
머신 러닝의 베이즈 정리: 소개, 적용 방법 및 예
게시 됨: 2021-02-04목차
소개: 베이즈 정리란 무엇입니까?
Bayes Theorem은 확률을 포함하는 수학 분야인 의사결정 이론에서 광범위하게 연구한 영국 수학자 Thomas Bayes의 이름을 따서 명명되었습니다. Bayes Theorem은 기계 학습에서도 널리 사용되며, 정확하고 정확하게 클래스를 예측하는 간단하고 효과적인 방법입니다. 조건부 확률을 계산하는 베이지안 방법은 분류 작업과 관련된 기계 학습 응용 프로그램에서 사용됩니다.
나이브 베이즈 분류로 알려진 베이즈 정리의 단순화된 버전은 계산 시간과 비용을 줄이는 데 사용됩니다. 이 기사에서는 이러한 개념을 살펴보고 머신 러닝에서 베이즈 정리의 적용에 대해 논의합니다.
세계 최고의 대학에서 온라인으로 머신 러닝 과정 에 참여하십시오. 석사, 대학원 대학원 과정, ML 및 AI 고급 인증 프로그램을 통해 빠르게 경력을 쌓을 수 있습니다.
기계 학습에서 베이즈 정리를 사용하는 이유는 무엇입니까?
베이즈 정리는 조건부 확률, 즉 다른 이벤트가 이미 발생했음을 감안할 때 한 이벤트가 발생할 확률을 결정하는 방법입니다. 조건부 확률에는 추가 조건(즉, 더 많은 데이터)이 포함되기 때문에 더 정확한 결과에 기여할 수 있습니다.
따라서 조건부 확률은 머신 러닝에서 정확한 예측과 확률을 결정하는 데 필수적입니다. 이 분야가 다양한 도메인에 걸쳐 점점 더 보편화되고 있다는 점을 감안할 때 머신 러닝에서 베이즈 정리와 같은 알고리즘 및 방법의 역할을 이해하는 것이 중요합니다.
정리 자체에 들어가기 전에 예를 통해 몇 가지 용어를 이해합시다. 서점 관리자가 고객의 나이와 수입에 대한 정보를 가지고 있다고 가정해 보겠습니다. 그는 청소년(18-35세), 중년(35-60세), 노인(60세 이상)과 같은 세 가지 연령대의 고객에게 도서 판매가 어떻게 분포되어 있는지 알고 싶어합니다.

데이터를 X라고 합시다. 베이지안 용어로 X를 증거라고 합니다. 우리는 특정 클래스 C에 속하는 일부 X가 있는 일부 가설 H가 있습니다.
우리의 목표는 주어진 X, 즉 P(H | X) 가설 H의 조건부 확률을 결정하는 것입니다.
간단히 말해서 P(H | X)를 결정하면 X가 주어지면 X가 클래스 C에 속할 확률을 얻습니다. X에는 연령과 소득 속성이 있습니다. H는 고객이 책을 구매할 것이라는 우리의 가설입니다.
다음 네 가지 용어에 주의하십시오.
- 증거 – 앞에서 논의한 바와 같이 P(X)는 증거로 알려져 있습니다. 이 경우 고객이 26세가 되어 2,000달러를 벌게 될 확률은 간단합니다.
- 사전 확률 – 사전 확률로 알려진 P(H)는 고객이 책을 구매할 것이라는 가설의 단순 확률입니다. 이 확률에는 연령 및 소득에 따른 추가 입력이 제공되지 않습니다. 계산이 더 적은 정보로 수행되기 때문에 결과가 덜 정확합니다.
- 사후 확률 – P(H | X)는 사후 확률로 알려져 있습니다. 여기서 P(H | X)는 X(그가 26세이고 $2000를 번)가 주어진 책(H)을 구매할 확률입니다.
- 가능성 – P(X | H)는 가능성 확률입니다. 이 경우 고객이 책을 구입할 것이라는 것을 알고 있다고 가정할 때 가능성 확률은 고객이 26세이고 소득이 $2000일 확률입니다.
이를 감안할 때 Bayes Theorem은 다음과 같이 말합니다.
P(H | X) = [ P(X | H) * P(H) ] / P(X)
정리에서 위의 네 가지 용어(사후 확률, 가능성 확률, 사전 확률 및 증거)의 모양에 유의하십시오.
읽기: Naive Bayes 설명
머신 러닝에 베이즈 정리를 적용하는 방법
Bayes Theorem의 단순화된 버전인 Naive Bayes Classifier는 데이터를 정확도와 속도로 다양한 클래스로 분류하는 분류 알고리즘으로 사용됩니다.
Naive Bayes Classifier를 분류 알고리즘으로 적용하는 방법을 살펴보겠습니다.
- 일반적인 예를 고려하십시오. X는 'n' 속성으로 구성된 벡터입니다. 즉, X = {x1, x2, x3, …, xn}입니다.
