
Python의 탐색적 데이터 분석: 알아야 할 사항은 무엇입니까?
게시 됨: 2021-03-12탐색적 데이터 분석(EDA)은 모든 데이터 과학자들이 따르는 매우 일반적이고 중요한 관행입니다. 데이터의 테이블과 테이블을 완전히 이해하기 위해 다양한 각도에서 바라보는 과정입니다. 데이터를 잘 이해하면 데이터를 정리하고 요약하는 데 도움이 됩니다. 그러면 그렇지 않으면 명확하지 않은 통찰력과 추세가 나옵니다.
EDA에는 예를 들어 '데이터 분석'과 같이 따라야 하는 엄격한 규칙이 없습니다. 이 분야를 처음 접하는 사람들은 항상 두 용어를 혼동하는 경향이 있습니다. 이 두 용어는 대부분 비슷하지만 목적이 다릅니다. EDA와 달리 데이터 분석은 다양한 변형 간의 사실과 관계를 밝히기 위해 확률 및 통계적 방법을 구현하는 데 더 치우쳐 있습니다.
돌아와서 EDA를 수행하는 데 옳고 그른 방법은 없습니다. 사람에 따라 다르지만 일반적으로 다음과 같은 몇 가지 주요 지침을 따릅니다.
- 누락된 값 처리: 모든 데이터가 수집 중에 사용 가능하지 않거나 기록되지 않았을 때 Null 값이 표시될 수 있습니다.
- 중복 데이터 제거: 반복 데이터 레코드를 사용하여 기계 학습 알고리즘을 학습하는 동안 생성되는 과적합 또는 편향을 방지하는 것이 중요합니다 .
- 이상값 처리: 이상값 은 나머지 데이터와 크게 다르고 추세를 따르지 않는 레코드입니다. 데이터 수집 중 특정 예외 또는 부정확성으로 인해 발생할 수 있습니다.
- 스케일링 및 정규화: 이것은 수치 데이터 변수에 대해서만 수행됩니다. 대부분의 경우 변수는 범위와 척도가 크게 달라 변수를 비교하고 상관 관계를 찾기가 어렵습니다.
- 단변량 및 이변량 분석: 단변량 분석은 일반적으로 하나의 변수가 대상 변수에 어떻게 영향을 미치는지 확인하여 수행됩니다. 이변량 분석은 2개의 변수 사이에서 수행되며 수치적이거나 범주적이거나 둘 다일 수 있습니다.
여기 에서 Kaggle에서 사용할 수 있는 매우 유명한 'Home Credit Default Risk' 데이터 세트를 사용하여 이들 중 일부를 구현하는 방법을 살펴보겠습니다 . 데이터에는 대출 신청 당시 대출 신청자에 대한 정보가 포함되어 있습니다. 여기에는 두 가지 유형의 시나리오가 포함됩니다.
- 결제에 어려움이 있는 고객 : X일 이상 결제를 연체 한 고객
샘플에서 대출의 첫 번째 Y 할부 중 적어도 하나에서,
- 기타 모든 경우 : 결제가 제때 결제되는 기타 모든 경우.
우리는 이 기사를 위해 애플리케이션 데이터 파일에 대해서만 작업할 것입니다.
관련 항목: Python 프로젝트 아이디어 및 초보자를 위한 주제
목차
데이터 살펴보기
app_data = pd.read_csv( 'application_data.csv' )
app_data.info()
애플리케이션 데이터를 읽은 후 info() 함수를 사용하여 처리할 데이터에 대한 간략한 개요를 얻습니다. 아래 출력은 122개의 변수가 있는 약 300000개의 대출 레코드가 있음을 알려줍니다. 이 중 16개의 범주형 변수와 나머지 숫자가 있습니다.
<클래스 'pandas.core.frame.DataFrame'>
RangeIndex: 307511 항목, 0 ~ 307510
열: 122개 항목, SK_ID_CURR~AMT_REQ_CREDIT_BUREAU_YEAR
dtypes: float64(65), int64(41), 객체(16)
메모리 사용량: 286.2MB 이상
수치 데이터와 범주 데이터를 별도로 처리하고 분석하는 것은 항상 좋은 방법입니다.
범주형 = app_data.select_dtypes(포함 = 개체).columns
app_data[카테고리].apply(pd.Series.nunique, 축 = 0)
아래의 범주형 기능만 보면 대부분의 범주가 간단한 플롯을 사용하여 더 쉽게 분석할 수 있는 몇 가지 범주만 있다는 것을 알 수 있습니다.
