
상위 10개의 Hadoop 명령 [사용법 포함]
게시 됨: 2021-01-29방대한 데이터 덩어리가 있는 이 시대에는 이를 처리하는 것이 필수적입니다. 고객이 증가하는 조직에서 생성되는 데이터는 기존 데이터 관리 도구가 저장할 수 있는 것보다 훨씬 큽니다. 하나의 대형 컴퓨터나 기존 데이터 관리 도구를 사용하지 않고 기가바이트에서 페타바이트에 이르는 더 큰 데이터 집합을 관리해야 하는 문제가 발생합니다.
여기서 Apache Hadoop 프레임워크가 주목을 받습니다. Hadoop 명령 구현에 대해 알아보기 전에 Hadoop 프레임워크와 그 중요성에 대해 간략히 알아보겠습니다.
목차
하둡이란?
Hadoop은 매일 큰 GB(기가바이트)의 데이터를 저장하는 것부터 데이터에 대한 컴퓨팅 작업에 이르기까지 다양한 문제를 해결하기 위해 주요 비즈니스 조직에서 일반적으로 사용됩니다.
전통적으로 데이터를 저장하고 애플리케이션을 처리하는 데 사용되는 오픈 소스 소프트웨어 프레임워크로 정의된 Hadoop은 대다수의 기존 데이터 관리 도구와 상당히 차별화됩니다. 프레임워크에 몇 개의 노드를 추가하여 컴퓨팅 성능을 향상하고 데이터 저장 제한을 확장하여 확장성이 뛰어납니다. 또한 데이터 및 응용 프로그램 프로세스는 다양한 하드웨어 오류로부터 보호됩니다.
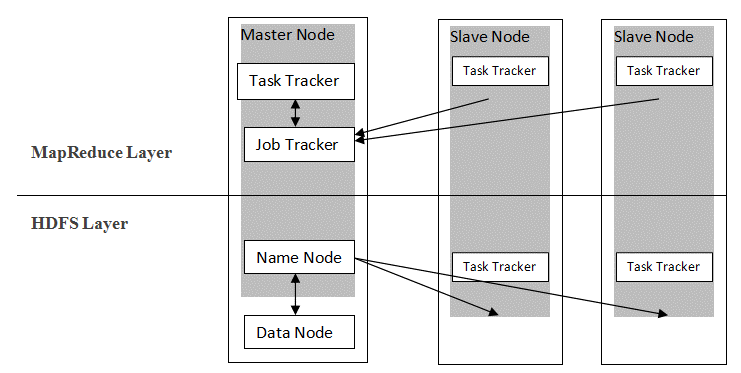
Hadoop은 마스터-슬레이브 아키텍처를 따라 MapReduce 및 HDFS를 사용하여 데이터를 배포하고 저장합니다. 아래 그림과 같이 아키텍처는 Name, Data, Master 및 Slave라는 4개의 기본 노드를 사용하여 데이터 관리 작업을 수행하도록 정의된 방식으로 조정됩니다. Hadoop의 핵심 구성 요소는 프레임워크 위에 직접 구축됩니다. 다른 구성 요소는 세그먼트와 직접 통합됩니다.
 원천
원천

하둡 명령
Hadoop 프레임워크의 주요 기능은 일관된 특성을 나타내며, Hadoop 명령을 학습하여 빅 데이터를 관리할 때 보다 사용자 친화적입니다. 다음은 관리 및 HDFS 클러스터 파일 처리와 같은 다양한 작업을 수행할 수 있는 편리한 Hadoop 명령입니다. 이 명령 목록은 특정 프로세스 결과를 달성하는 데 자주 필요합니다.
1. 하둡 터치즈
hadoop fs -touchz /디렉토리/파일 이름
이 명령을 사용하면 HDFS 클러스터에 새 파일을 만들 수 있습니다. 명령어에서 "디렉토리"는 사용자가 새로운 파일을 생성하고자 하는 디렉토리명을 의미하며, "파일명"은 명령어 완료 시 생성될 새로운 파일의 이름을 의미한다.
2. 하둡 테스트 명령어
hadoop fs -test -[defsz] <경로>
이 특정 명령은 HDFS 클러스터에서 파일의 존재를 테스트하는 목적을 수행합니다. 명령에서 "[defsz]"의 문자는 필요에 따라 수정해야 합니다. 다음은 이 캐릭터에 대한 간략한 설명입니다.
- d -> 디렉토리인지 아닌지 확인
- e -> 경로인지 아닌지 확인
- f -> 파일인지 확인
- s -> 빈 경로인지 확인
- r -> 경로 존재 여부 및 읽기 권한 확인
- w -> 경로 존재 여부 및 쓰기 권한 확인
- z -> 파일 크기 확인
3. 하둡 텍스트 명령
하둡 fs -텍스트 <src>
text 명령은 할당된 zip 파일을 텍스트 형식으로 표시하는 데 특히 유용합니다. 소스 파일을 처리하고 콘텐츠를 일반 디코딩된 텍스트 형식으로 제공하여 작동합니다.

