
머신러닝의 가짜 뉴스 탐지 [코딩 예제로 설명]
게시 됨: 2021-02-08가짜 뉴스는 인터넷과 소셜 미디어 시대의 가장 큰 문제 중 하나입니다. 불과 몇 시간 만에 뉴스가 세계의 한 구석에서 다른 구석으로 흘러가는 것은 축복이지만, 가짜 뉴스를 퍼뜨리는 많은 사람들과 단체를 보는 것도 가슴 아픈 일입니다.
자연어 처리 및 딥 러닝을 사용하는 기계 학습 기술을 사용하여 이 문제를 어느 정도 해결할 수 있습니다. 이 튜토리얼에서는 기계 학습을 사용하여 가짜 뉴스 탐지 모델을 구축할 것입니다.
이 기사가 끝나면 다음을 알게 될 것입니다.
- 텍스트 데이터 처리
- NLP 처리 기술
- 카운트 벡터화 및 TF-IDF
- 예측 및 뉴스 텍스트 분류
세계 최고의 대학에서 온라인으로 AI 및 ML 과정 에 참여하십시오. 석사, 대학원 대학원 프로그램, ML 및 AI 고급 인증 프로그램을 통해 빠르게 경력을 쌓을 수 있습니다.
목차
데이터 및 문제
Kaggle Fake News 챌린지 데이터를 사용하여 분류기를 만들 것입니다. 데이터 세트는 4개의 기능과 1개의 바이너리 대상으로 구성됩니다. 4가지 기능은 다음과 같습니다.
- id : 뉴스 기사의 고유 id
- title : 뉴스 기사의 제목
- 저자 : 뉴스 기사의 저자
- text : 기사의 텍스트; 불완전할 수 있다
그리고 대상은 이진 값 0과 1을 포함하는 "레이블"입니다. 여기서 0은 신뢰할 수 있는 뉴스 소스, 즉 가짜가 아님을 의미합니다. 1은 잠재적으로 가짜 뉴스이며 신뢰할 수 없음을 의미합니다. 우리가 만든 데이터 세트는 20800개의 인스턴스로 구성되었습니다. 바로 뛰어들자.

데이터 전처리 및 정리
| pandas 를 pd 로 가져오기 df=pd.read_csv( '가짜 뉴스/train.csv' ) df.head() |
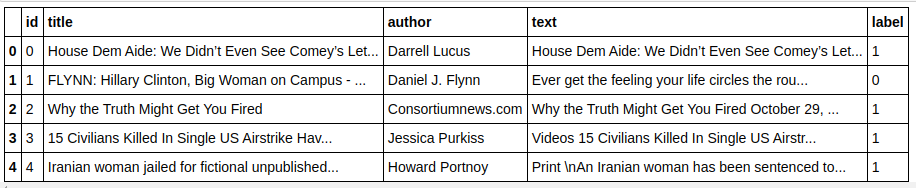
| X=df.drop( 'label' ,axis= 1 ) # 기능 y=df[ 'label' ] # 타겟 |
이제 데이터가 누락된 인스턴스를 삭제해야 합니다.
| df=df.dropna() |
![]()
보시다시피 데이터가 누락된 모든 인스턴스를 삭제했습니다.
| 메시지=df.copy() message.reset_index(inplace= True ) 메시지.헤드( 10 ) |
데이터를 한 번 살펴보겠습니다.
| 메시지['텍스트'][6] |

보시다시피 다음 단계를 수행해야 합니다.
- 불용어 제거: 데이터와 상관없이 텍스트에 가치를 더하지 않는 단어가 많이 있습니다. 예: "I", "a", "am" 등. 이 단어는 정보 가치가 없으므로 제거하여 말뭉치의 크기를 줄여 실제 가치가 있는 단어/토큰에만 집중할 수 있습니다. .
- 단어 어간 추출: 어간 추출과 표제어는 단어를 어간이나 어근으로 줄이는 기술입니다. 이 단계의 주요 이점은 어휘의 크기를 줄이는 것입니다. 예를 들어 Play, Playing, Played와 같은 단어는 "Play"로 축소됩니다. 형태소 분석은 단어를 가장 짧은 단어로 자르고 텍스트의 문법적 측면을 고려하지 않습니다. 반면에 표제어 표기법은 문법적 고려도 취하므로 훨씬 더 나은 결과를 산출합니다. 그러나 표제어 분류는 사전을 참조하고 문법적 측면을 고려해야 하기 때문에 일반적으로 형태소 분석보다 느립니다.
