
React 및 Tesseract.js(OCR)를 사용한 이미지에서 텍스트로의 변환
게시 됨: 2022-03-10애플리케이션의 주요 목적은 인간의 문제를 해결하는 것이기 때문에 데이터는 모든 소프트웨어 애플리케이션의 중추입니다. 인간의 문제를 해결하려면 그에 대한 정보가 필요합니다.
이러한 정보는 특히 계산을 통해 데이터로 표시됩니다. 웹에서 데이터는 대부분 텍스트, 이미지, 비디오 등의 형태로 수집됩니다. 때로는 이미지에 특정 목적을 달성하기 위해 처리해야 하는 필수 텍스트가 포함되어 있습니다. 이러한 이미지는 프로그래밍 방식으로 처리할 방법이 없었기 때문에 대부분 수동으로 처리되었습니다.
이미지에서 텍스트를 추출할 수 없다는 것은 지난 회사에서 직접 경험한 데이터 처리 제한 사항이었습니다. 스캔한 기프트 카드를 처리해야 했고 이미지에서 텍스트를 추출할 수 없었기 때문에 수동으로 처리해야 했습니다 .
회사 내에는 기프트 카드를 수동으로 확인하고 사용자 계정에 크레딧을 적용하는 "운영"이라는 부서가 있었습니다. 사용자가 우리와 연결할 수 있는 웹사이트가 있었지만 기프트 카드 처리는 무대 뒤에서 수동으로 수행되었습니다.
당시 저희 웹사이트는 주로 백엔드는 PHP(라라벨), 프론트엔드는 자바스크립트(jQuery, Vue)로 구축했습니다. 우리의 기술 스택은 경영진이 문제를 중요하게 여긴다면 Tesseract.js와 함께 작동하기에 충분했습니다.
나는 기꺼이 문제를 해결해 주었지만, 기업'이나 경영자의 관점에서 볼 때 굳이 문제를 해결할 필요는 없었다. 회사를 떠난 후 몇 가지 연구를 수행하고 가능한 솔루션을 찾기로 결정했습니다 . 결국 나는 OCR을 발견했다.
OCR이란 무엇입니까?
OCR은 "광학 문자 인식" 또는 "광학 문자 판독기"를 나타냅니다. 이미지에서 텍스트를 추출하는 데 사용됩니다.
OCR의 진화는 여러 발명품으로 추적할 수 있지만 Optophone, "Gismo", CCD 평판 스캐너, Newton MessagePad 및 Tesseract는 문자 인식을 다른 수준의 유용성으로 가져온 주요 발명품입니다.
그렇다면 OCR을 사용하는 이유는 무엇입니까? 음, 광학 문자 인식은 많은 문제를 해결하며 그 중 하나가 제가 이 기사를 쓰게 된 계기가 되었습니다. 이미지에서 텍스트를 추출하는 기능이 다음과 같은 많은 가능성을 보장한다는 것을 깨달았습니다.
- 규제
모든 조직은 몇 가지 이유로 사용자의 활동을 규제해야 합니다. 이 규정은 사용자의 권리를 보호하고 위협이나 사기로부터 보호하는 데 사용될 수 있습니다.
이미지에서 텍스트를 추출하면 조직에서 특히 일부 사용자가 이미지를 제공한 경우 규제를 위해 이미지의 텍스트 정보를 처리할 수 있습니다.
예를 들어, 광고에 사용되는 이미지의 텍스트 수에 대한 Facebook과 같은 규제는 OCR을 통해 달성할 수 있습니다. 또한 트위터에서 민감한 콘텐츠를 숨기는 것도 OCR을 통해 가능합니다. - 검색 가능성
검색은 특히 인터넷에서 가장 일반적인 활동 중 하나입니다. 검색 알고리즘은 대부분 텍스트 조작을 기반으로 합니다. 광학 문자 인식을 사용하면 이미지의 문자를 인식하고 이를 사용하여 사용자에게 관련 이미지 결과를 제공할 수 있습니다. 요컨대, 이제 OCR의 도움으로 이미지와 비디오를 검색할 수 있습니다. - 접근성
이미지에 텍스트를 표시하는 것은 접근성에 있어 항상 어려운 문제였으며 이미지에 텍스트가 거의 없도록 하는 것이 일반적입니다. OCR을 사용하면 화면 판독기가 이미지의 텍스트에 액세스하여 사용자에게 필요한 경험을 제공할 수 있습니다. - 데이터 처리 자동화 데이터 처리 는 대부분 규모를 위해 자동화됩니다. 이미지에 텍스트를 포함하는 것은 텍스트를 수동으로 처리하지 않고는 처리할 수 없기 때문에 데이터 처리의 한계입니다. OCR(광학 문자 인식)을 사용하면 프로그래밍 방식으로 이미지의 텍스트를 추출할 수 있으므로 특히 이미지의 텍스트 처리와 관련된 데이터 처리 자동화를 보장합니다.
