
CNN의 이미지 분류: 알아야 할 모든 것
게시 됨: 2021-02-25목차
소개
Facebook 피드를 살펴보는 동안 Facebook 소프트웨어에서 그룹 사진의 사람들이 자동으로 레이블을 지정하는 방법을 궁금해 한 적이 있습니까? Facebook의 모든 대화형 사용자 인터페이스 뒤에는 소셜 미디어 플랫폼에 업로드한 각 사진을 인식하고 레이블을 지정하는 데 사용되는 복잡하고 강력한 알고리즘이 있습니다. 우리의 모든 사진은 알고리즘의 효율성을 높이는 데만 도움이 됩니다. 예, 이미지 분류는 인공 지능의 적용을 볼 때 가장 널리 사용되는 알고리즘 중 하나입니다.
최근 CNN(Convolutional Neural Networks)은 딥 러닝의 가장 강력한 지지자 중 하나가 되었습니다. 이러한 Convolutional Networks의 인기 있는 응용 프로그램 중 하나는 Image Classification입니다. 이 자습서에서는 Convolutional Neural Networks의 기본 사항을 살펴보고 CNN 모델 구축과 관련된 다양한 계층을 살펴보고 마지막으로 Image Classification 작업의 예를 시각화합니다.
이미지 분류
Deep Learning 및 Convolutional Neural Networks에 대해 자세히 알아보기 전에 이미지 분류의 기본 사항을 이해하겠습니다. 일반적으로 이미지 분류는 클래스 또는 이미지가 속한 클래스의 확률을 출력하는 특정 알고리즘을 사용하여 구축된 모델에 입력으로 이미지를 제공하는 작업으로 정의됩니다. 특정 클래스에 이미지에 레이블을 지정하는 이 프로세스를 지도 학습이라고 합니다.
우리가 이미지를 보는 방식과 기계(컴퓨터)가 동일한 이미지를 보는 방식에는 큰 차이가 있습니다. 우리는 이미지를 시각화하고 색상과 크기를 기반으로 특성화할 수 있습니다. 반면에 기계에게 보이는 것은 숫자뿐입니다. 보이는 숫자를 픽셀이라고 합니다.
각 픽셀은 0에서 255 사이의 값을 갖습니다. 따라서 이러한 수치 데이터를 사용하여 기계는 한 이미지를 다른 이미지와 구별하는 특정 패턴이나 특징을 도출하기 위해 몇 가지 사전 처리 단계가 필요합니다. Convolutional Neural Networks는 이미지에서 특정 패턴을 도출할 수 있는 알고리즘을 구축하는 데 도움이 됩니다.
우리가 보는 것과 컴퓨터가 보는 것
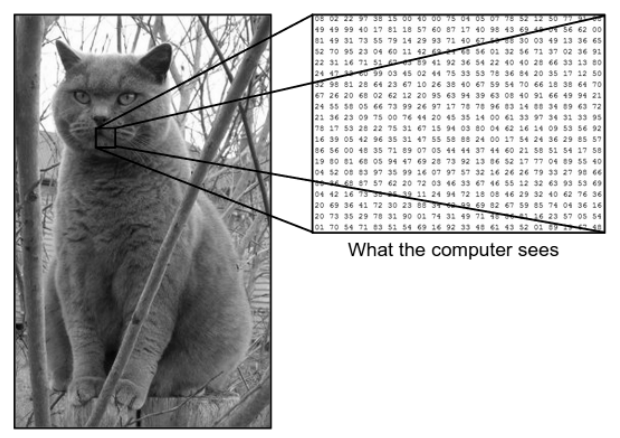 출처 - 컴퓨터와 인간의 눈의 차이점
출처 - 컴퓨터와 인간의 눈의 차이점

이미지 분류를 위한 딥 러닝
이미지 분류가 무엇인지 이해했으므로 이제 인공 지능을 사용하여 이미지 분류를 구현하는 방법을 살펴보겠습니다. 이를 위해 인기 있는 딥 러닝 방법을 사용합니다. 딥 러닝은 대규모 이미지 데이터 세트를 사용하여 다양한 이미지에서 패턴을 인식하고 유도하여 이미지 데이터 세트에 있는 다양한 클래스를 구별하는 인공 지능의 하위 집합입니다.
