
GraphQL 입문서: API 디자인의 진화(2부)
게시 됨: 2022-03-101부에서는 지난 수십 년 동안 API가 어떻게 발전해 왔으며 각각이 다음 단계로 넘어가는 과정을 살펴보았습니다. 또한 모바일 클라이언트 개발에 REST를 사용할 때의 몇 가지 특정 단점에 대해서도 이야기했습니다. 이 기사에서는 GraphQL에 특히 중점을 두고 모바일 클라이언트 API 디자인이 어디로 향하고 있는지 살펴보고 싶습니다.
물론 HAL, Swagger/OpenAPI, OData JSON API 및 기타 수십 개의 소규모 또는 내부 프로젝트에서 REST의 단점을 해결하기 위해 수년 동안 노력한 많은 사람, 회사 및 프로젝트가 있습니다. 사양이 없는 REST의 세계. 세상을 있는 그대로 받아들이고 점진적인 개선을 제안하거나 REST를 필요한 것으로 만들기 위해 충분히 이질적인 조각을 조합하려고 하기보다는 사고 실험을 해보고 싶습니다. 과거에 효과가 있었던 기술과 그렇지 않은 기술에 대한 이해를 감안할 때, 저는 오늘날의 제약 조건과 훨씬 더 표현력이 풍부한 언어를 사용하여 원하는 API를 시도하고 스케치하고 싶습니다. 구현을 앞으로 하기 보다는 개발자 경험을 뒤로 하여 작업해 보겠습니다(저는 SQL을 보고 있습니다).
최소 HTTP 트래픽
모든 (HTTP/1) 네트워크 요청의 비용은 대기 시간에서 배터리 수명에 이르는 몇 가지 측면에서 높다는 것을 알고 있습니다. 이상적으로는 새로운 API의 클라이언트가 가능한 한 적은 왕복으로 필요한 모든 데이터를 요청할 수 있는 방법이 필요합니다.
최소 페이로드
우리는 또한 평균적인 클라이언트가 대역폭, CPU, 메모리 면에서 리소스가 제한되어 있다는 것을 알고 있으므로 클라이언트가 필요로 하는 정보만 보내는 것이 목표여야 합니다. 이렇게 하려면 클라이언트가 특정 데이터 조각을 요청할 수 있는 방법이 필요할 것입니다.
사람이 읽을 수 있는
우리는 API가 상호 작용하기 쉽지 않다는 SOAP 시대를 배웠고 사람들은 API에 대해 언급하면 얼굴을 찡그릴 것입니다. 엔지니어링 팀은 curl , wget 및 Charles 및 브라우저의 네트워크 탭과 같이 우리가 수년 동안 사용했던 것과 동일한 도구를 사용하기를 원합니다.
풍부한 도구
XML-RPC와 SOAP에서 배운 또 다른 사실은 특히 클라이언트/서버 계약과 유형 시스템이 놀라울 정도로 유용하다는 것입니다. 가능하다면 새로운 API는 JSON 또는 YAML과 같은 형식의 가벼움과 보다 구조화되고 유형이 안전한 계약의 내성 기능을 갖출 것입니다.
국지적 추론의 보존
수년에 걸쳐 우리는 대규모 코드베이스를 구성하는 방법에 대한 몇 가지 지침 원칙에 동의하게 되었습니다. 주요 원칙은 "관심 분리"입니다. 불행히도 대부분의 프로젝트에서 이것은 중앙 집중식 데이터 액세스 계층의 형태로 분해되는 경향이 있습니다. 가능하다면 애플리케이션의 다른 부분에 다른 기능과 함께 자체 데이터 요구 사항을 관리할 수 있는 옵션이 있어야 합니다.
우리는 클라이언트 중심 API를 설계하고 있으므로 이와 같은 API에서 데이터를 가져오는 것이 어떤 모습일지부터 시작하겠습니다. 최소한의 왕복 이동이 필요하고 원하지 않는 필드를 필터링할 수 있어야 한다는 것을 알고 있다면 대규모 데이터 세트를 순회하고 데이터의 일부만 요청하는 방법이 필요합니다. 우리에게 유용합니다. 쿼리 언어가 여기에 잘 맞는 것 같습니다.
