
GoogleアシスタントとAmazonAlexaの音声スキルの作成
公開: 2022-03-10過去10年間で、会話型インターフェイスへの大きな変化がありました。 人々が「ピークスクリーン」に到達し、ほとんどのオペレーティングシステムに組み込まれているデジタルウェルビーイング機能を使用してデバイスの使用を縮小し始めると、
画面の疲労に対抗するために、音声アシスタントが市場に参入し、情報をすばやく取得するための好ましいオプションになりました。 よく繰り返される統計によると、2020年には検索の50%が音声で行われる予定です。また、採用が増えるにつれて、ツールベルトに「会話型インターフェース」と「音声アシスタント」を追加するのは開発者次第です。
インビジブルのデザイン
多くの人にとって、音声UI(VUI)プロジェクトに着手することは、Unknownに入るのと少し似ている可能性があります。 音声用に設計するときにWilliamMerrillが学んだ教訓について詳しく調べてください。 関連記事を読む→
会話型インターフェースとは何ですか?
会話型インターフェイス(CUIと略されることもあります)は、人間の言語のインターフェイスです。フロントエンド開発者が構築に慣れているグラフィックユーザーインターフェイスGUIよりも、一般の人々にとってより自然なインターフェイスになるようになっています。GUIには人間が必要です。インターフェイスの特定の構文(ボタン、スライダー、ドロップダウンなど)を学習します。
人間の言語を使用する際のこの重要な違いにより、CUIは人々にとってより自然になります。 それはほとんど知識を必要とせず、デバイスに理解の負担をかけます。
通常、CUIには、チャットボットと音声アシスタントの2つの形式があります。 自然言語処理(NLP)の進歩のおかげで、どちらも過去10年間で大幅な普及率を示しています。
音声専門用語を理解する

| キーワード | 意味 |
|---|---|
| スキル/アクション | 一連の目的を果たすことができる音声アプリケーション |
| 意図 | スキルが実行するための意図されたアクション、ユーザーが自分の言うことに応じてスキルに実行させたいこと。 |
| 発話 | ユーザーが言う、または発する文。 |
| ウェイクワード | 音声アシスタントのリスニングを開始するために使用される単語またはフレーズ。例:「Heygoogle」、「Alexa」、「HeySiri」 |
| 環境 | 発話内のコンテキスト情報。スキルが意図を実現するのに役立ちます。たとえば、「今日」、「今」、「家に帰ったとき」などです。 |
音声アシスタントとは何ですか?
音声アシスタントは、NLP(自然言語処理)が可能なソフトウェアです。 音声コマンドを受信し、音声形式で回答を返します。 近年、アシスタントとの関わり方の範囲は拡大し、進化していますが、テクノロジーの核心は自然言語の入力、多くの計算、自然言語の出力です。
もう少し詳細をお探しの方へ:
- このソフトウェアは、ユーザーから音声要求を受け取り、その音を言語の構成要素である音素に処理します。
- AI(具体的にはSpeech-To-Text)の魔法により、これらの音素は近似リクエストの文字列に変換されます。これは、ユーザー、リクエスト、セッションに関する追加情報も含むJSONファイル内に保持されます。
- 次に、JSONが処理され(通常はクラウドで)、リクエストのコンテキストと意図がわかります。
- 意図に基づいて、応答は、文字列またはSSMLのいずれかとして(後で詳しく説明します)、より大きなJSON応答内で返されます。
- 応答はAI(当然のことながら逆-Text-To-Speech)を使用して処理され、ユーザーに返されます。
そこにはたくさんのことが起こっていますが、そのほとんどは考え直す必要はありません。 ただし、プラットフォームごとにこれは異なります。もう少し理解が必要なのは、プラットフォームのニュアンスです。

音声対応デバイス
デバイスが音声アシスタントを焼き付けることができるための要件はかなり低いです。 マイク、インターネット接続、スピーカーが必要です。 NestMiniやEchoDotなどのスマートスピーカーは、この種のローファイ音声制御を提供します。
次のランクは音声+画面です。これは「マルチモーダル」デバイスとして知られており(これらについては後で詳しく説明します)、NestHubやEchoShowなどのデバイスです。 スマートフォンにはこの機能があるため、マルチモーダル音声対応デバイスの一種と見なすこともできます。
音声スキル
まず、プラットフォームごとに「音声スキル」の名前が異なります。Amazonにはスキルがあります。これは、普遍的に理解されている用語として使用します。 Googleは「アクション」を選択し、Samsungは「カプセル」を選択します。
各プラットフォームには、時間、天気、スポーツゲームなど、独自のスキルが組み込まれています。 開発者が作成した(サードパーティの)スキルは、特定のフレーズを使用して呼び出すことができます。または、プラットフォームが気に入った場合は、キーフレーズを使用せずに暗黙的に呼び出すことができます。
明示的な呼び出し:「ねぇGoogle、<アプリ名>に話しかけてください。」
どのスキルが求められているかが明確に示されています。
暗黙の呼び出し:「ねぇGoogle、今日の天気はどう?」
これは、リクエストのコンテキストによって、ユーザーが必要とするサービスを意味します。
どんな音声助手がいますか?
