
Node.jsとRedisを使用して社内でPub / Subサービスを構築する
公開: 2022-03-10今日の世界はリアルタイムで動作します。 株の取引であろうと食品の注文であろうと、今日の消費者は即座の結果を期待しています。 同様に、ニュースであろうとスポーツであろうと、私たちは皆すぐに物事を知ることを期待しています。 言い換えれば、ゼロは新しいヒーローです。
これはソフトウェア開発者にも当てはまります—おそらく最もせっかちな人々の何人かです! BrowserStackの話に飛び込む前に、Pub / Subについての背景情報を提供しないのは私の怠慢です。 基本に精通している方は、次の2つの段落をスキップしてください。
今日の多くのアプリケーションは、リアルタイムのデータ転送に依存しています。 例を詳しく見てみましょう:ソーシャルネットワーク。 FacebookやTwitterのようなものは、関連するフィードを生成し、あなたは(彼らのアプリを介して)それを消費し、あなたの友人をスパイします。 彼らはメッセージング機能でこれを達成します。ユーザーがデータを生成すると、他のユーザーが瞬く間に消費できるように投稿されます。 大幅な遅延やユーザーからの不満はあり、使用量は減少し、それが続く場合は解約します。 賭け金は高く、ユーザーの期待も高くなります。 では、WhatsApp、Facebook、TD Ameritrade、Wall Street Journal、GrubHubなどのサービスは、大量のリアルタイムデータ転送をどのようにサポートしているのでしょうか。
それらはすべて、一般にPub / Subと呼ばれる「パブリッシュ/サブスクライブ」モデルと呼ばれる高レベルの同様のソフトウェアアーキテクチャを使用します。
「ソフトウェアアーキテクチャでは、パブリッシュ/サブスクライブは、パブリッシャーと呼ばれるメッセージの送信者が、サブスクライバーと呼ばれる特定の受信者に直接送信されるメッセージをプログラムせず、代わりに、サブスクライバーと呼ばれる特定の受信者にメッセージを分類するメッセージングパターンです。いずれか、あるかもしれません。 同様に、サブスクライバーは1つ以上のクラスに関心を示し、関心のあるメッセージのみを受信します。発行者が存在するかどうかはわかりません。」
—ウィキペディア
定義に飽きましたか? 話に戻りましょう。
BrowserStackでは、すべての製品が、テストログの自動化、焼きたてのブラウザスクリーンショット、15 fpsのモバイルストリーミングなど、実質的なリアルタイムの依存関係コンポーネントを備えたソフトウェアを(何らかの形で)サポートしています。
このような場合、1つのメッセージがドロップすると、顧客はバグを防ぐために不可欠な情報を失う可能性があります。 したがって、さまざまなデータサイズ要件に合わせてスケーリングする必要がありました。 たとえば、特定の時点でのデバイスロガーサービスでは、1つのメッセージで50MBのデータが生成される場合があります。 このようなサイズでは、ブラウザがクラッシュする可能性があります。 言うまでもなく、BrowserStackのシステムは、将来、追加の製品に合わせて拡張する必要があります。
各メッセージのデータサイズは数バイトから最大100MBまで異なるため、多数のシナリオをサポートできるスケーラブルなソリューションが必要でした。 言い換えれば、私たちはすべてのケーキを切ることができる剣を探しました。 この記事では、Pub / Subサービスを社内で構築する理由、方法、および結果について説明します。
BrowserStackの実際の問題のレンズを通して、独自のPub / Subを構築するための要件とプロセスをより深く理解することができます。
Pub / Subサービスの必要性
BrowserStackには約1億以上のメッセージがあり、各メッセージは約2バイトから100MB以上の間です。 これらは、すべて異なるインターネット速度で、いつでも世界中に渡されます。
これらのメッセージの最大のジェネレーターは、メッセージサイズで、BrowserStackAutomate製品です。 どちらにも、ユーザーテストの各コマンドのすべての要求と応答を表示するリアルタイムダッシュボードがあります。 したがって、誰かが100のリクエストでテストを実行し、平均リクエスト/レスポンスサイズが10バイトの場合、これは1×100×10 = 1000バイトを送信します。
