
PoP를 통해 WordPress 웹 사이트에 코드 분할 기능 추가
게시 됨: 2022-03-10속도는 오늘날 모든 웹사이트의 최우선 순위입니다. 웹 사이트를 더 빠르게 로드하는 한 가지 방법은 코드 분할입니다. 요청 시 로드할 수 있는 청크로 애플리케이션을 분할합니다. 필요한 JavaScript만 로드하고 다른 것은 로드하지 않습니다. JavaScript 프레임워크를 기반으로 하는 웹사이트는 인기 있는 JavaScript 번들러인 Webpack을 통해 즉시 코드 분할을 구현할 수 있습니다. 그러나 WordPress 웹 사이트의 경우 그렇게 쉽지 않습니다. 첫째, Webpack은 의도적으로 WordPress와 함께 작동하도록 제작되지 않았으므로 설정하려면 상당한 해결 방법이 필요합니다. 둘째, WordPress에 대한 기본 주문형 자산 로딩 기능을 제공하는 도구가 없는 것 같습니다.
WordPress에 적합한 솔루션이 부족하기 때문에 내가 만든 WordPress 웹 사이트를 구축하기 위한 오픈 소스 프레임워크인 PoP용 코드 분할 버전을 구현하기로 결정했습니다. PoP가 설치된 WordPress 웹 사이트에는 기본적으로 코드 분할 기능이 있으므로 Webpack이나 다른 번들러에 의존할 필요가 없습니다. 이 기사에서는 프레임워크 아키텍처의 측면을 기반으로 어떤 결정이 내려졌는지 설명하면서 완료 방법을 보여 드리겠습니다. 마지막으로 코드 분할이 있거나 없는 웹사이트의 성능과 외부 번들러를 통해 사용자 정의 구현을 사용할 때의 장점과 단점을 분석할 것입니다. 즐거운 라이딩 하시길 바랍니다!
전략 정의
코드 분할은 크게 다음 두 단계로 나눌 수 있습니다.
- 모든 경로에 대해 로드해야 하는 자산 계산,
- 요청 시 해당 자산을 동적으로 로드합니다.
첫 번째 단계를 해결하려면 애플리케이션의 모든 자산을 포함하는 자산 종속성 맵을 생성해야 합니다. 자산은 이 맵에 재귀적으로 추가되어야 합니다. 더 이상 자산이 필요하지 않을 때까지 종속성의 종속성도 추가해야 합니다. 그런 다음 경로의 진입점(즉, 실행을 시작하는 파일 또는 코드 조각)에서 시작하여 마지막 수준까지 자산 종속성 맵을 탐색하여 특정 경로에 필요한 모든 종속성을 계산할 수 있습니다.
두 번째 단계를 처리하기 위해 서버 측에서 요청된 URL에 필요한 자산을 계산한 다음 애플리케이션이 로드해야 하는 필요한 자산 목록을 응답으로 보내거나 직접 HTTP/ 2 응답과 함께 리소스를 푸시합니다.
그러나 이러한 솔루션은 최적이 아닙니다. 첫 번째 경우 애플리케이션은 응답이 반환된 후 모든 자산을 요청해야 하므로 자산을 가져오기 위한 추가 일련의 왕복 요청이 있어야 하며 모든 자산이 로드되기 전에 보기를 생성할 수 없어 결과가 사용자가 기다려야 함(이 문제는 서비스 워커를 통해 모든 자산을 사전 캐싱함으로써 완화되므로 대기 시간이 단축되지만 응답이 돌아온 후에만 발생하는 자산의 구문 분석을 피할 수 없습니다). 두 번째 경우에는 동일한 자산을 반복적으로 푸시할 수 있으며(예: 쿠키를 통해 이미 로드한 리소스를 나타내는 추가 논리를 추가하지 않는 한, 이는 실제로 원하지 않는 복잡성을 추가하고 응답이 캐시되는 것을 차단합니다.) CDN에서 자산을 제공할 수 없습니다.
이 때문에 이 논리를 클라이언트 측에서 처리하기로 결정했습니다. 각 경로에 필요한 자산 목록은 클라이언트의 애플리케이션에서 사용할 수 있으므로 요청된 URL에 어떤 자산이 필요한지 이미 알고 있습니다. 이것은 위에서 언급한 문제를 해결합니다.
- 서버의 응답을 기다릴 필요 없이 자산을 즉시 로드할 수 있습니다. (서비스 워커와 결합하면 응답이 돌아올 때까지 모든 리소스가 로드되고 구문 분석되므로 추가 대기 시간이 없다고 확신할 수 있습니다.)
- 애플리케이션은 이미 로드된 자산을 알고 있습니다. 따라서 해당 경로에 필요한 모든 자산을 요청하지 않고 아직 로드되지 않은 자산만 요청합니다.
이 목록을 프런트 엔드에 전달할 때의 부정적인 측면은 웹 사이트의 크기(예: 사용 가능한 경로 수)에 따라 무거워질 수 있다는 것입니다. 우리는 응용 프로그램의 인식 로딩 시간을 늘리지 않고 로드하는 방법을 찾아야 합니다. 이에 대한 자세한 내용은 나중에 설명합니다.
이러한 결정을 내리면 설계를 진행한 다음 애플리케이션에서 코드 분할을 구현할 수 있습니다. 이해를 돕기 위해 프로세스를 다음 단계로 구분했습니다.
- 애플리케이션 아키텍처를 이해하고,
- 자산 종속성 매핑,
- 모든 신청 경로를 나열하고,
- 각 경로에 필요한 자산을 정의하는 목록 생성,
- 동적으로 자산 로드,
- 최적화를 적용합니다.
바로 들어가 봅시다!
0. 애플리케이션 아키텍처 이해
모든 자산의 관계를 서로 매핑해야 합니다. 이 목표를 달성하는 데 가장 적합한 솔루션을 설계하기 위해 PoP 아키텍처의 특성을 살펴보겠습니다.
