
유형 및 무형의 혼합: Adobe XD를 사용하여 다중 모드 인터페이스 디자인
게시 됨: 2022-03-10(이 기사는 Adobe의 후원을 받아 작성되었습니다.) 사용자 인터페이스는 진화하고 있습니다. 음성 지원 인터페이스는 그래픽 사용자 인터페이스의 오랜 지배에 도전하고 있으며 빠르게 일상 생활의 일반적인 부분이 되고 있습니다. 자동 음성 인식(APS) 및 자연어 처리(NLP)의 상당한 발전과 인상적인 소비자 기반(음성 지원 기능이 내장된 수백만 대의 모바일 장치)은 음성 기반 인터페이스의 급속한 개발 및 채택에 영향을 미쳤습니다.
음성을 기본 인터페이스로 사용하는 제품이 점점 더 대중화되고 있습니다. 미국에서만 4,730만 명의 성인이 스마트 스피커에 액세스할 수 있으며(미국 성인 인구의 5분의 1에 해당), 그 수는 계속 증가하고 있습니다. 그러나 음성 인터페이스는 개인 및 가정에서 사용할 뿐만 아니라 밝은 미래를 가지고 있습니다. 사람들이 음성 인터페이스에 익숙해짐에 따라 비즈니스 컨텍스트에서도 음성 인터페이스를 기대하게 될 것입니다. 곧 "내 프레젠테이션 보여줘"와 같은 말을 하여 회의실 프로젝터를 작동시킬 수 있다고 상상해 보십시오.
인간-기계 통신이 서면 및 음성 상호 작용을 모두 포함하도록 빠르게 확장되고 있음이 분명합니다. 그러나 미래의 인터페이스가 음성 전용이 될 것이라는 의미입니까? 일부 공상 과학 묘사에도 불구하고 음성이 그래픽 사용자 인터페이스를 완전히 대체하지는 않습니다. 대신 새로운 형식의 인터페이스인 음성 지원 다중 모드 인터페이스에서 음성, 시각 및 제스처의 시너지 효과를 얻을 수 있습니다.
이 문서에서는 다음을 수행합니다.
- 음성 지원 인터페이스의 개념을 탐색하고 다양한 유형의 음성 지원 인터페이스를 검토합니다.
- 음성 지원, 다중 모드 사용자 인터페이스가 선호되는 사용자 경험이 될 이유를 알아보십시오.
- Adobe XD를 사용하여 다중 모드 UI를 구축하는 방법을 확인하십시오.
음성 사용자 인터페이스(VUI)의 상태
음성 사용자 인터페이스에 대해 자세히 알아보기 전에 음성 입력이 무엇인지 정의해야 합니다. 음성 입력은 사용자가 명령을 작성하는 대신 말을 하는 인간-컴퓨터 상호 작용입니다. 음성 입력의 장점은 사람들이 보다 자연스럽게 상호 작용할 수 있다는 것입니다. 사용자는 시스템과 상호 작용할 때 특정 구문으로 제한되지 않습니다. 그들은 인간의 대화에서 하는 것처럼 다양한 방식으로 입력을 구성할 수 있습니다.
음성 사용자 인터페이스는 사용자에게 다음과 같은 이점을 제공합니다.
- 상호작용 비용 감소
음성 지원 인터페이스를 사용하는 것은 상호작용 비용을 수반하지만, 이 비용은 새로운 GUI를 배우는 것보다 (이론적으로) 더 적습니다. - 핸즈프리 제어
VUI는 운전, 요리 또는 운동과 같이 사용자의 손이 바쁠 때 유용합니다. - 속도
질문을 하는 것이 타이핑하고 결과를 읽는 것보다 빠를 때 음성이 탁월합니다. 예를 들어, 자동차에서 음성을 사용할 때 터치스크린에 위치를 입력하는 것보다 내비게이션 시스템에 장소를 말하는 것이 더 빠릅니다. - 감정과 성격
음성은 들어도 화자의 이미지가 보이지 않더라도 머리로는 화자를 상상할 수 있습니다. 이것은 사용자 참여를 향상시킬 수 있는 기회가 있습니다. - 접근성
시각 장애가 있는 사용자와 이동 장애가 있는 사용자는 음성을 사용하여 시스템과 상호 작용할 수 있습니다.
세 가지 유형의 음성 지원 인터페이스
음성을 사용하는 방식에 따라 다음과 같은 유형의 인터페이스 중 하나가 될 수 있습니다.
화면 우선 장치의 음성 에이전트
Apple Siri와 Google Assistant는 음성 에이전트의 대표적인 예입니다. 이러한 시스템의 경우 음성은 기존 GUI의 향상된 기능과 유사합니다. 많은 경우 에이전트는 사용자 여정의 첫 번째 단계로 작동합니다. 사용자는 음성 에이전트를 트리거하고 음성을 통해 명령을 제공하는 반면 다른 모든 상호 작용은 터치스크린을 사용하여 수행됩니다. 예를 들어 Siri에게 질문하면 목록 형식으로 답변이 제공되며 해당 목록과 상호 작용해야 합니다. 결과적으로 사용자 경험은 단편화됩니다. 우리는 음성을 사용하여 상호 작용을 시작한 다음 터치로 전환하여 계속합니다.