西部市場では、音声アシスタントは非常に3頭の競馬です。 Apple、Google、Amazonは、アシスタントに対するアプローチが大きく異なるため、さまざまなタイプの開発者や顧客にアピールしています。
AppleのSiri
デバイス名:「Siri」
ウェイクフレーズ:「HeySiri」
Siriには3億7500万人以上のアクティブユーザーがいますが、簡潔にするために、Siriについてはあまり詳しく説明しません。 これは世界的に広く採用されており、ほとんどのAppleデバイスに組み込まれている可能性がありますが、開発者はAppleのプラットフォームの1つにアプリがあり、迅速に記述されている必要があります(他のプラットフォームは、誰もが好きなJavascriptで記述できます)。 あなたが彼らのアプリの提供を拡大したいアプリ開発者でない限り、彼らが彼らのプラットフォームを開くまで、あなたは現在アップルをスキップすることができます。
Googleアシスタント
デバイス名:「GoogleHome、Nest」
ウェイクフレーズ:「ねぇGoogle」
Googleはビッグ3の中で最も多くのデバイスを持っており、世界中で10億を超えています。これは主に、専用のスマートスピーカーに関して、Googleアシスタントが組み込まれているAndroidデバイスの数が少し少ないためです。 アシスタントを使用したGoogleの全体的な使命はユーザーを喜ばせることであり、ユーザーは常に軽量で直感的なインターフェースを提供することに長けています。
プラットフォームでの彼らの主な目的は、時間を使うことです—顧客の日常の一部になるという考えを持っています。 そのため、彼らは主に実用性、家族の楽しみ、そして楽しい経験に焦点を当てています。
Google向けに構築されたスキルは、主に家族向けの楽しみに焦点を当てたエンゲージメントピースやゲームである場合に最適です。 最近ゲーム用のキャンバスが追加されたことは、このアプローチの証です。 Googleプラットフォームはスキルの提出に対してはるかに厳格であるため、そのディレクトリははるかに小さくなっています。
アマゾンアレクサ
デバイス名:「AmazonFire、AmazonEcho」
ウェイクフレーズ:「アレクサ」
アマゾンは2019年に1億台のデバイスを超えました。これは主に、スマートスピーカーとスマートディスプレイ、および「ファイア」レンジまたはタブレットとストリーミングデバイスの販売によるものです。
アマゾン向けに構築されたスキルは、スキルの購入を目的とする傾向があります。 eコマース/サービスを拡張するためのプラットフォームを探している場合、またはサブスクリプションを提供している場合は、Amazonが最適です。 そうは言っても、ISPはAlexa Skillsの要件ではなく、あらゆる種類の使用をサポートし、提出に対してはるかにオープンです。
他人
SamsungのBixby、MicrosoftのCortana、人気のあるオープンソースの音声アシスタントMycroftなど、さらに多くの音声アシスタントがあります。 3つすべてに合理的な支持がありますが、Amazon、Google、Appleの3つのゴリアテスと比較するとまだ少数派です。
AmazonAlexaで構築
Amazons Ecosystem for voiceは、開発者がAlexaコンソール内ですべてのスキルを構築できるように進化したため、簡単な例として、その組み込み機能を使用します。
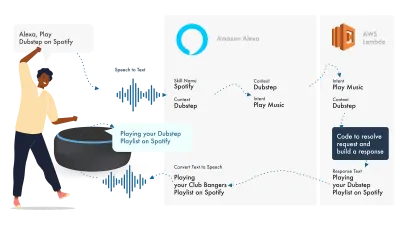
Alexaは自然言語処理を処理し、適切なインテントを見つけます。これは、ロジックを処理するためにLambda関数に渡されます。 これにより、会話ビット(SSML、テキスト、カードなど)がAlexaに返され、Alexaはそれらのビットをオーディオとビジュアルに変換してデバイスに表示します。
Amazonでの作業は、Alexa Developer Console内でスキルのすべての部分を作成できるため、比較的簡単です。 AWSまたはHTTPSエンドポイントを使用する柔軟性がありますが、単純なスキルの場合、開発コンソール内ですべてを実行するだけで十分です。
シンプルなAlexaスキルを構築しましょう
Amazon Alexaコンソールにアクセスし、アカウントがない場合はアカウントを作成して、ログインします。
[ Create Skillをクリックして、名前を付けます。
モデルとしてcustomを選択し、
バックエンドリソースとしてAlexa-Hosted (Node.js)を選択します。
プロビジョニングが完了すると、基本的なAlexaスキルが得られます。インテントが構築され、開始するためのバックエンドコードがいくつかあります。
インテントでHelloWorldIntentをクリックすると、いくつかのサンプル発話がすでに設定されているのがわかります。上部に新しい発話を追加しましょう。 私たちのスキルはhelloworldと呼ばれているので、サンプル発話としてHelloWorldを追加します。 アイデアは、このインテントをトリガーするためにユーザーが言う可能性のあるものをすべてキャプチャすることです。 これは、「Hi World」、「HowdyWorld」などです。
フルフィルメントJSで何が起こっているのですか?
では、コードは何をしているのでしょうか? デフォルトのコードは次のとおりです。
