
Scikit을 사용한 선형 회귀 가이드 [예제 포함]
게시 됨: 2021-06-18지도 학습 알고리즘은 일반적으로 연속 및 이산 출력을 예측하는 회귀 및 분류의 두 가지 유형이 있습니다.
다음 기사에서는 Python의 가장 인기 있는 기계 학습 라이브러리 중 하나인 Scikit-learn 라이브러리를 사용한 선형 회귀 및 구현에 대해 설명합니다. 기계 학습 및 통계 모델을 위한 도구는 분류, 회귀, 클러스터링 및 차원 축소를 위한 Python 라이브러리에서 사용할 수 있습니다. 파이썬 프로그래밍 언어로 작성된 이 라이브러리는 NumPy, SciPy 및 Matplotlib 파이썬 라이브러리를 기반으로 합니다.
목차
선형 회귀
선형 회귀는 지도 학습 방법에서 회귀 작업을 수행합니다. 독립변수를 기반으로 목표값을 예측합니다. 이 방법은 주로 변수 간의 관계를 예측하고 식별하는 데 사용됩니다.
대수학에서 선형성이라는 용어는 변수 간의 선형 관계를 의미합니다. 2차원 공간에서 변수 사이에 직선이 추론됩니다.
선이 X축의 독립변수와 Y축의 종속변수 사이의 플롯이면 데이터 포인트에 가장 잘 맞는 선형 회귀를 통해 직선을 이룹니다.
직선의 방정식은 다음과 같습니다.

Y = mx + b
여기서, b= 절편
m = 선의 기울기
따라서 선형 회귀를 통해
- 절편과 기울기에 대한 최적의 값은 2차원에서 결정됩니다.
- x 및 y 변수는 데이터 기능이므로 변경되지 않고 그대로 유지됩니다.
- 절편과 기울기 값만 제어할 수 있습니다.
- 기울기와 절편 값을 기반으로 하는 여러 직선이 존재할 수 있지만 선형 회귀 알고리즘을 통해 여러 직선이 데이터 포인트에 맞춰지고 오류가 가장 적은 라인이 반환됩니다.
Python을 사용한 선형 회귀
파이썬에서 선형 회귀를 구현하려면 해당 기능 및 클래스와 함께 적절한 패키지를 적용해야 합니다. Python의 NumPy 패키지는 오픈 소스이며 단일 및 다차원 배열 모두에서 배열에 대한 여러 작업을 허용합니다.
파이썬에서 널리 사용되는 또 다른 라이브러리는 기계 학습 문제에 사용되는 Scikit-learn입니다.
Scikit-learnN
Scikit-learn 라이브러리는 지도 및 비지도 학습을 기반으로 하는 개발자 알고리즘을 제공합니다. Python의 오픈 소스 라이브러리는 기계 학습 작업을 위해 설계되었습니다.
데이터 과학자는 scikit-learn을 사용하여 데이터를 가져오고, 전처리하고, 플롯하고, 데이터를 예측할 수 있습니다.
David Cournapeau는 2007년에 scikit-learn을 처음 개발했으며 라이브러리는 수십 년 동안 성장해 왔습니다.
scikit-learn에서 제공하는 도구는 다음과 같습니다.
- 회귀: 로지스틱 회귀 및 선형 회귀 포함
- 분류: K-Nearest Neighbors 방법 포함
- 모델 선택
- 클러스터링: K-Means++ 및 K-Means 모두 포함
- 전처리
라이브러리의 장점은 다음과 같습니다.
- 라이브러리의 학습 및 구현이 쉽습니다.
- 오픈 소스 라이브러리이므로 무료입니다.
- 머신 러닝 측면은 딥 러닝을 포함하여 은폐될 수 있습니다.
- 강력하고 다재다능한 패키지입니다.
- 라이브러리에는 자세한 문서가 있습니다.
- 머신 러닝에 가장 많이 사용되는 툴킷 중 하나입니다.
scikit-learn 가져오기
scikit-learn은 먼저 pip 또는 conda를 통해 설치해야 합니다.
- 요구 사항: NumPy 및 Scipy 라이브러리가 설치된 64비트 버전의 Python 3. 또한 데이터 플롯 시각화를 위해서는 matplotlib가 필요합니다.
설치 명령: pip install -U scikit-learn
그런 다음 설치가 완료되었는지 확인하십시오.
