
에이전시에서 새로운 서버리스 데이터베이스 기술 선택(사례 연구)
게시 됨: 2022-03-10이 기사는 모든 소프트웨어 개발 팀을 위해 운영 데이터 작업을 생산적이고 확장 가능하며 안전하게 만드는 Fauna의 친애하는 친구들에 의해 친절하게 지원되었습니다. 감사합니다!

새로운 기술을 채택하는 것은 리더십 역할을 하는 기술자에게 가장 어려운 결정 중 하나입니다. 이것은 다른 조직을 위해 소프트웨어를 구축하든 자신의 조직 내에서 소프트웨어를 구축하든 종종 크고 불편한 위험 영역입니다.
소프트웨어 엔지니어로서 지난 12년 동안 저는 새로운 기술을 점점 더 자주 평가 해야 하는 처지에 놓이게 되었습니다. 이것은 차세대 프론트엔드 프레임워크, 새로운 언어 또는 서버리스와 같은 완전히 새로운 아키텍처일 수 있습니다.
실험 단계는 종종 재미있고 흥미진진합니다. 소프트웨어 엔지니어가 가장 집에 있는 곳은 "아하" 순간의 참신함과 행복감을 받아들이면서 새로운 개념을 모색하는 곳입니다. 엔지니어로서 우리는 생각하고 수정하는 것을 좋아하지만 충분한 경험을 통해 모든 엔지니어는 가장 놀라운 기술에도 흠이 있다는 것을 배웁니다. 아직 찾지 못했을 뿐입니다.
이제 크리에이티브 에이전시의 공동 설립자로서 나와 팀은 종종 새로운 기술을 사용하는 독특한 위치에 있습니다. 우리는 새로운 것을 소개할 완벽한 기회가 되는 많은 미개발 프로젝트를 봅니다. 또한 이러한 프로젝트는 더 큰 조직과 기술적으로 격리된 수준을 확인하고 종종 이전 결정에 대한 부담을 덜 받습니다.
즉, 좋은 에이전시 리더는 다른 사람의 큰 아이디어를 돌보고 그것을 세상에 전달하는 일을 맡게 됩니다. 우리는 우리 자신의 프로젝트보다 훨씬 더 조심스럽게 다루어야 합니다. 나는 새로운 기술에 대한 최종 결정을 내릴 때마다 공동 창립자인 Stack Overflow Joel Spolski의 다음과 같은 지혜를 종종 생각합니다.
"그것이 충분히 좋다는 것을 정말로 알기 전에 또는 아무리 노력해도 할 수 없다는 것을 깨닫기 전에 1, 2년 동안 그 물건으로 땀을 흘리고 피를 흘려야 합니다."
이것은 두려움입니다. 이것은 기술 리더가 자신을 찾고 싶어하지 않는 곳입니다. 실제 프로젝트를 위한 새로운 기술을 선택하는 것은 충분히 어렵지만 에이전시로서 이러한 결정을 다른 사람의 프로젝트, 누군가와 함께 해야 합니다. 다른 사람의 꿈, 다른 사람의 돈. 에이전시에서 마지막으로 원하는 것은 프로젝트 마감일에 가까운 흠집 중 하나를 찾는 것입니다. 빡빡한 일정과 예산으로 인해 특정 임계값을 넘은 후에는 방향을 바꾸는 것이 거의 불가능 하므로 기술이 중요한 작업을 수행할 수 없거나 프로젝트에서 너무 늦게 신뢰할 수 없다는 사실을 발견하는 것은 재앙이 될 수 있습니다.
소프트웨어 엔지니어로 일하면서 SaaS 회사와 크리에이티브 에이전시에서 일했습니다. 프로젝트에 새로운 기술을 적용할 때 이 두 환경은 기준이 매우 다릅니다. 기준이 중복되지만 대체로 에이전시 환경은 엄격한 예산과 엄격한 시간 제약 으로 작업해야 합니다. 우리는 우리가 구축한 제품이 시간이 지남에 따라 잘 숙성되기를 바라지만, 덜 입증된 것에 투자하거나 더 가파른 학습 곡선과 거친 가장자리를 가진 기술을 채택하는 것이 더 어려운 경우가 많습니다.
즉, 기관에는 단일 조직에는 없는 몇 가지 고유한 제약 조건이 있습니다. 효율성과 안정성을 위해 편향되어야 합니다. 청구 가능 시간은 프로젝트 완료 시 최종 측정 단위인 경우가 많습니다. 저는 설정이나 빌드 파이프라인에 하루나 이틀을 보내는 것이 별 문제가 되지 않는 SaaS 회사에 있었습니다.
에이전시에서 이러한 유형의 시간 비용은 재무 팀이 눈에 보이는 결과가 거의 나타나지 않는 이익 마진을 좁히는 것을 보기 때문에 관계에 부담을 줍니다. 또한 프로젝트의 장기 유지 관리와 반대로 프로젝트를 클라이언트에게 다시 넘겨야 하는 경우 어떤 일이 발생하는지 고려해야 합니다. 따라서 우리는 우리가 선택한 기술의 효율성, 학습 곡선 및 안정성에 대해 편향되어야 합니다.
