
データマイニングのディシジョンツリーとは何ですか? タイプ、実際の例とアプリケーション
公開: 2021-06-15目次
データマイニングの概要
多くの場合、データは、有用な情報に変換するために効果的に処理する必要がある生データとして存在します。 結果の予測は、多くの場合、データ内のパターン、異常、または相関関係を見つけるプロセスに依存します。 このプロセスは「データベースでの知識発見」と呼ばれていました。
「データマイニング」という用語が作られたのは1990年代だけでした。 データマイニングは、統計、人工知能、機械学習の3つの分野で設立されました。 自動化されたデータマイニングは、分析のプロセスを退屈なアプローチからより高速なアプローチにシフトしました。 データマイニングにより、ユーザーは次のことが可能になります。
- ノイズの多い混沌としたデータをすべて削除する
- 関連するデータを理解し、有用な情報の予測に使用します。
- 情報に基づいた意思決定を予測するプロセスが加速されます。
データマイニングは、分類が必要な情報の隠れたパターンを識別するプロセスと呼ばれることもあります。 そうして初めて、データを有用なデータに変換できます。 有用なデータは、データウェアハウス、データマイニングアルゴリズム、意思決定のためのデータ分析に提供できます。
データマイニングの決定木
データマイニング手法の一種であるデータマイニングの決定木は、データ分類のモデルを構築します。 モデルはツリー構造の形式で構築されているため、監視された形式の学習に属します。 分類モデル以外に、意思決定プロセスを支援するクラスラベルまたは値を予測するための回帰モデルを構築するために決定木が使用されます。 性別、年齢などの数値データとカテゴリデータの両方を決定木で使用できます。
デシジョンツリーの構造
デシジョンツリーの構造は、ルートノード、ブランチ、およびリーフノードで構成されます。 分岐ノードはツリーの結果であり、内部ノードは属性のテストを表します。 リーフノードはクラスラベルを表します。
デシジョンツリーの動作
1.決定木は、離散変数と連続変数の両方の教師あり学習アプローチの下で機能します。 データセットは、データセットの最も重要な属性に基づいてサブセットに分割されます。 属性の識別と分割は、アルゴリズムを介して行われます。
2.決定木の構造は、重要な予測ノードであるルートノードで構成されます。 分割のプロセスは、ツリーのサブノードである決定ノードから発生します。 それ以上分割されないノードは、リーフノードまたはターミナルノードと呼ばれます。
3.データセットは、トップダウンのアプローチに従って、均質な領域と重複しない領域に分割されます。 最上層は、単一の場所での観測を提供し、その後、ブランチに分割されます。 このプロセスは、将来のノードではなく現在のノードのみに焦点を当てているため、「欲張りアプローチ」と呼ばれます。
4.停止基準に到達するまで、および到達しない限り、デシジョンツリーは実行を継続します。