딥 러닝이 직면한 주요 과제는 거대한 데이터베이스의 경우 시간이 매우 오래 걸리고 계산 비용이 높다는 것입니다. 그러나 Deep Learning 알고리즘의 일종인 Convolutional Neural Networks는 이 문제를 잘 해결합니다.
컨볼루션 신경망
Deep Learning에서 Convolutional Neural Networks는 시각적 이미지에 주로 사용되는 Deep Neural Networks의 클래스입니다. 1998년 Yann LeCunn이 제안한 인공 신경망(ANN)의 특수 아키텍처입니다. Convolutional Neural Networks는 두 부분으로 구성됩니다.
첫 번째 부분은 주요 특징 추출 프로세스가 발생하는 Convolutional 레이어와 Pooling 레이어로 구성됩니다. 두 번째 부분에서 완전 연결 및 밀도 계층은 추출된 기능에 대해 여러 비선형 변환을 수행하고 분류기 부분으로 작동합니다. 이미지 분류를 위해 CNN을 배우십시오.
인간과 기계가 보는 것에 대한 위에 표시된 이미지 예를 고려하십시오. 보시다시피 컴퓨터는 픽셀 배열을 봅니다. 예를 들어 이미지 크기가 500x500이면 배열의 크기는 500x500x3이 됩니다. 여기서 500은 각 높이와 너비를 나타내고 3은 각 색상 채널이 별도의 배열로 표시되는 RGB 채널을 나타냅니다. 픽셀 강도는 0에서 255까지 다양합니다.
이제 이미지 분류를 위해 컴퓨터는 기본 수준에서 기능을 찾습니다. 우리 인간에 따르면 고양이의 이러한 기본 수준의 특징은 귀, 코 및 수염입니다. 컴퓨터의 경우 이러한 기본 수준 기능은 곡률과 경계입니다. 이러한 방식으로 Convolutional 레이어 및 Pooling 레이어와 같은 여러 레이어를 사용하여 컴퓨터는 이미지에서 기본 수준 기능을 추출합니다.
Convolutional Neural Network 모델에는 다음과 같은 여러 유형의 레이어가 있습니다.
- 입력 레이어
- 컨볼루션 레이어
- 풀링 레이어
- 완전 연결 계층
- 출력 레이어
- 활성화 기능
이미지 분류에 적용하기 전에 각 레이어를 간략하게 살펴보겠습니다.
입력 레이어
이름에서 우리는 이것이 입력 이미지가 CNN 모델에 공급될 레이어임을 이해합니다. 요구 사항에 따라 (28,28,3)과 같은 다양한 크기로 이미지를 변경할 수 있습니다.
컨볼루션 레이어
그런 다음 고정 크기의 필터(커널이라고도 함)로 구성된 가장 중요한 레이어가 나옵니다. Convolution의 수학적 연산은 입력 이미지와 필터 사이에서 수행됩니다. 날카로운 모서리와 곡선과 같은 기본 특징의 대부분이 이미지에서 추출되는 단계이므로 이 레이어를 특징 추출기 레이어라고도 합니다.
풀링 레이어
Convolution 연산을 수행한 후 Pooling 연산을 수행합니다. 이것은 이미지의 공간 볼륨이 감소하는 다운샘플링이라고도 합니다. 예를 들어, 크기가 28×28인 이미지에서 보폭이 2인 Pooling 연산을 수행하면 이미지 크기가 14×14로 줄어들고 원래 크기의 절반으로 줄어듭니다.
완전 연결 계층
완전 연결 계층(FC)은 CNN 모델의 최종 분류 출력 바로 앞에 배치됩니다. 이 레이어는 분류하기 전에 결과를 병합하는 데 사용됩니다. 여기에는 여러 편향, 가중치 및 뉴런이 포함됩니다. 분류 전에 FC 레이어를 연결하면 N차원 벡터가 생성됩니다. 여기서 N은 모델이 클래스를 선택해야 하는 클래스의 수입니다.
출력 레이어
마지막으로 Output Layer는 대부분 one-hot 인코딩 방식을 사용하여 인코딩되는 레이블로 구성됩니다.
