
실제 예제를 사용한 Python의 이항 분포 [2022]
게시 됨: 2021-01-09데이터 과학 분야에서 확률과 통계의 가치는 엄청났습니다. 인공 지능과 머신 러닝은 이에 크게 의존하고 있습니다. A/B 테스트 및 투자 모델링을 수행할 때마다 정규 분포의 프로세스 모델을 사용하고 있습니다.
그러나 Python의 이항 분포는 여러 프로세스를 수행하기 위해 여러 방식으로 적용됩니다. 그러나 Python에서 이항 분포를 시작하기 전에 일반적인 이항 분포와 일상 생활에서의 사용에 대해 알아야 합니다. 초보자이고 데이터 과학에 대해 더 자세히 알고 싶다면 최고의 대학에서 제공하는 데이터 과학 교육을 확인하십시오.
목차
이항 분포 란 무엇입니까 ?
동전을 던진 적이 있습니까? 그렇다면 앞면이나 뒷면이 나올 확률이 같다는 것을 알아야 합니다. 그러나 총 10번의 동전 던지기에서 7번의 뒷면이 나올 확률은 어떻습니까? 여기에서 이항 분포 가 각 던지기의 결과를 계산하는 데 도움이 될 수 있으므로 동전 10개를 던졌을 때 7개의 꼬리가 나올 확률을 알아낼 수 있습니다.
확률 분포의 핵심은 모든 이벤트의 분산에서 비롯됩니다. 각 10개의 동전 던지기 세트에 대해 앞면과 뒷면이 나올 확률은 1번에서 10번 사이일 수 있습니다. 결과의 불확실성(분산이라고도 함)은 생성된 결과의 분포를 생성하는 데 도움이 됩니다.
즉, 이항 분포 는 참 또는 거짓의 두 가지 가능한 결과만 있는 프로세스입니다. 따라서 매번 동일한 작업이 수행되므로 모든 이벤트에서 두 결과의 확률이 동일합니다. 단 하나의 조건이 있습니다... 단계는 서로 완전히 영향을 받지 않아야 하며 결과는 동일할 수도 있고 아닐 수도 있습니다.
따라서 이항 분포의 확률 함수는 다음과 같습니다.
f f( k k , n n, p p) = P r Pr( k k; n n, p p) = P r Pr ( X X= k k) =
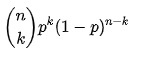
원천
어디에,
![]() = 엔 엔 ! k k !( n n!- k k!)
= 엔 엔 ! k k !( n n!- k k!)
여기서 n = 총 시행 횟수
p = 성공 확률
k = 목표 성공 횟수
Python의 이항 분포
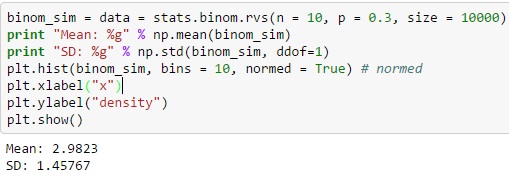
Python을 통한 이항 분포의 경우 binom.rvs() 함수에서 고유한 확률 변수를 생성할 수 있습니다. 여기서 'n'은 총 시행 빈도로 정의되고 'p'는 성공 확률과 같습니다.
loc 함수를 사용하여 분포를 이동할 수도 있으며 크기는 시리즈에서 반복되는 동작의 빈도를 정의합니다. random_state를 추가하면 재현성을 유지하는 데 도움이 될 수 있습니다.

원천
Python의 이항 분포의 실제 예
파이썬에서 이항 분포로 해결할 수 있는 더 많은 이벤트(동전 던지기보다 더 큰)가 있습니다. 일부 사용 사례는 대기업과 중소기업의 ROI(투자 수익률)를 추적하고 개선하는 데 도움이 될 수 있습니다. 방법은 다음과 같습니다.
- 각 직원에게 매일 평균 50개의 전화가 할당되는 콜센터를 생각해 보십시오.