데이터베이스와 같은 방식으로 데이터에 대해 질문할 필요가 없으므로 SQL과 같은 명령형 언어는 잘못된 도구처럼 보입니다. 사실, 우리의 주요 목표는 기존 관계를 탐색하고 비교적 간단하고 선언적인 것으로 할 수 있어야 하는 필드를 제한하는 것입니다. 업계는 바이너리가 아닌 데이터에 대해 JSON에 꽤 잘 정착했으므로 JSON과 유사한 선언적 쿼리 언어로 시작하겠습니다. 필요한 데이터를 설명할 수 있어야 하고 서버는 해당 필드가 포함된 JSON을 반환해야 합니다.

선언적 쿼리 언어는 최소 페이로드와 최소 HTTP 트래픽 모두에 대한 요구 사항을 충족하지만 다른 설계 목표를 달성하는 데 도움이 되는 또 다른 이점이 있습니다. 쿼리 및 기타 많은 선언적 언어는 마치 데이터인 것처럼 효율적으로 조작될 수 있습니다. 신중하게 디자인하면 쿼리 언어를 통해 개발자가 대규모 요청을 분리하고 프로젝트에 적합한 방식으로 재결합할 수 있습니다. 이와 같은 쿼리 언어를 사용하면 지역 추론의 보존이라는 궁극적인 목표를 향해 나아가는 데 도움이 될 것입니다.
쿼리가 "데이터"가 되면 할 수 있는 흥미로운 일이 많이 있습니다. 예를 들어 Virtual DOM이 DOM 업데이트를 일괄 처리하는 방식과 유사하게 모든 요청을 가로채서 일괄 처리할 수 있습니다. 또한 컴파일러를 사용하여 빌드 시 작은 쿼리를 추출하여 데이터를 미리 캐시하거나 정교한 캐시 시스템을 구축할 수도 있습니다. 아폴로 캐시처럼.
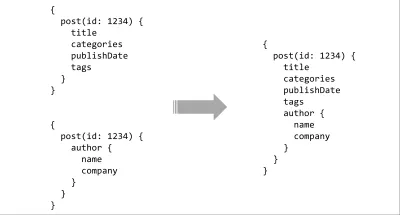
API 희망 목록의 마지막 항목은 도구입니다. 쿼리 언어를 사용하여 이미 이 중 일부를 얻었지만 유형 시스템과 함께 사용할 때 진정한 힘이 나옵니다. 서버에 간단한 유형의 스키마가 있으면 풍부한 도구를 사용할 수 있는 가능성이 거의 무한합니다. 쿼리는 계약에 대해 정적으로 분석 및 검증될 수 있으며, IDE 통합은 힌트 또는 자동 완성을 제공할 수 있으며, 컴파일러는 쿼리에 대한 빌드 타임 최적화를 수행하거나 여러 스키마를 함께 연결하여 연속적인 API 표면을 형성할 수 있습니다.

쿼리 언어와 유형 시스템을 결합하는 API를 설계하는 것은 극적인 제안처럼 들릴 수 있지만 사람들은 수년 동안 다양한 형태로 이를 실험해 왔습니다. XML-RPC는 90년대 중반에 형식화된 응답을 추진했으며 그 후계자인 SOAP는 수년간 지배적이었습니다! 더 최근에는 Meteor의 MongoDB 추상화, RethinkDB의 (RIP) Horizon, Netflix의 놀라운 Falcor와 같은 것들이 있습니다. Netflix.com에서 수년 동안 사용해 왔으며 마지막으로 Facebook의 GraphQL이 있습니다. 이 에세이의 나머지 부분에서는 Falcor와 같은 다른 프로젝트가 비슷한 일을 하고 있지만 커뮤니티의 공감대가 압도적으로 선호하는 것 같기 때문에 GraphQL에 중점을 둘 것입니다.
GraphQL이란 무엇입니까?
먼저 제가 거짓말을 조금 했습니다. 위에서 구축한 API는 GraphQL입니다. GraphQL은 데이터에 대한 유형 시스템, 데이터를 탐색하기 위한 쿼리 언어입니다. 나머지는 세부 정보일 뿐입니다. GraphQL에서 데이터를 상호 연결의 그래프로 설명하면 클라이언트가 필요한 데이터의 하위 집합을 구체적으로 요청합니다. GraphQL이 가능하게 하는 모든 놀라운 것들에 대해 많은 말과 글이 있지만 핵심 개념은 매우 관리하기 쉽고 복잡하지 않습니다.
