
Mac OS에서 IoT 장치용 방 감지기 구축
게시 됨: 2022-03-10어떤 방에 있는지 알면 조명 켜기에서 TV 채널 변경에 이르기까지 다양한 IoT 응용 프로그램을 사용할 수 있습니다. 그렇다면 귀하와 귀하의 휴대전화가 부엌, 침실 또는 거실에 있는 순간을 어떻게 감지할 수 있습니까? 오늘날의 상용 하드웨어에는 수많은 가능성이 있습니다.
한 가지 해결책은 각 방에 블루투스 장치를 갖추는 것 입니다. 휴대전화가 블루투스 장치 범위 내에 있으면 휴대전화는 블루투스 장치를 기반으로 자신이 어느 방인지 알 수 있습니다. 그러나 일련의 Bluetooth 장치를 유지 관리하는 것은 배터리 교체부터 고장난 장치 교체에 이르기까지 상당한 오버헤드입니다. 또한 Bluetooth 장치에 근접하는 것이 항상 정답은 아닙니다. 거실에 있는 경우 부엌과 공유하는 벽 옆에 있는 경우 주방 가전제품이 음식을 휘젓기 시작해서는 안 됩니다.
비실용적이지만 또 다른 솔루션은 GPS를 사용하는 것 입니다. 그러나 GPS는 수많은 벽, 기타 신호 및 기타 장애물이 GPS의 정밀도에 큰 피해를 주는 실내에서는 제대로 작동하지 않는다는 점을 명심하십시오.
대신 우리의 접근 방식 은 모든 범위 내 WiFi 네트워크(휴대폰이 연결되지 않은 네트워크 포함)를 활용 하는 것입니다. 방법은 다음과 같습니다. 주방에서 WiFi A의 강점을 고려하십시오. 부엌과 침실 사이에 벽이 있기 때문에 침실의 WiFi A 강도가 다를 것으로 합리적으로 기대할 수 있습니다. 2라고 가정합니다. 이 차이를 이용하여 우리가 있는 방을 예측할 수 있습니다. 게다가 이웃의 WiFi 네트워크 B는 거실에서만 감지할 수 있지만 부엌에서는 효과적으로 보이지 않습니다. 그러면 예측이 훨씬 쉬워집니다. 요컨대 모든 범위 내 WiFi 목록은 풍부한 정보를 제공합니다.
이 방법에는 다음과 같은 뚜렷한 이점이 있습니다.
- 더 많은 하드웨어가 필요하지 않습니다.
- WiFi와 같은 보다 안정적인 신호에 의존
- GPS와 같은 다른 기술이 약한 곳에서 잘 작동합니다.
벽이 많을수록 좋고, WiFi 네트워크의 강도가 다양할수록 방을 더 쉽게 분류할 수 있습니다. 데이터를 수집하고, 데이터에서 학습하고, 주어진 시간에 어떤 방에 있는지 예측하는 간단한 데스크톱 앱을 빌드합니다.
SmashingMag에 대한 추가 정보:
- 지능형 대화형 UI의 부상
- 디자이너를 위한 머신 러닝 적용
- IoT 경험을 프로토타이핑하는 방법: 하드웨어 구축
- 감성적인 사물의 인터넷을 위한 디자인
전제 조건
이 튜토리얼에서는 Mac OSX가 필요합니다. 코드는 모든 플랫폼에 적용할 수 있지만 Mac에 대한 종속성 설치 지침만 제공합니다.
- 맥 OS X
- Mac OSX용 패키지 관리자인 Homebrew. 설치하려면 brew.sh에서 명령을 복사하여 붙여넣습니다.
- NodeJS 10.8.0+ 및 npm 설치
- Python 3.6+ 및 pip 설치. "virtualenv 설치 방법, pip로 설치 및 패키지 관리 방법"의 처음 3개 섹션을 참조하십시오.
0단계: 작업 환경 설정
데스크탑 앱은 NodeJS로 작성됩니다. 그러나 numpy 와 같은 보다 효율적인 계산 라이브러리를 활용하기 위해 학습 및 예측 코드는 Python으로 작성됩니다. 시작하려면 환경을 설정하고 종속성을 설치합니다. 프로젝트를 저장할 새 디렉터리를 만듭니다.
mkdir ~/riot디렉토리로 이동합니다.
cd ~/riotpip를 사용하여 Python의 기본 가상 환경 관리자를 설치합니다.
sudo pip install virtualenv riot 라는 Python3.6 가상 환경을 만듭니다.
virtualenv riot --python=python3.6가상 환경을 활성화합니다.
source riot/bin/activate 이제 프롬프트 앞에 (riot) 가 옵니다. 이것은 가상 환경에 성공적으로 진입했음을 나타냅니다. pip 를 사용하여 다음 패키지를 설치합니다.
-
numpy: 효율적인 선형 대수학 라이브러리 -
scipy: 인기 있는 기계 학습 모델을 구현하는 과학 컴퓨팅 라이브러리
pip install numpy==1.14.3 scipy ==1.1.0작업 디렉터리 설정을 통해 범위 내의 모든 WiFi 네트워크를 기록하는 데스크톱 앱으로 시작합니다. 이러한 기록은 기계 학습 모델에 대한 교육 데이터를 구성합니다. 데이터가 준비되면 이전에 수집한 WiFi 신호에 대해 훈련된 최소 자승 분류기를 작성합니다. 마지막으로 범위 내 WiFi 네트워크를 기반으로 최소 제곱 모델을 사용하여 현재 있는 방을 예측합니다.
