
TypeScriptジェネリックを理解する
公開: 2022-03-10この記事では、TypeScriptでジェネリックスの概念を学び、ジェネリックスを使用してモジュール式の分離された再利用可能なコードを作成する方法を検討します。 その過程で、それらがより良いテストパターン、エラー処理へのアプローチ、およびドメイン/データアクセスの分離にどのように適合するかについて簡単に説明します。
実際の例
ジェネリックスが何であるかを説明するのではなく、ジェネリックスが有用である理由の直感的な例を提供することによって、ジェネリックスの世界に入りたいと思います。 機能豊富な動的リストの作成を任されているとします。 言語の背景に応じて、配列、 ArrayList 、 List 、 std::vectorなどと呼ぶことができます。 おそらく、このデータ構造には、組み込みまたはスワップ可能なバッファシステムも必要です(循環バッファ挿入オプションなど)。 これは通常のJavaScript配列のラッパーになるため、プレーン配列の代わりに構造体を操作できます。
あなたが遭遇する当面の問題は、型システムによって課せられる制約の問題です。 現時点では、関数またはメソッドに必要な型をきれいな方法で受け入れることはできません(このステートメントについては後で再検討します)。
唯一の明白な解決策は、すべての異なるタイプのデータ構造を複製することです。
const intList = IntegerList.create(); intList.add(4); const stringList = StringList.create(); stringList.add('hello'); const userList = UserList.create(); userList.add(new User('Jamie')); ここでの.create()構文は任意に見える可能性があり、実際、 new SomethingList()の方が簡単ですが、この静的ファクトリメソッドを後で使用する理由がわかります。 内部的には、 createメソッドはコンストラクターを呼び出します。
これは酷い。 このコレクション構造には多くのロジックがあり、さまざまなユースケースをサポートするために露骨に複製しており、プロセスのDRY原則を完全に破っています。 実装を変更する場合は、上記の後者の例のように、ユーザー定義の型を含め、サポートするすべての構造と型にそれらの変更を手動で伝播/反映する必要があります。 コレクション構造自体が100行の長さであると仮定します。複数の異なる実装を維持することは、それらの間の唯一の違いがタイプである場合、悪夢になります。
特にOOPの考え方がある場合に頭に浮かぶ可能性のある当面の解決策は、必要に応じてルートの「スーパータイプ」を検討することです。 たとえば、C#では、 objectという名前の型があり、 objectはSystem.Objectクラスのエイリアスです。 C#の型システムでは、すべての型は、事前定義またはユーザー定義であり、参照型または値型であるかどうかにかかわらず、 System.Objectから直接または間接的に継承します。 これは、任意の値をobject型の変数に割り当てることができることを意味します(スタック/ヒープおよびボックス化/アンボックス化のセマンティクスに入る必要はありません)。
この場合、問題は解決したようです。 他のタイプと同じように使用できます。これにより、構造を複製することなく、コレクション内に必要なものをany格納できます。実際、これは非常に真実です。
const intList = AnyList.create(); intList.add(4); const stringList = AnyList.create(); stringList.add('hello'); const userList = AnyList.create(); userList.add(new User('Jamie')); anyを使用して、リストの実際の実装を見てみましょう。
class AnyList { private values: any[] = []; private constructor (values: any[]) { this.values = values; // Some more construction work. } public add(value: any): void { this.values.push(value); } public where(predicate: (value: any) => boolean): AnyList { return AnyList.from(this.values.filter(predicate)); } public select(selector: (value: any) => any): AnyList { return AnyList.from(this.values.map(selector)); } public toArray(): any[] { return this.values; } public static from(values: any[]): AnyList { // Perhaps we perform some logic here. // ... return new AnyList(values); } public static create(values?: any[]): AnyList { return new AnyList(values ?? []); } // Other collection functions. // ... }すべてのメソッドは比較的単純ですが、コンストラクターから始めます。 リストは複雑であり、任意の構築を禁止したいと想定しているため、その可視性は非公開です。 また、構築前にロジックを実行することもできます。そのため、これらの理由から、コンストラクターを純粋に保つために、これらの懸念事項を静的ファクトリ/ヘルパーメソッドに委任します。これは良い習慣と考えられています。
fromおよびcreateの静的メソッドが提供されています。 fromのメソッドは、値の配列を受け取り、カスタムロジックを実行してから、それらを使用してリストを作成します。 create staticメソッドは、リストに初期データをシードする場合に備えて、オプションの値の配列を取ります。 「nullish合体演算子」( ?? )は、空の配列が提供されていない場合に、空の配列でリストを作成するために使用されます。 オペランドの左側がnullまたはundefinedの場合、右側にフォールバックします。この場合、 valuesはオプションであるため、 undefinedの可能性があります。 nullishの合体について詳しくは、関連するTypeScriptのドキュメントページをご覧ください。
selectメソッドとwhereメソッドも追加しました。 これらのメソッドは、JavaScriptのmapとfilterそれぞれラップするだけです。 selectを使用すると、提供されたセレクター関数に基づいて要素の配列を新しい形式に投影できます。また、提供された述語関数に基づいて特定の要素をフィルターwhere除外できます。 toArrayメソッドは、内部で保持している配列参照を返すことにより、リストを配列に変換するだけです。
最後に、 Userクラスに、名前を返し、最初で唯一のコンストラクター引数として名前を受け入れるgetNameメソッドが含まれているとします。
注:一部の読者は、C#のLINQからWhereandSelectを認識しますが、これを単純にしようとしているので、怠惰や実行の遅延について心配する必要はありません。 これらは、実際に行うことができ、行う必要がある最適化です。
さらに、興味深いことに、「述語」の意味についても説明したいと思います。 離散数学と命題論理には、「命題」の概念があります。 命題は、「4つは2つで割り切れる」など、真または偽と見なすことができるステートメントです。 「述語」は、1つ以上の変数を含む命題であるため、命題の真実性はそれらの変数の真実性に依存します。P(x) = x is divisible by twoような関数のように考えることができます。これは、ステートメントがtrueかfalseかを判断するためにxの値を知る必要があるためです。 述語論理について詳しくは、こちらをご覧ください。
の使用から発生する問題がいくつかありany 。 TypeScriptコンパイラは、リスト/内部配列内の要素について何も認識しないため、 where内、 select内、または要素の追加時にヘルプを提供しません。
// Providing seed data. const userList = AnyList.create([new User('Jamie')]); // This is fine and expected. userList.add(new User('Tom')); userList.add(new User('Alice')); // This is an acceptable input to the TS Compiler, // but it's not what we want. We'll definitely // be surprised later to find strings in a list // of users. userList.add('Hello, World!'); // Also acceptable. We have a large tuple // at this point rather than a homogeneous array. userList.add(0); // This compiles just fine despite the spelling mistake (extra 's'): // The type of `users` is any. const users = userList.where(user => user.getNames() === 'Jamie'); // Property `ssn` doesn't even exist on a `user`, yet it compiles. users.toArray()[0].ssn = '000000000'; // `usersWithId` is, again, just `any`. const usersWithId = userList.select(user => ({ id: newUuid(), name: user.getName() })); // Oops, it's "id" not "ID", but TS doesn't help us. // We compile just fine. console.log(usersWithId.toArray()[0].ID); TypeScriptはすべての配列要素の型がanyであることを認識しているだけなので、コンパイル時に存在しないプロパティまたは存在すらしないgetNames関数を使用することはできません。したがって、このコードは複数の予期しないランタイムエラーを引き起こします。 。
正直なところ、物事はかなり陰気に見え始めています。 サポートしたい具体的なタイプごとにデータ構造を実装しようとしましたが、それは決して維持できないことにすぐに気付きました。 次に、すべての型が派生する継承チェーンのルートスーパータイプに依存することに類似した、 anyを使用してどこかに到達していると思いましたが、その方法では型の安全性が失われると結論付けました。 では、解決策は何ですか?