이러한 개념을 보다 구체적으로 만들고 GraphQL이 Part 1의 일부 문제를 해결하는 방법을 설명하기 위해 이 게시물의 나머지 부분에서는 이 시리즈의 Part 1에 있는 블로그를 강화할 수 있는 GraphQL API를 빌드합니다. 코드를 시작하기 전에 GraphQL에 대해 염두에 두어야 할 몇 가지 사항이 있습니다.
GraphQL은 사양입니다(구현이 아님)
GraphQL은 사양일 뿐입니다. 간단한 쿼리 언어와 함께 유형 시스템을 정의하면 됩니다. 이것에서 가장 먼저 떨어지는 것은 GraphQL이 어떤 식으로든 특정 언어에 묶여 있지 않다는 것입니다. Haskell에서 C++에 이르기까지 모든 것에 24가지가 넘는 구현이 있으며 그 중 JavaScript는 하나만 있습니다. 사양이 발표된 직후 Facebook은 JavaScript로 참조 구현을 출시했지만 내부적으로 사용하지 않기 때문에 Go 및 Clojure와 같은 언어로 구현하는 것이 훨씬 더 좋거나 빠를 수 있습니다.
GraphQL의 사양에는 클라이언트 또는 데이터가 언급되어 있지 않습니다.
사양을 읽으면 두 가지가 눈에 띄게 빠져 있음을 알 수 있습니다. 첫째, 쿼리 언어 외에 클라이언트 통합에 대한 언급이 없습니다. Apollo, Relay, Loka 등과 같은 도구는 GraphQL의 설계로 인해 가능하지만 사용에 일부이거나 필수는 아닙니다. 둘째, 특정 데이터 계층에 대한 언급이 없습니다. 동일한 GraphQL 서버는 이기종 소스 세트에서 데이터를 가져올 수 있고 자주 수행합니다. Redis에서 캐시된 데이터를 요청하고, USPS API에서 주소 조회를 수행하고, protobuff 기반 마이크로서비스를 호출할 수 있으며 클라이언트는 그 차이를 절대 알 수 없습니다.
복잡성의 점진적인 공개
많은 사람들에게 GraphQL은 강력함과 단순함의 드문 교차점에 도달했습니다. 그것은 단순한 일을 단순하고 어려운 일을 가능하게 만드는 환상적인 일을 합니다. HTTP를 통해 서버를 실행하고 유형이 지정된 데이터를 제공하는 것은 상상할 수 있는 거의 모든 언어로 된 몇 줄의 코드일 수 있습니다.
예를 들어 GraphQL 서버는 기존 REST API를 래핑할 수 있으며 해당 클라이언트는 다른 서비스와 상호 작용하는 것처럼 일반 GET 요청으로 데이터를 가져올 수 있습니다. 여기에서 데모를 볼 수 있습니다. 또는 프로젝트에 보다 정교한 도구 세트가 필요한 경우 GraphQL을 사용하여 필드 수준 인증, 게시/구독 구독 또는 사전 컴파일/캐시된 쿼리와 같은 작업을 수행할 수 있습니다.
예제 앱
이 예제의 목표는 광범위한 튜토리얼을 작성하는 것이 아니라 최대 70줄의 JavaScript로 GraphQL의 강력함과 단순성을 입증하는 것입니다. 구문과 의미에 대해 너무 자세히 설명하지는 않겠지만 여기에 있는 모든 코드는 실행할 수 있으며 기사 끝에 다운로드 가능한 프로젝트 버전에 대한 링크가 있습니다. 이 과정을 거친 후 좀 더 깊이 파고들고 싶다면 내 블로그에 더 크고 강력한 서비스를 구축하는 데 도움이 되는 리소스 모음이 있습니다.
데모에서는 JavaScript를 사용하지만 단계는 모든 언어에서 매우 유사합니다. 놀라운 Mocky.io를 사용하여 몇 가지 샘플 데이터부터 시작하겠습니다.
