
UXデザイナーのための定量的データツール
公開: 2022-03-10多くのUXデザイナーは、統計と数学の深い知識が必要であると信じて、データをいくらか恐れています。 これは高度なデータサイエンスには当てはまるかもしれませんが、ほとんどのUXデザイナーが必要とする基礎研究データ分析には当てはまりません。 私たちはますますデータ主導の世界に住んでいるため、基本的なデータリテラシーは、UXデザイナーだけでなく、ほとんどすべての専門家に役立ちます。
GoogleのインタラクションデザイナーであるAaronGitlinは、多くのデザイナーはまだデータ駆動型ではないと主張しています。
「多くの企業はデータ主導型であると宣伝していますが、ほとんどの設計者は本能、コラボレーション、および定性的調査方法によって推進されています。」
— Aaron Gitlin、「データ対応デザイナーになる」
この記事では、UXデザイナーにデータを日常業務に組み込むための知識とツールを提供したいと思います。
しかし、最初に、いくつかのデータの概念
この記事では、構造化データ、つまり行と列を含むテーブルで表すことができるデータについて説明します。 Devin Pickell(G2 Crowdのコンテンツマーケティングスペシャリスト、データと分析について書いている)が彼の記事「構造化データと非構造化データ–違いは何ですか?」で指摘したように、非構造化データはそれ自体が主題であるため、分析がより困難です。 構造化データを表形式で表すことができる場合、主な概念は次のとおりです。
データセット
分析する予定のデータセット全体。 これは、たとえば、Excelテーブルである可能性があります。 データセットを保存するためのもう1つの一般的な形式は、コンマ区切り値ファイル(CSV)です。 CSVファイルは、テーブルのような情報を保存するために使用される単純なテキストファイルです。 各CSV行はテーブル内の行に対応し、各CSV行には、テーブルセルに対応するコンマで(自然に)区切られた値があります。
データポイント
データセットテーブルの1つの行がデータポイントです。 このように、データセットはデータポイントのコレクションです。
データ変数
データポイント行の単一の値は、データ変数を表します。簡単に言うと、テーブルセルです。 データ変数には、質的変数と量的変数の2種類があります。 質的変数(カテゴリ変数とも呼ばれます)には、 color = red/green/blueなどの個別の値のセットがあります。 量的変数には、 height = 167などの数値があります。 量的変数は、質的変数とは異なり、任意の値を取ることができます。
データプロジェクトの作成
これで基本がわかったので、手を汚して最初のデータプロジェクトを作成します。 プロジェクトの範囲は、データのインポート、処理、およびプロットのデータフロー全体を実行することにより、データセットを分析することです。 まず、データセットを選択し、次にデータを分析するためのツールをダウンロードしてインストールします。
車のデータセット
この記事では、シンプルで直感的な車のデータセットを選択しました。 データ分析では、車についてすでに知っていることを簡単に確認できます。データフローとツールに重点を置いているため、これは問題ありません。
無料のデータセットの最大のソースの1つであるKaggleから中古車のデータセットをダウンロードできます。 最初に登録する必要があります。
ファイルをダウンロードしたら、ファイルを開いて確認してください。 非常に大きなCSVファイルですが、要点を理解する必要があります。 このファイルの行は次のようになります。
19500,2015,2965,Miami,FL,WBA3B1G54FNT02351,BMW,3ご覧のとおり、このデータポイントには、コンマで区切られたいくつかの変数があります。 データセットができたので、ツールについて少し話しましょう。
貿易の道具
R言語とRStudioを使用してデータセットを分析します。 Rは非常に人気があり、習得しやすい言語であり、データサイエンティストだけでなく、金融市場、医学、その他多くの分野の人々にも使用されています。 RStudioはRプロジェクトが開発される環境であり、UXデザイナーとしての私たちのニーズには十分すぎるほどの無料バージョンがあります。
一部のUXデザイナーは、データワークフローにExcelを使用している可能性があります。 それがあなたを意味するなら、Rを試してみてください—習得が簡単で、Excelよりも柔軟で強力なので、あなたがそれを好きになる可能性が高いです。 ツールキットにRを追加すると、違いが生じます。
ツールのインストール