記事の冒頭で、私は嘘をついたことがわかりました:
「現時点では、関数やメソッドに必要なタイプをきれいに受け入れることはできません。」
あなたは実際にそうすることができます、そしてそれがジェネリックスの出番です。私が「この時点で」と言ったことに注意してください。記事のその時点でジェネリックスについて知らなかったと思っていたからです。
Genericsを使用したリスト構造の完全な実装を示すことから始め、次に一歩下がって、実際に何であるかを議論し、より正式に構文を決定します。 以前のAnyListと区別するために、 TypedListという名前を付けました。
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T): void { this.values.push(value); } public where(predicate: (value: T) => boolean): TypedList<T> { return TypedList.from<T>(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U): TypedList<U> { return TypedList.from<U>(this.values.map(selector)); } public toArray(): T[] { return this.values; } public static from<U>(values: U[]): TypedList<U> { // Perhaps we perform some logic here. // ... return new TypedList<U>(values); } public static create<U>(values?: U[]): TypedList<U> { return new TypedList<U>(values ?? []); } // Other collection functions. // .. }もう一度、前と同じ間違いをしてみましょう。
// Here's the magic. `TypedList` will operate on objects // of type `User` due to the `<User>` syntax. const userList = TypedList.create<User>([new User('Jamie')]); // The compiler expects this. userList.add(new User('Tom')); userList.add(new User('Alice')); // Argument of type '0' is not assignable to parameter // of type 'User'. ts(2345) userList.add(0); // Property 'getNames' does not exist on type 'User'. // Did you mean 'getName'? ts(2551) // Note: TypeScript infers the type of `users` to be // `TypedList<User>` const users = userList.where(user => user.getNames() === 'Jamie'); // Property 'ssn' does not exist on type 'User'. ts(2339) users.toArray()[0].ssn = '000000000'; // TypeScript infers `usersWithId` to be of type // `TypedList<`{ id: string, name: string }> const usersWithId = userList.select(user => ({ id: newUuid(), name: user.getName() })); // Property 'ID' does not exist on type '{ id: string; name: string; }'. // Did you mean 'id'? ts(2551) console.log(usersWithId.toArray()[0].ID)ご覧のとおり、TypeScriptコンパイラは型安全性を積極的に支援しています。 これらのコメントはすべて、このコードをコンパイルしようとしたときにコンパイラから受け取るエラーです。 ジェネリックスでは、リストの操作を許可するタイプを指定できます。そこから、TypeScriptは、配列内の個々のオブジェクトのプロパティに至るまで、すべてのタイプを通知できます。
私たちが提供するタイプは、私たちが望むように単純なものから複雑なものまであります。 ここでは、プリミティブと複雑なインターフェイスの両方を渡すことができることがわかります。 他の配列、クラス、またはその他のものを渡すこともできます。
const numberList = TypedList.create<number>(); numberList.add(4); const stringList = TypedList.create<string>(); stringList.add('Hello, World'); // Example of a complex type interface IAircraft { apuStatus: ApuStatus; inboardOneRPM: number; altimeter: number; tcasAlert: boolean; pushBackAndStart(): Promise<void>; ilsCaptureGlidescope(): boolean; getFuelStats(): IFuelStats; getTCASHistory(): ITCASHistory; } const aircraftList = TypedList.create<IAircraft>(); aircraftList.add(/* ... */); // Aggregate and generate report: const stats = aircraftList.select(a => ({ ...a.getFuelStats(), ...a.getTCASHistory() })); TypedList<T>実装でのTとU 、および<T>と<U>の特殊な使用法は、実際のジェネリックスの例です。 タイプセーフなコレクション構造を構築するという指令を実行したので、この例は今のところ残しておきます。ジェネリックが実際に何であるか、それらがどのように機能するか、およびそれらの構文を理解したら、この例に戻ります。 新しい概念を学ぶときは、常に使用中の概念の複雑な例を見るところから始めるのが好きです。そうすれば、基本を学び始めるときに、基本的なトピックと既存の例を結び付けることができます。頭。
ジェネリックとは何ですか?
ジェネリックスを理解するための簡単な方法は、それらをプレースホルダーまたは変数に比較的類似していると見なすことですが、型についてです。 ジェネリック型プレースホルダーに対して変数と同じ操作を実行できるというわけではありませんが、ジェネリック型変数は、将来使用される具体的な型を表すプレースホルダーと考えることができます。 つまり、ジェネリックスを使用することは、後で指定されるタイプの観点からプログラムを作成する方法です。 これが役立つ理由は、操作対象のさまざまなタイプ(またはタイプに依存しない)間で再利用可能なデータ構造を構築できるためです。
これは特に優れた説明ではないため、これまで見てきたように、より簡単に言えば、プログラミングでは、特定の型で動作する関数/クラス/データ構造を構築する必要がある場合がありますが、このようなデータ構造は、さまざまなタイプでも機能する必要があることも同様に一般的です。 データ構造を設計するとき(コンパイル時)にデータ構造が動作する具体的な型を静的に宣言しなければならない状況に陥った場合、それらを再構築する必要があることがすぐにわかります。上記の例で見たように、サポートしたいすべてのタイプに対してほぼ同じ方法で構造を作成します。
ジェネリックスは、具体的なタイプの要件が実際にわかるまで延期できるようにすることで、この問題を解決するのに役立ちます。
TypeScriptのジェネリックス
ジェネリックスがなぜ有用であるかについて、私たちは今やや有機的な考えを持っており、実際にそれらの少し複雑な例を見てきました。 ほとんどの場合、 TypedList<T>の実装は、特に静的に型付けされた言語のバックグラウンドを持っている場合は、おそらくすでに多くの意味がありますが、最初に学習したときに概念を理解するのに苦労したことを覚えているので、単純な関数から始めて、その例を構築します。 ソフトウェアの抽象化に関連する概念は、内部化するのが難しいことで有名です。したがって、ジェネリックスの概念がまだ完全にクリックされていない場合、それは完全に問題ありません。この記事の締めくくりまでに、アイデアは少なくともある程度直感的になるでしょう。
その例を理解できるようになるために、単純な関数から作業を進めましょう。 まず、「恒等関数」から始めます。これは、TypeScriptドキュメント自体を含むほとんどの記事で使用されているものです。
数学における「恒等関数」は、 f(x) = xのように、入力を出力に直接マップする関数です。 あなたが入れるものはあなたが出すものです。 これは、JavaScriptで次のように表すことができます。
function identity(input) { return input; }または、もっと簡潔に:
const identity = input => input; これをTypeScriptに移植しようとすると、以前に見たのと同じ型システムの問題が発生します。 解決策は、 anyのタイプで入力することです。これは、ほとんど良い考えではないことがわかっています。各タイプの関数を複製/オーバーロードする(DRYを中断する)か、ジェネリックスを使用します。
後者のオプションを使用すると、関数を次のように表すことができます。
// ES5 Function function identity<T>(input: T): T { return input; } // Arrow Function const identity = <T>(input: T): T => input; console.log(identity<number>(5)); // 5 console.log(identity<string>('hello')); // hello ここでの<T>構文は、この関数をGenericとして宣言します。 関数で任意の入力パラメーターを引数リストに渡すことができるのと同じように、ジェネリック関数を使用すると、任意の型パラメーターを渡すこともできます。