5.決定木の構築に伴い、多くのノイズと外れ値が生成されます。 これらの外れ値とノイズの多いデータを削除するために、「ツリーの剪定」の方法が適用されます。 したがって、モデルの精度が向上します。
6.モデルの精度は、テストタプルとクラスラベルで構成されるテストセットでチェックされます。 正確なモデルは、モデルによる分類テストセットのタプルとクラスのパーセンテージに基づいて定義されます。
図1 :剪定されていないツリーと剪定されたツリーの例
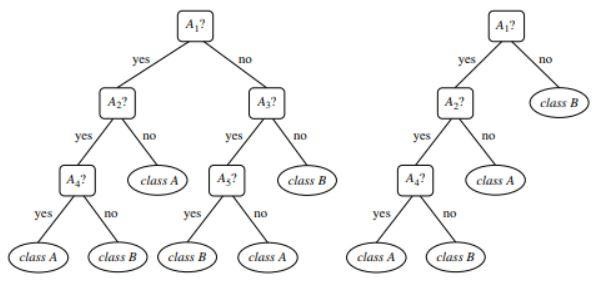
ソース
デシジョンツリーの種類
決定木は、木のような構造に基づく分類と回帰のモデルの開発につながります。 データは小さなサブセットに分割されます。 デシジョンツリーの結果は、デシジョンノードとリーフノードを持つツリーになります。 2種類の決定木について以下に説明します。
1.分類
分類には、重要なクラスラベルを記述するモデルの構築が含まれます。 それらは、機械学習とパターン認識の分野で適用されます。 分類モデルによる機械学習の決定木は、不正の検出、医療診断などにつながります。分類モデルの2つのステップのプロセスには、次のものが含まれます。
- 学習:トレーニングデータに基づく分類モデルが構築されます。
- 分類:モデルの精度がチェックされ、新しいデータの分類に使用されます。 クラスラベルは、「yes」や「no」などの個別の値の形式です。
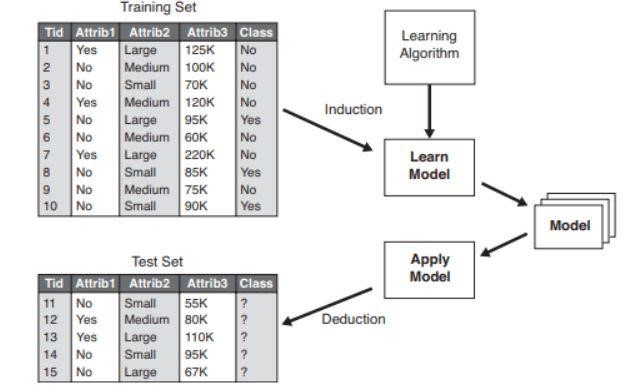
図2 :分類モデルの例。
ソース
2.回帰
回帰モデルは、データの回帰分析、つまり数値属性の予測に使用されます。 これらは連続値とも呼ばれます。 したがって、クラスラベルを予測する代わりに、回帰モデルは連続値を予測します。
使用されたアルゴリズムのリスト
「ID3」として知られる決定木アルゴリズムは、1980年にJ.RossQuinlanという名前の機械研究者によって開発されました。 このアルゴリズムは、彼が開発したC4.5のような他のアルゴリズムに引き継がれました。 両方のアルゴリズムは欲張りアプローチを適用しました。 アルゴリズムC4.5はバックトラッキングを使用せず、ツリーはトップダウンの再帰分割統治法で構築されます。 アルゴリズムは、ツリーが構築されるときに小さなサブセットに分割されるクラスラベルを持つトレーニングデータセットを使用しました。
- 最初に、属性リスト、属性選択方法、データパーティションの3つのパラメータが選択されます。 トレーニングセットの属性は、属性リストに記述されています。
- アトリビューション選択方法には、タプル間の識別に最適な属性を選択する方法が含まれます。
- ツリー構造は、属性の選択方法によって異なります。
- ツリーの構築は、単一のノードから始まります。
- タプルの分割は、異なるクラスラベルがタプルで表されている場合に発生します。 これは、木の枝の形成につながります。
- 分割の方法によって、データパーティションに選択する属性が決まります。 この方法に基づいて、テストの結果に基づいてノードからブランチが成長します。
- 分割と分割の方法は再帰的に実行され、最終的にトレーニングデータセットタプルの決定木になります。