const HelloWorldIntentHandler = { canHandle(handlerInput) { return Alexa.getRequestType(handlerInput.requestEnvelope) === 'IntentRequest' && Alexa.getIntentName(handlerInput.requestEnvelope) === 'HelloWorldIntent'; }, handle(handlerInput) { const speakOutput = 'Hello World!'; return handlerInput.responseBuilder .speak(speakOutput) .getResponse(); } }; これはask-sdk-coreを利用しており、基本的にJSONを構築しています。 canHandleは、インテント、具体的には「HelloWorldIntent」を処理できることをaskに通知しています。 handleは入力を受け取り、応答を作成します。 これが生成するものは次のようになります。
{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }{ "body": { "version": "1.0", "response": { "outputSpeech": { "type": "SSML", "ssml": " Hello World! " }, "type": "_DEFAULT_RESPONSE" }, "sessionAttributes": {}, "userAgent": "ask-node/2.3.0 Node/v8.10.0" } }
そのspeakはjsonでssmlを出力することがわかります。これは、Alexaによって話されたときにユーザーに聞こえるものです。

Googleアシスタントの構築
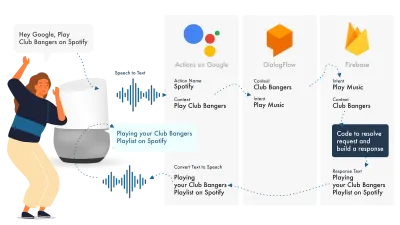
Googleでアクションを構築する最も簡単な方法は、AoGコンソールをDialogflowと組み合わせて使用することです。Firebaseを使用してスキルを拡張できますが、Amazon Alexaチュートリアルと同様に、物事をシンプルに保ちましょう。
Googleアシスタントは、NLPを処理するAoG、インテントを処理するDialogflow、リクエストを実行してAoGに返送されるレスポンスを生成するFirebaseの3つの主要部分を使用します。
Alexaと同様に、Dialogflowではプラットフォーム内で直接関数を構築できます。
Googleでアクションを作成しましょう
Googleのソリューションと同時に連携するプラットフォームは3つあり、3つの異なるコンソールからアクセスできるので、タブを押してください。
Dialogflowの設定
Dialogflowコンソールにログインすることから始めましょう。 ログインしたら、Dialogflowロゴのすぐ下にあるドロップダウンから新しいエージェントを作成します。
エージェントに名前を付け、[新しいGoogleプロジェクトを作成する]を選択した状態で[Googleプロジェクトのドロップダウン]を追加します。
作成ボタンをクリックして、魔法をかけましょう。エージェントの設定には少し時間がかかりますので、しばらくお待ちください。
Firebase機能の設定
これで、フルフィルメントロジックのプラグインを開始できます。
[フルフィルメント]タブに移動します。 チェックマークを付けてインラインエディタを有効にし、以下のJSスニペットを使用します。
index.js
'use strict'; // So that you have access to the dialogflow and conversation object const { dialogflow } = require('actions-on-google'); // So you have access to the request response stuff >> functions.https.onRequest(app) const functions = require('firebase-functions'); // Create an instance of dialogflow for your app const app = dialogflow({debug: true}); // Build an intent to be fulfilled by firebase, // the name is the name of the intent that dialogflow passes over app.intent('Default Welcome Intent', (conv) => { // Any extra logic goes here for the intent, before returning a response for firebase to deal with return conv.ask(`Welcome to a firebase fulfillment`); }); // Finally we export as dialogflowFirebaseFulfillment so the inline editor knows to use it exports.dialogflowFirebaseFulfillment = functions.https.onRequest(app);package.json
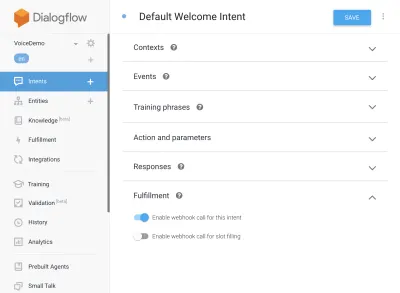
