
Node.js로 Amazon 제품 스크레이퍼를 구축하는 방법
게시 됨: 2022-03-10특정 제품의 시장을 자세히 알아야 하는 상황에 처한 적이 있습니까? 일부 소프트웨어를 출시하고 가격을 책정하는 방법을 알아야 할 수도 있습니다. 또는 이미 시장에 자신의 제품이 있고 경쟁 우위를 위해 어떤 기능을 추가해야 하는지 알고 싶을 수도 있습니다. 아니면 그냥 자신을 위해 무언가를 사고 싶고 가장 좋은 결과를 얻기를 원할 수도 있습니다.
이러한 모든 상황에는 한 가지 공통점이 있습니다. 올바른 결정을 내리려면 정확한 데이터가 필요합니다 . 사실, 그들이 공유하는 또 다른 것이 있습니다. 웹 스크레이퍼를 사용하면 모든 시나리오에서 이점을 얻을 수 있습니다.
웹 스크래핑은 소프트웨어를 사용하여 대량의 웹 데이터를 추출하는 관행입니다. 따라서 본질적으로 '복사'하고 '붙여넣기'를 200번 하는 지루한 과정을 자동화하는 방법입니다. 물론 봇은 이 문장을 읽는 데 걸리는 시간에 그렇게 할 수 있으므로 덜 지루할 뿐만 아니라 훨씬 빠릅니다.
그러나 불타는 질문은 왜 누군가가 Amazon 페이지를 스크랩하고 싶어할까요?
이제 곧 알게 될 것입니다! 그러나 무엇보다도 먼저, 저는 지금 당장 분명히 하고 싶은 것이 있습니다. 공개적으로 사용 가능한 데이터를 스크랩하는 행위는 합법이지만 Amazon은 페이지에서 이를 방지하기 위한 몇 가지 조치를 취하고 있습니다. 따라서 긁을 때 항상 웹 사이트를 염두에두고 손상되지 않도록주의하고 윤리적 지침을 따르십시오.
추천 자료 : Andreas Altheimer의 "Node.js와 Puppeteer를 사용한 동적 웹사이트의 윤리적 스크래핑 가이드"
Amazon 제품 데이터를 추출해야 하는 이유
지구상에서 가장 큰 온라인 소매 업체이기 때문에 무언가를 사고 싶다면 아마존에서 구입할 수 있다고 말하는 것이 안전합니다. 따라서 웹 사이트가 얼마나 많은 데이터 보물을 가지고 있는지는 말할 필요도 없습니다.
웹을 스크랩할 때 가장 중요한 질문은 해당 데이터로 무엇을 하느냐 하는 것입니다. 여러 가지 개인적인 이유가 있지만 두 가지 두드러진 사용 사례로 요약됩니다. 제품 최적화와 최상의 거래 찾기입니다.
"
첫 번째 시나리오부터 시작하겠습니다. 진정으로 혁신적인 신제품을 디자인하지 않았다면 아마존에서 이미 비슷한 제품을 찾을 가능성이 있습니다. 해당 제품 페이지를 스크랩하면 다음과 같은 귀중한 데이터를 얻을 수 있습니다.
- 경쟁사의 가격 전략
따라서 경쟁력을 갖도록 가격을 조정하고 다른 사람들이 판촉 거래를 처리하는 방법을 이해할 수 있습니다. - 고객 의견
미래의 고객 기반이 무엇을 가장 중요하게 생각하고 고객 경험을 개선할 수 있는지 확인합니다. - 가장 일반적인 기능
어떤 기능이 중요하고 나중에 남겨둘 수 있는지 알기 위해 경쟁업체가 제공하는 것을 확인합니다.
본질적으로 Amazon에는 심층 시장 및 제품 분석에 필요한 모든 것이 있습니다. 해당 데이터를 사용하여 제품 라인업을 설계, 출시 및 확장할 수 있도록 더 잘 준비할 수 있습니다.
