
구성 요소 기반 API 소개
게시 됨: 2022-03-10이 기사는 독자의 피드백에 대응하기 위해 2019년 1월 31일에 업데이트되었습니다. 저자는 구성 요소 기반 API에 사용자 정의 쿼리 기능을 추가했으며 작동 방식을 설명합니다 .
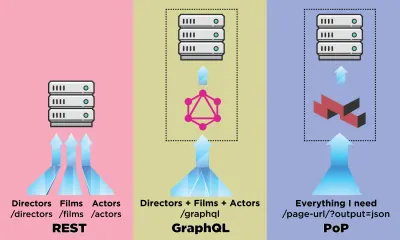
API는 애플리케이션이 서버에서 데이터를 로드하기 위한 통신 채널입니다. API 세계에서 REST는 보다 확립된 방법론이었지만 최근에는 REST보다 중요한 이점을 제공하는 GraphQL에 의해 가려졌습니다. REST는 구성 요소를 렌더링하기 위해 데이터 세트를 가져오기 위해 여러 HTTP 요청이 필요한 반면, GraphQL은 단일 요청에서 이러한 데이터를 쿼리하고 검색할 수 있으며 응답은 일반적으로 발생하는 데이터 초과 또는 부족 없이 필요한 것입니다. 쉬다.
이 기사에서는 내가 설계하고 "PoP"라고 부르는 데이터를 가져오는 또 다른 방법을 설명할 것입니다. 이 방법은 GraphQL이 도입한 단일 요청에서 여러 엔터티에 대한 데이터를 가져오는 아이디어를 확장한 것입니다. 한 단계 더 나아가, REST가 하나의 리소스에 대한 데이터를 가져오고 GraphQL이 한 구성 요소의 모든 리소스에 대한 데이터를 가져오는 동안 구성 요소 기반 API는 한 페이지의 모든 구성 요소에서 모든 리소스에 대한 데이터를 가져올 수 있습니다.
구성 요소 기반 API를 사용하는 것은 구성 요소를 사용하여 웹사이트 자체를 구축할 때 가장 의미가 있습니다. 예를 들어, 아래 이미지에 표시된 웹 페이지는 사각형으로 윤곽선이 표시된 구성 요소로 구축되었습니다.
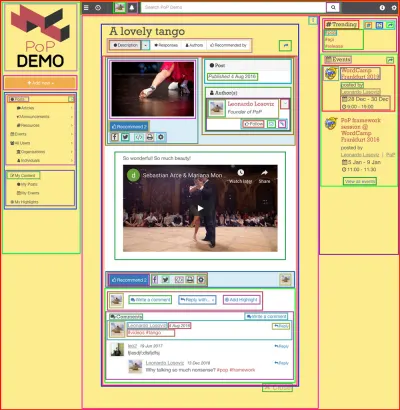
구성 요소 기반 API는 구성 요소 간의 관계를 API 구조 자체.
무엇보다도 이 구조는 다음과 같은 몇 가지 이점을 제공합니다.
- 많은 구성 요소가 있는 페이지는 많은 요청 대신 하나의 요청만 트리거합니다.
- 구성 요소 간에 공유되는 데이터는 DB에서 한 번만 가져오고 응답에서 한 번만 인쇄할 수 있습니다.
- 데이터 저장소의 필요성을 크게 줄이거나 완전히 제거할 수 있습니다.
기사 전체에서 이러한 내용을 자세히 살펴보겠지만 먼저 실제로 구성 요소가 무엇인지, 이러한 구성 요소를 기반으로 사이트를 구축하는 방법을 살펴보고 마지막으로 구성 요소 기반 API가 작동하는 방식을 살펴보겠습니다.
추천 자료 : GraphQL 입문서: 새로운 종류의 API가 필요한 이유
구성 요소를 통해 사이트 구축
구성 요소는 단순히 HTML, JavaScript 및 CSS 코드 조각의 집합입니다. 그런 다음 다른 구성 요소를 래핑하여 더 복잡한 구조를 생성하고 다른 구성 요소에 의해 자체적으로 래핑될 수도 있습니다. 구성 요소에는 매우 기본적인 것(예: 링크 또는 버튼)에서 매우 정교한 것(예: 캐러셀 또는 끌어서 놓기 이미지 업로더)에 이르기까지 다양한 목적이 있습니다. 구성 요소는 일반적이고 삽입된 속성(또는 "소품")을 통해 사용자 지정이 가능하여 광범위한 사용 사례를 제공할 수 있을 때 가장 유용합니다. 최대의 경우 사이트 자체가 구성 요소가 됩니다.
"구성 요소"라는 용어는 종종 기능과 디자인을 모두 나타내는 데 사용됩니다. 예를 들어 기능과 관련하여 React 또는 Vue와 같은 JavaScript 프레임워크는 자체 렌더링(예: API가 필요한 데이터를 가져온 후)이 가능한 클라이언트 측 구성 요소를 생성하고 props를 사용하여 구성 값을 설정할 수 있습니다. 래핑된 구성 요소로 코드 재사용이 가능합니다. 디자인과 관련하여 Bootstrap은 프론트 엔드 구성 요소 라이브러리를 통해 웹 사이트의 모양과 느낌을 표준화했으며 팀이 웹 사이트를 유지 관리하기 위해 디자인 시스템을 만드는 건전한 추세가 되었습니다. 마케터와 세일즈맨)은 통일된 언어를 사용하고 일관된 정체성을 표현합니다.
사이트를 구성 요소화하는 것은 웹 사이트를 유지 관리하기 쉽게 만드는 매우 합리적인 방법입니다. React 및 Vue와 같은 JavaScript 프레임워크를 사용하는 사이트는 이미 구성 요소 기반입니다(적어도 클라이언트 측에서는). Bootstrap과 같은 구성 요소 라이브러리를 사용한다고 해서 반드시 구성 요소 기반이 되는 것은 아니지만(HTML의 큰 덩어리가 될 수 있음) 사용자 인터페이스에 재사용 가능한 요소의 개념을 통합합니다.
사이트 가 HTML의 큰 덩어리인 경우 이를 구성 요소화하려면 레이아웃을 일련의 반복 패턴으로 분할해야 합니다. 이에 대해 기능 및 스타일의 유사성을 기반으로 페이지의 섹션을 식별하고 분류해야 하며 이러한 패턴을 분리해야 합니다. 섹션을 가능한 한 세분화하여 각 레이어가 단일 목표 또는 작업에 초점을 맞추도록 하고 여러 섹션에서 공통 레이어를 일치시키려고 합니다.
참고 : Brad Frost의 "Atomic Design"은 이러한 공통 패턴을 식별하고 재사용 가능한 디자인 시스템을 구축하기 위한 훌륭한 방법론입니다.
따라서 구성 요소를 통해 사이트를 구축하는 것은 LEGO를 가지고 노는 것과 유사합니다. 각 구성 요소는 원자적 기능, 다른 구성 요소의 구성 또는 둘의 조합입니다.
아래와 같이 기본 컴포넌트(아바타)는 상단의 웹페이지를 얻을 때까지 다른 컴포넌트에 의해 반복적으로 구성됩니다.

구성 요소 기반 API 사양
제가 디자인한 컴포넌트 기반 API의 경우 컴포넌트를 '모듈'이라고 부르므로 앞으로 '컴포넌트'와 '모듈'이라는 용어를 혼용합니다.
