
レコメンデーションシステムの機械学習を構築するための簡単なガイド[2022]
公開: 2021-03-11今日のインターネットビジネスのほとんどは、パーソナライズされたユーザーエクスペリエンスを提供する傾向があります。 機械学習のレコメンデーションシステムは、ユーザーが興味を持つ可能性のあるコンテンツに関するパーソナライズされたレコメンデーションをユーザーに提供する、特定のタイプのパーソナライズされたWebベースのアプリケーションです。 レコメンデーションシステムは、レコメンダーシステムとも呼ばれます。
目次
レコメンデーションシステムとは何ですか?
機械学習のレコメンデーションシステムは、ユーザーにとっての一連の要件を予測し、必要となる可能性のある上位のものを推奨することができます。
レコメンデーションシステムは、企業に適用される機械学習テクノロジーの最も普及しているアプリケーションの1つです。
大規模なレコメンデーションシステムは、小売店、ビデオオンデマンド、または音楽ストリーミングで見つけることができます。
レコメンデーションシステムは、独自のデータ公開モデルの一部をロボット化しようとします。このモデルでは、個人が同等の好みを持つ他の人を発見しようとし、後で新しいアイテムを推奨するように要求します。
世界のトップ大学(修士、エグゼクティブ大学院プログラム、ML&AIの高度な証明書プログラム)からオンラインで機械学習コースに参加して、キャリアを早急に進めましょう。

レコメンデーションシステムの種類
- パーソナライズ-あなたの興味に基づいた推薦。
- パーソナライズされていない-他の顧客が現在見ているもの。
レコメンデーションシステムの必要性は何ですか?
機械学習でレコメンデーションシステムが必要な主な理由の1つは、インターネットのおかげで、人々が購入できる選択肢が多すぎることです。
以前は、品物の在庫が限られていた実店舗で買い物をしていました。
たとえば、ビデオレンタル店に配置される映画の数は、店のサイズによって異なります。 Webを使用すると、人々は多くのオンラインリソースにアクセスできます。 Netflixには素晴らしい映画のコレクションがあります。 入手可能な情報の量が増えるにつれ、新たな問題が発生し、人々はさまざまな選択肢から選択するのが難しいことに気づきました。 そのため、レコメンデーションシステムが使用されるようになりました。
レコメンデーションシステムはどこで使用されていますか?
- 大規模なeコマースサイトは、このツールを使用して、消費者が購入したいと思う可能性のあるアイテムを提案します。
- Webのパーソナライズ。
レコメンデーションシステムはどのように機能しますか?
- 他のクライアントの間で一般的に人気のあるものをクライアントに提案することができます。
- 私たちは、クライアントを製品の選択に従っていくつかのグループに分け、彼らが購入する可能性のあるものを提案することができます。
上記の手法には両方とも欠点があります。 最初のケースでは、最も人気のある主流のものはすべてのクライアントで同じです。 したがって、おそらく誰もが同様の提案を受け取るでしょう。 2つ目では、クライアントの数が増えると、提案として強調表示されるものの数も増えます。 したがって、すべてのクライアントを異なるセクションにグループ化することは困難です。
次に、レコメンデーションシステムがどのように機能するかを見ていきます。
データ収集
これは、レコメンデーションシステムを作成するための最初の最も重要なステップです。 情報は、明示的および暗黙的の2つの方法で収集されることがよくあります。
明示的な情報は、意図的に提供されたデータ、つまり、映画レビューなどのクライアントによる貢献です。 暗黙的な情報とは、意図的に提供されていないが、クリック、検索履歴、リクエスト履歴などのアクセス可能な情報ストリームから収集されたデータです。
データリポジトリ
情報の量は、モデルの提案の正直さを示しています。 情報タイプは、大規模な母集団からデータを選択する上で重要な役割を果たします。 容量は、標準のSQLおよびNoSQL情報ベース、または記事の備蓄の形式で構成できます。
データフィルタリング
収集および保存後、このデータをフィルタリングして、最終的な推奨事項を作成するための情報を抽出する必要があります。 さまざまなアルゴリズムにより、フィルタリングプロセスが簡単になります。
レコメンデーションシステムのアルゴリズム
ソフトウェアシステムは、アイテム/ユーザーの過去の反復と属性を利用してユーザーに提案を提供します。
レコメンデーションシステムを構築する方法は2つあります。
1.コンテンツベースの推奨
- アイテム/ユーザーの属性を使用します
- 過去にユーザーが気に入ったものと同様のアイテムをお勧めします
2.協調フィルタリング
- 類似ユーザーが気に入ったアイテムをおすすめする
- 多様なコンテンツの探索を可能にする
コンテンツベースの推奨事項
教師あり機械学習は、分類器を誘導して、興味深いユーザーアイテムと興味のないユーザーアイテムを区別します。

レコメンデーションシステムの目的は、ユーザーの評価されていないもののスコアを予測することです。 コンテンツフィルタリングの背後にある基本的な考え方は、すべてにいくつかのハイライトxがあるということです。
たとえば、映画「Love at last」は恋愛映画であり、ハイライトx1のスコアは高く、x2のスコアは低くなっています。
