
有形と無形の混合:AdobeXDを使用したマルチモーダルインターフェイスの設計
公開: 2022-03-10(この記事はアドビが後援しています。)ユーザーインターフェイスは進化しています。 音声対応インターフェースは、グラフィカルユーザーインターフェースの長い支配に挑戦しており、急速に私たちの日常生活の一部になりつつあります。 自動音声認識(APS)と自然言語処理(NLP)の大幅な進歩は、印象的な消費者基盤(音声アシスタントが組み込まれた数百万のモバイルデバイス)とともに、音声ベースのインターフェイスの急速な開発と採用に影響を与えました。
音声を主要なインターフェースとして使用する製品は、ますます人気が高まっています。 米国だけでも、4,730万人の成人がスマートスピーカーを利用でき(米国の成人人口の5分の1)、その数は増え続けています。 しかし、音声インターフェイスには、個人および家庭での使用だけでなく、明るい未来があります。 人々が音声インターフェースに慣れてくると、ビジネスの文脈でもそれらを期待するようになります。 「プレゼンテーションを表示して」のように言うと、すぐに会議室のプロジェクターをトリガーできるようになると想像してみてください。
人間と機械のコミュニケーションが急速に拡大し、書面と口頭の両方のやり取りが含まれるようになっていることは明らかです。 しかし、それは将来のインターフェースが音声のみになることを意味するのでしょうか? いくつかの空想科学小説の描写にもかかわらず、音声はグラフィカルユーザーインターフェイスを完全に置き換えるわけではありません。 代わりに、音声対応のマルチモーダルインターフェイスという新しい形式のインターフェイスで、音声、視覚、ジェスチャーの相乗効果が得られます。
この記事では、次のことを行います。
- 音声対応インターフェイスの概念を調べ、さまざまなタイプの音声対応インターフェイスを確認します。
- 音声対応のマルチモーダルユーザーインターフェイスが好ましいユーザーエクスペリエンスになる理由を確認してください。
- AdobeXDを使用してマルチモーダルUIを構築する方法をご覧ください。
音声ユーザーインターフェイス(VUI)の状態
音声ユーザーインターフェイスの詳細に入る前に、音声入力とは何かを定義する必要があります。 音声入力は、ユーザーがコマンドを書く代わりに話すという人間とコンピューターの相互作用です。 音声入力の利点は、人々にとってより自然な対話であるということです。ユーザーは、システムと対話するときに特定の構文に制限されません。 人間の会話の場合と同じように、さまざまな方法で入力を構成できます。
音声ユーザーインターフェイスは、ユーザーに次の利点をもたらします。
- インタラクションコストの削減
音声対応のインターフェイスを使用するにはインタラクションコストがかかりますが、このコストは(理論的には)新しいGUIを学習する場合よりも小さくなります。 - ハンズフリー制御
VUIは、運転中、料理中、運動中など、ユーザーの手が忙しいときに最適です。 - スピード
質問を入力して結果を読むよりも速く質問する場合、音声は優れています。 たとえば、車の中で音声を使用する場合、タッチスクリーンに場所を入力するよりも、ナビゲーションシステムに場所を伝える方が高速です。 - 感情と性格
声は聞こえても話者の画像が見えなくても、頭の中で話者を描くことができます。 これには、ユーザーエンゲージメントを向上させる機会があります。 - アクセシビリティ
視覚障害のあるユーザーや運動障害のあるユーザーは、音声を使用してシステムと対話できます。
3種類の音声対応インターフェイス
音声の使用方法に応じて、次のタイプのインターフェイスのいずれかになります。
画面優先デバイスの音声エージェント
AppleSiriとGoogleアシスタントは音声エージェントの代表的な例です。 このようなシステムの場合、音声は既存のGUIの拡張機能のように機能します。 多くの場合、エージェントはユーザーの旅の最初のステップとして機能します。ユーザーは音声エージェントをトリガーし、音声でコマンドを提供しますが、他のすべての対話はタッチスクリーンを使用して行われます。 たとえば、Siriに質問すると、リストの形式で回答が提供されるため、そのリストを操作する必要があります。 その結果、ユーザーエクスペリエンスは断片化されます。音声を使用して対話を開始し、次にタッチにシフトして対話を続行します。