ここで、全体像を、もちろん、1日に1つのテストだけを実行するのではないと考えてみましょう。 BrowserStackを使用して、約850,000を超えるBrowserStackAutomateおよびAppAutomateテストが毎日実行されています。 はい、テストごとに平均して約235の要求/応答があります。 ユーザーはSeleniumでスクリーンショットを撮ったり、ページソースを要求したりできるため、要求と応答の平均サイズは約220バイトです。
では、計算機に戻りましょう。
850,000×235×220 = 43,945,000,000バイト(約)または1日あたりわずか43.945GB
それでは、BrowserStackLiveとAppLiveについて話しましょう。 確かに、データのサイズの形で勝者としてAutomateがあります。 ただし、渡されるメッセージの数に関しては、Live製品が主導権を握っています。 ライブテストごとに、毎分約20のメッセージが渡されます。 約100,000のライブテストを実行します。各テストの平均は約12分で、次のことを意味します。
100,000×12×20 = 1日あたり24,000,000メッセージ
ここで、驚くべき注目すべき点について説明します。ec2の6つのt1.microインスタンスを使用して、このいわゆるプッシャーのアプリケーションを構築、実行、および維持します。 サービスの実行コストは? 月額約70ドル。
構築するか購入するかを選択する
まず最初に:スタートアップとして、他のほとんどの人と同じように、私たちは常に社内で物を作ることに興奮していました。 しかし、まだいくつかのサービスを評価しました。 私たちが持っていた主な要件は次のとおりです。
- 信頼性と安定性、
- 高性能、そして
- 費用対効果。
月額70ドル未満の外部サービスは考えられないので、費用対効果の基準は省きましょう(そうしていることを知っているなら、私にツイートしてください!)。 だから私たちの答えは明らかです。
信頼性と安定性の観点から、99.9%以上の稼働率のSLAを備えたサービスとしてPub / Subを提供している企業が見つかりましたが、多くのT&Cが付属していました。 特に、システムとクライアントの間にあるオープンインターネットの広大な土地を考えると、問題は思ったほど単純ではありません。 インターネットインフラストラクチャに精通している人なら誰でも、安定した接続が最大の課題であることを知っています。 さらに、送信されるデータの量はトラフィックによって異なります。 たとえば、1分間ゼロであるデータパイプは、次の間にバーストする可能性があります。 そのようなバーストの瞬間に十分な信頼性を提供するサービスはまれです(GoogleとAmazon)。
私たちのプロジェクトのパフォーマンスとは、ほぼゼロのレイテンシですべてのリスニングノードにデータを取得して送信することを意味します。 BrowserStackでは、コロケーションホスティングとともにクラウドサービス(AWS)を利用しています。 ただし、パブリッシャーやサブスクライバーはどこにでも配置できます。 たとえば、AWSアプリケーションサーバーが非常に必要なログデータを生成したり、ターミナル(ユーザーがテストのために安全に接続できるマシン)を使用したりする場合があります。 オープンインターネットの問題に戻ると、リスクを軽減するには、Pub / Subが最高のホストサービスとAWSを活用していることを確認する必要があります。
もう1つの重要な要件は、すべてのタイプのデータ(バイト、テキスト、奇妙なメディアデータなど)を送信する機能でした。 すべてを考慮すると、当社の製品をサポートするためにサードパーティのソリューションに依存することは意味がありませんでした。 次に、私たちはスタートアップの精神を復活させ、独自のソリューションをコーディングするために袖をまくり上げることにしました。
ソリューションの構築
Pub / Subは、設計上、データを生成および送信するパブリッシャーと、それを受け入れて処理するサブスクライバーが存在することを意味します。 これはラジオに似ています。ラジオチャネルは、範囲内のあらゆる場所でコンテンツをブロードキャスト(公開)します。 加入者は、そのチャンネルにチューニングして聞く(またはラジオを完全にオフにする)かどうかを決定できます。

すべての人がデータを無料で利用できるラジオの例えとは異なり、私たちのデジタルシナリオでは、認証が必要です。つまり、発行者が生成するデータは、特定の1人のクライアントまたは加入者のみのものである可能性があります。
