
Express 및 ES6+ JavaScript 스택 시작하기
게시 됨: 2022-03-10이 기사는 Node.js, ES6+ JavaScript, 콜백 함수, 화살표 함수, API, HTTP 프로토콜, JSON, MongoDB 및 더.
이 기사에서는 이전 기사에서 얻은 기술을 바탕으로 사용자 책 목록 정보를 저장하기 위한 MongoDB 데이터베이스를 구현 및 배포하는 방법, Node.js 및 Express Web Application 프레임워크를 사용하여 해당 데이터베이스를 노출하는 API를 구축하는 방법을 학습합니다. CRUD 작업을 수행하는 등의 작업을 수행합니다. 그 과정에서 ES6 Object Destructuring, ES6 Object Shorthand, Async/Await 구문, Spread Operator에 대해 논의하고 CORS, Same Origin Policy 등에 대해 간략히 살펴보겠습니다.
나중 기사에서는 3계층 아키텍처를 활용하고 종속성 주입을 통해 제어 역전을 달성하여 우려 사항을 분리하기 위해 코드베이스를 리팩토링하고 JSON 웹 토큰 및 Firebase 인증 기반 보안 및 액세스 제어를 수행하고 안전한 방법을 배웁니다. 암호를 저장하고 AWS Simple Storage Service를 사용하여 Node.js 버퍼 및 스트림으로 사용자 아바타를 저장하는 동시에 데이터 지속성을 위해 PostgreSQL을 활용합니다. 그 과정에서 우리는 고전적인 OOP 개념(예: 다형성, 상속, 구성 등)과 팩토리 및 어댑터와 같은 디자인 패턴을 검사하기 위해 TypeScript에서 처음부터 코드베이스를 다시 작성할 것입니다.
경고의 말씀
오늘날 Node.js에 대해 논의하는 대부분의 기사에는 문제가 있습니다. 전부는 아니지만 대부분은 Express Routing을 설정하고, Mongoose를 통합하고, JSON 웹 토큰 인증을 활용하는 방법을 설명하는 것 이상으로 진행되지 않습니다. 문제는 그들이 아키텍처, 보안 모범 사례, 깨끗한 코딩 원칙, ACID 규정 준수, 관계형 데이터베이스, 제5정규형, CAP 정리 또는 트랜잭션에 대해 이야기하지 않는다는 것입니다. 들어오는 모든 것에 대해 알고 있거나 앞서 언급한 지식을 보증할 만큼 크거나 대중적인 프로젝트를 구축하지 않을 것이라고 가정합니다.
몇 가지 다른 유형의 Node 개발자가 있는 것 같습니다. 그 중 일부는 일반적으로 프로그래밍을 처음 접하는 사람이고 다른 일부는 C# 및 .NET Framework 또는 Java Spring Framework를 사용한 엔터프라이즈 개발의 오랜 역사에서 왔습니다. 대부분의 기사는 전자 그룹을 대상으로 합니다.
이 기사에서는 너무 많은 기사가 하고 있다고 방금 언급한 것을 정확히 수행할 것이지만 후속 기사에서는 코드베이스를 완전히 리팩토링하여 종속성 주입, 3-3-3과 같은 원칙을 설명할 수 있도록 할 것입니다. 레이어 아키텍처(컨트롤러/서비스/리포지토리), 데이터 매핑 및 활성 레코드, 디자인 패턴, 단위, 통합 및 돌연변이 테스트, SOLID 원칙, 작업 단위, 인터페이스에 대한 코딩, HSTS, CSRF, NoSQL 및 SQL 주입과 같은 보안 모범 사례 예방 등이 있습니다. 우리는 또한 ORM 대신 간단한 쿼리 빌더 Knex를 사용하여 MongoDB에서 PostgreSQL로 마이그레이션할 것입니다. 이를 통해 자체 데이터 액세스 인프라를 구축하고 다양한 유형의 관계(One- 일대일, 다대다 등) 등이 있습니다. 따라서 이 기사는 초보자에게 어필해야 하지만 다음 기사는 아키텍처를 개선하려는 중급 개발자를 대상으로 해야 합니다.
여기서는 책 데이터를 유지하는 것에 대해서만 걱정할 것입니다. 사용자 인증, 암호 해싱, 아키텍처 또는 이와 유사한 복잡한 것은 처리하지 않습니다. 그 모든 것은 다음 기사와 앞으로 나올 기사에서 다룰 것입니다. 지금은 기본적으로 클라이언트가 데이터베이스에 책 정보를 저장하기 위해 HTTP 프로토콜을 통해 웹 서버와 통신할 수 있도록 하는 방법을 구축할 것입니다.
참고 : 나는 의도적으로 그것을 극도로 단순하게 유지했으며 아마도 여기에서는 그다지 실용적이지 않을 것입니다. 왜냐하면 이 기사 자체가 매우 길기 때문입니다. 따라서 우리는 이 시리즈를 통해 API의 품질과 복잡성을 점진적으로 개선할 것이지만 다시 한 번 이것이 Express에 대한 첫 번째 소개 중 하나로 간주되기 때문에 의도적으로 매우 단순하게 유지하고 있습니다.
- ES6 객체 구조 분해
- ES6 객체 속기
- ES6 스프레드 연산자(...)
- 올라오다...
ES6 객체 구조 분해
ES6 Object Destructuring 또는 Destructuring Assignment Syntax는 배열이나 객체의 값을 자체 변수로 추출하거나 압축을 푸는 방법입니다. 객체 속성으로 시작한 다음 배열 요소에 대해 논의하겠습니다.
const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; // Log properties: console.log('Name:', person.name); console.log('Occupation:', person.occupation); 이러한 작업은 매우 원시적이지만 어디에서나 person.something 을 계속 참조해야 한다는 점을 고려하면 다소 번거로울 수 있습니다. 코드 전체에 그렇게 해야 하는 10개의 다른 위치가 있다고 가정해 보겠습니다. 매우 빠르게 매우 힘들 것입니다. 간결한 방법은 이러한 값을 자체 변수에 할당하는 것입니다.
const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; const personName = person.name; const personOccupation = person.occupation; // Log properties: console.log('Name:', personName); console.log('Occupation:', personOccupation); 아마도 이것은 합리적으로 보일 수 있지만 person 객체에도 10개의 다른 속성이 중첩되어 있다면 어떻게 될까요? 변수에 값을 할당하기 위한 불필요한 줄이 많을 것입니다. 이 시점에서 객체 속성이 변경되면 변수가 해당 변경 사항을 반영하지 않기 때문에 위험합니다(객체에 대한 참조만 const 할당으로 변경할 수 없음을 기억하십시오. 개체의 속성이 아님), 기본적으로 더 이상 "상태"를 동기화할 수 없습니다(저는 그 단어를 느슨하게 사용하고 있습니다). 참조에 의한 전달과 값에 의한 전달이 여기서 작용할 수 있지만 이 섹션의 범위에서 너무 벗어나고 싶지 않습니다.
ES6 Object Destructing은 기본적으로 다음을 가능하게 합니다.
const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; // This is new. It's called Object Destructuring. const { name, occupation } = person; // Log properties: console.log('Name:', name); console.log('Occupation:', occupation); 우리는 새로운 객체/객체 리터럴을 만드는 것이 아니라 원래 객체에서 name 과 occupation 속성을 풀고 같은 이름의 자체 변수에 넣는 것입니다. 우리가 사용하는 이름은 추출하려는 속성 이름과 일치해야 합니다.
다시, 구문 const { a, b } = someObject; 구체적 a 어떤 속성과 속성 b 가 someObject 내에 존재할 것으로 예상하고(예: someObject 는 { a: 'dataA', b: 'dataB' } 가 될 수 있음) 값이 무엇이든 배치하기를 원한다는 것입니다. 동일한 이름의 const 변수 내의 해당 키/속성. 이것이 위의 구문이 두 개의 변수 const a = someObject.a 및 const b = someObject.b 를 제공하는 이유입니다.
이것이 의미하는 바는 Object Destructuring에는 두 가지 측면이 있다는 것입니다. "Template" 쪽과 "Source" 쪽, 여기서 const { a, b } 쪽(왼쪽)은 템플릿 이고 someObject 쪽(오른쪽)은 소스 쪽입니다. — "소스" 측의 데이터를 미러링하는 왼쪽에 구조 또는 "템플릿"을 정의하고 있습니다.
다시 한 번, 이를 명확히 하기 위해 몇 가지 예를 제시합니다.
// ----- Destructure from Object Variable with const ----- // const objOne = { a: 'dataA', b: 'dataB' }; // Destructure const { a, b } = objOne; console.log(a); // dataA console.log(b); // dataB // ----- Destructure from Object Variable with let ----- // let objTwo = { c: 'dataC', d: 'dataD' }; // Destructure let { c, d } = objTwo; console.log(c); // dataC console.log(d); // dataD // Destructure from Object Literal with const ----- // const { e, f } = { e: 'dataE', f: 'dataF' }; // <-- Destructure console.log(e); // dataE console.log(f); // dataF // Destructure from Object Literal with let ----- // let { g, h } = { g: 'dataG', h: 'dataH' }; // <-- Destructure console.log(g); // dataG console.log(h); // dataH중첩 속성의 경우 파괴 할당에서 동일한 구조를 미러링합니다.
const person = { name: 'Richard P. Feynman', occupation: { type: 'Theoretical Physicist', location: { lat: 1, lng: 2 } } }; // Attempt one: const { name, occupation } = person; console.log(name); // Richard P. Feynman console.log(occupation); // The entire `occupation` object. // Attempt two: const { occupation: { type, location } } = person; console.log(type); // Theoretical Physicist console.log(location) // The entire `location` object. // Attempt three: const { occupation: { location: { lat, lng } } } = person; console.log(lat); // 1 console.log(lng); // 2보시다시피, 제거하기로 결정한 속성은 선택 사항이며 중첩된 속성의 압축을 풀려면 구조 해제 구문의 템플릿 측에서 원래 개체(소스)의 구조를 미러링하면 됩니다. 원래 개체에 없는 속성을 구조화하려고 하면 해당 값이 정의되지 않습니다.
다음 구문을 사용하여 변수를 먼저 선언하지 않고(선언 없는 할당) 추가로 구조를 분해할 수 있습니다.
let name, occupation; const person = { name: 'Richard P. Feynman', occupation: 'Theoretical Physicist' }; ;({ name, occupation } = person); console.log(name); // Richard P. Feynman console.log(occupation); // Theoretical Physicist이전 줄에 함수가 있는 IIFE(즉시 호출된 함수 식)를 실수로 생성하지 않도록 식 앞에 세미콜론을 붙이고(이러한 함수가 있는 경우) 할당 문 주위에 괄호가 필요합니다. JavaScript가 왼쪽(템플릿)을 블록으로 취급하지 않도록 합니다.
구조화의 매우 일반적인 사용 사례는 함수 인수 내에 존재합니다.
const config = { baseUrl: '<baseURL>', awsBucket: '<bucket>', secret: '<secret-key>' // <- Make this an env var. }; // Destructures `baseUrl` and `awsBucket` off `config`. const performOperation = ({ baseUrl, awsBucket }) => { fetch(baseUrl).then(() => console.log('Done')); console.log(awsBucket); // <bucket> }; performOperation(config);보시다시피, 우리는 다음과 같이 함수 내부에 이제 익숙한 일반 구조 해제 구문을 사용할 수 있습니다.
const config = { baseUrl: '<baseURL>', awsBucket: '<bucket>', secret: '<secret-key>' // <- Make this an env var. }; const performOperation = someConfig => { const { baseUrl, awsBucket } = someConfig; fetch(baseUrl).then(() => console.log('Done')); console.log(awsBucket); // <bucket> }; performOperation(config);그러나 함수 시그니처 안에 해당 구문을 배치하면 자동으로 구조 해제가 수행되어 한 줄을 절약할 수 있습니다.
이것의 실제 사용 사례는 React Functional Components for props 에 있습니다.
import React from 'react'; // Destructure `titleText` and `secondaryText` from `props`. export default ({ titleText, secondaryText }) => ( <div> <h1>{titleText}</h1> <h3>{secondaryText}</h3> </div> );반대로:
import React from 'react'; export default props => ( <div> <h1>{props.titleText}</h1> <h3>{props.secondaryText}</h3> </div> );두 경우 모두 기본값을 속성에도 설정할 수 있습니다.
const personOne = { name: 'User One', password: 'BCrypt Hash' }; const personTwo = { password: 'BCrypt Hash' }; const createUser = ({ name = 'Anonymous', password }) => { if (!password) throw new Error('InvalidArgumentException'); console.log(name); console.log(password); return { id: Math.random().toString(36) // <--- Should follow RFC 4122 Spec in real app. .substring(2, 15) + Math.random() .toString(36).substring(2, 15), name: name, // <-- We'll discuss this next. password: password // <-- We'll discuss this next. }; } createUser(personOne); // User One, BCrypt Hash createUser(personTwo); // Anonymous, BCrypt Hash 보시다시피 구조 해제 시 해당 name 이 없는 경우 기본값을 제공합니다. 이전 구문으로도 이 작업을 수행할 수 있습니다.
const { a, b, c = 'Default' } = { a: 'dataA', b: 'dataB' }; console.log(a); // dataA console.log(b); // dataB console.log(c); // Default배열도 비구조화될 수 있습니다.
const myArr = [4, 3]; // Destructuring happens here. const [valOne, valTwo] = myArr; console.log(valOne); // 4 console.log(valTwo); // 3 // ----- Destructuring without assignment: ----- // let a, b; // Destructuring happens here. ;([a, b] = [10, 2]); console.log(a + b); // 12배열 구조 해제의 실질적인 이유는 React Hooks에서 발생합니다. (그리고 다른 많은 이유가 있습니다. 저는 단지 예로 React를 사용하고 있습니다).
import React, { useState } from "react"; export default () => { const [buttonText, setButtonText] = useState("Default"); return ( <button onClick={() => setButtonText("Toggled")}> {buttonText} </button> ); } useState 는 내보내기에서 구조화 해제되고 배열 함수/값은 useState 후크에서 구조화 해제됩니다. 다시 말하지만, 위의 내용이 이해가 되지 않더라도 걱정하지 마십시오. React를 이해해야 합니다. 저는 단지 예시로 사용하고 있습니다.
ES6 Object Destructuring에 대해 더 많은 것이 있지만 여기에서 한 가지 더 다룰 것입니다. Destructuring Renaming, 이는 범위 충돌이나 변수 그림자 등을 방지하는 데 유용합니다. 우리가 person 이라는 객체에서 name 이라는 속성을 구조화하고 싶지만 범위에 name 이름의 변수가 이미 있습니다. 콜론을 사용하여 즉시 이름을 바꿀 수 있습니다.
// JS Destructuring Naming Collision Example: const name = 'Jamie Corkhill'; const person = { name: 'Alan Turing' }; // Rename `name` from `person` to `personName` after destructuring. const { name: personName } = person; console.log(name); // Jamie Corkhill <-- As expected. console.log(personName); // Alan Turing <-- Variable was renamed.마지막으로 이름을 변경하여 기본값을 설정할 수도 있습니다.
const name = 'Jamie Corkhill'; const person = { location: 'New York City, United States' }; const { name: personName = 'Anonymous', location } = person; console.log(name); // Jamie Corkhill console.log(personName); // Anonymous console.log(location); // New York City, United States 보시다시피, 이 경우 사람의 name ( person.name )은 person 이름으로 personName 존재하지 않는 경우 Anonymous 의 기본값으로 설정됩니다.