저자
{ 9: { id: 9, name: "Eric Baer", company: "Formidable" }, ... }게시물
[ { id: 17, author: "author/7", categories: [ "software engineering" ], publishdate: "2016/03/27 14:00", summary: "...", tags: [ "http/2", "interlock" ], title: "http/2 server push" }, ... ] 첫 번째 단계는 express 및 express-graphql 미들웨어를 사용하여 새 프로젝트를 만드는 것입니다.
bash npm init -y && npm install --save graphql express express-graphql 그리고 익스프레스 서버로 index.js 파일을 생성합니다.
const app = require("express")(); const PORT = 5000; app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); GraphQL 작업을 시작하려면 REST API에서 데이터를 모델링하는 것으로 시작할 수 있습니다. schema.js 라는 새 파일에 다음을 추가합니다.
const { GraphQLInt, GraphQLList, GraphQLObjectType, GraphQLSchema, GraphQLString } = require("graphql"); const Author = new GraphQLObjectType({ name: "Author", fields: { id: { type: GraphQLInt }, name: { type: GraphQLString }, company: { type: GraphQLString }, } }); const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author }, categories: { type: new GraphQLList(GraphQLString) }, publishDate: { type: GraphQLString }, summary: { type: GraphQLString }, tags: { type: new GraphQLList(GraphQLString) }, title: { type: GraphQLString } } }); const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post) } } }); module.exports = new GraphQLSchema({ query: Blog }); 위의 코드는 API의 JSON 응답 유형을 GraphQL 유형에 매핑합니다. GraphQLObjectType 은 JavaScript Object 에 해당하고 GraphQLString 은 JavaScript String 에 해당합니다. 주의해야 할 한 가지 특별한 유형은 마지막 몇 줄에 있는 GraphQLSchema 입니다. GraphQLSchema 는 그래프를 트래버스하는 쿼리의 시작점인 GraphQL의 루트 수준 내보내기입니다. 이 기본 예에서는 query 만 정의하고 있습니다. 여기에서 돌연변이(쓰기) 및 구독을 정의합니다.

다음으로 index.js 파일의 익스프레스 서버에 스키마를 추가합니다. 이를 위해 express-graphql 미들웨어를 추가하고 스키마를 전달합니다.
const graphqlHttp = require("express-graphql"); const schema = require("./schema.js"); const app = require("express")(); const PORT = 5000; app.use(graphqlHttp({ schema, // Pretty Print the JSON response pretty: true, // Enable the GraphiQL dev tool graphiql: true })); app.listen(PORT, () => { console.log(`Server running at https://localhost:${PORT}`); }); 이 시점에서 데이터를 반환하지 않지만 클라이언트에 스키마를 제공하는 작동 중인 GraphQL 서버가 있습니다. 애플리케이션을 더 쉽게 시작할 수 있도록 package.json 에 시작 스크립트도 추가합니다.
"scripts": { "start": "nodemon index.js" }, 프로젝트를 실행하고 https://localhost:5000/으로 이동하면 GraphiQL이라는 데이터 탐색기가 표시되어야 합니다. HTTP Accept 헤더가 application/json 으로 설정되지 않은 한 GraphiQL은 기본적으로 로드됩니다. application/json 을 사용하여 fetch 또는 cURL 로 이 동일한 URL을 호출하면 JSON 결과가 반환됩니다. 내장 문서를 자유롭게 사용하고 쿼리를 작성하십시오.

서버를 완성하기 위해 남은 유일한 일은 기본 데이터를 스키마에 연결하는 것입니다. 이렇게 하려면 resolve 함수를 정의해야 합니다. GraphQL에서 쿼리는 트리를 횡단할 때 resolve 함수를 호출하여 위에서 아래로 실행됩니다. 예를 들어 다음 쿼리의 경우:
query homepage { posts { title } } GraphQL은 먼저 posts.resolve(parentData) 를 호출한 다음 posts.title.resolve(parentData) parentData) 를 호출합니다. 블로그 게시물 목록에서 리졸버를 정의하는 것으로 시작하겠습니다.
