
반드시 읽어야 하는 24개의 Datastage 인터뷰 질문 및 답변 [Ultimate Guide 2022]
게시 됨: 2021-01-08Datastage는 InfoSphere 제품군 및 Information Solutions Platforms 제품군에서 IBM이 제공하는 ETL, 즉 추출, 변환 및 로드 도구입니다. 널리 사용되는 ETL 도구이며 대용량 데이터 세트 및 웨어하우스로 작업하여 데이터 리포지토리를 만들고 유지 관리하는 데 사용됩니다. 이 기사에서는 가장 자주 묻는 DataStage 인터뷰 질문 을 살펴보고 이러한 질문에 대한 답변도 제공합니다. 초보자이고 데이터 과학에 대해 더 자세히 알고 싶다면 최고의 대학에서 제공하는 데이터 과학 교육을 확인하십시오.
가장 일반적인 DataStage 인터뷰 질문과 답변 은 다음과 같습니다.
목차
DataStage 인터뷰 질문 및 답변
1. IBM DataStage란 무엇이며 왜 사용합니까?
DataStage는 IBM에서 제공하는 도구로 Windows 서버의 데이터베이스에서 데이터를 추출하여 데이터를 데이터 웨어하우스에 채우는 애플리케이션을 설계, 개발 및 실행하는 데 사용됩니다. 데이터 통합을 위한 그래픽 시각화 기능이 포함되어 있으며 여러 소스에서 데이터를 추출할 수도 있습니다. 따라서 가장 강력한 ETL 도구 중 하나로 간주됩니다. DataStage에는 기업이 요구 사항에 따라 사용할 수 있는 다양한 버전이 있습니다. 버전은 Server Edition, MVS Edition 및 Enterprise Edition입니다.
2. DataStage의 특징은 무엇입니까?
IBM DataStage의 특징은 다음과 같습니다.
- 필요와 요구 사항에 따라 로컬 서버와 클라우드에 배포할 수 있습니다.
- 사용이 간편하며 데이터 통합의 속도와 유연성을 효율적으로 높일 수 있습니다.
- 빅데이터를 지원하며 JDBC 통합자, JSON 지원, 분산 파일 시스템 등 다양한 방식으로 빅데이터에 접근할 수 있다.
3. DataStage 아키텍처를 간략하게 설명하십시오.
IBM DataStage는 아키텍처로 클라이언트-서버 모델을 따르며 다양한 버전에 대해 서로 다른 아키텍처 유형을 가지고 있습니다. 클라이언트-서버 아키텍처의 구성 요소는 다음과 같습니다.
- 클라이언트 구성 요소
- 서버
- 스테이지
- 테이블 정의
- 컨테이너
- 프로젝트
- 채용 정보
4. DataStage에서 명령줄을 사용하여 작업을 실행하려면 어떻게 해야 합니까?
명령은 다음과 같습니다. dsjob -run -jobstatus <프로젝트 이름> <작업 이름>
5. 'dsjob' 명령을 사용하여 실행할 수 있는 몇 가지 기능을 나열하십시오.
$dsjob 명령을 사용하여 수행할 수 있는 다양한 기능은 다음과 같습니다.
- $dsjob -run: DataStage 작업을 실행하는 데 사용됩니다.
- $dsjob -stop: 현재 프로세스에 있는 작업을 중지하는 데 사용됩니다.
- $dsjob -jobid: 작업 정보 제공에 사용
- $dsjob -report: 전체 작업 보고서를 표시하는 데 사용됩니다.
- $dsjob -lprojects: 존재하는 모든 프로젝트를 나열하는 데 사용됩니다.
- $dsjob -ljobs: 프로젝트에 있는 모든 작업을 나열하는 데 사용됩니다.
- $dsjob -lstages: 현재 작업의 모든 단계를 나열하는 데 사용됩니다.
- $dsjob -llinks: 모든 링크를 나열하는 데 사용됩니다.
- $dsjobs -lparams: 작업의 모든 매개변수를 나열하는 데 사용됩니다.
- $dsjob -projectinfo: 프로젝트에 대한 정보를 검색하는 데 사용됩니다.
- $dsjob -jobinfo: 작업의 정보 검색에 사용됩니다.
- $dsjob -stageinfo: 해당 작업의 해당 단계에 대한 정보 검색에 사용됩니다.
- $dsjob -linkinfo: 해당 링크의 정보를 얻기 위해 사용
- $dsjob -paraminfo: 모든 매개변수의 정보를 제공합니다.
- $dsjob -loginfo: 로그에 대한 정보를 얻기 위해 사용
- $dsjob -log: 로그에 텍스트 메시지를 추가할 때 사용
- $dsjob -logsum: 로그 데이터를 표시하는 데 사용됩니다.
- $dsjob -logdetail: 로그의 모든 세부 정보를 표시하는 데 사용됩니다.
- $dsjob -lognewest: 최신 로그의 ID를 검색하는 데 사용됩니다.
