
HTTP/3: 성능 향상(2부)
게시 됨: 2022-03-10새로운 HTTP/3 프로토콜에 대한 이 시리즈에 오신 것을 환영합니다. 1부에서는 HTTP/3와 기본 QUIC 프로토콜이 정확히 필요한 이유와 주요 새로운 기능이 무엇인지 살펴보았습니다.
이 두 번째 부분에서는 QUIC 및 HTTP/3가 웹 페이지 로드를 위해 테이블에 가져오는 성능 향상 을 확대할 것입니다. 그러나 실제로 이러한 새로운 기능에서 기대할 수 있는 영향에 대해서도 다소 회의적입니다.
앞으로 보게 되겠지만, QUIC와 HTTP/3는 실제로 훌륭한 웹 성능 잠재력을 가지고 있지만 주로 느린 네트워크를 사용하는 사용자에게 적합합니다 . 일반 방문자가 고속 케이블 또는 셀룰러 네트워크에 있는 경우 새 프로토콜의 이점을 그다지 얻지 못할 것입니다. 그러나 일반적으로 빠른 업링크가 있는 국가 및 지역에서도 잠재고객의 가장 느린 1%에서 10%(소위 99 번째 백분위수 또는 90번째 백분위수 )는 여전히 잠재적으로 많은 이득을 얻을 수 있습니다. HTTP/3 및 QUIC가 주로 오늘날의 인터넷에서 발생할 수 있는 다소 드물지만 잠재적으로 큰 영향을 미치는 문제를 처리하는 데 도움이 되기 때문입니다.
이 부분은 첫 번째 부분보다 약간 더 기술적인 부분입니다. 하지만 이러한 부분이 일반 웹 개발자에게 중요한 이유를 설명하는 데 중점을 두고 외부 소스에 대한 대부분의 정말 깊은 내용을 오프로드합니다.
- 1부: HTTP/3의 역사와 핵심 개념
이 기사는 HTTP/3 및 일반적인 프로토콜을 처음 접하는 사람들을 대상으로 하며 주로 기본 사항에 대해 설명합니다. - 2부: HTTP/3 성능 기능
이것은 더 깊이 있고 기술적인 것입니다. 기본 사항을 이미 알고 있는 사람들은 여기에서 시작할 수 있습니다. - 3부: 실용적인 HTTP/3 배포 옵션
이 시리즈의 세 번째 기사에서는 HTTP/3을 직접 배포하고 테스트하는 것과 관련된 문제에 대해 설명합니다. 웹 페이지와 리소스도 변경해야 하는 방법과 변경 여부에 대해 자세히 설명합니다.
속도에 대한 입문서
성능과 "속도"에 대한 논의는 빠르게 복잡해질 수 있습니다. 많은 기본 측면이 웹 페이지 로딩에 "천천히" 기여하기 때문입니다. 여기에서는 네트워크 프로토콜을 다루기 때문에 네트워크 측면을 주로 살펴보고 그 중 가장 중요한 두 가지는 대기 시간과 대역폭입니다.
대기 시간은 A 지점(예: 클라이언트)에서 B 지점(서버)으로 패킷을 보내는 데 걸리는 시간 으로 대략 정의할 수 있습니다. 그것은 물리적으로 빛의 속도 또는 실제로 신호가 전선이나 야외에서 얼마나 빨리 이동할 수 있는지에 의해 제한됩니다. 즉, 지연 시간은 종종 A와 B 사이의 물리적인 실제 거리에 따라 달라집니다.
지구에서 이는 일반적인 대기 시간이 개념적으로 약 10~200밀리초로 짧음을 의미합니다. 그러나 이것은 한 가지 방법일 뿐입니다. 패킷에 대한 응답도 다시 돌아와야 합니다. 양방향 지연은 종종 왕복 시간(RTT) 이라고 합니다.
혼잡 제어 (아래 참조)와 같은 기능으로 인해 단일 파일을 로드하는 데에도 꽤 많은 왕복이 필요한 경우가 많습니다. 따라서 지연 시간이 50밀리초 미만인 경우에도 상당한 지연이 발생할 수 있습니다. 이것이 콘텐츠 전송 네트워크(CDN)가 존재하는 주요 이유 중 하나입니다. CDN은 대기 시간을 줄여 최대한 지연시키기 위해 서버를 최종 사용자와 물리적으로 더 가깝게 배치합니다.
그러면 대역폭은 대략적으로 동시에 보낼 수 있는 패킷 수라고 할 수 있습니다 . 이것은 매체의 물리적 속성(예: 전파의 사용 주파수), 네트워크의 사용자 수 및 서로 다른 하위 네트워크를 상호 연결하는 장치에 따라 다르기 때문에 설명하기가 조금 더 어렵습니다. 일반적으로 초당 특정 수의 패킷만 처리할 수 있습니다.
자주 사용되는 은유는 물을 운반하는 데 사용되는 파이프의 은유입니다. 파이프의 길이는 대기 시간이고 파이프의 너비는 대역폭입니다. 그러나 인터넷에는 일반적으로 긴 일련의 연결된 파이프 가 있으며 그 중 일부는 다른 것보다 넓을 수 있습니다(가장 좁은 링크에서 소위 병목 현상이 발생함). 따라서 지점 A와 B 사이의 종단 간 대역폭은 종종 가장 느린 하위 섹션에 의해 제한됩니다.
이 포스트의 나머지 부분에서는 이러한 개념에 대한 완벽한 이해가 필요하지 않지만 공통된 높은 수준의 정의를 갖는 것이 좋습니다. 자세한 내용은 Ilya Grigorik의 저서 High Performance Browser Networking 에서 대기 시간 및 대역폭에 대한 뛰어난 장을 확인하는 것이 좋습니다.
혼잡 통제
성능의 한 측면은 전송 프로토콜이 네트워크의 전체(물리적) 대역폭을 얼마나 효율적 으로 사용할 수 있는지에 관한 것입니다(즉, 대략적으로 초당 몇 개의 패킷을 보내거나 받을 수 있는지). 이는 페이지의 리소스를 얼마나 빨리 다운로드할 수 있는지에 영향을 줍니다. 일부에서는 QUIC가 TCP보다 이 작업을 훨씬 더 잘 수행한다고 주장하지만 이는 사실이 아닙니다.
알고 계셨나요?
예를 들어 TCP 연결은 전체 대역폭에서 데이터 전송을 시작하지 않습니다. 이는 네트워크에 과부하(또는 혼잡)를 초래할 수 있기 때문입니다. 우리가 말했듯이 각 네트워크 링크에는 초당 (물리적으로) 처리할 수 있는 데이터의 양만 있기 때문입니다. 더 이상 주면 패킷 손실 로 이어지는 과도한 패킷을 삭제하는 것 외에 다른 옵션이 없습니다.
1부에서 논의한 바와 같이 TCP와 같은 신뢰할 수 있는 프로토콜의 경우 패킷 손실을 복구하는 유일한 방법은 데이터의 새 복사본을 재전송하는 것이며 이 작업에는 한 번의 왕복이 소요됩니다. 특히 대기 시간이 긴 네트워크(예: 50밀리초 이상의 RTT 사용)에서 패킷 손실은 성능에 심각한 영향을 미칠 수 있습니다.
또 다른 문제는 최대 대역폭 이 얼마인지 미리 알 수 없다는 것입니다. 종종 종단 간 연결의 어딘가에 병목 현상이 발생하지만 이것이 어디에 있는지 예측하거나 알 수 없습니다. 인터넷은 또한 링크 용량을 끝점으로 다시 보내는 신호를 보내는 메커니즘(아직)이 없습니다.
또한 사용 가능한 물리적 대역폭을 알고 있다고 해도 모든 대역폭을 직접 사용할 수 있다는 의미는 아닙니다. 일반적으로 여러 사용자가 네트워크에서 동시에 활성 상태이며 각 사용자는 사용 가능한 대역폭의 공정한 공유가 필요합니다.
따라서 연결은 사전에 얼마나 많은 대역폭을 안전하거나 공정하게 사용할 수 있는지 알지 못하며 이 대역폭은 사용자가 네트워크에 가입, 탈퇴 및 사용함에 따라 변경될 수 있습니다. 이 문제를 해결하기 위해 TCP는 정체 제어 라는 메커니즘을 사용하여 시간이 지남에 따라 사용 가능한 대역폭을 지속적으로 찾으려고 시도합니다.
연결이 시작될 때 몇 개의 패킷(실제로는 10~100개 패킷 또는 약 14~140KB 데이터 범위)만 보내고 수신자가 이러한 패킷에 대한 승인을 다시 보낼 때까지 한 번의 왕복을 기다립니다. 모두 승인되면 네트워크가 해당 전송 속도를 처리할 수 있으며 더 많은 데이터를 사용하여 프로세스를 반복할 수 있음을 의미합니다(실제로 전송 속도는 일반적으로 반복할 때마다 두 배가 됨).
이런 식으로 전송 속도는 일부 패킷이 확인되지 않을 때까지 계속 증가 합니다(패킷 손실 및 네트워크 정체를 나타냄). 이 첫 번째 단계를 일반적으로 "느린 시작"이라고 합니다. 패킷 손실을 감지하면 TCP는 전송 속도를 줄이고 (잠시 후) 전송 속도를 (훨씬) 더 작은 증분으로 다시 증가시키기 시작합니다. 이 감소 후 증가 논리는 이후의 모든 패킷 손실에 대해 반복됩니다. 결국 이것은 TCP가 이상적이고 공정한 대역폭 공유에 도달하기 위해 지속적으로 노력한다는 것을 의미합니다. 이 메커니즘은 그림 1에 나와 있습니다.
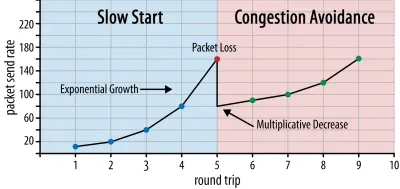
이것은 혼잡 제어에 대한 지나치게 단순화된 설명입니다. 실제로는 버퍼 블로트, 혼잡으로 인한 RTT의 변동, 여러 동시 발신자가 대역폭을 공정하게 공유해야 한다는 사실과 같은 많은 다른 요인이 작용합니다. 이와 같이 다양한 혼잡 제어 알고리즘이 존재하며 오늘날에도 여전히 많은 것이 개발되고 있으며 모든 상황에서 최적의 성능을 발휘하는 알고리즘은 없습니다.
