
C의 데이터 구조는 무엇이며 어떻게 사용합니까?
게시 됨: 2021-02-26목차
소개
우선, 데이터 구조는 하나의 이름이나 제목으로 함께 보관되는 데이터 항목의 모음이며 데이터를 효율적으로 사용할 수 있도록 데이터를 저장하고 조합하는 특정 방법입니다.
유형
데이터 구조는 널리 퍼져 있으며 거의 모든 소프트웨어 시스템에서 사용됩니다. 데이터 구조의 가장 일반적인 예로는 배열, 대기열, 스택, 연결 목록 및 트리가 있습니다.
애플리케이션
컴파일러, 운영 체제, 데이터베이스, 인공 지능 응용 프로그램 등을 설계하는 데 사용됩니다.
분류
데이터 구조는 원시 데이터 구조와 비원시 데이터 구조의 두 가지 범주로 분류됩니다.
1. 기본: 프로그래밍 언어에서 지원하는 기본 데이터 유형입니다. 이 분류의 일반적인 예는 정수, 문자 및 부울입니다.
2. 비 기본: 이러한 데이터 구조 범주는 기본 데이터 구조를 사용하여 생성됩니다. 예로는 연결 스택, 연결 목록, 그래프 및 트리가 있습니다.

배열
배열은 데이터 유형이 동일한 데이터 요소의 단순한 모음입니다. 즉, 정수 유형의 배열은 정수 값만 저장할 수 있습니다. float 데이터 유형의 배열은 float 데이터 유형에 해당하는 값만 저장할 수 있습니다.
배열에 저장된 요소는 선형으로 액세스할 수 있으며 인덱스를 사용하여 참조할 수 있는 연속 메모리 블록에 있습니다.
배열 선언
C에서 배열은 다음과 같이 선언할 수 있습니다.
데이터 유형 이름[길이];
예를 들어,
정수 주문[10];
위의 코드 줄은 정수 값을 저장할 수 있는 10개의 메모리 블록 배열을 만듭니다. C에서 배열 인덱스 값은 0부터 시작합니다. 따라서 인덱스 값의 범위는 0에서 9까지입니다. 해당 배열의 특정 값에 액세스하려면 다음을 입력하기만 하면 됩니다.
printf(주문[색인번호]);
배열을 선언하는 또 다른 방법은 다음과 같습니다.
data_type array_name[크기]={값 목록};
예를 들어,
정수 표시[5]={9, 8, 7, 9, 8};
위의 명령 줄은 각 블록에 고정 값이 있는 5개의 메모리 블록이 있는 배열을 만듭니다. 32비트 컴파일러에서 int 데이터 유형이 차지하는 32비트 메모리는 4바이트입니다. 따라서 5개의 메모리 블록은 20바이트의 메모리를 차지합니다.
배열을 초기화하는 또 다른 합법적인 방법은 다음과 같습니다.
정수 표시 [5] = {9, 45};
이 명령은 5개 블록의 배열을 생성하며 마지막 3개 블록은 값으로 0을 갖습니다.
또 다른 합법적인 방법은 다음과 같습니다.
정수 표시 [] = {9, 5, 2, 1, 3,4};
C 컴파일러는 이러한 데이터를 배열에 맞추는 데 5개의 블록만 필요하다는 것을 이해합니다. 따라서 크기가 5인 이름 표시의 배열을 초기화합니다.
유사하게, 2차원 배열은 다음과 같은 방식으로 초기화될 수 있습니다.
정수 표시[2][3]={{9,7,7},{6, 2, 1}};
위의 명령은 2개의 행과 3개의 열이 있는 2차원 배열을 생성합니다.
읽기: 데이터 구조 프로젝트 아이디어 및 주제
운영
어레이에서 수행할 수 있는 몇 가지 작업이 있습니다. 예를 들어:
- 배열 순회
- 배열에 요소 삽입
- 배열에서 특정 요소 검색
- 배열에서 특정 요소 삭제
- 두 배열을 병합하고,
- 배열 정렬 - 오름차순 또는 내림차순.
단점
어레이에 할당된 메모리는 고정되어 있습니다. 이것은 실제로 문제입니다. 크기가 50인 배열을 만들고 30개의 메모리 블록에만 액세스했다고 가정해 보겠습니다. 나머지 20개 블록은 사용하지 않고 메모리를 차지합니다. 따라서 이 문제를 해결하기 위해 연결 목록이 있습니다.
연결 목록
연결 목록은 배열과 매우 유사하게 데이터를 직렬로 저장합니다. 주요 차이점은 모든 것을 한 번에 저장하지 않는다는 것입니다. 대신 데이터를 저장하거나 필요할 때 메모리 블록을 사용할 수 있도록 합니다. 연결 목록에서 블록은 두 부분으로 나뉩니다. 첫 번째 부분은 실제 데이터를 포함합니다.