Numpy, Scipy 및 matplotlib 설치
설치는 다음을 통해 확인할 수 있습니다.
원천
Scikit-learn을 통한 선형 회귀
scikit-learn 패키지를 통한 선형 회귀 구현에는 다음 단계가 포함됩니다.
- 필요한 패키지와 클래스를 가져와야 합니다.
- 데이터는 작업을 수행하고 적절한 변환을 수행하는 데 필요합니다.
- 회귀 모델을 생성하고 기존 데이터에 맞춰야 합니다.
- 모델 피팅 데이터를 확인하여 생성된 모델이 만족스러운지 분석합니다.
- 예측은 모델의 적용을 통해 이루어집니다.
NumPy 패키지와 LinearRegression 클래스는 sklearn.linear_model에서 가져와야 합니다.

원천
sklearn 선형 회귀 에 필요한 기능 은 모두 최종적으로 선형 회귀를 구현하기 위해 존재합니다. sklearn.linear_model.LinearRegression 클래스는 회귀 분석( 선형 및 다항식 모두)을 수행하고 예측을 수행하는 데 사용됩니다.
모든 기계 학습 알고리즘 및 scikit 학습 선형 회귀 의 경우 먼저 데이터 세트를 가져와야 합니다. 데이터를 가져오기 위해 Scikit-learn에서 세 가지 옵션을 사용할 수 있습니다.
- 홍채 분류와 같은 데이터 세트 또는 보스턴 주택 가격에 대한 회귀 세트.
- Scikit-learn의 사전 정의된 기능을 통해 실제 세계의 데이터 세트를 인터넷에서 직접 다운로드할 수 있습니다.
- Scikit-learn 데이터 생성기를 통해 특정 패턴과 일치하도록 데이터 세트를 무작위로 생성할 수 있습니다.
어떤 옵션을 선택하든 모듈 데이터 세트를 가져와야 합니다.

sklearn.datasets 를 데이터 세트로 가져오기
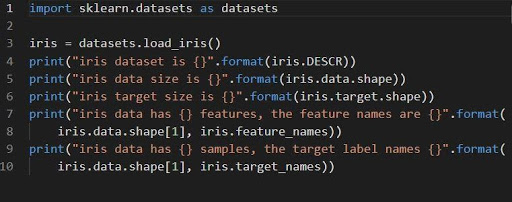
1. 홍채의 분류 집합
홍채 = 데이터 세트.load_iris()
데이터 세트 홍채는 n_samples * n_features의 2D 배열 데이터 필드로 저장됩니다 . 가져오기는 사전의 개체로 수행됩니다. 여기에는 메타데이터와 함께 필요한 모든 데이터가 포함됩니다.
DESCR, shape 및 _names 함수를 사용하여 데이터의 설명과 형식을 얻을 수 있습니다. 기능 결과의 인쇄는 홍채 데이터셋에서 작업하는 동안 필요할 수 있는 데이터셋의 정보를 표시합니다.
다음 코드는 홍채 데이터 세트의 정보를 로드합니다.
원천
2. 회귀 데이터 생성
내장 데이터에 대한 요구 사항이 없으면 선택할 수 있는 분포를 통해 데이터를 생성할 수 있습니다.
정보 기능 1개와 기능 1개로 구성된 회귀 데이터 생성.
X, Y = datasets.make_regression(n_features=1, n_informative=1)
생성된 데이터는 개체 x 및 y가 있는 2D 데이터세트에 저장됩니다. 생성된 데이터의 특성은 make_regression 함수의 매개변수를 변경하여 변경할 수 있습니다.
이 예에서는 정보 기능 및 기능 의 매개 변수 가 기본값인 10에서 1로 변경됩니다.
고려되는 다른 매개 변수는 추적되는 대상 및 샘플 변수의 수가 제어되는 샘플 및 대상 입니다.
- ML 알고리즘에 유용한 정보를 제공하는 기능을 정보 기능이라고 하고 도움이 되지 않는 기능을 정보 제공 기능이라고 합니다.