최상위 모듈에서 마지막 레벨까지 서로를 감싸는 모든 모듈의 관계를 "구성 요소 계층"이라고 합니다. 이 관계는 서버 측의 연관 배열(key => 속성의 배열)을 통해 표현될 수 있습니다. 여기에서 각 모듈은 이름을 키 속성으로 명시하고 내부 모듈은 속성 modules 아래에 있습니다. 그런 다음 API는 이 배열을 소비를 위한 JSON 객체로 간단히 인코딩합니다.
// Component hierarchy on server-side, eg through PHP: [ "top-module" => [ "modules" => [ "module-level1" => [ "modules" => [ "module-level11" => [ "modules" => [...] ], "module-level12" => [ "modules" => [ "module-level121" => [ "modules" => [...] ] ] ] ] ], "module-level2" => [ "modules" => [ "module-level21" => [ "modules" => [...] ] ] ] ] ] ] // Component hierarchy encoded as JSON: { "top-module": { modules: { "module-level1": { modules: { "module-level11": { ... }, "module-level12": { modules: { "module-level121": { ... } } } } }, "module-level2": { modules: { "module-level21": { ... } } } } } }모듈 간의 관계는 엄격한 하향식 방식으로 정의됩니다. 모듈은 다른 모듈을 래핑하고 자신이 누구인지 알지만 어떤 모듈이 자신을 래핑하는지 알지 못합니다.
예를 들어 위의 JSON 코드에서 module-level1 은 모듈 module-level11 및 module-level12 를 래핑한다는 것을 알고 있으며 이행적으로 module-level121 도 래핑한다는 것을 알고 있습니다. 그러나 module module-level11 은 누가 그것을 래핑하는지 상관하지 않으므로 결과적으로 module-level1 을 인식하지 못합니다.
구성 요소 기반 구조를 가지므로 이제 각 모듈에 필요한 실제 정보를 추가할 수 있습니다. 이 정보는 설정(예: 구성 값 및 기타 속성)과 데이터(예: 쿼리된 데이터베이스 개체 및 기타 속성의 ID)로 분류됩니다. , 그리고 이에 따라 modulesettings 및 moduledata 항목 아래에 배치됩니다.
{ modulesettings: { "top-module": { configuration: {...}, ..., modules: { "module-level1": { configuration: {...}, ..., modules: { "module-level11": { repeat... }, "module-level12": { configuration: {...}, ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { configuration: {...}, ..., modules: { "module-level21": { repeat... } } } } } }, moduledata: { "top-module": { dbobjectids: [...], ..., modules: { "module-level1": { dbobjectids: [...], ..., modules: { "module-level11": { repeat... }, "module-level12": { dbobjectids: [...], ..., modules: { "module-level121": { repeat... } } } } }, "module-level2": { dbobjectids: [...], ..., modules: { "module-level21": { repeat... } } } } } } } 다음으로 API는 데이터베이스 개체 데이터를 추가합니다. 이 정보는 각 모듈 아래에 배치되지 않고 databases 라는 공유 섹션 아래에 배치되어 두 개 이상의 다른 모듈이 데이터베이스에서 동일한 객체를 가져올 때 정보가 중복되는 것을 방지합니다.
또한 API는 데이터베이스 개체 데이터를 관계형으로 표현하여 두 개 이상의 서로 다른 데이터베이스 개체가 공통 개체(예: 작성자가 동일한 두 개의 게시물)와 관련된 경우 정보가 중복되는 것을 방지합니다. 즉, 데이터베이스 개체 데이터가 정규화됩니다.
추천 자료 : 정적 사이트를 위한 서버리스 문의 양식 작성
구조는 먼저 각 객체 유형 아래에 구성된 사전이며, 두 번째로 객체 ID로 구성되어 객체 속성을 얻을 수 있습니다.
{ databases: { primary: { dbobject_type: { dbobject_id: { property: ..., ... }, ... }, ... } } }이 JSON 개체는 이미 구성 요소 기반 API의 응답입니다. 그 형식은 그 자체로 사양입니다. 서버가 필요한 형식으로 JSON 응답을 반환하는 한 클라이언트는 구현 방법과 독립적으로 API를 사용할 수 있습니다. 따라서 API는 모든 언어에서 구현될 수 있습니다(이는 GraphQL의 장점 중 하나입니다. 실제 구현이 아닌 사양이기 때문에 수많은 언어에서 사용할 수 있게 되었습니다.)
참고 : 다음 기사에서 PHP로 구성 요소 기반 API를 구현하는 방법에 대해 설명하겠습니다(리포지토리에서 사용 가능한 API).
API 응답 예시
예를 들어 아래 API 응답에는 두 개의 모듈 page => post-feed 가 있는 구성 요소 계층이 포함되어 있습니다. 여기서 모듈 post-feed 블로그 게시물을 가져옵니다. 다음 사항에 유의하십시오.
- 각 모듈은 속성
dbobjectids(블로그 게시물의 경우 ID4및9)에서 쿼리된 개체가 무엇인지 알고 있습니다. - 각 모듈은
dbkeys속성에서 쿼리된 개체에 대한 개체 유형을 알고 있습니다(각 게시물의 데이터는posts아래에 있으며, 게시물의 작성자 데이터는 게시물의 속성author아래에 제공된 ID를 가진 작성자에 해당하며users아래에 있습니다). - 데이터베이스 개체 데이터는 관계형이므로 속성
author는 작성자 데이터를 직접 인쇄하는 대신 작성자 개체에 대한 ID를 포함합니다.
{ moduledata: { "page": { modules: { "post-feed": { dbobjectids: [4, 9] } } } }, modulesettings: { "page": { modules: { "post-feed": { dbkeys: { id: "posts", author: "users" } } } } }, databases: { primary: { posts: { 4: { title: "Hello World!", author: 7 }, 9: { title: "Everything fine?", author: 7 } }, users: { 7: { name: "Leo" } } } } }리소스 기반, 스키마 기반 및 구성 요소 기반 API에서 데이터 가져오기의 차이점
PoP와 같은 컴포넌트 기반 API가 데이터를 가져올 때 REST와 같은 리소스 기반 API와 GraphQL과 같은 스키마 기반 API를 어떻게 비교하는지 알아보겠습니다.
IMDB에 데이터를 가져와야 하는 두 가지 구성 요소가 있는 페이지가 있다고 가정해 보겠습니다. "추천 감독"(조지 루카스에 대한 설명과 그의 영화 목록 표시) 및 "추천 영화"( 스타워즈: 에피소드 I 와 같은 영화 표시) — 유령의 위협 과 터미네이터 ). 다음과 같이 보일 수 있습니다.