音声専用デバイス
これらのデバイスには視覚的な表示はありません。 ユーザーは、入力と出力の両方をオーディオに依存しています。 AmazonEchoとGoogleHomeスマートスピーカーは、このカテゴリの製品の代表的な例です。 視覚的な表示の欠如は、情報とオプションをユーザーに伝達するデバイスの能力に対する重大な制約です。 その結果、ほとんどの人はこれらのデバイスを使用して、音楽の再生や簡単な質問への回答の取得などの簡単なタスクを完了します。

音声優先デバイス
音声優先システムでは、デバイスは主に音声コマンドを介してユーザー入力を受け入れますが、統合された画面表示も備えています。 これは、音声が主要なユーザーインターフェイスであるが、唯一のユーザーインターフェイスではないことを意味します。 「写真は千の言葉に値する」という古いことわざは、現代の音声対応システムにも当てはまります。 人間の脳には信じられないほどの画像処理能力があります。視覚的に見ると、複雑な情報をより速く理解することができます。 音声のみのデバイスと比較して、音声優先デバイスを使用すると、ユーザーはより多くの情報にアクセスでき、多くのタスクがはるかに簡単になります。
Amazon Echo Showは、音声優先システムを採用したデバイスの代表的な例です。 視覚情報は、全体的なシステムの一部として徐々に組み込まれています。画面にはアプリアイコンが読み込まれていません。 むしろ、システムはユーザーにさまざまな音声コマンドを試すように促します(「アレクサを試して、午後5時に天気を見せて」などの音声コマンドを提案します)。 この画面では、調理中のレシピの確認などの一般的なタスクもはるかに簡単になります。ユーザーは注意深く耳を傾け、すべての情報を頭に入れておく必要はありません。 情報が必要なときは、画面を見るだけです。

マルチモーダルインターフェースの紹介
UIデザインで音声を使用する場合、音声を単独で使用できるものとは考えないでください。 Amazon Echo Showなどのデバイスには画面が含まれていますが、主要な入力方法として音声を採用しているため、より包括的なユーザーエクスペリエンスが実現します。 これは、新世代のユーザーインターフェイスであるマルチモーダルインターフェイスに向けた最初のステップです。
マルチモーダルインターフェイスは、音声、タッチ、オーディオ、およびさまざまなタイプのビジュアルを単一のシームレスなUIにブレンドするインターフェイスです。 Amazon Echo Showは、音声対応のマルチモーダルインターフェイスを最大限に活用するデバイスの優れた例です。 ユーザーがShowを操作するときは、音声のみのデバイスの場合と同じようにリクエストを行います。 ただし、彼らが受け取る反応は、音声と視覚の両方の反応を含むマルチモーダルである可能性があります。
マルチモーダル製品は、視覚のみまたは音声のみに依存する製品よりも複雑です。 そもそもなぜ誰もがマルチモーダルインターフェースを作成する必要があるのでしょうか。 その質問に答えるには、一歩下がって、人々が周囲の環境をどのように認識しているかを確認する必要があります。 人々には五感があり、一緒に働く私たちの感覚の組み合わせは、私たちが物事をどのように知覚するかです。 たとえば、ライブコンサートで音楽を聴いているとき、私たちの感覚は一緒に働きます。 1つの感覚(たとえば、聴覚)を取り除くと、体験はまったく異なる文脈を取ります。

あまりにも長い間、私たちはユーザーエクスペリエンスを視覚的またはジェスチャー的なデザインとしてのみ考えてきました。 この考え方を変える時が来ました。 マルチモーダルデザインは、私たちの感覚能力をつなぐ体験について考え、デザインする方法です。
マルチモーダルインターフェースは、ユーザーとマシンが通信するためのより人間的な方法のように感じます。 それらは、より深い相互作用のための新しい機会を開きます。 そして今日では、これまで製品との相互作用を制約していた技術的な制限が解消されているため、マルチモーダルインターフェイスの設計がはるかに簡単になっています。