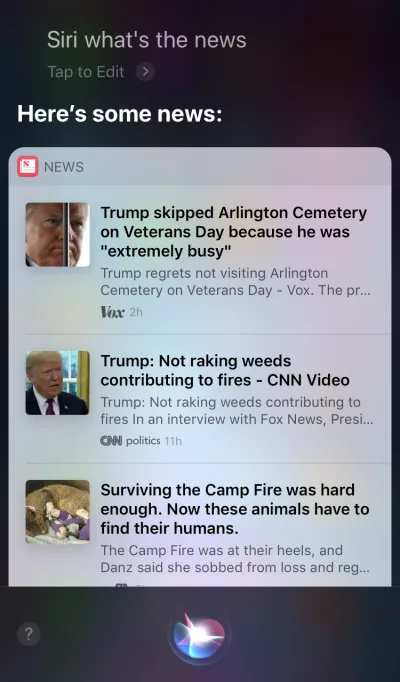
음성 전용 장치
이러한 장치에는 시각적 디스플레이가 없습니다. 사용자는 입력과 출력 모두에 대해 오디오에 의존합니다. Amazon Echo 및 Google Home 스마트 스피커는 이 범주의 제품의 대표적인 예입니다. 시각적 디스플레이의 부족은 정보와 옵션을 사용자에게 전달하는 장치의 능력에 상당한 제약이 됩니다. 결과적으로 대부분의 사람들은 이러한 장치를 사용하여 음악을 재생하고 간단한 질문에 대한 답변을 얻는 것과 같은 간단한 작업을 수행합니다.

음성 우선 장치
음성 우선 시스템을 사용하는 이 장치는 주로 음성 명령을 통해 사용자 입력을 받아들이지만 통합 화면 디스플레이도 갖추고 있습니다. 이는 음성이 기본 사용자 인터페이스이지만 유일한 인터페이스는 아님을 의미합니다. "한 장의 그림은 천 마디 말의 가치가 있다"라는 오래된 속담은 현대의 음성 지원 시스템에도 여전히 적용됩니다. 인간의 두뇌는 놀라운 이미지 처리 능력을 가지고 있습니다. 우리는 시각적으로 볼 때 복잡한 정보를 더 빨리 이해할 수 있습니다. 음성 전용 장치에 비해 음성 우선 장치를 사용하면 사용자가 더 많은 양의 정보에 액세스하고 많은 작업을 훨씬 쉽게 수행할 수 있습니다.
Amazon Echo Show는 음성 우선 시스템을 사용하는 장치의 대표적인 예입니다. 시각적 정보는 전체적인 시스템의 일부로 점차 통합됩니다. 화면에는 앱 아이콘이 로드되지 않습니다. 오히려 시스템은 사용자가 다른 음성 명령을 시도하도록 권장합니다(예: "Alexa를 사용해 보세요. 오후 5시에 날씨를 보여주세요"와 같은 음성 명령 제안). 이 화면은 요리하는 동안 레시피를 확인하는 것과 같은 일반적인 작업을 훨씬 쉽게 만들어 줍니다. 사용자는 주의 깊게 듣고 모든 정보를 머리 속에 유지할 필요가 없습니다. 정보가 필요할 때 그들은 단순히 화면을 봅니다.

다중 모드 인터페이스 소개
UI 디자인에서 음성을 사용할 때 음성을 혼자 사용할 수 있는 것으로 생각하지 마십시오. Amazon Echo Show와 같은 장치에는 화면이 포함되어 있지만 음성을 기본 입력 방법으로 사용하여 보다 전체적인 사용자 경험을 제공합니다. 이것은 새로운 세대의 사용자 인터페이스인 다중 모드 인터페이스를 향한 첫 번째 단계입니다.
다중 모드 인터페이스는 음성, 터치, 오디오 및 다양한 유형의 시각 자료를 하나의 매끄러운 UI에 혼합한 인터페이스입니다. Amazon Echo Show는 음성 지원 다중 모드 인터페이스를 최대한 활용하는 장치의 훌륭한 예입니다. 사용자는 Show와 상호 작용할 때 음성 전용 장치에서와 마찬가지로 요청을 합니다. 그러나 그들이 받는 응답은 음성 및 시각적 응답을 모두 포함하는 다중 모드일 가능성이 높습니다.
멀티모달 제품은 시각에만 의존하거나 음성에만 의존하는 제품보다 더 복잡합니다. 처음에 다중 모드 인터페이스를 만들어야 하는 이유는 무엇입니까? 그 질문에 답하기 위해 우리는 한 걸음 물러나서 사람들이 주변 환경을 어떻게 인식하는지 볼 필요가 있습니다. 사람은 오감을 가지고 있으며, 우리의 감각이 함께 작용하여 사물을 인식하는 방식입니다. 예를 들어, 라이브 콘서트에서 음악을 들을 때 감각이 함께 작동합니다. 하나의 감각(예: 청각)을 제거하면 경험이 완전히 다른 맥락을 갖게 됩니다.

너무 오랫동안 우리는 사용자 경험을 시각적 또는 제스처 디자인으로만 생각했습니다. 이 생각을 바꿀 때입니다. 다중 모드 디자인은 감각 능력을 함께 연결하는 경험에 대해 생각하고 디자인하는 방법입니다.
다중 모드 인터페이스는 사용자와 기계가 통신하는 더 인간적인 방식처럼 느껴집니다. 그들은 더 깊은 상호작용을 위한 새로운 기회를 열어줍니다. 그리고 오늘날에는 과거에 제품과의 상호 작용을 제한했던 기술적 한계가 사라지고 있기 때문에 다중 모드 인터페이스를 설계하는 것이 훨씬 쉽습니다.
