
ScrapyでスケーラブルなWebスクレイパーを構築するための究極のガイド
公開: 2022-03-10Webスクレイピングは、APIやWebサイトのデータベースにアクセスすることなく、Webサイトからデータを取得する方法です。 サイトのデータにアクセスするだけで済みます—ブラウザがデータにアクセスできる限り、データを取得することができます。
現実的には、ほとんどの場合、手動でWebサイトにアクセスし、コピーアンドペーストを使用して「手動で」データを取得できますが、多くの場合、手動作業に何時間もかかり、最終的にはコストがかかる可能性があります。特に、タスクを実行するために誰かを雇った場合は、データの価値よりもはるかに多くの価値があります。 プログラムに数秒ごとにクエリを自動的に実行させることができるのに、なぜクエリごとに1〜2分で作業する人を雇うのでしょうか。
たとえば、アカデミー作品賞の受賞者のリストを、監督、主演俳優、リリース日、実行時間とともにまとめたいとします。 Googleを使用すると、これらの映画を名前で一覧表示するサイトがいくつかあり、追加情報もあることがわかりますが、通常は、必要なすべての情報を取得するためにリンクをたどる必要があります。
明らかに、1927年から今日までのすべてのリンクを調べて、各ページから手動で情報を見つけようとするのは非現実的で時間がかかります。 Webスクレイピングでは、これらすべての情報を含むページを含むWebサイトを見つけて、適切な指示に従ってプログラムを適切な方向に向ける必要があります。
このチュートリアルでは、必要なすべての情報が含まれているWikipediaをWebサイトとして使用し、次にScrapy onPythonをツールとして使用して情報を取得します。
始める前のいくつかの注意事項:
データスクレイピングでは、スクレイピングするサイトのサーバー負荷を増やす必要があります。つまり、サイトをホストしている企業のコストが高くなり、そのサイトの他のユーザーのエクスペリエンスの品質が低下します。 Webサイトを実行しているサーバーの品質、取得しようとしているデータの量、およびサーバーに要求を送信する速度によって、サーバーへの影響が緩和されます。 これを念頭に置いて、いくつかのルールに固執することを確認する必要があります。
ほとんどのサイトでは、メインディレクトリにrobots.txtというファイルもあります。 このファイルは、サイトがスクレーパーにアクセスさせたくないディレクトリのルールを設定します。 通常、Webサイトの利用規約ページには、データスクレイピングに関するポリシーが記載されています。 たとえば、IMDBの条件ページには次の句があります。
ロボットとスクリーンスクレイピング:以下に記載されている書面による明示的な同意がない限り、このサイトでデータマイニング、ロボット、スクリーンスクレイピング、または同様のデータ収集および抽出ツールを使用することはできません。
ウェブサイトのデータを取得する前に、常にウェブサイトの利用規約とrobots.txtをチェックして、法的なデータを取得していることを確認する必要があります。 スクレーパーを構築するときは、サーバーが処理できない要求でサーバーを圧倒しないようにする必要もあります。
幸いなことに、多くのWebサイトは、ユーザーがデータを取得する必要性を認識しており、APIを介してデータを利用できるようにしています。 これらが利用可能な場合、通常、スクレイピングよりもAPIを介してデータを取得する方がはるかに簡単です。
ウィキペディアでは、 robots.txtで指定されているように、ボットが「速すぎない」限り、データのスクレイピングを許可しています。 また、ダウンロード可能なデータセットを提供しているため、ユーザーは自分のマシンでデータを処理できます。 速度が速すぎると、サーバーが自動的にIPをブロックするため、ルールを維持するためにタイマーを実装します。
はじめに、Pipを使用した関連ライブラリのインストール
まず、Scrapyをインストールしましょう。
ウィンドウズ
https://www.python.org/downloads/windows/から最新バージョンのPythonをインストールします
注: WindowsユーザーにはMicrosoft Visual C ++ 14.0も必要です。これは、こちらの「Microsoft Visual C ++ビルドツール」から入手できます。
また、最新バージョンのpipを使用していることを確認する必要があります。
cmd.exeに、次のように入力します。
python -m pip install --upgrade pip pip install pypiwin32 pip install scrapyこれにより、Scrapyとすべての依存関係が自動的にインストールされます。
Linux
まず、すべての依存関係をインストールする必要があります。
ターミナルで、次のように入力します。
sudo apt-get install python3 python3-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-devすべてインストールしたら、次のように入力します。
pip install --upgrade pippipが更新されていることを確認するには、次のようにします。
pip install scrapyそして、それはすべて完了しました。
マック
まず、システムにc-compilerがあることを確認する必要があります。 ターミナルで、次のように入力します。
xcode-select --installその後、https://brew.sh/からhomebrewをインストールします。
システムパッケージの前に自作パッケージが使用されるように、PATH変数を更新します。
echo "export PATH=/usr/local/bin:/usr/local/sbin:$PATH" >> ~/.bashrc source ~/.bashrcPythonをインストールします。
brew install pythonそして、すべてが更新されていることを確認します。
brew update; brew upgrade pythonそれが終わったら、pipを使用してScrapyをインストールするだけです。
pip install Scrapy > ## Scrapyの概要、ピースがどのように組み合わされるか、パーサー、スパイダーなどScrapyを実行するための「スパイダー」と呼ばれるスクリプトを作成しますが、心配しないでください。Scrapyスパイダーは、その名前にもかかわらず、まったく怖くありません。 Scrapyスパイダーと本物のスパイダーの唯一の類似点は、Web上をクロールするのが好きなことです。
スパイダーの中には、Scrapyに何をすべきかを指示する定義するclassがあります。 たとえば、クロールを開始する場所、クロールが行うリクエストの種類、ページ上のリンクをたどる方法、データを解析する方法などです。 ファイルに出力する前に、データを処理するカスタム関数を追加することもできます。