TCP의 혼잡 제어는 TCP를 강력하게 만들지만 RTT 및 실제 사용 가능한 대역폭에 따라 최적의 전송 속도에 도달 하는 데 시간이 걸립니다. 웹 페이지 로드의 경우 이 느린 시작 방식은 처음 몇 번 왕복할 때 소량의 데이터(수십 ~ 수백 KB)만 전송할 수 있기 때문에 콘텐츠가 포함된 첫 번째 페인트와 같은 메트릭에도 영향을 줄 수 있습니다. (중요한 데이터를 14KB 미만으로 유지하라는 권장 사항을 들어보셨을 것입니다.)
따라서 보다 적극적인 접근 방식을 선택하면 특히 가끔 발생하는 패킷 손실에 신경 쓰지 않는 경우 고대역폭 및 대기 시간이 긴 네트워크에서 더 나은 결과를 얻을 수 있습니다. 여기에서 QUIC의 작동 방식에 대한 많은 잘못된 해석 을 다시 보았습니다.
1부에서 논의한 바와 같이 QUIC는 이론적으로 각 리소스의 바이트 스트림에 대한 패킷 손실을 독립적으로 처리하기 때문에 패킷 손실(및 관련 HOL(head-of-line) 차단)을 덜 겪습니다. 또한 QUIC는 TCP와 달리 혼잡 제어 기능이 내장되어 있지 않은 UDP( 사용자 데이터그램 프로토콜 )를 통해 실행됩니다. 원하는 속도로 전송할 수 있으며 손실된 데이터를 재전송하지 않습니다.
이로 인해 QUIC도 혼잡 제어를 사용하지 않고 대신 QUIC가 UDP를 통해 훨씬 더 높은 속도로 데이터 전송을 시작할 수 있다고 주장하는 많은 기사로 이어졌습니다(패킷 손실을 처리하기 위해 HOL 차단 제거에 의존). 이것이 바로 그 이유입니다. QUIC는 TCP보다 훨씬 빠릅니다.
실제로 QUIC는 실제로 TCP와 매우 유사한 대역폭 관리 기술을 사용합니다 . 또한 낮은 전송률에서 시작하여 시간이 지남에 따라 증가하며 승인을 네트워크 용량을 측정하는 핵심 메커니즘으로 사용합니다. 이것은 (다른 이유 중) QUIC가 HTTP와 같은 것에 유용하기 위해 신뢰할 수 있어야 하고, 다른 QUIC(및 TCP!) 연결에 공정해야 하고, HOL 차단 제거가 수행되지 않기 때문입니다. 실제로 패킷 손실을 방지하는 데 도움이 됩니다(아래에서 볼 수 있음).
그러나 이것이 QUIC가 TCP보다 대역폭을 관리하는 방법에 대해 (조금) 더 똑똑할 수 없다는 것을 의미하지는 않습니다. 이것은 주로 QUIC가 TCP보다 더 유연하고 진화하기 쉽기 때문입니다. 우리가 말했듯이 혼잡 제어 알고리즘은 오늘날에도 여전히 크게 발전하고 있으며 예를 들어 5G를 최대한 활용하기 위해 상황을 조정해야 할 것입니다.
그러나 TCP는 일반적으로 운영 체제(OS') 커널에서 구현되며, 이는 대부분의 OS에서 오픈 소스도 아닌 안전하고 더 제한된 환경입니다. 따라서 혼잡 논리 조정은 일반적으로 선택된 소수의 개발자에 의해서만 수행되며 발전 속도가 느립니다.
대조적으로, 대부분의 QUIC 구현은 현재 "사용자 공간"(일반적으로 기본 앱을 실행하는 곳)에서 수행되고 있으며 훨씬 더 광범위한 개발자 풀의 실험을 명시적으로 장려하기 위해 오픈 소스로 만들어졌습니다(예: Facebook ).
또 다른 구체적인 예는 QUIC에 대한 지연된 승인 주파수 확장 제안입니다. 기본적으로 QUIC는 수신된 패킷 2개마다 승인을 전송하지만 이 확장을 사용하면 엔드포인트가 대신 예를 들어 패킷 10개마다 승인할 수 있습니다. 이는 승인 패킷을 전송하는 오버헤드가 낮아지기 때문에 위성 및 고대역폭 네트워크에서 큰 속도 이점 을 제공하는 것으로 나타났습니다. TCP에 이러한 확장을 추가하면 채택하는 데 오랜 시간이 걸리지만 QUIC의 경우 배포하기가 훨씬 쉽습니다.
따라서 우리는 QUIC의 유연성이 시간이 지남에 따라 더 많은 실험과 더 나은 혼잡 제어 알고리즘으로 이어질 것이며, 이를 개선하기 위해 TCP로 백포트될 수도 있습니다.
알고 계셨나요?
공식 QUIC Recovery RFC 9002는 NewReno 혼잡 제어 알고리즘의 사용을 지정합니다. 이 접근 방식은 강력하지만 다소 구식 이어서 실제로 더 이상 광범위하게 사용되지 않습니다. 그렇다면 QUIC RFC에 있는 이유는 무엇입니까? 첫 번째 이유는 QUIC이 시작되었을 때 NewReno가 자체적으로 표준화된 가장 최근의 혼잡 제어 알고리즘이었기 때문입니다. BBR 및 CUBIC과 같은 고급 알고리즘은 아직 표준화되지 않았거나 최근에야 RFC가 되었습니다.
두 번째 이유는 NewReno가 비교적 간단한 설정이기 때문입니다. 알고리즘은 TCP와 QUIC의 차이점을 처리하기 위해 약간의 조정이 필요하기 때문에 더 간단한 알고리즘에서 이러한 변경 사항을 설명하는 것이 더 쉽습니다. 따라서 RFC 9002는 "이것이 QUIC에 사용해야 하는 것"이 아니라 "혼잡 제어 알고리즘을 QUIC에 적용하는 방법"으로 더 읽어야 합니다. 실제로 대부분의 프로덕션 수준 QUIC 구현은 Cubic 및 BBR 모두의 사용자 지정 구현을 만들었습니다.
혼잡 제어 알고리즘 이 TCP 또는 QUIC에 고유하지 않다는 것을 반복합니다. 두 프로토콜 모두에서 사용할 수 있으며 QUIC의 발전이 결국에는 TCP 스택에도 적용되기를 바랍니다.
알고 계셨나요?
혼잡 제어 다음에는 흐름 제어라는 관련 개념이 있습니다. 이 두 가지 기능은 TCP에서 종종 혼동되는데, 그 이유는 둘 다 "TCP 창" 을 사용한다고 하기 때문입니다. 실제로는 혼잡 창과 TCP 수신 창이라는 두 개의 창이 있습니다. 그러나 흐름 제어는 우리가 관심을 갖고 있는 웹 페이지 로딩의 사용 사례에서 훨씬 덜 작동하므로 여기에서 건너뛸 것입니다. 더 자세한 정보를 얻을 수 있습니다.
모든 것은 무엇을 의미합니까?
QUIC는 여전히 물리학 법칙과 인터넷의 다른 발신자에게 친절해야 할 필요가 있습니다. 즉, TCP보다 훨씬 빠르게 웹 사이트 리소스를 마술처럼 다운로드 하지 않습니다 . 그러나 QUIC의 유연성은 새로운 혼잡 제어 알고리즘을 실험하는 것이 더 쉬워지고 TCP와 QUIC 모두에 대해 향후 개선될 것임을 의미합니다.
0-RTT 연결 설정
두 번째 성능 측면은 새 연결에서 유용한 HTTP 데이터(예: 페이지 리소스)를 보내기 전에 얼마나 많은 왕복 이 필요한지에 관한 것입니다. 일부에서는 QUIC가 TCP + TLS보다 왕복 2~3회 더 빠르다고 주장하지만 실제로는 1회에 불과합니다.
알고 계셨나요?
1부에서 말했듯이 연결은 일반적으로 HTTP 요청과 응답을 교환하기 전에 한 번(TCP) 또는 두 번(TCP + TLS) 핸드셰이크를 수행합니다. 이러한 핸드셰이크는 예를 들어 데이터를 암호화하기 위해 클라이언트와 서버가 모두 알아야 하는 초기 매개변수를 교환합니다.
아래 그림 2에서 볼 수 있듯이 각 개별 핸드셰이크는 완료하는 데 최소 한 번의 왕복이 필요하고(TCP + TLS 1.3, (b)) 때로는 두 번(TLS 1.2 및 이전 (a))이 필요합니다. 이것은 비효율적입니다. 첫 번째 HTTP 요청을 보내기 전에 핸드셰이크 대기 시간(오버헤드)이 두 번 이상 필요하기 때문입니다. 즉, 첫 번째 HTTP 응답 데이터(반환하는 빨간색 화살표)가 올 때까지 세 번 이상 기다려야 합니다. 느린 네트워크에서 이것은 100~200밀리초의 오버헤드를 의미할 수 있습니다.
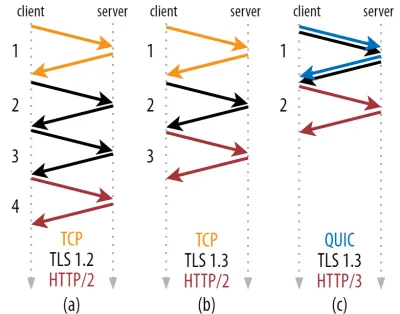
TCP + TLS 핸드셰이크를 동일한 왕복으로 간단히 결합할 수 없는 이유가 궁금할 것입니다. 이것은 개념적으로 가능하지만(QUIC은 정확히 그렇게 합니다) 처음에는 TLS가 있거나 없는 TCP를 사용할 수 있어야 하기 때문에 처음에는 이와 같이 설계되지 않았습니다. 달리 말하면 TCP는 핸드셰이크 중에 TCP가 아닌 항목을 보내는 것을 지원하지 않습니다 . TCP Fast Open 확장으로 이것을 추가하려는 노력이 있었습니다. 그러나 1부에서 논의한 것처럼 대규모 배포가 어려운 것으로 나타났습니다.
운 좋게도 QUIC는 처음부터 TLS를 염두에 두고 설계되었으므로 단일 메커니즘에서 전송 및 암호화 핸드셰이크를 모두 결합합니다. 즉, QUIC 핸드셰이크는 TCP + TLS 1.3(위의 그림 2c 참조)보다 1회 적은 총 1회 왕복만 소요됩니다.