GUI와 다중 모드 인터페이스의 차이점
여기서 주요 차이점은 Amazon Echo Show와 같은 다중 모드 인터페이스가 음성 및 시각적 인터페이스를 동기화한다는 것입니다. 결과적으로 경험을 디자인할 때 음성과 영상은 더 이상 독립적인 부분이 아닙니다. 그것들은 시스템이 제공하는 경험의 필수적인 부분입니다.
시각 및 음성 채널: 각각을 사용하는 경우
음성과 영상을 입력 및 출력 채널로 생각하는 것이 중요합니다. 각 채널에는 고유한 강점과 약점이 있습니다.
비주얼부터 시작하겠습니다. 어떤 정보는 들을 때가 아니라 눈으로 볼 때 더 이해하기 쉽다는 것은 분명합니다. 다음을 제공해야 할 때 시각적 개체가 더 잘 작동합니다.
- 긴 옵션 목록(긴 목록을 읽는 것은 시간이 많이 걸리고 따라가기 어렵습니다);
- 데이터가 많은 정보(예: 다이어그램 및 그래프)
- 제품 정보(예: 온라인 상점의 제품, 구매하기 전에 제품을 보고 싶어할 가능성이 높음) 및 제품 비교(옵션의 긴 목록과 마찬가지로 음성만으로 모든 정보를 제공하기 어려울 수 있음) .
그러나 일부 정보에 대해서는 구두 의사 소통에 쉽게 의존할 수 있습니다. 음성은 다음과 같은 경우에 적합할 수 있습니다.
- 사용자 명령(음성은 효율적인 입력 방식이므로 사용자가 시스템에 빠르게 명령을 내리고 복잡한 탐색 메뉴를 건너뛸 수 있음)
- 간단한 사용자 지침(예: 처방에 대한 일상적인 확인)
- 경고 및 알림(예: 운전 중 음성 알림과 함께 오디오 경고).
이것들은 시각과 음성이 결합된 몇 가지 전형적인 경우이지만, 우리는 이 둘을 서로 분리할 수 없다는 것을 아는 것이 중요합니다. 음성과 영상이 함께 작동할 때만 더 나은 사용자 경험을 만들 수 있습니다. 예를 들어, 새 신발 한 켤레를 구매하려고 한다고 가정해 보겠습니다. 음성을 사용하여 시스템에서 "뉴발란스 신발을 보여주세요"라고 요청할 수 있습니다. 시스템은 귀하의 요청을 처리하고 제품 정보를 시각적으로 제공합니다(신발을 비교하는 더 쉬운 방법).
음성 지원, 다중 모드 인터페이스를 설계하기 위해 알아야 할 사항
음성은 UX 디자이너에게 가장 흥미로운 과제 중 하나입니다. 참신함에도 불구하고 음성 지원 다중 모드 인터페이스를 설계하기 위한 기본 규칙은 시각적 디자인을 만드는 데 사용하는 규칙과 동일합니다. 디자이너는 사용자를 배려해야 합니다. 그들은 효율적인 방법으로 문제를 해결하여 사용자의 마찰을 줄이는 것을 목표로 해야 하며 사용자의 선택을 명확하게 하기 위해 명확성을 우선시해야 합니다.
그러나 다중 모드 인터페이스에도 몇 가지 고유한 설계 원칙이 있습니다.
올바른 문제를 해결했는지 확인
디자인은 문제를 해결해야 합니다. 그러나 올바른 문제를 해결하는 것이 중요합니다. 그렇지 않으면 사용자에게 많은 가치를 제공하지 않는 경험을 만드는 데 많은 시간을 할애할 수 있습니다. 따라서 올바른 문제를 해결하는 데 집중해야 합니다. 음성 상호 작용은 사용자에게 이해가 되어야 합니다. 사용자는 클릭 또는 탭과 같은 다른 상호 작용 방법을 통해 음성을 사용해야 하는 설득력 있는 이유가 있어야 합니다. 그렇기 때문에 디자인을 시작하기 전에도 새 제품을 만들 때 사용자 조사를 수행하고 음성이 UX를 개선하는지 여부를 결정하는 것이 필수적입니다.
사용자 여정 지도를 만드는 것부터 시작하십시오. 여정 지도를 분석하고 음성을 채널로 포함하면 UX에 도움이 되는 장소를 찾습니다.
- 사용자가 마찰과 좌절을 경험할 수 있는 여정의 장소를 찾으십시오. 음성을 사용하면 마찰이 줄어들까요?
- 사용자의 컨텍스트에 대해 생각하십시오. 특정 상황에서 음성이 작동합니까?
- 음성으로 가능하게 하는 고유한 기능에 대해 생각해 보십시오. 핸즈프리 및 눈 없는 상호 작용과 같은 음성 사용의 고유한 이점을 기억하십시오. 음성이 경험에 가치를 더할 수 있습니까?
대화 흐름 만들기
이상적으로는 디자인하는 인터페이스에 상호 작용 비용이 필요하지 않아야 합니다. 사용자는 시스템과 상호 작용하는 방법을 배우는 데 추가 시간을 들이지 않고도 요구 사항을 충족할 수 있어야 합니다. 이는 음성 상호 작용이 음성 명령 형식으로 래핑된 시스템 대화가 아니라 실제 대화와 유사한 경우에만 발생합니다. 좋은 UI의 기본 규칙은 간단합니다. 컴퓨터는 그 반대가 아니라 인간에 적응해야 합니다.
