
FaunaDB, Netlify 및 11ty를 사용하여 책갈피 응용 프로그램 만들기
게시 됨: 2022-03-10JAMstack(JavaScript, API 및 Markup) 혁명이 한창 진행 중입니다. 정적 사이트는 안전하고 빠르고 안정적이며 즐겁게 작업할 수 있습니다. JAMstack의 핵심에는 데이터를 플랫 파일(Markdown, YAML, JSON, HTML 등)로 저장하는 SSG(정적 사이트 생성기)가 있습니다. 때때로 이러한 방식으로 데이터를 관리하는 것은 지나치게 복잡할 수 있습니다. 때때로 우리는 여전히 데이터베이스가 필요합니다.
이를 염두에 두고 정적 사이트 호스트인 Netlify와 서버리스 클라우드 데이터베이스인 FaunaDB가 협력하여 두 시스템을 더 쉽게 결합할 수 있었습니다.
왜 북마크 사이트인가?
JAMstack은 많은 전문적인 용도에 적합하지만 이 기술 세트의 가장 좋아하는 측면 중 하나는 개인 도구 및 프로젝트에 대한 진입 장벽이 낮다는 것입니다.
내가 생각해낼 수 있는 대부분의 응용 프로그램에 대해 시장에 좋은 제품이 많이 있지만, 나를 위해 정확하게 설정되는 제품은 없습니다. 아무도 내 콘텐츠를 완전히 제어할 수 없습니다. 비용(금전적 또는 정보 제공) 없이는 아무 것도 얻을 수 없습니다.
이를 염두에 두고 JAMstack 메서드를 사용하여 자체 미니 서비스를 만들 수 있습니다. 이 경우에 우리는 일상적인 기술 독서에서 접하는 흥미로운 기사를 저장하고 게시할 사이트를 만들 것입니다.
나는 트위터에서 공유된 기사를 읽는 데 많은 시간을 할애합니다. 마음에 들면 "하트" 아이콘을 칩니다. 그런 다음 며칠 안에 새로운 즐겨찾기의 유입으로 인해 찾기가 거의 불가능합니다. 나는 "마음"의 편안함에 가깝지만 내가 소유하고 통제하는 것을 만들고 싶습니다.
어떻게 하면 될까요? 물어봐주셔서 기쁩니다.
코드 받기에 관심이 있으세요? Github에서 가져오거나 해당 저장소에서 Netlify로 바로 배포할 수 있습니다! 여기에서 완성품을 살펴보세요.
우리의 기술
호스팅 및 서버리스 기능: Netlify
호스팅 및 서버리스 기능의 경우 Netlify를 활용합니다. 추가 보너스로 위에서 언급한 새로운 협업을 통해 Netlify의 CLI("Netlify Dev")는 자동으로 FaunaDB에 연결하고 API 키를 환경 변수로 저장합니다.
데이터베이스: FaunaDB
FaunaDB는 "서버리스" NoSQL 데이터베이스입니다. 북마크 데이터를 저장하는 데 사용할 것입니다.
정적 사이트 생성기: 11ty
저는 HTML을 크게 믿습니다. 이 때문에 튜토리얼에서는 프론트엔드 JavaScript를 사용하여 책갈피를 렌더링하지 않습니다. 대신 11ty를 정적 사이트 생성기로 활용합니다. 11ty에는 몇 가지 짧은 JavaScript 함수를 작성하는 것만큼 쉽게 API에서 데이터를 가져올 수 있는 데이터 기능이 내장되어 있습니다.
iOS 단축키
데이터베이스에 데이터를 게시할 수 있는 쉬운 방법이 필요합니다. 이 경우 iOS의 바로 가기 앱을 사용합니다. 이것은 Android 또는 데스크탑 JavaScript 북마크로도 변환될 수 있습니다.
Netlify Dev를 통한 FaunaDB 설정
FaunaDB에 이미 가입했거나 새 계정을 만들어야 하는 경우, FaunaDB와 Netlify 간의 링크를 설정하는 가장 쉬운 방법은 Netlify의 CLI: Netlify Dev를 사용하는 것입니다. 여기에서 FaunaDB의 전체 지침을 찾거나 아래를 따를 수 있습니다.