물론 함수 서명에서도 동일한 작업을 수행할 수 있습니다.
const personOne = { name: 'User One', password: 'BCrypt Hash' }; const personTwo = { password: 'BCrypt Hash' }; const createUser = ({ name: personName = 'Anonymous', password }) => { if (!password) throw new Error('InvalidArgumentException'); console.log(personName); console.log(password); return { id: Math.random().toString(36).substring(2, 15) + Math.random().toString(36).substring(2, 15), name: personName, password: password // <-- We'll discuss this next. }; } createUser(personOne); // User One, BCrypt Hash createUser(personTwo); // Anonymous, BCrypt HashES6 객체 속기
다음과 같은 공장이 있다고 가정합니다. (공장에 대해서는 나중에 다루겠습니다)
const createPersonFactory = (name, location, position) => ({ name: name, location: location, position: position }); 다음과 같이 이 팩토리를 사용하여 person 개체를 만들 수 있습니다. 또한 팩토리가 암시적으로 객체를 반환한다는 점에 유의하십시오. Arrow 함수의 괄호 주위에 괄호가 있는 것을 알 수 있습니다.
const person = createPersonFactory('Jamie', 'Texas', 'Developer'); console.log(person); // { ... } 그것이 우리가 ES5 Object Literal Syntax에서 이미 알고 있는 것입니다. 그러나 팩토리 함수에서 각 속성의 값은 속성 식별자(키) 자체와 동일한 이름입니다. 즉, location: location 또는 name: name 입니다. 그것은 JS 개발자들에게 꽤 흔한 일이라는 것이 밝혀졌습니다.
ES6의 약식 구문을 사용하여 다음과 같이 팩토리를 다시 작성하여 동일한 결과를 얻을 수 있습니다.
const createPersonFactory = (name, location, position) => ({ name, location, position }); const person = createPersonFactory('Jamie', 'Texas', 'Developer'); console.log(person);출력 생성:
{ name: 'Jamie', location: 'Texas', position: 'Developer' }생성하고자 하는 객체가 변수를 기반으로 동적으로 생성되는 경우에만 이 약칭을 사용할 수 있다는 점을 인식하는 것이 중요합니다. 여기서 변수 이름은 변수를 할당하려는 속성의 이름과 동일합니다.
이 동일한 구문은 객체 값에 대해 작동합니다.
const createPersonFactory = (name, location, position, extra) => ({ name, location, position, extra // <- right here. }); const extra = { interests: [ 'Mathematics', 'Quantum Mechanics', 'Spacecraft Launch Systems' ], favoriteLanguages: [ 'JavaScript', 'C#' ] }; const person = createPersonFactory('Jamie', 'Texas', 'Developer', extra); console.log(person);출력 생성:
{ name: 'Jamie', location: 'Texas', position: 'Developer', extra: { interests: [ 'Mathematics', 'Quantum Mechanics', 'Spacecraft Launch Systems' ], favoriteLanguages: [ 'JavaScript', 'C#' ] } }마지막 예로서 이것은 객체 리터럴에서도 작동합니다:
const id = '314159265358979'; const name = 'Archimedes of Syracuse'; const location = 'Syracuse'; const greatMathematician = { id, name, location };ES6 스프레드 연산자(…)
Spread Operator를 사용하면 다양한 작업을 수행할 수 있으며 그 중 일부는 여기에서 설명합니다.
첫째, 한 객체에서 다른 객체로 속성을 분산할 수 있습니다.
const myObjOne = { a: 'a', b: 'b' }; const myObjTwo = { ...myObjOne }: 이것은 myObjTwo 가 이제 { a: 'a', b: 'b' } 가 되도록 myObjTwo 의 모든 속성을 myObjOne 에 배치하는 효과가 있습니다. 이 방법을 사용하여 이전 속성을 재정의할 수 있습니다. 사용자가 계정을 업데이트하려고 한다고 가정합니다.
const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */const user = { name: 'John Doe', email: '[email protected]', password: ' ', bio: 'Lorem ipsum' }; const updates = { password: ' ', bio: 'Ipsum lorem', email: '[email protected]' }; const updatedUser = { ...user, // <- original ...updates // <- updates }; console.log(updatedUser); /* { name: 'John Doe', email: '[email protected]', // Updated password: ' ', // Updated bio: 'Ipsum lorem' } */
배열에서도 동일한 작업을 수행할 수 있습니다.
const apollo13Astronauts = ['Jim', 'Jack', 'Fred']; const apollo11Astronauts = ['Neil', 'Buz', 'Michael']; const unionOfAstronauts = [...apollo13Astronauts, ...apollo11Astronauts]; console.log(unionOfAstronauts); // ['Jim', 'Jack', 'Fred', 'Neil', 'Buz, 'Michael'];배열을 새 배열로 분산하여 두 집합(배열)의 합집합을 만들었습니다.
Rest/Spread 연산자에는 더 많은 것이 있지만 이 기사의 범위를 벗어납니다. 예를 들어, 함수에 대한 여러 인수를 얻는 데 사용할 수 있습니다. 더 자세히 알고 싶다면 여기에서 MDN 문서를 보십시오.
ES6 비동기/대기
Async/Await는 약속 연결의 고통을 덜어주는 구문입니다.
await 예약 키워드를 사용하면 약속이 확정될 때까지 "대기"할 수 있지만 async 키워드로 표시된 함수에서만 사용할 수 있습니다. 약속을 반환하는 함수가 있다고 가정합니다. 새로운 async 함수에서 .then 및 .catch 를 사용하는 대신 해당 약속의 결과를 await 수 있습니다.
// Returns a promise. const myFunctionThatReturnsAPromise = () => { return new Promise((resolve, reject) => { setTimeout(() => resolve('Hello'), 3000); }); } const myAsyncFunction = async () => { const promiseResolutionResult = await myFunctionThatReturnsAPromise(); console.log(promiseResolutionResult); }; // Writes the log statement after three seconds. myAsyncFunction(); 여기서 주의할 사항이 몇 가지 있습니다. async 함수에서 await 를 사용하면 해결된 값만 왼쪽 변수에 들어갑니다. 함수가 거부하면 잠시 후에 살펴보겠지만 우리가 잡아야 하는 오류입니다. 또한 async 로 표시된 모든 함수는 기본적으로 약속을 반환합니다.
두 개의 API 호출을 수행해야 한다고 가정해 보겠습니다. 하나는 전자의 응답입니다. Promise와 Promise Chaining을 사용하면 다음과 같이 할 수 있습니다.
const makeAPICall = route => new Promise((resolve, reject) => { console.log(route) resolve(route); }); const main = () => { makeAPICall('/whatever') .then(response => makeAPICall(response + ' second call')) .then(response => console.log(response + ' logged')) .catch(err => console.error(err)) }; main(); // Result: /* /whatever /whatever second call /whatever second call logged */ 여기서 일어나는 일은 /whatever 에 전달되는 makeAPICall 을 먼저 호출하는 것입니다. 이 호출은 처음으로 기록됩니다. 약속은 그 가치로 해결됩니다. 그런 다음 우리는 makeAPICall 을 다시 호출하여 기록되는 /whatever second call 을 전달하고 다시 약속이 새 값으로 해결됩니다. 마지막으로, 우리는 약속이 해결된 /whatever second call 새로운 값을 가져와서 최종 로그에 직접 logged 하고 마지막에 on을 추가합니다. 이것이 이해가 되지 않는다면, 당신은 promise chaining을 살펴보아야 합니다.
async / await 를 사용하여 다음과 같이 리팩토링할 수 있습니다.
const main = async () => { const resultOne = await makeAPICall('/whatever'); const resultTwo = await makeAPICall(resultOne + ' second call'); console.log(resultTwo + ' logged'); }; 다음은 일어날 일입니다. 전체 함수는 makeAPICall 에 대한 첫 번째 호출의 약속이 해결될 때까지 첫 번째 await 문에서 실행을 중지하고 해결 시 해결된 값은 resultOne 에 배치됩니다. 그런 일이 발생하면 함수는 두 번째 await 문으로 이동하여 약속이 정착되는 동안 바로 거기에서 다시 일시 중지합니다. 약속이 해결되면 해결 결과가 resultTwo 에 배치됩니다. 함수 실행에 대한 아이디어가 차단되는 것처럼 들리더라도 두려워하지 마십시오. 여전히 비동기식이므로 잠시 후에 그 이유에 대해 설명하겠습니다.
이것은 단지 "행복한" 경로를 나타냅니다. 약속 중 하나가 거부되는 경우 try/catch를 사용하여 이를 잡을 수 있습니다. 왜냐하면 약속이 거부되면 오류가 발생하기 때문입니다. 이는 약속이 거부된 모든 오류가 될 것이기 때문입니다.
const main = async () => { try { const resultOne = await makeAPICall('/whatever'); const resultTwo = await makeAPICall(resultOne + ' second call'); console.log(resultTwo + ' logged'); } catch (e) { console.log(e) } }; 앞서 말했듯이 async 로 선언된 모든 함수는 약속을 반환합니다. 따라서 다른 함수에서 비동기 함수를 호출하려면 일반 promise를 사용하거나 호출 함수 async 를 선언한 경우 await 를 사용할 수 있습니다. 그러나 최상위 코드에서 async 함수를 호출하고 결과를 기다리려면 .then 및 .catch 를 사용해야 합니다.
예를 들어:
const returnNumberOne = async () => 1; returnNumberOne().then(value => console.log(value)); // 1또는 IIFE(즉시 호출 함수 표현식)를 사용할 수 있습니다.
(async () => { const value = await returnNumberOne(); console.log(value); // 1 })(); async 함수에서 await 를 사용하는 경우 함수 실행은 약속이 해결될 때까지 해당 await 문에서 중지됩니다. 그러나 다른 모든 기능은 실행을 계속할 수 있으므로 추가 CPU 리소스가 할당되지 않으며 스레드가 차단되지도 않습니다. 다시 한 번 말씀드리지만 특정 시간에 해당 기능의 작업은 약속이 확정될 때까지 중지되지만 다른 모든 기능은 자유롭게 실행할 수 있습니다. HTTP 웹 서버를 고려하십시오. 요청별로 모든 기능은 요청이 생성될 때 모든 사용자에 대해 동시에 자유롭게 실행할 수 있습니다. async/await 구문은 작업이 동기 적이고 차단 된다는 환상 을 제공할 뿐입니다. 작업하기가 더 쉬울 것을 약속하지만 모든 것이 훌륭하고 비동기적으로 유지됩니다.
이것이 async / await 의 전부는 아니지만 기본 원칙을 이해하는 데 도움이 될 것입니다.
클래식 OOP 공장
이제 JavaScript 세계를 떠나 Java 세계로 들어갑니다. 객체 생성 프로세스(이 경우 클래스 인스턴스, 다시 Java)가 상당히 복잡하거나 일련의 매개변수를 기반으로 다른 객체를 생성하려는 경우가 있습니다. 다른 오류 객체를 생성하는 함수를 예로 들 수 있습니다. 팩토리는 객체 지향 프로그래밍에서 일반적인 디자인 패턴이며 기본적으로 객체를 생성하는 기능입니다. 이를 탐색하기 위해 JavaScript에서 Java의 세계로 이동해 보겠습니다. 이것은 정적으로 유형이 지정된 언어 배경인 Classical OOP(즉, 프로토타입이 아님)에서 온 개발자에게 의미가 있습니다. 그러한 개발자가 아닌 경우 이 섹션을 건너뛰어도 됩니다. 이것은 작은 편차이므로 여기를 따르면 JavaScript의 흐름이 중단되면 다시 이 섹션을 건너뛰십시오.
일반적인 생성 패턴인 팩토리 패턴을 사용하면 해당 생성을 수행하는 데 필요한 비즈니스 로직을 노출하지 않고도 객체를 생성할 수 있습니다.
우리가 n차원의 원시 형태를 시각화할 수 있는 프로그램을 작성하고 있다고 가정합니다. 예를 들어 큐브를 제공하면 2D 큐브(정사각형), 3D 큐브(큐브) 및 4D 큐브(Tesseract 또는 Hypercube)가 표시됩니다. 다음은 Java에서 실제 그리기 부분을 제외하고 간단하게 수행할 수 있는 방법입니다.
// Main.java // Defining an interface for the shape (can be used as a base type) interface IShape { void draw(); } // Implementing the interface for 2-dimensions: class TwoDimensions implements IShape { @Override public void draw() { System.out.println("Drawing a shape in 2D."); } } // Implementing the interface for 3-dimensions: class ThreeDimensions implements IShape { @Override public void draw() { System.out.println("Drawing a shape in 3D."); } } // Implementing the interface for 4-dimensions: class FourDimensions implements IShape { @Override public void draw() { System.out.println("Drawing a shape in 4D."); } } // Handles object creation class ShapeFactory { // Factory method (notice return type is the base interface) public IShape createShape(int dimensions) { switch(dimensions) { case 2: return new TwoDimensions(); case 3: return new ThreeDimensions(); case 4: return new FourDimensions(); default: throw new IllegalArgumentException("Invalid dimension."); } } } // Main class and entry point. public class Main { public static void main(String[] args) throws Exception { ShapeFactory shapeFactory = new ShapeFactory(); IShape fourDimensions = shapeFactory.createShape(4); fourDimensions.draw(); // Drawing a shape in 4D. } } 보시다시피 모양을 그리는 방법을 지정하는 인터페이스를 정의합니다. 다른 클래스가 인터페이스를 구현하도록 함으로써 모든 모양을 그릴 수 있음을 보장할 수 있습니다(모든 모양에는 인터페이스 정의에 따라 재정의 가능한 draw 메서드가 있어야 하기 때문입니다). 이 모양이 보이는 차원에 따라 다르게 그려지는 것을 고려하여 n차원 렌더링을 시뮬레이션하는 GPU 집약적 작업을 수행하기 위해 인터페이스를 구현하는 도우미 클래스를 정의합니다. ShapeFactory 는 올바른 클래스를 인스턴스화하는 작업을 수행합니다. createShape 메서드는 팩토리이며 위의 정의와 같이 클래스의 개체를 반환하는 메서드입니다. IShape 인터페이스가 모든 모양의 기본 유형이기 때문에 createShape 의 반환 유형은 IShape 인터페이스입니다( draw 메서드가 있기 때문에).
이 Java 예제는 매우 사소하지만 개체를 생성하기 위한 설정이 그렇게 간단하지 않을 수 있는 더 큰 응용 프로그램에서 얼마나 유용한지 쉽게 알 수 있습니다. 그 예로 비디오 게임을 들 수 있습니다. 사용자가 다른 적들에서 살아남아야 한다고 가정합니다. 추상 클래스와 인터페이스는 모든 적에게 사용할 수 있는 핵심 기능(및 재정의할 수 있는 메서드)을 정의하는 데 사용될 수 있으며, 아마도 위임 패턴(Gang of Four가 제안한 상속보다 구성을 선호하여 확장에 얽매이지 않도록 단일 기본 클래스 및 테스트/모킹/DI를 더 쉽게 만들기 위해). 다른 방식으로 인스턴스화된 적 객체의 경우 인터페이스는 일반 인터페이스 유형에 의존하면서 팩토리 객체 생성을 허용합니다. 적이 동적으로 생성된 경우 이는 매우 관련이 있습니다.
