
다항식 회귀: 중요성, 단계별 구현
게시 됨: 2021-01-29목차
소개
이 방대한 기계 학습 분야에서 우리 대부분이 연구했을 첫 번째 알고리즘은 무엇입니까? 예, 선형 회귀입니다. 주로 기계 학습 프로그래밍의 초기에 배웠을 첫 번째 프로그램 및 알고리즘인 선형 회귀는 선형 유형의 데이터에 대해 고유한 중요성과 힘을 가지고 있습니다.
우리가 접하는 데이터 세트가 선형으로 분리할 수 없다면 어떻게 될까요? 선형 회귀 모델이 독립 변수와 종속 변수 사이에 어떤 종류의 관계도 도출할 수 없다면 어떻게 될까요?
다항식 회귀로 알려진 또 다른 유형의 회귀가 있습니다. 다항식 회귀는 이름 그대로 종속(y) 변수와 독립 변수(x) 간의 관계를 n차 다항식으로 모델링하는 회귀 알고리즘입니다. 이 기사에서는 Python에서의 구현과 함께 다항식 회귀 뒤에 있는 알고리즘과 수학을 이해할 것입니다.
다항식 회귀란 무엇입니까?
앞에서 정의한 것처럼 다항식 회귀는 종속 변수와 독립 변수 간의 곡선 관계를 형성하는 비선형 데이터에 지정된 (n) 차수가 있는 다항식 방정식이 맞는 선형 회귀의 특수한 경우입니다.
y= b 0 +b 1 x 1 + b 2 x 1 2 + b 3 x 1 3 +… b n x 1 n
여기,

y 는 종속 변수(출력 변수)입니다.
x1 은 독립변수(예측변수)입니다.
b 0 은 편향입니다.
b 1 , b 2 , ….b n 은 회귀 방정식의 가중치입니다.
다항식( n )의 차수가 높을수록 다항식이 복잡해지고 모델이 과적합되는 경향이 있을 수 있는데 이는 뒷부분에서 다루게 된다.
회귀 방정식의 비교
단순 선형 회귀 ===> y= b0+b1x
다중 선형 회귀 ===> y= b0+b1x1+ b2x2+ b3x3+… bnxn
다항식 회귀 ===> y= b0+b1x1+ b2x12+ b3x13+… bnx1n
위의 세 방정식에서 몇 가지 미묘한 차이가 있음을 알 수 있습니다. 단순 및 다중 선형 회귀는 차수가 1이라는 점에서 다항식 회귀 방정식과 다릅니다. 다중 선형 회귀는 여러 변수 x1, x2 등으로 구성됩니다. 다항식 회귀 방정식에는 변수 x1이 하나만 있지만 다른 두 변수와 구별되는 차수 n이 있습니다.
다항식 회귀의 필요성
아래 다이어그램에서 첫 번째 다이어그램에서 선형 라인이 주어진 비선형 데이터 포인트 세트에 맞춰지도록 시도되었음을 알 수 있습니다. 이 비선형 데이터와 직선이 관계를 형성하는 것이 매우 어려워지는 것으로 이해됩니다. 이 때문에 모델을 훈련할 때 손실 함수가 증가하여 높은 오류가 발생합니다.
반면에 다항식 회귀를 적용하면 선이 데이터 포인트에 잘 맞는 것을 분명히 볼 수 있습니다. 이것은 데이터 포인트에 맞는 다항식 방정식이 데이터 세트의 변수 사이에 일종의 관계를 유도한다는 것을 의미합니다. 따라서 데이터 포인트가 비선형 방식으로 배열되는 경우에는 다항식 회귀 모델이 필요합니다.
Python에서 다항식 회귀 구현
여기에서 Python으로 다항식 회귀를 구현하는 기계 학습 모델을 구축합니다. 선형 회귀 및 다항식 회귀로 얻은 결과를 비교할 것입니다. 먼저 다항식 회귀로 해결할 문제를 이해합시다.
문제 설명
여기에서 한 회사에서 여러 후보자를 고용하려는 스타트업의 경우를 생각해 보십시오. 회사에는 다양한 직무에 대한 다양한 기회가 있습니다. 신생 기업에는 이전 회사의 각 역할에 대한 급여 세부 정보가 있습니다. 따라서 후보자가 이전 급여를 언급할 때 창업 HR은 기존 데이터로 이를 검증해야 한다. 따라서 Position과 Level이라는 두 개의 독립 변수가 있습니다. 종속 변수(출력)는 다항식 회귀를 사용하여 예측되는 급여 입니다.
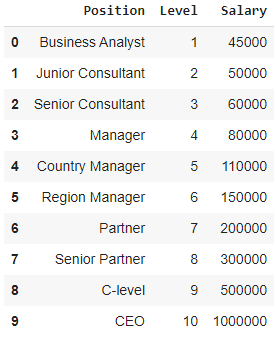
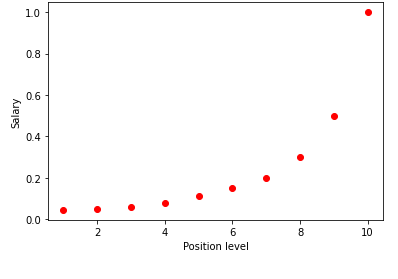
위의 표를 그래프로 시각화하면 데이터가 본질적으로 비선형임을 알 수 있습니다. 즉, 레벨이 증가함에 따라 급여가 더 높은 비율로 증가하므로 아래와 같은 곡선이 나타납니다.