- 인쇄물의 디지털화
모든 것이 디지털화되고 있으며 여전히 디지털화해야 할 문서가 많습니다. 이제 광학 문자 인식을 사용하여 수표, 인증서 및 기타 물리적 문서를 디지털화할 수 있습니다.
위의 모든 용도를 찾아내 관심이 깊어졌으므로 다음 질문을 함으로써 더 나아가기로 결정했습니다.
"웹, 특히 React 애플리케이션에서 OCR을 어떻게 사용할 수 있습니까?"
그 질문은 나를 Tesseract.js로 이끌었습니다.
Tesseract.js은(는) 무엇인가요?
Tesseract.js는 원본 Tesseract를 C에서 JavaScript WebAssembly로 컴파일하여 브라우저에서 OCR에 액세스할 수 있도록 하는 JavaScript 라이브러리입니다. Tesseract.js 엔진은 원래 ASM.js로 작성되었으며 나중에 WebAssembly로 이식되었지만 WebAssembly가 지원되지 않는 경우에는 ASM.js가 여전히 백업 역할을 합니다.
Tesseract.js 웹사이트에 명시된 바와 같이 100개 이상의 언어 , 자동 텍스트 방향 및 스크립트 감지, 단락, 단어 및 문자 경계 상자를 읽기 위한 간단한 인터페이스를 지원합니다.
Tesseract는 다양한 운영 체제를 위한 광학 문자 인식 엔진입니다. Apache 라이선스에 따라 출시된 무료 소프트웨어입니다. Hewlett-Packard는 1980년대에 Tesseract를 독점 소프트웨어로 개발했습니다. 2005년에 오픈 소스로 출시되었으며 2006년부터 Google의 후원으로 개발되었습니다.
Tesseract의 최신 버전인 버전 4는 2018년 10월에 출시되었으며 LSTM( Long Short-Term Memory) 기반의 신경망 시스템 을 사용하는 새로운 OCR 엔진을 포함하며 보다 정확한 결과를 생성하기 위한 것입니다.
Tesseract API 이해
Tesseract가 어떻게 작동하는지 제대로 이해하려면 일부 API와 해당 구성 요소를 분석해야 합니다. Tesseract.js 문서에 따르면 이를 사용하는 방법에는 두 가지가 있습니다. 다음은 첫 번째 접근 방식입니다.
Tesseract.recognize( image,language, { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { console.log(result); }) } recognize 방법은 이미지를 첫 번째 인수로, 언어(여러 개일 수 있음)를 두 번째 인수로, { logger: m => console.log(me) } 를 마지막 인수로 사용합니다. Tesseract가 지원하는 이미지 형식은 jpg, png, bmp 및 pbm이며 요소(img, video 또는 canvas), 파일 개체( <input> ), blob 개체, 이미지에 대한 경로 또는 URL 및 base64로 인코딩된 이미지로만 제공할 수 있습니다. . (Tesseract가 처리할 수 있는 모든 이미지 형식에 대한 자세한 내용은 여기를 참조하십시오.)
언어는 eng 과 같은 문자열로 제공됩니다. + 기호는 eng+chi_tra 에서와 같이 여러 언어를 연결하는 데 사용할 수 있습니다. 언어 인수는 이미지 처리에 사용할 훈련된 언어 데이터를 결정하는 데 사용됩니다.
참고 : 여기에서 사용 가능한 모든 언어와 해당 코드를 찾을 수 있습니다.
{ logger: m => console.log(m) } 처리 중인 이미지의 진행 상황에 대한 정보를 얻는 데 매우 유용합니다. logger 속성은 Tesseract가 이미지를 처리할 때 여러 번 호출되는 함수를 사용합니다. 로거 함수에 대한 매개변수는 workerId , jobId , status 및 progress 가 속성으로 포함된 객체여야 합니다.
{ workerId: 'worker-200030', jobId: 'job-734747', status: 'recognizing text', progress: '0.9' } progress 은 0과 1 사이의 숫자이며 이미지 인식 프로세스의 진행 상황을 백분율로 표시합니다.
Tesseract는 자동으로 객체를 로거 함수에 대한 매개변수로 생성하지만 수동으로 제공할 수도 있습니다. 인식 프로세스가 진행됨에 따라 함수가 호출될 때마다 logger 객체 속성이 업데이트됩니다. 따라서 변환 진행률 표시줄을 표시하거나 응용 프로그램의 일부를 변경하거나 원하는 결과를 얻는 데 사용할 수 있습니다.