NAME_CONTRACT_TYPE 2
CODE_GENDER 3
FLAG_OWN_CAR 2
FLAG_OWN_REALTY 2
NAME_TYPE_SUITE 7
NAME_INCOME_TYPE 8
NAME_EDUCATION_TYPE 5
NAME_FAMILY_STATUS 6
NAME_HOUSING_TYPE 6
직업_유형 18
WEEKDAY_APPR_PROCESS_START 7
ORGANIZATION_TYPE 58
FONDKAPREMONT_MODE 4
HOUSETYPE_MODE 3
WALLSMATERIAL_MODE 7
비상 상태_모드 2
dtype: int64
이제 숫자 기능의 경우 describe() 메서드가 데이터 통계를 제공합니다.
숫자= app_data.describe()
숫자 = 숫자.열
숫자
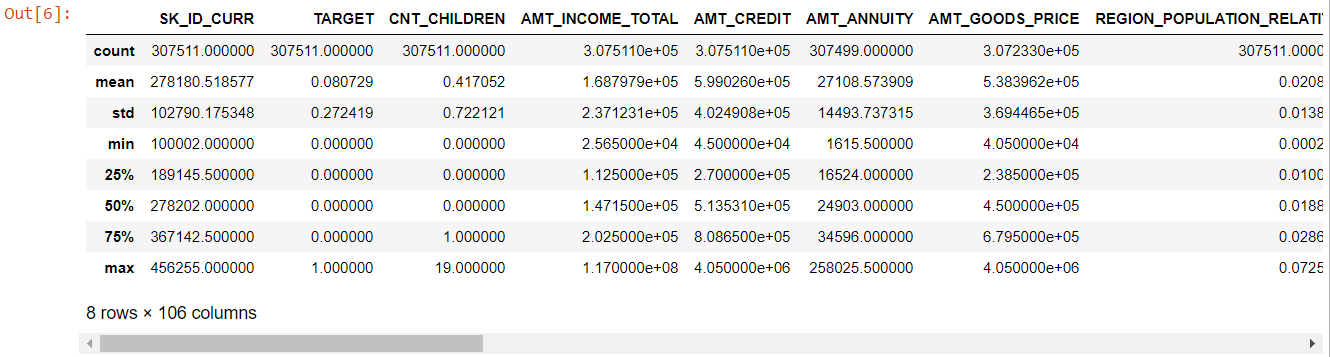
전체 테이블을 보면 다음과 같은 사실이 분명합니다.
- days_born이 음수: 신청일을 기준으로 한 신청자의 나이(일)
- days_Employee에 이상 값이 있습니다(최대값은 약 100년)(635243).
- amt_annuity- 최대 값보다 훨씬 작은 의미
이제 우리는 어떤 기능이 더 분석되어야 하는지 알게 되었습니다.
데이터 누락
Y축을 따라 결측 데이터의 %를 플로팅하여 결측값이 있는 모든 기능의 포인트 플롯을 만들 수 있습니다.

누락 = pd.DataFrame( (app_data.isnull().sum()) * 100 / app_data.shape[0]).reset_index()
plt.Figure(figsize = (16,5))
ax = sns.pointplot('인덱스', 0, 데이터 = 누락)
plt.xticks(회전 = 90, 글꼴 크기 = 7)
plt.title("결측값 비율")
plt.ylabel(“퍼센트”)
plt.show()
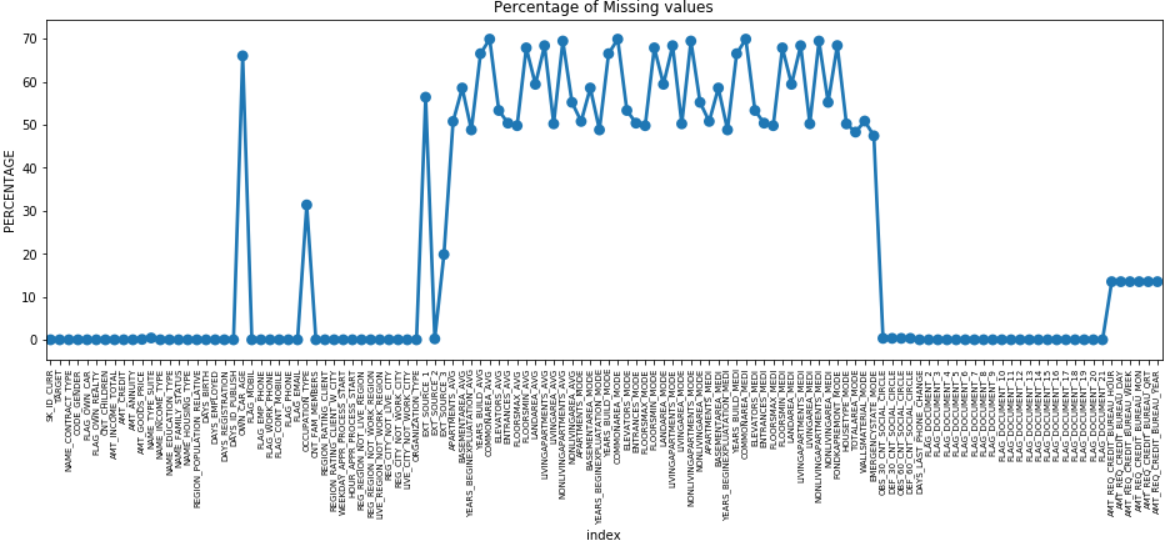
많은 열에는 누락된 데이터가 많고(30-70%), 일부는 누락된 데이터가 거의 없고(13-19%), 많은 열에도 누락된 데이터가 전혀 없습니다. EDA만 수행해야 하는 경우 데이터 세트를 수정할 필요는 없습니다. 그러나 데이터 전처리를 진행하려면 결측값을 처리하는 방법을 알아야 합니다.