identity<T>(input: T): Tおよび<T>(input: T): Tのシグネチャの<T>部分は、どちらの場合も、問題の関数がTという名前の1つのジェネリック型パラメーターを受け入れることを宣言します。 変数に任意の名前を付けることができるのと同じように、汎用プレースホルダーも同様ですが、大文字の「T」(「タイプ」を表す「T」)を使用し、必要に応じてアルファベットを下に移動するのが慣例です。 Tは型であるため、 T型でinputされた名前の関数引数を1つ受け入れ、関数がT型を返すことも述べています。 署名が言っているのはそれだけです。 T = stringを頭に入れてみてください—すべてのTをそれらの署名のstringに置き換えてください。 魔法のようなことが何も起こっていないのがわかりますか? 毎日関数を使用する非ジェネリックな方法とどれほど似ているか見てみましょう。
TypeScriptと関数のシグネチャについてすでに知っていることを覚えておいてください。 私たちが言っているのは、 inputが関数を呼び出すときにユーザーが提供する任意の値であるのと同じように、 Tはユーザーが関数を呼び出すときに提供する任意のタイプであるということです。 この場合、 inputは、関数が将来呼び出されるときにそのタイプTが何であれでなければなりません。
次に、「future」では、2つのログステートメントで、変数を実行するのと同じように、使用する具象型を「渡し」ます。 ここでの言い回しの切り替えに注意してください— <T> signatureの初期形式では、関数を宣言するとき、それはジェネリックです—つまり、ジェネリック型、または後で指定される型で機能します。 これは、実際に関数を作成するときに、呼び出し元がどのタイプを使用したいかわからないためです。 ただし、呼び出し元が関数を呼び出すと、操作するタイプ(この場合はstringとnumber )を正確に把握できます。
サードパーティのライブラリでこのようにログ関数を宣言するというアイデアを想像できます。ライブラリの作成者は、ライブラリを使用する開発者がどのタイプを使用したいかわからないため、関数を汎用化し、本質的に必要性を延期します。それらが実際に知られるまで、具体的なタイプのために。
このプロセスは、より直感的な理解を得るために変数を関数に渡すという概念と同じように考える必要があることを強調したいと思います。 現在行っているのは、型を渡すことだけです。
numberパラメーターを使用して関数を呼び出した時点で、元の署名は、すべての目的と目的で、 identity(input: number): numberと考えることができます。 また、 stringパラメーターを使用して関数を呼び出した時点でも、元の署名はidentity(input: string): stringであった可能性があります。 電話をかけると、すべての汎用Tが、その時点で提供する具象型に置き換えられることが想像できます。
一般的な構文の調査
ES5関数、矢印関数、型エイリアス、インターフェイス、およびクラスのコンテキストでジェネリックを指定するためのさまざまな構文とセマンティクスがあります。 このセクションでは、これらの違いについて説明します。
一般的な構文の調査—関数
これまでにジェネリック関数の例をいくつか見てきましたが、ジェネリック関数は、変数と同じように、複数のジェネリック型パラメーターを受け入れることができることに注意してください。 1つ、2つ、3つ、または必要な数のタイプをすべてコンマで区切って要求することを選択できます(ここでも、入力引数と同じように)。
この関数は3つの入力タイプを受け入れ、そのうちの1つをランダムに返します。
function randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V { // This is a tuple if you're not familiar. const options: [T, U, V] = [ one, two, three ]; const rndNum = getRndNumInInclusiveRange(0, 2); return options[rndNum]; } // Calling the function. // `value` has type `string | number | IAircraft` const value = randomValue< string, number, IAircraft >( myString, myNumber, myAircraft );また、ES5関数とArrow関数のどちらを使用するかによって構文がわずかに異なることがわかりますが、どちらも署名で型パラメーターを宣言しています。
const randomValue = <T, U, V>( one: T, two: U, three: V ): T | U | V => { // This is a tuple if you're not familiar. const options: [T, U, V] = [ one, two, three ]; const rndNum = getRndNumInInclusiveRange(0, 2); return options[rndNum]; } タイプに強制される「一意性の制約」はないことに注意してください。たとえば、2つのstringと1つのnumberなど、任意の組み合わせで渡すことができます。 さらに、入力引数が関数の本体の「スコープ内」にあるのと同様に、ジェネリック型パラメーターも同様です。 前者の例は、関数の本体内からT 、 U 、およびVに完全にアクセスできることを示しており、これらを使用してローカルの3タプルを宣言しました。
これらのジェネリックは、特定の「コンテキスト」または特定の「ライフタイム」内で動作することを想像できます。これは、宣言されている場所によって異なります。 関数のジェネリックは、関数の署名と本体(およびネストされた関数によって作成されたクロージャ)内のスコープにありますが、クラス、インターフェイス、または型エイリアスで宣言されたジェネリックは、クラス、インターフェイス、または型エイリアスのすべてのメンバーのスコープにあります。
関数のジェネリックスの概念は、「フリー関数」または「フローティング関数」(オブジェクトまたはクラスにアタッチされていない関数、C ++用語)に限定されず、他の構造にアタッチされた関数にも使用できます。
そのrandomValueをクラスに配置し、それをまったく同じように呼び出すことができます。
class Utils { public randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V { // ... } // Or, as an arrow function: public randomValue = <T, U, V>( one: T, two: U, three: V ): T | U | V => { // ... } }インターフェイス内に定義を配置することもできます。
interface IUtils { randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V; }またはタイプエイリアス内:
type Utils = { randomValue<T, U, V>( one: T, two: U, three: V ): T | U | V; }以前と同様に、これらのジェネリック型パラメーターは、その特定の関数の「スコープ内」にあります。クラス、インターフェイス、またはエイリアス全体の型ではありません。 それらは、指定された特定の機能内でのみ存在します。 構造体のすべてのメンバー間でジェネリック型を共有するには、以下に示すように、構造体の名前自体に注釈を付ける必要があります。
一般的な構文の調査—タイプエイリアス
タイプエイリアスでは、エイリアスの名前に一般的な構文が使用されます。
たとえば、値を受け入れ、その値を変更する可能性があるが、voidを返す「アクション」関数は、次のように記述できます。
type Action<T> = (val: T) => void;注:これは、Action <T>デリゲートを理解しているC#開発者にはおなじみのはずです。
または、エラーと値の両方を受け入れるコールバック関数を次のように宣言することもできます。
type CallbackFunction<T> = (err: Error, data: T) => void; const usersApi = { get(uri: string, cb: CallbackFunction<User>) { /// ... } }関数ジェネリックの知識があれば、さらに進んでAPIオブジェクトの関数もジェネリックにすることができます。
type CallbackFunction<T> = (err: Error, data: T) => void; const api = { // `T` is available for use within this function. get<T>(uri: string, cb: CallbackFunction<T>) { /// ... } } ここで、 get関数はいくつかのジェネリック型パラメーターを受け入れ、それが何であれ、 CallbackFunctionはそれを受け取ると言っています。 基本的に、Getにget TをCallbackFunctionのTとして「渡し」ました。 名前を変更すると、おそらくこれはより理にかなっています。
type CallbackFunction<TData> = (err: Error, data: TData) => void; const api = { get<TResponse>(uri: string, cb: CallbackFunction<TResponse>) { // ... } } タイプパラメータの前にTを付けるのは単なる慣例であり、インターフェイスの前にI付けたり、メンバー変数の前に_を付けたりするのと同じです。 ここで確認できるのは、 CallbackFunctionが関数で使用可能なデータペイロードを表すタイプ( TData )を受け入れ、 getがHTTP応答データタイプ/シェイプ( TResponse )を表すタイプパラメーターを受け入れることです。 HTTPクライアント( api )は、Axiosと同様に、 TResponseがCallbackFunctionのTDataとして使用されます。 これにより、API呼び出し元はAPIから受信するデータ型を選択できます(パイプラインのどこかに、JSONをDTOに解析するミドルウェアがあるとします)。
これをもう少し進めたい場合は、 CallbackFunctionのジェネリック型パラメーターを変更して、カスタムエラー型も受け入れることができます。
type CallbackFunction<TData, TError> = (err: TError, data: TData) => void;また、関数の引数をオプションにすることができるのと同じように、型パラメーターを使用することもできます。 ユーザーがエラータイプを指定しない場合、デフォルトでエラーコンストラクターに設定します。