- 알파벳 값을 제외한 모든 값 제거: 알파벳이 아닌 값은 여기에서 그다지 유용하지 않으므로 제거할 수 있습니다. 그러나 수치 데이터 또는 기타 유형의 데이터가 대상에 영향을 미치는지 확인하기 위해 추가로 탐색할 수 있습니다.
- 소문자 단어: 단어를 소문자로 줄여 어휘를 줄입니다.
- 문장 토큰화: 문장 에서 토큰 생성.
| sklearn.feature_extraction.text에서 CountVectorizer, TfidfVectorizer, HashingVectorizer 가져오기 nltk.corpus에서 불용어 가져오기 nltk.stem.porter에서 가져오기 PorterStemmer 다시 수입 ps = PorterStemmer() 범위(0, len(messages))의 i에 대해 말뭉치 = []: 리뷰 = re.sub('[^a-zA-Z]', ' ', 메시지['텍스트'][i]) 리뷰 = review.lower() 리뷰 = review.split() review = [ps.stem(word) for word in review if not not word in stopwords.words('english')] review = ' '.join(review) corpus.append(검토) |
이제 코퍼스를 살펴보겠습니다.
| 말뭉치[ 3 ] |
![]()
우리가 볼 수 있듯이 단어는 이제 어근 단어로 파생됩니다.
TF-IDF 벡터라이저
이제 단어를 벡터화라고도 하는 숫자 데이터로 벡터화해야 합니다. 벡터화하는 가장 쉬운 방법은 Bag of Words를 사용하는 것입니다. 그러나 Bag of Words는 희소 행렬을 생성하므로 많은 처리 메모리가 필요합니다. 게다가, BoW는 단어의 빈도를 고려하지 않아 나쁜 알고리즘이 됩니다.
TF-IDF(Term Frequency – Inverse Document Frequency)는 단어 빈도를 고려하여 단어를 벡터화하는 또 다른 방법입니다. 예를 들어 "we", "our", "우리"와 같은 일반적인 단어는 모든 문서/인스턴스에 있으므로 BoW 값이 너무 높아 오해의 소지가 있습니다. 이것은 나쁜 모델로 이어질 것입니다. TF-IDF는 Term Frequency와 Inverse Document Frequency를 곱한 것입니다.
용어 빈도는 문서의 단어 빈도를 고려하고 역 문서 빈도는 전체 코퍼스에 존재하는 단어를 고려합니다. 전체 코퍼스에 걸쳐 존재하는 단어는 IDF 값이 훨씬 낮기 때문에 중요성이 감소했습니다. 하나의 문서에 구체적으로 존재하는 단어는 높은 IDF 값을 가지므로 전체 TF-IDF 값이 높아집니다.
| ## TFi df 벡터 라이저 sklearn.feature_extraction.text 에서 TfidfVectorizer 가져오기 tfidf_v = TfidfVectorizer(max_features= 5000 ,ngram_range=( 1 , 3 )) X=tfidf_v.fit_transform(corpus).toarray() y=messages[ 'label' ] |
위의 코드에서는 Sklearn의 feature 추출 모듈에서 TF-IDF Vectorizer를 가져옵니다. max_features를 5000으로, ngram_range를 (1,3)으로 전달하여 객체를 만듭니다. 매개변수 max_features는 생성하려는 특징 벡터의 최대 수를 정의하고 ngram_range 매개변수는 포함하려는 ngram 조합을 정의합니다. 우리의 경우 1단어, 2단어, 3단어의 3가지 조합을 얻습니다. 생성된 몇 가지 기능을 살펴보겠습니다.

| tfidf_v.get_feature_names()[: 20 ] |

보시다시피 여러 유형의 조합이 형성되어 있습니다. 1개의 토큰, 2개의 토큰 및 3개의 토큰이 있는 기능 이름이 있습니다.