6. IBM DataStage에서 플로우 디자이너란 무엇입니까?
Flow Designer는 DataStage의 웹 기반 사용자 인터페이스이며 DataStage에서 작업을 생성, 편집, 로드 및 실행하는 데 사용됩니다.
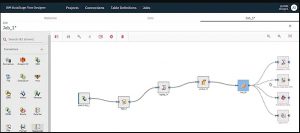
원천
7. Flow Designer의 주요 기능은 무엇입니까?
흐름 디자이너의 주요 기능은 다음과 같습니다.
- 단계가 많은 작업을 수행하는 데 매우 유용합니다.
- 흐름 디자이너를 사용하기 위해 작업을 마이그레이션할 필요가 없습니다.
- 제공된 팔레트를 사용하여 끌어서 놓기 기능을 사용하여 디자이너 캔버스에서 커넥터와 연산자를 추가 및 제거할 수 있습니다.
자세히 알아보기: 데이터 과학 대 데이터 마이닝: 데이터 과학과 데이터 마이닝의 차이점
8. DataStage에서 서버 작업을 병렬 작업으로 변환하는 방법은 무엇입니까?
링크 수집기와 IPC 수집기를 사용하여 서버 작업을 병렬 작업으로 변환할 수 있습니다.
9 . HBase 커넥터란 무엇입니까?
DataStage의 HBase 커넥터는 HBase 데이터베이스에 있는 데이터베이스와 테이블을 연결하는 데 사용되는 도구입니다. 주로 다음 작업을 수행하는 데 사용됩니다.
- HBase 데이터베이스에서 데이터를 읽고 씁니다.
- 병렬 모드에서 데이터 읽기.
- HBase를 뷰 테이블로 사용하기
10. Hive 커넥터란 무엇입니까?
Hive 커넥터는 데이터를 읽는 동안 파티션 모드를 지원하는 데 사용되는 도구입니다. 두 가지 방법으로 수행할 수 있습니다.
- 모듈러스 파티션 모드
- 최소-최대 파티션 모드
11. DataStage에서 Infosphere란 무엇입니까?

infosphere 정보 서버는 기업의 대용량 요구 사항을 관리할 수 있으며 고품질의 빠른 결과를 제공합니다. 이는 기업이 방대한 양의 정보를 이해, 정리, 변환 및 전달할 수 있는 데이터 관리를 위한 단일 플랫폼을 제공합니다.

원천
12. InfoSphere Information Server의 다른 모든 계층을 나열합니까?
InfoSphere Information Server의 다양한 계층은 다음과 같습니다.
- 클라이언트 계층
- 서비스 계층
- 엔진 계층
- 메타데이터 저장소 계층
13. Infosphere Information Server의 클라이언트 계층에 대해 간략하게 설명합니다.
Infosphere Information Server의 클라이언트 계층은 클라이언트 프로그램과 콘솔을 사용하여 컴퓨터를 개발하고 전체 관리하는 데 사용됩니다.
14. Infosphere Information Server의 서비스 계층에 대해 간략하게 설명하십시오.
Infosphere Information Server의 서비스 계층은 메타데이터, 로깅 및 기타 모듈별 서비스와 같은 표준 서비스를 제공하는 데 사용됩니다. 여기에는 애플리케이션 서버, 다양한 제품 모듈 및 기타 제품 서비스가 포함됩니다.
15. Infosphere Information Server의 엔진 계층에 대해 간략하게 설명합니다.
Infosphere Information Server의 엔진 계층은 제품 모듈에 대한 작업 및 기타 작업을 실행하는 데 사용되는 논리적 구성 요소 집합입니다.
16. Infosphere Information Server의 Metadata Repository 계층에 대해 간략하게 설명합니다.
Infosphere Information Server의 메타데이터 저장소 계층에는 메타데이터 저장소, 분석 데이터베이스 및 컴퓨터가 포함됩니다. 메타데이터, 공유 데이터 및 구성 정보를 공유하는 데 사용됩니다.
17. DataStage의 병렬 처리 유형은 무엇입니까?
병렬 처리에는 다음과 같은 두 가지 유형이 있습니다.
- 데이터 분할
- 데이터 파이프라이닝
18 . 데이터 파티셔닝이란 무엇입니까?
데이터 분할은 데이터 처리를 위한 일종의 병렬 접근 방식입니다. 여기에는 처리를 위해 레코드를 파티션으로 나누는 프로세스가 포함됩니다. 선형 모델에서 처리 효율성을 높입니다.
더 읽어보기: 머신 러닝의 데이터 전처리: 따라야 할 7가지 쉬운 단계
19. 데이터 파이프라이닝이란 무엇입니까?
데이터 파이프라이닝은 소스에서 데이터 추출을 수행한 다음 필요한 출력을 얻기 위해 일련의 처리 기능을 통과하도록 하는 데이터 처리를 위한 일종의 병렬 접근 방식입니다.