1단계: 초기 데스크톱 애플리케이션
이 단계에서는 Electron JS를 사용하여 새로운 데스크톱 애플리케이션을 생성합니다. 시작하려면 대신 노드 패키지 관리자 npm 및 다운로드 유틸리티 wget 을 사용합니다.
brew install npm wget시작하려면 새 Node 프로젝트를 만듭니다.
npm init 그러면 패키지 이름과 버전 번호를 입력하라는 메시지가 표시됩니다. riot 의 기본 이름과 1.0.0 의 기본 버전을 수락하려면 ENTER 키를 누르십시오.
package name: (riot) version: (1.0.0) 그러면 프로젝트 설명을 입력하라는 메시지가 표시됩니다. 비어 있지 않은 설명을 추가하세요. 아래 설명은 room detector 입니다.
description: room detector 그러면 진입점 또는 프로젝트를 실행할 기본 파일을 묻는 메시지가 표시됩니다. app.js 를 입력합니다.
entry point: (index.js) app.js 그러면 test command 과 git repository 를 입력하라는 메시지가 표시됩니다. 지금은 이 필드를 건너뛰려면 ENTER 키를 누르십시오.
test command: git repository: keywords 와 author 를 입력하라는 메시지가 표시됩니다. 원하는 값을 입력합니다. 아래에서는 키워드로 iot , wifi 를 사용하고 작성자로 John Doe Do를 사용합니다.
keywords: iot,wifi author: John Doe 라이선스를 묻는 메시지가 표시됩니다. ENTER 를 눌러 ISC 의 기본값을 승인하십시오.
license: (ISC) 이 시점에서 npm 은 지금까지의 정보 요약을 표시합니다. 출력은 다음과 유사해야 합니다.
{ "name": "riot", "version": "1.0.0", "description": "room detector", "main": "app.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "keywords": [ "iot", "wifi" ], "author": "John Doe", "license": "ISC" } 수락하려면 ENTER 키를 누르십시오. 그런 다음 npm 은 package.json 을 생성합니다. 재확인할 모든 파일을 나열합니다.
ls그러면 가상 환경 폴더와 함께 이 디렉터리의 유일한 파일이 출력됩니다.
package.json riot프로젝트에 대한 NodeJS 종속성을 설치합니다.
npm install electron --global # makes electron binary accessible globally npm install node-wifi --save 아래를 사용하여 파일을 다운로드하여 Electron Quick Start에서 main.js 로 시작합니다. 다음 -O 인수는 main.js 의 이름을 app.js 로 바꿉니다.
wget https://raw.githubusercontent.com/electron/electron-quick-start/master/main.js -O app.js nano 또는 즐겨 사용하는 텍스트 편집기에서 app.js 를 엽니다.
nano app.js 12행에서 index.html 을 static/index.html 로 변경합니다. 모든 HTML 템플릿을 포함하는 static 디렉토리를 생성할 것이기 때문입니다.
function createWindow () { // Create the browser window. win = new BrowserWindow({width: 1200, height: 800}) // and load the index.html of the app. win.loadFile('static/index.html') // Open the DevTools. 변경 사항을 저장하고 편집기를 종료합니다. 파일은 app.js 파일의 소스 코드와 일치해야 합니다. 이제 HTML 템플릿을 저장할 새 디렉토리를 만듭니다.
mkdir static이 프로젝트를 위해 생성된 스타일시트를 다운로드하십시오.
wget https://raw.githubusercontent.com/alvinwan/riot/master/static/style.css?token=AB-ObfDtD46ANlqrObDanckTQJ2Q1Pyuks5bf79PwA%3D%3D -O static/style.css nano 또는 즐겨 사용하는 텍스트 편집기에서 static/index.html 을 엽니다. 표준 HTML 구조로 시작하십시오.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> </head> <body> <main> </main> </body> </html>제목 바로 뒤에 Google Fonts와 스타일시트로 링크된 Montserrat 글꼴을 링크합니다.
<title>Riot | Room Detector</title> <!-- start new code --> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> <!-- end new code --> </head> main 태그 사이에 예상 방 이름에 대한 슬롯을 추가하십시오.
<main> <!-- start new code --> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> <!-- end new code --> </main>이제 스크립트가 다음과 정확히 일치해야 합니다. 편집기를 종료합니다.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Room Detector</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <p class="text">I believe you're in the</p> <h1 class="title">(I dunno)</h1> </main> </body> </html>이제 시작 명령을 포함하도록 패키지 파일을 수정합니다.
nano package.json 7행 바로 뒤에 electron . 으로 별칭이 지정된 start 명령을 추가합니다. . 이전 줄 끝에 쉼표를 추가해야 합니다.