GUIとマルチモーダルインターフェイスの違い
ここでの主な違いは、Amazon EchoShowのようなマルチモーダルインターフェイスが音声およびビジュアルインターフェイスを同期することです。 その結果、エクスペリエンスを設計するとき、音声とビジュアルはもはや独立した部分ではありません。 それらは、システムが提供するエクスペリエンスの不可欠な部分です。
ビジュアルチャネルと音声チャネル:それぞれをいつ使用するか
音声とビジュアルを入力と出力のチャネルとして考えることが重要です。 各チャネルには、独自の長所と短所があります。
ビジュアルから始めましょう。 一部の情報は、聞いたときよりも見たときに理解しやすいことは明らかです。 次のものを提供する必要がある場合、ビジュアルはより適切に機能します。
- オプションの長いリスト(長いリストを読むのは時間がかかり、フォローするのが難しいでしょう);
- データ量の多い情報(図やグラフなど)。
- 商品情報(たとえば、オンラインショップの商品。購入する前に商品を確認することをお勧めします)と商品の比較(オプションの長いリストと同様に、音声だけですべての情報を提供することは困難です) 。
ただし、一部の情報については、口頭でのコミュニケーションに簡単に頼ることができます。 音声は、次の場合に適している可能性があります。
- ユーザーコマンド(音声は効率的な入力モダリティであり、ユーザーがシステムにコマンドをすばやく提供し、複雑なナビゲーションメニューをバイパスできるようにします)。
- 簡単なユーザーの指示(たとえば、処方箋の定期的なチェック);
- 警告と通知(たとえば、運転中の音声通知と組み合わせた音声警告)。
これらは視覚と音声を組み合わせたいくつかの典型的なケースですが、2つを互いに分離することはできないことを知っておくことが重要です。 音声とビジュアルの両方が連携する場合にのみ、より優れたユーザーエクスペリエンスを作成できます。 たとえば、新しい靴を購入したいとします。 音声を使用して、システムに「ニューバランスの靴を見せて」とリクエストすることができます。 システムはあなたのリクエストを処理し、製品情報を視覚的に提供します(靴を比較するためのより簡単な方法)。
音声対応のマルチモーダルインターフェイスを設計するために知っておくべきこと
音声は、UXデザイナーにとって最もエキサイティングな課題の1つです。 その斬新さにもかかわらず、音声対応のマルチモーダルインターフェイスを設計するための基本的なルールは、ビジュアルデザインを作成するために使用するものと同じです。 設計者はユーザーを気にする必要があります。 彼らは、効率的な方法で問題を解決することによってユーザーの摩擦を減らすことを目指し、ユーザーの選択を明確にするために明確さを優先する必要があります。
ただし、マルチモーダルインターフェイスにも独自の設計原則がいくつかあります。
正しい問題を確実に解決する
デザインは問題を解決するはずです。 しかし、適切な問題を解決することが重要です。 そうしないと、ユーザーにあまり価値をもたらさないエクスペリエンスの作成に多くの時間を費やす可能性があります。 したがって、正しい問題の解決に集中していることを確認してください。 音声対話はユーザーにとって意味のあるものでなければなりません。 ユーザーには、他の対話方法(クリックやタップなど)よりも音声を使用する説得力のある理由が必要です。 そのため、新製品を作成するときは、デザインを開始する前であっても、ユーザーリサーチを実施し、音声がUXを改善するかどうかを判断することが不可欠です。
ユーザージャーニーマップの作成から始めます。 ジャーニーマップを分析し、チャネルとして音声を含めることがUXに役立つ場所を見つけます。
- ユーザーが摩擦や欲求不満に遭遇する可能性のある旅の場所を見つけます。 音声を使用すると摩擦が減りますか?
- ユーザーのコンテキストについて考えてください。 音声は特定のコンテキストで機能しますか?
- 音声によって独自に可能になるものについて考えてください。 ハンズフリーやアイフリーのインタラクションなど、音声を使用することのユニークな利点を覚えておいてください。 音声は体験に付加価値を与えることができますか?