데이터 프레임 만들기
| ## 데이터세트를 학습과 테스트로 나눕니다. sklearn.model_selection import train_test_split 에서 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= 0.33 , random_state= 0 ) count_df = pd.DataFrame(X_train, 열=tfidf_v.get_feature_names()) count_df.head() |
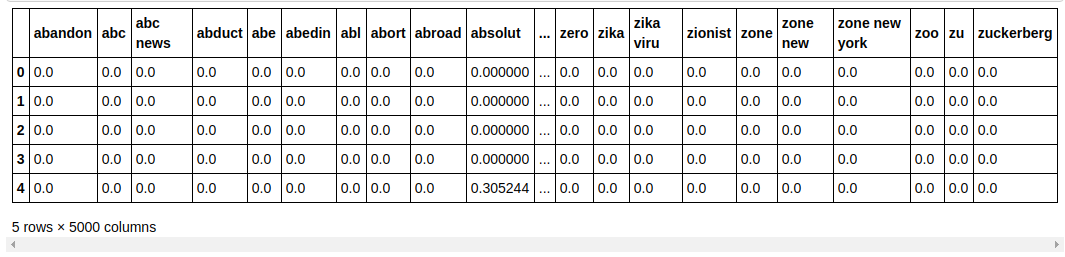
우리는 보이지 않는 데이터에 대한 모델의 성능을 테스트할 수 있도록 데이터 세트를 훈련과 테스트로 나눕니다. 그런 다음 새 특징 벡터를 포함하는 새 데이터 프레임을 만듭니다.
모델링 및 튜닝
다항식NB 알고리즘
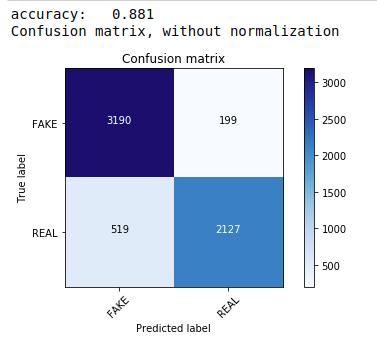
먼저 텍스트 데이터 분류에 선호되는 가장 일반적이고 가장 쉬운 알고리즘인 Multinomial Naive Bayes 정리를 사용합니다. 우리는 훈련 데이터에 적합하고 테스트 데이터에 대해 예측합니다. 나중에 우리는 정오분류표를 계산하고 플로팅하여 88.1%의 정확도를 얻습니다.
| sklearn.naive_bayes 에서 MultinomialNB 가져오기 sklearn 가져오기 측정항목 에서 numpy 를 np 로 가져오기 가져오기 itertools sklearn.metrics 에서 plot_confusion_matrix 가져오기 분류자=다항식NB() classifier.fit(X_train, y_train) pred = classifier.predict(X_test) 점수 = metrics.accuracy_score(y_test, pred) print( "정확도: %0.3f" % 점수) cm = metrics.confusion_matrix(y_test, pred) plot_confusion_matrix(cm, 클래스=[ 'FAKE' , 'REAL' ]) |
초매개변수 조정이 있는 다항 분류기
MultinomialNB에는 추가로 조정할 수 있는 매개변수 알파가 있습니다. 따라서 루프를 실행하여 서로 다른 알파 값을 가진 여러 MultinomialNB 분류기를 시도하고 정확도 점수를 확인합니다. 그리고 현재 점수가 이전 점수보다 높은지 확인합니다. 그렇다면 분류기를 현재 분류기로 설정합니다.
| 이전 점수= 0 np.arange( 0 , 1 , 0.1 ) 의 알파 의 경우 : sub_classifier=다항식NB(알파=알파) sub_classifier.fit(X_train,y_train) y_pred=sub_classifier.predict(X_test) 점수 = metrics.accuracy_score(y_test, y_pred) 점수>이전 _점수인 경우 : 분류자=sub_classifier print( "알파: {}, 점수: {}" .format(알파, 점수)) |
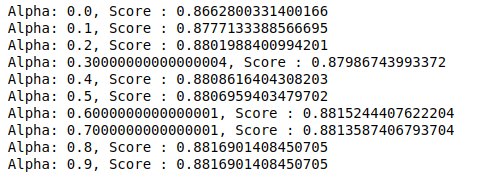
따라서 우리는 0.9 또는 0.8의 알파 값이 가장 높은 정확도 점수를 주었다는 것을 알 수 있습니다.
