
머신 러닝의 데이터 전처리: 따라야 할 7가지 쉬운 단계
게시 됨: 2021-07-15머신 러닝의 데이터 전처리는 데이터에서 의미 있는 통찰력의 추출을 촉진하기 위해 데이터 품질을 향상시키는 데 도움이 되는 중요한 단계입니다. 기계 학습에서 데이터 전처리는 기계 학습 모델을 구축하고 훈련하는 데 적합하도록 원시 데이터를 준비(정리 및 구성)하는 기술을 말합니다. 간단히 말해서 머신 러닝의 데이터 전처리는 원시 데이터를 이해하고 읽을 수 있는 형식으로 변환하는 데이터 마이닝 기술입니다.
목차
머신 러닝에서 데이터 전처리를 하는 이유
머신 러닝 모델을 생성할 때 데이터 사전 처리는 프로세스 시작을 표시하는 첫 번째 단계입니다. 일반적으로 실제 데이터는 불완전하고 일관성이 없으며 정확하지 않으며(오류 또는 이상값 포함) 특정 속성 값/트렌드가 부족한 경우가 많습니다. 여기에서 데이터 사전 처리가 시나리오에 들어갑니다. 원시 데이터를 정리, 형식 지정 및 구성하여 기계 학습 모델에 사용할 준비가 되도록 만드는 데 도움이 됩니다. 머신 러닝에서 데이터 전처리의 다양한 단계를 살펴보겠습니다.
세계 최고의 대학에서 온라인으로 인공 지능 과정 (석사, 대학원 대학원 프로그램, ML 및 AI 고급 인증 프로그램)에 참여하여 경력을 빠르게 추적하십시오 .
머신 러닝의 데이터 전처리 단계
머신 러닝의 데이터 전처리에는 7가지 중요한 단계가 있습니다.
1. 데이터세트 획득
데이터 세트를 획득하는 것은 머신 러닝에서 데이터 전처리의 첫 번째 단계입니다. 기계 학습 모델을 구축하고 개발하려면 먼저 관련 데이터 세트를 가져와야 합니다. 이 데이터 세트는 여러 이질적인 소스에서 수집된 데이터로 구성되며, 이 데이터는 데이터 세트를 형성하기 위해 적절한 형식으로 결합됩니다. 데이터세트 형식은 사용 사례에 따라 다릅니다. 예를 들어 비즈니스 데이터 세트는 의료 데이터 세트와 완전히 다릅니다. 비즈니스 데이터 세트에는 관련 산업 및 비즈니스 데이터가 포함되지만 의료 데이터 세트에는 의료 관련 데이터가 포함됩니다.
https://www.kaggle.com/uciml/datasets 및 https://archive.ics.uci.edu/ml/index.php 와 같은 데이터 세트를 다운로드할 수 있는 여러 온라인 소스가 있습니다 . 다른 Python API를 통해 데이터를 수집하여 데이터 세트를 생성할 수도 있습니다. 데이터 세트가 준비되면 CSV, HTML 또는 XLSX 파일 형식으로 저장해야 합니다.

2. 모든 중요한 라이브러리 가져오기
Python은 전 세계 데이터 과학자들이 가장 광범위하게 사용하고 가장 선호하는 라이브러리이기 때문에 Machine Learning에서 데이터 전처리를 위해 Python 라이브러리를 가져오는 방법을 보여 드리겠습니다. 여기에서 데이터 과학용 Python 라이브러리에 대해 자세히 알아보세요. 사전 정의된 Python 라이브러리는 특정 데이터 사전 처리 작업을 수행할 수 있습니다. 모든 중요한 라이브러리를 가져오는 것은 기계 학습에서 데이터 전처리의 두 번째 단계입니다. 기계 학습에서 이 데이터 사전 처리에 사용되는 세 가지 핵심 Python 라이브러리는 다음과 같습니다.
- NumPy – NumPy는 Python의 과학적 계산을 위한 기본 패키지입니다. 따라서 코드에 모든 유형의 수학 연산을 삽입하는 데 사용됩니다. NumPy를 사용하면 코드에 큰 다차원 배열과 행렬을 추가할 수도 있습니다.
- Pandas – Pandas는 데이터 조작 및 분석을 위한 우수한 오픈 소스 Python 라이브러리입니다. 데이터 세트를 가져오고 관리하는 데 광범위하게 사용됩니다. 고성능의 사용하기 쉬운 데이터 구조와 Python용 데이터 분석 도구가 포함되어 있습니다.