결측값이 더 적은 기능의 경우 기능에 따라 회귀를 사용하여 결측값을 예측하거나 존재하는 값의 평균으로 채울 수 있습니다. 그리고 결측값 수가 매우 많은 기능의 경우 분석에 대한 통찰력이 매우 적기 때문에 해당 열을 삭제하는 것이 좋습니다.
데이터 불균형
이 데이터 세트에서 대출 채무 불이행자는 이진 변수 'TARGET'을 사용하여 식별됩니다.
100* 효도
0 91.927118
1 8.072882
이름: TARGET, dtype: float64
데이터가 92:8의 비율로 매우 불균형한 것을 볼 수 있습니다. 대부분의 대출이 제때 상환되었습니다(목표 = 0). 따라서 이러한 엄청난 불균형이 있을 때마다 특성을 취하여 대상 변수와 비교(표적 분석)하여 해당 특성의 어떤 범주가 다른 범주보다 대출을 더 많이 채무 불이행하는 경향이 있는지 확인하는 것이 좋습니다.
다음은 Seaborn Python 라이브러리와 간단한 사용자 정의 함수를 사용하여 만들 수 있는 그래프의 몇 가지 예입니다 .
성별
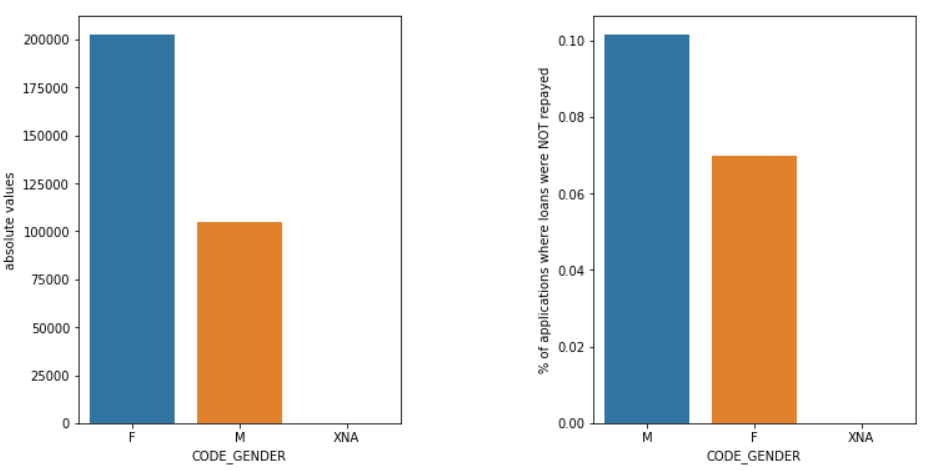
남성(M)은 여성(F)에 비해 여성 지원자가 거의 2배 가까이 많지만 채무 불이행 가능성이 더 높습니다. 따라서 여성은 남성보다 대출 상환에 대해 더 신뢰할 수 있습니다.