나는 새로운 기술을 평가할 때 세 가지 중요한 영역을 봅니다.
- 기술
- 개발자 경험
- 사업
이러한 각 영역에는 내가 실제로 코드를 살펴보고 실험을 시작하기 전에 충족된 기준 세트가 있습니다. 이 기사에서는 이러한 기준을 살펴보고 프로젝트에 대한 새 데이터베이스를 고려하는 예를 사용하고 각 렌즈에서 높은 수준에서 검토할 것입니다. 이와 같은 유형의 결정을 내리는 것은 이 프레임워크를 실제 세계에 적용하는 방법을 보여주는 데 도움이 될 것입니다.
기술
새로운 기술을 평가할 때 가장 먼저 살펴봐야 할 사항은 해당 솔루션이 해결해야 한다고 주장하는 문제를 해결할 수 있는지 여부입니다. 기술이 프로세스 및 비즈니스 운영에 어떻게 도움이 되는지 알아보기 전에 먼저 기능 요구 사항을 충족 하는지 확인하는 것이 중요합니다. 여기에서 우리가 사용하고 있는 기존 솔루션과 이 새로운 솔루션이 어떻게 비교되는지 살펴보고 싶습니다.
나는 스스로에게 다음과 같은 질문을 할 것이다.
- 최소한 기존 솔루션이 해결하는 문제를 해결합니까?
- 어떤 면에서 이 솔루션이 더 낫습니까?
- 어떤 면에서 더 나빠요?
- 더 나쁜 분야의 경우 이러한 단점을 극복하기 위해 무엇을 해야 합니까?
- 여러 도구를 대신할 것인가?
- 기술이 얼마나 안정적인가?
왜?
이 시점에서 우리가 다른 솔루션을 찾는 이유도 검토하고 싶습니다. 간단한 대답은 기존 솔루션으로는 해결되지 않는 문제 에 직면해 있다는 것입니다. 그러나 이러한 경우는 종종 드뭅니다. 우리는 오늘날 우리가 가지고 있는 모든 기술로 수년에 걸쳐 많은 소프트웨어 문제를 해결했습니다. 일반적으로 일어나는 일은 우리가 현재 하고 있는 일을 더 쉽고, 더 안정적이고, 더 빠르거나, 더 저렴하게 만드는 새로운 기술에 의존하는 것입니다.
React를 예로 들어 보겠습니다. jQuery 또는 Vanilla JavaScript가 작업을 수행할 때 React를 채택하기로 결정한 이유는 무엇입니까? 이 경우 프레임워크를 사용하면 이것이 상태 저장 프런트엔드를 처리하는 훨씬 더 나은 방법임을 강조했습니다. DOM을 직접 조작하는 대신 데이터 구조로 작업하여 필터링 및 정렬 기능과 같은 기능을 구축하는 것이 더 빨라졌습니다. 이는 시간을 절약하고 솔루션의 안정성을 높였습니다.
Typescript 는 코드의 안정성과 유지 관리 가능성이 증가했기 때문에 채택하기로 결정한 또 다른 예입니다. 새로운 기술을 채택하면 해결하려는 명확한 문제가 없는 경우가 많습니다. 오히려 최신 상태를 유지하고 현재 사용하고 있는 것보다 더 효율적이고 안정적인 솔루션을 찾는 것뿐입니다.
데이터베이스의 경우 특히 서버리스 옵션 으로의 전환을 고려했습니다. 우리는 서버리스 애플리케이션과 배포로 많은 성공을 거두어 조직의 오버헤드를 줄이는 것을 보았습니다. 이것이 부족하다고 느꼈던 영역 중 하나는 데이터 계층이었습니다. Amazon Aurora, Fauna, Cosmos 및 Firebase와 같은 서비스가 데이터베이스에 서버리스 원칙을 적용하는 것을 보았고 이제 스스로 도약할 때인지 확인하고 싶었습니다. 이 경우 우리는 운영 오버헤드를 낮추고 개발 속도와 효율성을 높이려고 했습니다.
이 수준에서는 새로운 제안을 시작하기 전에 그 이유 를 이해하는 것이 중요합니다. 이것은 당신이 새로운 문제를 해결하고 있기 때문일 수 있지만 훨씬 더 자주 당신은 이미 해결하고 있는 유형의 문제를 해결하는 능력을 향상시키려고 합니다. 이 경우 워크플로에 의미 있는 개선을 제공할 수 있는 항목을 파악하기 위해 방문했던 위치에 대한 목록 을 작성해야 합니다. 서버리스 데이터베이스를 살펴보는 예제를 바탕으로 현재 문제를 해결하는 방법과 이러한 솔루션이 부족한 부분을 살펴봐야 합니다.