"scripts": { "test": "echo \"Error: no test specified\" && exit 1", "start": "electron ." }, 저장 및 종료. 이제 Electron JS에서 데스크톱 앱을 시작할 준비가 되었습니다. npm 을 사용하여 애플리케이션을 시작합니다.
npm start데스크탑 애플리케이션은 다음과 일치해야 합니다.

이것으로 데스크톱 앱 시작이 완료됩니다. 종료하려면 터미널로 돌아가 CTRL+C를 누릅니다. 다음 단계에서는 Wi-Fi 네트워크를 기록하고 데스크톱 애플리케이션 UI를 통해 기록 유틸리티에 액세스할 수 있도록 합니다.
2단계: WiFi 네트워크 기록
이 단계에서는 모든 범위 내 Wi-Fi 네트워크의 강도와 빈도를 기록하는 NodeJS 스크립트를 작성합니다. 스크립트용 디렉터리를 만듭니다.
mkdir scripts nano 또는 선호하는 텍스트 편집기에서 scripts/observe.js 를 엽니다.
nano scripts/observe.jsNodeJS wifi 유틸리티와 파일 시스템 개체를 가져옵니다.
var wifi = require('node-wifi'); var fs = require('fs'); 완료 핸들러를 허용하는 record 함수를 정의하십시오.
/** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { } 새 기능 내에서 Wi-Fi 유틸리티를 초기화합니다. 이 값은 현재 관련이 없으므로 임의의 Wi-Fi 인터페이스로 초기화하려면 iface 를 null로 설정합니다.
function record(n, completion, hook) { wifi.init({ iface : null }); }샘플을 포함할 배열을 정의하십시오. 샘플 은 모델에 사용할 훈련 데이터입니다. 이 특정 자습서의 샘플은 범위 내 Wi-Fi 네트워크 및 관련 강도, 주파수, 이름 등의 목록입니다.
function record(n, completion, hook) { ... samples = [] } Wi-Fi 스캔을 비동기적으로 시작하는 재귀 함수 startScan 을 정의합니다. 완료되면 비동기식 Wi-Fi 스캔이 재귀적으로 startScan 을 호출합니다.
function record(n, completion, hook) { ... function startScan(i) { wifi.scan(function(err, networks) { }); } startScan(n); } wifi.scan 콜백에서 오류 또는 빈 네트워크 목록을 확인하고 그렇다면 스캔을 다시 시작하십시오.
wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } });완료 핸들러를 호출하는 재귀 함수의 기본 케이스를 추가하십시오.
wifi.scan(function(err, networks) { ... if (i <= 0) { return completion({samples: samples}); } });진행률 업데이트를 출력하고 샘플 목록에 추가하고 재귀 호출을 수행합니다.
wifi.scan(function(err, networks) { ... hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); 파일 끝에서 샘플을 디스크의 파일에 저장하는 콜백으로 record 함수를 호출합니다.
function record(completion) { ... } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + (21-i) + " with " + networks.length + " networks"); }) } cli();파일이 다음과 일치하는지 다시 확인하세요.
var wifi = require('node-wifi'); var fs = require('fs'); /** * Uses a recursive function for repeated scans, since scans are asynchronous. */ function record(n, completion, hook) { wifi.init({ iface : null // network interface, choose a random wifi interface if set to null }); samples = [] function startScan(i) { wifi.scan(function(err, networks) { if (err || networks.length == 0) { startScan(i); return } if (i <= 0) { return completion({samples: samples}); } hook(n-i+1, networks); samples.push(networks); startScan(i-1); }); } startScan(n); } function cli() { record(1, function(data) { fs.writeFile('samples.json', JSON.stringify(data), 'utf8', function() {}); }, function(i, networks) { console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks"); }) } cli();저장 및 종료. 스크립트를 실행합니다.
node scripts/observe.js출력은 다양한 수의 네트워크와 함께 다음과 일치합니다.
* [INFO] Collected sample 1 with 39 networks 방금 수집한 샘플을 검사합니다. 파이프를 json_pp 로 연결하여 JSON을 예쁘게 인쇄하고 파이프로 연결하여 처음 16줄을 봅니다.
cat samples.json | json_pp | head -16아래는 2.4GHz 네트워크의 출력 예입니다.
{ "samples": [ [ { "mac": "64:0f:28:79:9a:29", "bssid": "64:0f:28:79:9a:29", "ssid": "SMASHINGMAGAZINEROCKS", "channel": 4, "frequency": 2427, "signal_level": "-91", "security": "WPA WPA2", "security_flags": [ "(PSK/AES,TKIP/TKIP)", "(PSK/AES,TKIP/TKIP)" ] },이것으로 NodeJS 와이파이 스캐닝 스크립트를 마칩니다. 이를 통해 범위 내 모든 WiFi 네트워크를 볼 수 있습니다. 다음 단계에서는 데스크톱 앱에서 이 스크립트에 액세스할 수 있도록 합니다.
3단계: 스캔 스크립트를 데스크탑 앱에 연결
이 단계에서는 먼저 스크립트를 트리거할 버튼을 데스크탑 앱에 추가합니다. 그런 다음 스크립트의 진행 상황으로 데스크톱 앱 UI를 업데이트합니다.
static/index.html 을 엽니다.
nano static/index.html아래와 같이 "추가" 버튼을 삽입합니다.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <div class="buttons"> <a href="add.html" class="button">Add new room</a> </div> <!-- end new code --> </main> 저장 및 종료. static/add.html 을 엽니다.
nano static/add.html다음 내용을 붙여넣습니다.