3. 데이터 플로팅
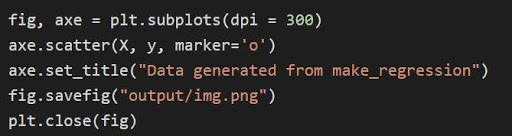
데이터는 matplotlib 라이브러리를 사용하여 플롯됩니다. 먼저 matplotlib를 가져와야 합니다.
matplotlib.pyplot을 plt로 가져오기
위의 그래프는 코드를 통해 matplotlib를 통해 플롯됩니다.
원천
위의 코드에서:
- 튜플 변수는 압축을 풀고 코드의 1행에 별도의 변수로 저장됩니다. 따라서 별도의 속성을 조작하고 저장할 수 있습니다.
- 데이터 세트 x, y는 라인 2를 통해 산점도를 생성하는 데 사용됩니다. matplotlib에서 마커 매개변수를 사용할 수 있게 되면 데이터 포인트를 점(o)으로 표시하여 시각적 효과가 향상됩니다.
- 생성된 플롯의 제목은 3행을 통해 설정됩니다.
- Figure를 .png 이미지 파일로 저장하면 현재 Figure가 닫힙니다.
위의 코드를 통해 생성된 회귀 플롯은
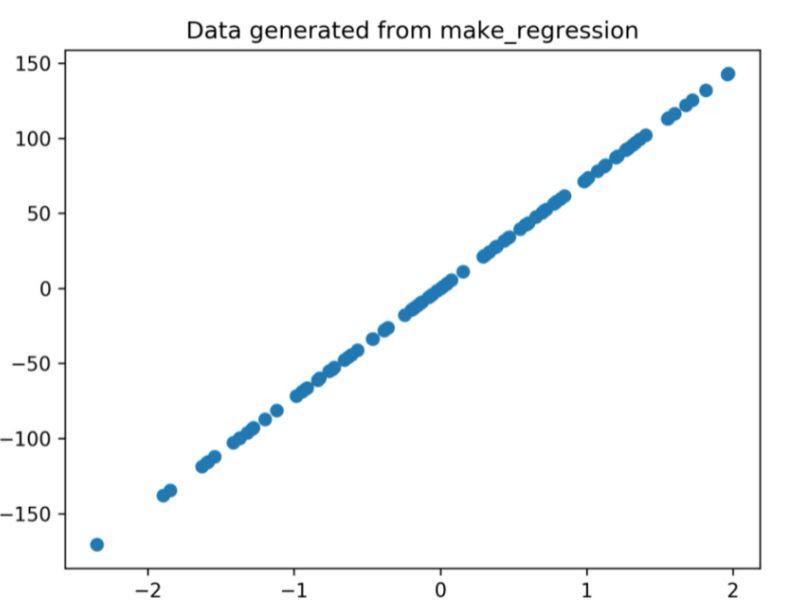
그림 1: 위의 코드에서 생성된 회귀 플롯.
4. 선형 회귀 알고리즘 구현
Boston 주택 가격의 샘플 데이터를 사용하여 Scikit-learn 선형 회귀 알고리즘 을 다음 예제에서 구현합니다. 다른 ML 알고리즘과 마찬가지로 데이터 세트를 가져온 다음 이전 데이터를 사용하여 훈련합니다.
선형 회귀 방법은 수치적 양과 그 변수 간의 관계를 출력 값에 대한 관계를 현실에 가치가 있다는 의미로 예측하는 예측 모델이기 때문에 기업에서 사용합니다.
이전 데이터의 로그가 있는 경우 패턴이 계속되는 경우 미래에 일어날 일의 미래 결과를 예측할 수 있으므로 모델을 가장 잘 적용할 수 있습니다.
수학적으로 데이터 포인트와 예측 값 사이에 존재하는 모든 잔차의 합을 최소화하기 위해 데이터를 맞출 수 있습니다.