- Matplotlib – Matplotlib는 Python에서 모든 유형의 차트를 그리는 데 사용되는 Python 2D 플로팅 라이브러리입니다. 플랫폼(IPython 셸, Jupyter 노트북, 웹 애플리케이션 서버 등) 전반에 걸쳐 다양한 하드카피 형식과 대화형 환경에서 출판 수준의 수치를 제공할 수 있습니다.
읽기 : 초보자를 위한 기계 학습 프로젝트 아이디어
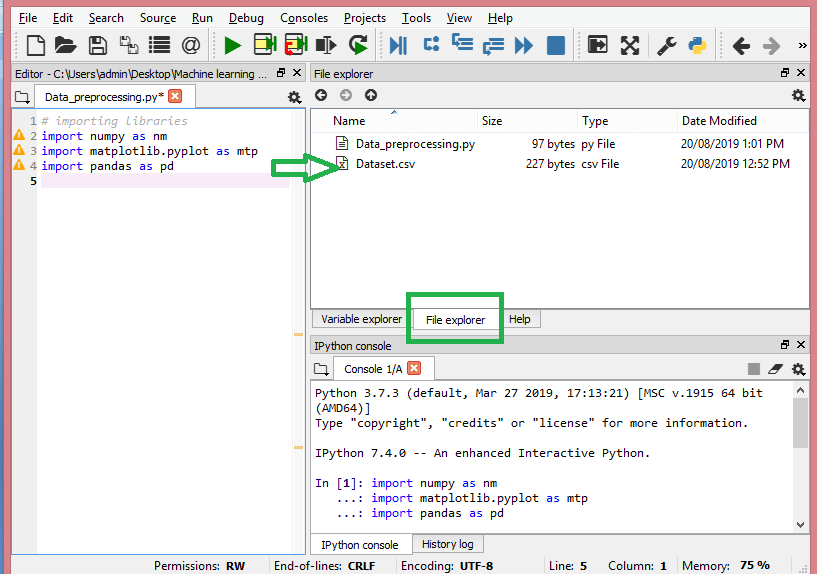
3. 데이터세트 가져오기
이 단계에서는 현재 ML 프로젝트에 대해 수집한 데이터 세트를 가져와야 합니다. 데이터 세트 가져오기는 머신 러닝에서 데이터 사전 처리의 중요한 단계 중 하나입니다. 그러나 데이터 세트를 가져오기 전에 현재 디렉토리를 작업 디렉토리로 설정해야 합니다. Spyder IDE의 작업 디렉토리는 간단한 3단계로 설정할 수 있습니다.
- 데이터 세트가 포함된 디렉토리에 Python 파일을 저장합니다.
- Spyder IDE의 파일 탐색기 옵션으로 이동하여 필요한 디렉터리를 선택합니다.
- 이제 F5 버튼이나 실행 옵션을 클릭하여 파일을 실행합니다.
원천
이것이 작업 디렉토리의 모습입니다.
관련 데이터셋이 포함된 작업 디렉터리를 설정한 후 Pandas 라이브러리의 "read_csv()" 함수를 사용하여 데이터셋을 가져올 수 있습니다. 이 기능은 CSV 파일(로컬 또는 URL을 통해)을 읽고 다양한 작업을 수행할 수도 있습니다. read_csv()는 다음과 같이 작성됩니다.
data_set= pd.read_csv('Dataset.csv')
이 코드 줄에서 "data_set"은 데이터 세트를 저장한 변수의 이름을 나타냅니다. 함수에는 데이터 세트의 이름도 포함됩니다. 이 코드를 실행하면 데이터세트를 성공적으로 가져옵니다.
데이터 세트를 가져오는 동안 종속 및 독립 변수를 추출하는 또 다른 필수 작업이 있습니다. 모든 기계 학습 모델에 대해 데이터 세트에서 독립 변수(기능 행렬)와 종속 변수를 분리해야 합니다.