const Blog = new GraphQLObjectType({ name: "Blog", fields: { posts: { type: new GraphQLList(Post), resolve: () => { return fetch('https://www.mocky.io/v2/594a3ac810000053021aa3a7') .then((response) => response.json()) } } } }); 여기에서 isomorphic-fetch 패키지를 사용하여 리졸버에서 Promise를 반환하는 방법을 훌륭하게 보여주기 때문에 HTTP 요청을 만들지만 원하는 모든 것을 사용할 수 있습니다. 이 함수는 블로그 유형에 대한 게시물 배열을 반환합니다. GraphQL의 JavaScript 구현을 위한 기본 확인 함수는 parentData.<fieldName> 입니다. 예를 들어 작성자 이름 필드의 기본 확인자는 다음과 같습니다.
rawAuthorObject => rawAuthorObject.name이 단일 재정의 해석기는 전체 게시물 개체에 대한 데이터를 제공해야 합니다. Author에 대한 리졸버를 정의해야 하지만 홈페이지에 필요한 데이터를 가져오기 위해 쿼리를 실행하면 제대로 작동하는 것을 볼 수 있습니다.
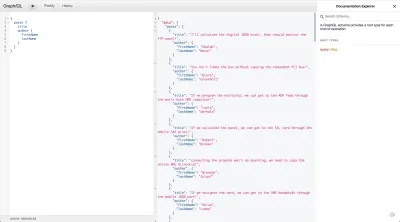
Posts API의 작성자 속성은 작성자 ID일 뿐이므로 GraphQL이 이름과 회사를 정의하는 개체를 찾고 문자열을 찾으면 null 만 반환합니다. Author를 연결하려면 Post 스키마를 다음과 같이 변경해야 합니다.
const Post = new GraphQLObjectType({ name: "Post", fields: { id: { type: GraphQLInt }, author: { type: Author, resolve: (subTree) => { // Get the AuthorId from the post data const authorId = subTree.author.split("/")[1]; return fetch('https://www.mocky.io/v2/594a3bd21000006d021aa3ac') .then((response) => response.json()) .then(authors => authors[authorId]); } }, ... } });이제 REST API를 래핑하는 완전히 작동하는 GraphQL 서버가 있습니다. 전체 소스는 이 Github 링크에서 다운로드하거나 이 GraphQL 런치패드에서 실행할 수 있습니다.
이와 같은 GraphQL 끝점을 사용하는 데 사용해야 하는 도구에 대해 궁금할 수 있습니다. Relay, Apollo 등의 옵션이 많이 있지만 일단은 간단한 접근 방식이 가장 좋다고 생각합니다. GraphiQL을 많이 사용했다면 URL이 길다는 것을 알아차렸을 것입니다. 이 URL은 쿼리의 URI로 인코딩된 버전일 뿐입니다. JavaScript에서 GraphQL 쿼리를 작성하려면 다음과 같이 할 수 있습니다.
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);또는 원하는 경우 다음과 같이 GraphiQL에서 바로 URL을 복사하여 붙여넣을 수 있습니다.
https://localhost:5000/?query=query%20homepage%20%7B%0A%20%20posts%20%7B%0A%20%20%20%20title%0A%20%20%20%20author%20%7B%0A%20%20%20%20%20%20name%0A%20%20%20%20%7D%0A%20%20%7D%0A%7D&operationName=homepageGraphQL 엔드포인트와 사용 방법이 있으므로 이를 RESTish API와 비교할 수 있습니다. RESTish API를 사용하여 데이터를 가져오기 위해 작성해야 하는 코드는 다음과 같습니다.
RESTish API 사용
const getPosts = () => fetch(`${API_ROOT}/posts`); const getPost = postId => fetch(`${API_ROOT}/post/${postId}`); const getAuthor = authorId => fetch(`${API_ROOT}/author/${postId}`); const getPostWithAuthor = post => { return getAuthor(post.author) .then(author => { return Object.assign({}, post, { author }) }) }; const getHomePageData = () => { return getPosts() .then(posts => { const postDetails = posts.map(getPostWithAuthor); return Promise.all(postDetails); }) };GraphQL API 사용
const homepageQuery = ` posts { title author { name } } `; const uriEncodedQuery = encodeURIComponent(homepageQuery); fetch(`https://localhost:5000/?query=${uriEncodedQuery}`);요약하면 GraphQL을 사용하여 다음을 수행했습니다.