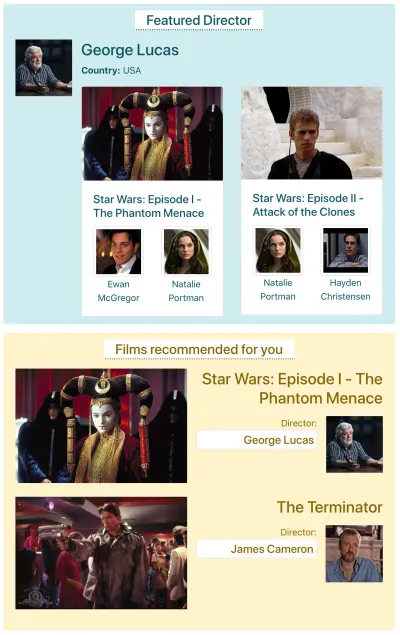
각 API 메소드를 통해 데이터를 가져오기 위해 얼마나 많은 요청이 필요한지 알아보겠습니다. 이 예에서 "추천 감독" 구성 요소는 하나의 결과("조지 루카스")를 가져오며, 여기서 두 개의 영화( 스타워즈: 에피소드 I — 유령의 위협 및 스타워즈: 에피소드 II — 클론의 습격 )를 검색합니다. 각 영화에 두 명의 배우가 있습니다(첫 번째 영화의 경우 "Ewan McGregor"와 "Natalie Portman", 두 번째 영화의 경우 "Natalie Portman"과 "Hayden Christensen"). "추천 영화" 구성 요소는 두 개의 결과( 스타워즈: 에피소드 I — 유령의 위협 및 터미네이터 )를 가져온 다음 해당 감독(각각 "조지 루카스" 및 "제임스 카메론")을 가져옵니다.
REST를 사용하여 component featured-director 를 렌더링하려면 다음 7개의 요청이 필요할 수 있습니다(이 수는 각 엔드포인트에서 제공하는 데이터의 양, 즉 얼마나 많은 오버페치가 구현되었는지에 따라 달라질 수 있음).
GET - /featured-director GET - /directors/george-lucas GET - /films/the-phantom-menace GET - /films/attack-of-the-clones GET - /actors/ewan-mcgregor GET - /actors/natalie-portman GET - /actors/hayden-christensen GraphQL을 사용하면 강력한 형식의 스키마를 통해 구성 요소당 하나의 단일 요청으로 필요한 모든 데이터를 가져올 수 있습니다. FeaturedDirector 구성 요소에 대해 featuredDirector 을 통해 데이터를 가져오는 쿼리는 다음과 같습니다(해당 스키마를 구현한 후).
query { featuredDirector { name country avatar films { title thumbnail actors { name avatar } } } }그리고 다음과 같은 응답을 생성합니다.
{ data: { featuredDirector: { name: "George Lucas", country: "USA", avatar: "...", films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", actors: [ { name: "Ewan McGregor", avatar: "...", }, { name: "Natalie Portman", avatar: "...", } ] }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "...", actors: [ { name: "Natalie Portman", avatar: "...", }, { name: "Hayden Christensen", avatar: "...", } ] } ] } } }그리고 "추천 영화" 구성 요소를 쿼리하면 다음과 같은 응답이 생성됩니다.
{ data: { films: [ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "...", director: { name: "George Lucas", avatar: "...", } }, { title: "The Terminator", thumbnail: "...", director: { name: "James Cameron", avatar: "...", } } ] } } PoP는 페이지의 모든 구성 요소에 대한 모든 데이터를 가져오고 결과를 정규화하기 위해 단 한 번의 요청만 발행합니다. 호출할 끝점은 단순히 데이터를 가져와야 하는 URL과 동일합니다. 데이터를 HTML로 인쇄하는 대신 JSON 형식으로 가져오도록 나타내는 추가 매개변수 output=json 을 추가하기만 하면 됩니다.
GET - /url-of-the-page/?output=json 모듈 구조에 featured-director 및 films-recommended-for-you 모듈이 포함된 page 라는 이름의 최상위 모듈이 있고 다음과 같은 하위 모듈도 있다고 가정합니다.
"page" modules "featured-director" modules "director-films" modules "film-actors" "films-recommended-for-you" modules "film-director"반환된 단일 JSON 응답은 다음과 같습니다.
{ modulesettings: { "page": { modules: { "featured-director": { dbkeys: { id: "people", }, modules: { "director-films": { dbkeys: { films: "films" }, modules: { "film-actors": { dbkeys: { actors: "people" }, } } } } }, "films-recommended-for-you": { dbkeys: { id: "films", }, modules: { "film-director": { dbkeys: { director: "people" }, } } } } } }, moduledata: { "page": { modules: { "featured-director": { dbobjectids: [1] }, "films-recommended-for-you": { dbobjectids: [1, 3] } } } }, databases: { primary: { people { 1: { name: "George Lucas", country: "USA", avatar: "..." films: [1, 2] }, 2: { name: "Ewan McGregor", avatar: "..." }, 3: { name: "Natalie Portman", avatar: "..." }, 4: { name: "Hayden Christensen", avatar: "..." }, 5: { name: "James Cameron", avatar: "..." }, }, films: { 1: { title: "Star Wars: Episode I - The Phantom Menace", actors: [2, 3], director: 1, thumbnail: "..." }, 2: { title: "Star Wars: Episode II - Attack of the Clones", actors: [3, 4], thumbnail: "..." }, 3: { title: "The Terminator", director: 5, thumbnail: "..." }, } } } }이 세 가지 방법이 검색되는 데이터의 속도와 양 측면에서 어떻게 서로 비교되는지 분석해 보겠습니다.
속도
REST를 통해 하나의 구성 요소를 렌더링하기 위해 7개의 요청을 가져와야 하는 것은 대부분 모바일 및 불안정한 데이터 연결에서 매우 느릴 수 있습니다. 따라서 REST에서 GraphQL로의 이동은 단 한 번의 요청으로 구성 요소를 렌더링할 수 있기 때문에 속도 면에서 큰 의미가 있습니다.
PoP는 하나의 요청으로 많은 구성 요소에 대한 모든 데이터를 가져올 수 있기 때문에 한 번에 많은 구성 요소를 렌더링하는 데 더 빠릅니다. 그러나 이것이 필요하지 않을 가능성이 큽니다. 구성 요소를 순서대로(페이지에 표시되는 대로) 렌더링하는 것은 이미 좋은 방법이며, 스크롤 없이 표시되는 구성 요소의 경우에는 렌더링을 서두르지 않아도 됩니다. 따라서 스키마 기반 API와 구성 요소 기반 API는 이미 리소스 기반 API보다 훨씬 우수하고 우수합니다.
데이터 양
각 요청에서 GraphQL 응답의 데이터는 복제될 수 있습니다. 첫 번째 구성 요소의 응답에서 여배우 "Natalie Portman"을 두 번 가져오고 두 구성 요소에 대한 공동 출력을 고려할 때 영화와 같은 공유 데이터도 찾을 수 있습니다. 스타워즈: 에피소드 I — 유령의 위협 .
반면에 PoP는 데이터베이스 데이터를 정규화하고 한 번만 인쇄하지만 모듈 구조를 인쇄하는 오버헤드를 수반합니다. 따라서 중복 데이터가 있는 특정 요청에 따라 스키마 기반 API 또는 구성 요소 기반 API의 크기가 더 작아집니다.
결론적으로 GraphQL과 같은 스키마 기반 API와 PoP와 같은 컴포넌트 기반 API는 성능면에서 유사하며 REST와 같은 리소스 기반 API보다 우수합니다.
추천 자료 : REST API 이해 및 사용
구성 요소 기반 API의 특정 속성
구성 요소 기반 API가 스키마 기반 API보다 성능 면에서 반드시 더 좋지 않은 경우 이 기사를 통해 내가 무엇을 달성하려고 하는지 궁금할 것입니다.
이 섹션에서는 그러한 API가 놀라운 잠재력을 가지고 있으며 매우 바람직한 몇 가지 기능을 제공하여 API 세계에서 강력한 경쟁자가 될 수 있음을 확신시켜 드리고자 합니다. 아래에서 각각의 고유한 뛰어난 기능을 설명하고 시연합니다.