우리가 있었던 곳…
에이전시로서 우리는 이전에 MySQL, PostgreSQL, MongoDB, DynamoDB, BigQuery 및 Firebase Cloud Storage를 포함하되 이에 국한되지 않는 광범위한 데이터베이스를 사용해 왔습니다. 우리 작업의 대부분은 PostgreSQL, MongoDB 및 Firebase 실시간 데이터베이스의 세 가지 핵심 데이터베이스를 중심으로 이루어졌습니다. 실제로 이들 각각에는 세미 서버리스 오퍼링이 있지만 새로운 오퍼링의 일부 주요 기능으로 인해 이전 가정을 다시 평가해야 했습니다. 먼저 이들 각각에 대한 역사적 경험을 살펴보고 우선 대안을 고려하게 된 이유를 살펴보겠습니다.
우리는 일반적으로 더 크고 장기적인 프로젝트를 위해 PostgreSQL 을 선택했습니다. 이것이 거의 모든 것에 대해 전투 테스트를 거친 황금 표준이기 때문입니다. 클래식 트랜잭션, 정규화된 데이터를 지원하며 ACID를 준수합니다. 거의 모든 언어로 사용할 수 있는 풍부한 도구와 ORM이 있으며 JSON 열을 지원하는 임시 NoSQL 데이터베이스로도 사용할 수 있습니다. 기존의 많은 프레임워크, 라이브러리 및 프로그래밍 언어와 잘 통합되어 어디에서나 사용할 수 있는 진정한 도구입니다. 또한 오픈 소스이므로 한 공급업체에 얽매이지 않습니다. 그들이 말했듯이 아무도 Postgres를 선택했다고 해고된 적이 없습니다.
즉, 우리는 노드 지향 상점이 되면서 점차 PostgreSQL을 덜 사용하게 되었습니다. 우리는 노드용 ORM이 부족하고 더 많은 사용자 정의 쿼리가 필요하다는 것을 발견했으며(지금은 문제가 줄어들었지만) NoSQL은 JavaScript 또는 TypeScript 런타임에서 작업할 때 더 자연스럽게 적합하다고 느꼈습니다. 즉, 전자 상거래 워크플로와 같은 고전적인 관계형 모델링 으로 매우 빠르게 수행할 수 있는 프로젝트가 종종 있었습니다. 그러나 데이터베이스의 로컬 설정을 처리하고 팀 간의 테스트 흐름을 통합하고 로컬 마이그레이션을 처리하는 것은 우리가 좋아하지 않았고 NoSQL, 클라우드 기반 데이터베이스가 더 대중화되면서 뒤로 남겨두는 일이었습니다.
우리가 선호하는 백엔드로 Node.js를 채택하면서 MongoDB 가 점점 더 많이 사용되는 데이터베이스가 되었습니다. MongoDB Atlas로 작업하면 우리 팀이 사용할 수 있는 빠른 개발 및 테스트 데이터베이스를 쉽게 만들 수 있습니다. 한동안 MongoDB는 ACID를 준수하지 않았고 트랜잭션을 지원하지 않았으며 내부 조인과 유사한 작업이 너무 많았기 때문에 전자 상거래 애플리케이션의 경우 여전히 Postgres를 가장 자주 사용했습니다. 즉, 함께 제공되는 풍부한 라이브러리가 있으며 Mongo의 쿼리 언어와 일류 JSON 지원은 우리가 관계형 데이터베이스에서 경험하지 못한 속도와 효율성을 제공했습니다. MongoDB는 최근 ACID 트랜잭션에 대한 지원을 추가했지만 오랫동안 이것이 우리가 대신 Postgres를 선택한 주된 이유였습니다.
MongoDB는 또한 우리에게 새로운 차원의 유연성을 제공했습니다. 에이전시 프로젝트 중에는 요구 사항이 변경될 수 있습니다. 아무리 강력하게 방어하더라도 막바지 데이터 요구 사항 은 항상 존재합니다. 일반적으로 NoSQL 데이터베이스를 사용하면 데이터 구조의 유연성으로 인해 이러한 유형의 변경이 덜 가혹해졌습니다. 프로젝트가 햇빛을 보기도 전에 추가 및 제거 및 추가된 열을 관리하기 위해 마이그레이션 파일로 가득 찬 폴더로 끝나지 않았습니다.
서비스로서 Mongo Atlas는 데이터베이스 클라우드 서비스에서 우리가 원했던 것과도 상당히 유사했습니다. Atlas를 관리하는 데 약간의 운영 오버헤드가 있기 때문에 Atlas를 세미 서버리스 제품으로 생각하고 싶습니다. 특정 크기의 데이터베이스를 프로비저닝하고 미리 메모리 양을 선택해야 합니다. 이러한 것들은 자동으로 확장되지 않으므로 더 많은 공간이나 메모리를 제공해야 할 때를 모니터링해야 합니다. 진정한 서버리스 데이터베이스에서는 이 모든 것이 자동으로 요청 시 발생합니다.
또한 몇 가지 프로젝트에 Firebase 실시간 데이터베이스를 활용했습니다. 이것은 실제로 데이터베이스가 온디맨드로 확장 및 축소되는 서버리스 제품이었고 사용한 만큼만 지불하는 가격 책정 방식 으로 확장이 사전에 알려지지 않았고 예산이 제한된 애플리케이션에 적합했습니다. 간단한 데이터 요구 사항이 있는 단기 프로젝트에 MongoDB 대신 이것을 사용했습니다.