まず、RとRStudioをダウンロードしてインストールする必要があります。 最初にRをインストールし、次にRStudioをインストールする必要があります。 RとRStudioの両方のインストールプロセスはシンプルで簡単です。
プロジェクトの設定
インストールが完了したら、プロジェクトフォルダを作成します—私はそれをused-cars-prjと呼んでいます。 そのフォルダーに、 dataというサブフォルダーを作成し、データセットファイル(Kaggleからダウンロード)をそのフォルダーにコピーして、名前をused-cars.csvに変更します。 次に、プロジェクトフォルダ( used-cars-prj )に戻り、 used-cars.rという名前のプレーンテキストファイルを作成します。 以下のスクリーンショットと同じ構造になります。
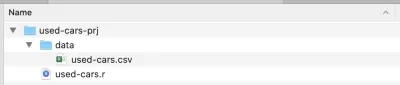
これでフォルダ構造が整いました。RStudioを開いて新しいRプロジェクトを作成できます。 [ファイル]メニューから[新しいプロジェクト... ]を選択し、2番目のオプションである[既存のディレクトリ]を選択します。 次に、プロジェクトディレクトリ( used-cars-prj )を選択します。 最後に、[プロジェクトの作成]ボタンを押すと完了です。 プロジェクトが作成されたら、RStudioでused-cars.rを開きます—これはすべてのRコードを追加するファイルです。
データのインポート
used-cars.csvファイルからデータを読み取るために、 used-cars.rに最初の行を追加します。 CSVファイルは、データの保存に使用される単なるプレーンテキストファイルであることに注意してください。 Rコードの最初の行は次のようになります。
cars <- read.csv("./data/used-cars.csv", stringsAsFactors = FALSE, sep=",") 少し威圧的に見えるかもしれませんが、実際にはそうではありません—ちなみに、これは記事全体の中で最も複雑な行です。 ここにあるのは、3つのパラメーターをread.csv関数です。
最初のパラメーターは、読み取るファイルです。この場合は、データフォルダーにあるused-cars.csvです。 2番目のパラメーターstringsAsFactors=FALSEは、「BMW」や「Audi」などの文字列がファクター(カテゴリデータのR用語)に変換されないようにするために設定されます。覚えているように、定性変数またはカテゴリ変数は、次のような離散値のみを持つことができます。 red/green/blue 。 最後に、3番目のパラメーターsep=","は、CSVファイルの値を区切るために使用される区切り文字の種類(コンマ)を指定します。
CSVファイルを読み取った後、データはcarsのデータフレームオブジェクトに保存されます。 データフレームは2次元のデータ構造(Excelテーブルのような)であり、Rでデータを操作するのに非常に便利です。 ラインを導入して実行すると、 carsのデータフレームが作成されます。 RStudioの右上の象限を見ると、[環境]タブの[データ]セクションにcarsのデータフレームがあります。 車をダブルクリックすると、RStudioの左上の象限に新しいタブが開き、 carsのデータフレームが表示されます。 ご想像のとおり、Excelテーブルのように見えます。
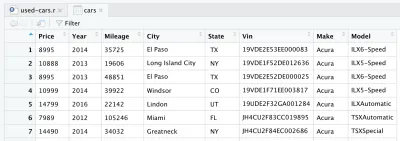
これは実際にはKaggleからダウンロードした生データです。 ただし、データ分析を実行するため、最初にデータセットを処理する必要があります。
情報処理
処理とは、実行したい種類の分析に備えるために、データセットに情報を削除、変換、または追加することを意味します。 データはデータフレームオブジェクトにあるので、データを操作するための強力なライブラリであるdplyrライブラリをインストールする必要があります。 ライブラリをR環境にインストールするには、Rファイルの先頭に次の行を書き込む必要があります。
install.packages("dplyr")次に、ライブラリを現在のプロジェクトに追加するために、次の行を使用します。
library(dplyr) dplyrライブラリがプロジェクトに追加されると、データの処理を開始できます。 非常に大きなデータセットがあり、価格と相関させるために必要なのは、同じ自動車メーカーとモデルを表すデータだけです。 次のRコードを使用して、BMW 3シリーズに関するデータのみを保持し、残りを削除します。 もちろん、データセットから他のメーカーとモデルを選択して、同じデータ特性を持つことを期待できます。