사람들은 단조롭고 선형적인 대화(한 턴만 지속되는 대화)를 거의 하지 않습니다. 그렇기 때문에 시스템과의 상호 작용이 실제 대화처럼 느껴지도록 디자이너는 대화 흐름을 만드는 데 집중해야 합니다. 각 대화 흐름은 시스템과 사용자 간에 발생하는 경로인 대화로 구성됩니다. 각 대화 상자에는 시스템의 프롬프트와 사용자의 가능한 응답이 포함됩니다.
대화의 흐름은 흐름도의 형태로 제시될 수 있습니다. 각 흐름은 하나의 특정 사용 사례에 초점을 맞춰야 합니다(예: 시스템을 사용하여 알람 시계 설정). 흐름에 있는 대부분의 대화에서는 상황이 정상을 벗어날 때 오류 경로를 고려하는 것이 중요합니다.
사용자의 각 음성 명령은 의도, 발화 및 슬롯의 세 가지 핵심 요소로 구성됩니다.
- 의도는 음성 지원 시스템과의 사용자 상호 작용의 목표입니다.
인텐트는 일련의 단어 뒤에 있는 목적을 정의하는 멋진 방법일 뿐입니다. 시스템과의 각 상호 작용은 사용자에게 약간의 유용성을 제공합니다. 그것이 정보이든 행동이든, 유틸리티는 의도에 있습니다. 사용자의 의도를 이해하는 것은 음성 지원 인터페이스의 중요한 부분입니다. VUI를 설계할 때 사용자의 의도가 무엇인지 항상 알 수는 없지만 높은 정확도로 추측할 수 있습니다. - 발화는 사용자가 요청을 표현하는 방식입니다.
일반적으로 사용자는 음성 명령을 공식화하는 방법이 두 가지 이상 있습니다. 예를 들어, "알람 시계를 오전 8시로 설정해", "내일 오전 8시 알람 시계" 또는 "오전 8시에 일어나야 해요"라고 말하여 알람 시계를 설정할 수 있습니다. 디자이너는 발화의 가능한 모든 변형을 고려해야 합니다. - 슬롯은 사용자가 명령에서 사용하는 변수입니다. 때때로 사용자는 요청에 추가 정보를 제공해야 합니다. 알람 시계의 예에서 "오전 8시"는 슬롯입니다.
사용자의 입에 단어를 넣지 마십시오
사람들은 말할 줄 압니다. 그들에게 명령을 가르치려고 하지 마십시오. "회의 약속을 보내려면 '일정, 회의, 새 회의 생성'이라고 말해야 합니다."와 같은 문구를 피하십시오. 명령을 설명해야 하는 경우 시스템을 설계하는 방식을 재고해야 합니다. 항상 자연어 회화를 목표로 하고 다양한 말하기 스타일을 수용하도록 노력하십시오).
일관성을 위해 노력하십시오
컨텍스트 전반에 걸쳐 언어와 음성의 일관성을 달성해야 합니다. 일관성은 상호 작용에서 친숙함을 구축하는 데 도움이 됩니다.
항상 피드백 제공
시스템 상태의 가시성은 좋은 GUI 디자인의 기본 원칙 중 하나입니다. 시스템은 합리적인 시간 내에 적절한 피드백을 통해 진행 상황을 사용자에게 항상 알려야 합니다. VUI 디자인에도 동일한 규칙이 적용됩니다.
- 시스템이 듣고 있음을 사용자에게 알리십시오.
장치가 사용자의 요청을 수신하거나 처리할 때 시각적 표시기를 표시합니다. 피드백이 없으면 사용자는 시스템이 무엇을 하고 있는지 추측할 수 있을 뿐입니다. 그렇기 때문에 Amazon Echo 및 Google Home과 같은 음성 전용 장치도 듣거나 답변을 검색할 때 멋진 시각적 피드백(깜빡이는 표시등)을 제공합니다. - 대화형 마커를 제공합니다.
대화 마커는 사용자가 대화에서 어디에 있는지 알려줍니다. - 작업이 완료되면 확인합니다.
예를 들어, 사용자가 음성 지원 스마트 홈 시스템에 "차고의 조명을 끄십시오"라고 묻는 경우 시스템은 명령이 성공적으로 실행되었음을 사용자에게 알려야 합니다. 확인이 없으면 사용자는 차고로 걸어가 조명을 확인해야 합니다. 그것은 사용자의 삶을 더 쉽게 만든다는 스마트 홈 시스템의 목적을 어깁니다.
긴 문장 피하기
음성 지원 시스템을 설계할 때 사용자에게 정보를 제공하는 방식을 고려하십시오. 긴 문장을 사용할 때 너무 많은 정보로 사용자를 압도하기가 비교적 쉽습니다. 첫째, 사용자는 단기 기억에 많은 정보를 저장할 수 없기 때문에 중요한 정보를 쉽게 잊어버릴 수 있습니다. 또한 오디오는 느린 매체입니다. 대부분의 사람들은 들을 수 있는 것보다 훨씬 빠르게 읽을 수 있습니다.