QUIC가 TCP보다 1회가 아니라 2회 또는 3회 왕복 빠르다는 것을 읽었기 때문에 혼란스러울 수 있습니다. 이는 대부분의 기사에서 최신 TCP + TLS 1.3이 "만" 두 번 왕복한다는 점을 언급하지 않고 최악의 경우(TCP + TLS 1.2, (a))만 고려하기 때문입니다((b)는 거의 표시되지 않음). 1회 왕복의 속도 향상은 좋지만 놀라운 것은 아닙니다. 특히 빠른 네트워크(예: 50밀리초 미만의 RTT)에서는 이러한 현상이 거의 눈에 띄지 않지만 느린 네트워크와 원격 서버에 대한 연결은 약간의 이익을 얻을 수 있습니다.
다음으로 악수를 기다려야 하는 이유가 궁금할 것입니다. 첫 번째 왕복에서 HTTP 요청을 보낼 수 없는 이유는 무엇입니까? 이는 주로 우리가 그렇게 한다면 첫 번째 요청이 암호화되지 않은 상태 로 전송되어 유선상의 도청자가 읽을 수 있기 때문입니다. 이는 분명히 개인 정보 보호 및 보안에 좋지 않습니다. 따라서 첫 번째 HTTP 요청을 보내기 전에 암호화 핸드셰이크가 완료될 때까지 기다려야 합니다. 아니면 우리는?
이것은 영리한 트릭이 실제로 사용되는 곳입니다. 우리는 사용자가 첫 방문 후 짧은 시간 내에 웹 페이지를 재방문하는 경우가 많다는 것을 알고 있습니다. 따라서 초기 암호화 연결 을 사용하여 향후 두 번째 연결을 부트스트랩할 수 있습니다. 간단히 말해서, 수명 중 언젠가는 첫 번째 연결을 사용하여 클라이언트와 서버 간에 새로운 암호화 매개변수를 안전하게 통신할 수 있습니다. 그런 다음 이러한 매개변수를 사용하여 전체 TLS 핸드셰이크가 완료될 때까지 기다릴 필요 없이 처음부터 두 번째 연결을 암호화 할 수 있습니다. 이 접근 방식을 "세션 재개"라고 합니다.
강력한 최적화가 가능합니다. 이제 QUIC/TLS 핸드셰이크와 함께 첫 번째 HTTP 요청을 안전하게 보낼 수 있어 또 다른 왕복을 절약할 수 있습니다! TLS 1.3의 경우 TLS 핸드셰이크의 대기 시간을 효과적으로 제거합니다. 이 방법은 종종 0-RTT라고 합니다(물론 HTTP 응답 데이터가 도착하기 시작하려면 한 번 왕복해야 하지만).
세션 재개와 0-RTT는 모두 QUIC 관련 기능으로 잘못 설명되는 경우가 종종 있었습니다. 실제로 이러한 기능 은 TLS 1.2에서 이미 어떤 형태로든 존재했고 이제 TLS 1.3에서 완전히 기능하는 TLS 기능입니다.
다르게 표현하면 아래 그림 3에서 볼 수 있듯이 TCP(따라서 HTTP/2 및 HTTP/1.1도 포함)를 통해 이러한 기능의 성능 이점을 얻을 수도 있습니다! 0-RTT를 사용하더라도 QUIC는 최적으로 작동하는 TCP + TLS 1.3 스택보다 단 한 번만 더 빠릅니다 . QUIC가 3번의 왕복이 더 빠르다는 주장은 그림 2의 (a)와 그림 3의 (f)를 비교하는 데서 비롯된 것입니다.
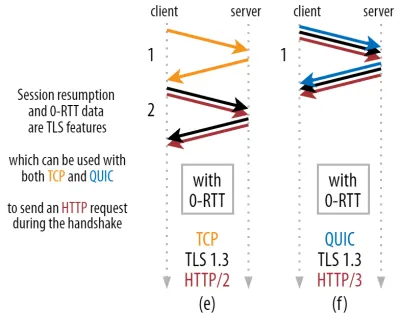
최악의 부분은 0-RTT를 사용할 때 QUIC가 보안으로 인해 얻은 왕복 여행을 제대로 사용할 수 없다는 것입니다. 이를 이해하려면 TCP 핸드셰이크가 존재하는 이유 중 하나를 이해해야 합니다. 첫째, 클라이언트는 상위 계층 데이터를 보내기 전에 주어진 IP 주소에서 서버가 실제로 사용 가능한지 확인할 수 있습니다.
두 번째로, 그리고 결정적으로 여기에서 서버는 연결을 여는 클라이언트가 데이터를 보내기 전에 실제로 누구이며 어디에 있는지 확인할 수 있습니다. 1부에서 4-튜플과의 연결을 정의한 방법을 기억한다면 클라이언트가 주로 IP 주소로 식별된다는 것을 알게 될 것입니다. 그리고 이것이 문제입니다. IP 주소는 스푸핑될 수 있습니다 !
공격자가 QUIC 0-RTT를 통해 HTTP를 통해 매우 큰 파일을 요청한다고 가정합니다. 그러나 그들은 자신의 IP 주소를 스푸핑하여 피해자의 컴퓨터에서 0-RTT 요청이 온 것처럼 보이게 합니다. 이는 아래 그림 4에 나와 있습니다. QUIC 서버는 IP가 스푸핑되었는지 여부를 감지할 방법이 없습니다. 이것이 해당 클라이언트에서 보는 첫 번째 패킷이기 때문입니다.

그런 다음 서버가 단순히 큰 파일을 스푸핑된 IP로 다시 보내기 시작 하면 피해자의 네트워크 대역폭에 과부하가 걸릴 수 있습니다(특히 공격자가 이러한 가짜 요청을 병렬로 많이 수행하는 경우). QUIC 응답은 들어오는 데이터를 기대하지 않기 때문에 피해자에 의해 삭제된다는 점에 유의하십시오. 그러나 그것은 중요하지 않습니다. 그들의 네트워크는 여전히 패킷을 처리해야 합니다!
이를 반사 또는 증폭 공격 이라고 하며 해커가 DDoS(분산 서비스 거부) 공격을 실행하는 중요한 방법입니다. TCP + TLS를 통한 0-RTT를 사용할 때는 이런 일이 발생하지 않습니다. 정확히는 0-RTT 요청이 TLS 핸드셰이크와 함께 전송되기 전에 먼저 TCP 핸드셰이크가 완료되어야 하기 때문입니다.
따라서 QUIC는 0-RTT 요청에 응답할 때 보수적이어야 하며 클라이언트가 피해자가 아닌 실제 클라이언트로 확인될 때까지 응답으로 보내는 데이터의 양을 제한해야 합니다. QUIC의 경우 이 데이터 양은 클라이언트에서 받은 양의 3배로 설정되었습니다.
달리 말하면, QUIC의 최대 "증폭 계수"는 3으로, 성능 유용성과 보안 위험 사이에 허용 가능한 절충점으로 결정되었습니다(특히 증폭 계수가 51,000배 이상인 일부 사건과 비교). 클라이언트는 일반적으로 1~2개의 패킷만 먼저 보내기 때문에 QUIC 서버의 0-RTT 응답은 4~6KB로 제한됩니다 (기타 QUIC 및 TLS 오버헤드 포함!). 이는 인상적이지 않은 수준입니다.
또한 다른 보안 문제로 인해 수행할 수 있는 HTTP 요청 유형이 제한되는 "재생 공격"이 발생할 수 있습니다. 예를 들어 Cloudflare는 0-RTT에서 쿼리 매개변수가 없는 HTTP GET 요청만 허용합니다. 이는 0-RTT의 유용성을 훨씬 더 제한합니다.
운 좋게도 QUIC에는 이를 조금 더 개선할 수 있는 옵션이 있습니다. 예를 들어, 서버는 0-RTT가 이전에 유효한 연결이 있었던 IP에서 온 것인지 확인할 수 있습니다. 그러나 클라이언트가 동일한 네트워크에 있는 경우에만 작동합니다(QUIC의 연결 마이그레이션 기능을 다소 제한함). 그리고 그것이 작동하더라도 QUIC의 응답은 위에서 논의한 정체 컨트롤러의 느린 시작 논리에 의해 여전히 제한됩니다. 따라서 저장된 한 번의 왕복 여행 외에 추가로 엄청난 속도 향상이 없습니다 .
알고 계셨나요?
QUIC의 3배 증폭 제한은 그림 2c의 일반적인 비0-RTT 핸드셰이크 프로세스에도 포함된다는 점에 주목하는 것이 흥미로웠습니다. 예를 들어 서버의 TLS 인증서가 너무 커서 4~6KB에 맞지 않는 경우 문제가 될 수 있습니다. 이 경우 분할되어야 하며 두 번째 청크는 두 번째 왕복이 전송될 때까지 기다려야 합니다(클라이언트의 IP가 스푸핑되지 않았음을 나타내는 처음 몇 개의 패킷 승인이 들어온 후). 이 경우 QUIC의 핸드셰이크는 여전히 TCP + TLS와 동일한 두 번의 왕복이 소요될 수 있습니다 ! 이것이 QUIC의 경우 인증서 압축과 같은 기술이 더욱 중요해지는 이유입니다.
알고 계셨나요?
특정 고급 설정은 이러한 문제를 완화하여 0-RTT를 더 유용하게 만들 수 있습니다. 예를 들어, 서버는 클라이언트가 마지막으로 볼 수 있었던 대역폭의 양을 기억할 수 있으므로 (스푸핑되지 않은) 클라이언트를 다시 연결하기 위한 정체 제어의 느린 시작에 의해 제한을 덜 받습니다. 이것은 학계에서 조사되었으며 이를 수행하기 위해 QUIC에서 제안된 확장도 있습니다. 여러 회사에서 이미 TCP 속도를 높이기 위해 이러한 유형의 작업을 수행하고 있습니다.
또 다른 옵션은 클라이언트 가 1개 또는 2개 이상의 패킷을 보내도록 하는 것 입니다(예: 패딩으로 7개 더 많은 패킷 보내기). 따라서 3배 제한은 연결 마이그레이션 후에도 더 흥미로운 12-14KB 응답으로 변환됩니다. 내 논문 중 하나에 이것에 대해 썼습니다.
마지막으로, (오작동하는) QUIC 서버는 그렇게 하는 것이 안전하다고 생각하거나 잠재적인 보안 문제에 관심이 없는 경우 의도적으로 3배 제한을 늘릴 수 있습니다(결국 이를 방지하는 프로토콜 경찰이 없음).
이 모든 것은 무엇을 의미합니까?
0-RTT를 사용한 QUIC의 더 빠른 연결 설정은 혁신적인 새 기능이라기보다 실제로는 마이크로 최적화에 가깝 습니다. 최첨단 TCP + TLS 1.3 설정과 비교할 때 최대 1회 왕복을 절약할 수 있습니다. 첫 번째 왕복에서 실제로 보낼 수 있는 데이터의 양은 여러 보안 고려 사항에 의해 추가로 제한됩니다.