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>Riot | Add New Room</title> <link href="https://fonts.googleapis.com/css?family=Montserrat:400,700" rel="stylesheet"> <link href="style.css" rel="stylesheet"> </head> <body> <main> <h1 class="title">0</h1> <p class="subtitle">of <span>20</span> samples needed. Feel free to move around the room.</p> <input type="text" class="text-field" placeholder="(room name)"> <div class="buttons"> <a href="#" class="button">Start recording</a> <a href="index.html" class="button light">Cancel</a> </div> <p class="text"></p> </main> <script> require('../scripts/observe.js') </script> </body> </html> 저장 및 종료. scripts/observe.js 다시 엽니다.
nano scripts/observe.js cli 함수 아래에 새 ui 함수를 정의합니다.
function cli() { ... } // start new code function ui() { } // end new code cli();기능이 실행되기 시작했음을 나타내도록 데스크탑 앱 상태를 업데이트합니다.
function ui() { var room_name = document.querySelector('#add-room-name').value; var status = document.querySelector('#add-status'); var number = document.querySelector('#add-title'); status.style.display = "block" status.innerHTML = "Listening for wifi..." }데이터를 훈련 및 검증 데이터 세트로 분할합니다.
function ui() { ... function completion(data) { train_data = {samples: data['samples'].slice(0, 15)} test_data = {samples: data['samples'].slice(15)} var train_json = JSON.stringify(train_data); var test_json = JSON.stringify(test_data); } } completion 콜백 내에서 두 데이터세트를 모두 디스크에 씁니다.
function ui() { ... function completion(data) { ... fs.writeFile('data/' + room_name + '_train.json', train_json, 'utf8', function() {}); fs.writeFile('data/' + room_name + '_test.json', test_json, 'utf8', function() {}); console.log(" * [INFO] Done") status.innerHTML = "Done." } } 적절한 콜백으로 record 를 호출하여 20개의 샘플을 기록하고 샘플을 디스크에 저장합니다.
function ui() { ... function completion(data) { ... } record(20, completion, function(i, networks) { number.innerHTML = i console.log(" * [INFO] Collected sample " + i + " with " + networks.length + " networks") }) } 마지막으로 적절한 경우 cli 및 ui 함수를 호출합니다. cli(); 파일 맨 아래에서 호출하십시오.
function ui() { ... } cli(); // remove me 문서 개체가 전역적으로 액세스 가능한지 확인합니다. 그렇지 않은 경우 스크립트는 명령줄에서 실행됩니다. 이 경우 cli 함수를 호출합니다. 그렇다면 스크립트는 데스크탑 앱 내에서 로드됩니다. 이 경우 클릭 리스너를 ui 함수에 바인딩합니다.
if (typeof document == 'undefined') { cli(); } else { document.querySelector('#start-recording').addEventListener('click', ui) }저장 및 종료. 데이터를 저장할 디렉토리를 만듭니다.
mkdir data데스크탑 앱을 실행합니다.
npm start아래와 같은 홈페이지가 보입니다. "방 추가"를 클릭합니다.
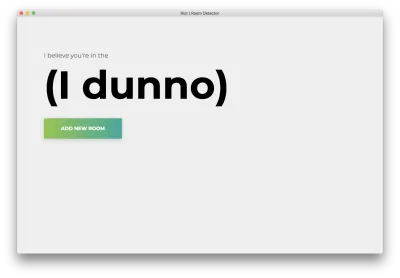
다음과 같은 형식이 표시됩니다. 방 이름을 입력합니다. 이 이름은 나중에 사용하므로 기억해 두십시오. 우리의 예는 bedroom 입니다.
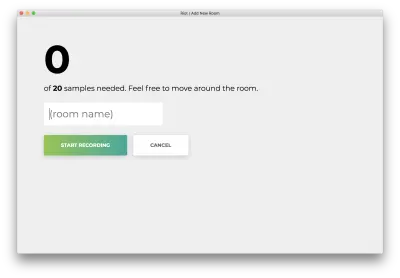
"녹화 시작"을 클릭하면 "Wifi 수신 중..." 상태가 표시됩니다.
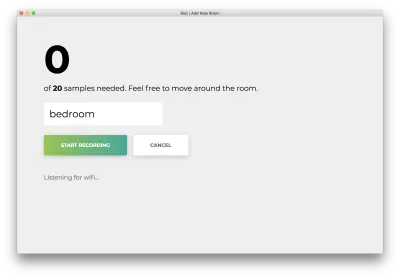
20개의 샘플이 모두 기록되면 앱이 다음과 일치합니다. 상태는 "완료"로 표시됩니다.

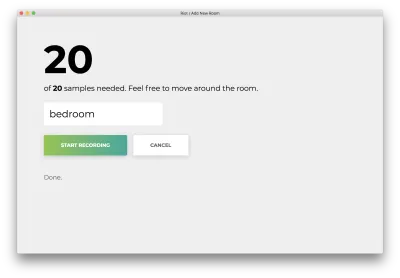
이름이 잘못된 "취소"를 클릭하면 다음과 일치하는 홈페이지로 돌아갑니다.