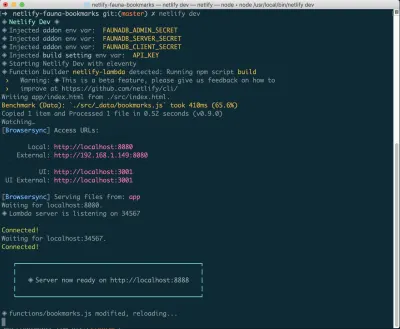
아직 설치하지 않은 경우 터미널에서 다음 명령을 실행할 수 있습니다.
npm install netlify-cli -g프로젝트 디렉터리 내에서 다음 명령을 실행합니다.
netlify init // This will connect your project to a Netlify project netlify addons:create fauna // This will install the FaunaDB "addon" netlify addons:auth fauna // This command will run you through connecting your account or setting up an account 이 모든 것이 연결되면 프로젝트에서 netlify dev 를 실행할 수 있습니다. 이것은 우리가 설정한 모든 빌드 스크립트를 실행하지만 Netlify 및 FaunaDB 서비스에 연결하고 필요한 환경 변수를 가져옵니다. 능숙한!
첫 번째 데이터 생성
여기에서 FaunaDB에 로그인하고 첫 번째 데이터 세트를 생성합니다. "책갈피"라는 새 데이터베이스를 만드는 것으로 시작하겠습니다. 데이터베이스 내부에는 컬렉션, 문서 및 색인이 있습니다.
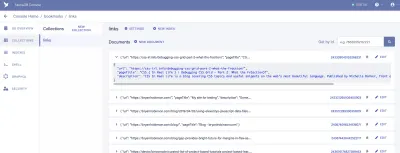
컬렉션은 분류된 데이터 그룹입니다. 각 데이터 조각은 문서 형식을 취합니다. 문서는 Fauna의 문서에 따르면 "FaunaDB 데이터베이스 내의 변경 가능한 단일 레코드"입니다. Collections는 전통적인 데이터베이스 테이블로, Document는 행으로 생각할 수 있습니다.
우리의 응용 프로그램에는 "링크"라고 하는 하나의 컬렉션이 필요합니다. "링크" 컬렉션 내의 각 문서는 세 가지 속성이 있는 간단한 JSON 개체입니다. 시작하려면 첫 번째 데이터 가져오기를 빌드하는 데 사용할 새 문서를 추가합니다.
{ "url": "https://css-irl.info/debugging-css-grid-part-2-what-the-fraction/", "pageTitle": "CSS { In Real Life } | Debugging CSS Grid – Part 2: What the Fr(action)?", "description": "CSS In Real Life is a blog covering CSS topics and useful snippets on the web's most beautiful language. Published by Michelle Barker, front end developer at Ordoo and CSS superfan." }이렇게 하면 책갈피에서 가져와야 하는 정보의 기초가 만들어지고 템플릿으로 가져올 첫 번째 데이터 집합이 제공됩니다.
당신이 나 같으면 당신의 노동의 결과를 즉시보고 싶습니다. 페이지에서 무언가를 얻자!
11ty 설치 및 데이터를 템플릿으로 가져오기
책갈피가 브라우저에서 가져오지 않고 HTML로 렌더링되기를 원하기 때문에 렌더링을 수행할 무언가가 필요합니다. 이를 수행하는 좋은 방법이 많이 있지만 간편함과 강력함을 위해 11ty 정적 사이트 생성기를 사용하는 것을 좋아합니다.
11ty는 JavaScript 정적 사이트 생성기이므로 NPM을 통해 설치할 수 있습니다.
npm install --save @11ty/eleventy 해당 설치에서 프로젝트에서 eleventy 또는 eleventy --serve 를 실행하여 시작하고 실행할 수 있습니다.
Netlify Dev는 종종 11ty를 요구 사항으로 감지하고 명령을 실행합니다. 이 작업을 수행하고 배포할 준비가 되었는지 확인하려면 package.json 에서 "serve" 및 "build" 명령을 생성할 수도 있습니다.
"scripts": { "build": "npx eleventy", "serve": "npx eleventy --serve" }11ty의 데이터 파일
대부분의 정적 사이트 생성기에는 "데이터 파일"이 내장되어 있습니다. 일반적으로 이러한 파일은 사이트에 추가 정보를 추가할 수 있는 JSON 또는 YAML 파일입니다.
11ty에서는 JSON 데이터 파일 또는 JavaScript 데이터 파일을 사용할 수 있습니다. JavaScript 파일을 활용하여 실제로 API를 호출하고 데이터를 템플릿으로 직접 반환할 수 있습니다.