두 번째 시나리오는 기업과 일반인 모두에게 적용될 수 있습니다. 아이디어는 앞서 언급한 것과 매우 유사합니다. 선택할 수 있는 모든 제품의 가격, 기능 및 리뷰를 스크랩할 수 있으므로 가장 저렴한 가격에 가장 많은 혜택을 제공하는 제품을 선택할 수 있습니다. 결국 누가 좋은 거래를 좋아하지 않습니까?
모든 제품이 이러한 수준의 세부 사항에 주의를 기울일 가치가 있는 것은 아니지만 값비싼 구매로 큰 차이를 만들 수 있습니다. 불행히도 이점은 분명하지만 Amazon을 긁는 데 많은 어려움이 따릅니다.
Amazon 제품 데이터 스크랩의 과제
모든 웹사이트가 같은 것은 아닙니다. 일반적으로 웹사이트가 복잡하고 광범위할수록 스크랩하기가 더 어렵습니다. 아마존이 가장 눈에 띄는 전자 상거래 사이트라고 말한 것을 기억하십니까? 글쎄, 그것은 그것을 매우 인기 있고 합리적으로 복잡하게 만듭니다.
먼저 Amazon은 스크래핑 봇이 어떻게 작동하는지 알고 있으므로 웹 사이트에는 대응책이 있습니다. 즉, 스크레이퍼가 예측 가능한 패턴을 따라 사람이 할 수 있는 것보다 빠르게 또는 거의 동일한 매개변수를 사용하여 고정된 간격으로 요청을 보내는 경우 Amazon은 IP를 감지하고 차단합니다. 프록시가 이 문제를 해결할 수 있지만 예제에서 너무 많은 페이지를 긁지 않을 것이기 때문에 프록시가 필요하지 않았습니다.
다음으로 Amazon은 의도적으로 제품에 다양한 페이지 구조를 사용합니다. 즉, 다른 제품의 페이지를 조사하면 구조와 속성에서 상당한 차이를 발견할 가능성이 큽니다. 그 이유는 아주 간단합니다. 특정 시스템에 맞게 스크레이퍼의 코드 를 조정해야 하며, 새로운 종류의 페이지에서 동일한 스크립트를 사용하는 경우 일부를 다시 작성해야 합니다. 따라서 그들은 본질적으로 데이터에 대해 더 많은 작업을 하게 만듭니다.
마지막으로 아마존은 방대한 웹사이트입니다. 많은 양의 데이터를 수집하려는 경우 컴퓨터에서 스크래핑 소프트웨어를 실행하면 필요에 비해 너무 많은 시간이 소요될 수 있습니다. 이 문제는 너무 빨리 가면 스크레이퍼가 차단된다는 사실로 인해 더욱 강화됩니다. 따라서 데이터 로드를 신속하게 수행하려면 진정으로 강력한 스크레이퍼가 필요합니다.
글쎄요, 문제에 대한 이야기로 충분합니다. 해결책에 집중합시다!
Amazon용 웹 스크레이퍼를 구축하는 방법
일을 단순하게 유지하기 위해 코드 작성에 대한 단계별 접근 방식을 취할 것입니다. 가이드와 병행하여 자유롭게 작업하십시오.
우리에게 필요한 데이터를 찾아라
그래서, 여기 시나리오가 있습니다. 저는 몇 달 후에 새로운 장소로 이사할 예정입니다. 그리고 책과 잡지를 보관할 새 선반이 몇 개 필요합니다. 내 모든 옵션을 알고 가능한 한 좋은 거래를 원합니다. 자, 아마존 시장으로 가서 "선반"을 검색하고 우리가 얻는 것을 봅시다.
이 검색 및 스크랩할 페이지의 URL이 여기에 있습니다.