사용자의 시간을 존중하십시오. 긴 오디오 독백을 읽지 마십시오. 응답을 디자인할 때 사용하는 단어가 적을수록 좋습니다. 그러나 사용자가 작업을 완료하려면 여전히 충분한 정보를 제공해야 합니다. 따라서 답변을 몇 단어로 요약할 수 없으면 대신 화면에 표시하십시오.
다음 단계를 순차적으로 제공
사용자는 긴 문장뿐만 아니라 한 번에 선택할 수 있는 옵션의 수도 압도될 수 있습니다. 음성 지원 시스템과의 상호 작용 프로세스를 한 입 크기의 덩어리로 나누는 것이 중요합니다. 사용자가 한 번에 선택할 수 있는 수를 제한하고 매 순간에 무엇을 해야 하는지 확인합니다.
기능이 많은 복잡한 음성 지원 시스템을 설계할 때 점진적 공개 기술을 사용할 수 있습니다. 작업을 완료하는 데 필요한 옵션이나 정보만 표시합니다.
강력한 오류 처리 전략 보유
물론 시스템은 애초에 오류가 발생하지 않도록 해야 합니다. 그러나 음성 지원 시스템이 아무리 우수하더라도 시스템이 사용자를 이해하지 못하는 시나리오에 대해 항상 설계해야 합니다. 귀하의 책임은 그러한 경우를 위해 설계하는 것입니다.
다음은 전략 수립을 위한 몇 가지 실용적인 팁입니다.

- 사용자를 비난하지 마십시오.
대화에는 오류가 없습니다. "당신의 대답은 틀렸습니다."와 같은 대답을 피하십시오. - 오류 복구 흐름을 제공합니다.
중요한 정보를 잃지 않고 대화를 주고받거나 시스템을 종료할 수 있는 옵션을 제공합니다. 사용자의 상태를 여정에 저장하여 중단한 지점부터 시스템에 다시 참여할 수 있습니다. - 사용자가 정보를 재생할 수 있습니다.
시스템이 질문이나 대답을 반복하도록 하는 옵션을 제공합니다. 이것은 사용자가 모든 정보를 작업 메모리에 커밋하기 어려운 복잡한 질문이나 답변에 도움이 될 수 있습니다. - 중지 문구를 제공합니다.
어떤 경우에는 사용자가 옵션을 듣는 데 관심이 없고 시스템이 해당 옵션에 대해 말하는 것을 중단하기를 원할 것입니다. 말을 멈추는 것은 그들이 그렇게 하는 데 도움이 될 것입니다. - 예상치 못한 말을 우아하게 처리하십시오.
시스템 설계에 아무리 많은 돈을 투자하더라도 시스템이 사용자를 이해하지 못하는 상황이 있을 것입니다. 그러한 경우를 우아하게 처리하는 것이 중요합니다. 시스템이 이해 부족을 인정하는 것을 두려워하지 마십시오. 시스템은 자신이 이해한 내용을 전달하고 도움이 되는 메시지를 제공해야 합니다. - 분석을 사용하여 오류 전략을 개선하십시오.
분석은 잘못된 방향과 잘못된 해석을 식별하는 데 도움이 될 수 있습니다.
컨텍스트 추적
시스템이 사용자 입력의 컨텍스트를 이해하는지 확인하십시오. 예를 들어 누군가 다음 주에 샌프란시스코행 항공편을 예약하고 싶다고 말하면 대화 흐름에서 "그것" 또는 "도시"를 언급할 수 있습니다. 시스템은 말한 내용을 기억하고 새로 수신된 정보와 일치시킬 수 있어야 합니다.
보다 강력한 상호 작용을 만들기 위해 사용자에 대해 알아보십시오.
음성 지원 시스템은 사용자가 원하는 것을 이해하기 위해 추가 정보(예: 사용자 컨텍스트 또는 과거 행동)를 사용할 때 더욱 정교해집니다. 이 기술을 지능형 해석이라고 하며 시스템이 사용자에 대해 능동적으로 학습하고 그에 따라 행동을 조정할 수 있어야 합니다. 이 지식은 시스템이 "아내의 생일에 어떤 선물을 사야 합니까?"와 같은 복잡한 질문에 대한 답변을 제공하는 데 도움이 될 것입니다.
VUI에 개성 부여
모든 음성 지원 시스템은 계획 여부와 상관없이 사용자에게 정서적인 영향을 미칩니다. 사람들은 음성을 기계보다 인간과 연관시킵니다. Speak Easy Global Edition 조사에 따르면 음성 기술 일반 사용자의 74%는 브랜드가 음성 지원 제품에 대해 고유한 음성과 개성을 갖기를 기대합니다. 개성을 통해 공감을 구축하고 더 높은 수준의 사용자 참여를 달성할 수 있습니다.
당신이 제시하는 목소리와 어조에 당신의 독특한 브랜드와 아이덴티티를 반영하도록 노력하십시오. 음성 지원 에이전트의 페르소나를 구성하고 대화를 생성할 때 이 페르소나에 의존하십시오.
신뢰를 쌓다
사용자가 시스템을 신뢰하지 않으면 사용할 동기가 없습니다. 그렇기 때문에 신뢰 구축은 제품 디자인의 필수 요건입니다. 시스템 기능과 유효한 결과라는 두 가지 요소가 구축된 신뢰 수준에 중요한 영향을 미칩니다.