활성화 기능
이러한 활성화 기능은 모든 컨볼루션 신경망 모델의 핵심입니다. 이러한 함수는 신경망의 출력을 결정하는 데 사용됩니다. 간단히 말해서 특정 뉴런을 활성화("발화")해야 하는지 여부를 결정합니다. 이들은 일반적으로 입력 신호에 대해 수행되는 비선형 기능입니다. 이 변환된 출력은 입력으로 뉴런의 다음 레이어로 전송됩니다. Sigmoid, ReLU, Leaky ReLU, TanH 및 Softmax와 같은 여러 활성화 함수가 있습니다.
기본 CNN 아키텍처
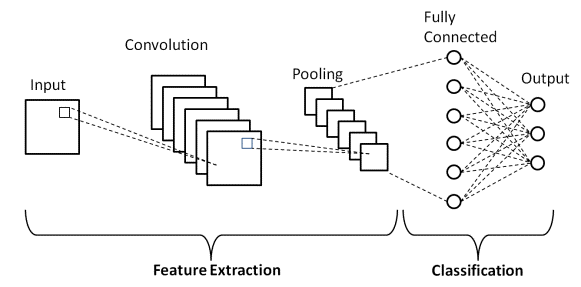
출처 : 기본 CNN 아키텍처
앞서 정의한 바와 같이 위의 다이어그램은 Convolutional Neural Network 모델의 기본 아키텍처입니다. 이제 이미지 분류와 CNN의 기본 사항이 준비되었으므로 이제 실시간 문제와 함께 해당 응용 프로그램에 대해 알아보겠습니다. 기본 CNN 아키텍처에 대해 자세히 알아보세요.
컨볼루션 신경망 구현
이제 이미지 분류 및 컨볼루션 신경망의 기본 사항을 이해했으므로 Python 코딩을 사용하여 TensorFlow/Keras에서 구현을 시각화해 보겠습니다. 여기에서 기본 LeNet 아키텍처를 사용하여 간단한 Convolutional Neural Network Model을 구축하고 훈련 세트 및 테스트 세트에서 모델을 훈련하고 마지막으로 테스트 세트 데이터에서 모델의 정확도를 얻습니다.
문제 세트
Convolutional Neural Network Model을 구축하고 훈련하기 위한 이 기사에서는 유명한 Fashion MNIST 데이터 세트를 사용할 것입니다. MNIST는 Modified National Institute of Standards and Technology의 약자입니다. Fashion-MNIST는 60,000개의 예제로 구성된 훈련 세트와 10,000개의 예제로 구성된 테스트 세트로 구성된 Zalando의 기사 이미지 데이터 세트입니다. 각 예제는 10개 클래스의 레이블과 연결된 28×28 회색조 이미지입니다.
각 훈련 및 테스트 예제는 다음 레이블 중 하나에 할당됩니다.
0 – 티셔츠/상판
1 - 바지
2 - 풀오버
3 – 드레스
4 – 코트
5 - 샌들
6 – 셔츠

7 - 운동화
8 – 가방
9 - 앵클 부츠
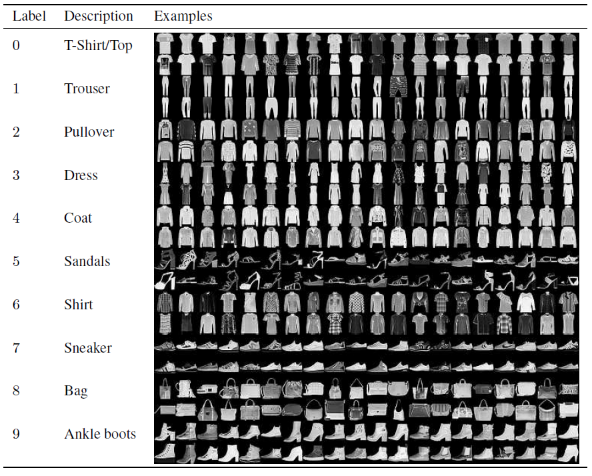
출처 : Fashion MNIST Dataset Images
프로그램 코드
1단계 – 라이브러리 가져오기
딥 러닝 모델을 구축하는 첫 번째 단계는 프로그램에 필요한 라이브러리를 가져오는 것입니다. 이 예에서는 TensorFlow 프레임워크를 사용하고 있으므로 Keras 라이브러리와 계산을 위한 번호 및 플롯을 플롯하기 위한 matplotlib와 같은 기타 중요한 라이브러리를 가져올 것입니다.