또 다른 예는 빌더 기능입니다. Delegation Pattern을 활용하여 인터페이스를 존중하는 다른 클래스에 대한 클래스 위임 작업을 수행한다고 가정합니다. 클래스에 정적 build 메서드를 배치하여 자체 인스턴스를 생성하도록 할 수 있습니다(종속성 주입 컨테이너/프레임워크를 사용하지 않는다고 가정). 각 setter를 호출하는 대신 다음을 수행할 수 있습니다.
public class User { private IMessagingService msgService; private String name; private int age; public User(String name, int age, IMessagingService msgService) { this.name = name; this.age = age; this.msgService = msgService; } public static User build(String name, int age) { return new User(name, age, new SomeMessageService()); } } 델리게이션 패턴에 익숙하지 않다면 이후 기사에서 설명하겠습니다. 기본적으로 구성을 통해 객체 모델링 측면에서 "is-a" 대신 "has-a" 관계를 생성합니다. 상속으로 얻을 수 있는 것과 같은 관계입니다. Mammal 클래스와 Dog 클래스가 있고 Dog 가 Mammal 을 확장하면 Dog 는 Mammal 입니다. 반면에 Bark 클래스가 있고 Bark 인스턴스를 Dog 생성자에 전달했다면 Dog 에는 Bark 가 있습니다. 상상할 수 있듯이 이것은 특히 단위 테스트를 더 쉽게 만듭니다. 왜냐하면 모의가 테스트 환경에서 인터페이스 계약을 준수하는 한 모의를 주입하고 모의에 대한 사실을 주장할 수 있기 때문입니다.
위의 static "빌드" 팩토리 메소드는 단순히 User 의 새 객체를 생성하고 구체적인 MessageService 를 전달합니다. 이것이 위의 정의에서 어떻게 따르는지 주목하세요. 클래스의 객체를 생성하기 위한 비즈니스 로직을 노출하지 않거나, 이 경우에는, 메시징 서비스 생성을 팩토리 호출자에게 노출하지 않습니다.
다시 말하지만, 이것은 반드시 실제 세계에서 작업을 수행하는 방법은 아니지만 팩토리 함수/메서드에 대한 아이디어를 아주 잘 나타냅니다. 예를 들어 의존성 주입 컨테이너를 대신 사용할 수 있습니다. 이제 JavaScript로 돌아갑니다.
익스프레스로 시작하기
Express는 HTTP 웹 서버를 생성할 수 있는 노드용 웹 애플리케이션 프레임워크(NPM 모듈을 통해 사용 가능)입니다. Express가 이를 수행하는 유일한 프레임워크가 아니며(Koa, Fastify 등이 있음) 이전 기사에서 보았듯이 Node는 Express 없이 독립 실행형 엔터티로 작동할 수 있습니다. (Express는 Node용으로 설계된 모듈일 뿐입니다. Express는 웹 서버에서 널리 사용되지만 Express는 노드 없이도 많은 작업을 수행할 수 있습니다.)
다시 말하지만, 아주 중요한 구분을 하겠습니다. Node/JavaScript와 Express 사이 에는 이분법이 있습니다. JavaScript를 실행하는 런타임/환경인 Node는 React Native 앱, 데스크톱 앱, 명령줄 도구 등을 빌드할 수 있도록 허용하는 등 많은 작업을 수행할 수 있습니다. Express는 Node의 저수준 네트워크 및 HTTP API를 처리하는 것과 달리 웹 서버를 구축하기 위한 Node/JS. 웹 서버를 구축하기 위해 Express가 필요하지 않습니다.
이 섹션을 시작하기 전에 HTTP 및 HTTP 요청(GET, POST 등)에 익숙하지 않다면 위에 링크된 내 이전 기사의 해당 섹션을 읽는 것이 좋습니다.
Express를 사용하여 HTTP 요청이 만들어질 수 있는 다양한 경로와 해당 경로에 대한 요청이 있을 때 실행되는 관련 끝점(콜백 함수)을 설정할 것입니다. 경로와 끝점이 현재 무의미하다고 걱정하지 마십시오. 나중에 설명하겠습니다.
다른 기사와 달리 전체 코드베이스를 하나의 스니펫으로 덤프한 다음 나중에 설명하는 대신 소스 코드를 한 줄씩 작성하는 방식을 취하겠습니다. 먼저 터미널을 열고(Windows의 Git Bash 상단에서 Terminus를 사용하고 있습니다. Linux 하위 시스템을 설정하지 않고 Bash Shell을 원하는 Windows 사용자에게 좋은 옵션입니다), 프로젝트의 상용구를 설정하고 엽니다. 비주얼 스튜디오 코드에서.
mkdir server && cd server touch server.js npm init -y npm install express code . server.js 파일 내에서 require() 함수를 사용하여 express 를 요구하는 것으로 시작하겠습니다.
const express = require('express'); require('express') 는 노드에게 나가서 우리가 이전에 설치한 Express 모듈을 가져오도록 지시합니다. 이 모듈은 현재 node_modules 폴더 안에 있습니다( npm install 이 하는 일입니다. node_modules 폴더를 만들고 거기에 모듈과 종속성을 넣습니다) 관습에 따라, 그리고 Express를 다룰 때 우리는 require('express') express 의 반환 결과를 보유하는 변수를 호출합니다.
우리가 express 라고 부르는 이 반환된 결과는 실제로 함수입니다. Express 앱을 만들고 경로를 설정하기 위해 호출해야 하는 함수입니다. Again, by convention, we call this app — app being the return result of express() — that is, the return result of calling the function that has the name express as express() .
const express = require('express'); const app = express(); // Note that the above variable names are the convention, but not required. // An example such as that below could also be used. const foo = require('express'); const bar = foo(); // Note also that the node module we installed is called express. The line const app = express(); simply puts a new Express Application inside of the app variable. It calls a function named express (the return result of require('express') ) and stores its return result in a constant named app . If you come from an object-oriented programming background, consider this equivalent to instantiating a new object of a class, where app would be the object and where express() would call the constructor function of the express class. Remember, JavaScript allows us to store functions in variables — functions are first-class citizens. The express variable, then, is nothing more than a mere function. It's provided to us by the developers of Express.
I apologize in advance if I'm taking a very long time to discuss what is actually very basic, but the above, although primitive, confused me quite a lot when I was first learning back-end development with Node.
Inside the Express source code, which is open-source on GitHub, the variable we called express is a function entitled createApplication , which, when invoked, performs the work necessary to create an Express Application:
A snippet of Express source code:
exports = module.exports = createApplication; /* * Create an express application */ // This is the function we are storing in the express variable. (- Jamie) function createApplication() { // This is what I mean by "Express App" (- Jamie) var app = function(req, res, next) { app.handle(req, res, next); }; mixin(app, EventEmitter.prototype, false); mixin(app, proto, false); // expose the prototype that will get set on requests app.request = Object.create(req, { app: { configurable: true, enumerable: true, writable: true, value: app } }) // expose the prototype that will get set on responses app.response = Object.create(res, { app: { configurable: true, enumerable: true, writable: true, value: app } }) app.init(); // See - `app` gets returned. (- Jamie) return app; }GitHub: https://github.com/expressjs/express/blob/master/lib/express.js
With that short deviation complete, let's continue setting up Express. Thus far, we have required the module and set up our app variable.
const express = require('express'); const app = express(); From here, we have to tell Express to listen on a port. Any HTTP Requests made to the URL and Port upon which our application is listening will be handled by Express. We do that by calling app.listen(...) , passing to it the port and a callback function which gets called when the server starts running:
const PORT = 3000; app.listen(PORT, () => console.log(`Server is up on port {PORT}.`)); We notate the PORT variable in capital by convention, for it is a constant variable that will never change. You could do that with all variables that you declare const , but that would look messy. It's up to the developer or development team to decide on notation, so we'll use the above sparsely. I use const everywhere as a method of “defensive coding” — that is, if I know that a variable is never going to change then I might as well just declare it const . Since I define everything const , I make the distinction between what variables should remain the same on a per-request basis and what variables are true actual global constants.
Here is what we have thus far:
const express = require('express'); const app = express(); const PORT = 3000; // We will build our API here. // ... // Binding our application to port 3000. app.listen(PORT, () => { console.log(`Server is up on port ${PORT}.`); });Let's test this to see if the server starts running on port 3000.
I'll open a terminal and navigate to our project's root directory. I'll then run node server/server.js . Note that this assumes you have Node already installed on your system (You can check with node -v ).
If everything works, you should see the following in the terminal:
Server is up on port 3000.
Go ahead and hit Ctrl + C to bring the server back down.
If this doesn't work for you, or if you see an error such as EADDRINUSE , then it means you may have a service already running on port 3000. Pick another port number, like 3001, 3002, 5000, 8000, etc. Be aware, lower number ports are reserved and there is an upper bound of 65535.
At this point, it's worth taking another small deviation as to understand servers and ports in the context of computer networking. We'll return to Express in a moment. I take this approach, rather than introducing servers and ports first, for the purpose of relevance. That is, it is difficult to learn a concept if you fail to see its applicability. In this way, you are already aware of the use case for ports and servers with Express, so the learning experience will be more pleasurable.
A Brief Look At Servers And Ports
A server is simply a computer or computer program that provides some sort of “functionality” to the clients that talk to it. More generally, it's a device, usually connected to the Internet, that handles connections in a pre-defined manner. In our case, that “pre-defined manner” will be HTTP or the HyperText Transfer Protocol. Servers that use the HTTP Protocol are called Web Servers.
When building an application, the server is a critical component of the “client-server model”, for it permits the sharing and syncing of data (generally via databases or file systems) across devices. It's a cross-platform approach, in a way, for the SDKs of platforms against which you may want to code — be they web, mobile, or desktop — all provide methods (APIs) to interact with a server over HTTP or TCP/UDP Sockets. It's important to make a distinction here — by APIs, I mean programming language constructs to talk to a server, like XMLHttpRequest or the Fetch API in JavaScript, or HttpUrlConnection in Java, or even HttpClient in C#/.NET. This is different from the kind of REST API we'll be building in this article to perform CRUD Operations on a database.
To talk about ports, it's important to understand how clients connect to a server. A client requires the IP Address of the server and the Port Number of our specific service on that server. An IP Address, or Internet Protocol Address, is just an address that uniquely identifies a device on a network. Public and private IPs exist, with private addresses commonly used behind a router or Network Address Translator on a local network. You might see private IP Addresses of the form 192.168.XXX.XXX or 10.0.XXX.XXX . When articulating an IP Address, decimals are called “dots”. So 192.168.0.1 (a common router IP Addr.) might be pronounced, “one nine two dot one six eight dot zero dot one”. (By the way, if you're ever in a hotel and your phone/laptop won't direct you to the AP captive portal, try typing 192.168.0.1 or 192.168.1.1 or similar directly into Chrome).
For simplicity, and since this is not an article about the complexities of computer networking, assume that an IP Address is equivalent to a house address, allowing you to uniquely identify a house (where a house is analogous to a server, client, or network device) in a neighborhood. One neighborhood is one network. Put together all of the neighborhoods in the United States, and you have the public Internet. (This is a basic view, and there are many more complexities — firewalls, NATs, ISP Tiers (Tier One, Tier Two, and Tier Three), fiber optics and fiber optic backbones, packet switches, hops, hubs, etc., subnet masks, etc., to name just a few — in the real networking world.) The traceroute Unix command can provide more insight into the above, displaying the path (and associated latency) that packets take through a network as a series of “hops”.
포트 번호는 서버에서 실행 중인 특정 서비스를 식별합니다. 장치에 대한 원격 셸 액세스를 허용하는 SSH 또는 보안 셸은 일반적으로 포트 22에서 실행됩니다. FTP 또는 파일 전송 프로토콜(예: FTP 클라이언트와 함께 고정 자산을 서버로 전송하는 데 사용)은 일반적으로 포트 21. 그러면 포트는 위의 비유에서 각 집 내부의 특정 방이라고 말할 수 있습니다. 집의 방은 잠자는 침실, 음식 준비를 위한 주방, 음식을 소비하기 위한 식당 등 다양한 용도로 만들어졌기 때문입니다. 음식 등은 포트와 마찬가지로 특정 서비스를 수행하는 프로그램에 해당합니다. 우리의 경우 웹 서버는 일반적으로 포트 80에서 실행되지만 다른 서비스에서 사용하지 않는 한 원하는 포트 번호를 자유롭게 지정할 수 있습니다(충돌할 수 없음).
웹사이트에 접속하기 위해서는 해당 사이트의 IP 주소가 필요합니다. 그럼에도 불구하고 우리는 일반적으로 URL을 통해 웹사이트에 액세스합니다. 뒤에서 DNS 또는 도메인 이름 서버는 해당 URL을 IP 주소로 변환하여 브라우저가 서버에 GET 요청을 하고 HTML을 가져와 화면에 렌더링할 수 있도록 합니다. 8.8.8.8 은 Google의 공개 DNS 서버 중 하나의 주소입니다. 원격 DNS 서버를 통해 호스트 이름을 IP 주소로 확인하는 데 시간이 걸릴 것이라고 상상할 수 있으며, 당신이 옳을 것입니다. 대기 시간을 줄이기 위해 운영 체제에는 DNS 조회 정보를 저장하는 임시 데이터베이스인 DNS 캐시가 있으므로 조회가 발생해야 하는 빈도가 줄어듭니다. DNS 확인자 캐시는 Windows에서 ipconfig /displaydns CMD 명령을 사용하여 볼 수 있고 ipconfig /flushdns 명령을 통해 제거할 수 있습니다.
Unix 서버에서 80과 같은 보다 일반적인 낮은 번호의 포트에는 루트 수준(Windows 배경에서 온 경우 에스컬레이션 됨) 권한이 필요합니다. 이러한 이유로 개발 작업에 포트 3000을 사용하지만 프로덕션 환경에 배포할 때 서버에서 포트 번호(사용 가능한 모든 것)를 선택할 수 있습니다.
마지막으로 Google 크롬의 검색 창에 직접 IP 주소를 입력할 수 있으므로 DNS 확인 메커니즘을 우회할 수 있습니다. 예를 들어 216.58.194.36 을 입력하면 Google.com으로 이동합니다. 개발 환경에서 자체 컴퓨터를 개발 서버로 사용할 때 localhost 및 포트 3000을 사용합니다. 주소는 hostname:port 형식이므로 서버는 localhost:3000 에 있습니다. Localhost 또는 127.0.0.1 은 루프백 주소이며 "이 컴퓨터"의 주소를 의미합니다. 호스트 이름이고 IPv4 주소는 127.0.0.1 로 확인됩니다. 지금 컴퓨터에서 localhost에 ping을 시도하십시오. IPv6 루프백 주소인 ::1 back 또는 IPv4 루프백 주소인 127.0.0.1 back을 얻을 수 있습니다. IPv4 및 IPv6은 서로 다른 표준과 관련된 두 가지 서로 다른 IP 주소 형식입니다. 일부 IPv6 주소는 IPv4로 변환할 수 있지만 전부는 아닙니다.
익스프레스로 돌아가기
이전 기사인 Get Started With Node: An Introduction to APIs, HTTP and ES6+ JavaScript에서 HTTP 요청, 동사 및 상태 코드에 대해 언급했습니다. 프로토콜에 대한 일반적인 이해가 없는 경우 해당 부분의 "HTTP 및 HTTP 요청" 섹션으로 자유롭게 이동하십시오.
Express에 대한 느낌을 얻기 위해 데이터베이스에서 수행할 4가지 기본 작업인 Create, Read, Update 및 Delete(집합적으로 CRUD라고 함)에 대한 끝점을 설정하기만 하면 됩니다.