신뢰 구축은 사용자 기대치를 설정하는 것으로 시작됩니다. 기존 GUI에는 사용자가 시스템의 기능을 이해하는 데 도움이 되는 많은 시각적 세부 정보가 있습니다. 음성 지원 시스템을 사용하면 디자이너가 의존할 수 있는 도구가 줄어듭니다. 그래도 시스템을 자연스럽게 검색할 수 있도록 하는 것이 중요합니다. 사용자는 시스템에서 가능한 것과 불가능한 것을 이해해야 합니다. 그렇기 때문에 음성 지원 시스템은 시스템이 무엇을 할 수 있는지 또는 무엇을 알고 있는지에 대해 이야기하는 사용자 온보딩이 필요할 수 있습니다. 온보딩을 디자인할 때 사람들에게 온보딩이 무엇을 할 수 있는지 알릴 수 있도록 의미 있는 예를 제공하려고 합니다(예시가 지침보다 효과적임).
유효한 결과와 관련하여 사람들은 음성 지원 시스템이 불완전하다는 것을 알고 있습니다. 시스템이 답변을 제공할 때 일부 사용자는 답변이 정확한지 의심할 수 있습니다. 이것은 사용자가 요청이 올바르게 이해되었는지 또는 답변을 찾는 데 사용된 알고리즘에 대한 정보가 없기 때문에 발생합니다. 신뢰 문제를 방지하려면 증거 지원 화면을 사용하고(화면에 원래 쿼리를 표시하고) 알고리즘에 대한 몇 가지 주요 정보를 제공합니다. 예를 들어 사용자가 "2018년 상위 5개 영화를 보여주세요"라고 묻는 경우 시스템은 "미국 박스오피스 기준 2018년 상위 5개 영화입니다."라고 말할 수 있습니다.
보안 및 데이터 개인 정보 보호를 무시하지 마십시오
개인의 소유인 모바일 기기와 달리 음성 기기는 주방과 같은 장소에 속하는 경향이 있다. 그리고 일반적으로 같은 위치에 두 명 이상의 사람이 있습니다. 다른 누군가가 귀하의 모든 개인 데이터에 액세스할 수 있는 시스템과 상호 작용할 수 있다고 상상해 보십시오. Amazon Alexa, Google Assistant 및 Apple Siri와 같은 일부 VUI 시스템은 개별 음성을 인식할 수 있으므로 시스템에 보안 계층이 추가됩니다. 그러나 시스템이 100%의 경우 고유한 음성 서명을 기반으로 사용자를 인식할 수 있다고 보장하지는 않습니다.
음성 인식은 지속적으로 개선되고 있으며 가까운 장래에 음성을 모방하는 것은 어렵거나 거의 불가능할 것입니다. 그러나 현재 현실에서는 데이터가 안전하다는 것을 사용자에게 확신시키기 위해 추가 인증 계층을 제공하는 것이 중요합니다. 건강 정보 또는 은행 세부 정보와 같은 민감한 데이터와 함께 작동하는 앱을 설계하는 경우 암호, 지문 또는 얼굴 인식과 같은 추가 인증 단계를 포함할 수 있습니다.
사용성 테스트 수행
사용성 테스트는 모든 시스템의 필수 요구 사항입니다. 초기에 테스트하고 자주 테스트하는 것이 디자인 프로세스의 기본 규칙이 되어야 합니다. 초기에 사용자 연구 데이터를 수집하고 디자인을 반복합니다. 그러나 다중 모드 인터페이스 테스트에는 고유한 특성이 있습니다. 고려해야 할 두 단계는 다음과 같습니다.
- 구상 단계
샘플 대화 상자를 테스트합니다. 샘플 대화를 소리내어 읽는 연습을 합니다. 대화 흐름이 끝나면 대화의 양쪽(사용자 발화 및 시스템 응답)을 녹음하고 녹음 내용을 듣고 자연스럽게 들리는지 이해하십시오. - 제품 개발 초기 단계(lo-fi 프로토타입으로 테스트)
Wizard of Oz 테스트는 대화형 인터페이스 테스트에 적합합니다. Wizard of Oz 테스트는 참가자가 컴퓨터로 작동한다고 생각하지만 실제로는 인간이 작동하는 시스템과 상호 작용하는 테스트 유형입니다. 테스트 참가자는 쿼리를 공식화하고 실제 사람은 다른 쪽에서 응답합니다. 이 방법은 Frank Baum 의 The Wonderful Wizard of Oz 라는 책에서 이름을 따왔습니다. 책에서 평범한 남자는 강력한 마법사인 척하며 커튼 뒤에 숨어 있습니다. 이 테스트를 통해 가능한 모든 상호 작용 시나리오를 매핑하고 결과적으로 보다 자연스러운 상호 작용을 생성할 수 있습니다. Say Wizard는 macOS에서 Wizard of Oz 음성 인터페이스 테스트를 실행하는 데 도움이 되는 훌륭한 도구입니다. - 제품 개발의 후기 단계(하이파이 프로토타입으로 테스트)
그래픽 사용자 인터페이스의 사용성 테스트에서 우리는 종종 사용자가 시스템과 상호 작용할 때 큰 소리로 말하도록 요청합니다. 음성 지원 시스템의 경우 시스템이 해당 내레이션을 들을 것이기 때문에 항상 가능한 것은 아닙니다. 따라서 사용자에게 큰 소리로 말하도록 요청하기보다 시스템과 사용자의 상호 작용을 관찰하는 것이 더 나을 수 있습니다.