PoP는 WordPress를 둘러싸는 레이어로, WordPress를 애플리케이션을 구동하는 CMS로 사용할 수 있게 하면서도 동적 웹사이트를 구축하기 위해 클라이언트 측에서 콘텐츠를 렌더링하는 사용자 지정 JavaScript 프레임워크를 제공합니다. 웹 페이지의 구성 요소를 재정의합니다. WordPress가 현재 HTML을 생성하는 계층적 템플릿(예: single.php , home.php 및 archive.php ) 개념을 기반으로 하는 반면 PoP는 "모듈, "는 원자적 기능이거나 다른 모듈의 구성입니다. PoP 애플리케이션을 구축하는 것은 LEGO 를 가지고 노는 것과 비슷합니다. 모듈을 서로 위에 쌓거나 서로 감싸서 궁극적으로 더 복잡한 구조를 만듭니다. 또한 Brad Frost의 원자 설계 구현으로 생각할 수 있으며 다음과 같습니다.
모듈은 블록, blockGroups, pageSections 및 topLevels와 같은 고차 엔터티로 그룹화할 수 있습니다. 이러한 엔터티는 추가 속성과 책임이 있는 모듈이기도 하며 각 모듈이 모든 내부 모듈의 속성을 보고 변경할 수 있는 엄격한 하향식 아키텍처에 따라 서로를 포함합니다. 모듈 간의 관계는 다음과 같습니다.
- 1 topLevel에는 N pageSections가 포함되어 있습니다.
- 1 pageSection에는 N개의 블록 또는 블록 그룹이 포함됩니다.
- 1개의 blockGroup은 N개의 블록 또는 blockGroup을 포함합니다.
- 1개의 블록은 N개의 모듈을 포함하고,
- 1개의 모듈은 N개의 모듈을 무한대로 포함합니다.
PoP에서 JavaScript 코드 실행
PoP는 pageSection 수준에서 시작하여 라인 아래로 모든 모듈을 반복하고 모듈의 미리 정의된 Handlebars 템플릿을 통해 각 모듈을 렌더링하고 마지막으로 모듈의 해당 새로 생성된 요소를 DOM에 추가하여 HTML을 동적으로 생성합니다. 이 작업이 완료되면 모듈별로 사전 정의된 JavaScript 기능을 실행합니다.
PoP는 애플리케이션의 흐름이 클라이언트에서 시작되지 않는다는 점에서 JavaScript 프레임워크(예: React 및 AngularJS)와 다르지만 여전히 백엔드, 모듈 구성(PHP 개체로 코딩됨) 내부에서 구성됩니다. WordPress 작업 후크의 영향을 받은 PoP는 게시-구독 패턴을 구현합니다.
- 각 모듈은 해당하는 새로 생성된 DOM 요소에서 실행되어야 하는 JavaScript 함수를 정의합니다. 이 코드를 실행할 항목이나 코드 출처를 미리 알 필요는 없습니다.
- JavaScript 객체는 구현하는 JavaScript 기능을 등록해야 합니다.
- 마지막으로 런타임 시 PoP는 어떤 JavaScript 객체가 어떤 JavaScript 기능을 실행해야 하는지 계산하고 적절하게 호출합니다.
예를 들어, 해당 PHP 객체를 통해 캘린더 모듈은 다음과 같이 DOM 요소에서 calendar 기능을 실행해야 함을 나타냅니다.
class CalendarModule { function get_jsmethods() { $methods = parent::get_jsmethods(); $this->add_jsmethod($methods, 'calendar'); return $methods; } ... } 그런 다음 JavaScript 객체(이 경우 popFullCalendar )는 calendar 기능이 구현되었음을 알립니다. 이것은 popJSLibraryManager.register 를 호출하여 수행됩니다.
window.popFullCalendar = { calendar : function(elements) { ... } }; popJSLibraryManager.register(popFullCalendar, ['calendar', ...]); 마지막으로, popJSLibraryManager 는 어떤 코드를 실행하는지 일치시킵니다. JavaScript 객체가 구현하는 기능을 등록할 수 있도록 하고 구독된 모든 JavaScript 객체에서 특정 기능을 실행하는 메서드를 제공합니다.
window.popJSLibraryManager = { libraries: [], methods: {}, register : function(library, methods) { this.libraries.push(library); for (var i = 0; i < methods.length; i++) { var method = methods[i]; this.methods[method] = this.methods[method] || []; this.methods[method].push(library); } }, execute : function(method, elements) { var libraries = this.methods[method] || []; for (var i = 0; i < libraries.length; i++) { var library = libraries[i]; library[method](elements); } } } ID가 calendar-293 인 새 달력 요소가 DOM에 추가되면 PoP는 다음 기능을 간단히 실행합니다.
popJSLibraryManager.execute("calendar", document.getElementById("calendar-293"));진입 지점
PoP의 경우 JavaScript 코드를 실행하기 위한 진입점은 HTML 출력 끝에 있는 다음 줄입니다.
<script type="text/javascript">popManager.init();</script> popManager.init() 는 먼저 프론트엔드 프레임워크를 초기화한 다음 위에서 설명한 것처럼 렌더링된 모든 모듈에 의해 정의된 JavaScript 함수를 실행합니다. 아래는 이 함수의 매우 단순한 형태입니다(원본 코드는 GitHub에 있음). popJSLibraryManager.execute('pageSectionInitialized', pageSection) 및 popJSLibraryManager.execute('documentInitialized') 를 호출하면 해당 기능을 구현하는 모든 JavaScript 객체( pageSectionInitialized 및 documentInitialized )가 이를 실행합니다.
(function($){ window.popManager = { // The configuration for all the modules (including pageSections and blocks) in the application configuration : {...}, init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { // Obtain the pageSection element in the DOM from the ID var pageSection = $('#'+pageSectionId); // Run all required JavaScript methods on it this.runJSMethods(pageSection, configuration); // Trigger an event marking the block as initialized popJSLibraryManager.execute('pageSectionInitialized', pageSection); }); // Trigger an event marking the document as initialized popJSLibraryManager.execute('documentInitialized'); }, ... }; })(jQuery); runJSMethods 함수는 최상위 모듈인 pageSection에서 시작하여 모든 내부 블록과 내부 모듈에 대해 행 아래로 각 모듈에 대해 정의된 JavaScript 메소드를 실행합니다.