Firebase에 대해 우리가 즐기지 못한 한 가지는 우리가 익숙했던 정규화된 데이터를 기반으로 구축된 일반적인 관계형 모델에서 더 멀리 떨어져 있다는 느낌이었습니다. 데이터 구조를 평평하게 유지 한다는 것은 종종 중복이 더 많다는 것을 의미했으며, 이는 프로젝트가 성장함에 따라 약간 추악해질 수 있습니다. 여러 위치에서 동일한 데이터를 업데이트하거나 다른 참조를 함께 결합하려고 하면 코드에서 추론하기 어려울 수 있는 여러 쿼리가 발생합니다. Firebase는 마음에 들었지만 쿼리 언어에 반한 적은 없었고 문서가 부실하다는 것을 발견하기도 했습니다.
일반적으로 MongoDB와 Firebase는 모두 비정규화된 데이터에 비슷한 초점을 두었고 효율적인 트랜잭션에 대한 액세스 없이 우리는 종종 관계형 데이터베이스에서 모델링하기 쉬운 많은 워크플로를 발견했습니다. NoSQL 대응. 기존 SQL 데이터베이스의 견고성과 관계형 모델링을 통해 이러한 NoSQL 제품의 유연성과 용이성을 얻을 수 있었다면 정말 훌륭한 일치 항목을 찾았을 것입니다. 우리는 MongoDB가 더 나은 API와 기능을 가지고 있다고 느꼈지만 Firebase는 운영상 진정한 서버리스 모델을 가지고 있었습니다.
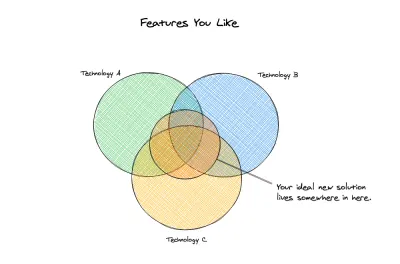
우리의 이상
이 시점에서 우리는 어떤 새로운 옵션을 고려할 것인지 살펴볼 수 있습니다. 우리는 이전 솔루션을 명확하게 정의했으며 새 솔루션에서 최소한 포함해야 하는 중요한 사항을 식별했습니다. 기본 또는 최소 요구 사항 집합이 있을 뿐만 아니라 새 솔루션으로 완화되었으면 하는 문제 집합도 있습니다. 다음은 기술 요구 사항 입니다.
- 온디맨드 규모의 서버리스 운영
- 유연한 모델링(스키마리스)
- 마이그레이션 또는 ORM에 의존하지 않음
- ACID 준수 트랜잭션
- 관계 및 정규화된 데이터 지원
- 서버리스 및 기존 백엔드 모두에서 작동
이제 필수 목록이 있으므로 실제로 몇 가지 옵션을 평가할 수 있습니다. 새로운 솔루션이 여기에서 모든 목표를 달성하는 것은 중요하지 않을 수 있습니다. 기존 솔루션이 겹치지 않는 기능의 올바른 조합을 맞추는 것일 수도 있습니다. 예를 들어 스키마 없는 유연성 을 원한다면 ACID 트랜잭션을 포기해야 했습니다. (이것은 데이터베이스의 경우 오랫동안 그랬습니다.)
다른 도메인의 예는 템플릿 렌더링에서 typescript 유효성 검사를 사용하려면 TSX 및 React를 사용해야 하는 경우입니다. Svelte 또는 Vue와 같은 옵션을 사용하는 경우 템플릿 렌더링 을 통해 부분적으로 그러나 완전히는 가질 수 없습니다. 따라서 React 및 TypeScript의 템플릿 수준 유형 검사와 함께 Svelte의 작은 공간과 속도를 제공하는 솔루션은 다른 기능이 누락된 경우에도 채택하기에 충분할 수 있습니다. 욕구와 필요의 균형은 프로젝트마다 바뀔 것입니다. 값이 어디에 있는지 파악하고 분석에서 가장 중요한 포인트를 표시하는 방법을 결정하는 것은 사용자의 몫입니다.
이제 솔루션을 살펴보고 원하는 솔루션과 비교하여 평가하는 방법을 확인할 수 있습니다. Fauna 는 글로벌 배포와 함께 온디맨드 규모를 자랑하는 서버리스 데이터베이스 솔루션 입니다. ACID 호환 트랜잭션을 제공하고 관계형 쿼리 및 정규화된 데이터를 기능으로 지원하는 스키마 없는 데이터베이스입니다. Fauna는 서버리스 애플리케이션과 보다 전통적인 백엔드 모두에서 사용할 수 있으며 가장 인기 있는 언어로 작업할 수 있는 라이브러리를 제공합니다. Fauna는 인증을 위한 워크플로와 쉽고 효율적인 멀티 테넌시를 추가로 제공합니다. 이 두 가지 기술은 평가에서 두 기술이 맞붙을 때 흔들리는 요소가 될 수 있기 때문에 주목해야 할 견고한 추가 기능입니다.