데이터베이스에서 검색할 데이터는 구성 요소 계층에서 추론할 수 있습니다.
모듈이 DB 개체의 속성을 표시할 때 모듈은 그것이 어떤 개체인지 알지 못하거나 신경 쓰지 않을 수 있습니다. 중요한 것은 로드된 개체에서 필요한 속성을 정의하는 것뿐입니다.
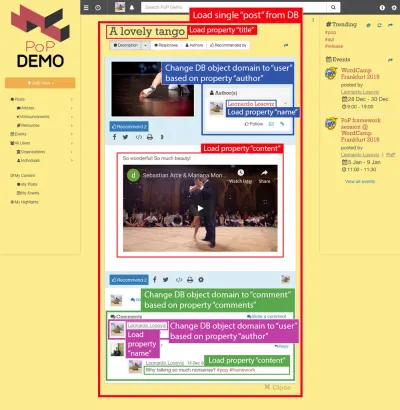
예를 들어, 아래 이미지를 고려하십시오. 모듈은 데이터베이스에서 객체를 로드하고(이 경우 단일 게시물), 그 하위 모듈은 title 및 content 과 같은 객체의 특정 속성을 표시합니다.
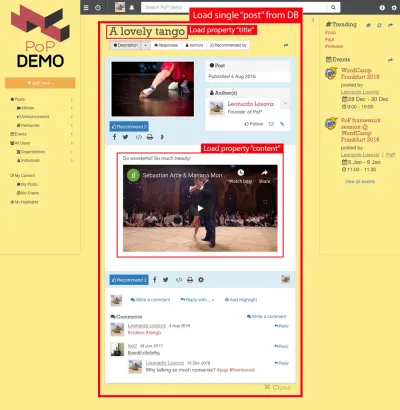
따라서 구성 요소 계층 구조를 따라 "dataloading" 모듈은 쿼리된 개체(이 경우 단일 게시물을 로드하는 모듈) 로드를 담당하고 하위 모듈은 DB 개체의 어떤 속성이 필요한지 정의합니다( title 및 content , 이 경우).
DB 개체에 필요한 모든 속성을 가져오는 것은 구성 요소 계층을 순회하여 자동으로 수행할 수 있습니다. 데이터 로드 모듈에서 시작하여 새 데이터 로드 모듈에 도달하거나 트리가 끝날 때까지 모든 하위 모듈을 반복합니다. 각 수준에서 필요한 모든 속성을 얻은 다음 모든 속성을 병합하고 데이터베이스에서 쿼리합니다. 모두 한 번만 가능합니다.
아래 구조에서 single-post 모듈은 DB(ID가 37인 게시물)에서 결과를 가져오고, 하위 모듈 post-title 및 post-content 는 쿼리된 DB 개체(각각 title 및 content )에 대해 로드할 속성을 정의합니다. 하위 모듈 post-layout 및 fetch-next-post-button 에는 데이터 필드가 필요하지 않습니다.
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "fetch-next-post-button"실행할 쿼리는 모든 모듈과 해당 하위 모듈에 필요한 모든 속성을 포함하는 구성 요소 계층 및 필수 데이터 필드에서 자동으로 계산됩니다.
SELECT title, content FROM posts WHERE id = 37 모듈에서 직접 검색할 속성을 가져오면 구성 요소 계층이 변경될 때마다 쿼리가 자동으로 업데이트됩니다. 예를 들어, 데이터 필드 thumbnail 이 필요한 하위 모듈 post-thumbnail 을 추가하면 다음과 같습니다.
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-thumbnail" => Load property "thumbnail" "fetch-next-post-button"그런 다음 쿼리가 자동으로 업데이트되어 추가 속성을 가져옵니다.
SELECT title, content, thumbnail FROM posts WHERE id = 37관계형으로 검색할 데이터베이스 개체 데이터를 설정했기 때문에 데이터베이스 개체 자체 간의 관계에도 이 전략을 적용할 수 있습니다.
아래 이미지를 고려하십시오. 객체 유형 post 에서 시작하여 구성 요소 계층 구조 아래로 이동하여 DB 객체 유형을 user 및 comment 로 각각 이동해야 합니다. 주석의 경우 해당 주석 작성자에 해당하는 user 로 개체 유형을 다시 한 번 변경해야 합니다.
데이터베이스 객체에서 관계형 객체로 이동하는 것( post => author 가 post 에서 user 로 이동하거나 author => 팔로워가 user 에서 user 로 이동하는 것과 같이 객체 유형을 변경할 수 있음)은 내가 "도메인 전환"이라고 부르는 것입니다. ".
새 도메인으로 전환한 후 구성 요소 계층의 해당 수준에서 아래쪽으로 모든 필수 속성이 새 도메인에 종속됩니다.
-
user개체(게시물의 작성자를 나타냄)에서name을 가져옵니다. -
content는comment개체(각 게시물의 댓글을 나타냄)에서 가져옵니다. -
name은user개체(각 주석의 작성자를 나타냄)에서 가져옵니다.
API는 구성 요소 계층을 순회하면서 새 도메인으로 전환할 때를 알고 적절하게 쿼리를 업데이트하여 관계형 개체를 가져옵니다.
예를 들어 게시물 작성자의 데이터를 표시해야 하는 경우 스택 하위 모듈 post-author 는 해당 수준의 도메인을 post 에서 해당 user 로 변경하고 이 수준에서 아래로 모듈에 전달된 컨텍스트에 로드된 DB 개체는 다음과 같습니다. 사용자. 그런 다음 post-author 아래의 하위 모듈 user-name 및 user-avatar 는 user 개체 아래에 속성 name 및 avatar 를 로드합니다.
"single-post" => Load objects with object type "post" and ID 37 modules "post-layout" modules "post-title" => Load property "title" "post-content" => Load property "content" "post-author" => Switch domain from "post" to "user", based on property "author" modules "user-layout" modules "user-name" => Load property "name" "user-avatar" => Load property "avatar" "fetch-next-post-button"다음 쿼리 결과:
SELECT p.title, p.content, p.author, u.name, u.avatar FROM posts p INNER JOIN users u WHERE p.id = 37 AND p.author = u.id요약하면, 각 모듈을 적절하게 구성하면 구성 요소 기반 API에 대한 데이터를 가져오기 위해 쿼리를 작성할 필요가 없습니다. 쿼리는 구성 요소 계층 구조 자체에서 자동으로 생성되어 데이터 로드 모듈에서 로드해야 하는 개체, 각 자손 모듈에 정의된 로드된 각 개체에 대해 검색할 필드 및 각 자손 모듈에 정의된 도메인 전환을 얻습니다.
모듈을 추가, 제거, 교체 또는 변경하면 쿼리가 자동으로 업데이트됩니다. 쿼리를 실행한 후 검색된 데이터는 그 이상도 이하도 아닌 정확히 필요한 것입니다.
데이터 관찰 및 추가 속성 계산
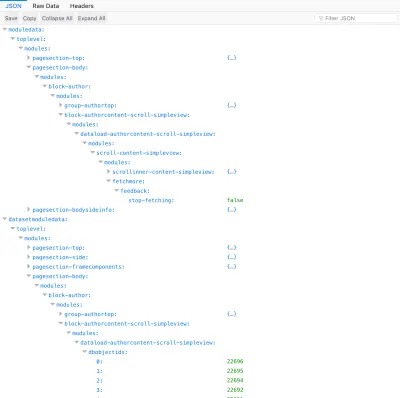
데이터 로드 모듈에서 시작하여 구성 요소 계층 구조 아래로 모든 모듈은 반환된 결과를 관찰하고 이를 기반으로 추가 데이터 항목을 계산하거나 입력 moduledata 아래에 있는 feedback 값을 계산할 수 있습니다.