우리는 URL의 경로를 통해 엔드포인트에 액세스한다는 것을 기억하십시오. 즉, "경로"와 "끝점"이라는 단어는 일반적으로 같은 의미로 사용되지만 끝점 은 기술적으로 일부 서버 측 작업을 수행하는 프로그래밍 언어 기능(예: ES6 Arrow Functions)이고 경로 는 끝점이 뒤에 있는 것입니다. 의 . 우리는 이러한 끝점을 콜백 함수로 지정합니다. 이 함수는 클라이언트에서 끝점이 있는 경로 로 적절한 요청이 있을 때 Express가 실행합니다. 기능을 수행하는 것은 끝점이며 경로는 끝점에 액세스하는 데 사용되는 이름이라는 것을 인식하면 위의 내용을 기억할 수 있습니다. 우리가 보게 되겠지만, 동일한 경로는 다른 HTTP 동사를 사용하여 여러 끝점과 연결될 수 있습니다(다형성이 있는 고전적인 OOP 배경에서 온 경우 메서드 오버로딩과 유사).
클라이언트가 서버에 요청할 수 있도록 허용하여 REST(REpresentational State Transfer) 아키텍처를 따릅니다. 이것은 결국 REST 또는 RESTful API입니다. 특정 경로 에 대한 특정 요청 은 특정 작업 을 수행하는 특정 엔드포인트 를 발생시킵니다. 엔드포인트가 수행할 수 있는 이러한 "일"의 예로는 데이터베이스에 새 데이터 추가, 데이터 제거, 데이터 업데이트 등이 있습니다.
Express는 명시적으로 요청 방법(GET, POST 등)과 경로를 알려주기 때문에 실행할 끝점을 알고 있습니다. 위의 특정 조합에 대해 실행할 함수를 정의하고 클라이언트가 다음을 지정하여 요청합니다. 경로와 방법. 이것을 더 간단하게 말하면 Node를 사용하여 Express에 알려줄 것입니다. 상황이 더 복잡해질 수 있습니다. “누군가 이 경로에 대해 GET 요청을 했지만 요청 헤더에 유효한 Authorization Bearer Token을 보내지 않으면 HTTP 401 Unauthorized 로 응답하십시오. 그들이 유효한 베어러 토큰을 소유하고 있다면 엔드포인트를 실행하여 찾고 있던 보호된 리소스를 보내주십시오. 감사합니다. 좋은 하루 보내세요.” 실제로, 프로그래밍 언어가 모호성을 누설하지 않고 높은 수준이 될 수 있다면 좋겠지만 그럼에도 불구하고 기본 개념을 보여줍니다.
끝점은 어떤 면에서 경로 뒤에 있다는 것을 기억하십시오. 따라서 클라이언트는 요청 헤더에서 Express가 수행할 작업을 파악할 수 있도록 사용하려는 방법을 제공해야 합니다. 요청은 서버에 연결할 때 클라이언트가 (요청 유형과 함께) 지정하는 특정 경로로 이루어지며, Express가 필요한 작업을 수행하고 Express가 콜백을 실행할 때 수행해야 하는 작업을 수행할 수 있습니다. . 그게 다야.
앞의 코드 예제에서 우리는 app 에서 사용할 수 있는 listen 함수를 호출하여 포트와 콜백을 전달했습니다. 기억한다면 app 자체는 express 변수를 함수로 호출한 결과(즉, express() )이고, express 변수는 node_modules 폴더에서 'express' 를 요구하여 반환 결과 이름을 지정한 것입니다. listen 이 app app 호출하여 HTTP 요청 끝점을 지정합니다. GET을 살펴보겠습니다.
app.get('/my-test-route', () => { // ... }); 첫 번째 매개변수는 string 이며 끝점이 있을 경로입니다. 콜백 함수는 끝점입니다. 다시 말하겠습니다. 콜백 함수(두 번째 매개변수) 는 HTTP GET 요청이 첫 번째 인수로 지정한 경로(이 경우 /my-test-route )에 대해 만들어질 때 실행되는 끝점입니다.
이제 Express로 더 이상 작업을 수행하기 전에 경로가 작동하는 방식을 알아야 합니다. 문자열로 지정하는 경로는 www.domain.com/the-route-we-chose-earlier-as-a-string 에 대한 요청을 통해 호출됩니다. 우리의 경우 도메인은 localhost:3000 입니다. 즉, 위의 콜백 함수를 실행하려면 localhost:3000/my-test-route 에 GET 요청을 해야 합니다. 위의 첫 번째 인수로 다른 문자열을 사용한 경우 URL은 JavaScript에서 지정한 것과 일치하도록 달라야 합니다.
이러한 것에 대해 이야기할 때 Glob Patterns에 대해 듣게 될 것입니다. 모든 API 경로가 localhost:3000/** Glob Pattern에 있다고 말할 수 있습니다. 여기서 ** 는 루트가 상위인 디렉토리 또는 하위 디렉토리(경로는 디렉토리가 아님 )를 의미하는 와일드카드입니다. 즉, 모든 것.
계속해서 해당 콜백 함수에 로그 문을 추가하여 다음과 같은 결과를 얻도록 하겠습니다.
// Getting the module from node_modules. const express = require('express'); // Creating our Express Application. const app = express(); // Defining the port we'll bind to. const PORT = 3000; // Defining a new endpoint behind the "/my-test-route" route. app.get('/my-test-route', () => { console.log('A GET Request was made to /my-test-route.'); }); // Binding the server to port 3000. app.listen(PORT, () => { console.log(`Server is up on port ${PORT}.`) }); 프로젝트의 루트 디렉토리에서 node server/server.js 를 실행하여 서버를 가동하고 실행할 것입니다. 이전과 마찬가지로 콘솔에 서버가 작동 중이라는 메시지가 표시되어야 합니다. 이제 서버가 실행 중이므로 브라우저를 열고 URL 표시줄에서 localhost:3000 을 방문합니다.
Cannot GET / 이라는 오류 메시지가 표시되어야 합니다. Chrome의 Windows에서 Ctrl + Shift + I을 눌러 개발자 콘솔을 봅니다. 거기에 404 (리소스를 찾을 수 없음)가 있는 것을 볼 수 있습니다. 그것은 말이 됩니다. 우리는 누군가가 localhost:3000/my-test-route 방문할 때 무엇을 해야 하는지 서버에 지시했습니다. 브라우저는 localhost:3000 에서 렌더링할 것이 없습니다(이는 슬래시가 있는 localhost:3000/ 과 동일함).
서버가 실행되고 있는 터미널 창을 보면 새로운 데이터가 없어야 합니다. 이제 브라우저의 URL 표시줄에서 localhost:3000/my-test-route 를 방문하십시오. Chrome 콘솔에서 동일한 오류 가 표시될 수 있지만(브라우저가 콘텐츠를 캐싱하고 여전히 렌더링할 HTML이 없기 때문에), 서버 프로세스가 실행 중인 터미널을 보면 콜백 함수가 실제로 실행되었음을 알 수 있습니다. 그리고 로그 메시지가 실제로 기록되었습니다.
Ctrl + C로 서버를 종료합니다.
이제 해당 경로에 대해 GET 요청이 있을 때 브라우저에 렌더링할 무언가를 제공하여 Cannot GET / 메시지를 잃을 수 있도록 합시다. 이전에 사용했던 app.get() 을 가져와서 콜백 함수에 두 개의 인수를 추가하겠습니다. 우리가 전달하는 콜백 함수는 배후에서 Express에 의해 호출되고 있으며 Express는 원하는 모든 인수를 추가할 수 있습니다. 실제로 2를 추가하고(기술적으로 3이지만 나중에 볼 것입니다) 둘 다 매우 중요하지만 지금은 첫 번째 것은 신경 쓰지 않습니다. 두 번째 인수는 res 라고 하며 response 의 약자이며 첫 번째 매개변수로 undefined 를 설정하여 액세스합니다.
app.get('/my-test-route', (undefined, res) => { console.log('A GET Request was made to /my-test-route.'); }); 다시 말하지만 우리는 원하는 대로 res 인수를 호출할 수 있지만 res 는 Express를 다룰 때 관례입니다. res 는 실제로 객체이며 클라이언트에 데이터를 다시 보내는 다른 방법이 존재합니다. 이 경우 브라우저에서 렌더링할 HTML을 다시 보내기 위해 res 에서 사용할 수 있는 send(...) 함수에 액세스하겠습니다. 그러나 HTML을 다시 보내는 것으로 제한되지 않으며 텍스트, JavaScript 개체, 스트림(스트림이 특히 아름답습니다) 등을 다시 보내도록 선택할 수 있습니다.
app.get('/my-test-route', (undefined, res) => { console.log('A GET Request was made to /my-test-route.'); res.send('<h1>Hello, World!</h1>'); }); 서버를 종료했다가 다시 불러온 다음 /my-test-route 경로에서 브라우저를 새로 고치면 HTML이 렌더링되는 것을 볼 수 있습니다.
Chrome 개발자 도구의 네트워크 탭을 사용하면 헤더와 관련된 이 GET 요청을 더 자세히 볼 수 있습니다.
이 시점에서 클라이언트가 요청한 후 전역적으로 실행될 수 있는 기능인 Express Middleware에 대해 배우기 시작하는 것이 좋습니다.
익스프레스 미들웨어
Express는 애플리케이션에 대한 사용자 정의 미들웨어를 정의하는 방법을 제공합니다. 실제로 Express Middleware의 의미는 Express Docs에 가장 잘 정의되어 있습니다.
미들웨어 기능은 애플리케이션의 요청-응답 주기에서 요청 객체(
req), 응답 객체(res) 및 다음 미들웨어 기능에 액세스할 수 있는 기능입니다. next 미들웨어 기능은 일반적으로next라는 변수로 표시됩니다.
미들웨어 기능은 다음 작업을 수행할 수 있습니다.
- 모든 코드를 실행합니다.
- 요청 및 응답 개체를 변경합니다.
- 요청-응답 주기를 종료합니다.
- 스택에서 다음 미들웨어 함수를 호출합니다.
즉, 미들웨어 기능은 우리(개발자)가 정의할 수 있는 사용자 정의 기능이며, Express가 요청을 수신할 때와 적절한 콜백 기능이 실행될 때 사이에 중개자 역할을 합니다. 예를 들어 요청이 있을 때마다 기록하는 log 기능을 만들 수 있습니다. 스택의 어디에 배치하느냐에 따라 엔드포인트가 실행된 후 이러한 미들웨어 기능이 실행되도록 선택할 수도 있습니다. 이는 나중에 보게 될 것입니다.
사용자 정의 미들웨어를 지정하려면 이를 함수로 정의하고 app.use(...) 에 전달해야 합니다.
const myMiddleware = (req, res, next) => { console.log(`Middleware has fired at time ${Date().now}`); next(); } app.use(myMiddleware); // This is the app variable returned from express().이제 우리는 다음을 갖게 되었습니다.
// Getting the module from node_modules. const express = require('express'); // Creating our Express Application. const app = express(); // Our middleware function. const myMiddleware = (req, res, next) => { console.log(`Middleware has fired at time ${Date().now}`); next(); } // Tell Express to use the middleware. app.use(myMiddleware); // Defining the port we'll bind to. const PORT = 3000; // Defining a new endpoint behind the "/my-test-route" route. app.get('/my-test-route', () => { console.log('A GET Request was made to /my-test-route.'); }); // Binding the server to port 3000. app.listen(PORT, () => { console.log(`Server is up on port ${PORT}.`) }); 브라우저를 통해 다시 요청하면 미들웨어 기능이 실행되고 타임스탬프를 기록하는 것을 볼 수 있습니다. 실험을 촉진하려면 next 함수에 대한 호출을 제거하고 어떤 일이 일어나는지 확인하십시오.
미들웨어 콜백 함수는 req , res 및 next 의 세 가지 인수로 호출됩니다. req 는 이전에 GET Handler를 구축할 때 건너뛴 매개변수이며 헤더, 사용자 정의 헤더, 매개변수 및 클라이언트에서 전송되었을 수 있는 본문(예: POST 요청으로 수행). 여기서 미들웨어에 대해 이야기하고 있다는 것을 알고 있지만 끝점과 미들웨어 함수는 모두 req 및 res 로 호출됩니다. req 및 res 는 클라이언트의 단일 요청 범위 내에서 미들웨어와 끝점 모두에서 동일합니다(둘 중 하나가 변경하지 않는 한). 즉, 예를 들어 미들웨어 기능을 사용하여 SQL 또는 NoSQL 주입을 수행하는 것을 목표로 할 수 있는 모든 문자를 제거한 다음 안전한 req 을 엔드포인트에 전달하여 데이터를 삭제할 수 있습니다.
res 는 앞서 보았듯이 몇 가지 다른 방법으로 클라이언트에 데이터를 다시 보낼 수 있도록 합니다.
next 는 스택이나 엔드포인트에서 다음 미들웨어 함수를 호출하기 위해 미들웨어가 작업을 완료했을 때 실행해야 하는 콜백 함수입니다. 미들웨어에서 실행하는 모든 비동기 함수의 then 블록에서 이것을 호출해야 합니다. 비동기 작업에 따라 catch 블록에서 호출할 수도 있고 원하지 않을 수도 있습니다. 즉, myMiddleware 함수는 클라이언트에서 요청이 이루어진 후 요청의 끝점 함수가 시작되기 전에 시작 됩니다. 이 코드를 실행하고 요청할 때 콘솔에서 A GET Request was made to... 지기 전에 Middleware has fired... 실행되었음을 확인해야 합니다. next() 를 호출하지 않으면 후자가 실행되지 않습니다. 요청에 대한 엔드포인트 기능이 실행되지 않습니다.
또한 이 함수를 익명으로 정의할 수도 있었습니다(내가 고수할 규칙).
app.use((req, res, next) => { console.log(`Middleware has fired at time ${Date().now}`); next(); }); JavaScript와 ES6을 처음 접하는 사람이라면 위의 방식이 즉시 이해가 되지 않는다면 아래 예제가 도움이 될 것입니다. 우리는 단순히 다른 콜백 함수( next )를 인수로 취하는 콜백 함수(익명 함수)를 정의하고 있습니다. 함수 인수를 취하는 함수를 Higher Order Function이라고 부릅니다. 아래 방법을 살펴보십시오. Express Source Code가 배후에서 어떻게 작동하는지에 대한 기본 예를 보여줍니다.
console.log('Suppose a request has just been made from the client.\n'); // This is what (it's not exactly) the code behind app.use() might look like. const use = callback => { // Simple log statement to see where we are. console.log('Inside use() - the "use" function has been called.'); // This depicts the termination of the middleware. const next = () => console.log('Terminating Middleware!\n'); // Suppose req and res are defined above (Express provides them). const req = res = null; // "callback" is the "middleware" function that is passed into "use". // "next" is the above function that pretends to stop the middleware. callback(req, res, next); }; // This is analogous to the middleware function we defined earlier. // It gets passed in as "callback" in the "use" function above. const myMiddleware = (req, res, next) => { console.log('Inside the myMiddleware function!'); next(); } // Here, we are actually calling "use()" to see everything work. use(myMiddleware); console.log('Moving on to actually handle the HTTP Request or the next middleware function.'); 먼저 myMiddleware 를 인수로 사용하는 use 를 호출합니다. myMiddleware 는 그 자체로 req , res 및 next 의 세 가지 인수를 취하는 함수입니다. use 내부에서 myMiddlware 가 호출되고 이 세 개의 인수가 전달됩니다. next 는 use 에 정의된 함수입니다. myMiddleware 는 use 메소드에서 callback 으로 정의됩니다. 이 예제에서 app 이라는 객체에 use 를 배치했다면 소켓이나 네트워크 연결 없이도 Express의 설정을 완전히 모방할 수 있었습니다.

