
Flask, Google의 Cloud SQL 및 App Engine을 사용하여 API 설정
게시 됨: 2022-03-10몇 가지 Python 프레임워크를 사용하여 API를 만들 수 있으며 그 중 두 가지는 Flask와 Django입니다. 프레임워크에는 개발자가 사용자가 응용 프로그램과 상호 작용하는 데 필요한 기능을 쉽게 구현할 수 있는 기능이 함께 제공됩니다. 웹 애플리케이션의 복잡성은 작업할 프레임워크를 선택할 때 결정적인 요소가 될 수 있습니다.
장고
Django는 기능이 내장된 미리 정의된 구조를 가진 강력한 프레임워크입니다. 그러나 견고성의 단점은 특정 프로젝트에 대해 프레임워크를 너무 복잡하게 만들 수 있다는 것입니다. Django의 고급 기능을 활용해야 하는 복잡한 웹 애플리케이션에 가장 적합합니다.
플라스크
반면 Flask는 API 구축을 위한 경량 프레임워크입니다. 시작하기 쉽고 패키지를 사용하여 이동하면서 견고하게 만들 수 있습니다. 이 문서에서는 보기 기능과 컨트롤러를 정의하고 GCP의 데이터베이스에 연결하고 GCP에 배포하는 방법에 중점을 둘 것입니다.
학습 목적으로 몇 가지 엔드포인트가 있는 Flask API를 구축하여 좋아하는 노래 모음을 관리합니다. 엔드포인트는 GET 및 POST 요청(리소스 가져오기 및 생성)을 위한 것입니다. 그와 함께 Google Cloud 플랫폼에서 서비스 제품군을 사용할 것입니다. 데이터베이스용으로 Google의 Cloud SQL을 설정하고 App Engine에 배포하여 앱을 시작하겠습니다. 이 가이드는 앱에 Google Cloud를 처음 사용하는 초보자를 대상으로 합니다.
플라스크 프로젝트 설정
이 자습서에서는 Python 3.x가 설치되어 있다고 가정합니다. 그렇지 않은 경우 공식 웹 사이트로 이동하여 다운로드하여 설치하십시오.
Python이 설치되어 있는지 확인하려면 명령줄 인터페이스(CLI)를 시작하고 아래 명령을 실행합니다.
python -V 첫 번째 단계는 프로젝트가 위치할 디렉토리를 만드는 것입니다. 우리는 그것을 flask-app 이라고 부를 것입니다:
mkdir flask-app && cd flask-appPython 프로젝트를 시작할 때 가장 먼저 해야 할 일은 가상 환경을 만드는 것입니다. 가상 환경은 작업 중인 Python 개발을 격리합니다. 이는 이 프로젝트가 컴퓨터의 다른 프로젝트와 다른 자체 종속성을 가질 수 있음을 의미합니다. venv는 Python 3과 함께 제공되는 모듈입니다.
flask-app 디렉토리에 가상 환경을 생성해 보겠습니다.
python3 -m venv env 이 명령은 디렉토리에 env 폴더를 생성합니다. 이름(이 경우 env )은 가상 환경의 별칭이며 아무 이름이나 지정할 수 있습니다.
이제 가상 환경을 만들었으므로 프로젝트에 이를 사용하도록 지시해야 합니다. 가상 환경을 활성화하려면 다음 명령을 사용하십시오.
source env/bin/activate 이제 CLI 프롬프트의 시작 부분에 환경이 활성 상태임을 나타내는 env 가 있는 것을 볼 수 있습니다.

(env) 가 프롬프트 앞에 나타남(큰 미리보기)이제 Flask 패키지를 설치해 보겠습니다.
pip install flask 현재 디렉터리에 api 라는 디렉터리를 만듭니다. 앱의 다른 폴더가 상주할 폴더를 갖도록 이 디렉토리를 생성합니다.
mkdir api && cd api 다음으로 우리 앱의 진입점 역할을 할 main.py 파일을 만듭니다.
touch main.py main.py 를 열고 다음 코드를 입력합니다.