기본적으로 11ty는 _data 디렉토리에 저장된 데이터 파일을 원합니다. 그런 다음 템플릿에서 파일 이름을 변수로 사용하여 데이터에 액세스할 수 있습니다. 우리의 경우 _data/bookmarks.js 에 파일을 만들고 {{ bookmarks }} 변수 이름을 통해 파일에 액세스합니다.
데이터 파일 구성에 대해 더 자세히 알아보려면 11ty 문서의 예제를 읽거나 Meetup API와 함께 11ty 데이터 파일 사용에 대한 이 자습서를 확인하세요.
파일은 JavaScript 모듈입니다. 따라서 작업을 수행하려면 데이터나 함수를 내보내야 합니다. 우리의 경우 함수를 내보냅니다.
module.exports = async function() { const data = mapBookmarks(await getBookmarks()); return data.reverse() } 분해해 보겠습니다. 여기에서 주요 작업을 수행하는 두 가지 함수가 있습니다: mapBookmarks() 및 getBookmarks( getBookmarks() .
getBookmarks() 함수는 FaunaDB 데이터베이스에서 데이터를 가져오고 mapBookmarks() 는 책갈피 배열을 가져와 템플릿에서 더 잘 작동하도록 재구성합니다.
getBookmarks() 에 대해 더 자세히 알아보겠습니다.
getBookmarks()
먼저 FaunaDB JavaScript 드라이버 인스턴스를 설치하고 초기화해야 합니다.
npm install --save faunadb이제 설치했으므로 데이터 파일의 맨 위에 추가해 보겠습니다. 이 코드는 Fauna의 문서에서 가져온 것입니다.
// Requires the Fauna module and sets up the query module, which we can use to create custom queries. const faunadb = require('faunadb'), q = faunadb.query; // Once required, we need a new instance with our secret var adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET }); 그 후에 함수를 생성할 수 있습니다. 드라이버에 내장된 메서드를 사용하여 첫 번째 쿼리를 작성하는 것으로 시작하겠습니다. 이 코드의 첫 번째 비트는 북마크된 모든 링크에 대한 전체 데이터를 가져오는 데 사용할 수 있는 데이터베이스 참조를 반환합니다. 데이터를 11ty에 넘기기 전에 페이지를 매기기로 결정한 경우 커서 상태를 관리하는 도우미로 Paginate 메서드를 사용합니다. 우리의 경우 모든 참조를 반환합니다.
이 예에서는 Netlify Dev CLI를 통해 FaunaDB를 설치하고 연결했다고 가정합니다. 이 프로세스를 사용하여 FaunaDB 비밀의 로컬 환경 변수를 얻습니다. 이 방법으로 설치하지 않았거나 프로젝트에서 netlify dev 를 실행하지 않는 경우 환경 변수를 생성하기 위해 dotenv 와 같은 패키지가 필요합니다. 또한 나중에 배포가 작동하도록 하려면 Netlify 사이트 구성에 환경 변수를 추가해야 합니다.
adminClient.query(q.Paginate( q.Match( // Match the reference below q.Ref("indexes/all_links") // Reference to match, in this case, our all_links index ) )) .then( response => { ... })이 코드는 모든 링크의 배열을 참조 형식으로 반환합니다. 이제 데이터베이스에 보낼 쿼리 목록을 작성할 수 있습니다.
adminClient.query(...) .then((response) => { const linkRefs = response.data; // Get just the references for the links from the response const getAllLinksDataQuery = linkRefs.map((ref) => { return q.Get(ref) // Return a Get query based on the reference passed in }) return adminClient.query(getAllLinksDataQuery).then(ret => { return ret // Return an array of all the links with full data }) }).catch(...) 여기에서 반환된 데이터를 정리하기만 하면 됩니다. 그것이 mapBookmarks() 가 들어오는 곳입니다!
mapBookmarks()
이 함수에서는 데이터의 두 가지 측면을 다룹니다.
먼저 FaunaDB에서 무료 dateTime을 얻습니다. 생성된 모든 데이터에는 타임스탬프( ts ) 속성이 있습니다. Liquid의 기본 날짜 필터를 만족시키는 방식으로 형식이 지정되지 않았으므로 수정하겠습니다.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); ... }) } 이를 제거하면 데이터에 대한 새 개체를 만들 수 있습니다. 이 경우에는 time 속성이 있고 Spread 연산자를 사용하여 data 개체를 구조화하여 한 수준에서 모두 활성화되도록 할 것입니다.
function mapBookmarks(data) { return data.map(bookmark => { const dateTime = new Date(bookmark.ts / 1000); return { time: dateTime, ...bookmark.data } }) }다음은 함수 이전의 데이터입니다.
