
기계 학습의 경사하강법: 어떻게 작동합니까?
게시 됨: 2021-01-28목차
소개
기계 학습의 가장 중요한 부분 중 하나는 알고리즘의 최적화입니다. 기계 학습의 거의 모든 알고리즘은 알고리즘의 핵심 역할을 하는 최적화 알고리즘을 기반으로 합니다. 우리 모두 알다시피 최적화는 실제 사건이나 시장에서 기술 기반 제품을 다룰 때에도 모든 알고리즘의 궁극적인 목표입니다.
현재 얼굴 인식, 자율 주행 자동차, 시장 기반 분석 등과 같은 여러 응용 프로그램에서 사용되는 최적화 알고리즘이 많이 있습니다. 마찬가지로 머신 러닝에서도 이러한 최적화 알고리즘이 중요한 역할을 합니다. 널리 사용되는 최적화 알고리즘 중 하나는 이 기사에서 다룰 Gradient Descent Algorithm입니다.
경사하강법이란?
기계 학습에서 경사 하강법 알고리즘은 가장 많이 사용되는 알고리즘 중 하나이지만 대부분의 신규 사용자를 어리둥절하게 만듭니다. 수학적으로 기울기 하강법은 미분 가능한 함수의 극소값을 찾는 데 사용되는 1차 반복 최적화 알고리즘입니다. 간단히 말해서 이 Gradient Descent 알고리즘은 비용 함수를 가능한 한 낮게 최소화하는 데 사용되는 함수의 매개변수(또는 계수) 값을 찾는 데 사용됩니다. 비용 함수는 구축된 기계 학습 모델의 예측 값과 실제 값 사이의 오류를 수량화하는 데 사용됩니다.
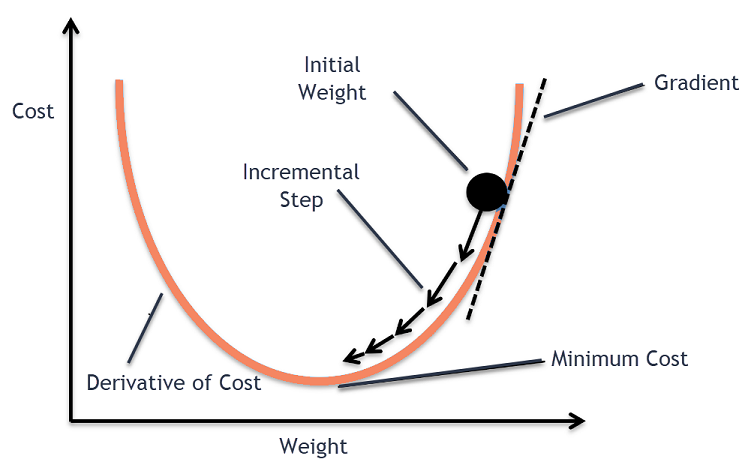
기울기 하강 직관
일반적으로 과일을 담거나 시리얼을 먹는 큰 그릇을 고려하십시오. 이 그릇은 비용 함수(f)가 됩니다.
이제 그릇 표면의 임의의 좌표는 비용 함수 계수의 현재 값이 됩니다. 그릇의 바닥은 계수의 가장 좋은 집합이며 함수의 최소값입니다.
여기에서 목표는 각 반복마다 계수의 다른 값을 계산하고 비용을 평가하고 더 나은 비용 함수 값(낮은 값)을 갖는 계수를 선택하는 것입니다. 여러 번 반복하면 보울의 바닥이 비용 함수를 최소화하는 데 가장 좋은 계수를 갖는다는 것을 알 수 있습니다.

이러한 방식으로 Gradient Descent 알고리즘은 최소 비용으로 작동합니다.
세계 최고의 대학(석사, 대학원 대학원 과정, ML 및 AI 고급 인증 프로그램) 의 기계 학습 과정 에 온라인으로 참여 하여 경력을 빠르게 추적하십시오.
경사하강법 절차
이 경사 하강 과정은 처음에 비용 함수의 계수에 값을 할당하는 것으로 시작됩니다. 이것은 0에 가까운 값이거나 작은 임의 값일 수 있습니다.
계수 = 0.0
다음으로, 비용 함수에 이를 적용하고 비용을 계산하여 계수의 비용을 구합니다.
비용 = f(계수)
그런 다음 비용 함수의 도함수가 계산됩니다. 비용 함수의 이 도함수는 미분학의 수학적 개념에 의해 얻어집니다. 도함수가 계산되는 주어진 지점에서 함수의 기울기를 제공합니다. 이 기울기는 더 낮은 비용 값을 얻기 위해 다음 반복에서 계수가 어느 방향으로 이동해야 하는지를 아는 데 필요합니다. 이것은 계산된 도함수의 부호를 관찰함으로써 수행됩니다.