이제 데스크탑 UI에서 Wi-Fi 네트워크를 스캔할 수 있습니다. 그러면 기록된 모든 샘플이 디스크의 파일에 저장됩니다. 다음으로 수집한 데이터에 대해 즉시 사용 가능한 머신 러닝 알고리즘(최소 제곱)을 훈련할 것입니다.
4단계: Python 교육 스크립트 작성
이 단계에서는 Python으로 학습 스크립트를 작성합니다. 교육 유틸리티에 대한 디렉터리를 만듭니다.
mkdir model model/train.py 열기
nano model/train.py 파일 맨 위에서 numpy 계산 라이브러리를 가져오고 최소 제곱 모델에 대한 scipy 를 가져옵니다.
import numpy as np from scipy.linalg import lstsq import json import sys다음 세 가지 유틸리티는 디스크에 있는 파일의 데이터 로드 및 설정을 처리합니다. 중첩 목록을 평면화하는 유틸리티 함수를 추가하여 시작하십시오. 이것을 사용하여 샘플 목록을 평면화합니다.
import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) 지정된 파일에서 샘플을 로드하는 두 번째 유틸리티를 추가합니다. 이 메서드는 샘플이 여러 파일에 분산되어 있다는 사실을 추상화하여 모든 샘플에 대해 단일 생성기를 반환합니다. 각 샘플에서 레이블은 파일의 인덱스입니다. 예를 들어, get_all_samples('a.json', 'b.json') 을 호출하면 b.json a.json 모든 샘플은 레이블 1이 됩니다.
def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, label다음으로, bag-of-words-esque 모델을 사용하여 샘플을 인코딩하는 유틸리티를 추가하십시오. 다음은 예입니다. 두 개의 샘플을 수집한다고 가정합니다.
- 강도 10의 Wi-Fi 네트워크 A 및 강도 15의 Wi-Fi 네트워크 B
- 강도 20의 Wi-Fi 네트워크 B 및 강도 25의 Wi-Fi 네트워크 C.
이 함수는 각 샘플에 대해 세 개의 숫자 목록을 생성합니다. 첫 번째 값은 Wi-Fi 네트워크 A의 강도, 두 번째 값은 네트워크 B, 세 번째 값은 C입니다. 실제로 형식은 [A, B, C ].
- [10, 15, 0]
- [0, 20, 25]
def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [strengths[networks.index(network)] if network in networks else 0 for network in ordering] 위의 세 가지 유틸리티를 모두 사용하여 샘플 컬렉션과 해당 레이블을 합성합니다. get_all_samples 를 사용하여 모든 샘플과 레이블을 수집합니다. 모든 샘플을 원-핫 인코딩하도록 일관된 형식 ordering 를 정의한 다음 샘플에 one_hot 인코딩을 적용합니다. 마지막으로 데이터 및 레이블 행렬 X 와 Y 를 각각 구성합니다.
def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, ordering이러한 함수는 데이터 파이프라인을 완료합니다. 다음으로 모델 예측 및 평가를 추상화합니다. 예측 방법을 정의하여 시작합니다. 첫 번째 함수는 모델 출력을 정규화하여 모든 값의 합계가 1이 되고 모든 값이 음수가 아니도록 합니다. 이렇게 하면 출력이 유효한 확률 분포가 됩니다. 두 번째는 모델을 평가합니다.
def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1)다음으로 모델의 정확도를 평가합니다. 첫 번째 줄은 모델을 사용하여 예측을 실행합니다. 두 번째는 예측 값과 참 값이 모두 일치하는 횟수를 계산한 다음 총 샘플 수로 정규화합니다.
def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy 이것으로 예측 및 평가 유틸리티를 마칩니다. 이러한 유틸리티 다음에 데이터 세트를 수집하고 훈련하고 평가할 main 기능을 정의하십시오. 명령줄 sys.argv 에서 인수 목록을 읽는 것으로 시작합니다. 교육에 포함할 방입니다. 그런 다음 지정된 모든 방에서 큰 데이터 세트를 만듭니다.
def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering)레이블에 원-핫 인코딩을 적용합니다. one-hot 인코딩 은 위의 bag-of-words 모델과 유사합니다. 이 인코딩을 사용하여 범주형 변수를 처리합니다. 3개의 가능한 레이블이 있다고 가정합니다. 1, 2 또는 3에 레이블을 지정하는 대신 [1, 0, 0], [0, 1, 0] 또는 [0, 0, 1]로 데이터에 레이블을 지정합니다. 이 자습서에서는 원-핫 인코딩이 중요한 이유에 대한 설명을 생략합니다. 모델을 훈련시키고 훈련 세트와 검증 세트 모두에서 평가합니다.
def main(): ... X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) test_accuracy = evaluate(X_test, Y_test, w)두 정확도를 모두 인쇄하고 모델을 디스크에 저장합니다.
def main(): ... print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, test_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() 파일 끝에서 main 함수를 실행합니다.
if __name__ == '__main__': main()저장 및 종료. 파일이 다음과 일치하는지 다시 확인하세요.