위 코드의 result 는 이미지 인식 프로세스의 결과입니다. result 의 각 속성에는 bbox 속성이 경계 상자의 x/y 좌표로 있습니다.
result 개체의 속성, 의미 또는 용도는 다음과 같습니다.
{ text: "I am codingnninja from Nigeria..." hocr: "<div class='ocr_page' id= ..." tsv: "1 1 0 0 0 0 0 0 1486 ..." box: null unlv: null osd: null confidence: 90 blocks: [{...}] psm: "SINGLE_BLOCK" oem: "DEFAULT" version: "4.0.0-825-g887c" paragraphs: [{...}] lines: (5) [{...}, ...] words: (47) [{...}, {...}, ...] symbols: (240) [{...}, {...}, ...] }-
text: 인식된 모든 텍스트를 문자열로 나타냅니다. -
lines: 인식된 모든 텍스트의 라인별 배열입니다. -
words: 인식된 모든 단어의 배열입니다. -
symbols: 인식된 각 문자의 배열입니다. -
paragraphs: 인식된 모든 단락의 배열입니다. 우리는 이 글의 뒷부분에서 "자신감"에 대해 논의할 것입니다.
Tesseract는 다음과 같이 더 명령적으로 사용할 수도 있습니다.
import { createWorker } from 'tesseract.js'; const worker = createWorker({ logger: m => console.log(m) }); (async () => { await worker.load(); await worker.loadLanguage('eng'); await worker.initialize('eng'); const { data: { text } } = await worker.recognize('https://tesseract.projectnaptha.com/img/eng_bw.png'); console.log(text); await worker.terminate(); })();이 접근 방식은 첫 번째 접근 방식과 관련이 있지만 구현이 다릅니다.
createWorker(options) 는 웹 작업자 또는 Tesseract 작업자를 만드는 노드 자식 프로세스를 만듭니다. 작업자가 Tesseract OCR 엔진 설정을 돕습니다. load() 메서드는 Tesseract 핵심 스크립트를 로드하고, loadLanguage() 는 제공된 모든 언어를 문자열로 로드하고, initialize() 는 Tesseract가 완전히 사용할 준비가 되었는지 확인한 다음, recognition 메서드를 사용하여 제공된 이미지를 처리합니다. terminate() 메서드는 작업자를 중지하고 모든 것을 정리합니다.
참고 : 자세한 내용은 Tesseract API 설명서를 확인하세요.
이제 Tesseract.js가 얼마나 효과적인지 확인하기 위해 무언가를 빌드해야 합니다.
무엇을 만들까요?
기프트 카드에서 PIN을 추출하는 것이 처음에 이 쓰기 모험으로 이어진 문제였기 때문에 기프트 카드 PIN 추출기를 구축할 것입니다.
스캔한 기프트 카드에서 PIN을 추출하는 간단한 애플리케이션을 빌드합니다. 간단한 기프트 카드 핀 추출기를 구축하기 시작하면서 내가 직면한 몇 가지 문제, 내가 제공한 솔루션 및 내 경험을 바탕으로 한 결론을 안내해 드리겠습니다.
- 소스 코드로 이동 →
아래는 실제 세계에서 가능한 몇 가지 현실적인 속성을 가지고 있기 때문에 테스트에 사용할 이미지입니다.

카드에서 AQUX-QWMB6L-R6JAU 를 추출합니다. 시작하겠습니다.
React 및 Tesseract 설치
React와 Tesseract.js를 설치하기 전에 주의해야 할 질문이 있습니다. 왜 Tesseract와 함께 React를 사용합니까? 실제로 Tesseract를 Vanilla JavaScript, React, Vue 및 Angular와 같은 JavaScript 라이브러리 또는 프레임워크와 함께 사용할 수 있습니다.
이 경우 React를 사용하는 것은 개인 취향입니다. 처음에는 Vue를 사용하고 싶었지만 Vue보다 React가 더 익숙하기 때문에 React로 결정했습니다.
이제 설치를 계속해 보겠습니다.
create-react-app으로 React를 설치하려면 아래 코드를 실행해야 합니다.
npx create-react-app image-to-text cd image-to-text yarn add Tesseract.js또는
npm install tesseract.js나는 npm으로 Tesseract를 설치할 수 없었지만 yarn이 스트레스 없이 작업을 완료했기 때문에 Tesseract.js를 설치하기 위해 yarn을 사용하기로 결정했습니다. npm을 사용해도 되지만 내 경험에 비추어 볼 때 원사로 Tesseract를 설치하는 것이 좋습니다.