이 경우 myMiddleware 와 callback 은 둘 다 함수를 인수로 사용하기 때문에 고차 함수입니다.
이 코드를 실행하면 다음 응답이 표시됩니다.
Suppose a request has just been made from the client. Inside use() - the "use" function has been called. Inside the middleware function! Terminating Middleware! Moving on to actually handle the HTTP Request or the next middleware function.동일한 결과를 얻기 위해 익명 함수를 사용할 수도 있었습니다.
console.log('Suppose a request has just been made from the client.'); // This is what (it's not exactly) the code behind app.use() might look like. const use = callback => { // Simple log statement to see where we are. console.log('Inside use() - the "use" function has been called.'); // This depicts the termination of the middlewear. const next = () => console.log('Terminating Middlewear!'); // Suppose req and res are defined above (Express provides them). const req = res = null; // "callback" is the function which is passed into "use". // "next" is the above function that pretends to stop the middlewear. callback(req, res, () => { console.log('Terminating Middlewear!'); }); }; // Here, we are actually calling "use()" to see everything work. use((req, res, next) => { console.log('Inside the middlewear function!'); next(); }); console.log('Moving on to actually handle the HTTP Request.');희망적으로 해결되었으므로 이제 실제 작업인 미들웨어 설정으로 돌아갈 수 있습니다.
문제는 일반적으로 HTTP 요청을 통해 데이터를 보내야 한다는 것입니다. URL 쿼리 매개변수 전송, 이전에 배운 req 객체에서 액세스할 수 있는 데이터 전송 등 몇 가지 옵션이 있습니다. 이 객체는 app.use() 뿐만 아니라 모든 엔드포인트에도 적용됩니다. 우리는 이전에 undefined 를 필러로 사용하여 HTML을 클라이언트에 다시 보내기 위해 res 에 집중할 수 있었지만 이제는 액세스해야 합니다.
app.use('/my-test-route', (req, res) => { // The req object contains client-defined data that is sent up. // The res object allows the server to send data back down. });HTTP POST 요청은 본문 객체를 서버로 보내야 할 수도 있습니다 . 클라이언트에 양식이 있고 사용자의 이름과 이메일을 사용하는 경우 요청 본문에서 해당 데이터를 서버로 보낼 것입니다.
클라이언트 측에서 어떻게 보이는지 살펴보겠습니다.
<!DOCTYPE html> <html> <body> <form action="https://localhost:3000/email-list" method="POST" > <input type="text" name="nameInput"> <input type="email" name="emailInput"> <input type="submit"> </form> </body> </html>서버 측에서:
app.post('/email-list', (req, res) => { // What do we now? // How do we access the values for the user's name and email? }); 사용자의 이름과 이메일에 액세스하려면 특정 유형의 미들웨어를 사용해야 합니다. 이것은 req 에서 사용 가능한 body 라는 객체에 데이터를 넣습니다. Body Parser는 이를 수행하는 인기 있는 방법으로 Express 개발자가 독립형 NPM 모듈로 사용할 수 있습니다. 이제 Express는 이를 수행하기 위해 자체 미들웨어와 함께 미리 패키지로 제공되며 다음과 같이 부를 것입니다.
app.use(express.urlencoded({ extended: true }));이제 다음을 수행할 수 있습니다.
app.post('/email-list', (req, res) => { console.log('User Name: ', req.body.nameInput); console.log('User Email: ', req.body.emailInput); }); 이 모든 작업은 클라이언트에서 전송된 사용자 정의 입력을 받아 req 의 body 개체에서 사용할 수 있도록 하는 것입니다. req.body 에는 이제 HTML의 input 태그 이름인 nameInput 및 emailInput 이 있습니다. 이제 이 클라이언트 정의 데이터는 위험한 것으로 간주되어야 하고(절대, 절대 클라이언트를 신뢰하지 않음) 삭제해야 하지만 나중에 다룰 것입니다.
express에서 제공하는 또 다른 유형의 미들웨어는 express.json() 입니다. express.json 은 클라이언트의 요청으로 전송된 모든 JSON 페이로드를 req.body 로 패키징하는 데 사용되는 반면, express.urlencoded 는 문자열, 배열 또는 기타 URL 인코딩 데이터와 함께 들어오는 모든 요청을 express.urlencoded 로 req.body 합니다. 간단히 말해서 둘 다 req.body 를 조작하지만 .json() 은 JSON 페이로드용이고 .urlencoded() 는 특히 POST 쿼리 매개변수용입니다.
이것을 말하는 또 다른 방법은 Content-Type: application/json 헤더가 있는 수신 요청(예: fetch API로 POST 본문 지정)은 express.json() 에 의해 처리되는 반면 헤더가 Content-Type: application/x-www-form-urlencoded 요청은 Content-Type: application/x-www-form-urlencoded (예: HTML Forms)는 express.urlencoded() 로 처리됩니다. 이제 이해가 되었으면 합니다.
MongoDB에 대한 CRUD 경로 시작
참고 : 이 기사에서 PATCH 요청을 수행할 때 JSONPatch RFC 사양을 따르지 않을 것입니다. 이 문제는 이 시리즈의 다음 기사에서 수정할 것입니다.
app 에서 관련 함수를 호출하여 각 엔드포인트를 지정하고 요청 및 응답 객체가 포함된 콜백 함수와 경로를 전달하여 각 엔드포인트를 지정한다는 점을 이해하면 Bookshelf API에 대한 CRUD 경로 정의를 시작할 수 있습니다. 사실, 그리고 이것이 입문용 기사라는 점을 고려할 때 저는 HTTP 및 REST 사양을 완전히 따르지 않을 것이며 가능한 가장 깔끔한 아키텍처를 사용하려고 시도하지 않을 것입니다. 그것은 미래의 기사에서 나올 것입니다.
지금까지 사용했던 server.js 파일을 열고 아래의 깨끗한 슬레이트부터 시작하기 위해 모든 것을 비울 것입니다.
// Getting the module from node_modules. const express = require('express'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true )); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // ... // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); 위 파일의 // ... 부분을 차지하는 다음 코드를 모두 고려하십시오.
엔드포인트를 정의하고 REST API를 구축하기 때문에 경로 이름을 지정하는 적절한 방법을 논의해야 합니다. 다시 말하지만, 자세한 내용은 이전 기사의 HTTP 섹션을 살펴봐야 합니다. 우리는 책을 다루고 있으므로 모든 경로는 /books 뒤에 위치합니다(복수 명명 규칙이 표준입니다).
| 요구 | 노선 |
|---|---|
| 게시하다 | /books |
| 가져 오기 | /books/id |
| 반점 | /books/id |
| 삭제 | /books/id |
보시다시피, 책을 게시할 때 ID를 지정할 필요가 없습니다. 왜냐하면 우리(또는 오히려 MongoDB)가 자동으로 서버 측에서 책을 생성할 것이기 때문입니다. GETting, PATCHing 및 DELETing 책은 모두 해당 ID를 끝점에 전달해야 하며, 이에 대해서는 나중에 설명합니다. 지금은 간단히 끝점을 생성해 보겠습니다.
// HTTP POST /books app.post('/books', (req, res) => { // ... console.log('A POST Request was made!'); }); // HTTP GET /books/:id app.get('/books/:id', (req, res) => { // ... console.log(`A GET Request was made! Getting book ${req.params.id}`); }); // HTTP PATCH /books/:id app.patch('/books/:id', (req, res) => { // ... console.log(`A PATCH Request was made! Updating book ${req.params.id}`); }); // HTTP DELETE /books/:id app.delete('/books/:id', (req, res) => { // ... console.log(`A DELETE Request was made! Deleting book ${req.params.id}`); }); :id 구문은 id 가 URL에서 전달될 동적 매개변수임을 Express에 알려줍니다. req 에서 사용할 수 있는 params 객체에서 액세스할 수 있습니다. "우리는 req 에 액세스할 수 있습니다"라는 소리가 마술처럼 들리고 마술(존재하지 않음)이 프로그래밍에서 위험하다는 것을 알고 있지만 Express는 블랙박스가 아니라는 것을 기억해야 합니다. MIT 라이선스에 따라 GitHub에서 사용할 수 있는 오픈 소스 프로젝트입니다. 동적 쿼리 매개변수가 req 개체에 어떻게 배치되는지 확인하려는 경우 소스 코드를 쉽게 볼 수 있습니다.
이제 server.js 파일에 다음이 모두 포함됩니다.
// Getting the module from node_modules. const express = require('express'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true })); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // HTTP POST /books app.post('/books', (req, res) => { // ... console.log('A POST Request was made!'); }); // HTTP GET /books/:id app.get('/books/:id', (req, res) => { // ... console.log(`A GET Request was made! Getting book ${req.params.id}`); }); // HTTP PATCH /books/:id app.patch('/books/:id', (req, res) => { // ... console.log(`A PATCH Request was made! Updating book ${req.params.id}`); }); // HTTP DELETE /books/:id app.delete('/books/:id', (req, res) => { // ... console.log(`A DELETE Request was made! Deleting book ${req.params.id}`); }); // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); 터미널이나 명령줄에서 node server.js 를 실행하여 서버를 시작하고 브라우저를 방문하십시오. Chrome 개발 콘솔을 열고 URL(Uniform Resource Locator) 표시줄에서 localhost:3000/books 를 방문합니다. GET에 대한 로그 명령문과 함께 서버가 작동 중이라는 표시기가 OS 터미널에 이미 표시되어야 합니다.
지금까지 웹 브라우저를 사용하여 GET 요청을 수행했습니다. 이제 막 시작하기에는 좋지만 API 경로를 테스트할 수 있는 더 나은 도구가 있다는 것을 곧 알게 될 것입니다. 실제로 fetch 호출을 콘솔에 직접 붙여넣거나 일부 온라인 서비스를 사용할 수 있습니다. 우리의 경우 시간을 절약하기 위해 cURL 과 Postman을 사용할 것입니다. 나는 이 기사에서 둘 다 사용합니다(또는 둘 중 하나를 사용할 수 있음). cURL 은 다양한 프로토콜을 사용하여 데이터를 전송하도록 설계된 라이브러리(매우 매우 중요한 라이브러리)이자 명령줄 도구입니다. Postman은 API 테스트를 위한 GUI 기반 도구입니다. 운영 체제에서 두 도구에 대한 관련 설치 지침을 따른 후 서버가 여전히 실행 중인지 확인하고 새 터미널에서 다음 명령(하나씩)을 실행합니다. 입력하고 개별적으로 실행한 다음 서버와 별도의 터미널에서 로그 메시지를 보는 것이 중요합니다. 또한 표준 프로그래밍 언어 주석 기호 // 는 Bash 또는 MS-DOS에서 유효한 기호가 아닙니다. 이러한 행은 생략해야 하며 여기서는 cURL 명령의 각 블록을 설명하는 데만 사용합니다.
// HTTP POST Request (Localhost, IPv4, IPv6) curl -X POST https://localhost:3000/books curl -X POST https://127.0.0.1:3000/books curl -X POST https://[::1]:3000/books // HTTP GET Request (Localhost, IPv4, IPv6) curl -X GET https://localhost:3000/books/123abc curl -X GET https://127.0.0.1:3000/books/book-id-123 curl -X GET https://[::1]:3000/books/book-abc123 // HTTP PATCH Request (Localhost, IPv4, IPv6) curl -X PATCH https://localhost:3000/books/456 curl -X PATCH https://127.0.0.1:3000/books/218 curl -X PATCH https://[::1]:3000/books/some-id // HTTP DELETE Request (Localhost, IPv4, IPv6) curl -X DELETE https://localhost:3000/books/abc curl -X DELETE https://127.0.0.1:3000/books/314 curl -X DELETE https://[::1]:3000/books/217 보시다시피 URL 매개변수로 전달되는 ID는 모든 값이 될 수 있습니다. -X 플래그는 HTTP 요청의 유형을 지정하고(GET의 경우 생략 가능) 이후에 요청이 이루어질 URL을 제공합니다. 각 요청을 세 번 복제하여 localhost 호스트 이름, localhost 가 확인되는 IPv4 주소( 127.0.0.1 ) 또는 localhost 가 확인하는 IPv6 주소( ::1 )를 사용하는지 여부에 관계없이 모든 것이 여전히 작동함을 확인할 수 있습니다. . cURL 은 IPv6 주소를 대괄호로 묶어야 합니다.
우리는 이제 적절한 위치에 있습니다. 경로와 끝점의 간단한 구조가 설정되었습니다. 서버가 올바르게 실행되고 예상대로 HTTP 요청을 수락합니다. 예상과 달리 이 시점에서 얼마 남지 않았습니다. 데이터베이스를 설정하고 호스팅하고(Database-as-a-Service — MongoDB Atlas 사용) 데이터베이스에 데이터를 유지하기만 하면 됩니다. 유효성 검사를 수행하고 오류 응답을 생성).
프로덕션 MongoDB 데이터베이스 설정
프로덕션 데이터베이스를 설정하기 위해 MongoDB Atlas 홈 페이지로 이동하여 무료 계정에 등록합니다. 그런 다음 새 클러스터를 만듭니다. 수수료 등급 적용 지역을 선택하여 기본 설정을 유지할 수 있습니다. 그런 다음 "클러스터 생성" 버튼을 누르십시오. 클러스터를 만드는 데 약간의 시간이 걸리고 데이터베이스 URL과 암호를 얻을 수 있습니다. 이것들을 볼 때 참고하십시오. 지금은 하드코딩한 다음 나중에 보안을 위해 환경 변수에 저장합니다. 클러스터 생성 및 연결에 대한 도움말은 MongoDB 설명서, 특히 이 페이지와 이 페이지를 참조하거나 아래에 의견을 남겨주시면 도와드리겠습니다.
몽구스 모델 만들기
NoSQL(Not Only SQL — Structured Query Language)의 맥락에서 문서 및 컬렉션의 의미를 이해하는 것이 좋습니다. 참고로 몽구스 퀵 스타트 가이드와 제 이전 기사의 MongoDB 섹션을 모두 읽고 싶을 수도 있습니다.
이제 CRUD 작업을 수락할 준비가 된 데이터베이스가 있습니다. Mongoose는 노드 모듈(또는 ODM — 개체 문서 매퍼)으로 이러한 작업을 수행하고(일부 복잡성을 추상화) 데이터베이스 컬렉션의 스키마 또는 구조를 설정할 수 있습니다.
중요한 면책 사항으로 ORM 및 Active Record 또는 Data Mapper와 같은 패턴에 대해 많은 논란이 있습니다. 일부 개발자는 ORM으로 맹세하고 다른 개발자는 ORM에 대해 맹세합니다(방해가 된다고 생각함). ORM은 연결 풀링, 소켓 연결 및 처리 등과 같이 많은 것을 추상화한다는 점에 유의하는 것도 중요합니다. MongoDB 네이티브 드라이버(또 다른 NPM 모듈)를 쉽게 사용할 수 있지만 더 많은 작업이 필요합니다. ORM을 사용하기 전에 기본 드라이버로 플레이하는 것이 좋지만 간결함을 위해 여기서는 기본 드라이버를 생략합니다. 관계형 데이터베이스에 대한 복잡한 SQL 작업의 경우 모든 ORM이 쿼리 속도에 최적화되지 않으며 결국 원시 SQL을 작성하게 될 수 있습니다. ORM은 무엇보다도 Domain-Driven Design 및 CQRS와 함께 많은 역할을 할 수 있습니다. They are an established concept in the .NET world, and the Node.js community has not completely caught up yet — TypeORM is better, but it's not NHibernate or Entity Framework.