(function($){ window.popManager = { ... runJSMethods : function(pageSection, configuration) { // Initialize the heap with "modules", starting from the top one, and recursively iterate over its inner modules var heap = [pageSection.data('module')], i; while (heap.length > 0) { // Get the first element of the heap var module = heap.pop(); // The configuration for that module contains which JavaScript methods to execute, and which are the module's inner modules var moduleConfiguration = configuration[module]; // The list of all JavaScript functions that must be executed on the module's newly created DOM elements var jsMethods = moduleConfiguration['js-methods']; // Get all of the elements added to the DOM for that module, which have been stored in JavaScript object `popJSRuntimeManager` upon creation var elements = popJSRuntimeManager.getDOMElements(module); // Iterate through all of the JavaScript methods and execute them, passing the elements as argument for (i = 0; i < jsMethods.length; i++) { popJSLibraryManager.execute(jsMethods[i], elements); } // Finally, add the inner-modules to the heap heap = heap.concat(moduleConfiguration['inner-modules']); } }, }; })(jQuery);요약하자면, PoP에서의 JavaScript 실행은 느슨하게 결합되어 있습니다. 고정된 종속성을 갖는 대신 모든 JavaScript 객체가 구독할 수 있는 후크를 통해 JavaScript 기능을 실행합니다.
웹 페이지 및 API
PoP 웹 사이트는 자체 사용 API입니다. PoP에서는 웹 페이지와 API 사이에 구분이 없습니다. 각 URL은 기본적으로 웹 페이지를 반환하고 output=json 매개변수를 추가하기만 하면 대신 해당 API를 반환합니다(예: getpop.org/en/은 웹 페이지이고 getpop.org/en/?output=json이 해당 API임). API는 PoP에서 콘텐츠를 동적으로 렌더링하는 데 사용됩니다. 따라서 다른 페이지로 연결되는 링크를 클릭하면 API가 요청됩니다. 그때쯤이면 웹사이트의 프레임이 로드되기 때문입니다(예: 상단 및 측면 탐색). 그러면 API 모드에 필요한 리소스 집합이 웹 페이지의 하위 집합이어야 합니다. 경로에 대한 종속성을 계산할 때 이를 고려해야 합니다. 웹사이트를 처음 로드할 때 경로를 로드하거나 일부 링크를 클릭하여 동적으로 로드하면 다른 필수 자산 세트가 생성됩니다.
이것들은 코드 분할의 설계와 구현을 정의할 PoP의 가장 중요한 측면입니다. 다음 단계를 진행해 보겠습니다.
1. 자산 종속성 매핑
명시적 종속성을 자세히 설명하는 각 JavaScript 파일에 대한 구성 파일을 추가할 수 있습니다. 그러나 이것은 코드를 복제하고 일관성을 유지하기 어려울 것입니다. 더 깨끗한 솔루션은 JavaScript 파일을 유일한 정보 소스로 유지하고 파일 내에서 코드를 추출한 다음 이 코드를 분석하여 종속성을 다시 만드는 것입니다.
매핑을 다시 생성할 수 있도록 JavaScript 소스 파일에서 찾고 있는 메타 데이터는 다음과 같습니다.
-
this.runJSMethods(...)와 같은 내부 메소드 호출 ; -
popJSRuntimeManager.getDOMElements(...)와 같은 외부 메소드 호출 ; - 그것을 구현하는 모든 객체에서 JavaScript 함수를 실행하는
popJSLibraryManager.execute(...)의 모든 발생; - 어떤 JavaScript 객체가 어떤 JavaScript 메소드를 구현하는지 얻기 위해 모든
popJSLibraryManager.register(...)발생.
다음과 같이 jParser 및 jTokenizer를 사용하여 PHP에서 JavaScript 소스 파일을 토큰화하고 메타 데이터를 추출합니다.
- 내부 메서드 호출(예:
this.runJSMethods)은 토큰this또는that+ 시퀀스를 찾을 때 추론됩니다.+ 내부 메소드(runJSMethods)의 이름인 다른 토큰. - 다음 시퀀스를 찾을 때 외부 메서드 호출(예:
popJSRuntimeManager.getDOMElements)이 추론됩니다. 애플리케이션의 모든 JavaScript 개체 목록에 포함된 토큰(이 목록이 미리 필요합니다. 이 경우에는 개체popJSRuntimeManager가 포함됨) +.+ 외부 메소드의 이름인 다른 토큰(getDOMElements). - 우리가
popJSLibraryManager.execute("someFunctionName")을 찾을 때마다 우리는 자바스크립트 메소드가someFunctionName이라고 추론합니다. - 우리가
popJSLibraryManager.register(someJSObject, ["someFunctionName1", "someFunctionName2"])를 찾을 때마다 우리는 메소드someFunctionName1,someFunctionName2를 구현하기 위해 자바스크립트 객체someJSObject를 추론합니다.
스크립트를 구현했지만 여기에서 설명하지 않습니다. (너무 길면 가치가 없지만 PoP의 저장소에서 찾을 수 있습니다.) 웹사이트의 개발 서버에서 내부 페이지를 요청할 때 실행되는 스크립트(이 방법은 서비스 워커에 대한 이전 기사에서 작성했습니다)는 매핑 파일을 생성하고 서버에 저장합니다. 생성된 매핑 파일의 예시를 준비했습니다. 다음 속성을 포함하는 간단한 JSON 파일입니다.
-
internalMethodCalls
각 JavaScript 개체에 대해 내부 함수 간의 종속성을 나열합니다. -
externalMethodCalls
각 JavaScript 개체에 대해 내부 함수에서 다른 JavaScript 개체의 함수에 대한 종속성을 나열합니다. -
publicMethods
등록된 모든 메소드를 나열하고 각 메소드에 대해 JavaScript 객체가 이를 구현합니다. -
methodExecutions
각 JavaScript 객체 및 각 내부 함수에 대해popJSLibraryManager.execute('someMethodName')을 통해 실행된 모든 메서드를 나열합니다.