- '클래스 {C1, C2, ..., Cm}이 있다고 가정합니다. 분류기는 X가 특정 클래스에 속한다고 예측해야 합니다. 사후 확률이 가장 높은 클래스가 최고의 클래스로 선택됩니다. 따라서 수학적으로 분류기는 클래스 Ci iff P(Ci | X) > P(Cj | X)에 대해 예측합니다. 베이즈 정리 적용:
P(Ci | X) = [ P(X | Ci) * P(Ci) ] / P(X)
- 조건 독립적인 P(X)는 각 클래스에 대해 일정합니다. 따라서 P(Ci | X)를 최대화하려면 [P(X | Ci) * P(Ci)]를 최대화해야 합니다. 모든 클래스가 동등할 가능성이 있다고 생각하면 P(C1) = P(C2) = P(C3) … = P(Cn)입니다. 따라서 궁극적으로 P(X | Ci)만 최대화해야 합니다.
- 일반적인 대형 데이터 세트는 여러 속성을 가질 가능성이 높기 때문에 각 속성에 대해 P(X | Ci) 연산을 수행하는 데 계산 비용이 많이 듭니다. 이것은 문제를 단순화하고 계산 비용을 줄이기 위해 클래스 조건부 독립이 필요한 곳입니다. 클래스 조건부 독립성이란 속성의 값을 조건부로 서로 독립적으로 간주한다는 의미입니다. 이것은 나이브 베이즈 분류입니다.
P(Xi | C) = P(x1 | C) * P(x2 | C) *... * P(xn | C)
이제 더 작은 확률을 쉽게 계산할 수 있습니다. 여기서 주목해야 할 한 가지 중요한 점은 xk가 각 속성에 속하기 때문에 우리가 다루고 있는 속성이 categorical 인지 연속적 인지 확인해야 합니다 .
- 범주 속성 이 있으면 상황이 더 간단합니다. 속성 k에 대한 값 xk로 구성된 Ci 클래스의 인스턴스 수를 계산한 다음 이를 Ci 클래스의 인스턴스 수로 나눌 수 있습니다.
- 연속 속성이 있는 경우 정규 분포 함수가 있다고 가정하고 다음 공식을 적용합니다. 평균 ? 및 표준 편차 ?:
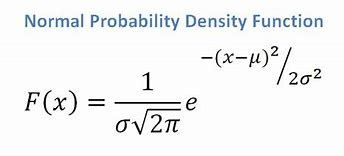

원천
궁극적으로 P(x | Ci) = F(xk, ?k, ?k)가 됩니다.
- 이제 각 클래스 Ci에 대해 Bayes Theorem을 사용하는 데 필요한 모든 값이 있습니다. 우리의 예측 클래스는 가장 높은 확률 P(X | Ci) * P(Ci)를 달성하는 클래스가 될 것입니다.
예: 서점의 고객을 예측적으로 분류하기
서점에서 가져온 다음 데이터세트가 있습니다.
| 나이 | 소득 | 학생 | 신용 등급 | 구매_도서 |
| 청년 | 높은 | 아니요 | 공정한 | 아니요 |
| 청년 | 높은 | 아니요 | 훌륭한 | 아니요 |
| 중년의 | 높은 | 아니요 | 공정한 | 네 |
| 상위 | 중간 | 아니요 | 공정한 | 네 |
| 상위 | 낮은 | 네 | 공정한 | 네 |
| 상위 | 낮은 | 네 | 훌륭한 | 아니요 |
| 중년의 | 낮은 | 네 | 훌륭한 | 네 |
| 청년 | 중간 | 아니요 | 공정한 | 아니요 |
| 청년 | 낮은 | 네 | 공정한 | 네 |
| 상위 | 중간 | 네 | 공정한 | 네 |
| 청년 | 중간 | 네 | 훌륭한 | 네 |
| 중년의 | 중간 | 아니요 | 훌륭한 | 네 |
| 중년의 | 높은 | 네 | 공정한 | 네 |
| 상위 | 중간 | 아니요 | 훌륭한 | 아니요 |
연령, 소득, 학생 및 신용 등급과 같은 속성이 있습니다. 우리 클래스 buys_book은 예 또는 아니오의 두 가지 결과를 가집니다.
우리의 목표는 다음 속성을 기반으로 분류하는 것입니다.
X = {나이 = 청소년, 학생 = 예, 소득 = 중간, 신용 등급 = 보통}.
앞에서 설명한 것처럼 P(Ci | X)를 최대화하려면 i = 1 및 i = 2에 대해 [ P(X | Ci) * P(Ci) ]를 최대화해야 합니다.