이제 이러한 모든 강점을 살펴본 후 약점을 평가해야 합니다 . 그 중 하나는 Fauna가 오픈 소스가 아니라는 것입니다. 이는 공급업체 종속 또는 통제할 수 없는 비즈니스 및 가격 변경의 위험이 있음을 의미합니다. 오픈 소스는 당신이 원하거나 잠재적으로 프로젝트에 다시 기여할 수 있다면 종종 다른 공급업체에 기술을 제공할 수 있기 때문에 유용할 수 있습니다.
에이전시 세계에서 벤더 종속 은 가격 때문이 아니라 우리가 면밀히 관찰해야 하는 것입니다. 그러나 기본 비즈니스의 생존 가능성이 중요합니다. 개발 중이거나 몇 년 된 프로젝트에서 데이터베이스를 변경해야 하는 것은 에이전시에게 재앙입니다. 종종 클라이언트는 이에 대한 비용을 부담해야 하는데, 이는 즐거운 대화가 아닙니다.
우리가 우려했던 또 다른 약점은 JAMstack 에 대한 초점입니다. 우리는 JAMstack을 좋아하지만 다양한 기존 웹 애플리케이션을 더 자주 구축하고 있습니다. 우리는 Fauna가 이러한 사용 사례를 계속 지원하기를 바랍니다. JAMstack에 올인한 호스팅 제공업체와 함께 과거에 좋지 않은 경험을 했고 결국 서비스에서 상당히 많은 사이트를 마이그레이션해야 했기 때문에 모든 사용 사례에서 계속해서 견고한 지원. 현재로서는 이것이 사실인 것 같으며 Fauna에서 제공하는 서버리스 워크플로는 실제로 더 전통적인 애플리케이션을 상당히 잘 보완할 수 있습니다.
이 시점에서 우리는 기능 연구를 완료했으며 이 솔루션이 실행 가능한지 여부를 알 수 있는 유일한 방법은 코드를 작성하는 것입니다. 에이전시 환경에서는 사람들이 여러 솔루션을 평가하기 위해 일정에서 몇 주가 소요될 수 없습니다. 이것이 대행사와 SaaS 환경 에서 일하는 것의 특성입니다. 후자의 경우 올바른 솔루션에 도달하기 위해 몇 가지 프로토타입을 빌드할 수 있습니다. 에이전시에서는 며칠 동안 실험을 하거나 사이드 프로젝트를 수행할 수 있는 기회를 얻을 수 있지만 대체로 이 단계에서 이를 하나 또는 두 개의 기술로 좁힌 다음 키보드에 손가락을 올려야 합니다.
개발자 경험
신기술의 경험 측면을 판단하는 것은 본질적으로 주관적이기 때문에 세 가지 영역 중 아마도 가장 어려울 것입니다. 또한 팀마다 편차가 있을 것입니다. 예를 들어 Ruby 프로그래머, Python 프로그래머, Rust 프로그래머에게 서로 다른 언어 기능에 대한 의견을 물어보면 상당히 다양한 답변을 얻을 수 있습니다. 따라서 경험을 판단하기 전에 먼저 팀 전체에 가장 중요한 특성을 결정해야 합니다.

에이전시의 경우 개발자 경험과 관련하여 두 가지 주요 병목 현상 이 발생한다고 생각합니다.

- 설정 시간 및 구성
- 학습 가능성
이 두 가지는 서로 다른 방식으로 신기술의 장기적 실행 가능성 에 영향을 미칩니다. 에이전시에서 임시 개발자 팀을 동기화 상태로 유지하는 것은 골치 아픈 일입니다. 초기 설정 비용과 구성이 많은 도구는 에이전시에서 사용하기 어려운 것으로 유명합니다. 다른 하나는 학습 가능성과 개발자가 새로운 기술을 얼마나 쉽게 성장시킬 수 있는지입니다. 개발자 경험을 평가하기 시작할 때 이것이 왜 내 기반인지 더 자세히 살펴보겠습니다.
설정 시간 및 구성
에이전시는 구성에 대한 인내심과 시간이 거의 없는 경향이 있습니다. 저는 인체공학적 디자인의 날카로운 도구를 좋아하므로 당면한 비즈니스 문제를 신속하게 해결할 수 있습니다. 몇 년 전에 저는 많은 구성과 관련된 복잡한 로컬 설정이 있고 설정 프로세스의 임의 지점에서 종종 실패하는 SaaS 회사에서 일했습니다. 일단 설정되면 기존의 지혜는 아무 것도 건드리지 않고 다른 컴퓨터에서 다시 설정해야 할 만큼 회사에 오래 있지 않기를 바랍니다. 나는 emacs 설정의 작은 부분 하나하나를 구성하는 것을 매우 즐겼고 고장난 로컬 환경에 몇 시간을 낭비하는 것을 전혀 생각하지 않는 개발자를 만났습니다.
일반적으로 저는 에이전시 엔지니어들이 일상 업무에서 이러한 유형의 일을 경멸한다는 사실을 알게 되었습니다. 집에 있는 동안에는 이러한 유형의 도구를 만지작거릴 수 있지만 마감 시간이 되면 제대로 작동하는 도구만큼 좋은 것은 없습니다. 대행사에서 우리는 일반적으로 각 개인의 취향에 맞게 각 기술을 구성하는 것보다 잘 작동하는 몇 가지 새로운 것을 지속적으로 배우는 것을 선호합니다.