{ ref: Ref(Collection("links"), "244778237839802888"), ts: 1569697568650000, data: { url: 'https://sample.com', pageTitle: 'Sample title', description: 'An escaped description goes here' } }다음은 함수 이후의 데이터입니다.
{ time: 1569697568650, url: 'https://sample.com', pageTitle: 'Sample title' description: 'An escaped description goes here' }이제 템플릿에 사용할 수 있는 형식이 잘 지정된 데이터가 있습니다!

간단한 템플릿을 작성해 보겠습니다. 책갈피를 반복해서 살펴보고 각 책갈피에 pageTitle 과 url 이 있는지 확인하여 어리석게 보이지 않도록 합니다.
<div class="bookmarks"> {% for link in bookmarks %} {% if link.url and link.pageTitle %} // confirms there's both title AND url for safety <div class="bookmark"> <h2><a href="{{ link.url }}">{{ link.pageTitle }}</a></h2> <p>Saved on {{ link.time | date: "%b %d, %Y" }}</p> {% if link.description != "" %} <p>{{ link.description }}</p> {% endif %} </div> {% endif %} {% endfor %} </div>이제 FaunaDB에서 데이터를 수집하고 표시하고 있습니다. 잠시 시간을 내어 이것이 순수한 HTML을 렌더링하고 클라이언트 측에서 데이터를 가져올 필요가 없다는 것이 얼마나 좋은지 생각해봅시다!
하지만 이것만으로는 우리에게 유용한 앱이 되기에 충분하지 않습니다. FaunaDB 콘솔에서 책갈피를 추가하는 것보다 더 나은 방법을 알아 봅시다.
Netlify 기능 입력
Netlify의 Functions 추가 기능은 AWS 람다 함수를 배포하는 더 쉬운 방법 중 하나입니다. 구성 단계가 없으므로 코드를 작성하려는 DIY 프로젝트에 적합합니다.
이 https://myproject.com/.netlify/functions/bookmarks 는 다음과 같은 프로젝트의 bookmarks.js 에 위치합니다.
기본 흐름
- URL을 함수 URL에 쿼리 매개변수로 전달합니다.
- 이 기능을 사용하여 URL을 로드하고 가능한 경우 페이지의 제목과 설명을 스크랩합니다.
- FaunaDB에 대한 세부 정보를 포맷합니다.
- 세부 정보를 FaunaDB 컬렉션에 푸시하세요.
- 사이트를 재구축합니다.
요구 사항
이것을 구축할 때 필요한 몇 가지 패키지가 있습니다. netlify-lambda CLI를 사용하여 로컬에서 기능을 빌드합니다. request-promise 는 요청에 사용할 패키지입니다. Cheerio.js는 요청된 페이지에서 특정 항목을 긁는 데 사용할 패키지입니다(Node용 jQuery를 생각해 보세요). 마지막으로 FaunaDb(이미 설치되어 있어야 합니다.
npm install --save netlify-lambda request-promise cheerio설치가 완료되면 로컬에서 기능을 빌드하고 제공하도록 프로젝트를 구성해 보겠습니다.
package.json 의 "build" 및 "serve" 스크립트를 다음과 같이 수정합니다.
"scripts": { "build": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy", "serve": "npx netlify-lambda build lambda --config ./webpack.functions.js && npx eleventy --serve" } 경고: Netlify의 함수가 빌드하는 데 사용하는 Webpack으로 컴파일할 때 Fauna의 NodeJS 드라이버에 오류가 있습니다. 이 문제를 해결하려면 Webpack에 대한 구성 파일을 정의해야 합니다. 다음 코드를 새 또는 기존 webpack.config.js 에 저장할 수 있습니다.
const webpack = require('webpack'); module.exports = { plugins: [ new webpack.DefinePlugin({ "global.GENTLY": false }) ] }; 이 파일이 존재하면 netlify-lambda 명령을 사용할 때 이 구성에서 실행하도록 지시해야 합니다. 이것이 우리의 "serve" 및 "build 스크립트가 해당 명령에 --config 값을 사용하는 이유입니다.