이제 아래 코드를 실행하여 개발 서버를 시작하겠습니다.
yarn start또는
npm startyarn start 또는 npm start를 실행한 후 기본 브라우저는 아래와 같은 웹페이지를 열어야 합니다.

페이지가 자동으로 실행되지 않는 경우 브라우저에서 localhost:3000 으로 이동할 수도 있습니다.
React와 Tesseract.js를 설치한 후 다음은 무엇입니까?
업로드 양식 설정
이 경우 브라우저에서 방금 본 홈 페이지(App.js)를 조정하여 필요한 양식을 포함할 것입니다.
import { useState, useRef } from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={imagePath} className="App-logo" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> </main> </div> ); } export default App 이 시점에서 주의가 필요한 위의 코드 부분은 함수 handleChange 입니다.
const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])); } 함수에서 URL.createObjectURL 은 event.target.files[0] 을 통해 선택된 파일을 가져와 img, audio, video와 같은 HTML 태그와 함께 사용할 수 있는 참조 URL을 생성합니다. setImagePath 를 사용하여 상태에 URL을 추가했습니다. 이제 imagePath 를 사용하여 URL에 액세스할 수 있습니다.
<img src={imagePath} className="App-logo" alt="image"/> 이미지의 src 속성을 {imagePath} 로 설정하여 처리하기 전에 브라우저에서 미리 봅니다.
선택한 이미지를 텍스트로 변환
선택한 이미지의 경로를 잡았으므로 이미지의 경로를 Tesseract.js에 전달하여 텍스트를 추출할 수 있습니다.
import { useState} from 'react'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [imagePath, setImagePath] = useState(""); const [text, setText] = useState(""); const handleChange = (event) => { setImagePath(URL.createObjectURL(event.target.files[0])); } const handleClick = () => { Tesseract.recognize( imagePath,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual imagePath uploaded</h3> <img src={imagePath} className="App-image" alt="logo"/> <h3>Extracted text</h3> <div className="text-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}> convert to text</button> </main> </div> ); } export default App"handleClick" 기능을 "App.js"에 추가하고 선택한 이미지의 경로를 가져오는 Tesseract.js API를 포함합니다. Tesseract.js는 "imagePath", "언어", "설정 개체"를 사용합니다.
아래 버튼은 버튼을 클릭할 때마다 이미지-텍스트 변환을 트리거하는 "handClick"을 호출하는 양식에 추가되었습니다.
<button onClick={handleClick} style={{height:50}}> convert to text</button>처리가 성공하면 결과에서 "신뢰"와 "텍스트"에 모두 액세스합니다. 그런 다음 "setText(text)"를 사용하여 상태에 "text"를 추가합니다.
<p> {text} </p> 에 추가하여 추출된 텍스트를 표시합니다.
이미지에서 '텍스트'가 추출되는 것은 당연하지만 자신감이란?
신뢰도는 변환이 얼마나 정확한지 보여줍니다. 신뢰 수준은 1에서 100 사이입니다. 정확도 측면에서 1은 최악을 나타내고 100은 최고를 나타냅니다. 추출된 텍스트를 정확한 것으로 받아들여야 하는지 여부를 결정하는 데에도 사용할 수 있습니다.
그렇다면 어떤 요인이 전체 전환의 신뢰도나 정확도에 영향을 미칠 수 있습니까? 이는 주로 사용된 문서의 품질과 특성, 문서에서 생성된 스캔 품질 및 Tesseract 엔진의 처리 능력이라는 세 가지 주요 요소의 영향을 받습니다.
이제 "App.css"에 아래 코드를 추가하여 응용 프로그램의 스타일을 약간 지정해 보겠습니다.
.App { text-align: center; } .App-image { width: 60vmin; pointer-events: none; } .App-main { background-color: #282c34; min-height: 100vh; display: flex; flex-direction: column; align-items: center; justify-content: center; font-size: calc(7px + 2vmin); color: white; } .text-box { background: #fff; color: #333; border-radius: 5px; text-align: center; }다음은 첫 번째 테스트 결과입니다.
Firefox의 결과
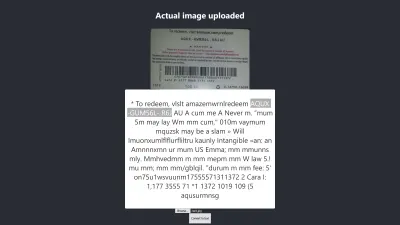
위 결과의 신뢰 수준은 64입니다. 기프트 카드 이미지의 색상이 어둡고 우리가 얻는 결과에 확실히 영향을 미친다는 점은 주목할 가치가 있습니다.