따라서 이 기능은 사용자가 대기 시간이 매우 긴 네트워크(예: RTT가 200밀리초 이상인 위성 네트워크)에 있거나 일반적으로 데이터를 많이 보내지 않는 경우에 대부분 빛을 발합니다. 후자의 예로는 캐시가 많은 웹 사이트와 API 및 DNS-over-QUIC와 같은 기타 프로토콜을 통해 정기적으로 작은 업데이트를 가져오는 단일 페이지 앱이 있습니다. Google이 QUIC에 대해 매우 좋은 0-RTT 결과를 본 이유 중 하나는 쿼리 응답이 매우 작은 이미 고도로 최적화된 검색 페이지에서 테스트했기 때문입니다.
다른 경우에는 기껏해야 수십 밀리초 만 얻을 수 있으며 이미 CDN을 사용하고 있는 경우에는 훨씬 더 적습니다(성능에 관심이 있는 경우 수행해야 함).
연결 마이그레이션
세 번째 성능 기능은 기존 연결을 그대로 유지 하여 네트워크 간에 전송할 때 QUIC를 더 빠르게 만듭니다. 이것이 실제로 작동하는 동안 이러한 유형의 네트워크 변경은 자주 발생하지 않으며 연결은 여전히 전송 속도를 재설정해야 합니다.
1부에서 설명한 것처럼 QUIC의 연결 ID(CID)를 사용하면 네트워크를 전환 할 때 연결 마이그레이션을 수행할 수 있습니다. 우리는 대용량 파일 다운로드를 수행하면서 Wi-Fi 네트워크에서 4G로 이동하는 클라이언트를 사용하여 이를 설명했습니다. TCP의 경우 해당 다운로드를 중단해야 하지만 QUIC의 경우 계속할 수 있습니다.
그러나 먼저 그러한 유형의 시나리오가 실제로 얼마나 자주 발생하는지 고려하십시오. 이는 건물 내의 Wi-Fi 액세스 포인트 간이나 이동 중에 셀룰러 타워 간을 이동할 때도 발생한다고 생각할 수 있습니다. 그러나 이러한 설정에서(올바르게 수행된 경우) 무선 기지국 간의 전환이 하위 프로토콜 계층에서 수행되기 때문에 장치는 일반적으로 IP를 그대로 유지합니다. 따라서 이는 완전히 다른 네트워크 사이를 이동할 때만 발생하며 자주 발생하지는 않습니다.
둘째, 대용량 파일 다운로드와 라이브 화상 회의 및 스트리밍 외에 다른 사용 사례에서도 이것이 작동하는지 여부를 물어볼 수 있습니다. 네트워크를 전환하는 정확한 순간에 웹 페이지를 로드하는 경우 실제로 일부 (나중에) 리소스를 다시 요청해야 할 수도 있습니다.
그러나 페이지를 로드하는 데는 일반적으로 몇 초 정도 걸리므로 네트워크 스위치와 일치하는 경우도 그리 흔하지 않습니다. 또한 이것이 시급한 문제인 사용 사례의 경우 일반적으로 다른 완화 조치가 이미 마련되어 있습니다. 예를 들어, 대용량 파일 다운로드를 제공하는 서버는 재개 가능한 다운로드를 허용하기 위해 HTTP 범위 요청을 지원할 수 있습니다.
일반적으로 네트워크 1이 중단되고 네트워크 2를 사용할 수 있게 되는 사이에 약간의 겹침 시간 이 있기 때문에 비디오 앱은 여러 연결(네트워크당 1개)을 열어 이전 네트워크가 완전히 사라지기 전에 동기화할 수 있습니다. 사용자는 여전히 스위치를 알 수 있지만 비디오 피드를 완전히 삭제하지는 않습니다.
셋째, 새 네트워크가 이전 네트워크만큼 많은 대역폭을 사용할 수 있다는 보장이 없습니다. 따라서 개념적 연결은 그대로 유지되더라도 QUIC 서버는 데이터를 고속으로 계속 보낼 수 없습니다. 대신, 새 네트워크에 과부하가 걸리는 것을 방지 하려면 전송 속도를 재설정(또는 최소한 낮추어야)하고 정체 컨트롤러의 느린 시작 단계에서 다시 시작해야 합니다 .
이 초기 전송 속도는 일반적으로 비디오 스트리밍과 같은 것을 실제로 지원하기에는 너무 낮기 때문에 QUIC에서도 약간 의 품질 손실 이나 딸꾹질이 나타납니다. 어떤 면에서 연결 마이그레이션은 성능 향상보다 서버의 연결 컨텍스트 변동 및 오버헤드를 방지하는 데 더 가깝습니다.
알고 계셨나요?
위의 0-RTT에 대해 논의한 것처럼 연결 마이그레이션을 개선하기 위해 몇 가지 고급 기술을 고안할 수 있습니다. 예를 들어, 우리는 지난번에 주어진 네트워크에서 얼마나 많은 대역폭을 사용할 수 있었는지 다시 기억 하고 새로운 마이그레이션을 위해 해당 수준까지 더 빠르게 증가시키려고 시도할 수 있습니다. 또한 우리는 단순히 네트워크 사이를 전환하는 것이 아니라 두 가지를 동시에 사용하는 것을 상상할 수 있습니다. 이 개념을 multipath 라고 하며 아래에서 더 자세히 설명합니다.
지금까지 사용자가 서로 다른 네트워크 간에 이동하는 활성 연결 마이그레이션에 대해 주로 이야기했습니다. 그러나 특정 네트워크 자체가 매개변수를 변경하는 수동 연결 마이그레이션의 경우도 있습니다. 이것의 좋은 예는 네트워크 주소 변환(NAT) 리바인딩입니다. NAT에 대한 전체 논의는 이 기사의 범위를 벗어나지만 주로 연결의 포트 번호가 경고 없이 주어진 시간에 변경될 수 있음을 의미합니다. 이것은 또한 대부분의 라우터에서 TCP보다 UDP에 대해 훨씬 더 자주 발생합니다.
이 경우 QUIC CID는 변경되지 않으며 대부분의 구현에서는 사용자가 여전히 동일한 물리적 네트워크에 있다고 가정하므로 정체 창 또는 기타 매개변수를 재설정하지 않습니다. QUIC에는 일반적으로 장기간 유휴 연결에서 발생하기 때문에 이러한 일이 발생하지 않도록 하는 PING 및 시간 초과 표시기와 같은 일부 기능도 포함되어 있습니다.
우리는 1부에서 QUIC가 보안상의 이유로 단일 CID를 사용하지 않는다는 것을 논의했습니다. 대신 활성 마이그레이션을 수행할 때 CID를 변경합니다. 실제로는 클라이언트와 서버 모두에 별도의 CID 목록(QUIC RFC에서는 소스 및 대상 CID라고 함)이 있기 때문에 훨씬 더 복잡합니다. 이는 아래 그림 5에 나와 있습니다.
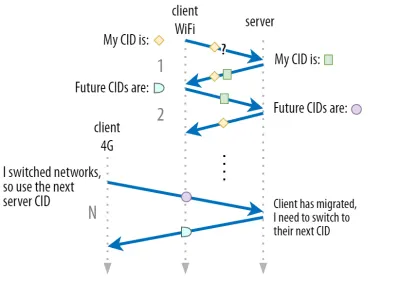
이는 각 엔드포인트가 고유한 CID 형식과 콘텐츠를 선택할 수 있도록 하기 위해 수행되며, 이는 차례로 고급 라우팅 및 로드 밸런싱 로직을 허용하는 데 중요합니다. 연결 마이그레이션을 통해 로드 밸런서는 더 이상 4-튜플을 보고 연결을 식별하고 올바른 백엔드 서버로 보낼 수 없습니다. 그러나 모든 QUIC 연결이 임의의 CID를 사용하는 경우 백엔드 서버에 대한 CID 매핑을 저장해야 하기 때문에 로드 밸런서의 메모리 요구 사항이 크게 증가합니다. 또한 CID가 새로운 임의 값으로 변경되기 때문에 연결 마이그레이션에서는 여전히 작동하지 않습니다.
따라서 로드 밸런서 뒤에 배치된 QUIC 백엔드 서버는 예측 가능한 CID 형식 을 갖고 있어 로드 밸런서가 마이그레이션 후에도 CID에서 올바른 백엔드 서버를 파생할 수 있도록 하는 것이 중요합니다. 이를 위한 몇 가지 옵션은 IETF의 제안 문서에 설명되어 있습니다. 이 모든 것을 가능하게 하려면 서버가 자체 CID를 선택할 수 있어야 합니다. 이는 연결 개시자(QUIC의 경우 항상 클라이언트임)가 CID를 선택했다면 불가능했을 것입니다. 이것이 QUIC에서 클라이언트와 서버 CID 사이에 분할이 있는 이유입니다.
이 모든 것은 무엇을 의미합니까?
따라서 연결 마이그레이션은 상황에 따른 기능입니다. 예를 들어, Google의 초기 테스트는 사용 사례에 대한 낮은 비율의 개선을 보여줍니다. 많은 QUIC 구현은 아직 이 기능을 구현하지 않습니다. 그렇게 하는 경우에도 일반적으로 데스크톱이 아닌 모바일 클라이언트 및 앱으로 제한합니다. 일부 사람들은 0-RTT로 새로운 연결을 열면 대부분의 경우 유사한 성능 속성을 가져야 하기 때문에 이 기능이 필요하지 않다는 의견도 있습니다.
그러나 사용 사례 또는 사용자 프로필에 따라 큰 영향을 미칠 수 있습니다. 웹사이트나 앱이 이동 중에 가장 자주 사용되는 경우 (예: Uber 또는 Google 지도) 사용자가 일반적으로 책상 뒤에 앉아 있을 때보다 더 많은 이점을 얻을 수 있습니다. Similarly, if you're focusing on constant interaction (be it video chat, collaborative editing, or gaming), then your worst-case scenarios should improve more than if you have a news website.
Head-of-Line Blocking Removal
The fourth performance feature is intended to make QUIC faster on networks with a high amount of packet loss by mitigating the head-of-line (HoL) blocking problem. While this is true in theory, we will see that in practice this will probably only provide minor benefits for web-page loading performance.
To understand this, though, we first need to take a detour and talk about stream prioritization and multiplexing.