#main.py from flask import Flask app = Flask(__name__) @app.route('/') def home(): return 'Hello World' if __name__ == '__main__': app.run() 여기서 우리가 한 일을 이해합시다. 먼저 Flask 패키지에서 Flask 클래스를 가져왔습니다. 그런 다음 클래스의 인스턴스를 만들고 app 에 할당했습니다. 다음으로 앱의 루트를 가리키는 첫 번째 끝점을 만들었습니다. 요약하면 이것은 / 경로를 호출하는 보기 함수입니다 — Hello World 를 반환합니다.
앱을 실행해 보겠습니다.
python main.py 이것은 로컬 서버를 시작하고 https://127.0.0.1:5000/ 에서 앱을 제공합니다. 브라우저에 URL을 입력하면 화면에 Hello World 응답이 인쇄되는 것을 볼 수 있습니다.
그리고 짜잔! 앱이 실행 중입니다. 다음 작업은 기능을 만드는 것입니다.
엔드포인트를 호출하기 위해 개발자가 엔드포인트를 테스트하는 데 도움이 되는 서비스인 Postman을 사용할 것입니다. 공식 웹사이트에서 다운로드할 수 있습니다.
main.py 가 일부 데이터를 반환하도록 합시다.
#main.py from flask import Flask, jsonify app = Flask(__name__) songs = [ { "title": "Rockstar", "artist": "Dababy", "genre": "rap", }, { "title": "Say So", "artist": "Doja Cat", "genre": "Hiphop", }, { "title": "Panini", "artist": "Lil Nas X", "genre": "Hiphop" } ] @app.route('/songs') def home(): return jsonify(songs) if __name__ == '__main__': app.run() 여기에 노래 제목과 아티스트 이름을 포함한 노래 목록이 포함되었습니다. 그런 다음 루트 / 경로를 /songs 로 변경했습니다. 이 경로는 우리가 지정한 노래 배열을 반환합니다. 목록을 JSON 값으로 가져오기 위해 jsonify 를 통해 목록을 전달하여 목록을 JSON화했습니다. 이제 간단한 Hello world 대신 https://127.0.0.1:5000/songs 엔드포인트에 액세스할 때 아티스트 목록이 표시됩니다.
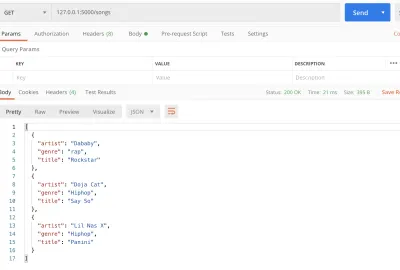
get (큰 미리보기) 변경될 때마다 서버를 다시 시작해야 한다는 사실을 눈치채셨을 것입니다. 코드가 변경될 때 자동 다시 로드를 활성화하려면 디버그 옵션을 활성화해 보겠습니다. 이렇게 하려면 app.run 을 다음과 같이 변경합니다.
app.run(debug=True) 다음으로 배열에 게시 요청을 사용하여 노래를 추가해 보겠습니다. 먼저 사용자로부터 들어오는 요청을 처리할 수 있도록 request 개체를 가져옵니다. 나중에 보기 함수에서 request 개체를 사용하여 JSON에서 사용자 입력을 가져옵니다.
#main.py from flask import Flask, jsonify, request app = Flask(__name__) songs = [ { "title": "Rockstar", "artist": "Dababy", "genre": "rap", }, { "title": "Say So", "artist": "Doja Cat", "genre": "Hiphop", }, { "title": "Panini", "artist": "Lil Nas X", "genre": "Hiphop" } ] @app.route('/songs') def home(): return jsonify(songs) @app.route('/songs', methods=['POST']) def add_songs(): song = request.get_json() songs.append(song) return jsonify(songs) if __name__ == '__main__': app.run(debug=True) add_songs 보기 기능은 사용자가 제출한 노래를 가져와 기존 노래 목록에 추가합니다.