결과는 아직 자산 종속성 맵이 아니라 JavaScript 개체 종속성 맵입니다. 이 맵에서 우리는 어떤 객체의 기능이 실행될 때마다 어떤 다른 객체도 필요할 것인지를 설정할 수 있습니다. 모든 자산에 대해 각 자산에 포함된 JavaScript 개체를 구성해야 합니다(jTokenizer 스크립트에서 JavaScript 개체는 외부 메서드 호출을 식별하기 위해 찾고 있는 토큰이므로 이 정보는 스크립트에 대한 입력이며 ' 소스 파일 자체에서 얻음). 이것은 resourceloader-processor.php와 같은 ResourceLoaderProcessor PHP 객체를 통해 수행됩니다.
마지막으로 지도와 구성을 결합하여 애플리케이션의 모든 경로에 필요한 모든 자산을 계산할 수 있습니다.
2. 모든 신청 경로 나열
애플리케이션에서 사용 가능한 모든 경로를 식별해야 합니다. WordPress 웹 사이트의 경우 이 목록은 각 템플릿 계층의 URL로 시작합니다. PoP를 위해 구현된 것들은 다음과 같습니다:
- 홈페이지: https://getpop.org/en/
- 저자: https://getpop.org/en/u/leo/
- 싱글: https://getpop.org/en/blog/new-feature-code-splitting/
- 태그: https://getpop.org/en/tags/internet/
- 페이지: https://getpop.org/en/philosophy/
- category: https://getpop.org/en/blog/ (카테고리가 실제로 페이지로 구현되어 URL 경로에서
category/를 제거) - 404: https://getpop.org/en/this-page-does-not-exist/
이러한 각 계층에 대해 고유한 구성을 생성하는 모든 경로를 확보해야 합니다(즉, 고유한 자산 세트가 필요함). PoP의 경우 다음이 있습니다.
- 홈 페이지와 404는 고유합니다.
- 태그 페이지는 모든 태그에 대해 항상 동일한 구성을 갖습니다. 따라서 모든 태그에 대한 단일 URL이면 충분합니다.
- 단일 게시물은 게시물 유형(예: "이벤트" 또는 "게시물")과 게시물의 주요 카테고리(예: "블로그" 또는 "기사")의 조합에 따라 다릅니다. 그런 다음 이러한 각 조합에 대한 URL이 필요합니다.
- 카테고리 페이지의 구성은 카테고리에 따라 다릅니다. 따라서 모든 게시물 카테고리의 URL이 필요합니다.
- 작성자 페이지는 작성자의 역할("개인", "조직" 또는 "커뮤니티")에 따라 다릅니다. 따라서 각각 이러한 역할 중 하나를 가진 세 명의 작성자에 대한 URL이 필요합니다.
- 각 페이지는 고유한 구성을 가질 수 있습니다("로그인", "연락처", "우리의 사명" 등). 따라서 모든 페이지 URL을 목록에 추가해야 합니다.
우리가 볼 수 있듯이, 목록은 이미 꽤 길다. 또한 애플리케이션은 구성을 변경하는 매개변수를 URL에 추가할 수 있으며 잠재적으로 필요한 자산도 변경할 수 있습니다. 예를 들어 PoP는 다음 URL 매개변수를 추가하도록 제안합니다.
- 탭(
?tab=…), 관련 정보 표시: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors; - 형식(
?format=…), 데이터 표시 방법 변경: https://getpop.org/en/blog/?format=list; - target(
?target=…), 다른 pageSection: https://getpop.org/en/add-post/?target=addons에서 페이지를 엽니다.
초기 경로 중 일부는 위의 매개변수 중 1개, 2개 또는 3개를 가질 수 있어 다양한 조합을 생성할 수 있습니다.
- 단일 게시물: https://getpop.org/en/blog/new-feature-code-splitting/
- 단일 게시물 작성자: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors
- 단일 게시물 작성자를 목록으로: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list
- 단일 게시물의 작성자를 모달 창의 목록으로: https://getpop.org/en/blog/new-feature-code-splitting/?tab=authors&format=list&target=modals
요약하면 PoP의 경우 가능한 모든 경로는 다음 항목의 조합입니다.
- 모든 초기 템플릿 계층 경로;
- 계층 구조가 다른 구성을 생성하는 모든 다른 값;
- 각 계층에 대해 가능한 모든 탭(계층마다 탭 값이 다를 수 있음: 단일 게시물에는 "작성자" 및 "응답" 탭이 있는 반면 작성자는 "게시자" 및 "팔로워" 탭이 있을 수 있음)
- 각 탭에 대해 가능한 모든 형식(다른 탭은 다른 형식으로 적용될 수 있음: "저자" 탭은 "지도" 형식을 가질 수 있지만 "응답" 탭은 그렇지 않을 수 있음)
- 각 경로가 표시될 수 있는 pageSections를 나타내는 가능한 모든 대상(게시물은 메인 섹션이나 떠 있는 창에서 만들 수 있지만 "친구와 공유" 페이지는 모달 창에서 열리도록 설정할 수 있습니다.)
따라서 약간 복잡한 응용 프로그램의 경우 모든 경로가 포함된 목록을 수동으로 생성할 수 없습니다. 그런 다음 데이터베이스에서 이 정보를 추출하고 조작하고 마지막으로 필요한 형식으로 출력하는 스크립트를 작성해야 합니다. 이 스크립트는 모든 다른 카테고리 페이지 URL 목록을 생성할 수 있는 모든 게시물 카테고리를 얻은 다음, 각 카테고리에 대해 동일한 아래에 있는 모든 게시물에 대한 데이터베이스를 쿼리하여 단일에 대한 URL을 생성합니다. 모든 카테고리에 게시하는 등. function get_resources() 에서 시작하여 전체 스크립트를 사용할 수 있습니다. 이 함수는 각 계층 구조 사례에 의해 구현될 후크를 노출합니다.
3. 각 경로에 필요한 자산을 정의하는 목록 생성
지금까지 자산 종속성 맵과 애플리케이션의 모든 경로 목록이 있습니다. 이제 이 두 가지를 결합하고 각 경로에 대해 어떤 자산이 필요한지 나타내는 목록을 생성해야 합니다.