Stream Prioritization
As discussed in part 1, a single TCP packet loss can delay data for multiple in-transit resources because TCP's bytestream abstraction considers all data to be part of a single file. QUIC, on the other hand, is intimately aware that there are multiple concurrent bytestreams and can handle loss on a per-stream basis. However, as we've also seen, these streams are not truly transmitting data in parallel: Rather, the stream data is multiplexed onto a single connection. This multiplexing can happen in many different ways.
For example, for streams A, B, and C, we might see a packet sequence of ABCABCABCABCABCABCABCABC , where we change the active stream in each packet (let's call this round-robin). However, we might also see the opposite pattern of AAAAAAAABBBBBBBBCCCCCCCC , where each stream is completed in full before starting the next one (let's call this sequential). Of course, many other options are possible in between these extremes ( AAAABBCAAAAABBC… , AABBCCAABBCC… , ABABABCCCC… , etc.). The multiplexing scheme is dynamic and driven by an HTTP-level feature called stream prioritization (discussed later in this article).
As it turns out, which multiplexing scheme you choose can have a huge impact on website loading performance. You can see this in the video below, courtesy of Cloudflare, as every browser uses a different multiplexer. The reasons why are quite complex, and I've written several academic papers on the topic, as well as talked about it in a conference. Patrick Meenan, of Webpagetest fame, even has a three-hour tutorial on just this topic.
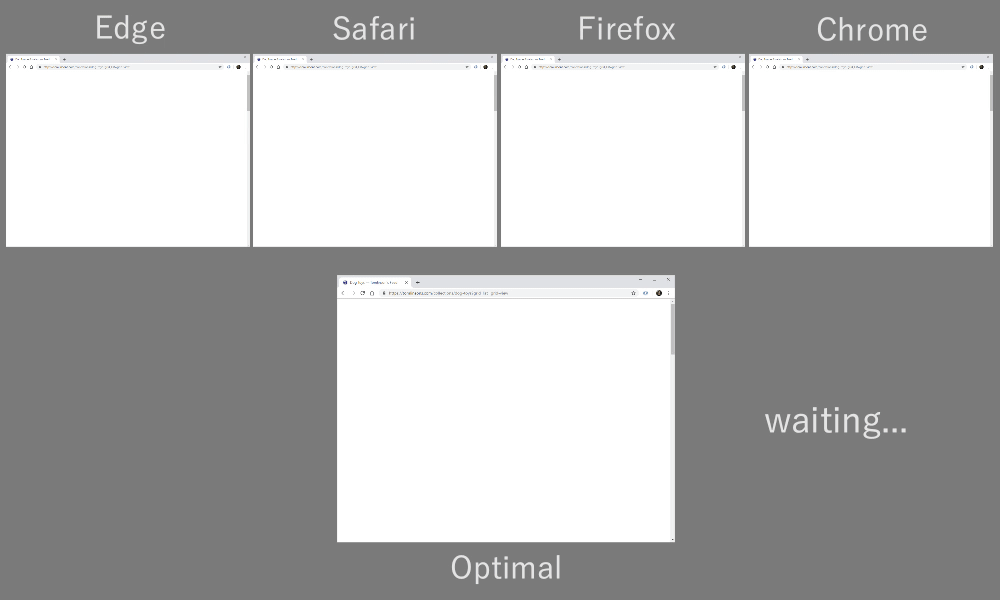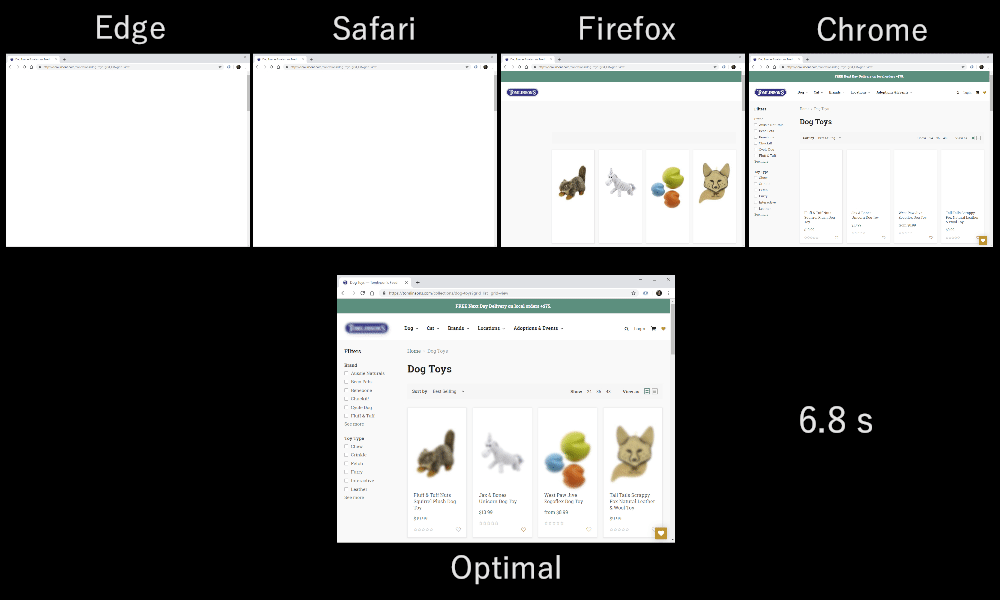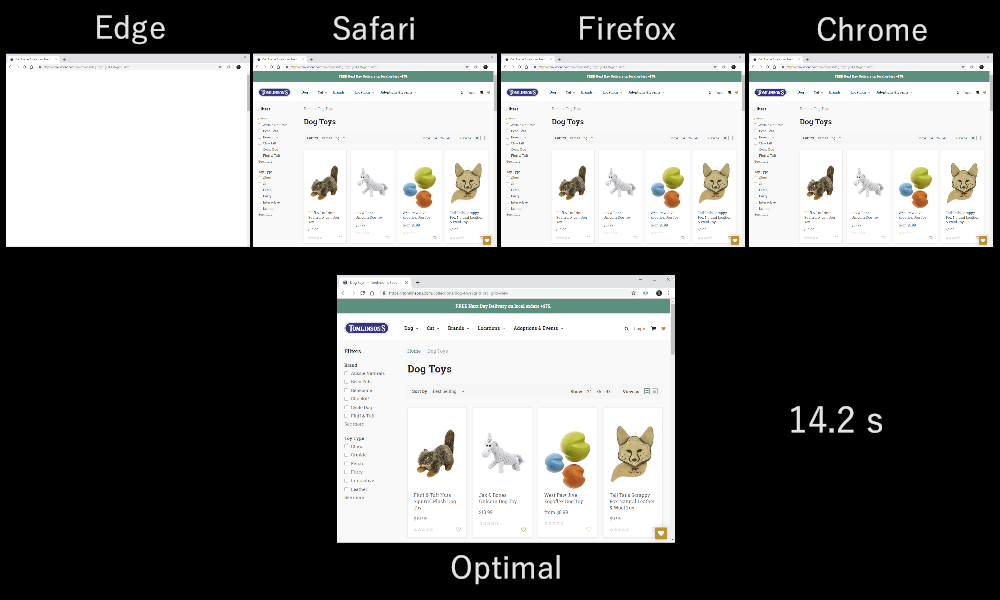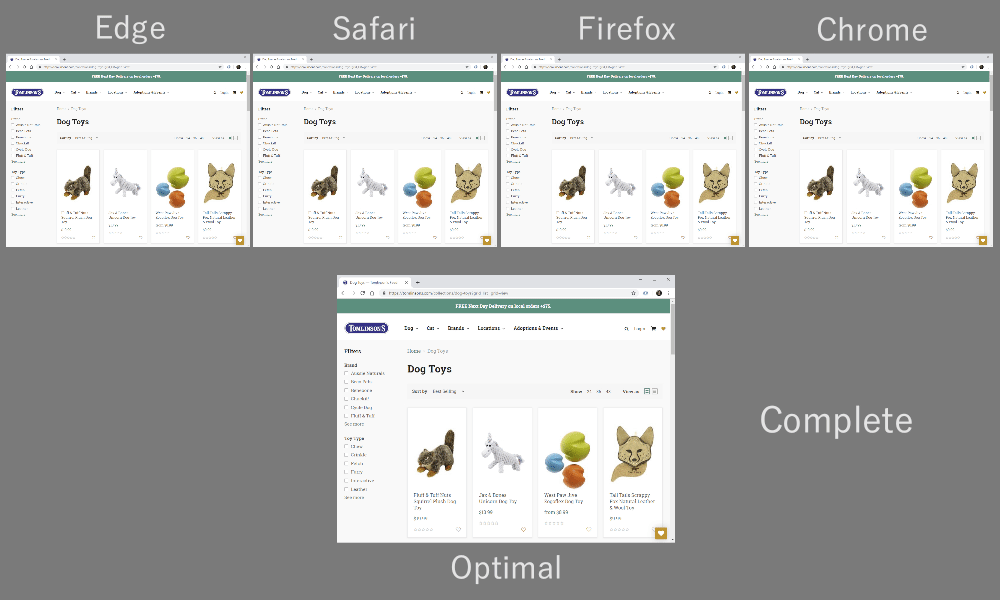
Luckily, we can explain the basics relatively easily. As you may know, some resources can be render blocking. This is the case for CSS files and for some JavaScript in the HTML head element. While these files are loading, the browser cannot paint the page (or, for example, execute new JavaScript).

What's more, CSS and JavaScript files need to be downloaded in full in order to be used (although they can often be incrementally parsed and compiled). As such, these resources need to be loaded as soon as possible, with the highest priority. Let's contemplate what would happen if A, B, and C were all render-blocking resources.
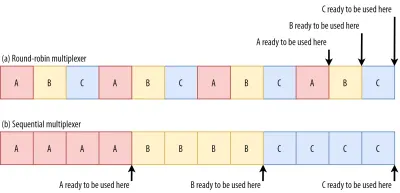
If we use a round-robin multiplexer (the top row in figure 6), we would actually delay each resource's total completion time, because they all need to share bandwidth with the others. Since we can only use them after they are fully loaded, this incurs a significant delay. However, if we multiplex them sequentially (the bottom row in figure 6), we would see that A and B complete much earlier (and can be used by the browser), while not actually delaying C's completion time.
However, that doesn't mean that sequential multiplexing is always the best, because some (mostly non-render-blocking) resources (such as HTML and progressive JPEGs) can actually be processed and used incrementally . In those (and some other) cases, it makes sense to use the first option (or at least something in between).
Still, for most web-page resources, it turns out that sequential multiplexing performs best . This is, for example, what Google Chrome is doing in the video above, while Internet Explorer is using the worst-case round-robin multiplexer.