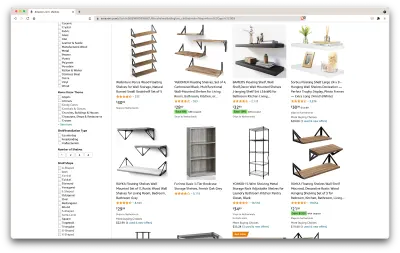
자, 여기 있는 것을 살펴보겠습니다. 페이지를 살펴보기만 해도 다음과 같은 좋은 정보를 얻을 수 있습니다.
- 선반이 어떻게 보이는지;
- 패키지에 포함된 내용
- 고객이 평가하는 방법
- 그들의 가격;
- 제품에 대한 링크;
- 일부 항목에 대한 더 저렴한 대안에 대한 제안.
그것은 우리가 요청할 수 있는 것 이상입니다!
필요한 도구 얻기
다음 단계를 계속하기 전에 다음 도구가 모두 설치 및 구성되었는지 확인하겠습니다.
- 크롬
여기에서 다운로드할 수 있습니다. - VS코드
이 페이지의 지침에 따라 특정 장치에 설치하십시오. - 노드.js
Axios나 Cheerio를 사용하기 전에 Node.js와 Node Package Manager를 설치해야 합니다. Node.js 및 NPM을 설치하는 가장 쉬운 방법은 Node.js 공식 소스에서 설치 프로그램 중 하나를 가져와 실행하는 것입니다.
이제 새 NPM 프로젝트를 생성해 보겠습니다. 프로젝트에 대한 새 폴더를 만들고 다음 명령을 실행합니다.
npm init -y웹 스크레이퍼를 생성하려면 프로젝트에 몇 가지 종속성을 설치해야 합니다.
- 안녕
마크업을 구문 분석하고 결과 데이터를 조작하기 위한 API를 제공하여 유용한 정보를 추출하는 데 도움이 되는 오픈 소스 라이브러리입니다. Cheerio를 사용하면$("div")선택자를 사용하여 HTML 문서의 태그를 선택할 수 있습니다. 이 특정 선택기는 페이지의 모든<div>요소를 선택하는 데 도움이 됩니다. Cheerio를 설치하려면 프로젝트 폴더에서 다음 명령을 실행하세요.
npm install cheerio- 악시오스
Node.js에서 HTTP 요청을 만드는 데 사용되는 JavaScript 라이브러리입니다.
npm install axios페이지 소스 검사
다음 단계에서는 페이지에서 정보가 구성되는 방식에 대해 자세히 알아보겠습니다. 아이디어는 소스에서 긁어모을 수 있는 내용을 더 잘 이해하는 것입니다.
개발자 도구는 웹사이트의 DOM(Document Object Model)을 대화식으로 탐색하는 데 도움이 됩니다. Chrome의 개발자 도구를 사용하지만 사용에 익숙한 모든 웹 브라우저를 사용할 수 있습니다.
페이지의 아무 곳이나 마우스 오른쪽 버튼으로 클릭하고 "검사" 옵션을 선택하여 열어 보겠습니다.
그러면 페이지의 소스 코드가 포함된 새 창이 열립니다. 전에 말했듯이 우리는 모든 선반의 정보를 긁어모으려고 합니다.
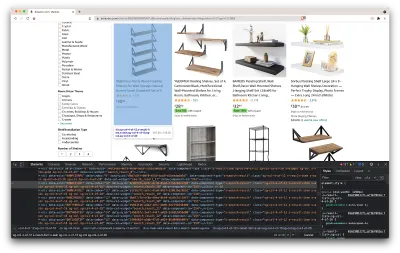
위의 스크린샷에서 볼 수 있듯이 모든 데이터를 포함하는 컨테이너에는 다음 클래스가 있습니다.
sg-col-4-of-12 s-result-item s-asin sg-col-4-of-16 sg-col sg-col-4-of-20다음 단계에서는 Cheerio를 사용하여 필요한 데이터가 포함된 모든 요소를 선택합니다.