type CallbackFunction<TData, TError = Error> = (err: TError, data: TData) => void;これにより、複数の方法でコールバック関数タイプを指定できるようになりました。
const apiOne = { // `Error` is used by default for `CallbackFunction`. get<TResponse>(uri: string, cb: CallbackFunction<TResponse>) { // ... } }; apiOne.get<string>('uri', (err: Error, data: string) => { // ... }); const apiTwo = { // Override the default and use `HttpError` instead. get<TResponse>(uri: string, cb: CallbackFunction<TResponse, HttpError>) { // ... } }; apiTwo.get<string>('uri', (err: HttpError, data: string) => { // ... });このデフォルトパラメータの考え方は、関数、クラス、インターフェイスなどで受け入れられます。これは、型エイリアスだけに限定されるものではありません。 これまで見てきたすべての例で、必要なタイプパラメータをデフォルト値に割り当てることができました。 型エイリアスは、関数と同様に、必要な数のジェネリック型パラメーターを取ることができます。
一般的な構文の調査—インターフェイス
これまで見てきたように、ジェネリック型パラメーターをインターフェース上の関数に提供することができます。
interface IUselessFunctions { // Not generic printHelloWorld(); // Generic identity<T>(t: T): T; } この場合、 Tは、入力および戻りタイプとしてのidentity関数に対してのみ存続します。
インターフェイス自体がジェネリックを受け入れるように指定することで、クラスや型エイリアスと同様に、インターフェイスのすべてのメンバーが型パラメータを使用できるようにすることもできます。 リポジトリパターンについては、ジェネリックスのより複雑なユースケースについて説明するときに少し後で説明するので、聞いたことがなくても大丈夫です。 リポジトリパターンを使用すると、データストレージを抽象化して、ビジネスロジックの永続性に依存しないようにすることができます。 不明なエンティティタイプで動作する汎用リポジトリインターフェイスを作成する場合は、次のように入力できます。
interface IRepository<T> { add(entity: T): Promise<void>; findById(id: string): Promise<T>; updateById(id: string, updated: T): Promise<void>; removeById(id: string): Promise<void>; }注: Martin Fowlerの定義からDDDAggregateの定義まで、リポジトリにはさまざまな考えがあります。 私はジェネリックスのユースケースを示すことを試みているだけなので、実装に関して完全に正しいことにはあまり関心がありません。 一般的なリポジトリを使用しないことについては確かに言うべきことがありますが、それについては後で説明します。
ここでわかるように、 IRepositoryは、データを格納および取得するためのメソッドを含むインターフェースです。 これは、 Tという名前のジェネリック型パラメーターで動作し、 Tは、 findByIdのpromise解決結果と同様にaddおよびupdateByIdへの入力として使用されます。
各関数自体がジェネリック型パラメーターを受け入れることを許可するのとは対照的に、インターフェース名でジェネリック型パラメーターを受け入れることには非常に大きな違いがあることに注意してください。 前者は、ここで行ったように、インターフェイス内の各関数が同じタイプTで動作することを保証します。 つまり、 IRepository<User>の場合、インターフェイスでTを使用するすべてのメソッドがUserオブジェクトで機能するようになりました。 後者の方法では、各関数は必要なタイプで動作することができます。 Userをリポジトリに追加することしかできないが、 PoliciesやOrdersを受け取ることができるのは非常に独特です。これは、タイプがすべてのメソッドで均一です。
特定のインターフェイスには、共有タイプだけでなく、そのメンバーに固有のタイプも含めることができます。 たとえば、配列を模倣したい場合は、次のようなインターフェイスを入力できます。
interface IArray<T> { forEach(func: (elem: T, index: number) => void): this; map<U>(func: (elem: T, index: number) => U): IArray<U>; } この場合、 forEachとmapの両方がインターフェース名からTにアクセスできます。 前述のように、 Tはインターフェイスのすべてのメンバーのスコープ内にあると想像できます。 それにもかかわらず、内部の個々の関数が独自の型パラメーターを受け入れることを妨げるものは何もありません。 map関数はUを使用します。 これで、 mapはTとUの両方にアクセスできるようになります。 Tはすでに使用されており、名前の衝突は望ましくないため、パラメータにUなどの別の文字を付ける必要がありました。 その名前とまったく同じように、 mapは配列内のタイプTの要素をタイプUの新しい要素に「マップ」します。 TをUにマップします。 この関数の戻り値はインターフェース自体であり、現在は新しいタイプUで動作しているため、JavaScriptの配列に対する流暢な連鎖可能な構文をいくらか模倣できます。
リポジトリパターンを実装し、依存性注入について説明すると、ジェネリックスとインターフェイスの能力の例がすぐにわかります。 繰り返しになりますが、インターフェイスの最後にスタックされた1つ以上のデフォルトパラメータを選択するだけでなく、できるだけ多くの汎用パラメータを受け入れることができます。
一般的な構文の調査—クラス
ジェネリック型パラメーターを型エイリアス、関数、またはインターフェイスに渡すことができるのとほぼ同じように、1つ以上をクラスに渡すこともできます。 そうすることで、その型パラメーターは、そのクラスのすべてのメンバー、および拡張基本クラスまたは実装されたインターフェースにアクセスできるようになります。
別のコレクションクラスを作成しましょう。ただし、上記のTypedListよりも少し単純なので、ジェネリック型、インターフェイス、およびメンバー間の相互運用を確認できます。 型を基本クラスに渡し、インターフェイスの継承を少し後で行う例を示します。
私たちのコレクションは、 mapとforEachメソッドに加えて、基本的なCRUD関数をサポートするだけです。
class Collection<T> { private elements: T[] = []; constructor (elements: T[] = []) { this.elements = elements; } add(elem: T): void { this.elements.push(elem); } contains(elem: T): boolean { return this.elements.includes(elem); } remove(elem: T): void { this.elements = this.elements.filter(existing => existing !== elem); } forEach(func: (elem: T, index: number) => void): void { return this.elements.forEach(func); } map<U>(func: (elem: T, index: number) => U): Collection<U> { return new Collection<U>(this.elements.map(func)); } } const stringCollection = new Collection<string>(); stringCollection.add('Hello, World!'); const numberCollection = new Collection<number>(); numberCollection.add(3.14159); const aircraftCollection = new Collection<IAircraft>(); aircraftCollection.add(myAircraft); ここで何が起こっているのかを話し合いましょう。 Collectionクラスは、 Tという名前の1つのジェネリック型パラメーターを受け入れます。 そのタイプは、クラスのすべてのメンバーがアクセスできるようになります。 これを使用して、 T[]型のプライベート配列を定義します。これは、 Array<T>の形式で指定することもできます(通常のTS配列型については、ジェネリックスを参照してください)。 さらに、ほとんどのメンバー関数は、追加および削除される型を制御したり、コレクションに要素が含まれているかどうかを確認したりするなど、何らかの方法でそのTを利用します。
最後に、前に見たように、 mapメソッドには独自のジェネリック型パラメーターが必要です。 We need to define in the signature of map that some type T is mapped to some type U through a callback function, thus we need a U . That U is unique to that function in particular, which means we could have another function in that class that also accepts some type named U , and that'd be fine, because those types are only “in scope” for their functions and not shared across them, thus there are no naming collisions. What we can't do is have another function that accepts a generic parameter named T , for that'd conflict with the T from the class signature.