import numpy as np from scipy.linalg import lstsq import json import sys def flatten(list_of_lists): """Flatten a list of lists to make a list. >>> flatten([[1], [2], [3, 4]]) [1, 2, 3, 4] """ return sum(list_of_lists, []) def get_all_samples(paths): """Load all samples from JSON files.""" for label, path in enumerate(paths): with open(path) as f: for sample in json.load(f)['samples']: signal_levels = [ network['signal_level'].replace('RSSI', '') or 0 for network in sample] yield [network['mac'] for network in sample], signal_levels, label def bag_of_words(all_networks, all_strengths, ordering): """Apply bag-of-words encoding to categorical variables. >>> samples = bag_of_words( ... [['a', 'b'], ['b', 'c'], ['a', 'c']], ... [[1, 2], [2, 3], [1, 3]], ... ['a', 'b', 'c']) >>> next(samples) [1, 2, 0] >>> next(samples) [0, 2, 3] """ for networks, strengths in zip(all_networks, all_strengths): yield [int(strengths[networks.index(network)]) if network in networks else 0 for network in ordering] def create_dataset(classpaths, ordering=None): """Create dataset from a list of paths to JSON files.""" networks, strengths, labels = zip(*get_all_samples(classpaths)) if ordering is None: ordering = list(sorted(set(flatten(networks)))) X = np.array(list(bag_of_words(networks, strengths, ordering))).astype(np.float64) Y = np.array(list(labels)).astype(np.int) return X, Y, ordering def softmax(x): """Convert one-hotted outputs into probability distribution""" x = np.exp(x) return x / np.sum(x) def predict(X, w): """Predict using model parameters""" return np.argmax(softmax(X.dot(w)), axis=1) def evaluate(X, Y, w): """Evaluate model w on samples X and labels Y.""" Y_pred = predict(X, w) accuracy = (Y == Y_pred).sum() / X.shape[0] return accuracy def main(): classes = sys.argv[1:] train_paths = sorted(['data/{}_train.json'.format(name) for name in classes]) test_paths = sorted(['data/{}_test.json'.format(name) for name in classes]) X_train, Y_train, ordering = create_dataset(train_paths) X_test, Y_test, _ = create_dataset(test_paths, ordering=ordering) Y_train_oh = np.eye(len(classes))[Y_train] w, _, _, _ = lstsq(X_train, Y_train_oh) train_accuracy = evaluate(X_train, Y_train, w) validation_accuracy = evaluate(X_test, Y_test, w) print('Train accuracy ({}%), Validation accuracy ({}%)'.format(train_accuracy*100, validation_accuracy*100)) np.save('w.npy', w) np.save('ordering.npy', np.array(ordering)) sys.stdout.flush() if __name__ == '__main__': main() 저장 및 종료. 20개의 샘플을 녹음할 때 위에서 사용한 방 이름을 기억하십시오. 아래 bedroom 대신 그 이름을 사용하십시오. 우리의 예는 bedroom 입니다. -W ignore 를 사용하여 LAPACK 버그의 경고를 무시합니다.
python -W ignore model/train.py bedroom한 방에 대한 훈련 샘플만 수집했으므로 훈련 및 검증 정확도가 100%여야 합니다.
Train accuracy (100.0%), Validation accuracy (100.0%)다음으로 이 교육 스크립트를 데스크톱 앱에 연결합니다.
5단계: 트레인 스크립트 연결
이 단계에서는 사용자가 새 샘플 배치를 수집할 때마다 모델을 자동으로 재학습합니다. scripts/observe.js 엽니다.
nano scripts/observe.js fs 가져오기 직후에 자식 프로세스 생성기와 유틸리티를 가져옵니다.
var fs = require('fs'); // start new code const spawn = require("child_process").spawn; var utils = require('./utils.js'); ui 함수에서 완료 핸들러 끝에 다음 호출을 추가하여 retrain 합니다.
function ui() { ... function completion() { ... retrain((data) => { var status = document.querySelector('#add-status'); accuracies = data.toString().split('\n')[0]; status.innerHTML = "Retraining succeeded: " + accuracies }); } ... } ui 함수 뒤에 다음 retrain 함수를 추가합니다. 이것은 파이썬 스크립트를 실행할 자식 프로세스를 생성합니다. 완료되면 프로세스는 완료 핸들러를 호출합니다. 실패 시 오류 메시지를 기록합니다.
function ui() { .. } function retrain(completion) { var filenames = utils.get_filenames() const pythonProcess = spawn('python', ["./model/train.py"].concat(filenames)); pythonProcess.stdout.on('data', completion); pythonProcess.stderr.on('data', (data) => { console.log(" * [ERROR] " + data.toString()) }) } 저장 및 종료. scripts/utils.js 엽니다.
nano scripts/utils.js data/ 의 모든 데이터세트를 가져오기 위해 다음 유틸리티를 추가합니다.
var fs = require('fs'); module.exports = { get_filenames: get_filenames } function get_filenames() { filenames = new Set([]); fs.readdirSync("data/").forEach(function(filename) { filenames.add(filename.replace('_train', '').replace('_test', '').replace('.json', '' )) }); filenames = Array.from(filenames.values()) filenames.sort(); filenames.splice(filenames.indexOf('.DS_Store'), 1) return filenames }저장 및 종료. 이 단계의 완료를 위해 물리적으로 새 위치로 이동합니다. 이상적으로는 원래 위치와 새 위치 사이에 벽이 있어야 합니다. 장벽이 많을수록 데스크톱 앱이 더 잘 작동합니다.