두 번째 부분은 연결 목록의 다음 블록을 가리키는 포인터입니다. 포인터는 데이터를 보유하고 있는 다음 블록의 주소를 저장합니다. 헤드 포인터로 알려진 포인터가 하나 더 있습니다. head는 연결 리스트의 첫 번째 메모리 블록을 가리킵니다. 다음은 연결 리스트를 표현한 것입니다. 이러한 블록을 '노드'라고도 합니다.

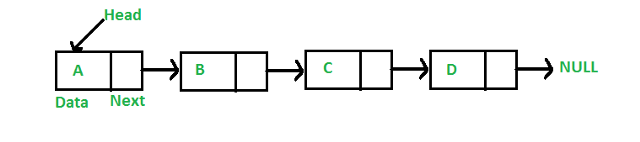
원천
연결 목록 초기화
링크 목록을 초기화하기 위해 구조 이름 노드를 생성합니다. 구조에는 두 가지가 있습니다. 1. 보유하고 있는 데이터 및 2. 다음 노드를 가리키는 포인터. 포인터의 데이터 유형은 구조 노드를 가리키는 구조의 데이터 유형입니다.
구조체 노드
{
정수 데이터;
구조체 노드 *다음;
};
연결 목록에서 마지막 노드의 포인터는 아무 것도 가리키지 않거나 단순히 null을 가리킵니다.
더 읽어보기: 데이터 구조의 그래프
연결 목록 순회
연결 목록에서 마지막 노드의 포인터는 아무 것도 가리키지 않거나 단순히 null을 가리킵니다. 따라서 전체 연결 목록을 순회하기 위해 처음에 머리를 가리키는 더미 포인터를 만듭니다. 그리고 연결 목록의 길이에 대해 포인터는 null을 가리키거나 연결 목록의 마지막 노드에 도달할 때까지 계속 앞으로 이동합니다.
노드 추가
특정 노드 앞에 노드를 추가하는 알고리즘은 다음과 같습니다.
- 처음에 머리를 가리키는 두 개의 더미 포인터(ptr 및 preptr)를 설정합니다.
- 노드를 삽입하기 전에 ptr.data가 데이터와 같아질 때까지 ptr을 이동합니다. preptr은 ptr보다 1노드 뒤에 있습니다.
- 노드 생성
- 더미 preptr이 가리키는 노드, 해당 노드의 다음 노드는 이 새 노드를 가리킵니다.
- 새 노드의 다음은 ptr을 가리킵니다.
특정 데이터 뒤에 노드를 추가하는 알고리즘도 비슷한 방식으로 수행됩니다.
연결 리스트의 장점
- 배열과 달리 동적 크기
- 삽입 및 삭제를 수행하는 것은 배열보다 연결 목록에서 더 쉽습니다.
대기 줄
대기열은 선입선출 또는 FIFO 유형의 시스템을 따릅니다. 배열 구현에서 Queue의 사용 사례를 보여주기 위해 두 개의 포인터가 있습니다.
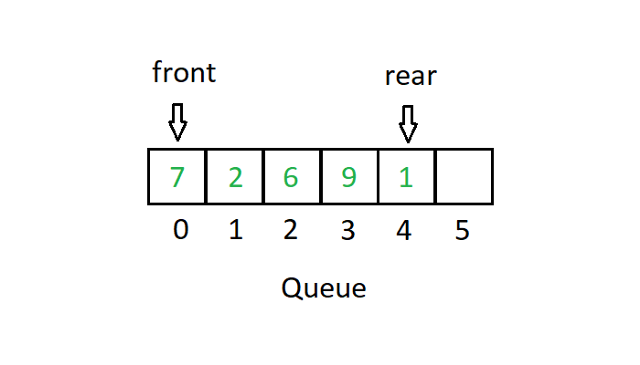
원천
FIFO는 기본적으로 스택에 먼저 들어가는 값이 배열을 먼저 떠나는 것을 의미합니다. 위의 대기열 다이어그램에서 포인터 front는 값 7을 가리킵니다. 첫 번째 블록을 삭제하면(dequeue), front는 이제 값 2를 가리킵니다. 마찬가지로 숫자(enqueue)를 입력하면 in 위치 5. 그러면 후면 포인터가 위치 5를 가리킵니다.
오버플로 및 언더플로 조건
그럼에도 불구하고 큐에 데이터 값을 입력하기 전에 오버플로 조건을 확인해야 합니다. 이미 가득 찬 큐에 요소를 삽입하려고 하면 오버플로가 발생합니다. 후면 = max_size–1이면 대기열이 가득 찰 것입니다.