데이터 가져오기
위에 제시된 모든 종속성을 설치한 후 새 index.js 파일을 만들고 다음 코드 줄을 입력해 보겠습니다.
const axios = require("axios"); const cheerio = require("cheerio"); const fetchShelves = async () => { try { const response = await axios.get('https://www.amazon.com/s?crid=36QNR0DBY6M7J&k=shelves&ref=glow_cls&refresh=1&sprefix=s%2Caps%2C309'); const html = response.data; const $ = cheerio.load(html); const shelves = []; $('div.sg-col-4-of-12.s-result-item.s-asin.sg-col-4-of-16.sg-col.sg-col-4-of-20').each((_idx, el) => { const shelf = $(el) const title = shelf.find('span.a-size-base-plus.a-color-base.a-text-normal').text() shelves.push(title) }); return shelves; } catch (error) { throw error; } }; fetchShelves().then((shelves) => console.log(shelves)); 보시다시피 처음 두 줄에 필요한 종속성을 가져온 다음 Cheerio를 사용하여 페이지에서 제품 정보가 포함된 모든 요소를 가져오는 fetchShelves() 함수를 만듭니다.

각각에 대해 반복하고 더 나은 형식의 결과를 얻기 위해 빈 배열로 푸시합니다.
fetchShelves() 함수는 현재 제품의 제목만 반환하므로 필요한 나머지 정보를 알아보겠습니다. 변수 title 을 정의한 줄 뒤에 다음 코드 줄을 추가하십시오.
const image = shelf.find('img.s-image').attr('src') const link = shelf.find('aa-link-normal.a-text-normal').attr('href') const reviews = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div.a-row.a-size-small').children('span').last().attr('aria-label') const stars = shelf.find('div.a-section.a-spacing-none.a-spacing-top-micro > div > span').attr('aria-label') const price = shelf.find('span.a-price > span.a-offscreen').text() let element = { title, image, link: `https://amazon.com${link}`, price, } if (reviews) { element.reviews = reviews } if (stars) { element.stars = stars } 그리고 shelves.push(title) 를 shelves.push(element) 로 바꿉니다.
이제 필요한 모든 정보를 선택하고 이를 element 라는 새 객체에 추가합니다. 모든 요소는 우리가 찾고 있는 데이터만 포함하는 객체 목록을 얻기 위해 shelves 배열로 푸시됩니다.
이것은 목록에 추가되기 전의 shelf 개체 모양입니다.
{ title: 'SUPERJARE Wall Mounted Shelves, Set of 2, Display Ledge, Storage Rack for Room/Kitchen/Office - White', image: 'https://m.media-amazon.com/images/I/61fTtaQNPnL._AC_UL320_.jpg', link: 'https://amazon.com/gp/slredirect/picassoRedirect.html/ref=pa_sp_btf_aps_sr_pg1_1?ie=UTF8&adId=A03078372WABZ8V6NFP9L&url=%2FSUPERJARE-Mounted-Floating-Shelves-Display%2Fdp%2FB07H4NRT36%2Fref%3Dsr_1_59_sspa%3Fcrid%3D36QNR0DBY6M7J%26dchild%3D1%26keywords%3Dshelves%26qid%3D1627970918%26refresh%3D1%26sprefix%3Ds%252Caps%252C309%26sr%3D8-59-spons%26psc%3D1&qualifier=1627970918&id=3373422987100422&widgetName=sp_btf', price: '$32.99', reviews: '6,171', stars: '4.7 out of 5 stars' }데이터 포맷
이제 필요한 데이터를 가져왔으므로 가독성을 높이기 위해 .CSV 파일로 저장하는 것이 좋습니다. 모든 데이터를 가져온 후 Node.js에서 제공하는 fs 모듈을 사용하고 saved-shelves.csv 라는 새 파일을 프로젝트 폴더에 저장합니다. 파일 맨 위에 있는 fs 모듈을 가져오고 다음 코드 줄을 따라 복사하거나 작성합니다.