다시 한 번 데스크톱 앱을 실행합니다.
npm start이전과 마찬가지로 교육 스크립트를 실행합니다. "방 추가"를 클릭합니다.
첫 번째 방과 다른 방 이름을 입력하십시오. 우리는 living room 을 사용할 것입니다.
"녹화 시작"을 클릭하면 "Wifi 수신 중..." 상태가 표시됩니다.
20개의 샘플이 모두 기록되면 앱이 다음과 일치합니다. 상태는 "완료. 모델 재교육…”
다음 단계에서는 이 재학습된 모델을 사용하여 현재 있는 방을 즉석에서 예측합니다.
6단계: Python 평가 스크립트 작성
이 단계에서는 사전 훈련된 모델 매개변수를 로드하고 Wi-Fi 네트워크를 스캔하고 스캔을 기반으로 방을 예측합니다.
model/eval.py 를 엽니다.
nano model/eval.py마지막 스크립트에서 사용 및 정의된 라이브러리를 가져옵니다.
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate 모든 데이터 세트의 이름을 추출하는 유틸리티를 정의하십시오. 이 함수는 모든 데이터 세트가 data/ 에 <dataset>_train.json 및 <dataset>_test.json _test.json 으로 저장되어 있다고 가정합니다.
from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) main 함수를 정의하고 학습 스크립트에서 저장된 매개변수를 로드하여 시작합니다.
def get_datasets(): ... def main(): w = np.load('w.npy') ordering = np.load('ordering.npy')데이터세트를 만들고 예측합니다.
def main(): ... classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w))상위 두 확률 간의 차이를 기반으로 신뢰 점수를 계산합니다.
def main(): ... sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) 마지막으로 범주를 추출하고 결과를 인쇄합니다. 스크립트를 마치려면 main 함수를 호출하십시오.
def main() ... category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()저장 및 종료. 코드가 다음(소스 코드)과 일치하는지 다시 확인하십시오.
import numpy as np import sys import json import os import json from train import predict from train import softmax from train import create_dataset from train import evaluate def get_datasets(): """Extract dataset names.""" return sorted(list({path.split('_')[0] for path in os.listdir('./data') if '.DS' not in path})) def main(): w = np.load('w.npy') ordering = np.load('ordering.npy') classpaths = [sys.argv[1]] X, _, _ = create_dataset(classpaths, ordering) y = np.asscalar(predict(X, w)) sorted_y = sorted(softmax(X.dot(w)).flatten()) confidence = 1 if len(sorted_y) > 1: confidence = round(sorted_y[-1] - sorted_y[-2], 2) category = get_datasets()[y] print(json.dumps({"category": category, "confidence": confidence})) if __name__ == '__main__': main()다음으로 이 평가 스크립트를 데스크톱 앱에 연결합니다. 데스크톱 앱은 지속적으로 Wi-Fi 스캔을 실행하고 예측된 방으로 UI를 업데이트합니다.
7단계: 평가판을 데스크탑 앱에 연결
이 단계에서는 "자신감" 표시로 UI를 업데이트합니다. 그러면 연결된 NodeJS 스크립트가 계속해서 스캔 및 예측을 실행하여 그에 따라 UI를 업데이트합니다.
static/index.html 을 엽니다.
nano static/index.html제목 바로 뒤와 버튼 앞에 확신을 주기 위해 줄을 추가하십시오.
<h1 class="title">(I dunno)</h1> <!-- start new code --> <p class="subtitle">with <span>0%</span> confidence</p> <!-- end new code --> <div class="buttons"> main 바로 뒤에 있지만 body 이 끝나기 전에 새 스크립트 predict.js 를 추가합니다.
</main> <!-- start new code --> <script> require('../scripts/predict.js') </script> <!-- end new code --> </body> 저장 및 종료. scripts/predict.js 엽니다.
nano scripts/predict.js파일 시스템, 유틸리티 및 자식 프로세스 생성기에 필요한 NodeJS 유틸리티를 가져옵니다.
var fs = require('fs'); var utils = require('./utils'); const spawn = require("child_process").spawn; Wi-Fi 네트워크를 감지하기 위해 별도의 노드 프로세스를 호출하고 방을 예측하기 위해 별도의 Python 프로세스를 호출하는 predict 기능을 정의합니다.
function predict(completion) { const nodeProcess = spawn('node', ["scripts/observe.js"]); const pythonProcess = spawn('python', ["-W", "ignore", "./model/eval.py", "samples.json"]); }두 프로세스가 모두 생성된 후 성공 및 오류 모두에 대해 Python 프로세스에 콜백을 추가합니다. 성공 콜백은 정보를 기록하고 완료 콜백을 호출하며 예측 및 신뢰도로 UI를 업데이트합니다. 오류 콜백은 오류를 기록합니다.
function predict(completion) { ... pythonProcess.stdout.on('data', (data) => { information = JSON.parse(data.toString()); console.log(" * [INFO] Room '" + information.category + "' with confidence '" + information.confidence + "'") completion() if (typeof document != "undefined") { document.querySelector('#predicted-room-name').innerHTML = information.category document.querySelector('#predicted-confidence').innerHTML = information.confidence } }); pythonProcess.stderr.on('data', (data) => { console.log(data.toString()); }) } predict 함수를 재귀적으로 영원히 호출하는 메인 함수를 정의하십시오.