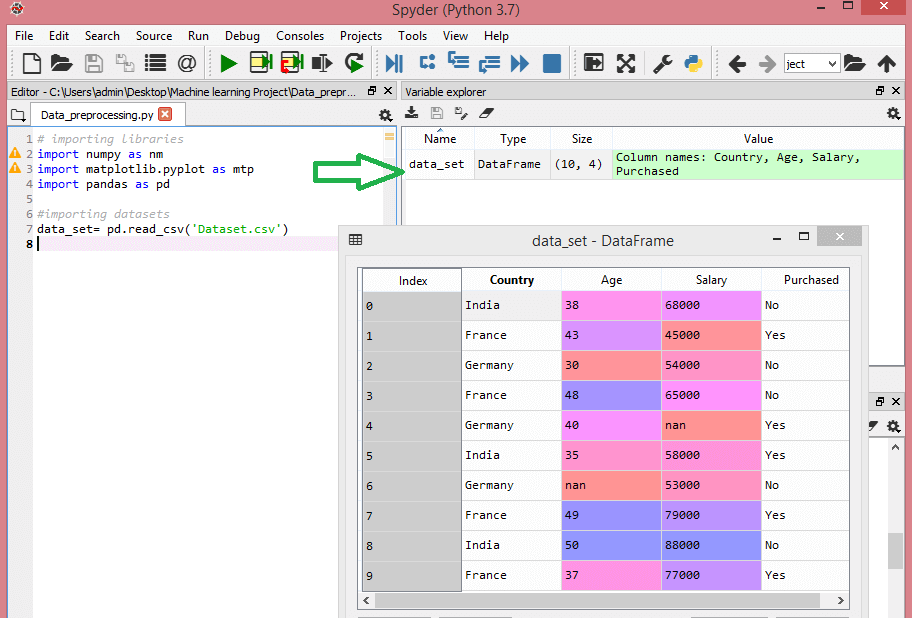
다음 데이터 세트를 고려하십시오.
원천
이 데이터 세트에는 국가, 연령 및 급여의 세 가지 독립 변수와 구매한 하나의 종속 변수가 포함되어 있습니다.
독립 변수를 추출하는 방법은 무엇입니까?
독립변수를 추출하기 위해 Pandas 라이브러리의 “iloc[ ]” 함수를 사용할 수 있습니다. 이 함수는 데이터세트에서 선택한 행과 열을 추출할 수 있습니다.
x= data_set.iloc[:,:-1].값
위의 코드 줄에서 첫 번째 콜론(:)은 모든 행을 고려하고 두 번째 콜론(:)은 모든 열을 고려합니다. 종속 변수를 포함하는 마지막 열을 생략해야 하므로 코드에는 ":-1"이 포함됩니다. 이 코드를 실행하면 다음과 같은 기능 매트릭스를 얻을 수 있습니다.
[['인도' 38.0 68000.0]
['프랑스' 43.0 45000.0]
['독일' 30.0 54000.0]
['프랑스' 48.0 65000.0]
['독일' 40.0 nan]
['인도' 35.0 58000.0]
['독일' nan 53000.0]
['프랑스' 49.0 79000.0]
['인도' 50.0 88000.0]
['프랑스' 37.0 77000.0]]
종속 변수를 추출하는 방법은 무엇입니까?
"iloc[ ]" 함수를 사용하여 종속 변수도 추출할 수 있습니다. 작성 방법은 다음과 같습니다.
y= data_set.iloc[:,3].값
이 코드 줄은 마지막 열만 있는 모든 행을 고려합니다. 위의 코드를 실행하면 다음과 같은 종속 변수 배열을 얻을 수 있습니다.
array(['아니요', '예', '아니요', '아니요', '예', '예', '아니요', '예', '아니요', '예'],
dtype=객체)
4. 결측값 식별 및 처리
데이터 전처리에서는 누락된 값을 식별하고 올바르게 처리하는 것이 중요합니다. 이를 수행하지 않으면 데이터에서 부정확하고 잘못된 결론과 추론을 이끌어낼 수 있습니다. 말할 필요도 없이 이것은 ML 프로젝트를 방해할 것입니다.
기본적으로 누락된 데이터를 처리하는 두 가지 방법이 있습니다.
- 특정 행 삭제 – 이 방법에서는 기능에 대해 null 값이 있는 특정 행이나 값의 75% 이상이 누락된 특정 열을 제거합니다. 그러나 이 방법은 100% 효율적이지 않으며 데이터 세트에 적절한 샘플이 있는 경우에만 사용하는 것이 좋습니다. 데이터를 삭제한 후 편향이 추가되지 않았는지 확인해야 합니다.