cars <- cars %>% filter(Make == "BMW", Model == "3")これで、11,000を超えるデータポイントが含まれているものの、より管理しやすいデータセットが得られました。これは、車の価格、年齢、走行距離の分布、およびそれらの間の相関関係を分析するという目的に適合しています。 そのためには、「Price」、「Year」、「Mileage」の列のみを保持し、残りを削除する必要があります。これは次の行で実行されます。
cars <- cars %>% select(Price, Year, Mileage)他の列を削除すると、データフレームは次のようになります。

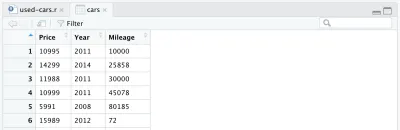
データセットに加えたいもう1つの変更があります。それは、製造年を車の年齢に置き換えることです。 次の2行を追加できます。最初の行は年齢を計算し、2番目の行は列名を変更します。
cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)最後に、完全に処理されたデータフレームは次のようになります。
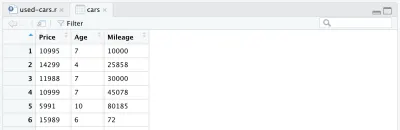
この時点で、Rコードは次のようになります。これでデータ処理は完了です。 これで、R言語がいかに簡単で強力であるかがわかります。 ほんの数行のコードで、初期データセットを非常に劇的に処理しました。
install.packages("dplyr") library(dplyr) cars = read.csv("./data/cars.csv", stringsAsFactors = FALSE, sep=",") cars <- cars %>% filter(Make == "BMW", Model == "3") cars <- cars %>% select(Price, Year, Mileage) cars <- cars %>% mutate(Year = max(Year) - Year) cars <- cars %>% rename(Age = Year)データ分析
データは正しい形になっているので、いくつかのプロットを作成することができます。 すでに述べたように、個々の変数の分布とそれらの間の相関という2つの側面に焦点を当てます。 変動分布は、中古車の中価格または高価格と見なされるもの、または特定の価格を超える車の割合を理解するのに役立ちます。 同じことが車の年齢と走行距離にも当てはまります。 一方、相関関係は、年齢や走行距離などの変数が互いにどのように関連しているかを理解するのに役立ちます。
とはいえ、変数分布のヒストグラムと相関の散布図の2種類のデータ視覚化を使用します。
価格分布
車の価格ヒストグラムをR言語でプロットするのは、次のように簡単です。
hist(cars$Price)ちょっとしたヒント:RStudioを使用している場合は、コードを1行ずつ実行できます。 たとえば、この場合、ヒストグラムを表示するには上の行だけを実行する必要があります。 すでに一度実行したので、すべてのコードを再度実行する必要はありません。 ヒストグラムは次のようになります。
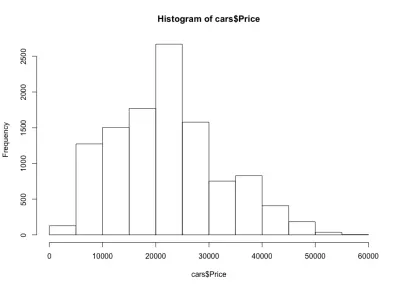
ヒストグラムを見ると、車の価格がベルのように分布していることがわかります。これは予想どおりです。 ほとんどの車はミドルレンジにあり、それぞれの側に移動するにつれて、私たちはますます少なくなっています。 車のほぼ80%は10,000ドルから30,000ドルの間であり、最大で2,500台以上の車が20,000ドルから25,000ドルの間です。 左側にはおそらく5,000米ドル未満の車が約150台あり、右側にはさらに少ない車があります。 このようなプロットがデータへの洞察を得るのにどれほど役立つかを簡単に理解できます。
年齢分布
車の価格と同じように、同様の線を使用して車の年齢ヒストグラムをプロットします。
hist(cars$Age)そして、ここにヒストグラムがあります:
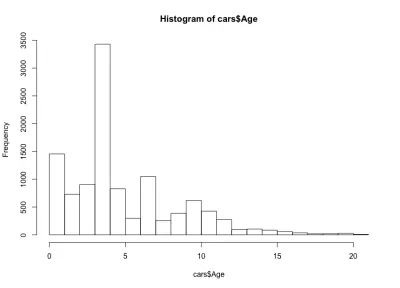
今回のヒストグラムは直感に反しているように見えます—単純なベルの形ではなく、ここに4つのベルがあります。 基本的に、ディストリビューションには3つのローカル最大値と1つのグローバル最大値がありますが、これは予想外のことです。 車の年齢のこの奇妙な分布が他の自動車メーカーとモデルに当てはまるかどうかを確認するのは興味深いでしょう。 この記事では、BMW 3シリーズのデータセットを使用しますが、興味がある場合は、データをさらに深く掘り下げることができます。 車の年齢分布については、90%以上が10年未満、80%以上が7年未満であることがわかります。 また、車の大部分は5年未満のものであることがわかります。