1단계: 데이터 사전 처리기계 학습 모델을 구축하는 첫 번째 단계는 라이브러리를 가져오는 것입니다. 여기서는 가져올 기본 라이브러리가 세 개뿐입니다. 그런 다음 GitHub 저장소에서 데이터 세트를 가져오고 종속 변수와 독립 변수를 할당합니다. 독립변수는 변수 X에 저장되고 종속변수는 변수 y에 저장됩니다.
numpy를 np로 가져오기
matplotlib.pyplot을 plt로 가져오기
pandas를 pd로 가져오기
데이터 세트 = pd.read_csv('https://raw.githubusercontent.com/mk-gurucharan/Regression/master/PositionSalary_Data.csv')
X = 데이터세트.iloc[:, 1:-1].값
y = 데이터세트.iloc[:, -1].값
여기서 [:, 1:-1]이라는 용어에서 첫 번째 콜론은 모든 행을 가져와야 함을 나타내고 1:-1이라는 용어는 포함할 열이 첫 번째 열에서 -1.

2단계: 선형 회귀 모델다음 단계에서는 다중 선형 회귀 모델을 만들고 이를 사용하여 독립 변수에서 급여 데이터를 예측합니다. 이를 위해 sklearn 라이브러리에서 LinearRegression 클래스를 가져옵니다. 그런 다음 훈련 목적으로 변수 X 및 y에 적합합니다.
sklearn.linear_model에서 LinearRegression 가져오기
회귀자 = LinearRegression()
regressor.fit(X, y)
모델이 구축되면 결과를 시각화하여 다음 그래프를 얻습니다.
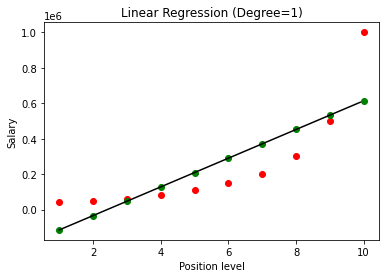
분명히 알 수 있듯이 비선형 데이터 세트에 직선을 맞추려고 시도하면 기계 학습 모델에서 파생되는 관계가 없습니다. 따라서 변수 간의 관계를 얻으려면 다항식 회귀를 사용해야 합니다.
3단계: 다항식 회귀 모델이 다음 단계에서는 이 데이터 세트에 다항식 회귀 모델을 적용하고 결과를 시각화합니다. 이를 위해 우리는 구축할 다항식 방정식의 차수를 제공하는 PolynomialFeatures라는 sklearn 모듈에서 다른 클래스를 가져옵니다. 그런 다음 LinearRegression 클래스를 사용하여 데이터 세트에 다항식 방정식을 맞춥니다.
sklearn.preprocessing에서 가져오기 PolynomialFeatures
sklearn.linear_model에서 LinearRegression 가져오기
poly_reg = 다항식 기능(차수 = 2)
X_poly = poly_reg.fit_transform(X)
lin_reg = 선형회귀()
lin_reg.fit(X_poly, y)
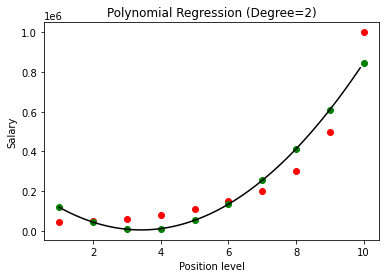
위의 경우 다항식 방정식의 차수를 2로 지정했습니다. 그래프를 그릴 때 일종의 곡선이 유도되지만 여전히 실제 데이터(빨간색 ) 및 예측된 곡선 점(녹색). 따라서 다음 단계에서 다항식의 차수를 3 & 4와 같은 더 높은 숫자로 증가시킨 다음 서로 비교할 것입니다.
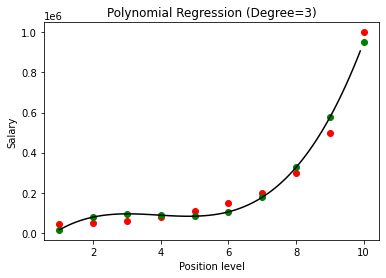
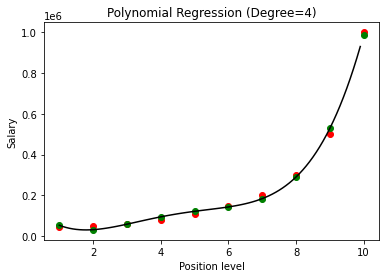
차수 3과 4의 다항식 회귀 결과를 비교하면 차수가 증가함에 따라 모델이 데이터와 함께 잘 훈련된다는 것을 알 수 있습니다. 따라서 차수가 높을수록 다항식 방정식이 훈련 데이터에 더 정확하게 맞출 수 있다고 추론할 수 있습니다. 그러나 이것은 과적합의 완벽한 경우입니다. 따라서 과적합을 방지하기 위해 n 값을 정확하게 선택하는 것이 중요합니다.