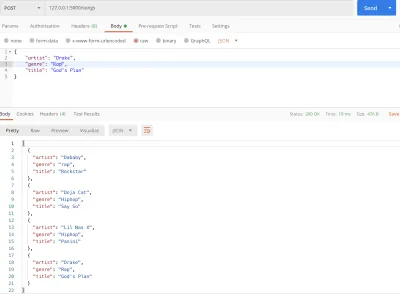
지금까지 Python 목록에서 데이터를 반환했습니다. 보다 강력한 환경에서 서버를 다시 시작하면 새로 추가된 데이터가 손실되기 때문에 이것은 실험적일 뿐입니다. 그것은 실현 가능하지 않으므로 데이터를 저장하고 검색하기 위해 라이브 데이터베이스가 필요합니다. Cloud SQL이 제공됩니다.
Cloud SQL 인스턴스를 사용하는 이유
공식 웹사이트에 따르면:
“Google Cloud SQL은 클라우드에서 관계형 MySQL 및 PostgreSQL 데이터베이스를 쉽게 설정, 유지, 관리할 수 있게 해주는 완전 관리형 데이터베이스 서비스입니다. Google Cloud Platform에서 호스팅되는 Cloud SQL은 어디서나 실행되는 애플리케이션을 위한 데이터베이스 인프라를 제공합니다."
즉, 유연한 가격으로 데이터베이스 인프라 관리를 전적으로 Google에 아웃소싱할 수 있습니다.
Cloud SQL과 자체 관리형 Compute Engine의 차이점 |
Google Cloud에서는 Google의 Compute Engine 인프라에서 가상 머신을 가동하고 SQL 인스턴스를 설치할 수 있습니다. 이는 수직 확장성, 복제 및 기타 구성 호스트를 담당하게 됨을 의미합니다. Cloud SQL을 사용하면 즉시 구성할 수 있으므로 코드에 더 많은 시간을 할애하고 설정하는 시간을 줄일 수 있습니다.
시작하기 전에:
- Google Cloud에 가입하세요. Google은 신규 사용자에게 $300의 무료 크레딧을 제공합니다.
- 프로젝트를 만듭니다. 이것은 매우 간단하며 콘솔에서 바로 수행할 수 있습니다.
Cloud SQL 인스턴스 만들기
Google Cloud에 가입한 후 왼쪽 패널에서 "SQL" 탭으로 스크롤하여 클릭합니다.
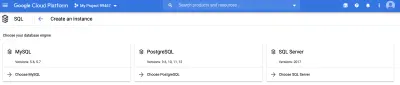
먼저 SQL 엔진을 선택해야 합니다. 이 기사에서는 MySQL을 사용할 것입니다.
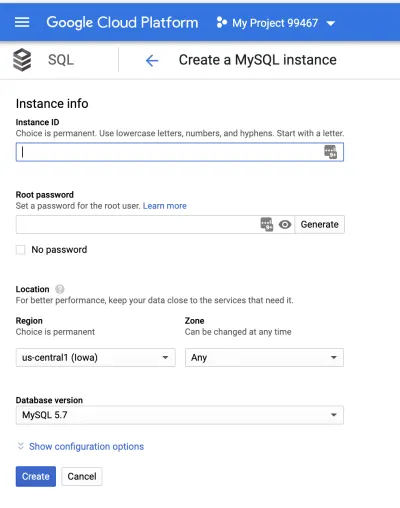
다음으로 인스턴스를 생성하겠습니다. 기본적으로 인스턴스는 미국에서 생성되며 영역은 자동으로 선택됩니다.