会話フローを作成する
理想的には、設計するインターフェースはインタラクションコストをゼロにする必要があります。ユーザーは、システムとのインタラクション方法の学習に余分な時間を費やすことなく、ニーズを満たすことができる必要があります。 これは、音声対話が実際の会話に似ている場合にのみ発生し、音声コマンドの形式でラップされたシステムダイアログではありません。 優れたUIの基本的なルールは単純です。コンピューターは人間に適応する必要があり、その逆ではありません。
人々がフラットで直線的な会話(1ターンしか続かない会話)をすることはめったにありません。 そのため、システムとの対話をライブの会話のように感じさせるには、設計者は会話フローの作成に集中する必要があります。 各会話フローは、システムとユーザーの間で発生する経路であるダイアログで構成されます。 各ダイアログには、システムのプロンプトとユーザーの可能な応答が含まれます。
会話フローは、フロー図の形式で表示できます。 各フローは、1つの特定のユースケースに焦点を当てる必要があります(たとえば、システムを使用して目覚まし時計を設定する)。 フロー内のほとんどのダイアログでは、問題が発生したときにエラーパスを考慮することが重要です。
ユーザーの各音声コマンドは、意図、発話、スロットの3つの主要な要素で構成されています。
- インテントは、音声対応システムとのユーザーの対話の目的です。
インテントは、一連の単語の背後にある目的を定義するための空想的な方法にすぎません。 システムとの各対話は、ユーザーに何らかの有用性をもたらします。 それが情報であろうと行動であろうと、ユーティリティは意図されています。 ユーザーの意図を理解することは、音声対応インターフェースの重要な部分です。 VUIを設計するとき、ユーザーの意図が何であるかを常に確実に知ることはできませんが、それを高精度で推測することはできます。 - 発話は、ユーザーがリクエストを表現する方法です。
通常、ユーザーは音声コマンドを作成する方法が複数あります。 たとえば、「目覚まし時計を午前8時に設定する」、「目覚まし時計を明日午前8時に設定する」、「目覚まし時計を午前8時に起こす必要がある」と言うことで、目覚まし時計を設定できます。 設計者は、発話の考えられるすべてのバリエーションを考慮する必要があります。 - スロットは、ユーザーがコマンドで使用する変数です。 ユーザーがリクエストで追加情報を提供する必要がある場合があります。 目覚まし時計の例では、「午前8時」がスロットです。
ユーザーの口に言葉を入れないでください
人々は話す方法を知っています。 彼らにコマンドを教えようとしないでください。 「会議の予定を送信するには、「カレンダー、会議、新しい会議を作成する」と言う必要があります。」などのフレーズは避けてください。 コマンドを説明する必要がある場合は、システムの設計方法を再検討する必要があります。 常に自然言語の会話を目指し、多様な話し方に対応するようにしてください)。
一貫性を追求する
コンテキスト間で言語と音声の一貫性を実現する必要があります。 一貫性は、相互作用に精通するのに役立ちます。
常にフィードバックを提供する
システムステータスの可視性は、優れたGUI設計の基本原則の1つです。 システムは、適切なフィードバックを通じて、合理的な時間内に何が起こっているかを常にユーザーに通知する必要があります。 同じルールがVUIデザインにも適用されます。
- システムがリッスンしていることをユーザーに知らせます。
デバイスがユーザーの要求をリッスンまたは処理しているときに、視覚的なインジケーターを表示します。 フィードバックがなければ、ユーザーはシステムが何かをしているのかどうかしか推測できません。 そのため、AmazonEchoやGoogleHomeなどの音声のみのデバイスでも、答えを聞いたり検索したりするときに、視覚的なフィードバック(ライトの点滅)が得られます。 - 会話マーカーを提供します。
会話マーカーは、会話のどこにいるかをユーザーに知らせます。 - タスクが完了したことを確認します。
たとえば、ユーザーが音声対応のスマートホームシステムに「ガレージの電気を消して」と尋ねた場合、システムはコマンドが正常に実行されたことをユーザーに通知する必要があります。 確認なしで、ユーザーはガレージに入ってライトを確認する必要があります。 これは、ユーザーの生活を楽にするというスマートホームシステムの目的を打ち破ります。
長い文を避ける
音声対応システムを設計するときは、ユーザーに情報を提供する方法を検討してください。 長い文章を使用すると、情報が多すぎてユーザーを圧倒するのは比較的簡単です。 まず、ユーザーは短期記憶に多くの情報を保持できないため、重要な情報を簡単に忘れてしまう可能性があります。 また、オーディオは遅いメディアです。ほとんどの人は、聞くよりもはるかに速く読むことができます。