- 9개의 요청을 줄입니다(게시물 목록, 4개의 블로그 게시물 및 각 게시물의 작성자).
- 전송되는 데이터의 양을 상당히 줄입니다.
- 놀라운 개발자 도구를 사용하여 쿼리를 작성하십시오.
- 클라이언트에서 훨씬 더 깔끔한 코드를 작성하십시오.
GraphQL의 결함
과대 광고가 정당하다고 생각하지만 은색 총알은 없으며 GraphQL만큼 훌륭하지만 결함이 없는 것은 아닙니다.
데이터 무결성
GraphQL은 때때로 좋은 데이터를 위해 특별히 제작된 도구처럼 보입니다. 종종 서로 다른 서비스나 고도로 정규화된 테이블을 연결하는 일종의 게이트웨이로 가장 잘 작동합니다. 사용하는 서비스에서 반환되는 데이터가 지저분하고 구조화되지 않은 경우 GraphQL 아래에 데이터 변환 파이프라인을 추가하는 것이 정말 어려울 수 있습니다. GraphQL resolve 함수의 범위는 자신의 데이터와 자식의 데이터일 뿐입니다. 오케스트레이션 작업이 트리의 형제 또는 부모 데이터에 액세스해야 하는 경우 특히 어려울 수 있습니다.
복잡한 오류 처리
GraphQL 요청은 임의의 수의 쿼리를 실행할 수 있으며 각 쿼리는 임의의 수의 서비스에 도달할 수 있습니다. 요청의 일부가 실패하면 전체 요청이 실패하는 것이 아니라 GraphQL이 기본적으로 부분 데이터를 반환합니다. 부분 데이터는 기술적으로 올바른 선택일 수 있으며 매우 유용하고 효율적일 수 있습니다. 단점은 오류 처리가 더 이상 HTTP 상태 코드를 확인하는 것만큼 간단하지 않다는 것입니다. 이 동작을 해제할 수 있지만 클라이언트가 더 복잡한 오류 사례로 끝나는 경우가 더 많습니다.
캐싱
정적 GraphQL 쿼리를 사용하는 것이 좋은 경우가 많지만 임의 쿼리를 허용하는 Github과 같은 조직의 경우 Varnish 또는 Fastly와 같은 표준 도구를 사용한 네트워크 캐싱은 더 이상 불가능합니다.
높은 CPU 비용
쿼리 구문 분석, 유효성 검사 및 유형 검사는 JavaScript와 같은 단일 스레드 언어에서 성능 문제를 유발할 수 있는 CPU 바운드 프로세스입니다.
이것은 런타임 쿼리 평가에 대한 문제일 뿐입니다.
마무리 생각
GraphQL의 기능은 혁명이 아닙니다. 그 중 일부는 거의 30년 동안 사용되었습니다. GraphQL을 강력하게 만드는 것은 세련된 수준, 통합 및 사용 편의성이 부품의 합 그 이상을 만든다는 것입니다.
GraphQL이 수행하는 많은 작업은 노력과 훈련을 통해 REST 또는 RPC를 사용하여 달성할 수 있지만 GraphQL은 자체적으로 이를 수행할 시간, 리소스 또는 도구가 없을 수 있는 수많은 프로젝트에 최첨단 API를 제공합니다. GraphQL이 만병통치약이 아닌 것도 사실이지만 그 결점은 사소하고 잘 이해되는 경향이 있습니다. 합리적으로 복잡한 GraphQL 서버를 구축한 사람으로서 나는 쉽게 비용보다 이점이 크다고 말할 수 있습니다.
이 에세이는 거의 전적으로 GraphQL이 존재하는 이유와 GraphQL이 해결하는 문제에 중점을 둡니다. 이것이 의미론과 사용 방법에 대해 더 많은 것을 배우는 데 관심을 불러일으켰다면 블로그, YouTube 또는 단지 소스 읽기(How To GraphQL이 특히 좋습니다)이든지 간에 가장 효과적인 방법을 배우기를 권장합니다.
이 기사가 마음에 들었다면(또는 싫어했다면) 저에게 피드백을 제공하고 싶다면 Twitter에서 @ebaerbaerbaer 또는 LinkedIn ericjbaer로 저를 찾으세요.