위의 이미지를 자세히 보면 카드의 핀이 추출된 텍스트에서 거의 정확하다는 것을 알 수 있습니다. 기프트 카드가 실제로 명확하지 않기 때문에 정확하지 않습니다.
오, 기다려! Chrome에서는 어떻게 표시되나요?
Chrome의 결과
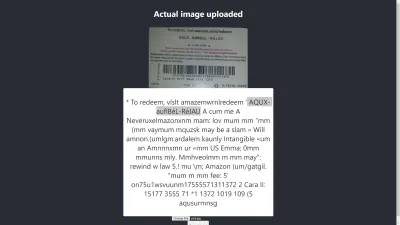
아! 결과는 Chrome에서 더 나쁩니다. 그러나 Chrome의 결과가 Mozilla Firefox와 다른 이유는 무엇입니까? 브라우저마다 이미지와 색상 프로필을 다르게 처리합니다. 즉 , 브라우저에 따라 이미지가 다르게 렌더링될 수 있습니다 . 미리 렌더링된 image.data 를 Tesseract에 제공하면 사용하는 브라우저에 따라 Tesseract에 제공되는 image.data 가 다르기 때문에 브라우저마다 다른 결과가 나올 수 있습니다. 이 기사의 뒷부분에서 볼 수 있듯이 이미지를 사전 처리하면 일관된 결과를 얻는 데 도움이 됩니다.
올바른 정보를 얻거나 제공할 수 있도록 더 정확해야 합니다. 그래서 우리는 조금 더 나아가야 합니다.
결국 목표를 달성할 수 있을지 더 노력해보자.
정확도 테스트
Tesseract.js를 사용하여 이미지를 텍스트로 변환하는 데 영향을 미치는 많은 요소가 있습니다. 이러한 요소의 대부분은 처리하려는 이미지의 특성을 중심으로 이루어지며 나머지는 Tesseract 엔진이 변환을 처리하는 방법에 따라 다릅니다.
내부적으로 Tesseract는 실제 OCR 변환 전에 이미지를 사전 처리하지만 항상 정확한 결과를 제공하지는 않습니다.
솔루션으로 이미지를 사전 처리하여 정확한 변환을 달성할 수 있습니다. Tesseract.js를 위해 이미지를 사전 처리하기 위해 이미지를 이진화, 반전, 확장, 기울기 보정 또는 재조정할 수 있습니다.
이미지 전처리 는 그 자체로 많은 작업 또는 광범위한 분야입니다. 다행히 P5.js는 우리가 사용하고자 하는 모든 이미지 전처리 기술을 제공했습니다. 바퀴를 재발명하거나 라이브러리의 일부를 사용하고 싶다는 이유만으로 라이브러리 전체를 사용하는 대신 필요한 것을 복사했습니다. 모든 이미지 전처리 기술은 preprocess.js에 포함되어 있습니다.
이진화란 무엇입니까?
이진화는 이미지의 픽셀을 흑백으로 변환하는 것입니다. 정확도가 더 좋은지 여부를 확인하기 위해 이전 기프트 카드를 이진화하려고 합니다.
이전에는 기프트 카드에서 일부 텍스트를 추출했지만 대상 PIN이 원하는 만큼 정확하지 않았습니다. 따라서 정확한 결과를 얻을 수 있는 다른 방법을 찾을 필요가 있습니다.
이제 우리 는 기프트 카드를 이진화 하려고 합니다. 즉, 더 나은 수준의 정확도를 달성할 수 있는지 여부를 확인할 수 있도록 픽셀을 흑백으로 변환하려고 합니다.
아래 함수는 이진화에 사용되며 preprocess.js라는 별도의 파일에 포함되어 있습니다.
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); thresholdFilter(image.data, 0.5); return image; } Export default preprocessImage위의 코드는 무엇을 합니까?
변환을 위해 Tesseract에 전달하기 전에 이미지를 사전 처리하기 위해 일부 필터를 적용하기 위해 이미지 데이터를 보유하는 캔버스를 도입합니다.
첫 번째 preprocessImage 함수는 preprocess.js 에 있으며 픽셀을 가져와서 사용할 캔버스를 준비합니다. thresholdFilter 함수 는 픽셀을 검은색 또는 흰색으로 변환 하여 이미지를 이진화합니다.
preprocessImage 를 호출하여 이전 기프트 카드에서 추출한 텍스트가 더 정확할 수 있는지 확인합니다.