- 평균 계산 – 이 방법은 연령, 급여, 연도 등과 같은 숫자 데이터가 있는 기능에 유용합니다. 여기에서 특정 기능 또는 누락된 값이 포함된 열이나 행의 평균, 중앙값 또는 모드를 계산하고 대체할 수 있습니다. 누락된 값에 대한 결과입니다. 이 방법은 데이터 세트에 분산을 추가할 수 있으며 데이터 손실을 효율적으로 무효화할 수 있습니다. 따라서 첫 번째 방법(행/열 생략)에 비해 더 나은 결과를 산출합니다. 근사의 또 다른 방법은 인접 값의 편차를 사용하는 것입니다. 그러나 이것은 선형 데이터에 가장 적합합니다.
읽기: 클라우드를 사용한 머신 러닝 애플리케이션의 애플리케이션
5. 범주형 데이터 인코딩
범주형 데이터는 데이터 세트 내에서 특정 범주가 있는 정보를 나타냅니다. 위에 인용된 데이터 세트에는 국가와 구매라는 두 가지 범주형 변수가 있습니다.
기계 학습 모델은 주로 수학 방정식을 기반으로 합니다. 따라서 방정식에 숫자만 필요하기 때문에 방정식에 범주형 데이터를 유지하면 특정 문제가 발생한다는 것을 직관적으로 이해할 수 있습니다.
국가 변수를 인코딩하는 방법은 무엇입니까?
데이터 세트 예에서 볼 수 있듯이 국가 열은 문제를 일으키므로 숫자 값으로 변환해야 합니다. 그렇게 하려면 sci-kit 학습 라이브러리의 LabelEncoder() 클래스를 사용할 수 있습니다. 코드는 다음과 같습니다.
#범주 데이터
#국가 변수용
sklearn.preprocessing 가져오기 LabelEncoder에서
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
그리고 출력은 -
아웃[15]:
배열([[2, 38.0, 68000.0],
[0, 43.0, 45000.0],
[1, 30.0, 54000.0],
[0, 48.0, 65000.0],
[1, 40.0, 65222.22222222222],
[2, 35.0, 58000.0],
[1, 41.111111111111114, 53000.0],
[0, 49.0, 79000.0],
[2, 50.0, 88000.0],
[0, 37.0, 77000.0]], dtype=객체)
여기에서 LabelEncoder 클래스가 변수를 숫자로 성공적으로 인코딩했음을 알 수 있습니다. 그러나 위에 표시된 출력에서 0, 1 및 2로 인코딩된 국가 변수가 있습니다. 따라서 ML 모델은 세 변수 사이에 어떤 상관관계가 있다고 가정하여 잘못된 출력을 생성할 수 있습니다. 이 문제를 제거하기 위해 이제 더미 인코딩을 사용합니다.
더미 변수는 결과를 이동할 수 있는 특정 범주 효과의 부재 또는 존재를 나타내기 위해 값 0 또는 1을 취하는 변수입니다. 이 경우 값 1은 특정 열에 해당 변수가 있음을 나타내고 다른 변수는 값 0이 됩니다. 더미 인코딩에서 열 수는 범주 수와 같습니다.
데이터 세트에는 세 개의 범주가 있으므로 값이 0과 1인 세 개의 열이 생성됩니다. 더미 인코딩의 경우 scikit-learn 라이브러리의 OneHotEncoder 클래스를 사용합니다. 입력 코드는 다음과 같습니다.
#국가 변수용
sklearn.preprocessing 가져오기 LabelEncoder, OneHotEncoder에서
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#더미 변수 인코딩
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
이 코드를 실행하면 다음과 같은 출력을 얻을 수 있습니다.
배열([[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.80000000e+01,
6.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.30000000e+01,
4.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 3.00000000e+01,
5.40000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.80000000e+01,
6.50000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.00000000e+01,
6.52222222e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 3.50000000e+01,

5.80000000e+04],
[0.00000000e+00, 1.00000000e+00, 0.00000000e+00, 4.11111111e+01,
5.30000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.90000000e+01,
7.90000000e+04],
[0.00000000e+00, 0.00000000e+00, 1.00000000e+00, 5.00000000e+01,
8.80000000e+04],
[1.00000000e+00, 0.00000000e+00, 0.00000000e+00, 3.70000000e+01,
7.70000000e+04]])
위에 표시된 출력에서 모든 변수는 3개의 열로 나뉘고 값 0과 1로 인코딩됩니다.