예를 들어, fetch-next-post-button 모듈은 가져올 결과가 더 있는지 여부를 나타내는 속성을 추가할 수 있습니다(이 피드백 값에 따라 결과가 더 없으면 버튼이 비활성화되거나 숨겨집니다).
{ moduledata: { "page": { modules: { "single-post": { modules: { "fetch-next-post-button": { feedback: { hasMoreResults: true } } } } } } } }필수 데이터에 대한 암묵적인 지식은 복잡성을 줄이고 "종점" 개념을 무용지물로 만듭니다.
위와 같이 컴포넌트 기반 API는 서버에 있는 모든 컴포넌트의 모델과 각 컴포넌트에 필요한 데이터 필드가 있기 때문에 필요한 데이터를 정확히 가져올 수 있습니다. 그런 다음 필요한 데이터 필드에 대한 지식을 암시적으로 만들 수 있습니다.
이점은 구성 요소에 필요한 데이터를 정의하는 것이 JavaScript 파일을 다시 배포할 필요 없이 서버 측에서 업데이트될 수 있다는 것입니다. , 따라서 클라이언트 측 응용 프로그램의 복잡성을 줄입니다.
또한 특정 URL에 대한 모든 구성 요소에 대한 데이터를 검색하기 위해 API를 호출하는 것은 해당 URL을 쿼리하고 페이지를 인쇄하는 대신 API 데이터 반환을 나타내는 추가 매개변수 output=json 을 추가하여 간단히 수행할 수 있습니다. 따라서 URL은 자체 엔드포인트가 되거나 다른 방식으로 고려하면 "엔드포인트" 개념이 더 이상 사용되지 않습니다.
데이터의 하위 집합 검색: 구성 요소 계층 구조의 모든 수준에서 찾을 수 있는 특정 모듈에 대한 데이터를 가져올 수 있습니다.
페이지의 모든 모듈에 대한 데이터를 가져올 필요가 없고 구성 요소 계층의 모든 수준에서 시작하는 특정 모듈에 대한 데이터만 가져오면 어떻게 될까요? 예를 들어 모듈이 무한 스크롤을 구현하는 경우 아래로 스크롤할 때 페이지의 다른 모듈이 아니라 이 모듈에 대한 새 데이터만 가져와야 합니다.

이는 응답에 포함될 구성 요소 계층의 분기를 필터링하여 지정된 모듈에서 시작하는 속성만 포함하고 이 수준 이상의 모든 것을 무시하도록 하여 수행할 수 있습니다. 내 구현에서(다음 기사에서 설명할 예정) URL에 modulefilter=modulepaths 매개변수를 추가하여 필터링을 활성화하고 선택한 모듈(또는 모듈들)을 modulepaths[] 매개변수를 통해 표시합니다. 여기서 "모듈 경로 "는 최상위 모듈에서 시작하여 특정 모듈까지의 모듈 목록입니다(예: module1 => module2 => module3 에는 모듈 경로가 [ module1 , module2 , module3 ]이고 URL 매개변수로 module1.module2.module3 로 전달됨). .
예를 들어, 모든 모듈 아래의 구성 요소 계층에는 dbobjectids 항목이 있습니다.
"module1" dbobjectids: [...] modules "module2" dbobjectids: [...] modules "module3" dbobjectids: [...] "module4" dbobjectids: [...] "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] 그런 다음 modulefilter=modulepaths 및 modulepaths[]=module1.module2.module5 매개변수를 추가하는 웹 페이지 URL을 요청하면 다음 응답이 생성됩니다.
"module1" modules "module2" modules "module5" dbobjectids: [...] modules "module6" dbobjectids: [...] 본질적으로 API는 module1 => module2 => module5 부터 데이터 로드를 시작합니다. 이것이 module6 아래에 있는 module5 도 데이터를 가져오는 반면 module3 및 module4 는 그렇지 않은 이유입니다.
또한 미리 정렬된 모듈 집합을 포함하도록 사용자 지정 모듈 필터를 만들 수 있습니다. 예를 들어 modulefilter=userstate 로 페이지를 호출하면 module3 및 module6 과 같이 클라이언트에서 렌더링하기 위해 사용자 상태가 필요한 모듈만 인쇄할 수 있습니다.
"module1" modules "module2" modules "module3" dbobjectids: [...] "module5" modules "module6" dbobjectids: [...] 시작 모듈에 대한 정보는 모듈 경로의 배열로 filteredmodules 항목 아래 requestmeta 섹션에 있습니다.
requestmeta: { filteredmodules: [ ["module1", "module2", "module3"], ["module1", "module2", "module5", "module6"] ] }이 기능을 사용하면 사이트의 프레임이 초기 요청에 로드되는 복잡하지 않은 단일 페이지 애플리케이션을 구현할 수 있습니다.
"page" modules "navigation-top" dbobjectids: [...] "navigation-side" dbobjectids: [...] "page-content" dbobjectids: [...] 그러나 이제부터는 요청된 모든 URL에 modulefilter=page 매개변수를 추가하여 프레임을 필터링하고 페이지 콘텐츠만 가져올 수 있습니다.
"page" modules "navigation-top" "navigation-side" "page-content" dbobjectids: [...] 위에서 설명한 모듈 필터 userstate 및 page 와 유사하게 사용자 정의 모듈 필터를 구현하고 풍부한 사용자 경험을 생성할 수 있습니다.
모듈은 자체 API입니다.
위에 표시된 대로 API 응답을 필터링하여 모든 모듈에서 시작하는 데이터를 검색할 수 있습니다. 결과적으로 모든 모듈은 모듈이 포함된 웹 페이지 URL에 모듈 경로를 추가하기만 하면 클라이언트에서 서버로 자체적으로 상호 작용할 수 있습니다.
나는 당신이 나의 지나친 흥분을 용서해주기를 바랍니다. 그러나 나는 진정으로 이 기능이 얼마나 훌륭한지 충분히 강조할 수 없습니다. 구성 요소를 만들 때 구성 요소가 이미 서버에서 자체적으로 통신하고 자체 로드할 수 있기 때문에 데이터(REST, GraphQL 또는 기타 모든 것)를 검색하기 위해 함께 사용할 API를 만들 필요가 없습니다. 데이터 — 완전히 자율적이며 자급자족 합니다.
각 데이터 로딩 모듈은 datasetmodulemeta 섹션의 dataloadsource 항목에서 상호 작용하기 위해 URL을 내보냅니다.
{ datasetmodulemeta: { "module1": { modules: { "module2": { modules: { "module5": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5" }, modules: { "module6": { meta: { dataloadsource: "https://page-url/?modulefilter=modulepaths&modulepaths[]=module1.module2.module5.module6" } } } } } } } } } }데이터 가져오기는 모듈과 DRY에서 분리됩니다.
구성 요소 기반 API에서 데이터를 가져오는 것이 고도로 분리되고 DRY( D 는 반복되지 않음 )라는 점을 강조하기 위해 먼저 GraphQL 과 같은 스키마 기반 API에서 어떻게 덜 분리되고 건조하지 않습니다.