#TensorFlow – 라이브러리 가져오기
numpy를 np로 가져오기
matplotlib.pyplot을 plt로 가져오기
%matplotlib 인라인
텐서플로를 tf로 가져오기
tensorflow import Keras에서
2단계 – 데이터 세트 가져오기 및 분할
라이브러리를 가져오면 다음 단계는 데이터 세트를 다운로드하고 Fashion MNIST 데이터 세트를 각각의 60,000개의 교육 데이터와 10,000개의 테스트 데이터로 분할하는 것입니다. 다행히 keras는 Fashion MNIST 데이터 세트를 가져오기 위한 사전 정의된 기능을 제공하며 우리는 스스로 이해할 수 있는 간단한 코드 라인을 사용하여 다음 라인에서 이를 분할할 수 있습니다.
#TensorFlow – 데이터 세트 가져오기 및 분할
fashion_mnist = keras.datasets.fashion_mnist
(train_images_tf, train_labels_tf), (test_images_tf, test_labels_tf) = fashion_mnist.load_data()
3단계 – 데이터 시각화
데이터 세트가 이미지 및 해당 레이블과 함께 다운로드될 때 사용자에게 더 명확하게 하기 위해 항상 데이터를 보는 것이 좋습니다. 그러면 우리가 컨볼루션 신경망 빌드를 처리하는 데이터 유형을 이해할 수 있습니다. 그에 따른 네트워크 모델. 여기에서 아래에 제공된 이 간단한 코드 블록을 사용하여 무작위로 섞인 훈련 데이터 세트의 처음 3개 이미지를 시각화합니다.
#TensorFlow – 데이터 시각화
def imshowTensorFlow(img):
plt.imshow(img, cmap='회색')
print("레이블:", img[0])
imshowTensorFlow(train_images_tf[0])
레이블: 9 레이블: 0 레이블: 3
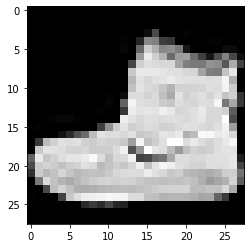


위에 제공된 이미지와 해당 레이블은 위의 Fashion MNIST 데이터 세트 세부 정보에 제공된 레이블로 확인할 수 있습니다. 이를 통해 데이터 이미지가 높이 28픽셀, 너비 28픽셀의 회색조 이미지임을 추론합니다.
따라서 모델은 (28,28,1)의 입력 크기로 구축될 수 있으며, 여기서 1은 회색조 이미지를 나타냅니다.
4단계 – 모델 구축
위에서 언급했듯이 이 기사에서는 LeNet 아키텍처를 사용하여 간단한 Convolutional Neural Network를 구축할 것입니다. LeNet은 Yann LeCun et al.이 제안한 합성곱 신경망 구조입니다. 일반적으로 LeNet은 LeNet-5를 말하며 간단한 Convolutional Neural Network입니다.
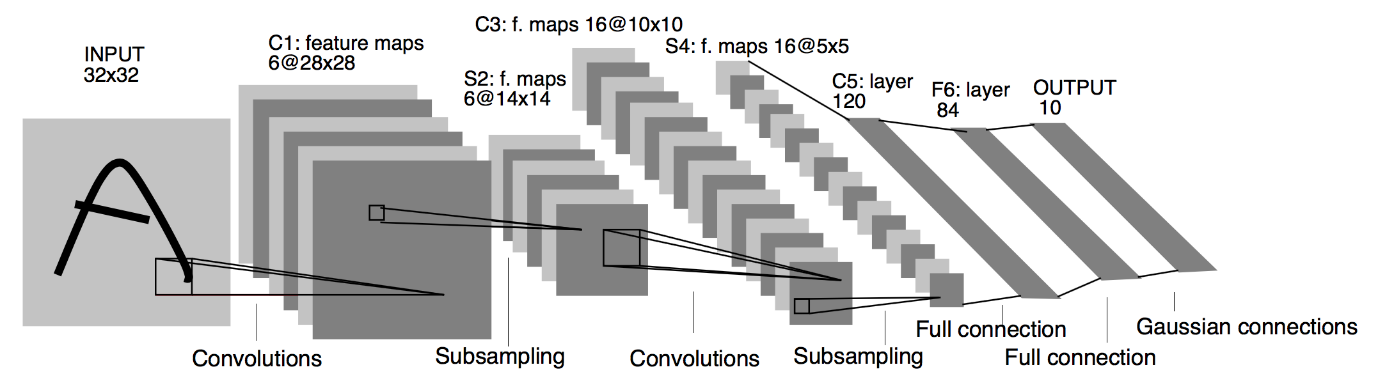
출처 : LeNet 아키텍처
위의 LeNet CNN 모델 아키텍처 다이어그램에서 5+2 레이어가 있음을 알 수 있습니다. 첫 번째 및 두 번째 레이어는 Convolutional 레이어와 Pooling 레이어입니다. 다시 말하지만, 세 번째와 네 번째 레이어는 Convolutional 레이어와 Pooling 레이어로 구성됩니다. 이러한 작업의 결과로 입력 이미지의 크기는 28×28에서 7×7로 줄어듭니다.