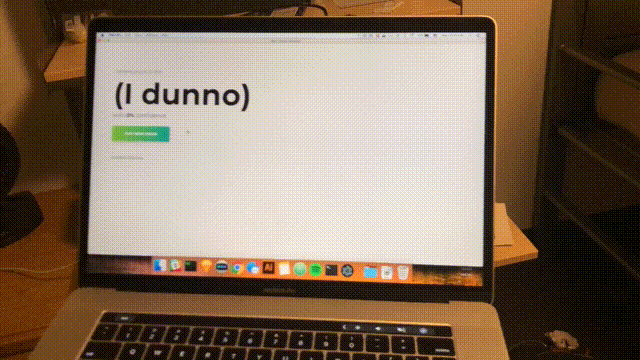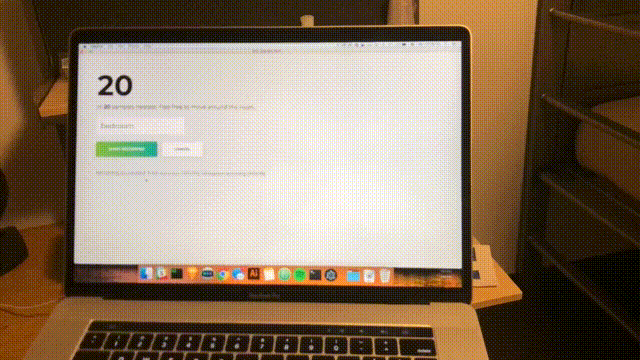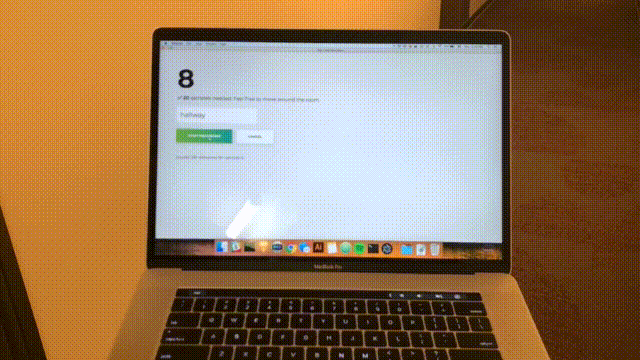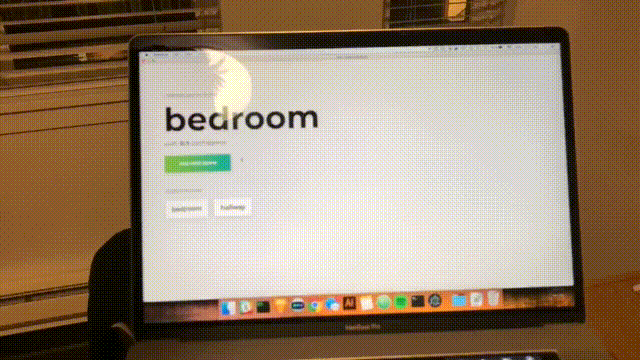
function main() { f = function() { predict(f) } predict(f) } main();마지막으로 데스크톱 앱을 열어 실시간 예측을 확인하세요.
npm start약 1초마다 스캔이 완료되고 인터페이스가 최신 신뢰도 및 예상 공간으로 업데이트됩니다. 축하합니다; 모든 범위 내 WiFi 네트워크를 기반으로 하는 간단한 실내 감지기를 완료했습니다.
결론
이 자습서에서는 데스크톱만 사용하여 건물 내 위치를 감지하는 솔루션을 만들었습니다. Electron JS를 사용하여 간단한 데스크톱 앱을 구축하고 모든 범위 내 WiFi 네트워크에 간단한 기계 학습 방법을 적용했습니다. 이것은 유지 비용이 많이 드는 장치 어레이가 필요 없이 사물 인터넷 응용 프로그램을 위한 길을 열어줍니다(비용이 아니라 시간 및 개발 측면에서 비용).
참고 : Github에서 전체 소스 코드를 볼 수 있습니다.
시간이 지나면 이 최소 자승법이 실제로 훌륭하게 수행되지 않는다는 것을 알게 될 것입니다. 한 방 내에서 두 위치를 찾거나 출입구에 서십시오. 최소 제곱은 큰 경우를 구분할 수 없습니다. 우리가 더 잘할 수 있습니까? 우리는 더 나은 성능을 위해 다른 기술과 기계 학습의 기초를 활용할 수 있으며 향후 수업에서 활용할 것입니다. 이 튜토리얼은 향후 실험을 위한 빠른 테스트 베드 역할을 합니다.