To create our Model, I'll create a new folder in the server directory entitled models , within which I'll create a single file with the name book.js . Thus far, our project's directory structure is as follows:
- server - node_modules - models - book.js - package.json - server.js Indeed, this directory structure is not required, but I use it here because it's simple. Allow me to note that this is not at all the kind of architecture you want to use for larger applications (and you might not even want to use JavaScript — TypeScript could be a better option), which I discuss in this article's closing. The next step will be to install mongoose , which is performed via, as you might expect, npm i mongoose .
The meaning of a Model is best ascertained from the Mongoose documentation:
Models are fancy constructors compiled from
Schemadefinitions. An instance of a model is called a document. Models are responsible for creating and reading documents from the underlying MongoDB database.
Before creating the Model, we'll define its Schema. A Schema will, among others, make certain expectations about the value of the properties provided. MongoDB is schemaless, and thus this functionality is provided by the Mongoose ODM. Let's start with a simple example. Suppose I want my database to store a user's name, email address, and password. Traditionally, as a plain old JavaScript Object (POJO), such a structure might look like this:
const userDocument = { name: 'Jamie Corkhill', email: '[email protected]', password: 'Bcrypt Hash' };If that above object was how we expected our user's object to look, then we would need to define a schema for it, like this:
const schema = { name: { type: String, trim: true, required: true }, email: { type: String, trim: true, required: true }, password: { type: String, required: true } }; Notice that when creating our schema, we define what properties will be available on each document in the collection as an object in the schema. In our case, that's name , email , and password . The fields type , trim , required tell Mongoose what data to expect. If we try to set the name field to a number, for example, or if we don't provide a field, Mongoose will throw an error (because we are expecting a type of String ), and we can send back a 400 Bad Request to the client. This might not make sense right now because we have defined an arbitrary schema object. However, the fields of type , trim , and required (among others) are special validators that Mongoose understands. trim , for example, will remove any whitespace from the beginning and end of the string. We'll pass the above schema to mongoose.Schema() in the future and that function will know what to do with the validators.
Understanding how Schemas work, we'll create the model for our Books Collection of the Bookshelf API. Let's define what data we require:
제목
ISBN Number
작가
이름
성
발행일
Finished Reading (Boolean)
I'm going to create this in the book.js file we created earlier in /models . Like the example above, we'll be performing validation:
const mongoose = require('mongoose'); // Define the schema: const mySchema = { title: { type: String, required: true, trim: true, }, isbn: { type: String, required: true, trim: true, }, author: { firstName:{ type: String, required: true, trim: true }, lastName: { type: String, required: true, trim: true } }, publishingDate: { type: String }, finishedReading: { type: Boolean, required: true, default: false } } default will set a default value for the property if none is provided — finishedReading for example, although a required field, will be set automatically to false if the client does not send one up.
Mongoose also provides the ability to perform custom validation on our fields, which is done by supplying the validate() method, which attains the value that was attempted to be set as its one and only parameter. In this function, we can throw an error if the validation fails. 다음은 예입니다.
// ... isbn: { type: String, required: true, trim: true, validate(value) { if (!validator.isISBN(value)) { throw new Error('ISBN is invalid.'); } } } // ... Now, if anyone supplies an invalid ISBN to our model, Mongoose will throw an error when trying to save that document to the collection. I've already installed the NPM module validator via npm i validator and required it. validator contains a bunch of helper functions for common validation requirements, and I use it here instead of RegEx because ISBNs can't be validated with RegEx alone due to a tailing checksum. Remember, users will be sending a JSON body to one of our POST routes. That endpoint will catch any errors (such as an invalid ISBN) when attempting to save, and if one is thrown, it'll return a blank response with an HTTP 400 Bad Request status — we haven't yet added that functionality.
Finally, we have to define our schema of earlier as the schema for our model, so I'll make a call to mongoose.Schema() passing in that schema:
const bookSchema = mongoose.Schema(mySchema); To make things more precise and clean, I'll replace the mySchema variable with the actual object all on one line:
const bookSchema = mongoose.Schema({ title:{ type: String, required: true, trim: true, }, isbn:{ type: String, required: true, trim: true, validate(value) { if (!validator.isISBN(value)) { throw new Error('ISBN is invalid.'); } } }, author:{ firstName: { type: String required: true, trim: true }, lastName:{ type: String, required: true, trim: true } }, publishingDate:{ type: String }, finishedReading:{ type: Boolean, required: true, default: false } });Let's take a final moment to discuss this schema. We are saying that each of our documents will consist of a title, an ISBN, an author with a first and last name, a publishing date, and a finishedReading boolean.
-
titlewill be of typeString, it's a required field, and we'll trim any whitespace. -
isbnwill be of typeString, it's a required field, it must match the validator, and we'll trim any whitespace. -
authoris of typeobjectcontaining a required, trimmed,stringfirstName and a required, trimmed,stringlastName. -
publishingDateis of type String (although we could make it of typeDateorNumberfor a Unix timestamp. -
finishedReadingis a requiredbooleanthat will default tofalseif not provided.
With our bookSchema defined, Mongoose knows what data and what fields to expect within each document to the collection that stores books. However, how do we tell it what collection that specific schema defines? We could have hundreds of collections, so how do we correlate, or tie, bookSchema to the Book collection?
The answer, as seen earlier, is with the use of models. We'll use bookSchema to create a model, and that model will model the data to be stored in the Book collection, which will be created by Mongoose automatically.
Append the following lines to the end of the file:
const Book = mongoose.model('Book', bookSchema); module.exports = Book; As you can see, we have created a model, the name of which is Book (— the first parameter to mongoose.model() ), and also provided the ruleset, or schema, to which all data is saved in the Book collection will have to abide. We export this model as a default export, allowing us to require the file for our endpoints to access. Book is the object upon which we'll call all of the required functions to Create, Read, Update, and Delete data which are provided by Mongoose.
Altogether, our book.js file should look as follows:
const mongoose = require('mongoose'); const validator = require('validator'); // Define the schema. const bookSchema = mongoose.Schema({ title:{ type: String, required: true, trim: true, }, isbn:{ type: String, required: true, trim: true, validate(value) { if (!validator.isISBN(value)) { throw new Error('ISBN is invalid.'); } } }, author:{ firstName: { type: String, required: true, trim: true }, lastName:{ type: String, required: true, trim: true } }, publishingDate:{ type: String }, finishedReading:{ type: Boolean, required: true, default: false } }); // Create the "Book" model of name Book with schema bookSchema. const Book = mongoose.model('Book', bookSchema); // Provide the model as a default export. module.exports = Book;Connecting To MongoDB (Basics)
Don't worry about copying down this code. I'll provide a better version in the next section. To connect to our database, we'll have to provide the database URL and password. We'll call the connect method available on mongoose to do so, passing to it the required data. For now, we are going hardcode the URL and password — an extremely frowned upon technique for many reasons: namely the accidental committing of sensitive data to a public (or private made public) GitHub Repository. Realize also that commit history is saved, and that if you accidentally commit a piece of sensitive data, removing it in a future commit will not prevent people from seeing it (or bots from harvesting it), because it's still available in the commit history. CLI tools exist to mitigate this issue and remove history.
As stated, for now, we'll hard code the URL and password, and then save them to environment variables later. At this point, let's look at simply how to do this, and then I'll mention a way to optimize it.
const mongoose = require('mongoose'); const MONGODB_URL = 'Your MongoDB URL'; mongoose.connect(MONGODB_URL, { useNewUrlParser: true, useCreateIndex: true, useFindAndModify: false, useUnifiedTopology: true });그러면 데이터베이스에 연결됩니다. MongoDB Atlas 대시보드에서 얻은 URL을 제공하고 두 번째 매개변수로 전달된 객체는 특히 사용 중단 경고를 방지하기 위해 사용할 기능을 지정합니다.
핵심 MongoDB 네이티브 드라이버를 배후에서 사용하는 Mongoose는 드라이버에 대한 주요 변경 사항을 따라가려고 시도해야 합니다. 새 버전의 드라이버에서는 연결 URL을 구문 분석하는 데 사용되는 메커니즘이 변경 useNewUrlParser: true 플래그를 전달하여 공식 드라이버에서 사용할 수 있는 최신 버전을 사용하도록 지정합니다.
기본적으로 데이터베이스의 데이터에 인덱스("인덱스"가 아닌 "인덱스"라고 함)를 설정하면 Mongoose는 기본 드라이버에서 사용할 수 있는 ensureIndex() 함수를 사용합니다. MongoDB는 createIndex() 대신 해당 함수를 사용하지 않으므로 useCreateIndex 플래그를 true로 설정하면 사용되지 않는 함수인 드라이버의 createIndex() 메서드를 사용하도록 Mongoose에 지시합니다.
Mongoose의 findOneAndUpdate (데이터베이스에서 문서를 찾아 업데이트하는 방법)의 원래 버전은 Native Driver 버전보다 앞선 것입니다. 즉, findOneAndUpdate() 는 원래 Native Driver 함수가 아니라 Mongoose에서 제공하는 함수이므로 Mongoose는 findOneAndUpdate 기능을 만들기 위해 드라이버에서 배후에서 제공하는 findAndModify 를 사용해야 했습니다. 이제 드라이버가 업데이트되어 자체 함수가 포함되어 있으므로 findAndModify 를 사용할 필요가 없습니다. 이것은 말이 안 될 수도 있고, 괜찮습니다. 이것은 사물의 규모에 관한 중요한 정보가 아닙니다.
마지막으로 MongoDB는 이전 서버 및 엔진 모니터링 시스템을 더 이상 사용하지 않습니다. useUnifiedTopology: true 와 함께 새 메서드를 사용합니다.
지금까지 우리가 가진 것은 데이터베이스에 연결하는 방법입니다. 그러나 여기에 문제가 있습니다. 확장 가능하거나 효율적이지 않습니다. 이 API에 대한 단위 테스트를 작성할 때 단위 테스트는 자체 테스트 데이터베이스에서 자체 테스트 데이터(또는 고정 장치)를 사용합니다. 따라서 우리는 테스트 환경(우리가 임의로 회전 및 해체할 수 있음)을 위한 연결, 개발 환경을 위한 연결, 프로덕션 환경을 위한 연결 등 다양한 목적으로 연결을 생성할 수 있는 방법을 원합니다. 그렇게 하기 위해 우리는 공장을 지을 것입니다. (이전부터 기억하시나요?)
Mongo에 연결 — JS 팩토리 구현 구축
사실, 자바 객체는 자바스크립트 객체와 전혀 유사하지 않으며, 따라서 위에서 우리가 팩토리 디자인 패턴에서 알고 있는 것은 적용되지 않을 것입니다. 나는 단지 전통적인 패턴을 보여주기 위해 예를 제공했습니다. Java, C#, C++ 등에서 객체를 얻으려면 클래스를 인스턴스화해야 합니다. 이것은 컴파일러에게 힙의 개체에 대한 메모리를 할당하도록 지시하는 new 키워드로 수행됩니다. C++에서 이것은 우리가 스스로 정리해야 하는 객체에 대한 포인터를 제공하므로 매달린 포인터나 메모리 누수가 없습니다(C++에는 C++에 구축된 Node/V8과 달리 가비지 수집기가 없습니다) JavaScript에서, 위의 작업을 수행할 필요가 없습니다. 객체를 얻기 위해 클래스를 인스턴스화할 필요가 없습니다. 객체는 단지 {} 입니다. 어떤 사람들은 JavaScript의 모든 것이 객체라고 말하지만 기본 유형은 객체가 아니기 때문에 기술적으로 사실이 아닙니다.
위의 이유로 JS 팩토리는 객체(JS 객체)를 반환하는 함수인 팩토리의 느슨한 정의를 고수하면서 더 간단할 것입니다. 함수는 객체이기 때문에( function 가 프로토타입 상속을 통해 object 에서 상속되는 경우) 아래 예제는 이 기준을 충족합니다. 팩토리를 구현하기 위해 db 라는 server 내부에 새 폴더를 생성하겠습니다. db 내에서 mongoose.js 라는 새 파일을 만듭니다. 이 파일은 데이터베이스에 연결합니다. mongoose.js 내부에서 connectionFactory 라는 함수를 만들고 기본적으로 내보냅니다.
// Directory - server/db/mongoose.js const mongoose = require('mongoose'); const MONGODB_URL = 'Your MongoDB URL'; const connectionFactory = () => { return mongoose.connect(MONGODB_URL, { useNewUrlParser: true, useCreateIndex: true, useFindAndModify: false }); }; module.exports = connectionFactory; 메서드 서명과 같은 줄에 하나의 명령문을 반환하는 Arrow Functions에 대해 ES6에서 connectionFactory 하는 약식을 사용하여 이 파일을 더 간단하게 만들겠습니다.
// server/db/mongoose.js const mongoose = require('mongoose'); const MONGODB_URL = 'Your MongoDB URL'; module.exports = () => mongoose.connect(MONGODB_URL, { useNewUrlParser: true, useCreateIndex: true, useFindAndModify: true });이제 다음과 같이 파일이 필요하고 내보내는 메서드를 호출하기만 하면 됩니다.
const connectionFactory = require('./db/mongoose'); connectionFactory(); // OR require('./db/mongoose')();MongoDB URL을 팩토리 함수에 대한 매개변수로 제공하여 제어를 반전할 수 있지만 환경에 따라 URL을 환경 변수로 동적으로 변경할 것입니다.
연결을 함수로 만들 때의 이점은 나중에 코드에서 해당 함수를 호출하여 프로덕션을 목표로 하는 파일과 온디바이스 및 원격 CI/CD 파이프라인 모두에서 로컬 및 원격 통합 테스트를 목표로 하는 파일에서 데이터베이스에 연결할 수 있다는 것입니다. /빌드 서버.
엔드포인트 구축
이제 끝점에 매우 간단한 CRUD 관련 논리를 추가하기 시작합니다. 이전에 언급했듯이 짧은 면책 조항이 있습니다. 여기에서 비즈니스 로직을 구현하는 방법은 단순한 프로젝트 이외의 다른 것에 대해 미러링해야 하는 방법이 아닙니다 . 데이터베이스에 연결하고 엔드포인트 내에서 직접 로직을 수행하는 것은 눈살을 찌푸리게 하는 일입니다. 왜냐하면 애플리케이션 전반에 걸친 리팩토링을 수행하지 않고도 서비스나 DBMS를 교체할 수 있는 능력을 상실하기 때문입니다. 그럼에도 불구하고 이것이 초보자의 기사라는 점을 고려하여 여기에서 이러한 나쁜 관행을 사용합니다. 이 시리즈의 향후 기사에서는 아키텍처의 복잡성과 품질을 모두 높일 수 있는 방법에 대해 설명합니다.
지금은 server.js 파일로 돌아가서 둘 다 시작점이 동일한지 확인하겠습니다. 데이터베이스 연결 팩토리에 대한 require 문을 추가했고 ./models/book.js 에서 내보낸 모델을 가져왔습니다.
const express = require('express'); // Database connection and model. require('./db/mongoose.js'); const Book = require('./models/book.js'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true })); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // HTTP POST /books app.post('/books', (req, res) => { // ... console.log('A POST Request was made!'); }); // HTTP GET /books/:id app.get('/books/:id', (req, res) => { // ... console.log(`A GET Request was made! Getting book ${req.params.id}`); }); // HTTP PATCH /books/:id app.patch('/books/:id', (req, res) => { // ... console.log(`A PATCH Request was made! Updating book ${req.params.id}`); }); // HTTP DELETE /books/:id app.delete('/books/:id', (req, res) => { // ... console.log(`A DELETE Request was made! Deleting book ${req.params.id}`); }); // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); app.post() 부터 시작하겠습니다. 책 모델을 만든 파일에서 내보냈기 때문에 Book 모델에 액세스할 수 있습니다. Mongoose 문서에 명시된 대로 Book 은 구성 가능합니다. 새 책을 만들기 위해 다음과 같이 생성자를 호출하고 책 데이터를 전달합니다.
const book = new Book(bookData); 우리의 경우에는 bookData 에서 사용할 수 있는 요청에서 전송된 객체로 req.body.book 를 갖게 됩니다. express.json() 미들웨어는 우리가 보내는 모든 JSON 데이터를 req.body 에 넣습니다. 다음 형식으로 JSON을 보내야 합니다.