LeNet 모델의 다섯 번째 계층은 이전 계층의 출력을 평면화하는 완전 연결 계층입니다. 두 개의 Dense 레이어가 뒤따르는 CNN 모델의 최종 출력 레이어는 10개 단위의 Softmax 활성화 함수로 구성됩니다. Softmax 함수는 Fashion MNIST 데이터 세트의 10개 클래스 각각에 대한 클래스 확률을 예측합니다.
#TensorFlow – 모델 구축
모델 = keras.Sequential([
keras.layers.Conv2D(input_shape=(28,28,1), 필터=6, kernel_size=5, strides=1, 패딩="동일", 활성화=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, strides=2),
keras.layers.Conv2D(16, kernel_size=5, strides=1, 패딩="동일", 활성화=tf.nn.relu),
keras.layers.AveragePooling2D(pool_size=2, strides=2),
keras.layers.Flatten(),
keras.layers.Dense(120, 활성화=tf.nn.relu),
keras.layers.Dense(84, 활성화=tf.nn.relu),
keras.layers.Dense(10, 활성화=tf.nn.softmax)
])
5단계 – 모델 요약
LeNet 모델의 레이어가 완성되면 모델을 컴파일하고 설계된 CNN 모델의 요약 버전을 볼 수 있습니다.
#TensorFlow – 모델 요약
model.compile(loss=keras.losses.categorical_crossentropy,
옵티마이저 = '아담',
측정항목=['acc'])
model.summary()
여기서 최종 출력에는 2개 이상의 클래스(10개 클래스)가 있으므로 손실 함수로 범주형 교차 엔트로피를 사용하고 모델을 구축하기 위해 Adam Optimizer를 사용합니다. 모델 요약은 아래와 같습니다.
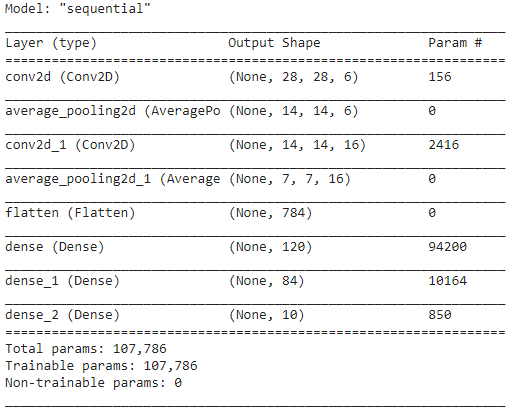
6단계 – 모델 훈련
마지막으로 LeNet CNN 모델의 학습 과정을 시작하는 부분에 도달합니다. 먼저 훈련 데이터 세트를 재구성하고 계산 비용을 줄이기 위해 255.0으로 나누어 더 작은 값으로 정규화합니다. 그런 다음 훈련 레이블이 정수 클래스 벡터에서 이진 클래스 행렬로 변환됩니다. 예를 들어 레이블 3은 [0, 0, 0, 1, 0, 0, 0, 0, 0]으로 변환됩니다.
#TensorFlow – 모델 학습
train_images_tensorflow = (기차_이미지_tf/255.0).reshape(기차_이미지_tf.shape[0], 28, 28, 1)
test_images_tensorflow = (test_images_tf / 255.0).reshape(test_images_tf.shape[0], 28, 28,1)
train_labels_tensorflow=keras.utils.to_categorical(train_labels_tf)
test_labels_tensorflow=keras.utils.to_categorical(test_labels_tf)
H = model.fit(train_images_tensorflow, train_labels_tensorflow, epochs=30, batch_size=32)
30 epoch 후 훈련이 끝나면 최종 훈련 정확도와 손실을 다음과 같이 얻습니다.