따라서 P(buys_book = yes) = 9/14 = 0.643
P(buys_book = no) = 5/14 = 0.357
P(나이 = 청소년 | buys_book = yes) = 2/9 = 0.222
P(나이 = 청소년 | buys_book = 아니오) =3/5 = 0.600
P(수입 = 중간 | buys_book = yes) = 4/9 = 0.444
P(수입 = 중간 | buys_book = 아니오) = 2/5 = 0.400
P(학생 = 예 | buys_book = 예) = 6/9 = 0.667
P(학생 = 예 | buys_book = 아니오) = 1/5 = 0.200
P(credit_rating = 공정 | buys_book = yes) = 6/9 = 0.667
P(credit_rating = 공정 | buys_book = no) = 2/5 = 0.400
위에서 계산한 확률을 이용하여
P(X | 매수_북 = 예) = 0.222 x 0.444 x 0.667 x 0.667 = 0.044
비슷하게,
P(X | 매수_북 = 아니오) = 0.600 x 0.400 x 0.200 x 0.400 = 0.019
Ci는 최대 P(X|Ci)*P(Ci)를 제공하는 클래스는 무엇입니까? 우리는 다음을 계산합니다.
P(X | Buys_book = yes)* P(buys_book = yes) = 0.044 x 0.643 = 0.028
P(X | Buys_book = no)* P(buys_book = no) = 0.019 x 0.357 = 0.007
위의 두 가지를 비교하면 0.028 > 0.007이기 때문에 Naive Bayes Classifier는 위에서 언급한 속성을 가진 고객이 책 을 구매할 것이라고 예측합니다.
확인: 기계 학습 프로젝트 아이디어 및 주제
베이지안 분류기가 좋은 방법입니까?
머신 러닝에서 베이즈 정리에 기반한 알고리즘은 다른 알고리즘과 유사한 결과를 제공하며 베이지안 분류기는 일반적으로 단순한 고정밀 방법으로 간주됩니다. 그러나 베이지안 분류기는 클래스 조건부 독립성의 가정이 유효한 경우에 특히 적합하며 모든 경우에 적용되는 것은 아님을 기억해야 합니다. 또 다른 실질적인 우려는 모든 확률 데이터를 획득하는 것이 항상 가능하지 않을 수 있다는 것입니다.
결론
Bayes Theorem은 기계 학습, 특히 분류 기반 문제에서 많은 응용 프로그램을 가지고 있습니다. 머신 러닝에 이 알고리즘 제품군을 적용하려면 사전 확률 및 사후 확률과 같은 용어에 익숙해야 합니다. 이 기사에서는 Bayes Theorem의 기본 사항과 머신 러닝 문제에서의 사용에 대해 논의하고 분류 예제를 통해 작업했습니다.
Bayes Theorem은 기계 학습에서 분류 기반 알고리즘의 중요한 부분을 구성하므로 기계 학습 및 NLP에서 upGrad의 고급 인증 프로그램에 대해 자세히 알아볼 수 있습니다 . 이 과정은 기계 학습에 관심이 있는 다양한 유형의 학생들을 염두에 두고 제작되었으며 1-1 멘토링 등을 제공합니다.
기계 학습에서 베이즈 정리를 사용하는 이유는 무엇입니까?
Bayes Theorem은 조건부 확률, 또는 이전에 다른 이벤트가 발생한 경우 한 이벤트가 발생할 가능성을 계산하는 방법입니다. 조건부 확률은 추가 조건, 즉 더 많은 데이터를 포함하여 더 정확한 결과를 도출할 수 있습니다. 머신러닝에서 정확한 추정과 확률을 얻기 위해서는 조건부 확률이 필요합니다. 광범위한 도메인에서 이 분야의 보급이 증가하고 있다는 점을 감안할 때 기계 학습에서 Bayes Theorem과 같은 접근 방식과 알고리즘의 중요성을 이해하는 것이 중요합니다.
베이지안 분류기가 좋은 선택입니까?
기계 학습에서 Bayes Theorem에 기반한 알고리즘은 다른 방법과 유사한 결과를 생성하며 Bayesian 분류기는 단순한 고정밀 접근 방식으로 널리 간주됩니다. 그러나 베이지안 분류기는 모든 상황이 아니라 클래스 조건부 독립의 조건이 정확할 때 가장 잘 사용된다는 점을 명심하는 것이 중요합니다. 또 다른 고려 사항은 모든 가능성 데이터를 얻는 것이 항상 가능하지 않을 수 있다는 것입니다.
Bayes 정리를 실제로 어떻게 적용할 수 있습니까?
베이즈 정리는 관련되거나 관련될 수 있는 새로운 증거를 기반으로 발생 가능성을 계산합니다. 이 방법은 또한 새로운 정보가 사실이라고 가정할 때 가상의 새로운 정보가 사건의 가능성에 어떻게 영향을 미치는지 확인하는 데 사용할 수 있습니다. 예를 들어 52장의 카드 더미에서 단일 카드를 선택합니다. 카드가 왕이 될 확률은 4를 52로 나눈 1/13 또는 약 7.69%입니다. 덱에는 4개의 킹이 포함되어 있음을 기억하십시오. 선택한 카드가 얼굴 카드라는 사실이 밝혀졌다고 가정해 봅시다. 한 덱에 12장의 앞면 카드가 있기 때문에 고른 카드가 왕일 확률은 4를 12로 나눈 값, 즉 대략 33.3%입니다.