이 목록을 만들기 위해 다음 절차를 적용합니다.
- 모든 경로에 대해 실행할 모든 JavaScript 메소드가 포함된 목록을 생성합니다.
경로의 모듈을 계산한 다음 각 모듈에 대한 구성을 얻은 다음 구성에서 모듈이 실행해야 하는 JavaScript 기능을 추출하고 모두 함께 추가합니다. - 다음으로, 각 JavaScript 함수에 대한 자산 종속성 맵을 탐색하고 필요한 모든 종속성 목록을 수집하고 모두 함께 추가합니다.
- 마지막으로 해당 경로 내에서 각 모듈을 렌더링하는 데 필요한 핸들바 템플릿을 추가합니다.
또한 앞에서 언급한 것처럼 각 URL에는 웹 페이지와 API 모드가 있으므로 각 모드에 대해 한 번씩 위의 절차를 두 번 실행해야 합니다(즉, API 모드의 경로를 나타내는 URL에 output=json 매개변수를 추가하면 웹 페이지 모드에 대해 URL을 변경하지 않은 상태로 유지). 그런 다음 용도가 다른 두 개의 목록을 생성합니다.
- 웹 페이지 모드 목록은 웹 사이트를 처음 로드할 때 사용되므로 해당 경로에 해당하는 스크립트가 초기 HTML 응답에 포함됩니다. 이 목록은 서버에 저장됩니다.
- API 모드 목록은 웹 사이트에서 페이지를 동적으로 로드할 때 사용됩니다. 이 목록은 링크를 클릭할 때 요청 시 로드해야 하는 추가 자산을 애플리케이션이 계산할 수 있도록 클라이언트에 로드됩니다.
로직의 대부분은 function add_resources_from_settingsprocessors($fetching_json, ...) 에서 시작하여 구현되었습니다(리포지토리에서 찾을 수 있음). $fetching_json 매개변수는 웹 페이지( false ) 모드와 API( true ) 모드를 구분합니다.
웹 페이지 모드에 대한 스크립트가 실행되면 다음 속성을 가진 JSON 객체인 resourceloader-bundle-mapping.json이 출력됩니다.
-
bundle-ids
이것은erhandlebarshandlebars-helperseq된 최대 4개의 리소스 모음입니다. -
bundlegroup-ids
이것은bundle-ids의 모음입니다. 각 bundleGroup은 고유한 리소스 집합을 나타냅니다. -
key-ids
이것은 경로(경로를 고유하게 만드는 모든 속성 집합을 식별하는 해시로 표시됨)와 해당 번들 그룹 간의 매핑입니다.
관찰할 수 있듯이 경로와 리소스 간의 매핑은 직선적이지 않습니다. key-ids 를 리소스 목록에 매핑하는 대신 고유한 번들 그룹에 매핑합니다. 이 번들 그룹은 그 자체가 bundles 목록이며 각 번들만 resources 목록입니다(각 번들에 최대 4개의 요소 포함). 왜 이렇게 되었을까요? 이것은 두 가지 용도로 사용됩니다.
- 이를 통해 고유한 bundleGroup 아래의 모든 리소스를 식별할 수 있습니다. 따라서 HTML 응답에 모든 리소스를 포함하는 대신 고유한 JavaScript 자산을 포함할 수 있습니다. 이 자산은 모든 해당 리소스 내에 번들로 묶인 해당 bundleGroup 파일입니다. 이것은 여전히 HTTP/2를 지원하지 않는 장치를 제공할 때 유용하며 단일 번들 파일을 Gzip으로 압축하는 것이 구성 파일을 자체적으로 압축한 다음 함께 추가하는 것보다 더 효과적이기 때문에 로드 시간도 향상됩니다. 또는 리소스와 번들 그룹 간의 절충안인 고유한 번들 그룹 대신 일련의 번들을 로드할 수도 있습니다(번들을 로드하는 것은 Gzip'ing 때문에 번들 그룹보다 느리지만 무효화가 자주 발생하는 경우 성능이 더 우수하므로 전체 bundleGroup이 아니라 업데이트된 번들만 다운로드함). 모든 리소스를 번들 및 번들 그룹으로 묶는 스크립트는 filegenerator-bundles.php 및 filegenerator-bundlegroups.php에 있습니다.
- 리소스 세트를 번들로 나누면 공통 패턴을 식별할 수 있으므로(예: 많은 경로 간에 공유되는 4개의 리소스 세트 식별) 결과적으로 다른 경로가 동일한 번들에 링크될 수 있습니다. 결과적으로 생성된 목록의 크기가 더 작아집니다. 이것은 서버에 있는 웹 페이지 목록에는 별로 유용하지 않을 수 있지만 나중에 보게 될 클라이언트에 로드될 API 목록에는 유용합니다.
API 모드용 스크립트가 실행되면 다음 속성과 함께 resources.js 파일이 출력됩니다.

-
bundles및bundle-groups은 웹 페이지 모드에 대해 명시된 것과 동일한 목적을 수행합니다. -
keys는 웹 페이지 모드의key-ids와 같은 용도로도 사용됩니다. 그러나 경로를 나타내는 키로 해시를 사용하는 대신 경로를 고유하게 만드는 모든 속성(우리의 경우 형식(f), 탭(t) 및 대상(r))을 연결합니다. -
sources는 각 리소스의 소스 파일입니다. -
types은 각 리소스에 대한 CSS 또는 JavaScript입니다(단순화를 위해 이 기사에서는 JavaScript 리소스가 CSS 리소스를 종속성으로 설정할 수도 있고 모듈이 자체 CSS 자산을 로드하여 점진적 CSS 로드 전략을 구현할 수 있다는 점을 다루지 않았습니다. ). -
resources는 각 계층에 대해 로드해야 하는 번들 그룹을 캡처합니다. -
ordered-load-resources에는 종속된 스크립트(기본적으로 비동기식)보다 먼저 로드되는 스크립트를 방지하기 위해 순서대로 로드해야 하는 리소스가 포함되어 있습니다.
다음 섹션에서 이 파일을 사용하는 방법을 살펴보겠습니다.