Adobe XD를 사용하여 다중 모드 인터페이스를 만드는 방법
이제 다중 모드 인터페이스가 무엇인지, 디자인할 때 기억해야 할 규칙이 무엇인지 확실히 이해했으므로 다중 모드 인터페이스의 프로토타입을 만드는 방법에 대해 논의할 수 있습니다.
프로토타이핑은 디자인 프로세스의 기본적인 부분입니다. 아이디어를 실현하고 다른 사람들과 공유할 수 있다는 것은 매우 중요합니다. 지금까지 프로토타이핑에 음성을 통합하려는 디자이너는 의지할 수 있는 도구가 거의 없었으며 그 중 가장 강력한 도구는 순서도였습니다. 사용자가 시스템과 상호 작용하는 방식을 상상하려면 순서도를 보는 사람의 많은 상상력이 필요했습니다. Adobe XD를 통해 디자이너는 이제 음성 매체에 액세스하여 프로토타입에서 사용할 수 있습니다. XD는 하나의 앱에서 화면과 음성 프로토타이핑을 매끄럽게 연결합니다.
새로운 경험, 동일한 프로세스
음성은 시각과 완전히 다른 매체이지만 Adobe XD에서 음성 프로토타이핑 프로세스는 GUI 프로토타이핑과 거의 동일합니다. Adobe XD 팀은 모든 디자이너가 자연스럽고 직관적으로 느낄 수 있는 방식으로 음성을 통합합니다. 디자이너는 음성 트리거 및 음성 재생을 사용하여 프로토타입과 상호 작용할 수 있습니다.
- 음성 트리거는 사용자가 특정 단어나 구(발화)를 말할 때 상호작용을 시작합니다.
- 음성 재생을 통해 디자이너는 텍스트 음성 변환 엔진에 액세스할 수 있습니다. XD는 디자이너가 정의한 단어와 문장을 말할 것입니다. 음성 재생은 다양한 용도로 사용할 수 있습니다. 예를 들어, 승인(사용자를 안심시키기 위해) 또는 안내(사용자가 다음에 무엇을 해야 하는지 알 수 있도록) 역할을 할 수 있습니다.
XD의 가장 큰 장점은 각 음성 플랫폼의 복잡성을 배우지 않아도 된다는 것입니다.
단어로 충분합니다. 실제로 어떻게 작동하는지 봅시다. 아래에 표시되는 모든 예제의 경우 Amazon Alexa용 Adobe XD UI 키트를 사용하여 만든 아트보드를 사용했습니다(키트 다운로드 링크). 키트에는 Amazon Alexa에 대한 경험을 생성하는 데 필요한 모든 스타일과 구성 요소가 포함되어 있습니다.
다음 아트보드가 있다고 가정합니다.
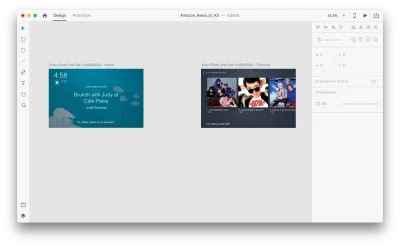
일부 음성 상호 작용을 추가하기 위해 프로토타이핑 모드로 이동해 보겠습니다. 음성 트리거부터 시작하겠습니다. 탭 및 드래그와 같은 트리거와 함께 이제 음성을 트리거로 사용할 수 있습니다. 다른 아트보드로 연결되는 핸들이 있는 한 음성 트리거에 모든 레이어를 사용할 수 있습니다. 대지를 함께 연결해 보겠습니다.
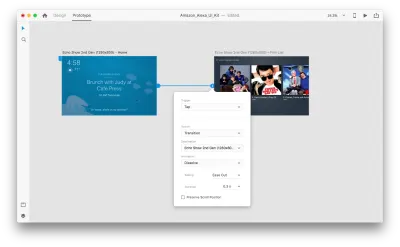
그렇게 하면 "트리거" 아래에 새로운 "음성" 옵션이 표시됩니다. 이 옵션을 선택하면 발언을 입력하는 데 사용할 수 있는 "명령" 필드가 표시됩니다. 이것이 XD가 실제로 수신하는 것입니다. 트리거를 활성화하려면 사용자가 이 명령을 말해야 합니다.
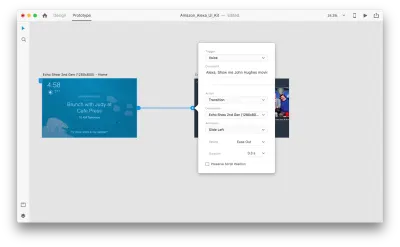
그게 다야! 우리는 첫 번째 음성 상호 작용을 정의했습니다. 이제 사용자는 무언가를 말할 수 있으며 프로토타입은 이에 응답합니다. 그러나 음성 재생을 추가하여 이 상호 작용을 훨씬 더 강력하게 만들 수 있습니다. 이전에 언급했듯이 음성 재생을 통해 시스템은 일부 단어를 말할 수 있습니다.
두 번째 대지 전체를 선택하고 파란색 핸들을 클릭합니다. 지연이 있는 "시간" 트리거를 선택하고 0.2초로 설정합니다. 작업 아래에 "음성 재생"이 있습니다. 가상 비서가 우리에게 말하는 내용을 적어 보겠습니다.