You can see that when we call the constructor, we pass in the type we want to work with (that is, what type each element of the internal array will be). In the calling code at the bottom of the example, we work with string s, number s, and IAircraft s.
How could we make this work with an interface? What if we have different collection interfaces that we might want to swap out or inject into calling code? To get that level of reduced coupling (low coupling and high cohesion is what we should always aim for), we'll need to depend on an abstraction. Generally, that abstraction will be an interface, but it could also be an abstract class.
Our collection interface will need to be generic, so let's define it:
interface ICollection<T> { add(t: T): void; contains(t: T): boolean; remove(t: T): void; forEach(func: (elem: T, index: number) => void): void; map<U>(func: (elem: T, index: number) => U): ICollection<U>; }Now, let's suppose we have different kinds of collections. We could have an in-memory collection, one that stores data on disk, one that uses a database, and so on. By having an interface, the dependent code can depend upon the abstraction, permitting us to swap out different implementations without affecting the existing code. Here is the in-memory collection.

class InMemoryCollection<T> implements ICollection<T> { private elements: T[] = []; constructor (elements: T[] = []) { this.elements = elements; } add(elem: T): void { this.elements.push(elem); } contains(elem: T): boolean { return this.elements.includes(elem); } remove(elem: T): void { this.elements = this.elements.filter(existing => existing !== elem); } forEach(func: (elem: T, index: number) => void): void { return this.elements.forEach(func); } map<U>(func: (elem: T, index: number) => U): ICollection<U> { return new InMemoryCollection<U>(this.elements.map(func)); } } The interface describes the public-facing methods and properties that our class is required to implement, expecting you to pass in a concrete type that those methods will operate upon. However, at the time of defining the class, we still don't know what type the API caller will wish to use. Thus, we make the class generic too — that is, InMemoryCollection expects to receive some generic type T , and whatever it is, it's immediately passed to the interface, and the interface methods are implemented using that type.
Calling code can now depend on the interface:
// Using type annotation to be explicit for the purposes of the // tutorial. const userCollection: ICollection<User> = new InMemoryCollection<User>(); function manageUsers(userCollection: ICollection<User>) { userCollection.add(new User()); } With this, any kind of collection can be passed into the manageUsers function as long as it satisfies the interface. This is useful for testing scenarios — rather than dealing with over-the-top mocking libraries, in unit and integration test scenarios, I can replace my SqlServerCollection<T> (for example) with InMemoryCollection<T> instead and perform state-based assertions instead of interaction-based assertions. This setup makes my tests agnostic to implementation details, which means they are, in turn, less likely to break when refactoring the SUT.
At this point, we should have worked up to the point where we can understand that first TypedList<T> example. Here it is again:
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T): void { this.values.push(value); } public where(predicate: (value: T) => boolean): TypedList<T> { return TypedList.from<T>(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U): TypedList<U> { return TypedList.from<U>(this.values.map(selector)); } public toArray(): T[] { return this.values; } public static from<U>(values: U[]): TypedList<U> { // Perhaps we perform some logic here. // ... return new TypedList<U>(values); } public static create<U>(values?: U[]): TypedList<U> { return new TypedList<U>(values ?? []); } // Other collection functions. // .. } The class itself accepts a generic type parameter named T , and all members of the class are provided access to it. The instance method select and the two static methods from and create , which are factories, accept their own generic type parameter named U .
The create static method permits the construction of a list with optional seed data. It accepts some type named U to be the type of every element in the list as well as an optional array of U elements, typed as U[] . When it calls the list's constructor with new , it passes that type U as the generic parameter to TypedList . This creates a new list where the type of every element is U . It is exactly the same as how we could call the constructor of our collection class earlier with new Collection<SomeType>() . The only difference is that the generic type is now passing through the create method rather than being provided and used at the top-level.
I want to make sure this is really, really clear. I've stated a few times that we can think about passing around types in a similar way that we do variables. It should already be quite intuitive that we can pass a variable through as many layers of indirection as we please. Forget generics and types for a moment and think about an example of the form:
class MyClass { private constructor (t: number) {} public static create(u: number) { return new MyClass(u); } } const myClass = MyClass.create(2.17); This is very similar to what is happening with the more-involved example, the difference being that we're working on generic type parameters, not variables. Here, 2.17 becomes the u in create , which ultimately becomes the t in the private constructor.
In the case of generics:
class MyClass<T> { private constructor () {} public static create<U>() { return new MyClass<U>(); } } const myClass = MyClass.create<number>(); The U passed to create is ultimately passed in as the T for MyClass<T> . When calling create , we provided number as U , thus now U = number . We put that U (which, again, is just number ) into the T for MyClass<T> , so that MyClass<T> effectively becomes MyClass<number> . The benefit of generics is that we're opened up to be able to work with types in this abstract and high-level fashion, similar to how we can normal variables.
The from method constructs a new list that operates on an array of elements of type U . It uses that type U , just like create , to construct a new instance of the TypedList class, now passing in that type U for T .
The where instance method performs a filtering operation based upon a predicate function. There's no mapping happening, thus the types of all elements remain the same throughout. The filter method available on JavaScript's array returns a new array of values, which we pass into the from method. So, to be clear, after we filter out the values that don't satisfy the predicate function, we get an array back containing the elements that do. All those elements are still of type T , which is the original type that the caller passed to create when the list was first created. Those filtered elements get given to the from method, which in turn creates a new list containing all those values, still using that original type T . The reason why we return a new instance of the TypedList class is to be able to chain new method calls onto the return result. This adds an element of “immutability” to our list.
Hopefully, this all provides you with a more intuitive example of generics in practice, and their reason for existence. Next, we'll look at a few of the more advanced topics.
Generic Type Inference
Throughout this article, in all cases where we've used generics, we've explicitly defined the type we're operating on. It's important to note that in most cases, we do not have to explicitly define the type parameter we pass in, for TypeScript can infer the type based on usage.