最初のスパイダーを開始するには、最初にScrapyプロジェクトを作成する必要があります。 これを行うには、コマンドラインに次のように入力します。
scrapy startproject oscarsこれにより、プロジェクトを含むフォルダーが作成されます。
基本的なスパイダーから始めましょう。 次のコードをPythonスクリプトに入力します。 /oscars/spidersで新しいPythonスクリプトを開き、 oscars_spider.pyという名前を付けます
Scrapyをインポートします。
import scrapy次に、Spiderクラスの定義を開始します。 最初に名前を設定し、次にスパイダーがスクレイプできるドメインを設定します。 最後に、どこからスクレイピングを開始するかをスパイダーに指示します。
class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ['https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture']次に、必要な情報を取得する関数が必要です。 今のところ、ページのタイトルを取得します。 CSSを使用して、タイトルテキストを含むタグを見つけ、それを抽出します。 最後に、情報をScrapyに返して、ログに記録したり、ファイルに書き込んだりします。
def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data 次に、コードを/oscars/spiders/oscars_spider.pyに保存します
このスパイダーを実行するには、コマンドラインに移動して次のように入力します。
scrapy crawl oscars次のような出力が表示されます。
2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars) ... 2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None) 2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture> {'title': ['Academy Award for Best Picture - Wikipedia']} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished) 2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats: {'downloader/request_bytes': 589, 'downloader/request_count': 2, 'downloader/request_method_count/GET': 2, 'downloader/response_bytes': 74517, 'downloader/response_count': 2, 'downloader/response_status_count/200': 2, 'finish_reason': 'finished', 'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319), 'item_scraped_count': 1, 'log_count/DEBUG': 3, 'log_count/INFO': 9, 'response_received_count': 2, 'robotstxt/request_count': 1, 'robotstxt/response_count': 1, 'robotstxt/response_status_count/200': 1, 'scheduler/dequeued': 1, 'scheduler/dequeued/memory': 1, 'scheduler/enqueued': 1, 'scheduler/enqueued/memory': 1, 'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)} 2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)
おめでとうございます。最初の基本的なScrapyスクレーパーを作成しました。

完全なコード:
import scrapy class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): data = {} data['title'] = response.css('title::text').extract() yield data明らかに、もう少し実行したいので、Scrapyを使用してデータを解析する方法を見てみましょう。
まず、Scrapyシェルについて理解しましょう。 Scrapyシェルは、コードをテストして、Scrapyが必要なデータを取得していることを確認するのに役立ちます。
シェルにアクセスするには、コマンドラインに次のように入力します。
scrapy shell “https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture”これにより、基本的に、指定したページが開き、1行のコードを実行できるようになります。 たとえば、次のように入力すると、ページの生のHTMLを表示できます。
print(response.text)または、次のように入力して、デフォルトのブラウザでページを開きます。
view(response)ここでの目標は、必要な情報を含むコードを見つけることです。 とりあえず、映画のタイトル名だけをつかんでみましょう。
必要なコードを見つける最も簡単な方法は、ブラウザでページを開いてコードを調べることです。 この例では、ChromeDevToolsを使用しています。 映画のタイトルを右クリックして、[検査]を選択します。
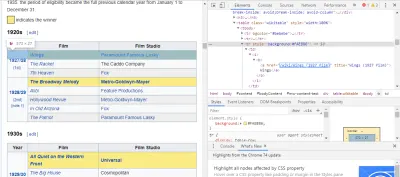
ご覧のとおり、オスカー受賞者の背景は黄色ですが、候補者の背景は無地です。 映画のタイトルに関する記事へのリンクもあり、映画のリンクは映画で終わりますfilm) 。 これがわかったので、CSSセレクターを使用してデータを取得できます。 Scrapyシェルに、次のように入力します。
response.css(r"tr[] a[href*='film)']").extract()ご覧のとおり、これですべてのオスカー作品賞受賞者のリストができました。
