
베이지안 네트워크 예 [그래픽 표현 포함]
게시 됨: 2021-01-29목차
소개
통계에서 확률 모델은 변수 간의 관계를 정의하는 데 사용되며 각 변수의 확률을 계산하는 데 사용할 수 있습니다. 많은 문제에는 많은 변수가 있습니다. 이러한 경우 완전 조건부 모델은 실시간으로 계산하기 어려울 수 있는 확률 함수의 모든 경우를 다루기 위해 엄청난 양의 데이터를 필요로 합니다. 나이브 베이즈(Naive Bayes)와 같은 조건부 확률 계산을 단순화하려는 여러 시도가 있었지만 여전히 여러 변수를 대폭 줄여서 효율적이지 않습니다.
유일한 방법은 확률 변수 간의 조건부 종속성과 다른 경우의 조건부 독립성을 유지할 수 있는 모델을 개발하는 것입니다. 이것은 우리를 베이지안 네트워크의 개념으로 이끕니다. 이러한 베이지안 네트워크는 각 도메인에 대한 확률 모델을 효과적으로 시각화하고 사용자 친화적인 그래프 형태로 랜덤 변수 간의 관계를 연구하는 데 도움이 됩니다.
세계 최고의 대학에서 ML 과정 을 배우십시오 . 석사, 이그 제 큐 티브 PGP 또는 고급 인증 프로그램을 획득하여 경력을 빠르게 추적하십시오.
베이지안 네트워크란?
정의에 따르면 베이지안 네트워크는 확률 계산에 베이지안 추론을 사용하는 확률적 그래픽 모델 유형입니다. DAG(방향성 비순환 그래프)를 사용하여 변수 집합과 조건부 확률을 나타냅니다. 주로 발생한 이벤트를 고려하고 알려진 몇 가지 가능한 원인 중 하나가 기여 요인일 가능성을 예측하는 데 적합합니다.
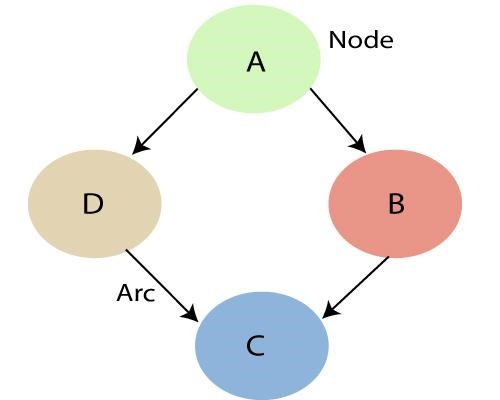
원천
위에서 언급한 바와 같이 베이지안 네트워크에 의해 지정된 관계를 사용하여 조건부 확률과 함께 JPF(Joint Probability Distribution)를 얻을 수 있습니다. 그래프의 각 노드는 랜덤 변수를 나타내고 호(또는 방향 화살표)는 노드 간의 관계를 나타냅니다. 그것들은 본질적으로 연속적이거나 불연속적일 수 있습니다.

위의 도표에서 A, B, C, D는 그래프의 네트워크에 주어진 노드로 표현되는 4개의 랜덤 변수입니다. 노드 B에서 A는 부모 노드이고 C는 자식 노드입니다. 노드 C는 노드 A와 독립적입니다.
베이지안 네트워크를 구현하기 전에 이해해야 할 몇 가지 확률 기본 사항이 있습니다.
지역 마르코프 속성
베이지안 네트워크는 로컬 마르코프 속성으로 알려진 속성을 충족합니다. 노드는 부모가 주어지면 비-하위 항목과 조건부로 독립적임을 나타냅니다. 위의 예에서 P(D|A, B)는 P(D|A)와 같습니다. D가 비하위 항목인 B와 독립적이기 때문입니다. 이 속성은 공동 분포를 단순화하는 데 도움이 됩니다. 지역 마르코프 속성은 마르코프 속성을 따른다고 하는 변수 주변의 임의 필드인 마르코프 랜덤 필드의 개념으로 안내합니다.
조건부 확률
수학에서 사건 A의 조건부 확률은 다른 사건 B가 이미 발생했을 때 사건 A가 발생할 확률입니다. 간단히 말해서 p(A | B)는 이벤트 B가 발생하는 경우 이벤트 A가 발생할 확률입니다. 그러나 A와 B 사이에는 두 가지 유형의 사건 가능성이 있습니다. 이들은 종속 사건 또는 독립 사건일 수 있습니다. 유형에 따라 조건부 확률을 계산하는 두 가지 방법이 있습니다.
- A와 B가 종속 이벤트인 경우 조건부 확률은 P(A| B) = P(A 및 B) / P(B)로 계산됩니다.
- A와 B가 독립적인 사건이면 조건부 확률에 대한 표현은 P(A| B) = P(A)로 표시됩니다.