Packet Loss Resilience
Now that we know that all streams aren't always active at the same time and that they can be multiplexed in different ways, we can consider what happens if we have packet loss. As explained in part 1, if one QUIC stream experiences packet loss, then other active streams can still be used (whereas, in TCP, all would be paused).
However, as we've just seen, having many concurrent active streams is typically not optimal for web performance, because it can delay some critical (render-blocking) resources, even without packet loss! We'd rather have just one or two active at the same time, using a sequential multiplexer. However, this reduces the impact of QUIC's HoL blocking removal.
Imagine, for example, that the sender could transmit 12 packets at a given time (see figure 7 below) — remember that this is limited by the congestion controller). If we fill all 12 of those packets with data for stream A (because it's high priority and render-blocking — think main.js ), then we would have only one active stream in that 12-packet window.
If one of those packets were to be lost, then QUIC would still end up fully HoL blocked because there would simply be no other streams it could process besides A : All of the data is for A , and so everything would still have to wait (we don't have B or C data to process), similar to TCP.

We see that we have a kind of contradiction: Sequential multiplexing ( AAAABBBBCCCC ) is typically better for web performance, but it doesn't allow us to take much advantage of QUIC's HoL blocking removal. Round-robin multiplexing ( ABCABCABCABC ) would be better against HoL blocking, but worse for web performance. As such, one best practice or optimization can end up undoing another .
그리고 그것은 더 나빠집니다. Up until now, we've sort of assumed that individual packets get lost one at a time. However, this isn't always true, because packet loss on the Internet is often “bursty”, meaning that multiple packets often get lost at the same time .
As discussed above, an important reason for packet loss is that a network is overloaded with too much data, having to drop excess packets. This is why the congestion controller starts sending slowly. However, it then keeps growing its send rate until… there is packet loss!
Put differently, the mechanism that's intended to prevent overloading the network actually overloads the network (albeit in a controlled fashion). On most networks, that occurs after quite a while, when the send rate has increased to hundreds of packets per round trip. When those reach the limit of the network, several of them are typically dropped together, leading to the bursty loss patterns.
Did You Know?
This is one of the reasons why we wanted to move to using a single (TCP) connection with HTTP/2, rather than the 6 to 30 connections with HTTP/1.1. Because each individual connection ramps up its send rate in pretty much the same way, HTTP/1.1 could get a good speed-up at the start, but the connections could actually start causing massive packet loss for each other as they caused the network to become overloaded.
At the time, Chromium developers speculated that this behaviour caused most of the packet loss seen on the Internet. This is also one of the reasons why BBR has become an often used congestion-control algorithm, because it uses fluctuations in observed RTTs, rather than packet loss, to assess available bandwidth.
Did You Know?
Other causes of packet loss can lead to fewer or individual packets becoming lost (or unusable), especially on wireless networks. There, however, the losses are often detected at lower protocol layers and solved between two local entities (say, the smartphone and the 4G cellular tower), rather than by retransmissions between the client and the server. These usually don't lead to real end-to-end packet loss, but rather show up as variations in packet latency (or “jitter”) and reordered packet arrivals.
So, let's say we are using a per-packet round-robin multiplexer ( ABCABCABCABCABCABCABCABC… ) to get the most out of HoL blocking removal, and we get a bursty loss of just 4 packets. We see that this will always impact all 3 streams (see figure 8, middle row)! In this case, QUIC's HoL blocking removal provides no benefits, because all streams have to wait for their own retransmissions .
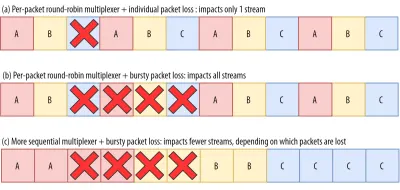
To lower the risk of multiple streams being affected by a lossy burst, we need to concatenate more data for each stream. For example, AABBCCAABBCCAABBCCAABBCC… is a small improvement, and AAAABBBBCCCCAAAABBBBCCCC… (see bottom row in figure 8 above) is even better. You can again see that a more sequential approach is better, even though that reduces the chances that we have multiple concurrent active streams.
In the end, predicting the actual impact of QUIC's HoL blocking removal is difficult, because it depends on the number of streams, the size and frequency of the loss bursts, how the stream data is actually used, etc. However, most results at this time indicate it will not help much for the use case of web-page loading, because there we typically want fewer concurrent streams.
If you want even more detail on this topic or just some concrete examples, please check out my in-depth article on HTTP HoL blocking.
Did You Know?
As with the previous sections, some advanced techniques can help us here. For example, modern congestion controllers use packet pacing. This means that they don't send, for example, 100 packets in a single burst, but rather spread them out over an entire RTT. This conceptually lowers the chances of overloading the network, and the QUIC Recovery RFC strongly recommends using it. Complementarily, some congestion-control algorithms such as BBR don't keep increasing their send rate until they cause packet loss, but rather back off before that (by looking at, for example, RTT fluctuations, because RTTs also rise when a network is becoming overloaded).
While these approaches lower the overall chances of packet loss, they don't necessarily lower its burstiness.
이 모든 것은 무엇을 의미합니까?
While QUIC's HoL blocking removal means, in theory, that it (and HTTP/3) should perform better on lossy networks, in practice this depends on a lot of factors. Because the use case of web-page loading typically favours a more sequential multiplexing set-up, and because packet loss is unpredictable, this feature would, again, likely affect mainly the slowest 1% of users . However, this is still a very active area of research, and only time will tell.
Still, there are situations that might see more improvements. These are mostly outside of the typical use case of the first full page load — for example, when resources are not render blocking, when they can be processed incrementally, when streams are completely independent, or when less data is sent at the same time.
Examples include repeat visits on well-cached pages and background downloads and API calls in single-page apps. For example, Facebook has seen some benefits from HoL blocking removal when using HTTP/3 to load data in its native app.
UDP 및 TLS 성능
QUIC 및 HTTP/3의 다섯 번째 성능 측면은 실제로 네트워크에서 패킷을 생성하고 전송할 수 있는 효율성과 성능에 관한 것입니다. 우리는 QUIC의 UDP 및 강력한 암호화 사용으로 인해 TCP보다 속도가 상당히 느려질 수 있음을 알 수 있습니다(그러나 상황이 개선되고 있음).
먼저, 우리는 이미 QUIC의 UDP 사용이 성능보다 유연성과 배포 가능성에 관한 것임을 논의했습니다. 이것은 최근까지 UDP를 통해 QUIC 패킷을 보내는 것이 일반적으로 TCP 패킷을 보내는 것보다 훨씬 느렸다는 사실에 의해 더욱 입증되었습니다. 이는 부분적으로 이러한 프로토콜이 일반적으로 구현되는 위치와 방법 때문입니다(아래 그림 9 참조).
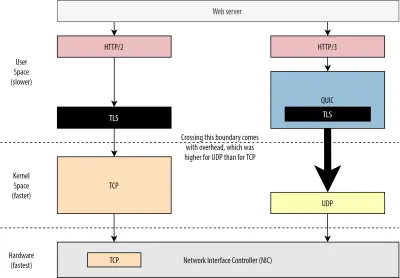
위에서 논의한 바와 같이 TCP와 UDP는 일반적으로 OS의 빠른 커널에서 직접 구현됩니다. 대조적으로 TLS 및 QUIC 구현은 대부분 느린 사용자 공간에 있습니다(QUIC에는 실제로 필요하지 않습니다. 훨씬 더 유연하기 때문에 대부분 수행됩니다). 이것은 QUIC를 이미 TCP보다 약간 느리게 만듭니다.
또한 사용자 공간 소프트웨어(예: 브라우저 및 웹 서버)에서 데이터를 보낼 때 이 데이터를 OS 커널에 전달 해야 합니다. 그러면 OS 커널은 TCP 또는 UDP를 사용하여 실제로 네트워크에 넣습니다. 이 데이터 전달은 API 호출당 일정량의 오버헤드를 포함하는 커널 API(시스템 호출)를 사용하여 수행됩니다. TCP의 경우 이러한 오버헤드는 UDP보다 훨씬 낮습니다.
이는 역사적으로 TCP가 UDP보다 훨씬 더 많이 사용되었기 때문입니다. 따라서 시간이 지남에 따라 패킷 송수신 오버헤드를 최소화하기 위해 TCP 구현 및 커널 API에 많은 최적화가 추가되었습니다. 많은 NIC(네트워크 인터페이스 컨트롤러)에는 TCP용 하드웨어 오프로드 기능이 내장되어 있습니다. 그러나 UDP는 더 제한된 사용이 추가 최적화에 대한 투자를 정당화하지 못했기 때문에 운이 좋지 않았습니다. 지난 5년 동안 이것은 운 좋게 바뀌었고 대부분의 OS는 UDP에 최적화된 옵션도 추가 했습니다.
둘째, QUIC는 각 패킷을 개별적으로 암호화 하기 때문에 많은 오버헤드가 있습니다. 이것은 패킷을 청크로 암호화할 수 있기 때문에 TCP를 통한 TLS를 사용하는 것보다 느립니다(한 번에 최대 약 16KB 또는 11개 패킷). 이는 더 효율적입니다. 이는 대량 암호화가 자체 형태의 HoL 차단으로 이어질 수 있기 때문에 QUIC에서 의도적으로 절충한 것이었습니다.
UDP(따라서 QUIC)를 더 빠르게 만들기 위해 추가 API를 추가할 수 있는 첫 번째 요점과 달리 여기에서 QUIC는 항상 TCP + TLS에 고유한 단점이 있습니다. 그러나 이것은 예를 들어 최적화된 암호화 라이브러리와 QUIC 패킷 헤더를 대량으로 암호화할 수 있는 영리한 방법을 사용하여 실제로 상당히 관리할 수 있습니다.
결과적으로 Google의 초기 QUIC 버전은 여전히 TCP + TLS보다 2배 느리지만 그 이후로 상황이 확실히 개선되었습니다. 예를 들어, 최근 테스트에서 Microsoft의 크게 최적화된 QUIC 스택은 동일한 시스템에서 TCP + TLS의 경우 11.85Gbps와 비교하여 7.85Gbps를 얻을 수 있었습니다(여기서 QUIC는 TCP + TLS보다 약 66% 빠름).
이것은 UDP를 더 빠르게 만든 최근 Windows 업데이트와 관련이 있습니다(전체 비교를 위해 해당 시스템의 UDP 처리량은 19.5Gbps였습니다). Google QUIC 스택의 가장 최적화된 버전은 현재 TCP + TLS보다 약 20% 느립니다. Fastly의 초기 테스트에서는 덜 발전된 시스템과 몇 가지 트릭으로 동일한 성능(약 450Mbps)을 주장하며 사용 사례에 따라 QUIC가 TCP와 확실히 경쟁할 수 있음을 보여줍니다.
