다. 주식 시장 예측에서 가격은 독립 변수이고 시간은 종속 변수입니다. 이 두 변수 사이의 선형 관계를 결정할 수 있다면 미래의 어느 시점에서나 주식의 가치를 정확하게 예측할 수 있습니다.
주식 시장 예측은 분류 또는 회귀 문제입니까?
대답하기 전에 주식 시장 예측이 의미하는 바를 이해해야 합니다. 이진 분류 문제입니까 아니면 회귀 문제입니까? 미래가 다음 날, 주, 월 또는 연도를 의미하는 주식의 미래를 예측한다고 가정합니다. 어떤 시점에서 주식의 과거 성과가 입력이고 미래가 출력이라면 회귀 문제입니다. 주식의 과거 성과와 주식의 미래가 독립적이라면 분류 문제입니다.