구매한 변수를 인코딩하는 방법은 무엇입니까?
두 번째 범주형 변수인 구매한 경우에는 LableEncoder 클래스의 "labelencoder" 개체를 사용할 수 있습니다. 구매한 변수에는 yes 또는 no 두 가지 범주만 있고 둘 다 0과 1로 인코딩되기 때문에 OneHotEncoder 클래스를 사용하지 않습니다.
이 변수의 입력 코드는 –
labelencoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
출력은 -
출력[17]: 배열([0, 1, 0, 0, 1, 1, 0, 1, 0, 1])
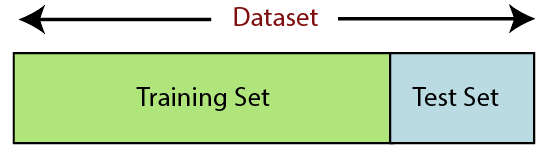
6. 데이터 세트 분할
데이터 세트 분할은 머신 러닝에서 데이터 전처리의 다음 단계입니다. 기계 학습 모델의 모든 데이터 세트는 훈련 세트와 테스트 세트라는 두 개의 개별 세트로 분할되어야 합니다.
원천
훈련 세트는 기계 학습 모델을 훈련하는 데 사용되는 데이터 세트의 하위 집합을 나타냅니다. 여기에서 이미 출력을 알고 있습니다. 반면에 테스트 세트는 기계 학습 모델을 테스트하는 데 사용되는 데이터 세트의 하위 집합입니다. ML 모델은 테스트 세트를 사용하여 결과를 예측합니다.
일반적으로 데이터 세트는 70:30 비율 또는 80:20 비율로 분할됩니다. 즉, 모델 교육에 데이터의 70% 또는 80%를 사용하고 나머지 30% 또는 20%는 생략합니다. 분할 프로세스는 해당 데이터 세트의 모양과 크기에 따라 다릅니다.
데이터 세트를 분할하려면 다음 코드 줄을 작성해야 합니다.
sklearn.model_selection import train_test_split에서
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
여기에서 첫 번째 줄은 데이터 세트의 배열을 무작위 학습 및 테스트 하위 집합으로 나눕니다. 코드의 두 번째 줄에는 4개의 변수가 포함됩니다.
- x_train – 훈련 데이터의 기능
- x_test – 테스트 데이터의 기능
- y_train – 훈련 데이터의 종속 변수
- y_test – 데이터 테스트를 위한 독립 변수
따라서 train_test_split() 함수에는 4개의 매개변수가 포함되며, 그 중 처음 두 개는 데이터 배열용입니다. test_size 함수는 테스트 세트의 크기를 지정합니다. test_size는 .5, .3 또는 .2일 수 있습니다. 이는 훈련 세트와 테스트 세트 간의 분할 비율을 지정합니다. 마지막 매개변수인 "random_state"는 출력이 항상 동일하도록 임의 생성기에 대한 시드를 설정합니다.
7. 기능 확장
기능 확장 은 기계 학습에서 데이터 사전 처리의 끝을 표시합니다. 특정 범위 내에서 데이터 세트의 독립 변수를 표준화하는 방법입니다. 다시 말해서, 특성 스케일링은 변수의 범위를 제한하므로 공통 근거에서 비교할 수 있습니다.
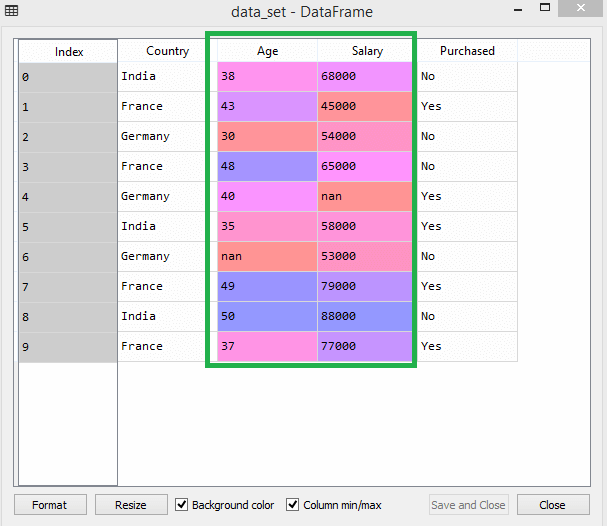
예를 들어 이 데이터 세트를 고려하십시오.