델타 = 파생상품(비용)
계산된 도함수에서 어떤 방향이 내리막인지 알게 되면 계수 값을 업데이트해야 합니다. 이를 위해 매개변수를 학습 매개변수라고 하며 알파(α)가 활용됩니다. 업데이트할 때마다 계수가 변경될 수 있는 정도를 제어하는 데 사용됩니다.
계수 = 계수 – (알파 * 델타)
원천
이러한 방식으로, 이 프로세스는 계수의 비용이 0.0과 같거나 0에 충분히 가까울 때까지 반복됩니다. 이것이 경사하강법 알고리즘의 절차입니다.
경사하강법의 종류
현대에는 현대 기계 학습 및 딥 러닝 알고리즘에 사용되는 3가지 기본 유형의 경사하강법이 있습니다. 이 3가지 유형의 주요 차이점은 계산 비용과 효율성입니다. 사용된 데이터의 양, 시간 복잡도 및 정확도에 따라 다음 세 가지 유형이 있습니다.
- 배치 경사하강법
- 확률적 경사하강법
- 미니 배치 경사하강법
배치 경사 하강법
이것은 전체 데이터 세트를 한 번에 비용 함수와 그 기울기를 계산하는 데 사용하는 기울기 하강법 알고리즘의 첫 번째 기본 버전입니다. 단일 업데이트를 위해 전체 데이터 세트가 한 번에 사용되기 때문에 이 유형의 기울기 계산은 매우 느릴 수 있으며 장치의 메모리 용량을 초과하는 데이터 세트에서는 불가능합니다.
따라서 이 Batch Gradient Descent 알고리즘은 더 작은 데이터 세트에만 사용되며 훈련 예제의 수가 많을 경우 Batch Gradient Descent를 선호하지 않습니다. 대신 확률적 및 미니 배치 경사하강법 알고리즘이 사용됩니다.
확률적 경사하강법
이것은 반복당 하나의 훈련 예제만 처리되는 또 다른 유형의 경사하강법 알고리즘입니다. 여기서 첫 번째 단계는 전체 훈련 데이터 세트를 무작위화하는 것입니다. 그런 다음 계수를 업데이트하는 데 하나의 훈련 예제만 사용됩니다. 이는 모든 훈련 예제가 평가될 때만 매개변수(계수)가 업데이트되는 배치 경사 하강법과 대조됩니다.

SGD(Stochastic Gradient Descent)는 이러한 유형의 빈번한 업데이트가 세부적인 개선 속도를 제공한다는 이점이 있습니다. 그러나 어떤 경우에는 반복 횟수가 매우 많아질 수 있는 모든 반복마다 하나의 예제만 처리하기 때문에 계산 비용이 많이 들 수 있습니다.
미니 배치 경사하강법
이것은 Batch 및 Stochastic Gradient Descent 알고리즘보다 빠른 최근에 개발된 알고리즘입니다. 앞서 언급한 두 알고리즘의 조합이므로 대부분 선호됩니다. 여기에서 훈련 세트를 여러 미니 배치로 분리하고 해당 배치의 기울기를 계산한 후 이러한 배치 각각에 대해 업데이트를 수행합니다(예: SGD에서).
일반적으로 배치 크기는 30에서 500까지 다양하지만 응용 프로그램마다 다르기 때문에 고정된 크기는 없습니다. 따라서 훈련 데이터셋이 크더라도 이 알고리즘은 'b' 미니 배치로 처리합니다. 따라서 반복 횟수가 적은 대규모 데이터 세트에 적합합니다.
'm'이 훈련 예제의 수이고 b==m이면 Mini Batch Gradient Descent는 Batch Gradient Descent 알고리즘과 유사합니다.
기계 학습에서 경사하강법의 변형
Gradient Descent에 대한 이러한 기반을 바탕으로 이로부터 개발된 몇 가지 다른 알고리즘이 있습니다. 그 중 몇 가지가 아래에 요약되어 있습니다.
바닐라 그라디언트 디센트
이것은 Gradient Descent Technique의 가장 간단한 형태 중 하나입니다. 바닐라라는 이름은 순수하거나 불순물이 없는 것을 의미합니다. 이 경우 비용 함수의 기울기를 계산하여 최소값 방향으로 작은 단계를 수행합니다. 위에서 언급한 알고리즘과 유사하게 업데이트 규칙은 다음과 같이 주어집니다.
계수 = 계수 – (알파 * 델타)
모멘텀이 있는 경사하강법
이 경우 알고리즘은 다음 단계를 수행하기 전에 이전 단계를 알도록 합니다. 이것은 이전 업데이트와 모멘텀으로 알려진 상수의 산물인 새로운 용어를 도입하여 수행됩니다. 여기서 가중치 업데이트 규칙은 다음과 같이 주어집니다.