루트 암호를 설정하고 인스턴스 이름을 지정한 다음 "만들기" 버튼을 클릭합니다. "구성 옵션 표시" 드롭다운을 클릭하여 인스턴스를 추가로 구성할 수 있습니다. 설정을 통해 인스턴스의 크기, 스토리지 용량, 보안, 가용성, 백업 등을 구성할 수 있습니다. 이 기사에서는 기본 설정을 사용합니다. 걱정하지 마세요. 이러한 변수는 나중에 변경할 수 있습니다.
프로세스가 완료되는 데 몇 분 정도 걸릴 수 있습니다. 녹색 확인 표시가 나타나면 인스턴스가 준비된 것입니다. 인스턴스 이름을 클릭하여 세부 정보 페이지로 이동합니다.
이제 실행이 완료되었으므로 몇 가지 작업을 수행합니다.
- 데이터베이스를 생성합니다.
- 새 사용자를 만듭니다.
- 우리의 IP 주소를 허용 목록에 추가하십시오.
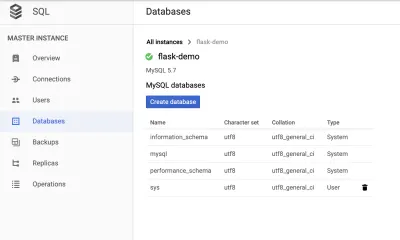
데이터베이스 생성
"데이터베이스" 탭으로 이동하여 데이터베이스를 생성합니다.
새 사용자 만들기
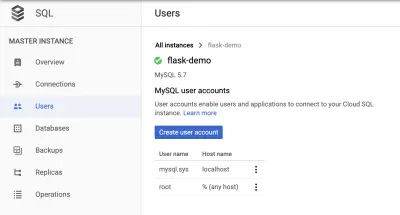
"호스트 이름" 섹션에서 "%(모든 호스트)"를 허용하도록 설정합니다.

화이트리스트 IP 주소
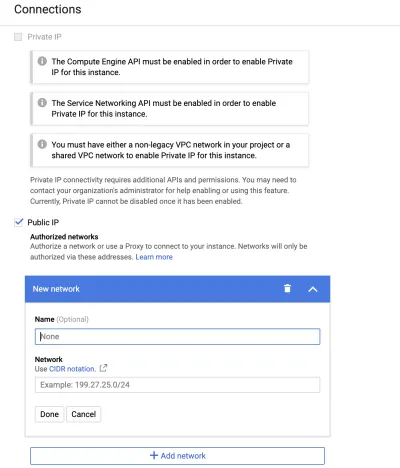
두 가지 방법 중 하나로 데이터베이스 인스턴스에 연결할 수 있습니다. 사설 IP 주소에는 가상 사설 클라우드(VPC)가 필요합니다. 이 옵션을 선택하면 GCP가 Google 관리형 VPC를 만들고 여기에 인스턴스를 배치합니다. 이 기사에서는 기본값인 공용 IP 주소를 사용합니다. IP 주소가 화이트리스트에 등록된 사람만 데이터베이스에 액세스할 수 있다는 점에서 공개입니다.
귀하의 IP 주소를 허용 목록에 추가하려면 Google 검색에 my ip 를 입력하여 귀하의 IP를 얻으십시오. 그런 다음 "연결" 탭과 "네트워크 추가"로 이동합니다.
인스턴스에 연결
그런 다음 "개요" 패널로 이동하여 클라우드 셸을 사용하여 연결합니다.
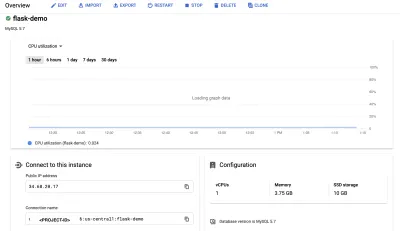
Cloud SQL 인스턴스에 연결하는 명령은 콘솔에 미리 입력됩니다.