공동 확률 분포
베이지안 네트워크의 예에 들어가기 전에 공동 확률 분포의 개념을 이해합시다. 3개의 변수 a1, a2 및 a3을 고려하십시오. 정의에 따르면, a1, a2 및 a3의 가능한 모든 조합의 확률을 합동 확률 분포라고 합니다.
만약 P[a1,a2, a3,…
P[a1,a2, a3,….., an] = P[a1 | a2, a3,…..,] * P[a2, a3,…..,]
= P[a1 | a2, a3,…..,] * P[a2 | a3,…..,]….P[an-1|an] * P[an]
위의 방정식을 일반화하면 공동 확률 분포를 다음과 같이 쓸 수 있습니다.
P(X i |X i-1 ,………, X n ) = P(X i |Parents(X i ))
베이지안 네트워크의 예
이제 간단한 예를 통해 베이지안 네트워크의 메커니즘과 장점을 이해해 보겠습니다. 이 예에서 학생이 방금 치른 시험에 대한 점수( m )를 모델링하는 작업이 주어졌다고 가정해 보겠습니다. 아래 주어진 베이지안 네트워크 그래프에서 우리는 마크가 두 개의 다른 변수에 의존한다는 것을 알 수 있습니다. 그들은,
- 시험 수준( e ) – 이 이산 변수는 시험의 난이도를 나타내며 두 가지 값(쉬움은 0, 어려움은 1)을 가집니다.
- IQ 수준( i ) – 이것은 학생의 지능 지수 수준을 나타내며 두 값(낮음은 0, 높음은 1)을 갖는 본질적으로 이산적입니다.
또한 학생의 IQ 수준은 학생의 적성 점수( s )인 또 다른 변수로 이어집니다. 이제 학생이 득점한 점수로 특정 대학에 입학할 수 있습니다. 대학에 합격( ) 할 확률 분포도 아래에 나와 있습니다.

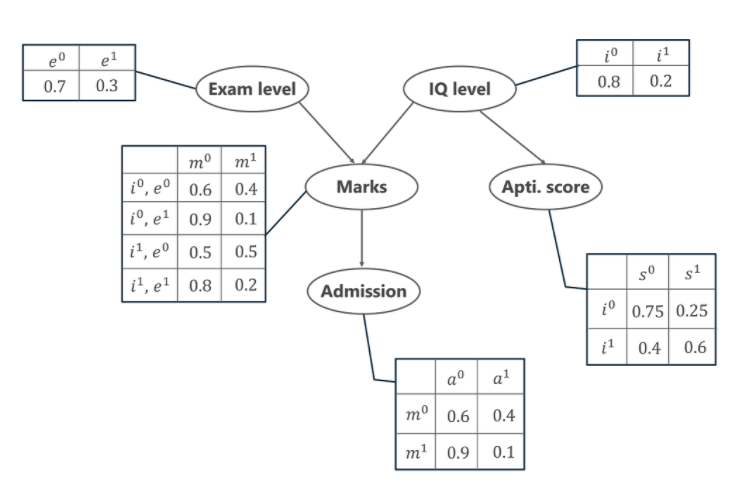
위의 그래프에서 주어진 5개 변수의 확률 분포 값을 나타내는 여러 테이블을 볼 수 있습니다. 이러한 테이블을 조건부 확률 테이블 또는 CPT라고 합니다. 아래에 주어진 CPT의 몇 가지 속성이 있습니다.
- 각 행에 있는 CPT 값의 합은 1과 같아야 합니다. 특정 변수에 대해 가능한 모든 경우가 완전하기 때문입니다(모든 가능성을 나타냄).
- 본질적으로 부울인 변수에 k 부울 부모가 있는 경우 CPT에서는 2K 확률 값을 갖습니다.
우리의 문제로 돌아가서 먼저 위에 주어진 표에서 발생하는 모든 가능한 이벤트를 나열하겠습니다.
- 시험 레벨 (e)
- IQ 수준 (i)
- 적성 점수
- 마크(m)
- 입학 (a)
이 5가지 변수는 조건부 확률 테이블과 함께 베이지안 네트워크 형식의 DAG(Directed Acyclic Graph) 형식으로 표시됩니다. 이제 공식이 주어진 5개 변수의 공동 확률 분포를 계산하기 위해,
P[a, m, i, e, s]= P(a | m) . 피(m | 나는, e) . 피(i) . 체육) . 피(들 | 나)
위의 공식으로부터,
- P(a | m)은 학생이 시험에서 득점한 점수를 기준으로 학생이 입학할 조건부 확률을 나타냅니다.
- P(m | i, e)는 학생이 자신의 IQ 수준과 시험 수준의 난이도를 감안할 때 채점할 점수를 나타냅니다.
- P(i)와 P(e)는 IQ 레벨과 시험 레벨의 확률을 나타냅니다.
- P(s | i)는 학생의 IQ 수준을 고려한 학생의 적성 점수의 조건부 확률입니다.