업데이트 = 알파 * 델타
속도 = 이전_업데이트 * 운동량
계수 = 계수 + 속도 – 업데이트
아다그라드
ADAGRAD라는 용어는 Adaptive Gradient Algorithm의 약자입니다. 이름에서 알 수 있듯이 적응형 기술을 사용하여 가중치를 업데이트합니다. 이 알고리즘은 희소 데이터에 더 적합합니다. 이 최적화는 훈련 중 매개변수 업데이트 빈도와 관련하여 학습률을 변경합니다. 예를 들어, 더 높은 기울기를 갖는 매개변수는 더 느린 학습률을 갖도록 만들어져 결국 최소값을 초과하지 않게 됩니다. 마찬가지로 기울기가 낮을수록 학습 속도가 빨라져 더 빨리 훈련됩니다.
아담
Gradient Descent 알고리즘에 뿌리를 둔 또 다른 적응 최적화 알고리즘은 적응 모멘트 추정(Adaptive Moment Estimation)을 나타내는 ADAM입니다. ADAGRAD와 SGD와 Momentum 알고리즘의 조합입니다. ADAGRAD 알고리즘을 기반으로 구축되었으며 더 불리하게 구축되었습니다. 간단히 말해서 ADAM = ADAGRAD + 모멘텀.
이러한 방식으로 AMSGrad, ADAMax와 같이 세계에서 개발 및 개발 중인 Gradient Descent Algorithms의 여러 변형이 있습니다.
결론
이 기사에서는 기계 학습에서 가장 일반적으로 사용되는 최적화 알고리즘 중 하나인 Gradient Descent Algorithms 뒤에 있는 알고리즘과 개발된 유형 및 변형을 살펴보았습니다.
upGrad는 기계 학습 및 인공 지능 분야의 PG 프로그램과 기계 학습 및 인공 지능 분야 의 석사 과정을 제공하여 경력을 쌓도록 안내합니다. 이 과정은 기계 학습의 필요성과 기계 학습의 경사하강법에 이르기까지 다양한 개념을 다루는 이 영역에서 지식을 수집하기 위한 추가 단계를 설명합니다.
Gradient Descent Algorithm은 어디에 최대로 기여할 수 있습니까?
모든 기계 학습 알고리즘 내에서 최적화는 알고리즘의 순도에 따라 점진적입니다. Gradient Descent Algorithm은 비용 함수 오류를 최소화하고 알고리즘 매개변수를 개선하는 데 도움이 됩니다. Gradient Descent 알고리즘은 Machine Learning 및 Deep Learning에서 널리 사용되지만 데이터 양, 선호하는 반복 및 정확도, 사용 가능한 시간에 따라 효율성이 결정될 수 있습니다. 소규모 데이터 세트의 경우 배치 경사 하강법이 최적입니다. Stochastic Gradient Descent(SGD)는 상세하고 광범위한 데이터 세트에 대해 더 효율적인 것으로 입증되었습니다. 대조적으로, Mini Batch Gradient Descent는 더 빠른 최적화를 위해 사용됩니다.
경사하강법에서 직면한 문제는 무엇입니까?
Gradient Descent는 비용 함수를 줄이기 위해 기계 학습 모델을 최적화하는 데 선호됩니다. 그러나 단점도 있습니다. 모델 레이어의 최소 출력 기능으로 인해 Gradient가 감소한다고 가정합니다. 이 경우 모델이 가중치와 편향을 업데이트하여 완전히 재학습하지 않기 때문에 반복은 효과적이지 않습니다. 때때로 오류 기울기는 반복 업데이트를 유지하기 위해 많은 가중치와 편향을 누적합니다. 그러나 이 기울기는 관리하기에는 너무 커져서 폭발 기울기라고 합니다. 인프라 요구 사항, 학습률 균형, 추진력을 해결해야 합니다.
경사하강법은 항상 수렴합니까?
수렴은 경사하강법 알고리즘이 비용 함수를 최적 수준으로 성공적으로 최소화하는 경우입니다. Gradient Descent Algorithm은 알고리즘 매개변수를 통해 비용 함수를 최소화하려고 합니다. 그러나 최적 지점 중 하나에 착륙할 수 있으며 반드시 전역 또는 로컬 최적 지점이 있는 것은 아닙니다. 최적의 수렴이 이루어지지 않는 한 가지 이유는 단계 크기입니다. 더 중요한 단계 크기는 더 많은 진동을 일으키고 전역 최적에서 벗어날 수 있습니다. 따라서 경사하강법이 항상 최상의 특징에 수렴하는 것은 아니지만 가장 가까운 특징 지점에 계속 착륙합니다.