{ "name": "functions", "description": "Cloud Functions for Firebase", "scripts": { "lint": "eslint .", "serve": "firebase serve --only functions", "shell": "firebase functions:shell", "start": "npm run shell", "deploy": "firebase deploy --only functions", "logs": "firebase functions:log" }, "engines": { "node": "10" }, "dependencies": { "actions-on-google": "^2.12.0", "firebase-admin": "~7.0.0", "firebase-functions": "^3.3.0" }, "devDependencies": { "eslint": "^5.12.0", "eslint-plugin-promise": "^4.0.1", "firebase-functions-test": "^0.1.6" }, "private": true }次に、インテントに戻り、デフォルトのウェルカムインテントに移動し、フルフィルメントまでスクロールダウンします。JavaScriptでフルフィルメントしたいインテントがないか、[このインテントのWebhook呼び出しを有効にする]がオンになっていることを確認します。 [保存]をクリックします。
AoGの設定
現在、フィニッシュラインに近づいています。 [統合]タブに移動し、上部のGoogleアシスタントオプションで[統合設定]をクリックします。 これによりモーダルが開くので、[テスト]をクリックして、DialogflowをGoogleと統合し、Actions onGoogleのテストウィンドウを開きます。
テストウィンドウで、[テストアプリに話しかける]をクリックすると(これはすぐに変更されます)、出来上がりです。JavaScriptからのメッセージがGoogleアシスタントテストに表示されます。
上部の[開発]タブでアシスタントの名前を変更できます。
では、Fulfillment JSで何が起こっているのでしょうか?
まず、2つのnpmパッケージを使用しています。actions-on-googleは、AoGとDialogflowの両方に必要なすべてのフルフィルメントを提供します。次に、firebase-functionsには、firebaseのヘルパーが含まれています。
次に、すべてのインテントを含むオブジェクトである「アプリ」を作成します。
作成された各インテントは、Actions OnGoogleが送信する会話オブジェクトである「conv」を渡します。 convのコンテンツを使用して、ユーザーとの以前のやり取りに関する情報(IDやユーザーとのセッションに関する情報など)を検出できます。
'conv.askオブジェクト'を返します。これには、ユーザーへの戻りメッセージが含まれており、ユーザーが別のインテントで応答できるようになっています。 そこで会話を終了したい場合は、「conv.close」を使用して会話を終了できます。
最後に、サーバー側のリクエスト/レスポンスロジックを処理するFirebaseHTTPS関数ですべてをまとめます。
繰り返しますが、生成される応答を見ると、次のようになります。
{ "payload": { "google": { "expectUserResponse": true, "richResponse": { "items": [ { "simpleResponse": { "textToSpeech": "Welcome to a firebase fulfillment" } } ] } } } } conv.askのテキストがtextToSpeech領域に挿入されていることがわかります。 conv.closeを選択した場合、 expectUserResponseはfalseに設定され、メッセージが配信された後に会話が終了します。
サードパーティの音声ビルダー
アプリ業界と同じように、音声が勢いを増すにつれて、開発者の負荷を軽減するためにサードパーティのツールが登場し始め、開発者は1回のデプロイで2回のデプロイが可能になります。
JovoとVoiceflowは、特にAppleによるPullStringの買収以来、現在最も人気のある2つです。 プラットフォームごとに異なるレベルの抽象化が提供されるため、実際には、インターフェースがどれだけ単純化されているかによって異なります。
あなたのスキルを拡張する
基本的な「HelloWorld」スキルの構築に頭を悩ませたので、スキルに追加できるベルとホイッスルがたくさんあります。 これらは音声アシスタントのケーキの上にあるチェリーであり、ユーザーに多くの付加価値を提供し、繰り返しのカスタムと潜在的な商業的機会につながります。
SSML
SSMLはSpeechSynthesis Markup Languageの略で、HTMLと同様の構文で動作します。主な違いは、Webページのコンテンツではなく、音声応答を作成していることです。
用語としての「SSML」は少し誤解を招く可能性があり、音声合成以上のことができます。 声を並行して流すことができ、アンビエンスノイズ、スピーチコン(それ自体で聞く価値があり、有名なフレーズの絵文字を考える)、および音楽を含めることができます。
SSMLはいつ使用する必要がありますか?