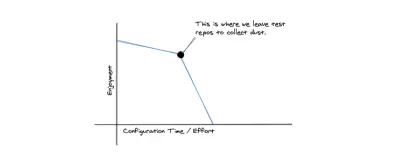
오픈 소스가 아닌 클라우드 플랫폼으로 작업할 때 좋은 점 중 하나는 설정 및 구성을 완전히 소유한다는 것입니다. 이것의 단점은 공급업체 종속이지만, 장점은 이러한 유형의 도구가 종종 제대로 작동하도록 설정된 작업을 수행한다는 것입니다. 환경, 로컬 설정 및 배포 파이프라인을 조작할 필요가 없습니다. 우리는 또한 더 적은 결정을 내려야 합니다.
이것은 본질적 으로 서버리스의 매력입니다 . 일반적으로 서버리스는 독점 서비스와 도구에 더 많이 의존합니다. 우리는 더 큰 안정성을 얻고 해결하려는 비즈니스 도메인의 문제에 집중할 수 있도록 호스팅과 소스 코드의 유연성을 교환합니다. 또한 기술을 평가할 때 플랫폼에서 마이그레이션해야 할 수도 있다는 느낌이 들 때 이는 처음부터 나쁜 신호인 경우가 많습니다.
데이터베이스의 경우 설정한 후 잊어버리는 설정은 데이터베이스 요구 사항이 모호할 수 있는 클라이언트와 작업할 때 이상적입니다. 프로그램이나 애플리케이션이 얼마나 인기가 있을지 확신이 서지 않는 고객이 있었습니다. 기술적으로 이러한 방식으로 지원하도록 계약되지 않은 클라이언트가 있었지만 데이터베이스나 애플리케이션을 확장해야 할 때 패닉에 빠져 우리를 불렀습니다.
과거에는 SOW를 만들 때 확장성을 위해 항상 중복성, 데이터 복제 및 샤딩과 같은 요소를 고려해야 했습니다. 데이터베이스가 확장되지 않는 경우에 대비하여 전체 비즈니스 책을 옮길 준비를 하면서 각 시나리오를 다루려고 하는 것은 준비하기 불가능한 상황입니다. 결국 서버리스 데이터베이스는 이러한 작업을 더 쉽게 만듭니다.
데이터를 잃지 않고 네트워크를 통해 데이터를 복제하거나 데이터를 실행할 더 큰 데이터베이스와 시스템을 프로비저닝하는 것에 대해 걱정할 필요가 없습니다. 이 모든 것이 제대로 작동합니다. 우리는 당면한 비즈니스 문제에만 초점을 맞추고 기술 아키텍처와 규모는 항상 관리됩니다. 우리 개발 팀에게 이것은 큰 승리입니다. 소방 훈련, 모니터링 및 컨텍스트 전환이 적습니다.
학습 가능성
개발자 경험에 적용할 수 있는 고전적인 사용자 경험 측정이 있습니다. 바로 학습 가능성 입니다. 특정 사용자 경험을 위해 디자인할 때 우리는 무언가가 명백하거나 첫 시도에서 쉬운지 확인하지 않습니다. 기술은 대부분의 경우보다 더 복잡합니다. 중요한 것은 새로운 사용자가 시스템을 얼마나 쉽게 배우고 마스터할 수 있는지입니다.
기술 도구, 특히 강력한 도구의 경우 학습 곡선이 0 이 되도록 요구하는 것이 많습니다. 일반적으로 우리가 찾는 것은 가장 일반적인 사용 사례에 대한 훌륭한 문서가 있고 프로젝트에 있을 때 해당 지식을 쉽고 빠르게 구축하는 것입니다. 기술로 첫 번째 프로젝트에서 배우는 데 약간의 시간을 허비하는 것은 괜찮습니다. 그 후, 우리는 각각의 연속적인 프로젝트에서 효율성이 향상되는 것을 볼 수 있을 것입니다.
여기서 내가 구체적으로 찾는 것은 학습 곡선을 단축하기 위해 이미 알고 있는 지식과 패턴을 활용하는 방법입니다. 예를 들어 서버리스 데이터베이스의 경우 클라우드에 설정하고 배포하는 데 필요한 학습 곡선이 거의 없습니다. 데이터베이스를 사용할 때 내가 좋아하는 것 중 하나는 수년간 관계형 데이터베이스 를 마스터하고 이러한 학습을 새로운 설정에 적용할 수 있다는 것입니다. 이 경우 새로운 도구를 사용하는 방법을 배우고 있지만 데이터 모델링을 처음부터 다시 생각해야 하는 것은 아닙니다.