GraphQL에서 데이터를 가져오는 쿼리는 하위 구성 요소를 포함할 수 있는 구성 요소의 데이터 필드를 나타내야 하며 여기에는 하위 구성 요소 등이 포함될 수도 있습니다. 그런 다음 최상위 구성 요소는 해당 데이터를 가져오기 위해 모든 하위 구성 요소에 필요한 데이터를 알아야 합니다.
예를 들어, <FeaturedDirector> 구성 요소를 렌더링하려면 다음 하위 구성 요소가 필요할 수 있습니다.
Render <FeaturedDirector>: <div> Country: {country} {foreach films as film} <Film film={film} /> {/foreach} </div> Render <Film>: <div> Title: {title} Pic: {thumbnail} {foreach actors as actor} <Actor actor={actor} /> {/foreach} </div> Render <Actor>: <div> Name: {name} Photo: {avatar} </div> 이 시나리오에서 GraphQL 쿼리는 <FeaturedDirector> 수준에서 구현됩니다. 그런 다음 하위 구성 요소 <Film> 이 업데이트되고 title 대신 filmTitle 속성을 통해 title 을 요청하면 이 새로운 정보를 미러링하기 위해 <FeaturedDirector> 구성 요소의 쿼리도 업데이트해야 합니다(GraphQL에는 다음을 처리할 수 있는 버전 관리 메커니즘이 있습니다. 하지만 조만간 정보를 업데이트해야 합니다.) 이로 인해 내부 구성 요소가 자주 변경되거나 타사 개발자가 생성하는 경우 처리하기 어려울 수 있는 유지 관리 복잡성이 발생합니다. 따라서 구성 요소는 서로 완전히 분리되지 않습니다.
유사하게, 특정 영화에 대한 <Film> 구성 요소를 직접 렌더링하고 싶을 수도 있습니다. 그런 다음 이 수준에서 GraphQL 쿼리도 구현하여 영화와 그 배우에 대한 데이터를 가져와야 하며, 이는 중복 코드를 추가합니다. 동일한 쿼리는 구성 요소 구조의 다른 수준에 있습니다. 따라서 GraphQL은 DRY가 아닙니다 .
구성 요소 기반 API는 구성 요소가 자체 구조에서 서로를 감싸는 방법을 이미 알고 있기 때문에 이러한 문제를 완전히 피할 수 있습니다. 첫째, 클라이언트는 이 데이터가 무엇이든 간에 필요한 필수 데이터를 간단히 요청할 수 있습니다. if a subcomponent data field changes, the overall model already knows and adapts immediately, without having to modify the query for the parent component in the client. Therefore, the modules are highly decoupled from each other.
For another, we can fetch data starting from any module path, and it will always return the exact required data starting from that level; there are no duplicated queries whatsoever, or even queries to start with. Hence, a component-based API is fully DRY . (This is another feature that really excites me and makes me get wet.)
(Yes, pun fully intended. Sorry about that.)
Retrieving Configuration Values In Addition To Database Data
Let's revisit the example of the featured-director component for the IMDB site described above, which was created — you guessed it! — with Bootstrap. Instead of hardcoding the Bootstrap classnames or other properties such as the title's HTML tag or the avatar max width inside of JavaScript files (whether they are fixed inside the component, or set through props by parent components), each module can set these as configuration values through the API, so that then these can be directly updated on the server and without the need to redeploy JavaScript files. Similarly, we can pass strings (such as the title Featured director ) which can be already translated/internationalized on the server-side, avoiding the need to deploy locale configuration files to the front-end.
Similar to fetching data, by traversing the component hierarchy, the API is able to deliver the required configuration values for each module and nothing more or less.
The configuration values for the featured-director component might look like this:
{ modulesettings: { "page": { modules: { "featured-director": { configuration: { class: "alert alert-info", title: "Featured director", titletag: "h3" }, modules: { "director-films": { configuration: { classes: { wrapper: "media", avatar: "mr-3", body: "media-body", films: "row", film: "col-sm-6" }, avatarmaxsize: "100px" }, modules: { "film-actors": { configuration: { classes: { wrapper: "card", image: "card-img-top", body: "card-body", title: "card-title", avatar: "img-thumbnail" } } } } } } } } } } } Please notice how — because the configuration properties for different modules are nested under each module's level — these will never collide with each other if having the same name (eg property classes from one module will not override property classes from another module), avoiding having to add namespaces for modules.
Higher Degree Of Modularity Achieved In The Application
According to Wikipedia, modularity means:
The degree to which a system's components may be separated and recombined, often with the benefit of flexibility and variety in use. The concept of modularity is used primarily to reduce complexity by breaking a system into varying degrees of interdependence and independence across and 'hide the complexity of each part behind an abstraction and interface'.
Being able to update a component just from the server-side, without the need to redeploy JavaScript files, has the consequence of better reusability and maintenance of components. I will demonstrate this by re-imagining how this example coded for React would fare in a component-based API.
Let's say that we have a <ShareOnSocialMedia> component, currently with two items: <FacebookShare> and <TwitterShare> , like this:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> </ul> But then Instagram got kind of cool, so we need to add an item <InstagramShare> to our <ShareOnSocialMedia> component, too:
Render <ShareOnSocialMedia>: <ul> <li>Share on Facebook: <FacebookShare url={window.location.href} /></li> <li>Share on Twitter: <TwitterShare url={window.location.href} /></li> <li>Share on Instagram: <InstagramShare url={window.location.href} /></li> </ul> In the React implementation, as it can be seen in the linked code, adding a new component <InstagramShare> under component <ShareOnSocialMedia> forces to redeploy the JavaScript file for the latter one, so then these two modules are not as decoupled as they could be.
그러나 구성 요소 기반 API에서는 이미 API에 설명된 모듈 간의 관계를 사용하여 모듈을 함께 연결할 수 있습니다. 원래는 다음과 같은 응답이 있습니다.
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} } } } } }Instagram을 추가하면 다음과 같이 업그레이드된 응답을 받게 됩니다.
{ modulesettings: { "share-on-social-media": { modules: { "facebook-share": { configuration: {...} }, "twitter-share": { configuration: {...} }, "instagram-share": { configuration: {...} } } } } } modulesettings["share-on-social-media"].modules 아래의 모든 값을 반복하기만 하면 JavaScript 파일을 다시 배포할 필요 없이 <ShareOnSocialMedia> 구성 요소를 업그레이드하여 <InstagramShare> 구성 요소를 표시할 수 있습니다. 따라서 API는 다른 모듈의 코드를 손상시키지 않고 모듈의 추가 및 제거를 지원하여 더 높은 수준의 모듈성을 달성합니다.
네이티브 클라이언트 측 캐시/데이터 저장소
검색된 데이터베이스 데이터는 사전 구조로 정규화되고 표준화되어 dbobjectids 의 값에서 시작하여 dbkeys 항목을 통해 표시된 대로 databases 아래의 모든 데이터 조각에 도달할 수 있습니다. . 따라서 데이터를 구성하는 논리는 이미 API 자체에 기본적으로 포함되어 있습니다.