- ツリー形成のプロセスは、残ったタプルがそれ以上分割できないまで、そしてそれを除いて継続します。
- アルゴリズムの複雑さは次のように表されます。
n * | D | *ログ|D|
ここで、nはトレーニングデータセットDおよび|D|の属性の数です。 タプルの数です。
ソース
図3:離散値分割
デシジョンツリーで使用されるアルゴリズムのリストは次のとおりです。
ID3
データセットS全体は、決定木を形成する際のルートノードと見なされます。 次に、すべての属性に対して反復が実行され、データがフラグメントに分割されます。 アルゴリズムは、繰り返される属性の前に取得されなかった属性をチェックして取得します。 ID3アルゴリズムでデータを分割することは時間がかかり、データをオーバーフィットするため、理想的なアルゴリズムではありません。
C4.5
データはサンプルとして分類されるため、これはアルゴリズムの高度な形式です。 ID3とは異なり、連続値と離散値の両方を効率的に処理できます。 不要な枝を取り除く剪定の方法があります。
カート
分類タスクと回帰タスクの両方をアルゴリズムで実行できます。 ID3やC4.5とは異なり、決定ポイントはジニ係数を考慮して作成されます。 貪欲アルゴリズムは、コスト関数を減らすことを目的とした分割方法に適用されます。 分類タスクでは、葉のノードの純度を示すためのコスト関数としてジニ係数が使用されます。 回帰タスクでは、残差平方和がコスト関数として使用され、最良の予測が見つかります。
チャイド
名前が示すように、これはカイ二乗自動相互作用検出器の略で、あらゆるタイプの変数を処理するプロセスです。 それらは、名義変数、順序変数、または連続変数である可能性があります。 回帰ツリーはF検定を使用し、カイ2乗検定は分類モデルで使用されます。
火星
多変量適応回帰スプラインの略です。 このアルゴリズムは、データがほとんど非線形である回帰タスクで特別に実装されます。
貪欲な再帰的バイナリ分割
バイナリ分割方式が発生し、2つのブランチが生成されます。 タプルの分割は、分割コスト関数の計算を使用して実行されます。 最も低いコスト分割が選択され、他のタプルのコスト関数を計算するためにプロセスが再帰的に実行されます。
実世界の例を使用した決定木
与えられたデータからローンの適格性プロセスを予測します。
ステップ1:データのロード

null値は、ドロップオフするか、いくつかの値で埋めることができます。 元のデータセットの形状は(614,13)であり、null値を削除した後の新しいデータセットは(480,13)です。
ステップ2:データセットを確認します。

ステップ3:データをトレーニングセットとテストセットに分割します。
ステップ4:モデルを作成し、列車セットを適合させる

視覚化する前に、いくつかの計算を行う必要があります。
計算1:データセット全体のエントロピーを計算します。

計算2:すべての列のエントロピーとゲインを見つけます。
- 性別列
- 条件1:すべての男性が含まれるデータセット、そして