If I have some function that returns a random number, and I pass the return result of that function to identity from earlier without specifying the type parameter, it will be inferred automatically as number :
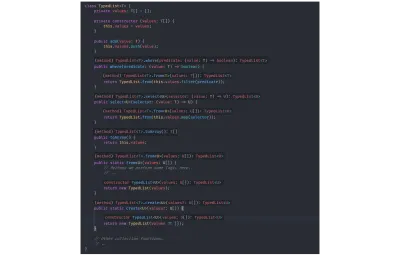
// `value` is inferred as type `number`. const value = identity(getRandomNumber()); 型推論を示すために、以前にTypedList構造から技術的に無関係な型注釈をすべて削除しました。下の図から、TSCがすべての型を正しく推論していることがわかります。
無関係な型宣言のないTypedList :
class TypedList<T> { private values: T[] = []; private constructor (values: T[]) { this.values = values; } public add(value: T) { this.values.push(value); } public where(predicate: (value: T) => boolean) { return TypedList.from(this.values.filter(predicate)); } public select<U>(selector: (value: T) => U) { return TypedList.from(this.values.map(selector)); } public toArray() { return this.values; } public static from<U>(values: U[]) { // Perhaps we perform some logic here. // ... return new TypedList(values); } public static create<U>(values?: U[]) { return new TypedList(values ?? []); } // Other collection functions. // .. } TSCは、関数の戻り値と、 from渡された入力型およびコンストラクターに基づいて、すべての型情報を理解します。 以下の画像では、複数の画像をつなぎ合わせており、Visual StudioのコードTypeScriptの言語拡張機能(したがってコンパイラー)がすべての型を推測していることを示しています。
一般的な制約
ジェネリック型の周りに制約を課したい場合があります。 おそらく、存在するすべてのタイプをサポートできるわけではありませんが、それらのサブセットをサポートすることはできます。 コレクションの長さを返す関数を作成するとします。 上記のように、デフォルトのJavaScript Arrayからカスタム配列まで、さまざまな種類の配列/コレクションを使用できます。 ジェネリック型にlengthプロパティが付加されていることを関数に通知するにはどうすればよいですか? 同様に、関数に渡す具象型を、必要なデータを含む型に制限するにはどうすればよいですか? たとえば、このような例は機能しません。
function getLength<T>(collection: T): number { // Error. TS does not know that a type T contains a `length` property. return collection.length; }答えは、ジェネリック制約を利用することです。 必要なプロパティを説明するインターフェースを定義できます。
interface IHasLength { length: number; }これで、ジェネリック関数を定義するときに、ジェネリック型をそのインターフェイスを拡張するものに制限できます。
function getLength<T extends IHasLength>(collection: T): number { // Restricting `collection` to be a type that contains // everything within the `IHasLength` interface. return collection.length; }実際の例
次のいくつかのセクションでは、よりエレガントで推論しやすいコードを作成するジェネリックスの実際の例について説明します。 些細な例をたくさん見てきましたが、エラー処理、データアクセスパターン、フロントエンドのReact状態/小道具へのいくつかのアプローチについて説明したいと思います。
実際の例—エラー処理へのアプローチ
JavaScriptには、ほとんどのプログラミング言語と同様に、エラーを処理するためのファーストクラスのメカニズムが含まれています— try / catch 。 それにもかかわらず、私はそれが使用されたときにどのように見えるかについてはあまり好きではありません。 メカニズムを使わないというわけではありませんが、できる限り隠そうとする傾向があります。 try / catch awayを抽象化することで、失敗する可能性のある操作全体でエラー処理ロジックを再利用することもできます。
データアクセス層を構築していると仮定します。 これは、データストレージメソッドを処理するための永続ロジックをラップするアプリケーションのレイヤーです。 データベース操作を実行していて、そのデータベースがネットワーク全体で使用されている場合、特定のDB固有のエラーと一時的な例外が発生する可能性があります。 専用のデータアクセス層を使用する理由の1つは、データベースをビジネスロジックから抽象化することです。 そのため、このようなDB固有のエラーがスタックにスローされてこのレイヤーから外れることはありません。 最初にそれらをラップする必要があります。
try / catchを使用する典型的な実装を見てみましょう:
async function queryUser(userID: string): Promise<User> { try { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(dbUser); } catch (e) { switch (true) { case e instanceof DbErrorOne: return Promise.reject(new WrapperErrorOne()); case e instanceof DbErrorTwo: return Promise.reject(new WrapperErrorTwo()); case e instanceof NetworkError: return Promise.reject(new TransientException()); default: return Promise.reject(new UnknownError()); } } } trueに切り替えることは、if / else ifのチェーンを宣言する必要があるのではなく、エラーチェックロジックにcaseステートメントを使用できるようにするためのメソッドにすぎません。@ Jeffijoeから最初に聞いたトリックです。
このような関数が複数ある場合は、このエラーラッピングロジックを複製する必要がありますが、これは非常に悪い習慣です。 1つの機能としてはかなり良さそうに見えますが、多くの機能があると悪夢になります。 このロジックを抽象化するために、結果を渡すカスタムエラー処理関数でラップすることができますが、エラーがスローされた場合はキャッチしてラップします。
async function withErrorHandling<T>( dalOperation: () => Promise<T> ): Promise<T> { try { // This unwraps the promise and returns the type `T`. return await dalOperation(); } catch (e) { switch (true) { case e instanceof DbErrorOne: return Promise.reject(new WrapperErrorOne()); case e instanceof DbErrorTwo: return Promise.reject(new WrapperErrorTwo()); case e instanceof NetworkError: return Promise.reject(new TransientException()); default: return Promise.reject(new UnknownError()); } } } これが理にかなっていることを確認するために、ジェネリック型パラメーターTを受け入れるwithErrorHandlingというタイトルの関数があります。 このTは、 dalOperationコールバック関数から返されると予想されるpromiseの成功した解決値のタイプを表します。 通常、非同期dalOperation関数の戻り結果を返すだけなので、それをawait必要はありません。これにより、関数が2番目の無関係なpromiseでラップされ、呼び出し元のコードにawaitことができます。 この場合、エラーをキャッチする必要があるため、 awaitが必要です。
これで、この関数を使用して、以前のDAL操作をラップできます。
async function queryUser(userID: string) { return withErrorHandling<User>(async () => { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(dbUser); }); }そして、そこに行きます。 タイプセーフおよびエラーセーフ関数のユーザークエリ関数があります。
さらに、前に見たように、TypeScriptコンパイラが暗黙的に型を推測するのに十分な情報を持っている場合は、それらを明示的に渡す必要はありません。 この場合、TSCは、関数の戻り結果がジェネリック型であることを認識しています。 したがって、 mapper.toDomain(user)がタイプUserを返した場合、タイプを渡す必要はまったくありません。
async function queryUser(userID: string) { return withErrorHandling(async () => { const dbUser = await db.raw(` SELECT * FROM users WHERE user_id = ? `, [userID]); return mapper.toDomain(user); }); } 私が好む傾向があるエラー処理への別のアプローチは、MonadicTypesのアプローチです。 どちらかのモナドは、 Either<T, U>の形式の代数的データ型です。ここで、 Tはエラーの種類を表し、 Uは障害の種類を表すことができます。 Monadic Typesを使用すると、関数型プログラミングに耳を傾けます。主な利点は、エラーがタイプセーフになることです。通常の関数シグネチャは、API呼び出し元に、その関数がスローする可能性のあるエラーについて何も通知しません。 queryUser内からNotFoundエラーをスローするとします。 queryUser(userID: string): Promise<User>はそれについて何も教えてくれません。 ただし、 queryUser(userID: string): Promise<Either<NotFound, User>>のような署名は絶対に行います。 どちらかのモナドのようなモナドは非常に複雑になる可能性があり、マッピング/バインディングなど、モナドと見なす必要のあるさまざまな方法があるため、この記事ではどのように機能するかについては説明しません。 それらについてもっと知りたい場合は、こことここでのスコット・ヴラシンの2つのNDC講演と、ここでのダニエル・チェンバーの講演をお勧めします。 このサイトだけでなく、これらのブログ投稿も役立つかもしれません。