과적합이란 무엇입니까?
이름에서 알 수 있듯이 과적합은 통계에서 함수(또는 이 경우 기계 학습 모델)가 제한된 데이터 포인트 세트에 너무 밀접하게 맞는 상황이라고 합니다. 이로 인해 새 데이터 포인트에서 기능이 제대로 수행되지 않습니다.
머신 러닝에서 모델이 주어진 훈련 데이터 포인트 세트에 대해 과적합(overfitting)한다고 하면 동일한 모델이 완전히 새로운 포인트 세트(예: 테스트 데이터 세트)에 도입되면 다음과 같이 매우 나쁜 성능을 보입니다. 과적합 모델은 데이터로 잘 일반화되지 않았으며 훈련 데이터 포인트에만 과적합됩니다.
다항식 회귀에서는 다항식의 차수가 증가함에 따라 모델이 훈련 데이터에 과적합될 가능성이 높습니다. 위에 표시된 예에서 우리는 최적의 차수 값을 선택하기 위한 시행착오 기반으로만 수정할 수 있는 다항식 회귀에서 과적합의 전형적인 경우를 봅니다.
더 읽어보기: 기계 학습 프로젝트 아이디어
결론
결론적으로 다항식 회귀는 종속 변수와 독립 변수 사이에 비선형 관계가 있는 많은 상황에서 활용됩니다. 이 알고리즘은 이상값에 민감하지만 회귀선을 맞추기 전에 이상값을 처리하여 수정할 수 있습니다. 따라서 이 기사에서는 간단한 데이터 세트에 대한 Python 프로그래밍 구현의 예와 함께 다항식 회귀의 개념을 소개했습니다.
기계 학습에 대해 자세히 알아보려면 IIIT-B 및 upGrad의 기계 학습 및 AI PG 디플로마를 확인하세요. 이 PG 디플로마는 일하는 전문가를 위해 설계되었으며 450시간 이상의 엄격한 교육, 30개 이상의 사례 연구 및 과제, IIIT- B 동문 자격, 5개 이상의 실용적인 실습 캡스톤 프로젝트 및 최고의 기업과의 취업 지원.
세계 최고의 대학에서 ML 과정 을 배우십시오 . 석사, 이그 제 큐 티브 PGP 또는 고급 인증 프로그램을 획득하여 경력을 빠르게 추적하십시오.
선형 회귀는 무엇을 의미합니까?
선형 회귀는 종속 변수의 도움으로 알려지지 않은 변수의 값을 찾을 수 있는 예측 수치 분석의 한 유형입니다. 또한 하나의 종속 변수와 하나 이상의 독립 변수 간의 연결을 설명합니다. 선형 회귀는 두 변수 간의 연결을 보여주기 위한 통계적 기법입니다. 선형 회귀는 데이터 요소 집합에서 추세선을 그립니다. 선형 회귀를 사용하여 암 진단이나 주가와 같이 겉보기에 무작위로 보이는 데이터에서 예측 모델을 생성할 수 있습니다. 선형 회귀를 계산하는 방법에는 여러 가지가 있습니다. 데이터에서 알려지지 않은 변수를 추정하고 데이터 포인트와 추세선 사이의 수직 거리의 합으로 시각적으로 변환하는 일반적인 최소제곱법이 가장 널리 사용되는 방법 중 하나입니다.
선형 회귀의 단점은 무엇입니까?
대부분의 경우 회귀 분석은 연구에서 변수 사이에 연결이 있는지 확인하는 데 사용됩니다. 그러나 두 변수 간의 연결이 한 변수가 다른 변수를 발생시킨다는 의미는 아니기 때문에 상관 관계가 인과 관계를 의미하지는 않습니다. 데이터 포인트에 잘 맞는 기본 선형 회귀의 선조차도 상황과 논리적 결과 간의 관계를 보장하지 않을 수 있습니다. 선형 회귀 모델을 사용하여 변수 간에 상관 관계가 있는지 여부를 결정할 수 있습니다. 연결의 정확한 특성과 한 변수가 다른 변수를 유발하는지 여부를 확인하려면 추가 조사 및 통계 분석이 필요합니다.
선형 회귀의 기본 가정은 무엇입니까?
선형 회귀에는 세 가지 주요 가정이 있습니다. 종속 변수와 독립 변수는 무엇보다도 선형 연결이 있어야 합니다. 종속 및 독립 변수의 산점도는 이 관계를 확인하는 데 사용됩니다. 둘째, 데이터 세트의 독립 변수 간에 다중 공선성이 최소 또는 0이어야 합니다. 이는 독립변수가 서로 관련이 없음을 의미합니다. 값은 제한되어야 하며 도메인 요구 사항에 따라 결정됩니다. 등분산성은 세 번째 요인입니다. 오차가 고르게 분포되어 있다는 가정은 가장 기본적인 가정 중 하나입니다.