{ "book": { "title": "The Art of Computer Programming", "isbn": "ISBN-13: 978-0-201-89683-1", "author": { "firstName": "Donald", "lastName": "Knuth" }, "publishingDate": "July 17, 1997", "finishedReading": true } } 그러면 우리가 전달한 JSON이 구문 분석되고 전체 JSON 객체(첫 번째 중괄호 쌍)가 express.json express.json() 미들웨어에 의해 req.body 에 배치된다는 의미입니다. JSON 객체의 유일한 속성은 book 이며 따라서 book 객체는 req.body.book 에서 사용할 수 있습니다.
이 시점에서 모델 생성자 함수를 호출하고 데이터를 전달할 수 있습니다.
app.post('/books', async (req, res) => { // <- Notice 'async' const book = new Book(req.body.book); await book.save(); // <- Notice 'await' }); 여기서 몇 가지 사항에 유의하십시오. 생성자 함수를 호출하여 얻은 인스턴스에서 save 메소드를 호출하면 req.body.book 객체가 Mongoose 모델에서 정의한 스키마를 준수하는 경우에만 데이터베이스에 유지됩니다. 데이터베이스에 데이터를 저장하는 작업은 비동기식 작업이며 이 save() 메서드는 우리가 많이 기다리는 약속을 반환합니다. .then() 호출에 연결하는 대신 ES6 Async/Await 구문을 사용합니다. 즉, app.post async 에 대한 콜백 함수를 만들어야 함을 의미합니다.
클라이언트가 보낸 객체가 우리가 정의한 스키마를 준수하지 않으면 book.save() 는 ValidationError 와 함께 거부합니다. 현재 설정은 매우 불안정하고 잘못 작성된 코드를 만듭니다. 유효성 검사와 관련된 오류가 발생한 경우 응용 프로그램이 충돌하는 것을 원하지 않기 때문입니다. 이 문제를 해결하기 위해 위험한 작업을 try/catch 절로 묶겠습니다. 오류가 발생하면 HTTP 400 Bad Request 또는 HTTP 422 Unprocessable Entity를 반환하겠습니다. 어느 것을 사용할 것인지에 대해 어느 정도 논쟁이 있기 때문에 이 기사에서는 400이 더 일반적이기 때문에 400을 사용하겠습니다.
app.post('/books', async (req, res) => { try { const book = new Book(req.body.book); await book.save(); return res.status(201).send({ book }); } catch (e) { return res.status(400).send({ error: 'ValidationError' }); } }); ES6 Object Shorthand를 사용하여 res.send({ book }) 를 사용하여 성공 사례에서 바로 book 객체를 클라이언트로 반환합니다. 이는 res.send({ book: book }) 와 동일합니다. 또한 함수가 종료되는지 확인하기 위해 표현식을 반환합니다. catch 블록에서 명시적으로 상태를 400으로 설정하고 반환되는 객체의 error 속성에 'ValidationError' 문자열을 반환합니다. 201은 "CREATED"를 의미하는 성공 경로 상태 코드입니다.
실제로 이것은 실패의 원인이 클라이언트 측의 잘못된 요청인지 확신할 수 없기 때문에 최선의 솔루션도 아닙니다. 데이터베이스에 대한 연결이 끊어졌을 수 있습니다(소켓 연결이 끊어져 일시적인 예외라고 가정함). 이 경우 500 내부 서버 오류를 반환해야 합니다. 이를 확인하는 방법은 e 오류 개체를 읽고 선택적으로 응답을 반환하는 것입니다. 지금 해보자. 하지만 내가 여러 번 말했듯이 후속 기사에서는 라우터, 컨트롤러, 서비스, 리포지토리, 사용자 지정 오류 클래스, 사용자 지정 오류 미들웨어, 사용자 지정 오류 응답, 데이터베이스 모델/도메인 엔터티 데이터 측면에서 적절한 아키텍처에 대해 설명합니다. 매핑 및 CQS(명령 쿼리 분리).
app.post('/books', async (req, res) => { try { const book = new Book(req.body.book); await book.save(); return res.send({ book }); } catch (e) { if (e instanceof mongoose.Error.ValidationError) { return res.status(400).send({ error: 'ValidationError' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } }); 계속해서 Postman을 열고(있는 경우, 다운로드 및 설치) 새 요청을 만듭니다. localhost:3000/books 에 대한 POST 요청을 만들 것입니다. Postman Request 섹션의 "Body" 탭에서 "raw" 라디오 버튼을 선택하고 맨 오른쪽에 있는 드롭다운 버튼에서 "JSON"을 선택하겠습니다. 그러면 자동으로 Content-Type: application/json 헤더가 요청에 추가됩니다. 그런 다음 이전의 Book JSON 개체를 복사하여 본문 텍스트 영역에 붙여넣겠습니다. 이것이 우리가 가지고 있는 것입니다:
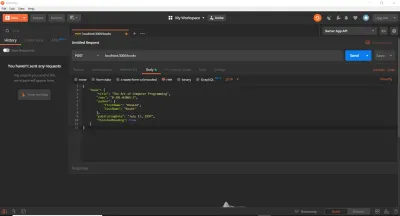
그런 다음 보내기 버튼을 누르면 Postman의 "응답" 섹션(하단 행)에 201 Created 응답이 표시됩니다. 우리는 Express가 201과 Book 객체로 응답하도록 특별히 요청했기 때문에 이것을 볼 수 있습니다. 상태 코드 없이 res.send() 를 수행했다면 express 는 자동으로 200 OK로 응답했을 것입니다. 보시다시피 Book 개체는 이제 데이터베이스에 저장되고 POST 요청에 대한 응답으로 클라이언트에 반환되었습니다.
MongoDB Atlas를 통해 데이터베이스 Book 컬렉션을 보면 그 책이 실제로 저장되었음을 알 수 있습니다.
또한 MongoDB가 __v 및 _id 필드를 삽입했음을 알 수 있습니다. 전자는 문서의 버전(이 경우 0)을 나타내고 후자는 문서의 ObjectID를 나타냅니다. 이는 MongoDB에 의해 자동으로 생성되며 낮은 충돌 확률을 보장합니다.
지금까지 다룬 내용 요약
우리는 기사에서 지금까지 많은 것을 다루었습니다. Express API를 끝내기 위해 돌아가기 전에 간략한 요약을 살펴보고 잠시 유예합시다.
ES6 Object Destructuring, ES6 Object Shorthand Syntax, ES6 Rest/Spread 연산자에 대해 배웠습니다. 이 세 가지 모두를 통해 다음을 수행할 수 있습니다(위에서 논의한 대로).
// Destructuring Object Properties: const { a: newNameA = 'Default', b } = { a: 'someData', b: 'info' }; console.log(`newNameA: ${newNameA}, b: ${b}`); // newNameA: someData, b: info // Destructuring Array Elements const [elemOne, elemTwo] = [() => console.log('hi'), 'data']; console.log(`elemOne(): ${elemOne()}, elemTwo: ${elemTwo}`); // elemOne(): hi, elemTwo: data // Object Shorthand const makeObj = (name) => ({ name }); console.log(`makeObj('Tim'): ${JSON.stringify(makeObj('Tim'))}`); // makeObj('Tim'): { "name": "Tim" } // Rest, Spread const [c, d, ...rest] = [0, 1, 2, 3, 4]; console.log(`c: ${c}, d: ${d}, rest: ${rest}`) // c: 0, d: 1, rest: 2, 3, 4 우리는 또한 Express, Expes Middleware, Servers, Ports, IP Addressing 등을 다루었습니다. require('express')(); app.get 및 app.post 와 같은 HTTP 동사의 이름을 사용합니다.
그 require('express')() 부분이 당신에게 이해가 되지 않는다면 이것이 내가 말하고 있는 요점입니다.
const express = require('express'); const app = express(); app.someHTTPVerb이전에 Mongoose에 대해 연결 팩토리를 시작했던 것과 같은 방식으로 이해해야 합니다.
끝점 함수(또는 콜백 함수)인 각 경로 처리기는 장면 뒤에서 Express의 req 개체와 res 개체로 전달됩니다. (기술적으로 next 도 얻습니다. 잠시 후에 보게 될 것입니다). req 에는 헤더 또는 전송된 JSON과 같이 클라이언트에서 들어오는 요청과 관련된 데이터가 포함됩니다. res 는 클라이언트에게 응답을 반환할 수 있게 해주는 것입니다. next 함수도 핸들러에 전달됩니다.
Mongoose를 사용하여 두 가지 방법으로 데이터베이스에 연결할 수 있는 방법을 보았습니다. 기본 방법과 Factory Pattern에서 차용한 보다 고급/실용적인 방법입니다. Jest를 사용한 단위 및 통합 테스트(및 돌연변이 테스트)에 대해 논의할 때 이를 사용하게 될 것입니다. 이는 어설션을 실행할 수 있는 시드 데이터로 채워진 DB의 테스트 인스턴스를 가동할 수 있기 때문입니다.
그 후, 우리는 Mongoose 스키마 객체를 생성하고 이를 사용하여 모델을 생성한 다음 해당 모델의 생성자를 호출하여 새 인스턴스를 생성하는 방법을 배웠습니다. 인스턴스에서 사용할 수 있는 save 메서드는 본질적으로 비동기식이며 전달한 개체 구조가 스키마를 준수하는지 확인하고, 일치하는 경우 약속을 해결하고, 다음과 같은 경우 ValidationError 로 약속을 거부합니다. 그렇지 않습니다. 해결의 경우 새 문서가 데이터베이스에 저장되고 HTTP 200 OK/201 CREATED로 응답합니다. 그렇지 않으면 엔드포인트에서 throw된 오류를 포착하고 클라이언트에 HTTP 400 잘못된 요청을 반환합니다.
계속해서 엔드포인트를 구축하면서 모델 및 모델 인스턴스에서 사용할 수 있는 몇 가지 방법에 대해 자세히 알게 될 것입니다.
끝점 마무리
POST 끝점을 완료했으면 GET을 처리해 보겠습니다. 앞서 언급했듯이 경로 내부의 :id 구문은 id 가 req.params 에서 액세스할 수 있는 경로 매개변수임을 Express에 알려줍니다. 경로에서 매개변수 "와일드카드"에 대한 일부 ID를 일치시키면 초기 예제에서 화면에 인쇄되는 것을 이미 보았습니다. 예를 들어 "/books/test-id-123"에 대한 GET 요청을 만든 경우 req.params.id 는 문자열 test-id-123 이 됩니다. 왜냐하면 경로가 HTTP GET /books/:id 이므로 매개변수 이름이 id 였기 때문입니다. HTTP GET /books/:id .
따라서 우리가 해야 할 일은 req 객체에서 해당 ID를 검색하고 데이터베이스의 문서에 동일한 ID가 있는지 확인하는 것뿐입니다. 이는 Mongoose(및 기본 드라이버)에서 매우 쉽게 만든 것입니다.
app.get('/books/:id', async (req, res) => { const book = await Book.findById(req.params.id); console.log(book); res.send({ book }); }); 우리 모델에서 접근할 수 있는 것은 ID로 문서를 찾는 우리가 호출할 수 있는 함수라는 것을 알 수 있습니다. 무대 뒤에서 Mongoose는 findById 에 전달한 모든 ID를 문서의 _id 필드 유형(이 경우 ObjectId )으로 캐스팅합니다. 일치하는 ID가 발견되면( ObjectId 에 대해 하나만 발견될 것이며 충돌 확률이 매우 낮음) 해당 문서는 book 상수 변수에 배치됩니다. 그렇지 않은 경우 book 은 null이 됩니다. 가까운 장래에 사용할 사실입니다.
지금은 서버를 다시 시작하고( nodemon 을 사용하지 않는 한 서버를 다시 시작해야 함) Books Collection 내에서 이전의 한 책 문서가 여전히 있는지 확인합니다. 계속해서 아래 이미지에서 강조 표시된 부분인 해당 문서의 ID를 복사합니다.

그리고 그것을 사용하여 다음과 같이 Postman을 사용하여 /books/:id 에 대한 GET 요청을 만듭니다(본문 데이터는 이전 POST 요청에서 남겨진 것입니다. 아래 이미지에 묘사되어 있음에도 불구하고 실제로 사용되지 않음) :
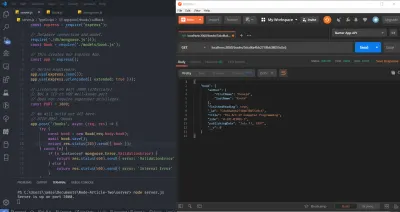
그렇게 하면 우편 배달부 응답 섹션 내에서 지정된 ID를 가진 책 문서를 다시 가져와야 합니다. 이전에는 서버에 새 리소스를 "POST" 또는 "푸시"하도록 설계된 POST 경로를 사용하여 새 리소스(또는 문서)가 생성되었기 때문에 201 Created로 응답했습니다. GET의 경우 새로 생성된 것이 없습니다. 특정 ID로 리소스를 요청했기 때문에 201 Created 대신 200 OK 상태 코드가 반환되었습니다.
소프트웨어 개발 분야에서 흔히 볼 수 있듯이, 엣지 케이스는 반드시 고려되어야 합니다. 사용자 입력은 본질적으로 안전하지 않고 오류가 있으며, 개발자로서 우리가 제공할 수 있는 입력 유형에 유연하게 대응하고 이에 대응하는 것이 우리의 임무입니다. 따라서. 사용자(또는 API 호출자)가 MongoDB ObjectID로 캐스트할 수 없는 ID 또는 캐스트할 수 있지만 존재하지 않는 ID를 전달하면 어떻게 해야 합니까?
전자의 경우 Mongoose는 CastError 를 던질 것입니다. 우리가 math-is-fun 과 같은 ID를 제공하면 분명히 ObjectID로 캐스트할 수 있는 것이 아니며 ObjectID로 캐스트하는 것이 구체적으로 무엇이기 때문에 이해할 수 있습니다. 몽구스는 후드 아래에서하고 있습니다.
후자의 경우 Null Check 또는 Guard Clause를 통해 문제를 쉽게 수정할 수 있습니다. 어느 쪽이든 HTTP 404 Not Found Response를 다시 보내겠습니다. 이 작업을 수행할 수 있는 몇 가지 방법, 즉 나쁜 방법과 더 나은 방법을 보여 드리겠습니다.