実際の例—リポジトリパターン
Genericsが役立つ可能性のある別のユースケースを見てみましょう。 ほとんどのバックエンドシステムは、何らかの方法でデータベースとインターフェイスする必要があります。これは、PostgreSQLのようなリレーショナルデータベース、MongoDBのようなドキュメントデータベース、またはNeo4jのようなグラフデータベースである可能性があります。
開発者として、低結合で非常にまとまりのある設計を目指す必要があるため、データベースシステムの移行による影響を検討することは公正な議論です。 また、データアクセスのニーズが異なれば、データアクセスアプローチも異なる可能性があると考えるのも妥当です(これは、読み取りと書き込みを分離するためのパターンであるCQRSに少し入り始めます。必要に応じて、MartinFowlerの投稿とMSDNリストを参照してください。詳細については、VaughnVernonによる「ImplementingDomainDriven Design」、およびScott Milletによる「Patterns、Principles、and Practices of Domain-Driven Design」も参考になります)。 自動テストも検討する必要があります。 Node.jsを使用したバックエンドシステムの構築を説明するチュートリアルの大部分は、データアクセスコードとルーティングを備えたビジネスロジックを組み合わせています。 つまり、MongoDBをMongoose ODMで使用する傾向があり、Active Recordアプローチを採用しており、関心の分離が明確ではありません。 このような手法は、大規模なアプリケーションでは嫌われています。 あるデータベースシステムを別のデータベースシステムに移行することを決定した瞬間、またはデータアクセスに別のアプローチを好むことに気付いた瞬間、古いデータアクセスコードを取り除いて、新しいコードに置き換える必要があります。途中でルーティングとビジネスロジックにバグが発生しなかったことを願っています。
確かに、ユニットテストと統合テストはリグレッションを防ぐと主張するかもしれませんが、それらのテストが結合され、不可知論者である必要がある実装の詳細に依存している場合、それらもプロセスで中断する可能性があります。
この問題を解決するための一般的なアプローチは、リポジトリパターンです。 コードを呼び出すには、データアクセス層がオブジェクトまたはドメインエンティティの単なるメモリ内コレクションを模倣できるようにする必要があると書かれています。 このようにして、データベース(データモデル)ではなく、ビジネスに設計を推進させることができます。 大規模なアプリケーションでは、ドメイン駆動設計と呼ばれるアーキテクチャパターンが役立ちます。 リポジトリパターンのリポジトリは、データソースにアクセスするためのすべてのロジックをカプセル化して内部に保持するコンポーネントであり、最も一般的にはクラスです。 これにより、データアクセスコードを1つのレイヤーに一元化して、テストと再利用を容易にすることができます。 さらに、マッピングレイヤーを間に配置して、データベースに依存しないドメインモデルを一連の1対1のテーブルマッピングにマッピングできるようにすることができます。 必要に応じて、リポジトリで使用可能な各関数は、オプションで異なるデータアクセス方法を使用できます。
リポジトリ、作業単位、テーブル間のデータベーストランザクションなどには、さまざまなアプローチとセマンティクスがあります。 これはジェネリックスに関する記事なので、雑草にあまり入り込みたくないので、ここで簡単な例を示しますが、アプリケーションごとにニーズが異なることに注意することが重要です。 たとえば、DDDアグリゲートのリポジトリは、ここで行っているものとはかなり異なります。 ここでリポジトリの実装をどのように表現するかは、実際のプロジェクトでそれらを実装する方法ではありません。多くの機能が不足していて、望ましくないアーキテクチャ手法が使用されているためです。
ドメインモデルとしてUsersとTasksがあるとしましょう。 これらは単なるPOTO—プレーン-古いTypeScriptオブジェクトである可能性があります。 それらにデータベースが組み込まれているという概念はないため、たとえば、Mongooseを使用する場合のように、 User.save()を呼び出すことはありません。 リポジトリパターンを使用すると、次のようにユーザーを永続化するか、ビジネスロジックからタスクを削除できます。
// Querying the DB for a User by their ID. const user: User = await userRepository.findById(userID); // Deleting a Task by its ID. await taskRepository.deleteById(taskID); // Deleting a Task by its owner's ID. await taskRepository.deleteByUserId(userID);明らかに、すべての厄介で一時的なデータアクセスロジックがこのリポジトリのファサード/抽象化の背後に隠されており、ビジネスロジックが永続性の懸念にとらわれないことがわかります。
いくつかの単純なドメインモデルを構築することから始めましょう。 これらは、アプリケーションコードが相互作用するモデルです。 ここでは貧血ですが、現実の世界でビジネスの不変条件を満たすための独自のロジックを保持します。つまり、単なるデータバッグではありません。
interface IHasIdentity { id: string; } class User implements IHasIdentity { public constructor ( private readonly _id: string, private readonly _username: string ) {} public get id() { return this._id; } public get username() { return this._username; } } class Task implements IHasIdentity { public constructor ( private readonly _id: string, private readonly _title: string ) {} public get id() { return this._id; } public get title() { return this._title; } } ID入力情報をインターフェースに抽出する理由がすぐにわかります。 ドメインモデルを定義し、すべてをコンストラクターに渡すこの方法は、私が現実の世界で行う方法ではありません。 さらに、 idの実装を無料で取得するには、インターフェイスよりも抽象ドメインモデルクラスに依存する方が望ましいでしょう。
リポジトリの場合、この場合、同じ永続化メカニズムの多くが異なるドメインモデル間で共有されると予想されるため、リポジトリメソッドを汎用インターフェイスに抽象化できます。
interface IRepository<T> { add(entity: T): Promise<void>; findById(id: string): Promise<T>; updateById(id: string, updated: T): Promise<void>; deleteById(id: string): Promise<void>; existsById(id: string): Promise<boolean>; }さらに進んで、重複を減らすために汎用リポジトリを作成することもできます。 簡潔にするために、ここではそれを行いません。このようなGenericRepositoryインターフェイスやGenericRepositoriesは、一般に、読み取り専用または書き込みの特定のエンティティがあるため、眉をひそめる傾向があることに注意してください。 -のみ、または削除できないもの、または同様のもの。 アプリケーションによって異なります。 また、テーブル間でトランザクションを共有するための「作業単位」の概念はありません。これは、現実の世界で実装する機能ですが、これも小さなデモなので、ありません。技術的になりすぎたい。
UserRepositoryを実装することから始めましょう。 ユーザーに固有のメソッドを保持するIUserRepositoryインターフェイスを定義します。これにより、依存性が具体的な実装を注入するときに、呼び出し元のコードがその抽象化に依存できるようになります。
interface IUserRepository extends IRepository<User> { existsByUsername(username: string): Promise<boolean>; } class UserRepository implements IUserRepository { // There are 6 methods to implement here all using the // concrete type of `User` - Five from IRepository<User> // and the one above. }タスクリポジトリは似ていますが、アプリケーションが適切と考えるように異なるメソッドが含まれます。
ここでは、汎用インターフェイスを拡張するインターフェイスを定義しているため、作業中の具象型を渡す必要があります。 両方のインターフェースからわかるように、これらのPOTOドメインモデルを送信して取得するという概念があります。 呼び出し元のコードは、基盤となる永続性メカニズムが何であるかを知りません。それがポイントです。
次に考慮すべきことは、選択したデータアクセス方法に応じて、データベース固有のエラーを処理する必要があるということです。 たとえば、MongooseまたはKnex Query Builderをこのリポジトリの背後に配置できます。その場合、これらの特定のエラーを処理する必要があります。ビジネスロジックにバブルアップして、関心の分離を破ることは望ましくありません。より大きな結合度を導入します。
エラーを処理できる、使用するデータアクセスメソッドのベースリポジトリを定義しましょう。