let csvContent = shelves.map(element => { return Object.values(element).map(item => `"${item}"`).join(',') }).join("\n") fs.writeFile('saved-shelves.csv', "Title, Image, Link, Price, Reviews, Stars" + '\n' + csvContent, 'utf8', function (err) { if (err) { console.log('Some error occurred - file either not saved or corrupted.') } else{ console.log('File has been saved!') } }) 보시다시피 처음 세 줄에서 쉼표를 사용하여 선반 개체의 모든 값을 결합하여 이전에 수집한 데이터의 형식을 지정합니다. 그런 다음 fs 모듈을 사용하여 saved-shelves.csv 라는 파일을 만들고 열 헤더가 포함된 새 행을 추가하고 방금 포맷한 데이터를 추가하고 오류를 처리하는 콜백 함수를 만듭니다.
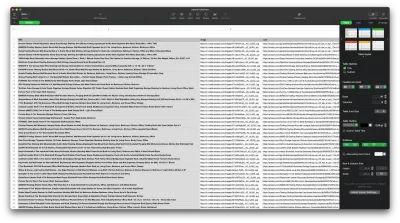
결과는 다음과 같아야 합니다.
보너스 팁!
단일 페이지 애플리케이션 스크래핑
웹 사이트가 그 어느 때보다 복잡해짐에 따라 오늘날 동적 콘텐츠가 표준이 되고 있습니다. 가능한 최고의 사용자 경험을 제공하기 위해 개발자는 동적 콘텐츠에 대해 다른 로드 메커니즘을 채택해야 하므로 작업이 조금 더 복잡해집니다. 이것이 무엇을 의미하는지 모른다면 그래픽 사용자 인터페이스가 없는 브라우저를 상상해 보십시오. 다행히도 Puppeteer가 있습니다. DevTools 프로토콜을 통해 Chrome 인스턴스를 제어하는 고급 API를 제공하는 마법 같은 Node 라이브러리입니다. 여전히 브라우저와 동일한 기능을 제공하지만 몇 줄의 코드를 입력하여 프로그래밍 방식으로 제어해야 합니다. 어떻게 작동하는지 봅시다.
이전에 만든 프로젝트에서 npm install puppeteer 를 실행하여 Puppeteer 라이브러리를 설치하고 새 puppeteer.js 파일을 만들고 다음 코드 줄을 따라 복사하거나 작성합니다.
const puppeteer = require('puppeteer') (async () => { try { const chrome = await puppeteer.launch() const page = await chrome.newPage() await page.goto('https://www.reddit.com/r/Kanye/hot/') await page.waitForSelector('.rpBJOHq2PR60pnwJlUyP0', { timeout: 2000 }) const body = await page.evaluate(() => { return document.querySelector('body').innerHTML }) console.log(body) await chrome.close() } catch (error) { console.log(error) } })() 위의 예에서는 Chrome 인스턴스를 만들고 이 링크로 이동하는 데 필요한 새 브라우저 페이지를 엽니다. 다음 줄에서 헤드리스 브라우저에 rpBJOHq2PR60pnwJlUyP0 클래스가 있는 요소가 페이지에 나타날 때까지 기다리라고 지시합니다. 또한 브라우저가 페이지가 로드될 때까지 기다려야 하는 시간 (2000밀리초)도 지정했습니다.
page 변수의 evaluate 메소드를 사용하여 요소가 최종적으로 로드된 직후 페이지 컨텍스트 내에서 자바스크립트 스니펫을 실행하도록 Puppeteer에 지시했습니다. 이렇게 하면 페이지의 HTML 콘텐츠에 액세스하고 페이지 본문을 출력으로 반환할 수 있습니다. 그런 다음 chrome 변수에서 close 메서드를 호출하여 Chrome 인스턴스를 닫습니다. 결과 작업은 동적으로 생성된 모든 HTML 코드로 구성되어야 합니다. 이것이 Puppeteer가 동적 HTML 콘텐츠를 로드하는 데 도움이 되는 방법입니다.