신기원 30/30
1875/1875 [===============================] – 4초 2ms/단계 – 손실: 0.0421 – 정확도: 0.9850
훈련 정확도: 98.294997215271 %
훈련 손실: 0.04584110900759697
7단계 – 결과 예측
마지막으로 CNN 모델의 훈련 과정이 끝나면 테스트 데이터 세트에 동일한 모델을 맞추고 10,000개의 테스트 이미지의 정확도를 예측합니다.
#TensorFlow – 결과 비교
예측 = model.predict(test_images_tensorflow)
맞음 = 0
i에 대해 열거(예측)에서 pred:
np.argmax(pred) == test_labels_tf[i]인 경우:
정확한 += 1
print('{} 테스트 이미지에서 모델의 테스트 정확도: {}% with TensorFlow'.format(test_images_tf.shape[0],100 * correct/test_images_tf.shape[0]))
우리가 얻는 출력은,
10000개의 테스트 이미지에서 모델의 테스트 정확도: TensorFlow 사용 시 90.67%
이것으로 Convolutional Neural Networks로 이미지 분류 모델을 구축하는 프로그램을 마치겠습니다.
더 읽어보기: 기계 학습 프로젝트 아이디어
결론
따라서 CNN에서 이미지 분류를 구현하는 방법에 대한 이 자습서에서는 TensorFlow 프레임워크를 사용하여 Python 프로그래밍 언어로 구현하는 것과 함께 이미지 분류, 컨볼루션 신경망의 기본 개념을 이해했습니다.
기계 학습에 대해 자세히 알아보려면 IIIT-B 및 upGrad의 기계 학습 및 AI PG 디플로마를 확인하세요. 이 PG 디플로마는 일하는 전문가를 위해 설계되었으며 450시간 이상의 엄격한 교육, 30개 이상의 사례 연구 및 과제, IIIT- B 동문 자격, 5개 이상의 실용적인 실습 캡스톤 프로젝트 및 최고의 기업과의 취업 지원.
이미지 분류에 가장 적합한 CNN 모델은 무엇입니까?
이미지 분류를 위한 최고의 CNN 모델은 VGG-16으로, 이는 대규모 이미지 인식을 위한 매우 깊은 컨볼루션 네트워크(Very Deep Convolutional Networks for Large-Scale Image Recognition)입니다. 심층 CNN으로 설계된 VGG는 ImageNet 외부의 광범위한 작업 및 데이터 세트에서 기준선을 능가합니다. 이 모델의 특징은 생성 시 많은 하이퍼 매개변수를 추가하는 것보다 우수한 컨볼루션 레이어를 통합하는 데 더 많은 관심을 기울였다는 것입니다. 총 16개의 레이어, 5개의 블록으로 구성되며 각 블록은 최대 풀링 레이어를 가지고 있어 상당히 큰 네트워크입니다.
이미지 분류에 CNN 모델을 사용할 때의 단점은 무엇입니까?
이미지 분류와 관련하여 CNN 모델은 매우 성공적입니다. 그러나 CNN을 사용하는 데에는 몇 가지 단점이 있습니다. 식별하고자 하는 그림이 기울어지거나 회전되면 CNN 모델은 이미지를 정확하게 식별하는데 문제가 있다. CNN이 이미지를 시각화할 때 구성 요소와 구성 요소의 부분-전체 연결에 대한 내부 표현이 없습니다. 또한, 적용할 CNN 모델이 다수의 convolutional layer를 포함하는 경우, 분류 과정에 오랜 시간이 소요됩니다.
이미지 데이터를 입력으로 사용할 때 ANN보다 CNN 모델을 선호하는 이유는 무엇입니까?
필터 또는 변환을 결합하여 CNN은 입력으로 제공되는 모든 이미지에 대해 여러 계층의 특징 표현을 학습할 수 있습니다. CNN에서 학습할 네트워크의 매개변수 수가 다층 신경망보다 훨씬 적기 때문에 과적합이 감소합니다. ANN을 사용할 때 신경망은 이미지의 단일 기능 표현을 학습할 수 있지만 복잡한 이미지의 경우 ANN은 입력 이미지에 존재하는 픽셀 종속성을 학습할 수 없기 때문에 향상된 시각화 또는 분류를 제공하지 못합니다.