- 각 호출에 대한 전환 확률은 4%입니다.
- 이러한 각 전환을 기반으로 한 회사의 평균 수익 창출은 USD 20입니다.
- 매일 200달러를 받는 직원 100명을 분석하면,
n = 50
p = 4%
코드는 다음과 같이 출력을 생성할 수 있습니다.
- 각 직원의 평균 전환율 = 2.13
- 각 콜센터 직원의 전환 표준 편차 = 1.48
- 총 전환 = 213
- 총 수익 창출 = USD 21,300
- 총 비용 = USD 20,000
- 총 이익 = USD 1,300
이항 분포 모델 및 기타 확률 분포는 동작 매개변수 'n' 및 'p' 측면에서 실제에 가까워질 수 있는 근사값만 예측할 수 있습니다. 그것은 우리가 우리의 초점 영역을 이해하고 식별하고 더 나은 성과와 효율성의 전반적인 기회를 개선하는 데 도움이 됩니다.
더 읽어보기: 초보자를 위한 13가지 흥미로운 데이터 구조 프로젝트 아이디어 및 주제
다음은?
데이터 과학에 대해 자세히 알아보려면 작업 전문가를 위해 만들어졌으며 10개 이상의 사례 연구 및 프로젝트, 실용적인 실습 워크숍 , 업계 전문가와의 멘토링, 1 - 업계 멘토와 일대일, 400시간 이상의 학습 및 최고의 기업과의 취업 지원.
이산 확률 분포와 연속 확률 분포의 차이점은 무엇입니까?
이산 확률 분포 또는 단순히 이산 분포는 이산될 수 있는 확률 변수의 확률을 계산합니다. 예를 들어, 동전을 두 번 던지면 총 앞면 수를 나타내는 확률 변수 X의 가능한 값은 임의의 값이 아닌 {0, 1, 2}가 됩니다. Bernoulli, Binomial, Hypergeometric은 이산 확률 분포의 몇 가지 예입니다. 반면에 연속 확률 분포는 임의의 숫자가 될 수 있는 임의 값의 확률을 제공합니다. 예를 들어, 도시의 시민 키를 나타내는 확률 변수 X의 값은 161.2, 150.9 등과 같은 숫자일 수 있습니다. Normal, Student's T, Chi-square는 연속 분포의 일부 예입니다.
데이터 과학에서 확률의 중요성은 무엇입니까?
데이터 과학은 데이터 연구에 관한 것이기 때문에 여기서 확률이 핵심적인 역할을 합니다. 다음 이유는 확률이 데이터 과학의 필수 불가결한 부분임을 설명합니다. 분석가와 연구자가 데이터 세트에서 예측을 수행하는 데 도움이 됩니다. 이러한 종류의 추정 결과는 데이터의 추가 분석을 위한 기초입니다. 확률은 기계 학습 모델에 사용되는 알고리즘을 개발하는 동안에도 사용됩니다. 모델 훈련에 사용되는 데이터 세트를 분석하는 데 도움이 됩니다. 데이터를 정량화하고 도함수, 평균 및 분포와 같은 결과를 도출할 수 있습니다. 확률을 사용하여 얻은 모든 결과는 결국 데이터를 요약합니다. 이 요약은 데이터 세트의 기존 이상값을 식별하는 데도 도움이 됩니다.
초기하 분포를 설명합니다. 어떤 경우에 이항 분포 경향이 있습니까?
교체 없이 시도 횟수 이상으로 성공했습니다. 빨간 공과 녹색 공으로 가득 찬 가방이 있고 5번의 시도에서 녹색 공을 뽑을 확률을 찾아야 하지만 공을 선택할 때마다 가방에 다시 돌려주지 않는다고 가정해 보겠습니다. 이것은 초기하 분포의 적절한 예입니다.
N이 크면 초기하 분포를 계산하는 것이 매우 어렵지만 N이 작으면 이 경우 이항 분포가 되는 경향이 있습니다.