기능 하우스키핑
기본 함수 파일을 가능한 한 깨끗하게 유지하기 위해 별도의 bookmarks 디렉토리에 함수를 만들고 기본 함수 파일로 가져옵니다.
import { getDetails, saveBookmark } from "./bookmarks/create"; getDetails(url)
getDetails() 함수는 내보낸 핸들러에서 전달된 URL을 사용합니다. 거기에서 해당 URL의 사이트에 접근하고 페이지의 관련 부분을 가져와 책갈피에 대한 데이터로 저장할 것입니다.
필요한 NPM 패키지를 요구하는 것으로 시작합니다.
const rp = require('request-promise'); const cheerio = require('cheerio'); 그런 다음 request-promise 모듈을 사용하여 요청된 페이지에 대한 HTML 문자열을 반환하고 이를 cheerio 에 전달하여 jQuery와 유사한 인터페이스를 제공합니다.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); ... }여기에서 페이지 제목과 메타 설명을 가져와야 합니다. 그렇게 하기 위해 jQuery에서와 같이 선택기를 사용합니다.
참고: 이 코드에서는 'head > title' 을 선택기로 사용하여 페이지 제목을 가져옵니다. 이것을 지정하지 않으면 페이지의 모든 SVG 내부에 <title> 태그가 표시될 수 있으며 이는 이상적이지 않습니다.
const getDetails = async function(url) { const data = rp(url).then(function(htmlString) { const $ = cheerio.load(htmlString); const title = $('head > title').text(); // Get the text inside the tag const description = $('meta[name="description"]').attr('content'); // Get the text of the content attribute // Return out the data in the structure we expect return { pageTitle: title, description: description }; }); return data //return to our main function }데이터가 있으면 북마크를 FaunaDB의 컬렉션으로 보낼 시간입니다!
saveBookmark(details)
저장 기능의 경우 getDetails 에서 얻은 세부 정보와 URL을 단일 객체로 전달하려고 합니다. Spread 연산자가 다시 공격합니다!
const savedResponse = await saveBookmark({url, ...details}); create.js 파일에서 FaunaDB 드라이버도 요구하고 설정해야 합니다. 이것은 11ty 데이터 파일에서 매우 친숙해 보일 것입니다.
const faunadb = require('faunadb'), q = faunadb.query; const adminClient = new faunadb.Client({ secret: process.env.FAUNADB_SERVER_SECRET });일단 제거하면 코딩할 수 있습니다.
먼저 세부 정보를 Fauna가 쿼리에 대해 기대하는 데이터 구조로 형식화해야 합니다. 동물군은 우리가 저장하려는 데이터를 포함하는 데이터 속성을 가진 개체를 기대합니다.
const saveBookmark = async function(details) { const data = { data: details }; ... }그런 다음 컬렉션에 추가할 새 쿼리를 엽니다. 이 경우 쿼리 도우미를 사용하고 Create 메서드를 사용합니다. Create()는 두 개의 인수를 사용합니다. 첫 번째는 데이터를 저장하려는 컬렉션이고 두 번째는 데이터 자체입니다.
저장한 후에는 성공 또는 실패를 핸들러에 반환합니다.
const saveBookmark = async function(details) { const data = { data: details }; return adminClient.query(q.Create(q.Collection("links"), data)) .then((response) => { /* Success! return the response with statusCode 200 */ return { statusCode: 200, body: JSON.stringify(response) } }).catch((error) => { /* Error! return the error with statusCode 400 */ return { statusCode: 400, body: JSON.stringify(error) } }) }전체 Function 파일을 살펴보겠습니다.
import { getDetails, saveBookmark } from "./bookmarks/create"; import { rebuildSite } from "./utilities/rebuild"; // For rebuilding the site (more on that in a minute) exports.handler = async function(event, context) { try { const url = event.queryStringParameters.url; // Grab the URL const details = await getDetails(url); // Get the details of the page const savedResponse = await saveBookmark({url, ...details}); //Save the URL and the details to Fauna if (savedResponse.statusCode === 200) { // If successful, return success and trigger a Netlify build await rebuildSite(); return { statusCode: 200, body: savedResponse.body } } else { return savedResponse //or else return the error } } catch (err) { return { statusCode: 500, body: `Error: ${err}` }; } }; rebuildSite()
안목 있는 눈은 핸들러로 가져온 함수가 하나 더 있음을 알 수 rebuildSite() . 이 기능은 Netlify의 Deploy Hook 기능을 사용하여 성공적으로 새 책갈피 저장을 제출할 때마다 새 데이터에서 사이트를 재구축합니다.