class BaseKnexRepository { // A constructor. /** * Wraps a likely to fail database operation within a function that handles errors by catching * them and wrapping them in a domain-safe error. * * @param dalOp The operation to perform upon the database. */ public async withErrorHandling<T>(dalOp: () => Promise<T>) { try { return await dalOp(); } catch (e) { // Use a proper logger: console.error(e); // Handle errors properly here. } } }これで、リポジトリ内のこの基本クラスを拡張して、そのジェネリックメソッドにアクセスできます。
interface IUserRepository extends IRepository<User> { existsByUsername(username: string): Promise<boolean>; } class UserRepository extends BaseKnexRepository implements IUserRepository { private readonly dbContext: Knex | Knex.Transaction; public constructor (private knexInstance: Knex | Knex.Transaction) { super(); this.dbContext = knexInstance; } // Example `findById` implementation: public async findById(id: string): Promise<User> { return this.withErrorHandling<User>(async () => { const dbUser = await this.dbContext<DbUser>() .select() .where({ user_id: id }) .first(); // Maps type DbUser to User return mapper.toDomain(dbUser); }); } // There are 5 methods to implement here all using the // concrete type of `User`. } この関数は、データベースからDbUserを取得し、それを返す前にUserドメインモデルにマップすることに注意してください。 これはデータマッパーパターンであり、関心の分離を維持するために重要です。 DbUserは、データベーステーブルへの1対1のマッピングであり、リポジトリが動作するデータモデルであるため、使用されるデータストレージテクノロジに大きく依存します。 このため、 DbUserはリポジトリを離れることはなく、返される前にUserドメインモデルにマップされます。 DbUserの実装は示していませんが、単純なクラスまたはインターフェイスである可能性があります。
これまでのところ、Genericsを利用したリポジトリパターンを使用して、データアクセスの懸念を小さな単位に抽象化し、型の安全性と再利用性を維持することができました。
最後に、ユニットテストと統合テストの目的で、メモリ内リポジトリの実装を維持して、テスト環境でそのリポジトリを挿入し、ディスク上で状態ベースのアサーションを実行できるようにするとします。モックフレームワーク。 このメソッドは、テストを実装の詳細に結合することを許可するのではなく、すべてを公開インターフェースに依存するように強制します。 各リポジトリ間の唯一の違いは、 ISomethingRepositoryインターフェイスで追加することを選択したメソッドであるため、汎用のメモリ内リポジトリを構築し、タイプ固有の実装内で拡張できます。
class InMemoryRepository<T extends IHasIdentity> implements IRepository<T> { protected entities: T[] = []; public findById(id: string): Promise<T> { const entityOrNone = this.entities.find(entity => entity.id === id); return entityOrNone ? Promise.resolve(entityOrNone) : Promise.reject(new NotFound()); } // Implement the rest of the IRepository<T> methods here. } この基本クラスの目的は、メモリ内ストレージを処理するためのすべてのロジックを実行して、メモリ内テストリポジトリ内でそれを複製する必要がないようにすることです。 findByIdのようなメソッドのため、このリポジトリはエンティティにidフィールドが含まれていることを理解する必要があります。そのため、 IHasIdentityインターフェイスの一般的な制約が必要です。 以前にこのインターフェースを見ました—それは私たちのドメインモデルが実装したものです。
これにより、メモリ内のユーザーまたはタスクリポジトリを構築する場合、このクラスを拡張して、ほとんどのメソッドを自動的に実装できます。
class InMemoryUserRepository extends InMemoryRepository<User> { public async existsByUsername(username: string): Promise<boolean> { const userOrNone = this.entities.find(entity => entity.username === username); return Boolean(userOrNone); // or, return !!userOrNone; } // And that's it here. InMemoryRepository implements the rest. } ここで、 InMemoryRepositoryは、エンティティにidやusernameなどのフィールドがあることを認識する必要があるため、ジェネリックパラメーターとしてUserを渡します。 UserはすでにIHasIdentityを実装しているため、一般的な制約が満たされ、 usernameプロパティもあることも示しています。
さて、ビジネスロジックレイヤーからこれらのリポジトリを使用したい場合、それは非常に簡単です。
class UserService { public constructor ( private readonly userRepository: IUserRepository, private readonly emailService: IEmailService ) {} public async createUser(dto: ICreateUserDTO) { // Validate the DTO: // ... // Create a User Domain Model from the DTO const user = userFactory(dto); // Persist the Entity await this.userRepository.add(user); // Send a welcome email await this.emailService.sendWelcomeEmail(user); } } (実際のアプリケーションでは、リクエストにレイテンシを追加しないように、また失敗時にべき等の再試行を実行できることを期待して、 emailServiceへの呼び出しをジョブキューに移動する可能性があることに注意してください(電子メールの送信は特にそうではありません)さらに、ユーザーオブジェクト全体をサービスに渡すことにも疑問があります。もう1つの問題は、ユーザーが永続化された後、電子メールが送信される前にサーバーがクラッシュする位置にいる可能性があることです。これを防ぐための緩和パターンがありますが、実用主義の目的では、適切なロギングを使用した人間の介入はおそらく問題なく機能します)。
そして、ジェネリックスの力でリポジトリパターンを使用して、DALをBLLから完全に切り離し、タイプセーフな方法でリポジトリとインターフェイスすることができました。 また、ユニットテストと統合テストの目的で、同等にタイプセーフなメモリ内リポジトリを迅速に構築する方法を開発しました。これにより、真のブラックボックステストと実装に依存しないテストが可能になります。 ジェネリック型がなければ、これは不可能でした。
免責事項として、このリポジトリの実装には多くの点が欠けていることにもう一度注意したいと思います。 ジェネリックスの利用に焦点が当てられているため、例を単純にしておきたかったので、重複を処理したり、トランザクションについて心配したりしませんでした。 適切なリポジトリの実装では、完全かつ正確に説明するためにすべての記事が必要になります。実装の詳細は、N層アーキテクチャとDDDのどちらを実行しているかによって異なります。 つまり、リポジトリパターンを使用する場合は、ここでの実装をベストプラクティスとして見るべきではありません。
実際の例— React State&Props
状態、ref、およびReact機能コンポーネントの残りのフックも汎用です。 Taskのプロパティを含むインターフェイスがあり、それらのコレクションをReactコンポーネントに保持したい場合は、次のように実行できます。
import React, { useState } from 'react'; export const MyComponent: React.FC = () => { // An empty array of tasks as the initial state: const [tasks, setTasks] = useState<Task[]>([]); // A counter: // Notice, type of `number` is inferred automatically. const [counter, setCounter] = useState(0); return ( <div> <h3>Counter Value: {counter}</h3> <ul> { tasks.map(task => ( <li key={task.id}> <TaskItem {...task} /> </li> )) } </ul> </div> ); }; さらに、一連の小道具を関数に渡したい場合は、一般的なReact.FC<T>タイプを使用して、 propsにアクセスできます。
import React from 'react'; interface IProps { id: string; title: string; description: string; } export const TaskItem: React.FC<IProps> = (props) => { return ( <div> <h3>{props.title}</h3> <p>{props.description}</p> </div> ); }; propsの種類は、TSコンパイラによって自動的にIPropsであると推測されます。
結論
この記事では、単純なコレクションからエラー処理アプローチ、データアクセス層の分離など、ジェネリックスとそのユースケースのさまざまな例を見てきました。 簡単に言うと、ジェネリックスを使用すると、コンパイル時に動作する具体的な時刻を知らなくても、データ構造を構築できます。 うまくいけば、これは主題をもう少し開き、ジェネリックの概念をもう少し直感的にし、彼らの真の力をもたらすのに役立つでしょう。