우리는 이 상황에서 여러 가지 이점을 얻을 수 있습니다. 예를 들어, 각 요청에 대해 반환된 데이터는 세션 전체에 걸쳐 사용자가 요청한 모든 데이터를 포함하는 클라이언트 측 캐시에 추가될 수 있습니다. 따라서 Redux와 같은 외부 데이터 저장소를 애플리케이션에 추가하는 것을 피할 수 있습니다(Undo/Redo, 협업 환경 또는 시간 여행 디버깅과 같은 다른 기능이 아니라 데이터 처리에 관한 것입니다).
또한 구성 요소 기반 구조는 캐싱을 촉진합니다. 구성 요소 계층은 URL이 아니라 해당 URL에 필요한 구성 요소에 따라 달라집니다. 이렇게 하면 /events/1/ 및 /events/2/ 아래의 두 이벤트가 동일한 구성 요소 계층 구조를 공유하고 필요한 모듈에 대한 정보를 이들 간에 다시 사용할 수 있습니다. 결과적으로 모든 속성(데이터베이스 데이터 제외)은 첫 번째 이벤트를 가져온 후 클라이언트에서 캐시되고 그때부터 재사용될 수 있으므로 각 후속 이벤트에 대한 데이터베이스 데이터만 가져와야 하고 다른 것은 가져오지 않아야 합니다.
확장성 및 용도 변경
API의 databases 섹션을 확장하여 해당 정보를 맞춤형 하위 섹션으로 분류할 수 있습니다. 기본적으로 모든 데이터베이스 개체 데이터는 primary 항목 아래에 배치되지만 특정 DB 개체 속성을 배치할 사용자 지정 항목을 만들 수도 있습니다.
예를 들어 앞서 설명한 "추천 영화" 구성 요소가 film DB 개체의 friendsWhoWatchedFilm 속성 아래 로그인한 사용자의 친구 목록을 표시하는 경우 이 값은 로그인한 사용자에 따라 변경되기 때문입니다. 그런 다음 사용자는 대신 이 속성을 userstate 항목 아래에 저장하므로 사용자가 로그아웃할 때 클라이언트의 캐시된 데이터베이스에서 이 분기만 삭제하지만 모든 primary 데이터는 여전히 남아 있습니다.
{ databases: { userstate: { films: { 5: { friendsWhoWatchedFilm: [22, 45] }, } }, primary: { films: { 5: { title: "The Terminator" }, } "people": { 22: { name: "Peter", }, 45: { name: "John", }, }, } } }또한 특정 시점까지 API 응답의 구조를 재조정할 수 있습니다. 특히 데이터베이스 결과는 기본 사전 대신 배열과 같은 다른 데이터 구조로 인쇄될 수 있습니다.
예를 들어, 객체 유형이 단 하나(예: films )인 경우 자동 완성 구성 요소에 직접 공급할 배열로 형식을 지정할 수 있습니다.
[ { title: "Star Wars: Episode I - The Phantom Menace", thumbnail: "..." }, { title: "Star Wars: Episode II - Attack of the Clones", thumbnail: "..." }, { title: "The Terminator", thumbnail: "..." }, ]Aspect 지향 프로그래밍 지원
데이터를 가져오는 것 외에도 구성 요소 기반 API는 게시물 작성 또는 댓글 추가와 같은 데이터를 게시하고 사용자 로그인 또는 로그아웃, 이메일 보내기, 로깅, 분석, 등등. 제한이 없습니다. 기본 CMS에서 제공하는 모든 기능은 모든 수준에서 모듈을 통해 호출할 수 있습니다.
구성 요소 계층 구조를 따라 원하는 수의 모듈을 추가할 수 있으며 각 모듈은 자체 작업을 실행할 수 있습니다. 따라서 REST에서 POST, PUT 또는 DELETE 작업을 수행하거나 GraphQL에서 변형을 보낼 때와 같이 모든 작업이 요청의 예상 작업과 반드시 관련되어야 하는 것은 아니지만 이메일 보내기와 같은 추가 기능을 제공하기 위해 추가할 수 있습니다. 사용자가 새 게시물을 작성할 때 관리자에게
따라서 종속성 주입 또는 구성 파일을 통해 구성 요소 계층을 정의함으로써 API는 Aspect 지향 프로그래밍을 지원한다고 말할 수 있습니다. "교차적인 문제를 분리하여 모듈성을 높이는 것을 목표로 하는 프로그래밍 패러다임"입니다.
추천 자료 : 기능 정책으로 사이트 보호
강화된 보안
모듈의 이름은 출력에 인쇄될 때 반드시 고정될 필요는 없지만 줄이거나, 임의로 변경하거나, (간단히) 의도한 대로 가변적으로 만들 수 있습니다. 원래 API 출력을 줄이기 위해 생각했지만(모듈 이름 carousel-featured-posts 또는 drag-and-drop-user-images 는 프로덕션 환경에 대해 a1 , a2 등과 같은 기본 64 표기법으로 단축될 수 있습니다.) ), 이 기능을 사용하면 보안상의 이유로 API의 응답에서 모듈 이름을 자주 변경할 수 있습니다.
예를 들어, 입력 이름은 기본적으로 해당 모듈로 명명됩니다. 그런 다음 클라이언트에서 각각 <input type="text" name="{input_name}"> 및 <input type="password" name="{input_name}"> 으로 렌더링되는 username 및 password 라는 모듈, 현재 c3oMLBjo 및 c46oVgN6 , 내일 zwH8DSeG 및 QBG7m6EF 과 같이 입력 이름에 대해 다양한 임의 값을 설정하여 스패머와 봇이 사이트를 대상으로 하는 것을 더 어렵게 만들 수 있습니다.
대체 모델을 통한 다양성
모듈을 중첩하면 다른 모듈로 분기하여 특정 매체 또는 기술에 대한 호환성을 추가하거나 일부 스타일 또는 기능을 변경한 다음 원래 분기로 돌아갈 수 있습니다.
예를 들어 웹 페이지가 다음과 같은 구조를 가지고 있다고 가정해 보겠습니다.
"module1" modules "module2" modules "module3" "module4" modules "module5" modules "module6" 이 경우 웹사이트를 AMP에서도 작동하도록 만들고 싶지만 모듈 module2 , module4 및 module5 는 AMP와 호환되지 않습니다. 이러한 모듈을 유사한 AMP 호환 모듈 module2AMP , module4AMP 및 module5AMP 로 분기할 수 있습니다. 그 후 원래 구성 요소 계층 구조를 계속 로드하므로 이 세 가지 모듈만 대체됩니다(다른 것은 없음).
"module1" modules "module2AMP" modules "module3" "module4AMP" modules "module5AMP" modules "module6"이렇게 하면 단일 코드베이스에서 다른 출력을 생성하는 것이 상당히 쉬워지고 필요에 따라 여기저기서만 포크를 추가하고 항상 범위가 개별 모듈로 제한되고 제한됩니다.
시연 시간
이 문서에 설명된 대로 API를 구현하는 코드는 이 오픈 소스 저장소에서 사용할 수 있습니다.
데모 목적으로 https://nextapi.getpop.org 에 PoP API를 배포했습니다. 웹 사이트는 WordPress에서 실행되므로 URL 영구 링크는 WordPress에 일반적인 것입니다. 앞서 언급했듯이 output=json 매개변수를 추가하면 이러한 URL이 자체 API 엔드포인트가 됩니다.
이 사이트는 PoP Demo 웹사이트의 동일한 데이터베이스에 의해 지원되므로 구성 요소 계층의 시각화 및 검색된 데이터는 이 다른 웹사이트의 동일한 URL을 쿼리하여 수행할 수 있습니다(예: https://demo.getpop.org/u/leo/ 방문). https://demo.getpop.org/u/leo/ 는 https://nextapi.getpop.org/u/leo/?output=json 의 데이터를 설명합니다.