ユーザーの時間を尊重してください。 長い独白を読み上げないでください。 応答を設計するときは、使用する単語が少ないほど良いです。 ただし、ユーザーがタスクを完了するために十分な情報を提供する必要があることを忘れないでください。 したがって、答えを一言で要約できない場合は、代わりに画面に表示してください。
次のステップを順番に提供する
ユーザーは、長い文章だけでなく、一度に選択できるオプションの数にも圧倒される可能性があります。 音声対応システムとの対話プロセスを一口サイズのチャンクに分割することが重要です。 ユーザーが一度に選択できる選択肢の数を制限し、ユーザーが常に何をすべきかを知っていることを確認してください。
多くの機能を備えた複雑な音声対応システムを設計する場合は、段階的開示の手法を使用できます。タスクを完了するために必要なオプションまたは情報のみを提示します。
強力なエラー処理戦略を持っている
もちろん、システムはそもそもエラーの発生を防ぐ必要があります。 ただし、音声対応システムがどれほど優れていても、システムがユーザーを理解しないシナリオに合わせて設計する必要があります。 あなたの責任はそのような場合のために設計することです。
戦略を作成するためのいくつかの実用的なヒントを次に示します。

- ユーザーを責めないでください。
会話では、エラーはありません。 「あなたの答えは間違っています」のような応答を避けるようにしてください。 - エラー回復フローを提供します。
重要な情報を失うことなく、会話を行ったり来たりするためのオプションを提供したり、システムを終了したりするためのオプションを提供します。 旅の途中でユーザーの状態を保存して、中断したところからシステムに再び参加できるようにします。 - ユーザーに情報を再生させます。
システムに質問または回答を繰り返させるオプションを提供します。 これは、ユーザーがすべての情報を作業メモリーにコミットするのが難しい複雑な質問や回答に役立つ場合があります。 - 停止の文言を提供します。
場合によっては、ユーザーはオプションを聞くことに興味がなく、システムがそれについて話すのをやめたいと思うでしょう。 言葉遣いをやめることは彼らがまさにそれをするのを助けるべきです。 - 予期しない発話を適切に処理します。
システムの設計にいくら投資しても、システムがユーザーを理解できない場合があります。 このような場合を適切に処理することが重要です。 システムに理解の欠如を認めさせることを恐れないでください。 システムは、理解したことを伝達し、役立つプロンプトを提供する必要があります。 - 分析を使用して、エラー戦略を改善します。
分析は、間違った方向転換や誤解を特定するのに役立ちます。
コンテキストを追跡する
システムがユーザーの入力のコンテキストを理解していることを確認してください。 たとえば、誰かが来週サンフランシスコ行きのフライトを予約したいと言った場合、会話の流れの中で「それ」または「都市」を指すことがあります。 システムは、言われたことを記憶し、それを新しく受け取った情報と照合できる必要があります。
より強力なインタラクションを作成するためのユーザーについて学ぶ
音声対応システムは、追加情報(ユーザーコンテキストや過去の動作など)を使用してユーザーが何を望んでいるかを理解すると、より高度になります。 この手法はインテリジェントな解釈と呼ばれ、システムがユーザーについて積極的に学習し、それに応じてユーザーの行動を調整できる必要があります。 この知識は、「妻の誕生日にどのような贈り物を買うべきか」などの複雑な質問に対しても、システムが回答を提供するのに役立ちます。
VUIに個性を与える
音声対応システムはすべて、計画しているかどうかに関係なく、ユーザーに感情的な影響を与えます。 人々は声を機械ではなく人間と関連付けます。 Speak Easy Global Editionの調査によると、音声テクノロジーの常連ユーザーの74%は、ブランドが音声対応製品に独自の声と個性を持っていることを期待しています。 個性を通じて共感を築き、より高いレベルのユーザーエンゲージメントを達成することが可能です。
あなたが提示する声とトーンにあなたのユニークなブランドとアイデンティティを反映するようにしてください。 音声対応エージェントのペルソナを作成し、ダイアログを作成するときにこのペルソナに依存します。
信頼を築く