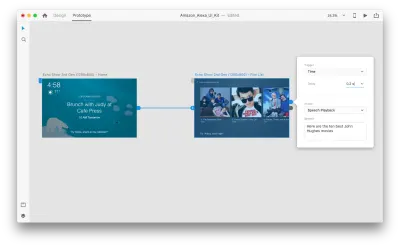
프로토타입을 테스트할 준비가 되었습니다. 첫 번째 아트보드를 선택하고 오른쪽 상단의 재생 버튼을 클릭하면 미리보기 창이 나타납니다. 음성 프로토타이핑과 상호 작용할 때 마이크가 켜져 있는지 확인하십시오. 그런 다음 스페이스바를 길게 눌러 음성 명령을 말합니다. 이 입력은 프로토타입에서 다음 작업을 트리거합니다.
Auto-Animate를 사용하여 보다 역동적인 경험 만들기
애니메이션은 UI 디자인에 많은 이점을 제공합니다. 다음과 같은 명확한 기능적 목적을 제공합니다.
- 객체 간의 공간적 관계 전달(객체는 어디에서 왔습니까? 해당 객체는 관련이 있습니까?);
- 커뮤니케이션 어포던스(다음에 무엇을 할 수 있나요?)
그러나 기능적 목적이 애니메이션의 유일한 이점은 아닙니다. 애니메이션은 또한 경험을 보다 생생하고 역동적으로 만듭니다. 이것이 UI 애니메이션이 다중 모드 인터페이스의 자연스러운 일부가 되어야 하는 이유입니다.
Adobe XD에서 사용할 수 있는 "Auto-Animate"를 사용하면 몰입형 애니메이션 전환으로 프로토타입을 훨씬 쉽게 만들 수 있습니다. Adobe XD가 모든 힘든 작업을 수행하므로 걱정할 필요가 없습니다. 두 아트보드 간에 애니메이션 전환을 생성하기 위해 해야 할 일은 아트보드를 복제하고 클론의 개체 속성(크기, 위치 및 회전과 같은 속성)을 수정하고 자동 애니메이트 작업을 적용하는 것입니다. XD는 각 아트보드 간의 속성 차이를 자동으로 애니메이션화합니다.
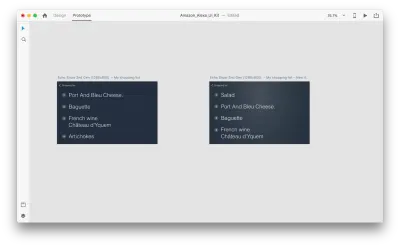
그것이 우리 디자인에서 어떻게 작동하는지 봅시다. Amazon Echo Show에 기존 쇼핑 목록이 있고 음성을 사용하여 목록에 새 객체를 추가하려고 한다고 가정합니다. 다음 아트보드를 복제합니다.
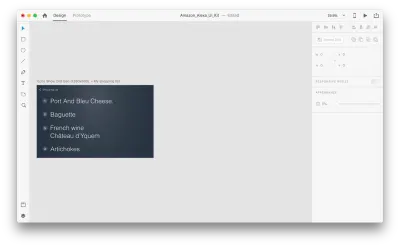
레이아웃에 몇 가지 변경 사항을 도입하겠습니다. 새 개체를 추가합니다. 여기에 제한이 없으므로 텍스트 속성, 색상, 불투명도, 개체 위치와 같은 속성을 쉽게 수정할 수 있습니다.
"Action"에서 Auto-Animate를 사용하여 프로토타입 모드에서 두 아트보드를 함께 연결하면 XD가 자동으로 각 아트보드 간의 속성 차이에 애니메이션을 적용합니다.
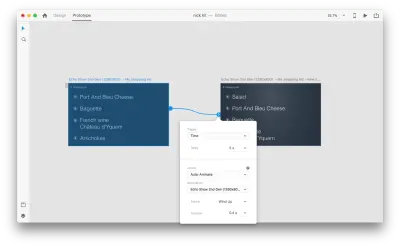
상호작용이 사용자에게 어떻게 보일지 보여줍니다.

언급해야 하는 한 가지 중요한 사항은 다음과 같습니다. 모든 레이어의 이름을 동일하게 유지합니다. 그렇지 않으면 Adobe XD에서 자동 애니메이션을 적용할 수 없습니다.
결론
우리는 사용자 인터페이스 혁명의 여명기에 있습니다. 새로운 세대의 인터페이스인 다중 모드 인터페이스는 사용자에게 더 많은 권한을 제공할 뿐만 아니라 사용자가 시스템과 상호 작용하는 방식도 바꿀 것입니다. We will probably still have displays, but we won't need keyboards to interact with the systems.
At the same time, the fundamental requirements for designing multimodal interfaces won't be much different from those of designing modern interfaces. Designers will need to keep the interaction simple; focus on the user and their needs; design, prototype, test and iterate.
And the great thing is that you don't need to wait to start designing for this new generation of interfaces. You can start today.
이 기사는 Adobe에서 후원하는 UX 디자인 시리즈의 일부입니다. Adobe XD 도구를 사용하면 아이디어에서 프로토타입으로 더 빠르게 이동할 수 있으므로 빠르고 유연한 UX 디자인 프로세스를 위해 만들어졌습니다. 하나의 앱에서 디자인, 프로토타입 및 공유가 모두 가능합니다. Behance에서 Adobe XD로 만든 더 많은 영감을 주는 프로젝트를 확인하고 Adobe 경험 디자인 뉴스레터에 등록하여 UX/UI 디자인에 대한 최신 트렌드와 통찰력에 대한 최신 정보를 받아볼 수 있습니다.