4. 자산을 동적으로 로드
명시된 대로 API 목록은 클라이언트에 로드되므로 사용자가 링크를 클릭한 직후 경로에 필요한 자산 로드를 시작할 수 있습니다.
매핑 스크립트 로드
애플리케이션의 모든 경로에 대한 리소스 목록과 함께 생성된 JavaScript 파일은 가볍지 않습니다. 이 경우 85KB로 나왔습니다(자체 최적화, 리소스 이름을 엉망으로 만들고 여러 경로에서 공통 패턴을 식별하기 위해 번들을 생성함). . JSON 구문 분석은 동일한 데이터에 대해 JavaScript 구문 분석보다 10배 빠르기 때문에 구문 분석 시간은 큰 병목 현상이 되어서는 안 됩니다. 그러나 크기는 네트워크 전송의 문제이므로 응용 프로그램의 인식 로딩 시간에 영향을 미치거나 사용자를 기다리게 하지 않는 방식으로 이 스크립트를 로드해야 합니다.
내가 구현한 솔루션은 서비스 워커를 사용하여 이 파일을 미리 캐시하고, 중요한 JavaScript 메서드를 실행하는 동안 메인 스레드를 차단하지 않도록 defer 를 사용하여 로드한 다음, 사용자가 링크를 클릭하면 대체 알림 메시지를 표시하는 것입니다. 스크립트가 로드되기 전: "웹사이트가 아직 로드 중입니다. 링크를 클릭하려면 잠시만 기다려 주십시오." 이것은 스크립트가 로드되는 동안 모든 것 위에 loadingscreen 클래스가 있는 고정 div를 추가한 다음 div 내부에 notificationmsg 클래스와 함께 알림 메시지를 추가하고 CSS의 다음 몇 줄을 추가하여 수행됩니다.
.loadingscreen > .notificationmsg { display: none; } .loadingscreen:focus > .notificationmsg, .loadingscreen:active > .notificationmsg { display: block; }또 다른 해결책은 이 파일을 여러 파일로 나누고 필요에 따라 점진적으로 로드하는 것입니다(이미 코딩한 전략). 또한 85KB 파일에는 "모달 창에 표시되는 썸네일에 표시된 작성자의 발표"와 같은 경로를 포함하여 애플리케이션에서 가능한 모든 경로가 포함되어 있습니다. 대부분 액세스되는 경로는 거의 몇 개(홈 페이지, 단일, 작성자, 태그 및 모든 페이지, 모두 추가 속성 없음)로 30KB 부근에서 훨씬 더 작은 파일을 생성해야 합니다.
요청된 URL에서 경로 가져오기
요청한 URL에서 경로를 식별할 수 있어야 합니다. 예를 들어:
-
https://getpop.org/en/u/leo/는 "author" 경로에 매핑됩니다. -
https://getpop.org/en/u/leo/?tab=followers는 "작가의 팔로워" 경로에 매핑됩니다. -
https://getpop.org/en/tags/internet/은 "태그" 경로에 매핑됩니다. -
https://getpop.org/en/tags/는 "page/tags/" 경로에 매핑됩니다. - 등등.
이를 수행하려면 URL을 평가하고 경로를 고유하게 만드는 요소인 계층 구조와 모든 속성(형식, 탭 및 대상)을 추론해야 합니다. 속성 식별은 URL의 매개변수이기 때문에 문제가 되지 않습니다. 유일한 문제는 URL을 여러 패턴과 일치시켜 URL에서 계층 구조(홈, 작성자, 단일, 페이지 또는 태그)를 추론하는 것입니다. 예를 들어,
-
https://getpop.org/en/u/로 시작하는 모든 것이 작성자입니다. - https://getpop.org/en/tags/로 시작하지만 정확히
https://getpop.org/en/tags/가 아닌 것은 태그입니다. 정확히https://getpop.org/en/tags/이면 페이지입니다. - 등등.
resourceloader.js의 321행에서 시작하여 구현된 아래 기능에는 이러한 모든 계층 구조에 대한 패턴이 포함된 구성이 제공되어야 합니다. 먼저 URL에 하위 경로가 없는지 확인합니다. 이 경우 "home"입니다. 그런 다음 "author", "tag" 및 "single"에 대한 계층 구조가 일치하는지 하나씩 확인합니다. 그 중 어느 것에도 성공하지 못하면 "페이지"인 기본 사례입니다.
window.popResourceLoader = { // The config will be populated externally, using a config.js file, generated by a script config : {}, getPath : function(url) { var parser = document.createElement('a'); parser.href = url; return parser.pathname; }, getHierarchy : function(url) { var path = this.getPath(url); if (!path) { return 'home'; } var config = this.config; if (path.startsWith(config.paths.author) && path != config.paths.author) { return 'author'; } if (path.startsWith(config.paths.tag) && path != config.paths.tag) { return 'tag'; } // We must also check that this path is, itself, not a potential page (https://getpop.org/en/posts/articles/ is "page", but https://getpop.org/en/posts/this-is-a-post/ is "single") if (config.paths.single.indexOf(path) === -1 && config.paths.single.some(function(single_path) { return path.startsWith(single_path) && path != single_path;})) { return 'single'; } return 'page'; }, ... };필요한 모든 데이터가 이미 데이터베이스(모든 범주, 모든 페이지 슬러그 등)에 있으므로 개발 또는 준비 환경에서 이 구성 파일을 자동으로 생성하는 스크립트를 실행합니다. 구현된 스크립트는 resourceloader-config.php로, 키 "paths" 아래에 "author", "tag" 및 "single" 계층 구조에 대한 URL 패턴이 있는 config.js를 생성합니다.