다음 확률을 계산하면 전체 베이지안 네트워크의 공동 확률 분포를 찾을 수 있습니다.
공동 확률 분포 계산
이제 두 가지 경우에 대한 JPD를 계산해 보겠습니다.
사례 1: 시험 수준이 어렵지만 IQ가 낮고 적성 점수가 낮은 학생이 시험에 합격하고 대학에 합격할 확률을 계산합니다.
위의 단어 문제 설명에서 공동 확률 분포는 다음과 같이 쓸 수 있습니다.
P[a=1, m=1, i=0, e=1, s=0]
위의 조건부 확률 표에서 주어진 조건에 대한 값이 공식에 입력되고 아래와 같이 계산됩니다.
P[a=1, m=1, i=0, e=0, s=0] = P(a=1 | m=1) . P(m=1 | i=0, e=1) . P(i=0) . P(e=1) . P(s=0 | i=0)
= 0.1 * 0.1 * 0.8 * 0.3 * 0.75
= 0.0018
사례 2: 또 다른 경우, 학생이 높은 IQ 수준과 적성 점수를 가질 확률을 계산합니다. 시험은 쉽지만 합격에 실패하고 대학 입학을 보장하지 않습니다.
JPD의 공식은 다음과 같습니다.
P[a=0, m=0, i=1, e=0, s=1]
따라서,
P[a=0, m=0, i=1, e=0, s=1]= P(a=0 | m=0) . P(m=0 | i=1, e=0) . P(i=1) . P(e=0) . P(s=1 | i=1)
= 0.6 * 0.5 * 0.2 * 0.7 * 0.6
= 0.0252
따라서 이러한 방식으로 베이지안 네트워크 및 확률 테이블을 사용하여 발생할 수 있는 다양한 이벤트에 대한 확률을 계산할 수 있습니다.
더 읽어보기: 기계 학습 프로젝트 아이디어 및 주제
결론
스팸 필터링, 의미 검색, 정보 검색 등에서 베이지안 네트워크에 대한 수많은 응용 프로그램이 있습니다. 예를 들어, 주어진 증상으로 우리는 질병에 기여하는 몇 가지 다른 요인과 함께 질병이 발생할 확률을 예측할 수 있습니다. 따라서 이 기사에서는 베이지안 네트워크의 개념을 실제 예제와 함께 구현과 함께 소개합니다.
기계 학습 및 AI를 마스터하는 데 관심이 있다면 IIIT-B 및 리버풀 존 무어스 대학의 기계 학습 및 AI에 대한 고급 과정을 통해 경력을 향상시키십시오.
베이지안 네트워크는 어떻게 구현됩니까?
베이지안 네트워크는 각 노드가 랜덤 변수를 나타내는 그래픽 모델입니다. 각 노드는 방향 호에 의해 다른 노드에 연결됩니다. 각 호는 자녀에게 주어진 부모의 조건부 확률 분포를 나타냅니다. 방향이 지정된 모서리는 부모가 자식에 미치는 영향을 나타냅니다. 노드는 일반적으로 실제 개체를 나타내고 호는 개체 간의 물리적 또는 논리적 관계를 나타냅니다. 베이지안 네트워크는 자동 음성 인식, 문서/이미지 분류, 의료 진단 및 로봇과 같은 많은 애플리케이션에서 사용됩니다.
베이지안 네트워크가 왜 중요한가요?
알다시피 베이지안 네트워크는 기계 학습 및 통계의 중요한 부분입니다. 데이터 마이닝 및 과학적 발견에 사용됩니다. 베이지안 네트워크는 랜덤 변수를 나타내는 노드와 직접적인 영향을 나타내는 호가 있는 방향성 비순환 그래프(DAG)입니다. 베이지안 네트워크는 텍스트 분석, 사기 탐지, 암 탐지, 이미지 인식 등과 같은 다양한 응용 프로그램에서 사용됩니다. 이 기사에서는 베이지안 네트워크의 추론에 대해 설명합니다. 베이지안 네트워크는 과거를 분석하고 미래를 예측하며 의사결정의 질을 향상시키는 중요한 도구입니다. 베이지안 네트워크는 통계에서 시작되었지만 현재 연구 과학자, 운영 연구 분석가, 산업 엔지니어, 마케팅 전문가, 비즈니스 컨설턴트 및 관리자를 포함한 모든 전문가가 사용하고 있습니다.
희소 베이지안 네트워크란 무엇입니까?
희소 베이지안 네트워크(SBN)는 조건부 확률 분포가 희소 그래프인 특수한 종류의 베이지안 네트워크입니다. 변수의 수가 많거나 관측치가 적은 경우 SBN을 사용하는 것이 적절할 수 있습니다. 일반적으로 베이지안 네트워크는 여러 요인을 조건으로 하여 관찰 또는 이벤트를 설명하는 데 관심이 있을 때 가장 유용합니다.