루트 사용자 또는 이전에 생성된 사용자를 사용할 수 있습니다. 아래 명령에서 우리는 다음과 같이 말하고 있습니다. 사용자 USERNAME 으로 flask-demo 인스턴스에 연결합니다. 사용자의 암호를 입력하라는 메시지가 표시됩니다.
gcloud sql connect flask-demo --user=USERNAME프로젝트 ID가 없다는 오류가 발생하면 다음을 실행하여 프로젝트 ID를 얻을 수 있습니다.
gcloud projects list 위 명령어에서 출력된 프로젝트 ID를 아래 명령어에 입력하여 PROJECT_ID 를 대입한다.
gcloud config set project PROJECT_ID 그런 다음 gcloud sql connect 명령어를 실행하면 연결됩니다.
활성 데이터베이스를 보려면 다음 명령을 실행하십시오.
> show databases; 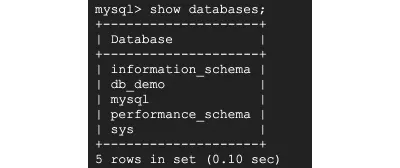
내 데이터베이스의 이름은 db_demo 이며 db_demo 데이터베이스를 사용하기 위해 아래 명령을 실행하겠습니다. information_schema 및 performance_schema 와 같은 다른 데이터베이스를 볼 수 있습니다. 이들은 테이블 메타 데이터를 저장하기 위해 있습니다.
> use db_demo;다음으로 Flask 앱의 목록을 미러링하는 테이블을 만듭니다. 메모장에 아래 코드를 입력하고 클라우드 셸에 붙여넣습니다.
create table songs( song_id INT NOT NULL AUTO_INCREMENT, title VARCHAR(255), artist VARCHAR(255), genre VARCHAR(255), PRIMARY KEY(song_id) ); 이 코드는 네 개의 열( song_id , title , artist 및 genre )이 있는 songs 이라는 테이블을 생성하는 SQL 명령입니다. 또한 테이블이 song_id 를 기본 키로 정의하고 1부터 자동으로 증가하도록 지시했습니다.
이제 show tables; 테이블이 생성되었는지 확인합니다.
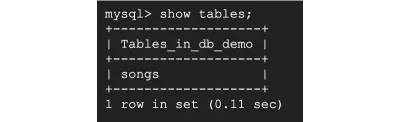
그렇게 해서 데이터베이스와 songs 테이블을 만들었습니다.
다음 작업은 앱을 배포할 수 있도록 Google App Engine을 설정하는 것입니다.
구글 앱 엔진
App Engine은 웹 애플리케이션을 대규모로 개발 및 호스팅하기 위한 완전 관리형 플랫폼입니다. App Engine에 배포하면 들어오는 트래픽에 맞게 앱을 자동으로 확장할 수 있다는 장점이 있습니다.
App Engine 웹 사이트는 다음과 같이 말합니다.
"서버 관리 및 구성 배포가 필요 없기 때문에 개발자는 관리 오버헤드 없이 훌륭한 애플리케이션을 구축하는 데에만 집중할 수 있습니다."
App Engine 설정
Google Cloud Console의 UI 또는 Google Cloud SDK를 통해 App Engine을 설정하는 몇 가지 방법이 있습니다. 이 섹션에서는 SDK를 사용합니다. 이를 통해 로컬 머신에서 Google Cloud 인스턴스를 배포, 관리, 모니터링할 수 있습니다.
구글 클라우드 SDK 설치
지침에 따라 Mac 또는 Windows용 SDK를 다운로드하고 설치합니다. 이 가이드에서는 CLI에서 SDK를 초기화하는 방법과 Google Cloud 프로젝트를 선택하는 방법도 보여줍니다.
SDK가 설치되었으므로 이제 데이터베이스의 자격 증명으로 Python 스크립트를 업데이트하고 App Engine에 배포하겠습니다.