먼저 다음을 수행할 수 있습니다.
app.get('/books/:id', async (req, res) => { try { const book = await Book.findById(req.params.id); if (!book) throw new Error(); return res.send({ book }); } catch (e) { return res.status(404).send({ error: 'Not Found' }); } }); 이것은 작동하고 우리는 그것을 잘 사용할 수 있습니다. ID 문자열을 ObjectID로 캐스트할 수 없는 경우 await Book.findById() 문이 Mongoose CastError 를 발생시켜 catch 블록이 실행될 것으로 예상합니다. 캐스팅할 수 있지만 해당 ObjectID가 존재하지 않는 경우 book 은 null 이 되고 Null Check는 오류를 발생시키고 catch 블록을 다시 실행합니다. catch 내부에서는 404만 반환합니다. 여기에는 두 가지 문제가 있습니다. 첫째, 책을 찾았지만 다른 알 수 없는 오류가 발생하더라도 클라이언트에게 일반 catch-all 500을 제공해야 할 때 404를 다시 보냅니다. 둘째, 보낸 ID가 유효한지 여부를 실제로 구별하지는 않지만 존재하지 않거나 단지 잘못된 ID인지 여부.
다른 방법이 있습니다.
const mongoose = require('mongoose'); app.get('/books/:id', async (req, res) => { try { const book = await Book.findById(req.params.id); if (!book) return res.status(404).send({ error: 'Not Found' }); return res.send({ book }); } catch (e) { if (e instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } }); 이것에 대한 좋은 점은 400, 404 및 일반 500의 세 가지 경우를 모두 처리할 수 있다는 것입니다. book 에서 Null Check 후에 응답에 return 키워드를 사용합니다. 이것은 우리가 그곳에서 라우트 핸들러를 확실히 종료하기를 원하기 때문에 매우 중요합니다.
Mongoose가 mongoose.Types.ObjectId.isValid('id); 를 사용하여 암시적으로 캐스팅하도록 허용하는 것과 달리 req.params 의 id 를 ObjectID로 명시적으로 캐스팅할 수 있는지 확인하는 다른 옵션이 있을 수 있습니다. , 그러나 때때로 예기치 않게 작동하게 하는 12바이트 문자열의 경우가 있습니다.
예를 들어 HTTP 응답 라이브러리인 Boom 을 사용하여 반복을 덜 고통스럽게 만들거나 오류 처리 미들웨어를 사용할 수 있습니다. 여기에 설명된 대로 Mongoose Hooks/Middleware를 사용하여 Mongoose Errors를 더 읽기 쉬운 것으로 변환할 수도 있습니다. 추가 옵션은 사용자 지정 오류 개체를 정의하고 전역 Express 오류 처리 미들웨어를 사용하는 것이지만 더 나은 아키텍처 방법에 대해 논의하는 다음 기사를 위해 저장하겠습니다.
PATCH /books/:id 의 끝점에서 문제의 책에 대한 업데이트가 포함된 업데이트 개체가 전달될 것으로 예상합니다. 이 기사에서는 모든 필드가 업데이트되도록 허용하지만 앞으로 특정 필드의 업데이트를 허용하지 않는 방법을 보여 드리겠습니다. 또한 PATCH 끝점의 오류 처리 논리가 GET 끝점과 동일하다는 것을 알 수 있습니다. 이는 우리가 DRY 원칙을 위반하고 있다는 표시이지만 나중에 다시 다루겠습니다.
모든 업데이트가 req.body 의 updates 개체에서 사용 가능하고(클라이언트가 updates 개체를 포함하는 JSON을 보낼 것임을 의미함) 업데이트를 수행하기 위해 특별한 플래그와 함께 Book.findByAndUpdate 함수를 사용할 것으로 예상합니다.
app.patch('/books/:id', async (req, res) => { const { id } = req.params; const { updates } = req.body; try { const updatedBook = await Book.findByIdAndUpdate(id, updates, { runValidators: true, new: true }); if (!updatedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: updatedBook }); } catch (e) { if (e instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } }); 여기서 몇 가지 사항에 유의하십시오. 먼저 req.params 에서 id 를 분해하고 req.params 에서 updates 를 req.body 합니다.
Book 모델에서 사용할 수 있는 함수는 해당 문서의 ID, 수행할 업데이트 및 선택적 옵션 개체를 사용하는 findByIdAndUpdate 라는 이름의 함수입니다. 일반적으로 Mongoose는 업데이트 작업에 대한 유효성 검사를 다시 수행하지 않으므로 options 객체로 전달하는 runValidators: true 플래그는 강제로 수행합니다. 또한 Mongoose 4부터 Model.findByIdAndUpdate 는 더 이상 수정된 문서를 반환하지 않고 대신 원본 문서를 반환합니다. new: true 플래그(기본적으로 false)는 해당 동작을 재정의합니다.
마지막으로 DELETE 엔드포인트를 구축할 수 있습니다. 이는 다른 모든 엔드포인트와 매우 유사합니다.
app.delete('/books/:id', async (req, res) => { try { const deletedBook = await Book.findByIdAndDelete(req.params.id); if (!deletedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: deletedBook }); } catch (e) { if (e instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { return res.status(500).send({ error: 'Internal Error' }); } } });이것으로 기본 API가 완성되었으며 모든 엔드포인트에 HTTP 요청을 만들어 테스트할 수 있습니다.
아키텍처 및 수정 방법에 대한 짧은 면책 조항
아키텍처 관점에서 볼 때 여기에 있는 코드는 매우 나쁘고 지저분하고 DRY도 아니고 SOLID도 아닙니다. 사실, 혐오스럽다고 부를 수도 있습니다. 이러한 소위 "경로 처리기"는 단순히 "경로를 전달"하는 것 이상의 일을 하며 우리 데이터베이스와 직접 인터페이스합니다. 즉, 추상화가 전혀 없습니다.
사실, 대부분의 애플리케이션은 결코 작지 않을 것입니다. 그렇지 않으면 Firebase 데이터베이스를 사용하여 서버리스 아키텍처에서 벗어날 수 있습니다. 나중에 보게 되겠지만 사용자는 자신의 책 등에서 아바타, 인용문 및 스니펫을 업로드하는 기능을 원할 것입니다. 어쩌면 WebSocket을 사용하여 사용자 간에 라이브 채팅 기능을 추가하고 싶을 수도 있습니다. 은 사용자가 소액의 비용으로 서로 책을 빌릴 수 있도록 애플리케이션을 열 것입니다. 이 시점에서 우리는 Stripe API와 결제 통합 및 Shippo API를 사용한 배송 물류를 고려해야 합니다.
현재 아키텍처를 계속 진행하고 이 기능을 모두 추가한다고 가정합니다. 컨트롤러 작업이라고도 하는 이러한 경로 처리기는 결국 순환적 복잡성 이 매우 커서 매우 커질 것입니다. 초기에는 이러한 코딩 스타일이 적합할 수 있지만 데이터가 참조 데이터이고 PostgreSQL이 MongoDB보다 더 나은 데이터베이스 선택이라고 결정하면 어떻게 될까요? 이제 전체 애플리케이션을 리팩터링하고, 몽구스를 제거하고, 컨트롤러를 변경하는 등의 작업을 수행해야 합니다. 이 모든 작업은 나머지 비즈니스 로직에서 잠재적인 버그로 이어질 수 있습니다. 또 다른 예로는 AWS S3가 너무 비싸서 GCP로 마이그레이션하고 싶다고 결정하는 경우가 있습니다. 다시 말하지만, 이는 애플리케이션 전체의 리팩터링이 필요합니다.
Domain-Driven Design, Command Query Responsibility Segregation, Event Sourcing에서 Test-Driven Development, SOILD, Layered Architecture, Onion Architecture 등에 이르기까지 아키텍처에 대한 많은 의견이 있지만 여기서는 간단한 Layered Architecture 구현에 중점을 둘 것입니다. 컨트롤러, 서비스 및 리포지토리로 구성되고 구성, 어댑터/래퍼 및 종속성 주입을 통한 제어 역전과 같은 디자인 패턴을 사용하는 향후 기사. 이것은 JavaScript로 어느 정도 수행할 수 있지만 이 아키텍처를 달성하기 위해 TypeScript 옵션도 조사하여 Generics와 같은 OOP 개념 외에도 어느 쪽 모나드와 같은 기능적 프로그래밍 패러다임을 사용할 수 있는지 살펴보겠습니다.
현재로서는 두 가지 작은 변경 사항이 있습니다. 오류 처리 로직은 모든 엔드포인트의 catch 블록에서 매우 유사하기 때문에 스택 맨 끝에 있는 사용자 지정 Express 오류 처리 미들웨어 기능으로 추출할 수 있습니다.
아키텍처 정리
현재 우리는 모든 엔드포인트에서 매우 많은 양의 오류 처리 논리를 반복하고 있습니다. 대신에 오류와 함께 호출되는 Express 미들웨어 기능인 Express 오류 처리 미들웨어 기능, req 및 res 개체, 그리고 다음 기능을 빌드할 수 있습니다.
지금은 해당 미들웨어 기능을 빌드해 보겠습니다. 내가 할 일은 다음과 같은 오류 처리 논리를 반복하는 것뿐입니다.
app.use((err, req, res, next) => { if (err instanceof mongoose.Error.ValidationError) { return res.status(400).send({ error: 'Validation Error' }); } else if (err instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { console.log(err); // Unexpected, so worth logging. return res.status(500).send({ error: 'Internal error' }); } }); 이것은 몽구스 오류에서 작동하지 않는 것으로 보이지만 일반적으로 if/else if/else 를 사용하여 오류 인스턴스를 결정하는 대신 오류의 생성자를 전환할 수 있습니다. 그러나 나는 우리가 가진 것을 남길 것입니다.
동기식 끝점/경로 처리기에서 오류가 발생하면 Express는 오류를 포착하고 사용자의 추가 작업 없이 처리합니다. 불행히도 우리는 그렇지 않습니다. 우리는 비동기 코드를 다루고 있습니다. 비동기 라우트 핸들러를 사용하여 Express에 오류 처리를 위임하기 위해 우리는 오류를 직접 잡아서 next() 에 전달합니다.
따라서 next 를 끝점의 세 번째 인수로 허용하고 catch 블록에서 오류 처리 논리를 제거하여 다음과 같이 오류 인스턴스를 next 로 전달합니다.
app.post('/books', async (req, res, next) => { try { const book = new Book(req.body.book); await book.save(); return res.send({ book }); } catch (e) { next(e) } });모든 경로 처리기에 대해 이 작업을 수행하면 다음 코드로 끝나야 합니다.
const express = require('express'); const mongoose = require('mongoose'); // Database connection and model. require('./db/mongoose.js')(); const Book = require('./models/book.js'); // This creates our Express App. const app = express(); // Define middleware. app.use(express.json()); app.use(express.urlencoded({ extended: true })); // Listening on port 3000 (arbitrary). // Not a TCP or UDP well-known port. // Does not require superuser privileges. const PORT = 3000; // We will build our API here. // HTTP POST /books app.post('/books', async (req, res, next) => { try { const book = new Book(req.body.book); await book.save(); return res.status(201).send({ book }); } catch (e) { next(e) } }); // HTTP GET /books/:id app.get('/books/:id', async (req, res) => { try { const book = await Book.findById(req.params.id); if (!book) return res.status(404).send({ error: 'Not Found' }); return res.send({ book }); } catch (e) { next(e); } }); // HTTP PATCH /books/:id app.patch('/books/:id', async (req, res, next) => { const { id } = req.params; const { updates } = req.body; try { const updatedBook = await Book.findByIdAndUpdate(id, updates, { runValidators: true, new: true }); if (!updatedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: updatedBook }); } catch (e) { next(e); } }); // HTTP DELETE /books/:id app.delete('/books/:id', async (req, res, next) => { try { const deletedBook = await Book.findByIdAndDelete(req.params.id); if (!deletedBook) return res.status(404).send({ error: 'Not Found' }); return res.send({ book: deletedBook }); } catch (e) { next(e); } }); // Notice - bottom of stack. app.use((err, req, res, next) => { if (err instanceof mongoose.Error.ValidationError) { return res.status(400).send({ error: 'Validation Error' }); } else if (err instanceof mongoose.Error.CastError) { return res.status(400).send({ error: 'Not a valid ID' }); } else { console.log(err); // Unexpected, so worth logging. return res.status(500).send({ error: 'Internal error' }); } }); // Binding our application to port 3000. app.listen(PORT, () => console.log(`Server is up on port ${PORT}.`)); 더 나아가서 오류 처리 미들웨어를 다른 파일로 분리할 가치가 있지만 이는 사소한 일이며 이 시리즈의 향후 기사에서 볼 수 있습니다. 또한, catch 블록에서 next를 호출하지 않아도 되도록 express-async-errors 라는 NPM 모듈을 사용할 수 있습니다.
CORS 및 동일 원산지 정책에 대한 한마디
웹 사이트가 myWebsite.com 도메인에서 제공되지만 서버가 myOtherDomain.com/api 에 있다고 가정합니다. CORS는 Cross-Origin Resource Sharing의 약자이며 교차 도메인 요청을 수행할 수 있는 메커니즘입니다. 위의 경우 서버와 프론트엔드 JS 코드가 서로 다른 도메인에 있으므로 보안상의 이유로 브라우저에서 일반적으로 제한하고 특정 HTTP 헤더를 제공하여 완화하는 두 개의 서로 다른 출처에 걸쳐 요청을 하게 됩니다.
동일한 출처 정책은 앞서 언급한 제한 사항을 수행하는 것입니다. 웹 브라우저는 동일한 출처에 대해서만 요구 사항을 허용할 것입니다.
나중에 React를 사용하여 Book API를 위한 Webpack 번들 프론트엔드를 빌드할 때 CORS와 SOP에 대해 다룰 것입니다.
결론 및 다음 단계
우리는 이 기사에서 많은 것을 논의했습니다. 아마도 완전히 실용적이지는 않았지만 Express 및 ES6 JavaScript 기능을 사용하여 작업하는 것이 더 편안하기를 바랍니다. 프로그래밍이 처음이고 Node가 시작하는 첫 번째 경로인 경우 Java, C++ 및 C#과 같은 정적 유형 언어에 대한 참조가 JavaScript와 정적 대응 언어 간의 차이점을 강조하는 데 도움이 되었기를 바랍니다.
다음 시간에는 Book Routes와 관련하여 현재 설정을 일부 수정하고 사용자가 책을 소유할 수 있도록 사용자 인증을 추가하여 Book API 구축을 마칠 것입니다. We'll do all of this with a similar architecture to what I described here and with MongoDB for data persistence. Finally, we'll permit users to upload avatar images to AWS S3 via Buffers.
In the article thereafter, we'll be rebuilding our application from the ground up in TypeScript, still with Express. We'll also move to PostgreSQL with Knex instead of MongoDB with Mongoose as to depict better architectural practices. Finally, we'll update our avatar image uploading process to use Node Streams (we'll discuss Writable, Readable, Duplex, and Transform Streams). Along the way, we'll cover a great amount of design and architectural patterns and functional paradigms, including:
- Controllers/Controller Actions
- 서비스
- 저장소
- 데이터 매핑
- The Adapter Pattern
- The Factory Pattern
- The Delegation Pattern
- OOP Principles and Composition vs Inheritance
- Inversion of Control via Dependency Injection
- SOLID Principles
- Coding against interfaces
- Data Transfer Objects
- Domain Models and Domain Entities
- Either Monads
- 확인
- 데코레이터
- Logging and Logging Levels
- Unit Tests, Integration Tests (E2E), and Mutation Tests
- The Structured Query Language
- 처지
- HTTP/Express Security Best Practices
- Node Best Practices
- OWASP Security Best Practices
- 그리고 더.
Using that new architecture, in the article after that, we'll write Unit, Integration, and Mutation tests, aiming for close to 100 percent testing coverage, and we'll finally discuss setting up a remote CI/CD pipeline with CircleCI, as well as Message Busses, Job/Task Scheduling, and load balancing/reverse proxying.
Hopefully, this article has been helpful, and if you have any queries or concerns, let me know in the comments below.