popResourceLoader.config = { "paths": { "author": "u/", "tag": "tags/", "single": ["posts/articles/", "posts/announcements/", ...] }, ... };Loading Resources for the Route
Once we have identified the route, we can obtain the required assets from the generated JavaScript file under the key “resources”, which looks like this:
config.resources = { "home": { "1": [1, 110, ...], "2": [2, 111, ...], ... }, "author": { "7": [6, 114, ...], "8": [7, 114, ...], ... }, "tag": { "119": [66, 127, ...], "120": [66, 127, ...], ... }, "single": { "posts/": { "7": [190, 142, ...], "3": [190, 142, ...], ... }, "events/": { "7": [213, 389, ...], "3": [213, 389, ...], ... }, ... }, "page": { "log-in/": { "3": [233, 115, ...] }, "log-out/": { "3": [234, 115, ...] }, "add-post/": { "3": [239, 398, ...] }, "posts/": { "120": [268, 127, ...], "122": [268, 127, ...], ... }, ... } };At the first level, we have the hierarchy (home, author, tag, single or page). Hierarchies are divided into two groups: those that have only one set of resources (home, author and tag), and those that have a specific subpath (page permalink for the pages, custom post type or category for the single). Finally, at the last level, for each key ID (which represents a unique combination of the possible values of “format”, “tab” and “target”, stored under “keys”), we have an array of two elements: [JS bundleGroup ID, CSS bundleGroup ID], plus additional bundleGroup IDs if executing progressive booting (JS bundleGroups to be loaded as "async" or "defer" are bundled separately; this will be explained in the optimizations section below).
Please note: For the single hierarchy, we have different configurations depending on the custom post type. This can be reflected in the subpath indicated above (for example, events and posts ) because this information is in the URL (for example, https://getpop.org/en/posts/the-winners-of-climate-change-techno-fixes/ and https://getpop.org/en/events/debate-post-fork/ ), so that, when clicking on a link, we will know the corresponding post type and can thus infer the corresponding route. However, this is not the case with the author hierarchy. As indicated earlier, an author may have three different configurations, depending on the user role ( individual , organization or community ); however, in this file, we've defined only one configuration for the author hierarchy, not three. That is because we are not able to tell from the URL what is the role of the author: user leo (under https://getpop.org/en/u/leo/ ) is an individual, whereas user pop (under https://getpop.org/en/u/pop/ ) is a community; however, their URLs have the same pattern. If we could instead have the URLs https://getpop.org/en/u/individuals/leo/ and https://getpop.org/en/u/communities/pop/ , then we could add a configuration for each user role. However, I've found no way to achieve this in WordPress. As a consequence, only for the API mode, we must merge the three routes (individuals, organizations and communities) into one, which will have all of the resources for the three cases; and clicking on the link for user leo will also load the resources for organizations and communities, even if we don't need them.
Finally, when a URL is requested, we obtain its route, from which we obtain the bundleGroup IDs (for both JavaScript and CSS assets). From each bundleGroup, we find the corresponding bundles under bundlegroups . Then, for each bundle, we obtain all resources under the key bundles . Finally, we identify which assets have not yet been loaded, and we load them by getting their source, which is stored under the key sources . The whole logic is coded starting from line 472 in resourceloader.js.
And with that, we have implemented code-splitting for our application! From now on, we can get better loading times by applying optimizations. Let's tackle that next.
5. Applying Optimizations
The objective is to load as little code as possible, as delayed as possible, and to cache as much of it as possible. Let's explore how to do this.
Splitting Up the Code Into Smaller Units
A single JavaScript asset may implement several functions (by calling popJSLibraryManager.register ), yet maybe only one of those functions is actually needed by the route. Thus, it makes sense to split up the asset into several subassets, implementing a single function on each of them, and extracting all common code from all of the functions into yet another asset, depended upon by all of them.
For instance, in the past, there was a unique file, waypoints.js , that implemented the functions waypointsFetchMore , waypointsTheater and a few more. However, in most cases, only the function waypointsFetchMore was needed, so I was loading the code for the function waypointsTheater unnecessarily. Then, I split up waypoints.js into the following assets:
- waypoints.js, with all common code and implementing no public functions;
- waypoints-fetchmore.js, which implements just the public function
waypointsFetchMore; - waypoints-theater.js, which implements just the public function
waypointsTheater.
Evaluating how to split the files is a manual job. Luckily, there is a tool that greatly eases the task: Chrome Developer Tools' “Coverage” tab, which displays in red those portions of JavaScript code that have not been invoked:
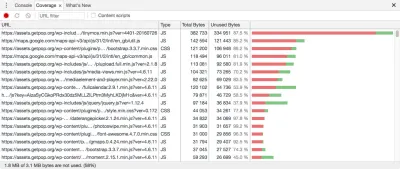
By using this tool, we can better understand how to split our JavaScript files into more granular units, thus reducing the amount of unneeded code that is loaded.
Integration With Service Workers
By precaching all of the resources using service workers, we can be pretty sure that, by the time the response is back from the server, all of the required assets will have been loaded and parsed. I wrote an article on Smashing Magazine on how to accomplish this.
Progressive Booting
PoP's architecture plays very nice with the concept of loading assets in different stages. When defining the JavaScript methods to execute on each module (by doing $this->add_jsmethod($methods, 'calendar') ), these can be set as either critical or non-critical . By default, all methods are set as non-critical, and critical methods must be explicitly defined by the developer, by adding an extra parameter: $this->add_jsmethod($methods, 'calendar', 'critical') . Then, we will be able to load scripts immediately for critical functions, and wait until the page is loaded to load non-critical functions, the JavaScript files of which are loaded using defer .
(function($){ window.popManager = { init : function() { var that = this; $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'critical'); ... }); window.addEventListener('load', function() { $.each(this.configuration, function(pageSectionId, configuration) { ... this.runJSMethods(pageSection, configuration, 'non-critical'); ... }); }); ... }, ... }; })(jQuery);The gains from progressive booting are major: The JavaScript engine needs not spend time parsing non-critical JavaScript initially, when a quick response to the user is most important, and overall reduces the time to interactive.