로컬 설정
로컬 환경에서는 Cloud SQL 및 App Engine을 포함하는 새로운 아키텍처에 맞게 설정을 업데이트할 것입니다.
먼저 루트 폴더에 app.yaml 파일을 추가합니다. 이것은 App Engine이 앱을 호스팅하고 실행하는 데 필요한 구성 파일입니다. 런타임 및 필요할 수 있는 기타 변수를 App Engine에 알립니다. 앱의 경우 App Engine이 데이터베이스의 인스턴스를 인식할 수 있도록 데이터베이스의 자격 증명을 환경 변수로 추가해야 합니다.
app.yaml 파일에서 아래 스니펫을 추가합니다. 데이터베이스 설정에서 런타임 및 데이터베이스 변수를 얻었을 것입니다. 값을 Cloud SQL을 설정할 때 사용한 사용자 이름, 비밀번호, 데이터베이스 이름, 연결 이름으로 바꿉니다.
#app.yaml runtime: python37 env_variables: CLOUD_SQL_USERNAME: YOUR-DB-USERNAME CLOUD_SQL_PASSWORD: YOUR-DB-PASSWORD CLOUD_SQL_DATABASE_NAME: YOUR-DB-NAME CLOUD_SQL_CONNECTION_NAME: YOUR-CONN-NAME이제 PyMySQL을 설치하겠습니다. 이것은 MySQL 데이터베이스에 연결하고 쿼리를 수행하는 Python MySQL 패키지입니다. CLI에서 다음 줄을 실행하여 PyMySQL 패키지를 설치합니다.
pip install pymysql이 시점에서 PyMySQL을 사용하여 앱에서 Cloud SQL 데이터베이스에 연결할 준비가 되었습니다. 이렇게 하면 데이터베이스에서 쿼리를 가져와 삽입할 수 있습니다.
데이터베이스 커넥터 초기화
먼저 루트 폴더에 db.py 파일을 만들고 아래 코드를 추가합니다.
#db.py import os import pymysql from flask import jsonify db_user = os.environ.get('CLOUD_SQL_USERNAME') db_password = os.environ.get('CLOUD_SQL_PASSWORD') db_name = os.environ.get('CLOUD_SQL_DATABASE_NAME') db_connection_name = os.environ.get('CLOUD_SQL_CONNECTION_NAME') def open_connection(): unix_socket = '/cloudsql/{}'.format(db_connection_name) try: if os.environ.get('GAE_ENV') == 'standard': conn = pymysql.connect(user=db_user, password=db_password, unix_socket=unix_socket, db=db_name, cursorclass=pymysql.cursors.DictCursor ) except pymysql.MySQLError as e: print(e) return conn def get_songs(): conn = open_connection() with conn.cursor() as cursor: result = cursor.execute('SELECT * FROM songs;') songs = cursor.fetchall() if result > 0: got_songs = jsonify(songs) else: got_songs = 'No Songs in DB' conn.close() return got_songs def add_songs(song): conn = open_connection() with conn.cursor() as cursor: cursor.execute('INSERT INTO songs (title, artist, genre) VALUES(%s, %s, %s)', (song["title"], song["artist"], song["genre"])) conn.commit() conn.close()여기에서 몇 가지 작업을 수행했습니다.
먼저 os.environ.get 메서드를 사용하여 app.yaml 파일에서 데이터베이스 자격 증명을 검색했습니다. App Engine은 app.yaml 에 정의된 환경 변수를 앱에서 사용할 수 있도록 할 수 있습니다.
두 번째로 open_connection 함수를 만들었습니다. 자격 증명을 사용하여 MySQL 데이터베이스에 연결합니다.
세 번째로 get_songs 및 add_songs 라는 두 가지 기능을 추가했습니다. 첫 번째는 open_connection 함수를 호출하여 데이터베이스에 대한 연결을 시작합니다. 그런 다음 모든 행에 대해 songs 테이블을 쿼리하고 비어 있으면 "DB에 노래 없음"을 반환합니다. add_songs 함수는 새 레코드를 songs 테이블에 삽입합니다.