Puppeteer를 사용하는 것이 불편하다면 NightwatchJS, NightmareJS 또는 CasperJS와 같은 몇 가지 대안이 있습니다. 약간 다르지만 결국 프로세스는 매우 유사합니다.
user-agent 헤더 설정
user-agent 는 방문하는 웹사이트에 자신, 즉 브라우저와 OS에 대해 알려주는 요청 헤더입니다. 이것은 설정을 위해 콘텐츠를 최적화하는 데 사용되지만 웹 사이트는 IPS를 변경하더라도 수많은 요청을 보내는 봇을 식별하는 데도 사용합니다.
user-agent 헤더는 다음과 같습니다.
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36탐지 및 차단되지 않도록 이 헤더를 정기적으로 변경해야 합니다. 평범한 사용자에게는 이런 일이 발생해서는 안 되므로 비어 있거나 오래된 헤더를 보내지 않도록 각별히 주의하십시오. 그러면 눈에 띄게 됩니다.
속도 제한
웹 스크레이퍼는 콘텐츠를 매우 빠르게 수집할 수 있지만 최고 속도로 이동하는 것은 피해야 합니다. 여기에는 두 가지 이유가 있습니다.
- 짧은 순서로 너무 많은 요청 은 웹사이트의 서버 속도를 늦추거나 심지어 다운시켜 소유자와 다른 방문자에게 문제를 일으킬 수 있습니다. 본질적으로 DoS 공격이 될 수 있습니다.
- 회전하는 프록시가 없으면 사람이 초당 수백 또는 수천 개의 요청을 보내지 않기 때문에 봇을 사용하고 있다고 큰 소리로 발표하는 것과 비슷합니다.
해결책은 요청 사이에 지연을 도입하는 것인데, 이를 "속도 제한"이라고 합니다. ( 구현하기도 매우 간단합니다! )
위에 제공된 Puppeteer 예제에서 body 변수를 생성하기 전에 Puppeteer에서 제공하는 waitForTimeout 메서드를 사용하여 다른 요청을 하기 전에 몇 초를 기다릴 수 있습니다.
await page.waitForTimeout(3000); 여기서 ms 는 대기할 시간(초)입니다.
또한 axios 예제에 대해 동일한 작업을 수행하려는 경우 원하는 밀리초 수를 기다리는 데 도움이 되도록 setTimeout() 메서드를 호출하는 약속을 만들 수 있습니다.
fetchShelves.then(result => new Promise(resolve => setTimeout(() => resolve(result), 3000)))이러한 방식으로 대상 서버에 너무 많은 압력을 가하는 것을 피할 수 있고 웹 스크래핑에 대한 보다 인간적인 접근 방식을 가져올 수 있습니다.
마무리 생각
Amazon 제품 데이터용 웹 스크레이퍼를 만드는 방법에 대한 단계별 가이드가 있습니다! 그러나 이것은 하나의 상황에 불과했다는 것을 기억하십시오. 다른 웹사이트를 긁고 싶다면 의미 있는 결과를 얻기 위해 몇 가지 조정을 해야 합니다.
관련 읽을거리
더 많은 웹 스크래핑 작업을 계속 보고 싶다면 다음과 같은 유용한 읽을거리가 있습니다.
- "JavaScript와 Node.J를 사용한 웹 스크래핑에 대한 궁극적인 가이드", Robert Sfichi
- "Puppeteer를 사용한 고급 Node.JS 웹 스크래핑", Gabriel Cioci
- "Python 웹 스크래핑: 스크레이퍼 구축을 위한 궁극적인 가이드", Raluca Penciuc