그러나 QUIC가 TCP + TLS보다 두 배 느리더라도 그렇게 나쁘지는 않습니다. 첫째, QUIC 및 TCP + TLS 처리는 일반적으로 서버에서 발생하는 가장 무거운 작업이 아닙니다. 다른 논리(예: HTTP, 캐싱, 프록시 등)도 실행해야 하기 때문입니다. 따라서 실제로 QUIC를 실행하는 데 두 배의 서버가 필요하지 않습니다 (하지만 대기업 중 어느 곳도 이에 대한 데이터를 공개하지 않았기 때문에 실제 데이터 센터에 얼마나 많은 영향을 미칠지는 불분명합니다).
둘째, 미래에 QUIC 구현을 최적화할 수 있는 기회가 여전히 많이 있습니다. 예를 들어, 시간이 지남에 따라 일부 QUIC 구현은 (부분적으로) OS 커널(TCP와 매우 유사)로 이동하거나 이를 우회합니다(일부는 MsQuic 및 Quant와 같이 이미 수행). 또한 QUIC 전용 하드웨어를 사용할 수 있을 것으로 예상할 수 있습니다.
그래도 TCP + TLS가 선호되는 옵션으로 남아 있는 몇 가지 사용 사례가 있을 수 있습니다. 예를 들어 Netflix는 TCP + TLS를 통해 비디오를 스트리밍하기 위해 사용자 지정 FreeBSD 설정에 막대한 투자를 했기 때문에 조만간 QUIC로 이전하지 않을 것이라고 밝혔습니다.
마찬가지로 Facebook은 QUIC가 주로 최종 사용자와 CDN의 에지 사이에서 사용될 것이라고 밝혔지만 더 큰 오버헤드로 인해 데이터 센터 간이나 에지 노드와 원본 서버 사이에서는 사용하지 않을 것입니다. 일반적으로 고대역폭 시나리오는 특히 향후 몇 년 동안 TCP + TLS를 계속 선호할 것입니다.
알고 계셨나요?
네트워크 스택 최적화는 위의 내용이 단지 표면을 긁는 데 불과한(그리고 많은 뉘앙스를 놓치는) 깊고 기술적인 토끼 구멍입니다. 당신이 충분히 용감하거나GRO/GSO,SO_TXTIME, 커널 바이패스,sendmmsg()및recvmmsg()()와 같은 용어가 무엇을 의미하는지 알고 싶다면 Cloudflare 및 Fastly에서 QUIC 최적화에 대한 몇 가지 훌륭한 기사도 추천할 수 있습니다. Microsoft의 광범위한 코드 설명 및 Cisco의 심층 강연으로 제공됩니다. 마지막으로 Google 엔지니어는 시간이 지남에 따라 QUIC 구현을 최적화하는 방법에 대해 매우 흥미로운 기조 연설을 했습니다.
이 모든 것은 무엇을 의미합니까?
QUIC의 UDP 및 TLS 프로토콜 사용은 역사적으로 TCP + TLS보다 훨씬 느립니다. 그러나 시간이 지남에 따라 격차를 다소 좁힌 몇 가지 개선 사항이 만들어졌으며 계속 구현될 것입니다. 웹 페이지 로딩의 일반적인 사용 사례에서는 이러한 불일치를 눈치채지 못할 수도 있지만 대규모 서버 팜을 유지 관리하는 경우 골치 아픈 문제가 될 수 있습니다.
HTTP/3 기능
지금까지 우리는 주로 QUIC 대 TCP의 새로운 성능 기능에 대해 이야기했습니다. 그러나 HTTP/3 대 HTTP/2는 어떻습니까? 1부에서 논의한 바와 같이 HTTP/3은 실제로 QUIC를 통한 HTTP/2 이므로 새 버전에는 실제적이고 큰 새 기능이 도입되지 않았습니다. 이는 HTTP/1.1에서 HTTP/2로의 이동과 다릅니다. HTTP/2는 훨씬 더 크고 헤더 압축, 스트림 우선 순위 지정 및 서버 푸시와 같은 새로운 기능을 도입했습니다. 이러한 기능은 모두 여전히 HTTP/3에 있지만 내부적으로 구현되는 방식에는 몇 가지 중요한 차이점이 있습니다.
이것은 주로 QUIC의 HoL 차단 제거가 작동하는 방식 때문입니다. 논의한 바와 같이 스트림 B의 손실은 더 이상 스트림 A와 C가 TCP를 통해 했던 것처럼 B의 재전송을 기다려야 함을 의미하지 않습니다. 따라서 A, B, C가 각각 QUIC 패킷을 순서대로 보낸다면 데이터는 A, C, B로 브라우저에 전달되고 처리될 수 있습니다! 다르게 말하면 TCP와 달리 QUIC는 더 이상 다른 스트림에서 완전히 정렬되지 않습니다 !
이것은 데이터 청크가 산재된 특수 제어 메시지를 사용하는 많은 기능의 설계에서 TCP의 엄격한 순서에 실제로 의존하는 HTTP/2의 문제입니다. QUIC에서 이러한 제어 메시지는 어떤 순서로든 도착(및 적용)될 수 있으며 잠재적으로 기능이 의도한 것과 반대 되는 기능을 수행하도록 만들 수도 있습니다! 기술적인 세부 사항은 이 기사에 필요하지 않지만 이 문서의 전반부는 이것이 얼마나 어리석게 복잡할 수 있는지에 대한 아이디어를 제공할 것입니다.
따라서 HTTP/3에서는 기능의 내부 메커니즘과 구현이 변경되어야 했습니다. 구체적인 예는 HTTP 헤더 압축 이며, 이는 반복되는 큰 HTTP 헤더(예: 쿠키 및 사용자 에이전트 문자열)의 오버헤드를 낮춥니다. HTTP/2에서는 HPACK 설정을 사용하여 이 작업을 수행했지만 HTTP/3에서는 더 복잡한 QPACK으로 재작업했습니다. 두 시스템 모두 동일한 기능(예: 헤더 압축)을 제공하지만 방식은 상당히 다릅니다. 이 주제에 대한 몇 가지 우수한 심층 기술 토론 및 다이어그램은 Litespeed 블로그에서 찾을 수 있습니다.
스트림 멀티플렉싱 로직을 구동하고 위에서 간략하게 논의한 우선 순위 지정 기능에 대해서도 유사한 것이 사실입니다. HTTP/2에서 이것은 모든 페이지 리소스와 그 상호 관계를 명시적으로 모델링하려고 시도하는 복잡한 "종속성 트리" 설정을 사용하여 구현되었습니다(자세한 내용은 "HTTP 리소스 우선 순위 지정에 대한 궁극적인 가이드" 참조). QUIC에서 직접 이 시스템을 사용하면 트리에 각 리소스를 추가하는 것이 별도의 제어 메시지가 되기 때문에 잠재적으로 매우 잘못된 트리 레이아웃이 발생할 수 있습니다.
또한 이 접근 방식은 불필요하게 복잡하여 많은 서버에서 많은 구현 버그와 비효율성과 낮은 성능으로 이어졌습니다. 두 가지 문제로 인해 우선 순위 지정 시스템이 훨씬 더 간단한 방식으로 HTTP/3용으로 재설계되었습니다. 이 보다 간단한 설정은 일부 고급 시나리오를 적용하기 어렵거나 불가능하게 만들지만(예: 단일 연결에서 여러 클라이언트의 트래픽 프록시), 여전히 웹 페이지 로딩 최적화를 위한 광범위한 옵션을 가능하게 합니다.
다시 말하지만 두 가지 접근 방식이 동일한 기본 기능(스트림 다중화 안내)을 제공하지만 HTTP/3의 설정이 더 쉬워 구현 버그가 줄어들기를 바랍니다.
마지막으로 서버 푸시 가 있습니다. 이 기능을 사용하면 서버가 먼저 명시적인 요청을 기다리지 않고 HTTP 응답을 보낼 수 있습니다. 이론적으로 이것은 탁월한 성능 향상을 제공할 수 있습니다. 그러나 실제로는 올바르게 사용하기 어렵고 일관되지 않게 구현되어 있는 것으로 나타났습니다. 결과적으로 Google 크롬에서 제거될 수도 있습니다.
이 모든 것에도 불구하고, 이것은 여전히 HTTP/3의 기능으로 정의되어 있습니다(비록 소수의 구현에서 지원하지만). 내부 작동은 이전 두 기능만큼 많이 변경되지 않았지만 QUIC의 비결정적 순서를 우회하도록 조정되었습니다. 그러나 슬프게도 이것은 오랜 문제를 해결하는 데 거의 도움이 되지 않을 것입니다.
이 모든 것은 무엇을 의미합니까?
이전에 말했듯이 HTTP/3의 잠재력 대부분은 HTTP/3 자체가 아니라 기본 QUIC에서 나옵니다. 프로토콜의 내부 구현은 HTTP/2와 매우 다르지만 높은 수준의 성능 기능과 사용할 수 있고 사용해야 하는 방법은 동일하게 유지되었습니다.
앞으로 주목해야 할 발전 사항
이 시리즈에서 저는 더 빠른 진화와 더 높은 유연성이 QUIC(그리고 확장하여 HTTP/3)의 핵심 측면임을 정기적으로 강조했습니다. 따라서 사람들이 이미 프로토콜에 대한 새로운 확장 및 응용 프로그램에 대해 작업하고 있다는 것은 놀라운 일이 아닙니다. 아래 목록은 아마도 어딘가에서 만날 수 있는 주요 항목입니다.
순방향 오류 수정
이 기술의 목적은 패킷 손실에 대한 QUIC의 복원력을 개선 하는 것입니다. 데이터의 중복 복사본을 전송하여 이 작업을 수행합니다(크기가 크지 않도록 영리하게 인코딩 및 압축됨). 그런 다음 패킷이 손실되었지만 중복 데이터가 도착하면 더 이상 재전송이 필요하지 않습니다.