Testing And Analizying Performance Gains
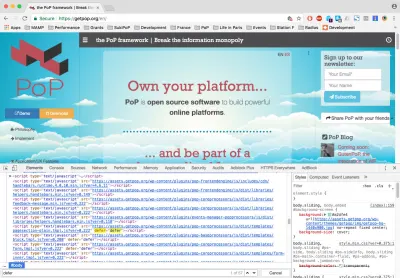
We can use https://getpop.org/en/, a PoP website, for testing purposes. When loading the home page, opening Chrome Developer Tools' “Elements” tab and searching for “defer”, it shows 4 occurrences. Thanks to progressive booting, that is 4 bundleGroup JavaScript files containing the contents of 57 Javascript files with non-critical methods that could wait until the website finished loading to be loaded:
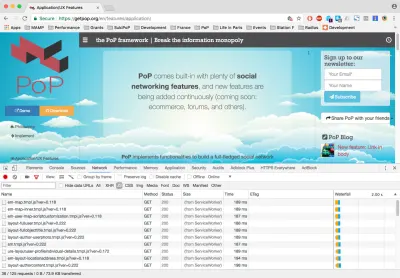
If we now switch to the “Network” tab and click on a link, we can see which assets get loaded. For instance, click on the link “Application/UX Features” on the left side. Filtering by JavaScript, we see it loaded 38 files, including JavaScript libraries and Handlebars templates. Filtering by CSS, we see it loaded 9 files. These 47 files have all been loaded on demand:
Let's check whether the loading time got boosted. We can use WebPagetest to measure the application with and without code-splitting, and calculate the difference.
- Without code-splitting: testing URL, WebPagetest results

- With code-splitting, loading resources: testing URL, WebPagetest Results

- With code-splitting, loading a bundleGroup: testing URL, WebPagetest Results

We can see that when loading the app bundle with all resources or when doing code-splitting and loading resources, there is not so much gain. However, when doing code-splitting and loading a bundleGroup, the gains are significant: 1.7 seconds in loading time, 500 milliseconds to the first meaningful paint, and 1 second to interactive.
Conclusion: Is It Worth It?
You might be thinking, Is it worth it all this trouble? Let's analyze the advantages and disadvantages of implementing our own code-splitting features.
단점
- 우리는 그것을 유지해야 합니다.
Webpack을 사용했다면 커뮤니티에 의존하여 소프트웨어를 최신 상태로 유지하고 플러그인 에코시스템의 이점을 누릴 수 있습니다. - 스크립트를 실행하는 데 시간이 걸립니다.
PoP 웹사이트 Agenda Urbana에는 304개의 다른 경로가 있으며, 이 경로에서 422개의 고유 리소스 세트가 생성됩니다. 이 웹사이트의 경우 2012년 MacBook Pro를 사용하여 자산 종속성 맵을 생성하는 스크립트를 실행하는 데 약 8분이 소요되며 모든 리소스가 포함된 목록을 생성하고 번들 및 번들 그룹 파일을 생성하는 스크립트를 실행하는 데 15분이 소요됩니다. . 커피 한 잔 하기에는 충분한 시간입니다! - 스테이징 환경이 필요합니다.
스크립트를 실행하기 위해 약 25분을 기다려야 하는 경우 프로덕션에서 실행할 수 없습니다. 프로덕션 시스템과 정확히 동일한 구성의 스테이징 환경이 필요합니다. - 관리를 위해 추가 코드가 웹사이트에 추가됩니다.
85KB의 코드는 그 자체로는 작동하지 않으며 단순히 다른 코드를 관리하기 위한 코드입니다. - 복잡성이 추가됩니다.
이는 자산을 더 작은 단위로 분할하려는 경우에 불가피합니다. Webpack은 또한 애플리케이션에 복잡성을 추가합니다.
장점
- 그것은 WordPress와 함께 작동합니다.
Webpack은 기본적으로 WordPress와 함께 작동하지 않으며 작동하려면 몇 가지 해결 방법이 필요합니다. 이 솔루션은 WordPress에서 즉시 사용할 수 있습니다(PoP가 설치되어 있는 한). - 확장 가능하고 확장 가능합니다.
JavaScript 파일은 요청 시 로드되기 때문에 응용 프로그램의 크기와 복잡성은 제한 없이 커질 수 있습니다. - 그것은 Gutenberg(일명 미래의 WordPress)를 지원합니다.
요청 시 JavaScript 프레임워크를 로드할 수 있기 때문에 개발자가 선택한 프레임워크에서 코딩될 것으로 예상되는 Gutenberg의 블록(Gutenblocks라고 함)을 지원하며 동일한 애플리케이션에 다른 프레임워크가 필요할 수 있는 잠재적인 결과가 있습니다. - 편리합니다.
빌드 도구는 구성 파일 생성을 처리합니다. 기다리는 것 외에 추가 노력은 필요하지 않습니다. - 최적화를 쉽게 만듭니다.
현재 WordPress 플러그인이 JavaScript 자산을 선택적으로 로드하려면 많은 조건문을 사용하여 페이지 ID가 올바른지 확인합니다. 이 도구를 사용하면 그럴 필요가 없습니다. 프로세스는 자동입니다. - 응용 프로그램이 더 빨리 로드됩니다.
이것이 우리가 이 도구를 코딩한 이유입니다. - 스테이징 환경이 필요합니다.
긍정적인 부작용으로 안정성이 향상됩니다. 프로덕션 환경에서 스크립트를 실행하지 않으므로 아무 것도 중단하지 않습니다. 배포 프로세스는 예기치 않은 동작으로 인해 실패하지 않습니다. 개발자는 프로덕션에서와 동일한 구성을 사용하여 애플리케이션을 테스트해야 합니다. - 그것은 우리의 응용 프로그램에 맞게 사용자 정의됩니다.
오버헤드나 해결 방법은 없습니다. 우리가 얻는 것은 우리가 작업하고 있는 아키텍처를 기반으로 정확히 우리가 필요로 하는 것입니다.
결론적으로: 예, 이제 WordPress 웹 사이트에서 요청 시 로드 자산을 적용하고 더 빠르게 로드할 수 있기 때문에 그만한 가치가 있습니다.
추가 리소스
- ""코드 분할" 가이드를 포함한 Webpack
- "더 나은 Webpack 빌드"(비디오), K. Adam White
Webpack과 WordPress의 통합 - "구텐베르크와 미래의 WordPress", Morten Rand-Hendriksen, WP Tavern
- "WordPress는 Gutenberg 블록을 구축하기 위한 JavaScript Framework-Agnostic 접근 방식을 탐색합니다." Sarah Gooding, WP Tavern