마지막으로 우리가 시작한 main.py 파일로 돌아갑니다. 이제 이전처럼 객체에서 노래를 가져오는 대신 add_songs get_songs 를 호출하여 데이터베이스에서 레코드를 검색합니다.
main.py 를 리팩토링합시다.
#main.py from flask import Flask, jsonify, request from db import get_songs, add_songs app = Flask(__name__) @app.route('/', methods=['POST', 'GET']) def songs(): if request.method == 'POST': if not request.is_json: return jsonify({"msg": "Missing JSON in request"}), 400 add_songs(request.get_json()) return 'Song Added' return get_songs() if __name__ == '__main__': app.run() get_songs 및 add_songs 함수를 가져와서 songs() 보기 함수에서 호출했습니다. post 요청을 하는 경우 add_songs 함수를 호출하고 get 요청을 하는 경우 get_songs 함수를 호출합니다.
그리고 우리의 앱이 완성되었습니다.
다음은 requirements.txt 파일을 추가하는 것입니다. 이 파일에는 앱을 실행하는 데 필요한 패키지 목록이 포함되어 있습니다. App Engine은 이 파일을 확인하고 나열된 패키지를 설치합니다.
pip freeze | grep "Flask\|PyMySQL" > requirements.txt 이 줄은 앱에 사용 중인 두 개의 패키지(Flask 및 PyMySQL)를 가져오고, requirements.txt 파일을 만들고, 패키지와 해당 버전을 파일에 추가합니다.
이 시점에서 db.py , app.yaml 및 requirements.txt 의 세 가지 새 파일을 추가했습니다.
Google App Engine에 배포
다음 명령을 실행하여 앱을 배포합니다.
gcloud app deploy문제가 없으면 콘솔에서 다음을 출력합니다.
이제 앱이 App Engine에서 실행되고 있습니다. 브라우저에서 보려면 CLI에서 gcloud app browse 를 실행하세요.
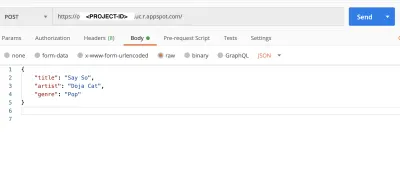
Postman을 시작하여 post 을 테스트하고 요청을 get 있습니다.
get 시연(큰 미리보기)우리 앱은 이제 Google 인프라에서 호스팅되며 서버리스 아키텍처의 모든 이점을 얻기 위해 구성을 조정할 수 있습니다. 앞으로 이 문서를 기반으로 서버리스 애플리케이션을 더욱 강력하게 만들 수 있습니다.
결론
App Engine 및 Cloud SQL과 같은 PaaS(Platform-as-a-Service) 인프라를 사용하면 기본적으로 인프라 수준을 추상화하고 더 빠르게 구축할 수 있습니다. 개발자로서 우리는 구성, 백업 및 복원, 운영 체제, 자동 크기 조정, 방화벽, 트래픽 마이그레이션 등에 대해 걱정할 필요가 없습니다. 그러나 기본 구성을 제어해야 하는 경우 맞춤형 서비스를 사용하는 것이 더 나을 수 있습니다.
참고문헌
- "파이썬 다운로드"
- "venv — 가상 환경 생성", Python(문서)
- "우체부 다운로드"
- "클라우드 SQL", 구글 클라우드
- 구글 클라우드
- "구글 클라우드 프리 티어", 구글 클라우드
- "프로젝트 생성 및 관리", Google Cloud
- "VPC 개요"(가상 사설 클라우드), Google Cloud
- "App Engine", Google Cloud
- "빠른 시작"(Google Cloud SDK 다운로드), Google Cloud
- PyMySQL 문서