20. DataStage에서 OSH란 무엇입니까?
OSH는 Orchestrate Shell의 약자로 병렬 엔진에서 내부적으로 DataStage에서 사용하는 스크립팅 언어입니다.
21. 플레이어란 무엇입니까?
DataStage의 플레이어는 핵심 프로세스입니다. 그것들은 병렬 처리를 수행하는 데 도움이 되며 각 노드의 운영자에게 할당됩니다.
22. DataStage의 컬렉션 라이브러리란 무엇입니까?
컬렉션 라이브러리는 연산자 집합이며 분할된 데이터를 수집하는 데 사용됩니다.
23. DataStage의 컬렉션 라이브러리에서 사용할 수 있는 수집기 유형은 무엇입니까?
컬렉션 라이브러리에서 사용할 수 있는 수집기 유형은 다음과 같습니다.
- Sortmerge 수집기
- 라운드 로빈 수집기
- 주문한 수집가
24. DataStage에서 소스 파일은 어떻게 채워집니까?
소스 파일은 SQL 쿼리와 행 생성기 추출 도구를 사용하여 채울 수 있습니다.
결론
모든 DataStage 인터뷰 질문과 답변 이 포함된 기사가 DataStage 인터뷰 를 준비하는 데 도움이 되었기를 바랍니다. upGrad에서 제공하는 다음 과정을 살펴보고 다음 주제에 대한 지식을 높일 수 있습니다.
- PG 디플로마 소프트웨어 개발 빅 데이터 전문화 : 이 과정은 개인에게 소프트웨어 개발에 필요한 지식을 제공하고 빅 데이터 관리에 대한 지식을 다룹니다.
- 풀 스택 개발의 PGC : 이 풀 스택 개발 과정은 upGrad와 Tech Mahindra의 업계 전문가가 만든 것으로 개인이 업계 수준의 문제를 해결하고 업계에 진입하고 일하는 데 필요한 모든 기술을 습득할 수 있도록 합니다.
upGrad 는 항상 여러분의 준비를 도와드립니다. 또한 우리가 항상 '라호 야심찬'이라고 말하듯이 면접과 미래의 직업 야망을 잘 준비하기 위해 업계에서 요구하는 모든 기술과 기술을 배우는 데 도움이 될 수 있는 과정을 볼 수 있습니다. 이 과정은 업계 전문가와 경험 많은 학자들이 만들고자 하는 기술과 기술에 능숙해질 수 있도록 합니다.
파이썬을 배우는 데 관심이 있고 다양한 도구와 라이브러리에 손을 대고 싶다면 데이터 과학의 Executive PG Program을 확인하십시오.
Datastage의 4가지 주요 단계는 무엇입니까?
IBM Datastage는 데이터베이스에서 데이터를 추출하여 데이터를 데이터 웨어하우스에 채우는 애플리케이션을 설계, 개발 및 실행하기 위한 강력한 도구입니다. 다음은 Datastage의 4가지 주요 단계입니다. 관리자는 DataStage 사용자 설정 및 기준 제거, 프로젝트 이동 및 이동 해제 등을 포함하는 관리 작업에 사용됩니다. 디자이너 또는 디자인 인터페이스는 Director가 규제하고 서버에서 실행하는 Datastage 응용 프로그램 또는 작업을 개발합니다. 이름에서 알 수 있듯이 관리자는 저장소를 유지 관리하고 사용자가 저장소를 통해 저장된 데이터를 수정할 수 있도록 합니다. Director는 병렬 작업 모니터링과 함께 작업 유효성 검사, 예약 및 실행을 비롯한 다양한 기능을 수행합니다.
어떤 목적으로 "dsjob" 명령이 사용됩니까?
dsjob 명령은 프로젝트 또는 작업에 대한 데이터 검색 및 표시를 비롯한 다양한 기능에 사용됩니다. 다음은 dsjob 명령을 사용하여 실행할 수 있는 몇 가지 기능입니다. $dsjob -run은 DataStage 작업을 실행하는 데 사용되며, $dsjob -stop은 현재 프로세스에 있는 작업을 중지하는 데 사용되며 $dsjob -jobid는 작업 정보를 제공하는 데 사용되며 $dsjob -report는 전체 작업 보고서를 표시하는 데 사용됩니다. , 등.
DataStage의 특징은 무엇입니까?
Datastage는 강력한 데이터 아키텍처 도구이며 다양한 특성을 가지고 있습니다. Datastage의 몇 가지 특징은 다음과 같습니다. Datastage는 사용자 요구 사항에 따라 로컬 서버와 클라우드 서버에 배포할 수 있습니다. 데이터 통합의 속도와 유연성은 언제든지 증가할 수 있고 효율적으로 사용할 수 있습니다. 빅데이터를 지원하며 JDBC 통합자, JSON 지원, 분산 파일 시스템 등 다양한 방식으로 빅데이터에 접근할 수 있다.