> response.css(r"tr[] a[href*='film']").extract() ['<a href="/wiki/Wings_(1927_film)" title="Wings (1927 film)">Wings</a>', ... '<a href="/wiki/Green_Book_(film)" title="Green Book (film)">Green Book</a>', '<a href="/wiki/Jim_Burke_(film_producer)" title="Jim Burke (film producer)">Jim Burke</a>']私たちの主な目標に戻って、私たちは、監督、主演俳優、リリース日、および実行時間とともに、最高の写真のためのオスカー受賞者のリストが必要です。 これを行うには、Scrapyがこれらの各映画ページからデータを取得する必要があります。
いくつか書き直して新しい関数を追加する必要がありますが、心配しないでください。非常に簡単です。
以前と同じ方法でスクレーパーを開始することから始めます。
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] しかし今回は、2つのことが変わります。 まず、ボットがスクレイプする速度を制限するタイマーを作成するため、 scrapyと一緒にtimeをインポートします。 また、最初にページを解析するときは、各タイトルへのリンクのリストのみを取得したいので、代わりにそれらのページから情報を取得できます。
def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req ここでは、ループを作成して、背景が黄色のfilm)で終わるページ上のすべてのリンクを探します。次に、それらのリンクをURLのリストに結合し、関数parse_titlesに送信してさらに渡します。 また、5秒ごとにのみページをリクエストするようにタイマーを入れています。 Scrapyシェルを使用してresponse.cssフィールドをテストし、正しいデータを取得していることを確認できることを忘れないでください。
def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield data 実際の作業は、 parse_data関数で行われます。この関数では、 dataという辞書を作成し、各キーに必要な情報を入力します。 繰り返しになりますが、これらのセレクターはすべて、前に示したようにChrome DevToolsを使用して検出され、Scrapyシェルでテストされました。
最後の行は、データディクショナリをScrapyに戻して保存します。
完全なコード:
import scrapy, time class OscarsSpider(scrapy.Spider): name = "oscars" allowed_domains = ["en.wikipedia.org"] start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"] def parse(self, response): for href in response.css(r"tr[] a[href*='film)']::attr(href)").extract(): url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) time.sleep(5) yield req def parse_titles(self, response): for sel in response.css('html').extract(): data = {} data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract() data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract() data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract() data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract() data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract() yield dataWebサイトがスクレイピングの試みをブロックしようとするため、プロキシを使用したい場合があります。
これを行うには、いくつかの変更を加えるだけで済みます。 この例を使用して、 def parse()で、次のように変更する必要があります。
def parse(self, response): for href in (r"tr[] a[href*='film)']::attr(href)").extract() : url = response.urljoin(href) print(url) req = scrapy.Request(url, callback=self.parse_titles) req.meta['proxy'] = "https://yourproxy.com:80" yield reqこれにより、プロキシサーバーを介してリクエストがルーティングされます。
展開とロギング、本番環境でスパイダーを実際に管理する方法を示します
今度はスパイダーを実行します。 Scrapyでスクレイピングを開始してからCSVファイルに出力するには、コマンドプロンプトに次のように入力します。
scrapy crawl oscars -o oscars.csv大きな出力が表示され、数分後に完了し、CSVファイルがプロジェクトフォルダーに保存されます。
結果のコンパイル、前の手順でコンパイルされた結果の使用方法を示します
CSVファイルを開くと、必要なすべての情報が表示されます(見出しのある列でソートされています)。 とても簡単です。
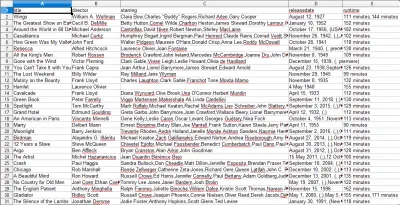
データスクレイピングを使用すると、情報が公開されている限り、必要なほぼすべてのカスタムデータセットを取得できます。 このデータで何をしたいかはあなた次第です。 このスキルは、市場調査を行ったり、Webサイトの情報を最新の状態に保つなど、さまざまなことに非常に役立ちます。
独自のWebスクレイパーを設定して独自のカスタムデータセットを取得するのはかなり簡単ですが、必要なデータを取得する方法は他にもある可能性があることを常に忘れないでください。 企業はあなたが望むデータを提供することに多くの投資をしているので、私たちが彼らの利用規約を尊重するのは公正なことです。
ScrapyおよびWebスクレイピング全般についてさらに学ぶための追加リソース
- 公式のScrapyWebサイト
- ScrapyのGitHubページ
- 「10のベストデータスクレイピングツールとWebスクレイピングツール」、Scraper API
- 「ブロックまたはブラックリストに登録せずにWebスクレイピングを行うための5つのヒント」ScraperAPI
- 正規表現を使用してHTMLからデータを抽出するPythonライブラリであるParsel。