App.js를 업데이트할 때쯤이면 이제 다음 코드처럼 보일 것입니다.
import { useState, useRef } from 'react'; import preprocessImage from './preprocess'; import Tesseract from 'tesseract.js'; import './App.css'; function App() { const [image, setImage] = useState(""); const [text, setText] = useState(""); const canvasRef = useRef(null); const imageRef = useRef(null); const handleChange = (event) => { setImage(URL.createObjectURL(event.target.files[0])) } const handleClick = () => { const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg"); Tesseract.recognize( dataUrl,'eng', { logger: m => console.log(m) } ) .catch (err => { console.error(err); }) .then(result => { // Get Confidence score let confidence = result.confidence console.log(confidence) // Get full output let text = result.text setText(text); }) } return ( <div className="App"> <main className="App-main"> <h3>Actual image uploaded</h3> <img src={image} className="App-logo" alt="logo" ref={imageRef} /> <h3>Canvas</h3> <canvas ref={canvasRef} width={700} height={250}></canvas> <h3>Extracted text</h3> <div className="pin-box"> <p> {text} </p> </div> <input type="file" onChange={handleChange} /> <button onClick={handleClick} style={{height:50}}>Convert to text</button> </main> </div> ); } export default App먼저 아래 코드를 사용하여 "preprocess.js"에서 "preprocessImage"를 가져와야 합니다.
import preprocessImage from './preprocess'; 그런 다음 양식에 캔버스 태그를 추가합니다. 캔버스와 img 태그의 ref 속성을 각각 { { canvasRef } 와 { imageRef } 로 설정했습니다. 참조는 앱 구성 요소에서 캔버스와 이미지에 액세스하는 데 사용됩니다. 다음과 같이 "useRef"를 사용하여 캔버스와 이미지를 모두 확보합니다.
const canvasRef = useRef(null); const imageRef = useRef(null);코드의 이 부분에서는 JavaScript에서 캔버스만 사전 처리할 수 있으므로 이미지를 캔버스에 병합합니다. 그런 다음 이미지 형식이 "jpeg"인 데이터 URL로 변환합니다.
const canvas = canvasRef.current; const ctx = canvas.getContext('2d'); ctx.drawImage(imageRef.current, 0, 0); ctx.putImageData(preprocessImage(canvas),0,0); const dataUrl = canvas.toDataURL("image/jpeg");"dataUrl"은 처리할 이미지로 Tesseract에 전달됩니다.
이제 추출된 텍스트가 더 정확한지 확인해 보겠습니다.
테스트 #2

위 이미지는 Firefox에서 결과를 보여줍니다. 이미지의 어두운 부분이 흰색으로 변경된 것은 분명하지만 이미지를 전처리한다고 해서 더 정확한 결과를 얻을 수는 없습니다. 더 나빠요.
첫 번째 변환에는 두 개의 잘못된 문자 만 있지만 이 변환에는 네 개의 잘못된 문자가 있습니다. 임계값 수준을 변경하려고 시도했지만 아무 소용이 없었습니다. 이진화가 나쁘기 때문이 아니라 이미지를 이진화해도 Tesseract 엔진에 적합한 방식으로 이미지의 특성이 수정되지 않기 때문에 더 나은 결과를 얻을 수 없습니다.
Chrome에서도 어떻게 보이는지 확인해 보겠습니다.

우리는 같은 결과를 얻습니다.
이미지를 이진화하여 더 나쁜 결과를 얻은 후 문제를 해결할 수 있는지 여부를 확인하기 위해 다른 이미지 전처리 기술을 확인할 필요가 있습니다. 그래서 우리는 팽창, 역전, 블러링을 다음에 시도할 것입니다.
이 기사에서 사용하는 P5.js에서 각 기술에 대한 코드를 가져와 보겠습니다. preprocess.js에 이미지 처리 기술을 추가하여 하나씩 사용하겠습니다. 사용하고자 하는 각각의 이미지 전처리 기술을 사용하기 전에 이해가 필요하므로 먼저 논의하겠습니다.
팽창이란 무엇입니까?
팽창은 이미지의 개체 경계에 픽셀을 추가하여 이미지를 더 넓게, 더 크게 또는 더 개방적으로 만드는 것입니다. "확장" 기술은 이미지의 개체 밝기를 증가시키기 위해 이미지를 사전 처리하는 데 사용됩니다. JavaScript를 사용하여 이미지를 확장하는 함수가 필요하므로 이미지를 확장하는 코드 스니펫이 preprocess.js에 추가됩니다.
흐림이란 무엇입니까?