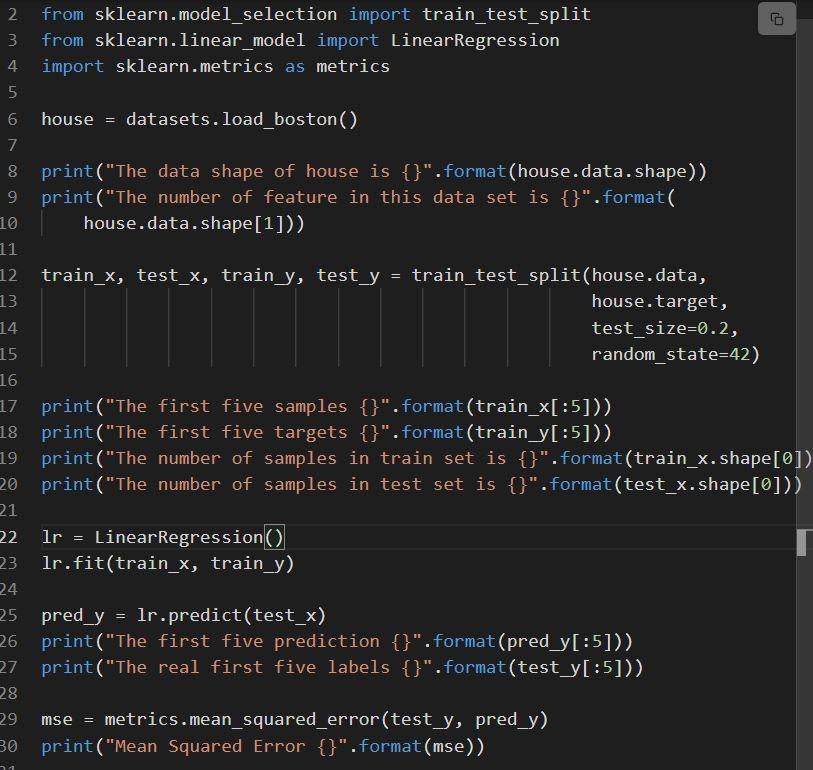
다음 스니펫은 sklearn 선형 회귀의 구현을 보여줍니다.
원천
코드는 다음과 같이 설명됩니다.
- 6행은 load_boston이라는 데이터 세트를 로드합니다.
- 데이터 세트는 12행에서 분할됩니다. 즉, 데이터가 80%인 훈련 세트와 데이터가 20%인 테스트 세트가 있습니다.
- 23행에서 선형 회귀 모델을 생성한 다음 에서 훈련합니다.
- 모델의 성능은 mean_squared_error를 호출하여 linen 29에서 평가됩니다.
sklearn 선형 회귀 플롯은 다음과 같습니다.
보스턴 주택 가격 표본 데이터의 선형 회귀 모형
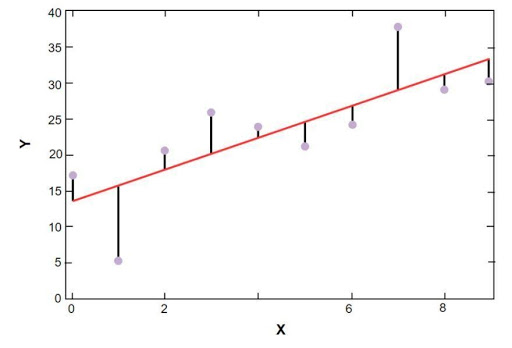
원천
위 그림에서 빨간선은 보스턴 주택가격의 표본데이터에 대해 풀린 선형모형을 나타낸다. 파란색 점은 원본 데이터를 나타내고 빨간색 선과 파란색 점 사이의 거리는 잔차의 합을 나타냅니다. scikit-learn 선형 회귀 모델 의 목표는 잔차의 합을 줄이는 것입니다.
결론
이 기사에서는 scikit-learn이라는 오픈 소스 Python 패키지를 사용하여 선형 회귀 및 구현에 대해 설명했습니다. 이제 이 패키지를 통해 선형 회귀를 구현하는 방법에 대한 개념을 얻을 수 있습니다. 데이터 분석을 위해 라이브러리를 사용하는 방법을 배우는 것은 가치가 있습니다.
기계 학습 및 AI 관련 문제에서 파이썬 패키지 구현과 같이 주제를 더 탐구하는 데 관심이 있다면 upGrad 에서 제공하는 기계 학습 및 AI의 과학 석사 과정을 확인할 수 있습니다. 21세에서 45세 사이의 초급 전문가를 대상으로 하는 이 과정은 650시간 이상의 온라인 교육, 25개 이상의 사례 연구 및 과제를 통해 기계 학습 학생들을 교육하는 것을 목표로 합니다. LJMU 에서 인증한 이 과정은 완벽한 안내와 취업 지원을 제공합니다. 질문이나 질문이 있는 경우 메시지를 남겨주세요. 기꺼이 연락드리겠습니다.