예를 들어 Firebase, MongoDB 및 DynamoDB를 사용할 때 서로 다른 문서를 조인하려고 하기보다 비정규화된 데이터를 권장 한다는 사실을 발견했습니다. 비즈니스 엔터티가 아닌 액세스 패턴 측면에서 생각해야 하므로 데이터를 모델링할 때 인지적 마찰이 많이 발생했습니다. 이 동물군의 다른 면에서 우리는 수년간의 관계 지식과 모델링 데이터와 관련하여 정규화된 데이터에 대한 선호도를 활용할 수 있었습니다.
우리가 익숙해져야 하는 부분은 인덱스와 새로운 쿼리 언어를 사용하여 이러한 조각들을 하나로 모으는 것이었습니다. 일반적으로 더 큰 소프트웨어 설계 패러다임의 일부인 개념을 유지하면 학습 가능성과 채택 측면에서 개발 팀이 더 쉬워진다는 것을 알게 되었습니다.
팀이 새로운 기술을 채택하고 사랑하는지 어떻게 알 수 있습니까? 가장 좋은 신호는 해당 도구가 해당 신기술과 통합되는지 여부를 묻는 것입니다. 새로운 기술이 팀에서 더 많은 프로젝트에 통합할 방법을 찾고 있는 바람직하고 즐거운 수준에 도달하면 승자가 있다는 좋은 신호입니다.
사업
이 섹션에서는 새로운 기술이 비즈니스 요구 사항 을 어떻게 충족하는지 살펴보아야 합니다. 여기에는 다음과 같은 질문이 포함됩니다.
- 얼마나 쉽게 가격을 책정하고 지원 계획에 통합할 수 있습니까?
- 고객에게 쉽게 전환할 수 있습니까?
- 필요한 경우 클라이언트를 이 도구에 온보딩할 수 있습니까?
- 이 도구는 실제로 얼마나 많은 시간을 절약합니까?
서버리스가 패러다임으로 부상하는 것은 에이전시에 잘 맞습니다. 데이터베이스 및 DevOps에 대해 이야기할 때 기관에서 이러한 영역의 전문가에 대한 필요성은 제한적입니다. 종종 우리는 프로젝트를 마치거나 제한된 용량으로 장기적으로 지원할 때 프로젝트를 넘겨줍니다. 이러한 요구 사항이 DevOps 요구 사항보다 훨씬 많기 때문에 우리는 전체 스택 엔지니어 에게 편향되는 경향이 있습니다. DevOps 엔지니어를 고용하면 프로젝트를 배포하는 데 몇 시간을 보내고 화재를 기다리며 더 많은 시간을 보낼 것입니다.
이와 관련하여 우리는 항상 일부 DevOps 계약자 가 준비되어 있지만 이러한 직책에 상근 직원을 고용하지 않습니다. 즉, DevOps 엔지니어가 예상치 못한 문제에 뛰어들 준비가 되어 있다고 믿을 수 없습니다. 우리는 AWS로 직접 이동하여 호스팅 요금을 더 높일 수 있다는 것을 알고 있지만 Heroku를 사용하면 대부분의 문제를 디버그하기 위해 기존 직원에게 의존할 수 있다는 것도 알고 있습니다. 특정 백엔드 요구 사항으로 장기적으로 지원해야 하는 클라이언트가 없는 한 우리는 기본적으로 관리형 플랫폼을 서비스로 사용하는 것을 선호합니다.
데이터베이스도 예외는 아닙니다. 우리는 이 프로세스를 가능한 한 쉽게 만들기 위해 Mongo Atlas 또는 Heroku Postgres와 같은 서비스에 기대는 것을 좋아합니다. Vercel, Netlify 또는 AWS Lambda와 같은 서버리스 도구에 스택 헤드가 점점 더 많이 사용되기 시작하면서 데이터베이스 요구 사항도 그에 따라 진화해야 했습니다. Firebase, DynamoDB, Fauna와 같은 서버리스 데이터베이스 는 서버리스 앱과 잘 통합될 뿐만 아니라 프로비저닝 및 확장에서 비즈니스를 완전히 자유롭게 해주기 때문에 훌륭합니다.
이러한 솔루션은 서버리스 애플리케이션이 없지만 데이터베이스 수준에서 서버리스 효율성을 계속 활용할 수 있는 보다 전통적인 애플리케이션에서도 잘 작동합니다. 비즈니스로서 컨텍스트 전환보다 두 세계에 모두 적용할 수 있는 단일 데이터베이스를 배우는 것이 더 생산적입니다. 이는 Node 및 동형 JavaScript(및 TypeScript)를 채택하기로 한 결정과 유사합니다.
서버리스에서 발견한 단점 중 하나는 이러한 서비스를 관리하는 클라이언트에 대한 가격 책정 이었습니다. 보다 전통적인 아키텍처에서 고정 요금 계층을 사용하면 증가 및 초과 비용이 발생할 수 있는 예측 가능한 상황이 있는 클라이언트의 요금으로 이를 매우 쉽게 변환할 수 있습니다. 서버리스의 경우 이는 모호할 수 있습니다. 재무 담당자는 일반적으로 100만 회를 초과하는 읽을 때마다 1/10 페니를 청구하는 등의 방식으로 듣는 것을 좋아하지 않습니다.