4. 하둡 찾기 명령어
hadoop fs -find <경로> ... <표현식>
이 명령은 일반적으로 HDFS 클러스터에서 파일을 검색할 목적으로 사용됩니다. 클러스터의 모든 파일과 함께 명령에서 주어진 표현식을 스캔하고 정의된 표현식과 일치하는 파일을 표시합니다.
읽기: 최고의 Hadoop 도구
5. 하둡 Getmerge 명령
hadoop fs -getmerge <src> <localdest>
Getmerge 명령을 사용하면 HDFS 파일 시스템 클러스터의 지정된 디렉토리에 있는 하나 이상의 파일을 병합할 수 있습니다. 로컬 파일 시스템에 있는 하나의 단일 파일로 파일을 누적합니다. "src" 및 "localdest"는 소스-대상 및 로컬 대상의 의미를 나타냅니다.
6. 하둡 카운트 명령
hadoop fs -count [옵션] <경로>
이름에서 알 수 있듯이 Hadoop count 명령은 지정된 디렉토리의 파일 수와 바이트 수를 계산합니다. 요구 사항에 따라 출력을 수정하는 다양한 옵션이 있습니다. 다음과 같습니다.
- q -> 할당량은 전체 이름 수와 공간 사용량에 대한 제한을 보여줍니다.
- u -> 할당량 및 사용량만 표시
- h -> 파일 크기 제공
- v -> 헤더 표시
7. Hadoop AppendToFile 명령
hadoop fs -appendToFile <localsrc> <대상>
이를 통해 사용자는 HDFS 파일 시스템 클러스터의 지정된 대상 파일에 있는 단일 파일에 하나 이상의 파일 내용을 추가할 수 있습니다. 이 명령을 실행하면 지정된 소스 파일이 명령의 지정된 파일 이름에 따라 대상 소스에 추가됩니다.
8. 하둡 ls 명령
하둡 fs -ls /경로
Hadoop의 ls 명령은 지정된 디렉토리, 즉 경로에 있는 파일/내용의 목록을 보여줍니다. /path 앞에 "R"을 추가하면 지정된 디렉토리에 지정된 각 파일의 이름, 크기, 소유자 등과 같은 내용의 세부 정보가 출력에 표시됩니다.
9. 하둡 mkdir 명령
하둡 fs -mkdir /경로/디렉토리 이름
이 명령의 고유한 기능은 디렉토리가 존재하지 않는 경우 HDFS 파일 시스템 클러스터에 디렉토리를 생성하는 것입니다. 게다가 지정된 디렉토리가 있는 경우 출력 메시지에 디렉토리의 존재를 나타내는 오류가 표시됩니다.
10. 하둡 chmod 명령
hadoop fs -chmod [-R] <모드> <경로>
이 명령은 특정 파일에 대한 접근 권한을 변경해야 할 때 사용합니다. chmod 명령을 내리면 지정된 파일의 권한이 변경됩니다. 그러나 파일 소유자가 이 명령을 실행할 때 권한이 수정된다는 점을 기억하는 것이 중요합니다.
읽어보기: Impala Hadoop 자습서
결론
이 기사는 오늘날 세계의 주요 조직이 직면한 데이터 스토리지의 중요한 문제를 시작으로 Hadoop을 도입하여 제한된 데이터 스토리지에 대한 솔루션과 Hadoop 명령을 사용하여 데이터 관리 작업을 수행하는 데 미치는 영향에 대해 논의했습니다. Hadoop의 초보자를 위해 프레임워크의 개요가 구성 요소 및 아키텍처와 함께 설명됩니다.

이 기사를 읽고 나면 Hadoop 프레임워크 및 적용된 명령 측면에 대한 지식에 대해 쉽게 확신할 수 있습니다. upGrad의 빅 데이터 독점 PG 인증: upGrad는 IIIT-Bangalore로 빅 데이터를 구성, 분석 및 해석할 빅 데이터 PG 인증을 위한 산업별 7.5개월 프로그램을 제공합니다.
일하는 전문가를 위해 세심하게 설계된 이 과정은 학생들이 실용적인 지식을 습득하고 빅 데이터 역할에 대한 진입을 촉진하는 데 도움이 될 것입니다.
프로그램 하이라이트:
- 관련 언어 및 도구 학습
- 분산 프로그래밍, 빅 데이터 플랫폼, 데이터베이스, 알고리즘 및 웹 마이닝의 고급 개념 학습
- IIT 방갈로르의 공인 인증서
- 최고의 다국적 기업에 흡수되기 위한 배치 지원
- 진행 상황을 추적하고 모든 지점에서 지원하는 1:1 멘토링
- 라이브 프로젝트 및 과제 작업
지원자격 : 수학/소프트웨어공학/통계/분석 배경지식
upGrad에서 다른 소프트웨어 엔지니어링 과정을 확인하십시오.