결과 해석
이제 이러한 분류기 계수 값이 의미하는 바를 살펴보겠습니다. 먼저 모든 기능 이름을 다른 변수에 저장합니다.
| ## 이름 가져 오기 feature_names = cv.get_feature_names() |
이제 값을 역순으로 정렬하면 최소값이 -4인 값을 얻습니다. 이것들은 가장 실제적이거나 가장 덜 가짜인 단어를 나타냅니다.
| ### 가장 실제 sorted(zip(classifier.coef_[ 0 ], feature_names), reverse= True )[: 20 ] |
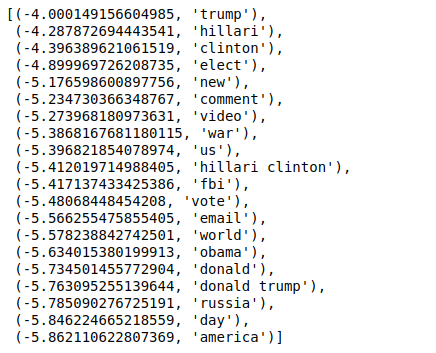
역순이 아닌 순서로 값을 정렬하면 최소값이 -10인 값을 얻습니다. 이것들은 가장 현실적이지 않거나 가장 가짜인 단어를 나타냅니다.
| ### 가장 실제 sorted(zip(classifier.coef_[ 0 ], feature_names))[: 20 ] |
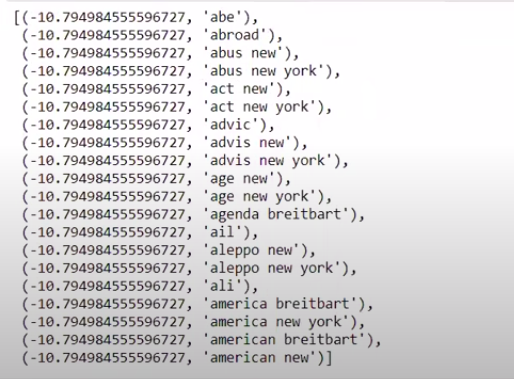
결론
이 자습서에서는 ML 알고리즘만 사용했지만 다른 신경망 방법도 사용합니다. 또한 텍스트 데이터를 벡터화하기 위해 TF-IDF 벡터라이저를 사용했습니다. Count Vectorizer, Hashing Vectorizer 등과 같은 더 많은 vectorizer가 있으며 작업을 더 잘 수행할 수 있습니다. 더 나은 결과를 얻을 수 있는지 여부를 확인하기 위해 다른 알고리즘과 기술을 시도하고 실험하십시오.
머신 러닝에 대해 자세히 알아보려면 IIIT-B & upGrad의 기계 학습 및 AI 경영자 PG 프로그램을 확인하세요. 이 프로그램은 일하는 전문가를 위해 설계되었으며 450시간 이상의 엄격한 교육, 30개 이상의 사례 연구 및 과제, IIIT를 제공합니다. -B 동문 자격, 5개 이상의 실용적인 실습 캡스톤 프로젝트 및 최고의 기업과의 취업 지원.
가짜 뉴스를 탐지해야 하는 이유는 무엇입니까?
현재 상황에서 소셜 미디어 플랫폼은 사용자가 민주주의, 교육, 건강과 같은 주제에 대해 토론하고 아이디어를 교환하고 토론할 수 있다는 점에서 매우 강력하고 가치가 있습니다. 그러나 특정 단체는 이러한 플랫폼을 악용하여 상황에 따라 금전적 이득을 취하거나 편견을 낳고 사고 방식을 바꾸며 풍자 또는 우스꽝스러운 내용을 유포합니다. 가짜 뉴스는 이 현상에 대한 용어입니다. 현실에 맞지 않는 게시물이 온라인에 확산되면서 정치, 스포츠, 건강, 과학 등 다양한 분야에서 많은 문제가 발생하고 있습니다.
어떤 회사가 가짜 뉴스 탐지를 주로 사용합니까?
가짜 뉴스 탐지는 소셜 미디어 및 뉴스 웹사이트와 같은 플랫폼에서 사용됩니다. 페이스북, 인스타그램, 트위터와 같은 거대 소셜 미디어는 대부분의 사용자가 최신 정보를 얻기 위해 매일 뉴스 소스로 신뢰하기 때문에 가짜 뉴스에 취약합니다. 가짜 탐지 기술은 미디어 회사에서 보유한 정보의 진위 여부를 확인하는 데에도 사용됩니다. 이메일은 개인이 뉴스를 수신할 수 있는 또 다른 매체로, 사실 여부를 식별하고 확인하기 어렵습니다. 사기, 스팸 및 정크 메일은 이메일을 통해 전송되는 것으로 잘 알려져 있습니다. 결과적으로 대부분의 이메일 플랫폼은 스팸과 정크 메일을 식별하기 위해 거짓 뉴스 탐지를 사용합니다.