용도가 무엇인지 확실하지 않은 응용 프로그램을 빌드하는 경우가 많기 때문에 엔지니어에게도 고정된 숫자로 변환하기 어렵습니다. 우리는 종종 스스로 계층을 만들어야 하지만 람다의 비용 계산에 들어가는 많은 변수는 머리를 감싸기 어려울 수 있습니다. 궁극적으로 SaaS 제품의 경우 이러한 종량제 가격 책정 모델은 훌륭하지만 더 구체적이고 예측 가능한 수치를 원하는 회계사에게는 적합합니다.
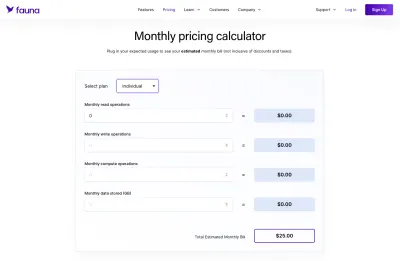
Fauna에 관해서는 정해진 공간에 대해 고정 요금 호스팅이 있는 표준 MySQL 데이터베이스를 말하는 것보다 확실히 이해하기가 더 모호했습니다. 장점은 Fauna가 자체 가격 책정 체계를 구성하는 데 사용할 수 있는 멋진 계산기를 제공한다는 것입니다.
서버리스의 또 다른 어려운 측면은 이러한 공급자 중 다수가 호스팅되는 각 응용 프로그램 을 쉽게 분석할 수 없다는 점입니다. 예를 들어 Heroku 플랫폼은 새로운 파이프라인과 팀을 만들어 이를 매우 쉽게 만듭니다. 고객이 호스팅 계획을 사용하지 않으려는 경우를 대비하여 고객의 신용 카드를 입력할 수도 있습니다. 이 모든 작업은 동일한 대시보드에서도 수행할 수 있으므로 여러 로그인을 만들 필요가 없습니다.
다른 서버리스 도구의 경우 이는 훨씬 더 어렵습니다. 서버리스 데이터베이스를 평가할 때 Firebase는 프로젝트별 분할 지불을 지원합니다. Fauna 또는 DynamoDB의 경우 이것이 불가능하므로 대시보드에서 사용량을 모니터링하기 위해 약간의 작업을 수행해야 하며 고객이 서비스를 떠나고자 하는 경우 데이터베이스를 자신의 계정으로 이전해야 합니다.
궁극적으로 서버리스 도구는 비용 절감, 관리 및 프로세스 효율성 측면에서 훌륭한 비즈니스 기회를 제공합니다. 그러나 가격 책정 및 계정 관리와 관련하여 대행사에 어려운 경우가 많습니다. 이것은 우리가 비용 계산기를 활용하여 예측 가능한 가격 계층을 생성하거나 고객이 직접 결제할 수 있도록 자체 계정을 설정해야 했던 영역 중 하나입니다.
결론
새로운 기술을 에이전시로 채택하는 것은 어려운 작업일 수 있습니다. 우리는 새로운 기술에 대한 기회가 있는 새로운 미개발 프로젝트와 함께 작업할 수 있는 독특한 위치에 있지만 이러한 프로젝트에 대한 장기 투자도 고려해야 합니다. 그들은 어떻게 수행할 것인가? 우리 직원들이 생산적이고 즐겁게 사용할 수 있습니까? Can we incorporate them into our business offering?
You need to have a firm grasp of where you have been before you figure out where you want to go technologically. When evaluating a new tool or platform it's important to think of what you have tried in the past and figure out what is most important to you and your team. We took a look at the concept of a serverless database and passed it through our three lenses – the technology, the experience, and the business. We were left with some pros and cons and had to strike the right balance.
After we evaluated serverless databases, we decided to adopt Fauna over the alternatives. We felt the technology was robust and ticked all of our boxes for our technology filter. When it came to the experience, virtually zero configuration and being able to leverage our existing knowledge of relational data modeling made this a winner with the development team. On the business side serverless provides clear wins to efficiency and productivity , however on the pricing side and account management there are still some difficulties. We decided the benefits in the other areas outweighed the pricing difficulties.
Overall, we highly recommend giving Fauna a shot on one of your next projects. It has become one of our favorite tools and our go-to database of choice for smaller serverless projects and even more traditional large backend applications. The community is very helpful, the learning curve is gentle, and we believe you'll find levels of productivity you hadn't realized before with existing databases.
When we first use a new technology on a project, we start with something either internal or on the smaller side. We try to mitigate the risk by wading into the water rather than leaping into the deep end by trying it on a large and complex project. As the team builds understanding of the technology, we start using it for larger projects but only after we feel comfortable that it has handled similar use cases well for us in the past.
In general, it can take up to a year for a technology to become a ubiquitous part of most projects so it is important to be patient. Agencies have a lot of flexibility but also are required to ensure stability in the products they produce, we don't get a second chance. Always be experimenting and pushing your agency to adopt new technologies, but do so carefully and you will reap the benefits.
추가 읽기
- Serverless Database Wishlist - What's Missing Today
- Relational NoSQL: Yes, that is an option
- Concerning toolkits - A great piece about the merits of zero configuration on developer experience