p = 278、n = 116、p + n = 489
エントロピー(G =男性)= 0.87
- 条件2:すべての女性が含まれるデータセット、そして
p = 54、n = 32、p + n = 86
エントロピー(G =女性)= 0.95
- 性別列の平均情報

- 既婚コラム
- 条件1:既婚=はい(1)
この分割では、データセット全体が既婚ステータスになりますはい
p = 227、n = 84、p + n = 311
E(既婚=はい)= 0.84
- 条件2:既婚= No(0)
この分割では、既婚ステータスのデータセット全体が
p = 105、n = 64、p + n = 169
E(既婚=いいえ)= 0.957
- 既婚欄の平均情報は
- 教育コラム
- 条件1:教育=大学院(1)
p = 271、n = 112、p + n = 383
E(教育=大学院)= 0.87
- 条件2:教育=卒業生ではない(0)
p = 61、n = 36、p + n = 97
E(教育=卒業生ではない)= 0.95
- 教育の平均情報列=0.886
ゲイン=0.01
4)自営業のコラム
- 条件1:自営業=はい(1)
p = 43、n = 23、p + n = 66
E(自営業=はい)= 0.93
- 条件2:自営業= No(0)
p = 289、n = 125、p + n = 414
E(自営業=いいえ)= 0.88
- 教育における自営業の平均情報列=0.886
ゲイン=0.01
- クレジットスコア列:列には0と1の値があります。
- 条件1:クレジットスコア= 1
p = 325、n = 85、p + n = 410
E(クレジットスコア= 1)= 0.73
- 条件2:クレジットスコア= 0
p = 63、n = 7、p + n = 70
E(クレジットスコア= 0)= 0.46
- クレジットスコア列の平均情報=0.69
ゲイン=0.2
すべてのゲイン値を比較します

クレジットスコアが最も高くなります。 したがって、ルートノードとして使用されます。
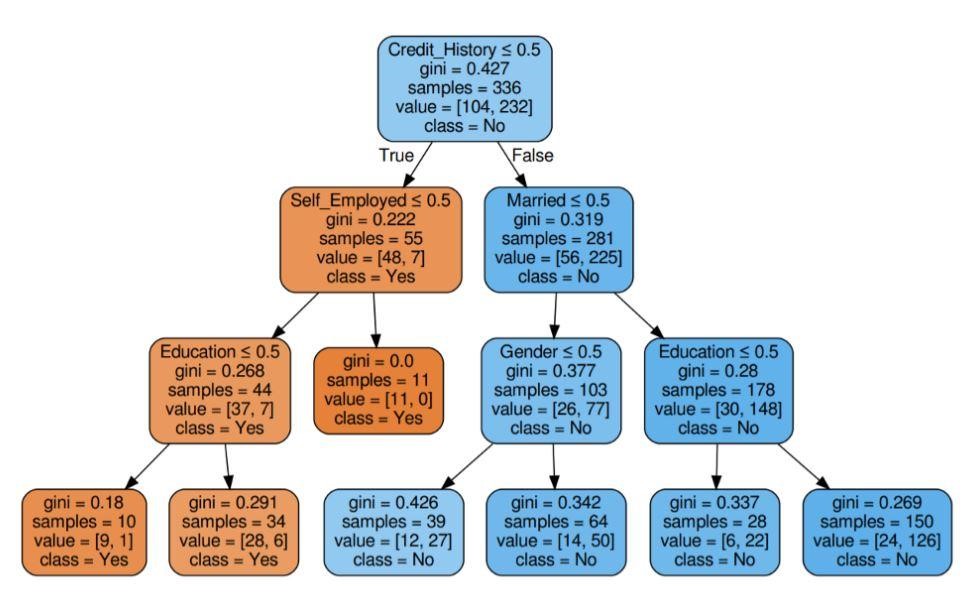
ステップ5:ディシジョンツリーを視覚化する

図5:基準ジニを使用した決定木
 ソース
ソース
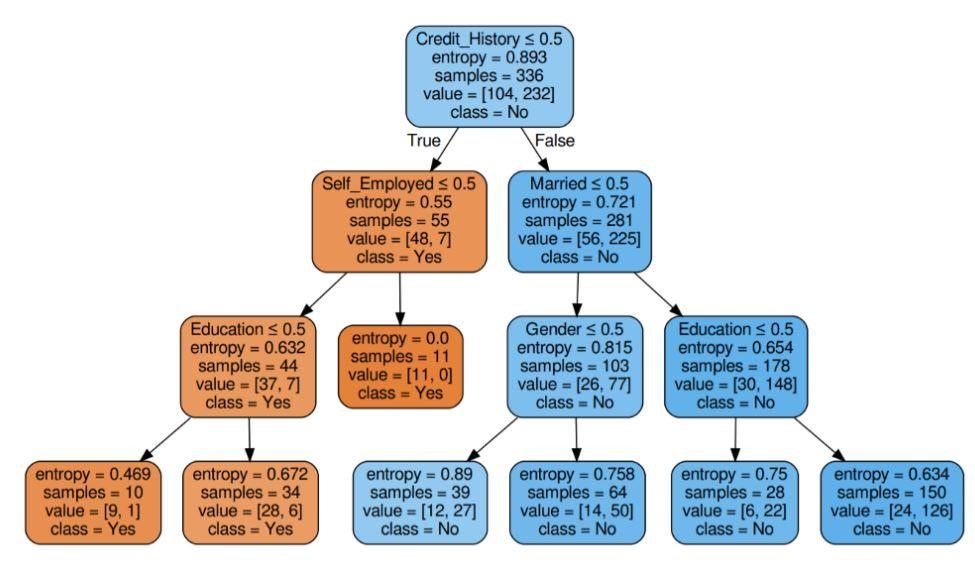
図6:基準エントロピーを使用した決定木
ソース
ステップ6:モデルのスコアを確認します
ほぼ80%の精度が得られました。
アプリケーションのリスト
デシジョンツリーは、主に情報の専門家が分析調査を行うために使用します。 それらは、ビジネス目的で問題を分析または予測するために広く使用される可能性があります。 デシジョンツリーの柔軟性により、それらを別の領域で使用できます。
1.ヘルスケア
デシジョンツリーを使用すると、患者が年齢、体重、性別などの条件で特定の病気にかかっているかどうかを予測できます。その他の予測には、組成、製造期間などの要素を考慮した薬の効果の決定が含まれます。
2.銀行セクター