マイレージ配分
さて、マイレージについて何が言えますか? もちろん、私たちは価格で持っていたのと同じベルの形を期待しています。 Rコードとヒストグラムは次のとおりです。
hist(cars$Mileage) 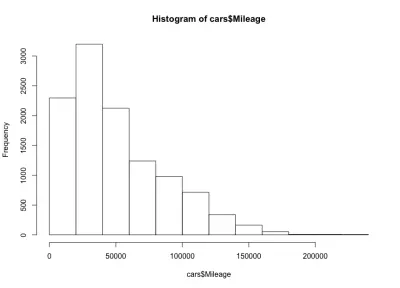
ここでは、左に曲がったベルの形をしています。つまり、市場には走行距離の少ない車が増えています。 また、大多数の車の走行距離は60,000マイル未満であり、最大距離は20,000〜40,000マイルです。
年齢と価格の相関関係
相関関係については、車の年齢と価格の相関関係を詳しく見てみましょう。 価格は年齢と負の相関関係があると予想されるかもしれません。車の年齢が上がると、価格は下がります。 R plot関数を使用して、次のように価格と年齢の相関関係を表示します。
plot(cars$Age, cars$Price)そして、プロットは次のようになります。
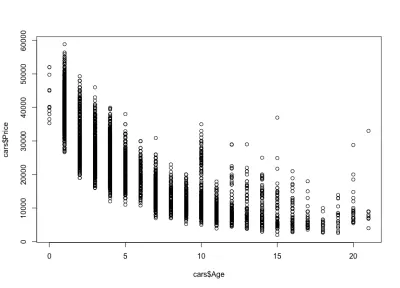
車の価格が年齢とともにどのように下がるかに気づきます。高価な新車と安価な古い車があります。 また、特定の年齢の価格変動間隔も確認できます。変動は、車の年齢とともに減少します。 この変動は、主に走行距離、構成、および車の全体的な状態によって決まります。 たとえば、4年前の車の場合、価格は10,000ドルから40,000ドルの間で変動します。
マイレージと年齢の相関関係
マイレージと年齢の相関関係を考慮すると、マイレージは年齢とともに増加すると予想されます。これは、正の相関関係を意味します。 コードは次のとおりです。
plot(cars$Mileage, cars$Age)そしてここにプロットがあります:
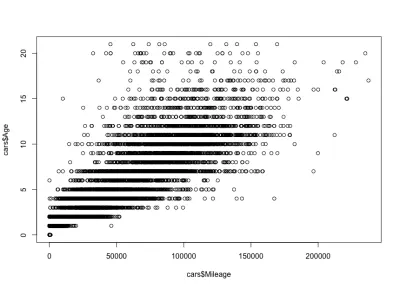
ご覧のとおり、車の価格と年齢は負の相関関係にありますが、車の年齢と走行距離は正の相関関係にあります。 また、特定の年齢で予想される走行距離の変動もあります。 つまり、同じ年齢の車の走行距離はさまざまです。 たとえば、ほとんどの4年前の車の走行距離は、10,000〜80,000マイルです。 しかし、より大きなマイレージを持つ外れ値もあります。
マイレージと価格の相関関係
予想通り、車の走行距離と価格の間には負の相関関係があります。つまり、走行距離を増やすと価格が下がります。
plot(cars$Mileage, cars$Price)そしてここにプロットがあります:
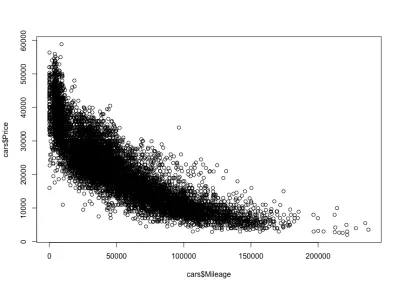
予想通り、負の相関関係。 また、総額が3,000ドルから50,000ドルの間、走行距離が0から150,000ドルの間であることがわかります。 分布の形を詳しく見ると、走行距離が長い車よりも走行距離が少ない車の方がはるかに早く価格が下がることがわかります。 走行距離がほぼゼロの車があり、価格が劇的に下がります。 また、走行距離が非常に長いため、200,000マイルを超える範囲では価格が一定に保たれます。
数値からデータの視覚化まで
この記事では、データ分布のヒストグラムとデータ相関の散布図の2種類の視覚化を使用しました。 ヒストグラムは、データ変数(実際の数値)の値を取得し、それらが範囲全体にどのように分布しているかを示す視覚的な表現です。 R hist()関数を使用してヒストグラムをプロットしました。
一方、散布図は、数値のペアを取り、それらを2つの軸で表します。 散布図はplot()関数を使用し、2つのパラメーターを提供します。調査する相関の最初と2番目のデータ変数です。 したがって、2つのR関数hist()とplot()は、意味のある視覚的表現で数値のセットを変換するのに役立ちます。
結論
データのインポート、処理、およびプロットのデータフロー全体を処理することで手を汚したため、状況ははるかに明確になりました。 遭遇する光沢のある新しいデータセットに同じデータフローを適用できます。 たとえば、ユーザーリサーチでは、タスクまたはエラーの分布に関する時間をグラフ化できます。また、タスクとエラーの相関関係に関する時間をプロットすることもできます。
R言語の詳細については、Quick-Rから始めることをお勧めしますが、Rブロガーを検討することもできます。 dplyrなどのRパッケージに関するドキュメントについては、 dplyrにアクセスしてください。 データで遊ぶのは楽しいこともありますが、データ駆動型の世界のUXデザイナーにとっても非常に役立ちます。 より多くのデータが収集され、ビジネス上の意思決定に情報を提供するために使用されるにつれて、データの性質を理解することが不可欠なデータの視覚化またはデータ製品に取り組むデザイナーの機会が増えます。