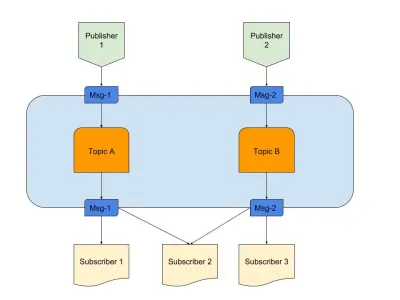
上の図は、次のような優れたPub / Subの例を示しています。
- 出版社
ここでは、事前定義されたロジックに基づいてメッセージを生成する2つのパブリッシャーがあります。 私たちのラジオの例えでは、これらはコンテンツを作成する私たちのラジオジョッキーです。 - トピック
ここには2つあります。つまり、2つのタイプのデータがあります。 これらは私たちの無線チャンネル1と2であると言えます。 - サブスクライバー
それぞれが特定のトピックに関するデータを読み取る3つがあります。 注意すべき点の1つは、サブスクライバー2が複数のトピックから読んでいることです。 私たちのラジオの例えでは、これらはラジオチャンネルに同調している人々です。
サービスに必要な要件を理解し始めましょう。
- イベントコンポーネント
これは、キックインするものがある場合にのみキックインします。 - 一時的なストレージ
これにより、データが短期間保持されるため、サブスクライバーが遅い場合でも、データを消費するためのウィンドウがあります。 - レイテンシーの削減
最小のホップと距離でネットワークを介して2つのエンティティを接続します。
上記の要件を満たすテクノロジースタックを選択しました。
- Node.js
なぜですか? イベントが発生すると、大量のデータ処理が不要になるだけでなく、簡単にオンボードできます。 - Redis
完全に短命のデータをサポートします。 開始、更新、自動期限切れするためのすべての機能があります。 また、アプリケーションへの負荷も少なくなります。
Node.js For Business Logic Connectivity
Node.jsは、IOとイベントを組み込んだコードの記述に関してはほぼ完璧な言語です。 私たちの特定の問題には両方があり、このオプションを私たちのニーズにとって最も実用的なものにしました。
確かに、Javaなどの他の言語をさらに最適化することも、Pythonなどの言語でスケーラビリティを提供することもできます。 ただし、これらの言語を開始するコストは非常に高いため、開発者は同じ期間にNodeでコードを書き終えることができます。
正直なところ、サービスにもっと複雑な機能を追加する機会があれば、他の言語や完成したスタックを調べることができたはずです。 しかし、ここではそれは天国で行われた結婚です。 これが私たちのpackage.jsonです:
{ "name": "Pusher", "version": "1.0.0", "dependencies": { "bstack-analytics": "*****", // Hidden for BrowserStack reasons. :) "ioredis": "^2.5.0", "socket.io": "^1.4.4" }, "devDependencies": {}, "scripts": { "start": "node server.js" } }非常に簡単に言えば、特にコードの記述に関しては、ミニマリズムを信じています。 一方、Expressなどのライブラリを使用して、このプロジェクトの拡張可能なコードを作成することもできます。 しかし、私たちのスタートアップの本能は、これを継承し、次のプロジェクトのために保存することにしました。 使用した追加ツール:
- ioredis
これは、Alibabaなどの企業で使用されているNode.jsとのRedis接続で最もサポートされているライブラリの1つです。 - socket.io
WebSocketとHTTPを使用した適切な接続とフォールバックに最適なライブラリ。
一時ストレージのRedis
サービススケールとしてのRedisは、信頼性が高く、構成可能です。 さらに、AWSを含むRedisには多くの信頼できるマネージドサービスプロバイダーがあります。 プロバイダーを使用したくない場合でも、Redisは簡単に使い始めることができます。
構成可能な部分を分解してみましょう。 通常のマスタースレーブ構成から始めましたが、Redisにはクラスターモードまたはセンチネルモードも付属しています。 すべてのモードには独自の利点があります。
何らかの方法でデータを共有できる場合は、Redisクラスターが最適です。 ただし、ヒューリスティックによってデータを共有した場合、ヒューリスティックを追跡する必要があるため、柔軟性が低下します。 ルールが少なく、より多くのコントロールが人生に良いです!