흐리게 하는 것은 선명도를 줄여 이미지의 색상을 부드럽게 하는 것입니다. 이미지에 작은 점/패치가 있는 경우가 있습니다. 이러한 패치를 제거하기 위해 이미지를 흐리게 할 수 있습니다. 이미지를 흐리게 처리하는 코드 스니펫은 preprocess.js에 포함되어 있습니다.
반전이란 무엇입니까?
반전은 이미지의 밝은 영역을 어두운 색으로 바꾸고 어두운 영역을 밝은 색으로 바꾸는 것입니다. 예를 들어 이미지에 검은색 배경과 흰색 전경이 있는 경우 배경이 흰색이고 전경이 검은색이 되도록 반전할 수 있습니다. 또한 이미지를 preprocess.js로 반전시키는 코드 스니펫을 추가했습니다.
dilate , invertColors 및 blurARGB 를 "preprocess.js"에 추가한 후 이제 이미지를 사전 처리하는 데 사용할 수 있습니다. 그것들을 사용하려면 preprocess.js에서 초기 "preprocessImage" 함수를 업데이트해야 합니다.
preprocessImage(...) 는 이제 다음과 같습니다.
function preprocessImage(canvas) { const level = 0.4; const radius = 1; const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); blurARGB(image.data, canvas, radius); dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, level); return image; } 위의 preprocessImage 에서 이미지에 네 가지 전처리 기술을 적용합니다. 이미지의 점을 제거하는 blurARGB() , 이미지의 밝기를 높이는 dilate( dilate() , 이미지의 전경색과 배경색을 전환하는 invertColors() , 그리고 thresholdFilter() 이미지를 Tesseract 변환에 더 적합한 흑백으로 변환합니다.
thresholdFilter() 는 image.data 와 level 을 매개변수로 사용합니다. level 은 이미지가 얼마나 흰색 또는 검정색이어야 하는지 설정하는 데 사용됩니다. 우리는 Tesseract가 훌륭한 결과를 생성하기 위해 이미지가 얼마나 흰색, 어둡거나 매끄러워야 하는지 확신할 수 없기 때문에 시행 착오를 통해 thresholdFilter 레벨과 blurRGB 반경을 결정했습니다.
테스트 #3
다음은 네 가지 기술을 적용한 후의 새로운 결과입니다.

위의 이미지는 Chrome과 Firefox 모두에서 얻은 결과를 나타냅니다.
앗! 결과는 끔찍합니다.
네 가지 기술을 모두 사용하는 대신 한 번에 두 가지만 사용하는 것이 어떻습니까?
응! invertColors 및 thresholdFilter 기술을 사용하여 이미지를 흑백으로 변환하고 이미지의 전경과 배경을 전환할 수 있습니다. 그러나 결합할 기술과 기술을 어떻게 알 수 있습니까? 우리는 전처리하려는 이미지의 특성에 따라 무엇을 결합해야 하는지 알고 있습니다.
예를 들어 디지털 이미지는 흑백으로 변환되어야 하고 패치가 있는 이미지는 도트/패치를 제거하기 위해 흐리게 처리해야 합니다. 정말 중요한 것은 각 기술이 무엇에 사용되는지 이해하는 것입니다.
invertColors 와 thresholdFilter 를 사용하려면 preprocessImage 에서 blurARGB 와 dilate 를 모두 주석 처리해야 합니다.
function preprocessImage(canvas) { const ctx = canvas.getContext('2d'); const image = ctx.getImageData(0,0,canvas.width, canvas.height); // blurARGB(image.data, canvas, 1); // dilate(image.data, canvas); invertColors(image.data); thresholdFilter(image.data, 0.5); return image; }테스트 #4
다음은 새로운 결과입니다.

결과는 전처리가 없는 것보다 여전히 나쁩니다. 이 특정 이미지와 일부 다른 이미지에 대한 각 기술을 조정한 후 다른 특성을 가진 이미지에는 다른 전처리 기술이 필요하다는 결론에 도달했습니다.
요컨대, 이미지 전처리 없이 Tesseract.js를 사용하면 위의 기프트 카드에 대해 최상의 결과를 얻을 수 있습니다. 이미지 전처리를 사용한 다른 모든 실험은 덜 정확한 결과를 산출했습니다.
문제
처음에는 Amazon 기프트 카드에서 PIN을 추출하고 싶었지만 일관된 결과를 얻기 위해 일치하지 않는 PIN을 일치시킬 이유가 없었기 때문에 달성할 수 없었습니다. 정확한 PIN을 얻기 위해 이미지를 처리하는 것이 가능하지만 이러한 사전 처리는 다른 특성을 가진 다른 이미지가 사용될 때까지 일관성이 없습니다.
최고의 결과물
아래 이미지는 실험에 의해 생성된 최상의 결과를 보여줍니다.