(映画の評価データ)
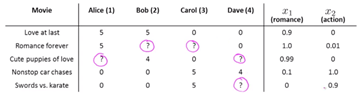
ソース
すべての個人には、恋愛映画がどれだけ好きか、アクション映画がどれだけ好きかを示すパラメータθがあります。
θ=[1、0.1]の場合、個人は恋愛映画が好きですが、アクション映画は好きではありません。
すべての個人の線形回帰で最適なθを見つけることができます。
(表記)
r(i、j):ユーザーjが映画iを評価した場合は1(それ以外の場合は0)
y(i、j):映画iのユーザーjの評価(定義されている場合)
θ(j):ユーザーベクトルパラメーター
x(i):映画iの特徴ベクトル
予測評価[ユーザーj、映画i] :(θ(j))ᵀx(i)
m(j):#映画ユーザーのjレートの数
nᵤ:ユーザー数
n:映画の特徴の数
読む:機械学習プロジェクトのアイデアとトピック
協調フィルタリング
コンテンツフィルタリングの欠点は、すべてのサイドデータが必要になることです。
たとえば、恋愛やアクションなどの分類は、映画のサイドデータです。 映画を見たり、各映画のサイドデータを追加したりする人を見つけるのはコストがかかります。
基本的な仮定
- 同様の関心を持つユーザーには、共通の好みがあります。
- 十分な数のユーザー設定が利用可能です。
主なアプローチ
- ユーザーベース
- アイテムベース
映画のすべての機能をどのようにリストアップできるでしょうか。 新しい機能を追加したい場合はどうなりますか? すべての映画に新機能を追加する必要がありますか?
協調フィルタリングはこの問題を解決します。
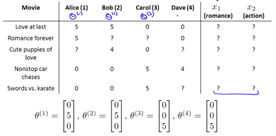
(映画の特徴を予測します)出典
機械学習におけるレコメンデーションシステムの問題とメンテナンス
問題
- 不確定なユーザー入力構造
- 批評研究に参加するユーザーを探しています
- 弱い計算
- 悪い結果
- 貧弱な情報
- 情報の欠如
- プライバシー管理(領収書と明確に連携しない場合があります)
メンテナンス
- 費用がかかる
- 情報は時代遅れになります
- 情報の質(巨大なサークルスペース開発)
機械学習の推奨システムは、情報検索、テキスト分類、機械学習、データマイニング、知識ベースシステムなどのさまざまなセクションからのさまざまな方法の適用など、さまざまな研究分野にルーツがあります。
レコメンデーションシステムの未来
- 持ち帰ったものを調べて、理解した否定的な評価を抽出します。
- 地域を提案に組み込む方法。
- レコメンデーションシステムは、アイテムへの関心を予測するために後で利用され、店舗ネットワークへの事前の連絡を可能にします。
upGradを使用して機械学習のキャリアをアップグレードする
機械学習について詳しく知りたい場合は、IIIT-BとupGradの機械学習とAIのエグゼクティブPGプログラムをご覧ください。このプログラムは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディと課題、IIITを提供しています。 -B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との雇用支援。
実生活のどこでレコメンデーションシステムを見つけることができますか?
レコメンデーションシステムまたはレコメンダーシステムは、機能するために機械学習を使用するデータフィルタリングアプリケーションとして概念化できます。 レコメンデーションシステムは、今日、最も関連性の高い製品またはサービスについて特定のユーザーグループまたは個々の消費者にレコメンデーションを送信するために広く使用されています。 顧客行動データ内に隠された特定のパターンを検索し、明示的または暗黙的に情報を収集し、それに応じて推奨事項を生成します。 レコメンデーションシステムを使用する最も評判の高いブランドには、Google、Netflix、Facebook、Amazonなどのグローバル組織があります。 実際、調査によると、Amazonの購入全体の35%は製品の推奨によるものです。
今日、どの企業が人工知能を使用していますか?
顧客体験の向上から業界全体のビジネス生産性の向上、運用効率の向上に始まり、今日、組織は人工知能に多額の投資を行っています。 実際、故意または無意識のうちに、私たち全員は日常生活においても常に人工知能にさらされています。 テスラ、アップル、グーグルの他に、今日AIをうまく利用している有名な組織には、Twitter、Uber、Amazon、YouTubeなどの名前があります。Twitterは2017年から人工知能と自然言語処理を採用しており、Netflixはその全体に焦点を当てています。データとAIに関する操作。
今日のインドでトップのAIの仕事は何ですか?
人工知能の分野で大規模な開発が進行中であり、人工知能の専門家に対する市場では前例のない需要がありました。 その結果、この業界は、この技術分野でニッチを切り開きたいと考えている人々にとって非常に有望であるように見えます。 今日の人工知能の分野でトップランクの仕事には、主要なデータサイエンティスト、AIリサーチエンジニア、コンピューターサイエンティスト、機械学習エンジニアの役割が含まれ、仕事の経験に基づいて、年収は9.5〜18万ルピー以上になります。 、スキルセット、およびその他のさまざまな要因。