아래 링크는 앞에서 설명한 경우에 대한 API를 보여줍니다.
- 홈페이지, 단일 게시물, 작성자, 게시물 목록 및 사용자 목록.
- 특정 모듈에서 필터링하는 이벤트입니다.
- 단일 페이지 애플리케이션에서 페이지만 가져오기 위해 사용자 상태 및 필터링이 필요한 필터링 모듈인 태그입니다.
- 자동 완성에 입력할 위치의 배열입니다.
- "우리가 누구인지" 페이지의 대체 모델: 일반, 인쇄 가능, 포함 가능.
- 모듈 이름 변경: 원본 대 맹글링.
- 필터링 정보: 모듈 설정, 모듈 데이터 및 데이터베이스 데이터만.
결론
좋은 API는 안정적이고 유지 관리가 쉬우며 강력한 애플리케이션을 만들기 위한 디딤돌입니다. 이 기사에서 나는 꽤 좋은 API라고 생각하는 구성 요소 기반 API를 구동하는 개념을 설명했으며, 여러분도 확신을 가졌기를 바랍니다.
지금까지 API의 설계와 구현은 여러 번 반복되었으며 5년 이상이 걸렸지만 아직 완전히 준비되지는 않았습니다. 그러나 그것은 생산 준비가되지 않은 안정적인 알파로서 꽤 괜찮은 상태입니다. 요즘에는 여전히 작업 중입니다. 공개 사양 정의 작업, 추가 레이어 구현(예: 렌더링) 및 문서 작성.
다음 기사에서는 API 구현이 어떻게 작동하는지 설명할 것입니다. 그때까지 긍정적이든 부정적이든 상관없이 그것에 대해 생각이 있으면 아래에서 귀하의 의견을 읽고 싶습니다.
업데이트(1월 31일): 사용자 지정 쿼리 기능
Alain Schlesser는 클라이언트에서 사용자 지정 쿼리할 수 없는 API는 가치가 없으며 REST 또는 GraphQL과 경쟁할 수 없기 때문에 SOAP로 다시 돌아가게 한다고 말했습니다. 그의 의견을 며칠 동안 생각한 후에 나는 그가 옳았다는 것을 인정해야 했습니다. 그러나 구성 요소 기반 API를 좋은 의도는 있지만 아직 노력하지 않은 것으로 무시하는 대신 훨씬 더 나은 작업을 수행했습니다. 사용자 지정 쿼리 기능을 구현해야 했습니다. 그리고 그것은 매력처럼 작동합니다!
다음 링크에서는 일반적으로 REST를 통해 수행되는 것처럼 리소스 또는 리소스 컬렉션에 대한 데이터를 가져옵니다. 그러나 매개변수 fields 를 통해 각 리소스에 대해 검색할 특정 데이터를 지정할 수도 있으므로 데이터를 초과하거나 적게 가져오는 것을 방지할 수 있습니다.
- 단일 게시물 및 매개변수
fields=title,content,datetime을 추가하는 게시물 모음 - 매개변수
fields=name,username,description
위의 링크는 쿼리된 리소스에 대해서만 데이터를 가져오는 방법을 보여줍니다. 그들의 관계는 어떻습니까? 예를 들어 "title" 및 "content" 필드가 있는 게시물 목록, "content" 및 "date" 필드가 있는 각 게시물의 댓글, 필드 "name" 및 "url" . GraphQL에서 이를 달성하기 위해 다음 쿼리를 구현합니다.
query { post { title content comments { content date author { name url } } } } 구성 요소 기반 API를 구현하기 위해 쿼리를 해당 "점 구문" 표현식으로 변환한 다음 매개변수 fields 를 통해 제공할 수 있습니다. "게시물" 리소스를 쿼리할 때 이 값은 다음과 같습니다.
fields=title,content,comments.content,comments.date,comments.author.name,comments.author.url 또는 | 를 사용하여 단순화할 수 있습니다. 동일한 리소스에 적용된 모든 필드를 그룹화하려면:
fields=title|content,comments.content|date,comments.author.name|url단일 게시물에서 이 쿼리를 실행할 때 관련된 모든 리소스에 대해 정확히 필요한 데이터를 얻습니다.
{ "datasetmodulesettings": { "dataload-dataquery-singlepost-fields": { "dbkeys": { "id": "posts", "comments": "comments", "comments.author": "users" } } }, "datasetmoduledata": { "dataload-dataquery-singlepost-fields": { "dbobjectids": [ 23691 ] } }, "databases": { "posts": { "23691": { "id": 23691, "title": "A lovely tango", "content": "<div class=\"responsiveembed-container\"><iframe loading="lazy" width=\"480\" height=\"270\" src=\"https:\\/\\/www.youtube.com\\/embed\\/sxm3Xyutc1s?feature=oembed\" frameborder=\"0\" allowfullscreen><\\/iframe><\\/div>\n", "comments": [ "25094", "25164" ] } }, "comments": { "25094": { "id": "25094", "content": "<p><a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/videos\\/\">#videos<\\/a>\\u00a0<a class=\"hashtagger-tag\" href=\"https:\\/\\/newapi.getpop.org\\/tags\\/tango\\/\">#tango<\\/a><\\/p>\n", "date": "4 Aug 2016", "author": "851" }, "25164": { "id": "25164", "content": "<p>fjlasdjf;dlsfjdfsj<\\/p>\n", "date": "19 Jun 2017", "author": "1924" } }, "users": { "851": { "id": 851, "name": "Leonardo Losoviz", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo\\/" }, "1924": { "id": 1924, "name": "leo2", "url": "https:\\/\\/newapi.getpop.org\\/u\\/leo2\\/" } } } } 따라서 REST 방식으로 리소스를 쿼리하고 GraphQL 방식으로 스키마 기반 쿼리를 지정할 수 있으며 데이터를 과도하게 가져오거나 적게 가져오지 않고 데이터가 중복되지 않도록 데이터베이스의 데이터를 정규화하지 않고 필요한 것을 정확히 얻을 수 있습니다. 바람직하게는 쿼리는 깊이에 관계없이 중첩된 관계를 포함할 수 있으며 선형 복잡도 시간으로 해결됩니다. 최악의 경우 O(n+m), 여기서 n은 도메인을 전환하는 노드의 수입니다(이 경우 2: comments 및 comments.author ) m 은 검색된 결과 수(이 경우 5: 1 게시물 + 2 댓글 + 2 사용자)이며 O(n)의 평균 경우입니다. (이는 다항식 복잡도 시간이 O(n^c)이고 레벨 깊이가 증가함에 따라 실행 시간이 증가하는 문제를 겪는 GraphQL보다 효율적입니다.)
마지막으로 이 API는 데이터를 쿼리할 때 수정자를 적용할 수도 있습니다. 이를 달성하기 위해 API는 단순히 애플리케이션의 상단에 위치하며 해당 기능을 편리하게 사용할 수 있으므로 바퀴를 다시 만들 필요가 없습니다. 예를 들어 filter=posts&searchfor=internet 매개변수를 추가하면 게시물 모음에서 "internet" 이 포함된 모든 게시물이 필터링됩니다.
이 새로운 기능의 구현은 다음 기사에서 설명될 것입니다.