원천
데이터 세트에서 연령 및 급여 열의 척도가 동일하지 않음을 알 수 있습니다. 이러한 시나리오에서 연령 및 급여 열에서 두 값을 계산하면 급여 값이 연령 값을 지배하고 잘못된 결과를 제공합니다. 따라서 Machine Learning에 대한 기능 확장을 수행하여 이 문제를 제거해야 합니다.
대부분의 ML 모델은 다음과 같이 표현되는 유클리드 거리를 기반으로 합니다.
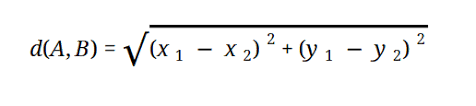
원천
두 가지 방법으로 기계 학습에서 기능 확장을 수행할 수 있습니다.
표준화
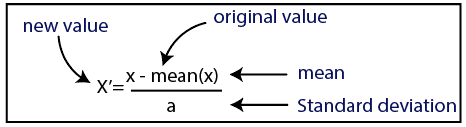
원천
표준화
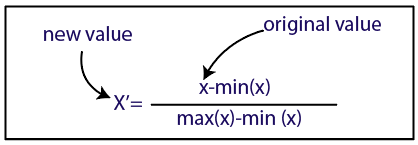
원천
데이터 세트의 경우 표준화 방법을 사용합니다. 그렇게 하려면 다음 코드 줄을 사용하여 sci-kit-learn 라이브러리의 StandardScaler 클래스를 가져옵니다.
sklearn.preprocessing 가져오기 StandardScaler에서
다음 단계는 독립 변수에 대한 StandardScaler 클래스의 개체를 만드는 것입니다. 그런 다음 다음 코드를 사용하여 훈련 데이터 세트를 적합하고 변환할 수 있습니다.
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
테스트 데이터 세트의 경우 transform() 함수를 직접 적용할 수 있습니다(fit_transform() 함수는 이미 훈련 세트에서 수행되기 때문에 사용할 필요가 없습니다). 코드는 다음과 같습니다.
x_test= st_x.transform(x_test)
테스트 데이터 세트의 출력은 다음과 같이 x_train 및 x_test의 크기 조정된 값을 표시합니다.
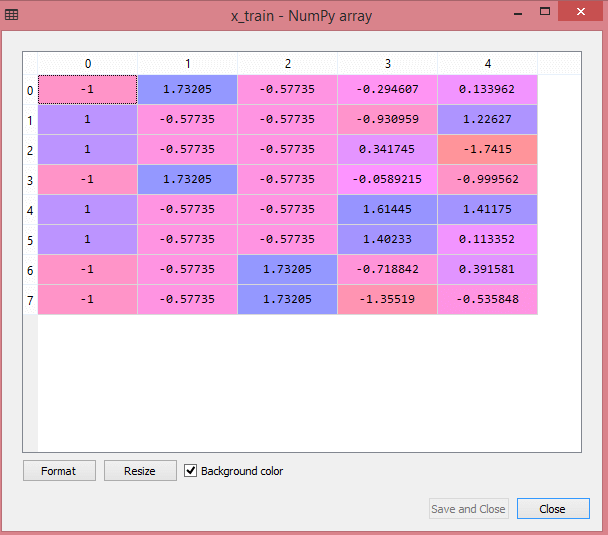
원천
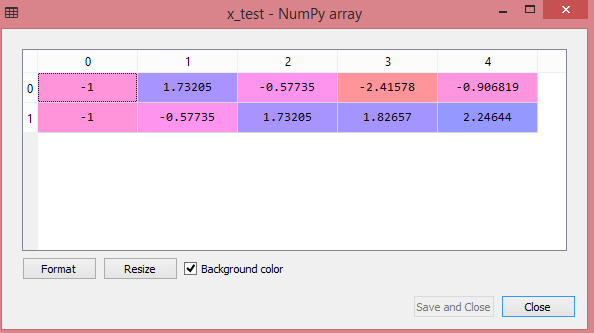
원천
출력의 모든 변수는 값 -1과 1 사이에서 조정됩니다.
이제 우리가 지금까지 수행한 모든 단계를 결합하여 다음을 얻습니다.