테스트 #5

이미지의 텍스트와 추출된 텍스트는 완전히 동일합니다. 변환의 정확도는 100%입니다. 결과물을 재현해 보았지만 비슷한 성질을 가진 이미지를 사용할 때만 재현할 수 있었습니다.
관찰과 교훈
- 사전 처리되지 않은 일부 이미지는 브라우저에 따라 다른 결과를 제공할 수 있습니다. 이 주장은 첫 번째 테스트에서 분명합니다. Firefox의 결과는 Chrome의 결과와 다릅니다. 그러나 이미지를 사전 처리하면 다른 테스트에서 일관된 결과를 얻는 데 도움이 됩니다.
- 흰색 배경에 검은색은 관리 가능한 결과를 제공하는 경향이 있습니다. 아래 이미지는 전처리를 하지 않은 정확한 결과 의 예시입니다. 저 역시 이미지를 전처리하여 같은 수준의 정확도를 얻을 수 있었지만 불필요한 조정이 많이 필요했습니다.
변환은 100% 정확합니다.
- 큰 글꼴 크기 를 가진 텍스트는 더 정확한 경향이 있습니다.
- 모서리가 구부러진 글꼴은 Tesseract를 혼동하는 경향이 있습니다. 내가 얻은 최고의 결과는 Arial(글꼴)을 사용할 때 달성되었습니다.
- OCR은 현재 특히 80% 수준 이상의 정확도가 필요한 경우 이미지에서 텍스트로의 변환을 자동화하는 데 충분하지 않습니다. 그러나 수동 수정을 위해 텍스트를 추출하여 이미지의 텍스트를 수동으로 처리하는 데 스트레스를 덜 받는 데 사용할 수 있습니다.
- OCR은 현재 접근성 을 위해 유용한 정보를 화면 판독기에 전달할 만큼 충분하지 않습니다. 화면 판독기에 부정확한 정보를 제공하면 사용자를 쉽게 오도하거나 주의를 분산시킬 수 있습니다.
- OCR은 신경망이 학습 및 개선을 가능하게 하므로 매우 유망합니다. 딥 러닝은 가까운 장래에 OCR을 게임 체인저로 만들 것 입니다.
- 자신감을 가지고 결정을 내립니다. 신뢰도 점수는 애플리케이션에 큰 영향을 미칠 수 있는 결정을 내리는 데 사용할 수 있습니다. 신뢰도 점수를 사용하여 결과를 승인할지 거부할지 결정할 수 있습니다. 내 경험과 실험을 통해 90 미만의 신뢰 점수는 실제로 유용하지 않다는 것을 깨달았습니다. 텍스트에서 일부 핀만 추출해야 하는 경우 75에서 100 사이의 신뢰도 점수를 기대하고 75 미만은 거부 됩니다.
일부를 추출할 필요 없이 텍스트를 처리하는 경우 90에서 100 사이의 신뢰도 점수는 확실히 수락하지만 그 미만의 점수는 거부합니다. 예를 들어, 수표, 역사적 어음과 같은 문서를 디지털화하려는 경우 또는 정확한 사본이 필요할 때마다 90 이상의 정확도가 예상됩니다. 그러나 기프트 카드에서 PIN을 받는 것과 같이 정확한 사본이 중요하지 않은 경우 75에서 90 사이의 점수가 허용됩니다. 간단히 말해서 신뢰도 점수는 애플리케이션에 영향을 미치는 결정을 내리는 데 도움이 됩니다 .
결론
이미지의 텍스트로 인한 데이터 처리 제한과 그에 따른 단점을 감안할 때 OCR(광학 문자 인식)은 수용할 수 있는 유용한 기술입니다. OCR은 한계가 있지만 신경망을 사용하기 때문에 매우 유망합니다.
시간이 지남에 따라 OCR은 딥 러닝의 도움으로 대부분의 한계를 극복할 것이지만 그 전에 이 기사에서 강조한 접근 방식을 활용하여 최소한 이미지에서 텍스트 추출을 처리 하여 수동 작업과 관련된 어려움과 손실을 줄일 수 있습니다. 처리 — 특히 비즈니스 관점에서.
이제 이미지에서 텍스트를 추출하기 위해 OCR을 시도할 차례입니다. 행운을 빕니다!
추가 읽기
- P5.js
- OCR에서 전처리
- 출력 품질 향상
- JavaScript를 사용하여 OCR용 이미지 사전 처리
- Tesseract.js를 사용하여 브라우저에서 OCR
- 광학 문자 인식의 빠른 역사
- OCR의 미래는 딥러닝입니다
- 광학 문자 인식 타임라인