Redis Sentinelは、データルックアップが1つのノードでのみ実行され、データがシャーディングされていない特定の時点で接続するため、最適に機能します。 これは、複数のノードが失われた場合でも、データが分散されて他のノードに存在することも意味します。 したがって、HAが増え、損失の可能性が低くなります。 もちろん、これにより長所はクラスターを持つことがなくなりましたが、私たちのユースケースは異なります。
30000フィートのアーキテクチャ
次の図は、AutomateダッシュボードとAppAutomateダッシュボードがどのように機能するかを非常に大まかに示しています。 前のセクションで使用したリアルタイムシステムを覚えていますか?
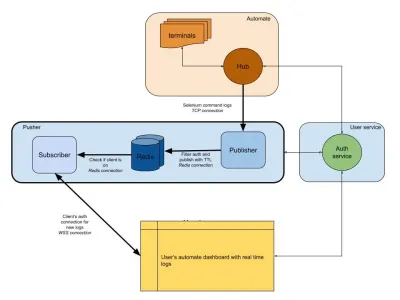
この図では、メインのワークフローが太い境界線で強調表示されています。 「自動」セクションは次の要素で構成されています。
- ターミナル
BrowserStackでのテスト中に取得するWindows、OSX、Android、またはiOSの元のバージョンで構成されています。 - ハブ
BrowserStackを使用したすべてのSeleniumおよびAppiumテストの連絡先。
ここでの「ユーザーサービス」セクションはゲートキーパーであり、適切な個人にデータが送信され、保存されるようにします。 それは私たちのセキュリティキーパーでもあります。 「プッシャー」セクションには、この記事で説明した内容の核心が組み込まれています。 それは以下を含む通常の容疑者で構成されています:
- Redis
メッセージ用の一時ストレージ。この場合、自動ログは一時的に保存されます。 - 出版社
これは基本的に、ハブからデータを取得するエンティティです。 すべてのリクエスト応答は、セッションIDをチャネルとしてsession_idに書き込むこのコンポーネントによってキャプチャされます。 - サブスクライバー
これにより、session_id用に生成されたRedisからデータが読み取られます。 また、クライアントがWebSocket(またはHTTP)を介して接続してデータを取得し、認証されたクライアントに送信するためのWebサーバーでもあります。
最後に、 session_idログが送信されることを確認するための認証済みWebSocket接続を表すユーザーのブラウザーセクションがあります。 これにより、フロントエンドJSは、ユーザーのために解析して美化することができます。
ログサービスと同様に、他の製品統合に使用されているプッシャーがここにあります。 session_idの代わりに、別の形式のIDを使用してそのチャネルを表します。 これはすべてプッシャーで機能します!
結論(TLDR)
Pub / Subの構築にかなりの成功を収めています。 社内で構築した理由をまとめると、次のようになります。
- 私たちのニーズに合わせて拡張します。
- アウトソーシングサービスよりも安い。
- アーキテクチャ全体を完全に制御します。
言うまでもなく、JSはこの種のシナリオに最適です。 イベントループと大量のIOが、問題に必要なものです。 JavaScriptは単一の疑似スレッドの魔法です。
システムとしてのイベントとRedisは、あるソースからデータを取得し、Redisを介して別のソースにプッシュできるため、開発者にとって物事をシンプルに保ちます。 だから私たちはそれを作りました。
使用法がシステムに適合する場合は、同じことを行うことをお勧めします。