デシジョンツリーは、個人の財政状態、給与、家族などを考慮して、ローンの対象となるかどうかを予測するのに役立ちます。また、クレジットカードの詐欺、ローンのデフォルトなどを特定することもできます。
3.教育セクター
メリットスコア、出席などに基づいた学生の候補リストは、決定木の助けを借りて決定することができます。
利点のリスト
- 意思決定モデルの解釈可能な結果は、上級管理職および利害関係者に表すことができます。
- デシジョンツリーモデルを構築する際、データの前処理、つまり正規化、スケーリングなどは必要ありません。
- 数値とカテゴリの両方のタイプのデータは、他のアルゴリズムよりも高い使用効率を示す決定木で処理できます。
- データに値がない場合、決定木のプロセスに影響を与えないため、柔軟なアルゴリズムになります。
次は何?
データマイニングの実践的な経験を積み、の専門家によるトレーニングを受けることに興味がある場合は、データサイエンスのupGradのエグゼクティブPGプログラムをチェックしてください。 このコースは、21〜45歳以内のすべての年齢層を対象としており、卒業時の最低資格基準は50%または同等の合格点です。 働く専門家なら誰でも、IIITバンガロアから認定されたこのエグゼクティブPGプログラムに参加できます。
データマイニングのディシジョンツリーには、非常に複雑なデータを処理する機能があります。 すべての決定木には、3つの重要なノードまたは部分があります。 以下でそれぞれについて説明しましょう。 デシジョンツリーの動作を理解したので、データマイニングでデシジョンツリーを使用することのいくつかの利点を見てみましょう。データマイニングのディシジョンツリーとは何ですか?
デシジョンツリーは、データマイニングでモデルを構築する方法です。 それは逆二分木として理解することができます。 これには、ルートノード、いくつかのブランチ、および最後のリーフノードが含まれます。
デシジョンツリーの各内部ノードは、属性に関する調査を意味します。 各部門は、その特定の研究または試験の結果を意味します。 そして最後に、各リーフノードはクラスタグを表します。
デシジョンツリーを構築する主な目的は、以前のデータの判断手順を使用して、特定のクラスを予測するために利用できる理想を作成することです。
ルートノードから始めて、ルート変数といくつかの関係を作り、それらの値に一致する除算を行います。 基本の選択に基づいて、後続のノードにジャンプします。 デシジョンツリーで使用される重要なノードにはどのようなものがありますか?
これらすべてのノードを接続すると、分割が行われます。 これらのノードと分割を無限に使用して、さまざまな困難を伴うツリーを形成できます。 デシジョンツリーを使用する利点は何ですか?
1.他の方法と比較すると、決定木は前処理中にデータをトレーニングするためにそれほど多くの計算を必要としません。
2.情報の安定化は、デシジョンツリーには含まれません。
3.また、情報のスケーリングも必要ありません。
4.データセットで一部の値が省略されている場合でも、これはツリーの構築に干渉しません。
5.これらのモデルは本能的に同一です。 説明のためにもストレスがありません。