교육 유형
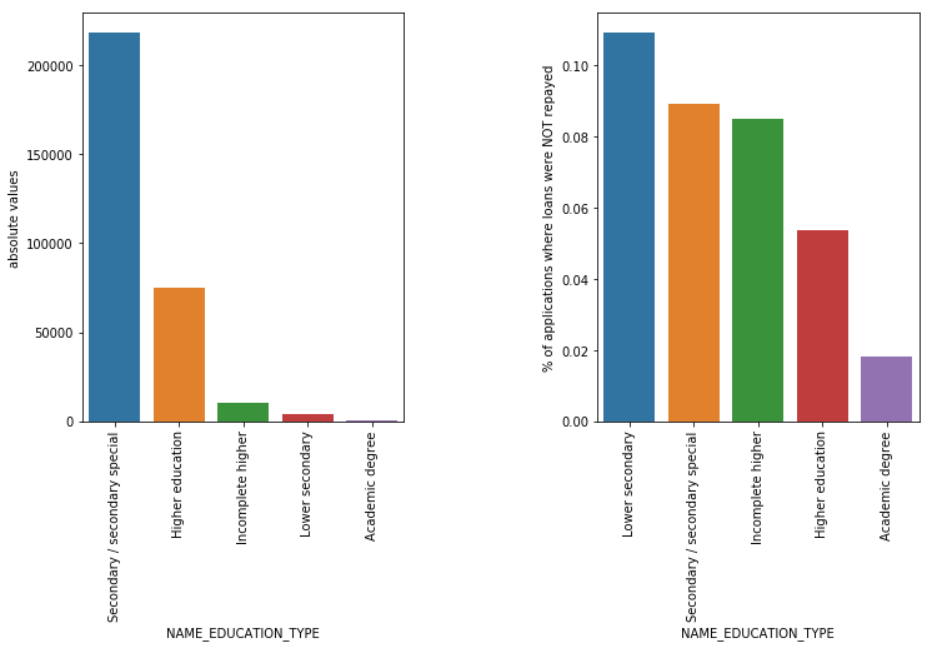
대부분의 학자금 대출은 중등 교육 또는 고등 교육을 위한 것이지만 회사에 가장 위험한 것은 중등 교육 대출이고 그 다음으로 중등 교육 대출입니다.
더 읽어보기: 데이터 과학 경력
결론
위에서 본 이러한 종류의 분석은 은행 및 금융 서비스의 위험 분석에서 광범위하게 수행됩니다. 이러한 방식으로 데이터 아카이브를 사용하여 고객에게 대출하는 동안 손실을 입을 위험을 최소화할 수 있습니다. 다른 모든 분야에서 EDA의 범위는 무궁무진하며 광범위하게 사용해야 합니다.
데이터 과학에 대해 궁금한 점이 있으면 작업 전문가를 위해 만들어졌으며 10개 이상의 사례 연구 및 프로젝트, 실용적인 실습 워크샵, 업계 전문가와의 멘토링, 1- 업계 멘토와 일대일, 400시간 이상의 학습 및 최고의 기업과의 취업 지원.
탐색적 데이터 분석은 데이터 모델링을 시작할 때 초기 수준으로 간주됩니다. 이것은 데이터 모델링을 위한 모범 사례를 분석하는 매우 통찰력 있는 기술입니다. 데이터에서 시각적 플롯, 그래프 및 보고서를 추출하여 완전히 이해할 수 있습니다. 이상치는 데이터의 이상 또는 약간의 편차를 나타냅니다. 데이터 수집 중에 발생할 수 있습니다. 데이터 세트에서 이상치를 감지하는 4가지 방법이 있습니다. 이러한 방법은 다음과 같습니다. 데이터 분석과 달리 EDA에는 엄격하고 빠른 규칙과 규정이 없습니다. 이것이 EDA를 수행하는 올바른 방법이거나 잘못된 방법이라고 말할 수는 없습니다. 초보자는 종종 오해를 받고 EDA와 데이터 분석을 혼동합니다.탐색적 데이터 분석(EDA)이 필요한 이유는 무엇입니까?
EDA는 통계 결과 도출, 누락된 데이터 값 찾기, 잘못된 데이터 입력 처리, 최종적으로 다양한 플롯 및 그래프 추론을 포함하여 데이터를 완전히 분석하기 위한 특정 단계를 포함합니다.
이 분석의 주요 목표는 사용 중인 데이터 세트가 모델링 알고리즘 적용을 시작하기에 적합한지 확인하는 것입니다. 이것이 모델링 단계로 이동하기 전에 데이터에 대해 수행해야 하는 첫 번째 단계인 이유입니다. 이상치는 무엇이며 어떻게 처리합니까?
1. Boxplot - Boxplot은 사분위수를 통해 데이터를 분리하는 이상값을 감지하는 방법입니다.
2. 산점도 - 산점도는 데카르트 평면에 표시된 점 집합의 형태로 2개 변수의 데이터를 표시합니다. 한 변수의 값은 가로축(x-ais)을 나타내고 다른 변수의 값은 세로축(y-축)을 나타냅니다.
3. Z-score - Z-score를 계산할 때 중심에서 멀리 떨어진 지점을 찾아 이상치로 간주합니다.
4. 사분위수 범위(IQR) - 사분위수 범위 또는 IQR은 상위 및 하위 사분위수 또는 75번째 및 25번째 사분위수 간의 차이이며, 종종 통계적 분산이라고도 합니다. EDA를 수행하기 위한 지침은 무엇입니까?
그러나 일반적으로 실행되는 몇 가지 지침이 있습니다.
1. 결측값 처리
2. 중복 데이터 제거
3. 이상치 다루기
4. 스케일링 및 정규화
5. 일변량 및 이변량 분석