마찬가지로 큐에서 데이터를 삭제하기 전에 언더플로 조건을 확인해야 합니다. 언더플로는 이미 비어 있는 큐에서 요소를 삭제하려는 시도가 있을 때 발생합니다. 즉, front = null 및 rear = null인 경우 큐는 비어 있습니다.
스택
스택은 스택의 맨 위라고도 하는 한쪽 끝에만 요소를 삽입하고 삭제하는 데이터 구조입니다. 따라서 스택 구현을 LIFO(후입선출) 구현이라고 합니다. 큐와 달리 스택의 경우 상단 포인터가 하나만 필요합니다.
배열에 요소를 입력(푸시)하려면 위쪽 포인터가 위로 이동하거나 1씩 증가합니다. 요소를 삭제(팝)하려면 위쪽 포인터가 1만큼 감소하거나 1단위 아래로 내려갑니다. 스택은 푸시, 팝, 엿보기의 세 가지 기본 작업을 지원합니다. Peep 작업은 단순히 스택의 최상위 요소를 표시하는 것입니다.
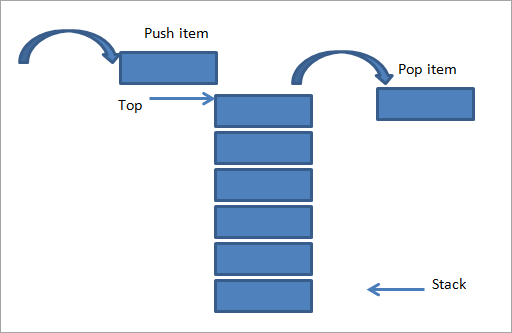
원천
세계 최고의 대학에서 온라인으로 소프트웨어 과정을 배우십시오 . 이그 제 큐 티브 PG 프로그램, 고급 인증 프로그램 또는 석사 프로그램을 획득하여 경력을 빠르게 추적하십시오.
결론
이 기사에서는 배열, 연결 목록, 대기열 및 스택의 4가지 유형의 데이터 구조에 대해 이야기했습니다. 이 기사가 마음에 드셨기를 바라며 더 흥미로운 읽을 거리를 계속 지켜봐 주시기 바랍니다. 다음 시간까지.
Javascript, 전체 스택 개발에 대해 자세히 알아보려면 작업 전문가를 위해 설계되었으며 500시간 이상의 엄격한 교육, 9개 이상의 프로젝트를 제공하는 upGrad & IIIT-B의 전체 스택 소프트웨어 개발 Executive PG 프로그램을 확인하십시오. , 과제, IIIT-B 동문 상태, 실질적인 실습 캡스톤 프로젝트 및 최고의 기업과의 취업 지원.
프로그래밍에서 데이터 구조는 무엇입니까?
데이터 구조는 프로그램에서 데이터를 정렬하는 방식입니다. 가장 중요한 두 가지 데이터 구조는 배열과 연결 목록입니다. 배열은 가장 친숙한 데이터 구조이며 가장 이해하기 쉽습니다. 배열은 기본적으로 관련 항목의 번호가 매겨진 목록입니다. 그들은 이해하고 사용하기 쉽지만 많은 양의 데이터로 작업할 때는 그다지 효율적이지 않습니다. 연결 목록은 더 복잡하지만 적절하게 사용하면 매우 효율적일 수 있습니다. 큰 목록 중간에 항목을 추가하거나 제거해야 하거나 큰 목록에서 항목을 검색해야 할 때 좋은 선택입니다.
연결 목록과 배열의 차이점은 무엇입니까?
배열에서 인덱스는 요소에 액세스하는 데 사용됩니다. 배열의 요소는 순차적으로 구성되어 인덱스를 사용하는 경우 요소에 쉽게 액세스하고 수정할 수 있습니다. 배열의 크기도 고정되어 있습니다. 요소는 생성 시 할당됩니다. 연결 목록에서 포인터는 요소에 액세스하는 데 사용됩니다. 연결 목록의 요소는 반드시 순차적으로 저장되지 않습니다. 연결 목록은 생성 당시 노드를 포함할 수 있으므로 크기를 알 수 없습니다. 포인터는 요소에 액세스하는 데 사용되므로 메모리 할당이 더 쉽습니다.
C에서 포인터란?
포인터는 모든 변수 또는 함수의 주소를 저장하는 C의 데이터 유형입니다. 일반적으로 다른 메모리 위치에 대한 참조로 사용됩니다. 포인터는 배열, 구조, 함수 또는 기타 유형의 메모리 주소를 보유할 수 있습니다. C는 포인터를 사용하여 함수에 값을 전달하고 함수에서 값을 받습니다. 포인터는 메모리 공간을 동적으로 할당하는 데 사용됩니다.