이것은 원래 Google QUIC의 일부였습니다(그리고 사람들이 QUIC이 패킷 손실에 좋다고 말하는 이유 중 하나). 그러나 성능 영향이 아직 입증되지 않았기 때문에 표준화된 QUIC 버전 1에는 포함되지 않았습니다. 그러나 연구원들은 현재 이를 사용하여 활발한 실험을 수행하고 있으며 PQUIC-FEC 다운로드 실험 앱을 사용하여 연구원을 도울 수 있습니다.다중 경로 QUIC
우리는 이전에 연결 마이그레이션과 Wi-Fi에서 셀룰러로 이동할 때 어떻게 도움이 되는지에 대해 논의했습니다. 그러나 그것은 우리가 Wi-Fi와 셀룰러 를 동시에 사용할 수도 있음을 의미하지 않습니까? 두 네트워크를 동시에 사용하면 사용 가능한 대역폭과 견고성이 향상됩니다! 이것이 다중 경로의 기본 개념입니다.
이것은 다시 Google에서 실험했지만 고유한 복잡성으로 인해 QUIC 버전 1에 포함되지 않은 것입니다. 그러나 연구원들은 이후 높은 잠재력을 보여 QUIC 버전 2로 만들 수 있습니다. TCP 다중 경로도 존재하지만 실제로 사용할 수 있게 되기까지 거의 10년이 걸렸습니다.QUIC 및 HTTP/3를 통한 신뢰할 수 없는 데이터
지금까지 살펴본 것처럼 QUIC는 완전히 신뢰할 수 있는 프로토콜입니다. 그러나 신뢰할 수 없는 UDP를 통해 실행되기 때문에 QUIC에 기능을 추가하여 신뢰할 수 없는 데이터도 보낼 수 있습니다. 이것은 제안된 데이터그램 확장에 설명되어 있습니다. 물론 이것을 사용하여 웹 페이지 리소스를 보내고 싶지는 않겠지만 게임 및 라이브 비디오 스트리밍과 같은 작업에는 유용할 수 있습니다. 이러한 방식으로 사용자는 QUIC 수준 암호화 및 (선택 사항) 혼잡 제어를 통해 UDP의 모든 이점을 얻을 수 있습니다.웹전송
브라우저는 주로 보안 문제로 인해 TCP 또는 UDP를 JavaScript에 직접 노출하지 않습니다. 대신 Fetch와 다소 유연한 WebSocket 및 WebRTC 프로토콜과 같은 HTTP 수준 API에 의존해야 합니다. 이 옵션 시리즈의 최신 옵션은 WebTransport라고 하며, 이는 주로 HTTP/3(및 확장하여 QUIC)을 보다 낮은 수준의 방식으로 사용할 수 있도록 합니다(필요한 경우 TCP 및 HTTP/2로 폴백할 수도 있지만 ).
결정적으로, HTTP/3를 통해 신뢰할 수 없는 데이터를 사용하는 기능이 포함될 것이며(이전 요점 참조) 게임과 같은 것을 브라우저에서 구현하기가 훨씬 더 쉬워질 것입니다. 물론 일반(JSON) API 호출의 경우 가능한 경우 자동으로 HTTP/3도 사용하는 Fetch를 계속 사용합니다. WebTransport는 현재 많은 논의가 진행 중이므로 최종적으로 어떤 모습일지 아직 명확하지 않습니다. 브라우저 중 Chromium만 현재 공개 개념 증명 구현을 작업 중입니다.DASH 및 HLS 비디오 스트리밍
라이브가 아닌 비디오(YouTube 및 Netflix)의 경우 브라우저는 일반적으로 DASH(Dynamic Adaptive Streaming over HTTP) 또는 HLS(HTTP Live Streaming) 프로토콜을 사용합니다. 둘 다 기본적으로 비디오를 더 작은 청크(2~10초)와 다른 품질 수준(720p, 1080p, 4K 등)으로 인코딩한다는 것을 의미합니다.
런타임에 브라우저는 네트워크가 처리할 수 있는 최고 품질(또는 주어진 사용 사례에 가장 최적화된 품질)을 추정하고 HTTP를 통해 서버에서 관련 파일을 요청합니다. 브라우저는 TCP 스택에 직접 액세스할 수 없기 때문에(일반적으로 커널에서 구현됨) 때때로 이러한 추정에서 약간의 실수를 하거나 변화하는 네트워크 조건에 반응하는 데 시간이 걸립니다(비디오 정지로 이어짐) .
QUIC는 브라우저의 일부로 구현되기 때문에 스트리밍 추정자에게 낮은 수준의 프로토콜 정보(예: 손실률, 대역폭 추정치 등)에 대한 액세스 권한을 부여하여 이를 상당히 개선할 수 있습니다. 다른 연구원들은 비디오 스트리밍을 위해 신뢰할 수 있는 데이터와 신뢰할 수 없는 데이터를 혼합하는 실험을 하고 있으며 몇 가지 유망한 결과를 얻었습니다.HTTP/3 이외의 프로토콜
QUIC가 범용 전송 프로토콜이기 때문에 현재 TCP를 통해 실행되는 많은 애플리케이션 계층 프로토콜이 QUIC 위에서도 실행될 것으로 기대할 수 있습니다. 진행 중인 일부 작업에는 QUIC를 통한 DNS, QUIC를 통한 SMB, 심지어 QUIC를 통한 SSH가 포함됩니다. 이러한 프로토콜은 일반적으로 HTTP 및 웹 페이지 로딩과 요구 사항이 매우 다르기 때문에 우리가 논의한 QUIC의 성능 개선 사항은 이러한 프로토콜에 대해 훨씬 더 잘 작동할 수 있습니다.
이 모든 것은 무엇을 의미합니까?
QUIC 버전 1은 시작에 불과합니다 . Google이 이전에 실험한 많은 고급 성능 지향 기능은 이 첫 번째 반복에 포함되지 않았습니다. 그러나 목표는 프로토콜을 빠르게 발전시켜 새로운 확장과 기능을 자주 도입하는 것입니다. 따라서 시간이 지남에 따라 QUIC(및 HTTP/3)는 TCP(및 HTTP/2)보다 확실히 더 빠르고 유연해져야 합니다.
결론
이 시리즈의 두 번째 파트에서는 HTTP/3, 특히 QUIC의 다양한 성능 기능과 측면에 대해 논의했습니다. 우리는 이러한 기능의 대부분이 매우 영향력 있는 것처럼 보이지만 실제로는 우리가 고려하고 있는 웹 페이지 로딩의 사용 사례에서 일반 사용자에게는 그다지 많은 기능을 하지 못할 수도 있음을 확인했습니다.
예를 들어, QUIC의 UDP 사용이 갑자기 TCP보다 더 많은 대역폭을 사용할 수 있다는 것을 의미하지도 않고 리소스를 더 빨리 다운로드할 수도 있다는 것을 의미하지도 않습니다. 자주 찬사를 받는 0-RTT 기능은 실제로 한 번의 왕복을 절약하는 미세 최적화이며, 이 경우 약 5KB(최악의 경우)를 보낼 수 있습니다.
대량 패킷 손실 이 있거나 렌더링 차단 리소스를 로드하는 경우 HoL 차단 제거가 제대로 작동하지 않습니다. 연결 마이그레이션은 상황에 따라 다르며 HTTP/3에는 HTTP/2보다 빠르게 만들 수 있는 주요 새 기능이 없습니다.
따라서 HTTP/3 및 QUIC를 건너뛰는 것이 좋습니다. 왜 귀찮게, 그렇지? 그러나 나는 그런 일을 절대 하지 않을 것입니다! 이러한 새로운 프로토콜은 빠른(도시) 네트워크의 사용자에게 많은 도움이 되지 않을 수 있지만 새로운 기능은 확실히 모바일이 많은 사용자와 느린 네트워크의 사용자에게 큰 영향을 미칠 가능성이 있습니다.
우리가 일반적으로 빠른 장치와 고속 셀룰러 네트워크에 액세스할 수 있는 벨기에와 같은 서구 시장에서도 이러한 상황은 제품에 따라 사용자 기반의 1%에서 10%까지 영향을 미칠 수 있습니다. 예를 들어 기차에 탄 사람이 웹사이트에서 중요한 정보를 찾기 위해 필사적으로 노력하지만 정보가 로드될 때까지 45초를 기다려야 하는 경우를 들 수 있습니다. 나는 누군가가 QUIC를 배치하여 그 상황에서 벗어나게 해주기를 바랐던 그런 상황에 있었다는 것을 확실히 알고 있습니다.
그러나 상황이 훨씬 더 나쁜 다른 국가와 지역이 있습니다. 그곳에서 평균적인 사용자는 벨기에에서 가장 느린 10%처럼 보일 수 있고 가장 느린 1%는 로드된 페이지를 전혀 보지 못할 수도 있습니다. 세계의 많은 지역에서 웹 성능은 접근성과 포괄성의 문제입니다.
이것이 우리가 자체 하드웨어에서 페이지를 테스트해서는 안 되는 이유(하지만 Webpagetest와 같은 서비스도 사용)와 QUIC 및 HTTP/3을 반드시 배포 해야 하는 이유입니다. 특히 사용자가 자주 이동하거나 고속 셀룰러 네트워크에 액세스할 가능성이 낮은 경우, 케이블 연결된 MacBook Pro에서 많은 것을 눈치채지 못하더라도 이러한 새로운 프로토콜은 세상을 변화시킬 수 있습니다. 자세한 내용은 해당 문제에 대한 Fastly의 게시물을 적극 권장합니다.
그것이 당신을 완전히 확신시키지 못한다면 QUIC와 HTTP/3가 계속해서 발전하고 앞으로 더 빨라질 것이라는 점을 고려하십시오. 프로토콜에 대한 약간의 초기 경험을 얻으면 결과적으로 보상을 받을 수 있으므로 가능한 한 빨리 새로운 기능의 이점을 얻을 수 있습니다. 또한 QUIC는 백그라운드에서 보안 및 개인 정보 보호 모범 사례를 시행하여 모든 사용자에게 이익이 됩니다.
마침내 확신? 그런 다음 시리즈의 3부를 계속하여 실제로 새 프로토콜을 사용하는 방법에 대해 읽으십시오.
- 1부: HTTP/3의 역사와 핵심 개념
이 기사는 HTTP/3 및 일반적인 프로토콜을 처음 접하는 사람들을 대상으로 하며 주로 기본 사항에 대해 설명합니다. - 2부: HTTP/3 성능 기능
이것은 더 깊이 있고 기술적인 것입니다. 기본 사항을 이미 알고 있는 사람들은 여기에서 시작할 수 있습니다. - 3부: 실용적인 HTTP/3 배포 옵션
이 시리즈의 세 번째 기사에서는 HTTP/3을 직접 배포하고 테스트하는 것과 관련된 문제에 대해 설명합니다. 웹 페이지와 리소스도 변경해야 하는 방법과 변경 여부에 대해 자세히 설명합니다.