Netlify의 사이트 설정에서 Build & Deploy 설정에 액세스하고 새로운 "Build Hook"을 만들 수 있습니다. 후크에는 배포 섹션에 표시되는 이름과 원할 경우 비마스터 브랜치를 배포할 수 있는 옵션이 있습니다. 이 경우 이름을 "new_link"로 지정하고 마스터 분기를 배포합니다.
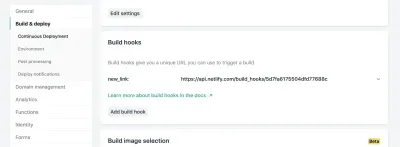
거기에서 제공된 URL로 POST 요청을 보내면 됩니다.
우리는 요청을 할 방법이 필요하고 이미 request-promise 를 설치했기 때문에 우리는 파일의 맨 위에 그것을 요구함으로써 그 패키지를 계속 사용할 것입니다.
const rp = require('request-promise'); const rebuildSite = async function() { var options = { method: 'POST', uri: 'https://api.netlify.com/build_hooks/5d7fa6175504dfd43377688c', body: {}, json: true }; const returned = await rp(options).then(function(res) { console.log('Successfully hit webhook', res); }).catch(function(err) { console.log('Error:', err); }); return returned } iOS 바로 가기 설정
그래서 우리는 데이터베이스, 데이터를 표시하는 방법 및 데이터를 추가하는 기능을 가지고 있지만 여전히 사용자 친화적이지 않습니다.
Netlify는 Lambda 함수에 대한 URL을 제공하지만 모바일 장치에 입력하는 것이 즐겁지 않습니다. 또한 URL을 쿼리 매개변수로 전달해야 합니다. 그것은 많은 노력입니다. 우리는 어떻게 이것을 가능한 한 적은 노력으로 만들 수 있습니까?
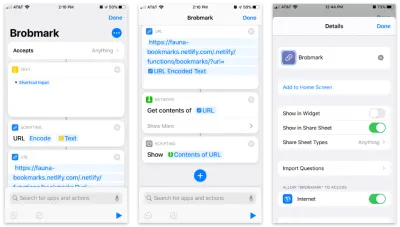
Apple의 Shortcuts 앱을 사용하면 사용자 정의 항목을 빌드하여 공유 시트로 이동할 수 있습니다. 이러한 바로 가기 내에서 공유 프로세스에서 수집된 다양한 유형의 데이터 요청을 보낼 수 있습니다.
단계별 단축키는 다음과 같습니다.
- 모든 항목을 수락하고 해당 항목을 "텍스트" 블록에 저장합니다.
- URL 인코딩을 위해 해당 텍스트를 "스크립팅" 블록에 전달합니다(경우에 따라).
- Netlify 함수의 URL과
url쿼리 매개변수를 사용하여 해당 문자열을 URL 블록에 전달합니다. - "네트워크"에서 "콘텐츠 가져오기" 블록을 사용하여 POST에서 JSON으로 우리 URL로 이동합니다.
- 선택 사항: "Scripting"에서 "Show" 마지막 단계의 내용(보내는 데이터를 확인하기 위해).
공유 메뉴에서 액세스하려면 이 바로 가기에 대한 설정을 열고 "공유 시트에 표시" 옵션을 토글합니다.
iOS13부터 이러한 공유 "작업"을 즐겨찾기에 추가하고 대화 상자에서 높은 위치로 이동할 수 있습니다.
이제 여러 플랫폼에서 책갈피를 공유하기 위한 "앱"이 작동합니다!
엑스트라 마일로 이동하십시오!
직접 시도해 보고 싶은 생각이 든다면 기능을 추가할 수 있는 다른 가능성이 많이 있습니다. DIY 웹의 즐거움은 이러한 종류의 응용 프로그램을 사용할 수 있다는 것입니다. 다음은 몇 가지 아이디어입니다.
- 빠른 인증을 위해 가짜 "API 키"를 사용하여 다른 사용자가 귀하의 사이트에 게시하지 않도록 합니다(내 사이트는 API 키를 사용하므로 게시하지 마십시오!).
- 책갈피를 구성하는 태그 기능을 추가합니다.
- 다른 사람들이 구독할 수 있도록 사이트에 RSS 피드를 추가합니다.
- 추가한 링크에 대해 프로그래밍 방식으로 주간 요약 이메일을 보냅니다.
정말 하늘이 한계니까 실험을 시작하세요!