# 라이브러리 가져오기
numpy를 nm로 가져오기
matplotlib.pyplot을 mtp로 가져오기
pandas를 pd로 가져오기
#데이터세트 가져오기
data_set= pd.read_csv('Dataset.csv')
#독립변수 추출
x= data_set.iloc[:, :-1].값
#종속변수 추출
y= data_set.iloc[:, 3].값
#handling 누락된 데이터(누락된 데이터를 평균값으로 대체)
sklearn.preprocessing 가져오기 임퓨터에서
imputer= Imputer(missing_values = 'NaN', 전략='평균', 축 = 0)
#임퓨터 객체를 독립 변수 x에 맞추기.
imputerimputer = imputer.fit(x[:, 1:3])
# 누락된 데이터를 계산된 평균값으로 대체
x[:, 1:3]= imputer.transform(x[:, 1:3])
#국가 변수용
sklearn.preprocessing 가져오기 LabelEncoder, OneHotEncoder에서
label_encoder_x= LabelEncoder()
x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
#더미 변수 인코딩
onehot_encoder= OneHotEncoder(categorical_features= [0])
x= onehot_encoder.fit_transform(x).toarray()
#구매한 변수에 대한 인코딩
labelencoder_y= LabelEncoder()
y= labelencoder_y.fit_transform(y)
# 데이터 세트를 훈련 세트와 테스트 세트로 나눕니다.
sklearn.model_selection import train_test_split에서
x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
#데이터세트의 기능 확장
sklearn.preprocessing 가져오기 StandardScaler에서
st_x= StandardScaler()
x_train= st_x.fit_transform(x_train)
x_test= st_x.transform(x_test)
간단히 말해서 머신 러닝에서의 데이터 처리입니다!
upGrad 와 연계하여 IIT Delhi의 Machine Learning & AI 부문 Executive PG Program을 확인할 수 있습니다. IIT Delhi 는 인도에서 가장 권위 있는 기관 중 하나입니다. 500명 이상의 사내 교수진과 함께 주제 문제에서 최고입니다.
데이터 전처리의 중요성은 무엇입니까?
오류, 중복, 누락된 값 및 불일치는 모두 데이터 세트의 무결성을 위태롭게 하므로 보다 정확한 결과를 얻으려면 이 모든 문제를 해결해야 합니다. 결함이 있는 데이터 세트를 사용하여 고객의 구매를 처리하도록 기계 학습 시스템을 교육한다고 가정합니다. 시스템은 편향과 편차를 생성하여 나쁜 사용자 경험을 초래할 수 있습니다. 결과적으로 해당 데이터를 의도한 목적으로 사용하기 전에 가능한 한 조직적이고 '깨끗'해야 합니다. 처리하는 어려움의 유형에 따라 다양한 옵션이 있습니다.
데이터 정리란 무엇입니까?
데이터 세트에는 거의 확실히 누락되고 노이즈가 있는 데이터가 있습니다. 데이터 수집 절차가 이상적이지 않기 때문에 쓸모없고 누락된 정보가 많이 있을 것입니다. 데이터 정리는 이 문제를 처리하기 위해 사용해야 하는 방법입니다. 이것은 두 가지 범주로 나눌 수 있습니다. 첫 번째는 누락된 데이터를 처리하는 방법에 대해 설명합니다. 데이터 수집의 이 섹션(튜플이라고 함)에서 누락된 값을 무시하도록 선택할 수 있습니다. 두 번째 데이터 정리 방법은 노이즈가 있는 데이터에 대한 것입니다. 전체 프로세스를 원활하게 실행하려면 시스템에서 읽을 수 없는 불필요한 데이터를 제거하는 것이 중요합니다.
데이터 변환 및 축소는 무엇을 의미합니까?
데이터 전처리는 우려 사항을 처리한 후 변환 단계로 이동합니다. 이를 사용하여 분석을 위해 데이터를 관련 형식으로 변환합니다. 정규화, 속성 선택, 이산화 및 개념 계층 생성은 이를 수행하는 데 사용할 수 있는 몇 가지 접근 방식입니다. 자동화된 방법의 경우에도 큰 데이터 세트를 선별하는 데 오랜 시간이 걸릴 수 있습니다. 이것이 바로 데이터 축소 단계가 매우 중요한 이유입니다. 가장 중요한 정보로 데이터를 제한하여 데이터 세트의 크기를 줄이고 저장 효율성을 높이는 동시에 데이터 작업에 드는 재정 및 시간 비용을 절감합니다.