SSMLは素晴らしいです。 これにより、ユーザーにとってはるかに魅力的なエクスペリエンスが実現しますが、オーディオ出力の柔軟性が低下することもあります。 より静的なスピーチ領域に使用することをお勧めします。 名前などに変数を使用できますが、SSMLジェネレーターを構築する予定がない限り、ほとんどのSSMLはかなり静的になります。
スキルの簡単なスピーチから始めて、それが完了したら、SSMLでより静的な領域を強化しますが、ベルやホイッスルに進む前にコアを取得します。 そうは言っても、最近のレポートによると、ユーザーの71%は、合成された声よりも人間の(実際の)声を好むので、そうする機能がある場合は、外に出てそれを実行してください。

スキル購入で
スキル内購入(またはISP)は、アプリ内購入の概念に似ています。 スキルは無料になる傾向がありますが、アプリ内で「プレミアム」コンテンツ/サブスクリプションの購入を許可するものもあります。これらは、ユーザーのエクスペリエンスを向上させたり、ゲームの新しいレベルのロックを解除したり、ペイウォールコンテンツへのアクセスを許可したりできます。
マルチモーダル
マルチモーダル応答は音声だけでなく、音声アシスタントをサポートするデバイスの補完的なビジュアルで音声アシスタントを実際に輝かせることができます。 マルチモーダルエクスペリエンスの定義ははるかに広く、基本的に複数の入力(キーボード、マウス、タッチスクリーン、音声など)を意味します。
マルチモーダルスキルは、コアボイスエクスペリエンスを補完することを目的としており、UXを向上させるための追加の補足情報を提供します。 マルチモーダルエクスペリエンスを構築するときは、音声が情報の主要なキャリアであることを忘れないでください。 多くのデバイスには画面がないため、画面がなくてもスキルを発揮する必要があるため、必ず複数のデバイスタイプでテストしてください。 実際の場合またはシミュレーターの場合。

多言語
多言語スキルは、複数の言語で機能し、スキルを複数の市場に開放するスキルです。
スキルを多言語化することの複雑さは、応答がどれほど動的であるかにかかっています。 毎回同じフレーズを返す、またはフレーズの小さなバケツのみを使用するなど、比較的静的な応答を伴うスキルは、動的なスキルを広めるよりもはるかに簡単に多言語を作成できます。
多言語の秘訣は、それが代理店を通じてであろうと、Fiverrの翻訳者を通じてであろうと、信頼できる翻訳パートナーを持つことです。 特に翻訳先の言語がわからない場合は、提供された翻訳を信頼できる必要があります。 グーグル翻訳はここでマスタードをカットしません!
結論
音声業界に参入する時期があったとしたら、それは今でしょう。 その初期と幼児期の両方、そしてビッグナインは、それを成長させ、音声アシスタントをみんなの家や日常生活に持ち込むことに何十億ドルも費やしています。
使用するプラットフォームの選択は難しい場合がありますが、構築するプラットフォームに基づいて、使用するプラットフォームを輝かせる必要があります。それができない場合は、サードパーティのツールを使用して賭けをヘッジし、複数のプラットフォームで構築する必要があります。可動部品が少なく、複雑さが軽減されます。
私は、声がどこにでもあるようになるにつれて、声の未来に興奮しています。 画面への依存度が低下し、顧客はアシスタントと自然にやり取りできるようになります。 しかし、最初に、人々がアシスタントに求めるスキルを構築するのは私たちの責任です。