ユーザーがシステムを信頼しない場合、システムを使用する動機がありません。 そのため、信頼の構築が製品設計の要件です。 構築される信頼のレベルには、システム機能と有効な結果という2つの要素が大きく影響します。
信頼の構築は、ユーザーの期待を設定することから始まります。 従来のGUIには、システムの機能をユーザーが理解するのに役立つ多くの視覚的な詳細があります。 音声対応システムを使用すると、設計者は信頼できるツールが少なくなります。 それでも、システムを自然に発見できるようにすることが重要です。 ユーザーは、システムで何が可能で何が不可能かを理解する必要があります。 そのため、音声対応システムでは、システムで何ができるか、またはシステムが何を知っているかについて話し合うユーザーのオンボーディングが必要になる場合があります。 オンボーディングを設計するときは、意味のある例を提供して、それが何ができるかを人々に知らせるようにしてください(例は指示よりもうまく機能します)。
有効な結果になると、人々は音声対応システムが不完全であることを知っています。 システムが答えを提供するとき、一部のユーザーは答えが正しいと疑うかもしれません。 これは、ユーザーが自分の要求が正しく理解されたかどうか、または答えを見つけるためにどのアルゴリズムが使用されたかについての情報を持っていないために発生します。 信頼の問題を防ぐために、証拠をサポートするために画面を使用し(画面に元のクエリを表示します)、アルゴリズムに関するいくつかの重要な情報を提供します。 たとえば、ユーザーが「2018年のトップ5の映画を見せて」と尋ねると、システムは「米国の興行収入によると、2018年のトップ5の映画はここにあります」と言うことができます。
セキュリティとデータプライバシーを無視しないでください
個人に属するモバイルデバイスとは異なり、音声デバイスはキッチンなどの場所に属する傾向があります。 そして通常、同じ場所に複数の人がいます。 他の誰かがあなたのすべての個人データにアクセスできるシステムと対話できると想像してみてください。 Amazon Alexa、Googleアシスタント、Apple Siriなどの一部のVUIシステムは、個々の音声を認識できるため、システムにセキュリティのレイヤーが追加されます。 それでも、100%の場合に、システムがユーザーの固有の音声署名に基づいてユーザーを認識できることを保証するものではありません。
音声認識は継続的に改善されており、近い将来、音声を模倣することは困難またはほぼ不可能になります。 ただし、現在の現実では、データが安全であることをユーザーに保証するために、追加の認証レイヤーを提供することが不可欠です。 健康情報や銀行の詳細などの機密データを処理するアプリを設計する場合は、パスワード、指紋、顔認識などの追加の認証手順を含めることができます。
ユーザビリティテストを実施する
ユーザビリティテストは、どのシステムでも必須の要件です。 早期にテストします。多くの場合、テストは設計プロセスの基本的なルールです。 早い段階でユーザー調査データを収集し、設計を繰り返します。 ただし、マルチモーダルインターフェイスのテストには独自の詳細があります。 考慮すべき2つのフェーズは次のとおりです。
- アイデアフェーズ
サンプルダイアログを試してみてください。 サンプルダイアログを大声で読む練習をします。 会話の流れができたら、会話の両側(ユーザーの発話とシステムの応答)を録音し、録音を聞いて自然に聞こえるかどうかを理解します。 - 製品開発の初期段階(lo-fiプロトタイプによるテスト)
Wizard of Ozテストは、会話型インターフェイスのテストに最適です。 Wizard of Ozテストは、参加者がコンピューターによって操作されていると信じているが実際には人間によって操作されているシステムと対話するタイプのテストです。 テスト参加者はクエリを作成し、実際の人が反対側で応答します。 この方法の名前は、フランク・バウムの著書「オズの魔法使い」に由来しています。 この本では、普通の人がカーテンの後ろに隠れて、強力な魔法使いのふりをしています。 このテストでは、相互作用の考えられるすべてのシナリオを計画し、その結果、より自然な相互作用を作成できます。 Say Wizardは、macOSでWizard ofOz音声インターフェイステストを実行するのに役立つ優れたツールです。 - 製品開発の後期段階(hi-fiプロトタイプによるテスト)
グラフィカルユーザーインターフェイスのユーザビリティテストでは、システムを操作するときにユーザーに声を出してもらうことがよくあります。 音声対応システムの場合、システムがそのナレーションをリッスンするため、これが常に可能であるとは限りません。 したがって、ユーザーに大声で話すように依頼するよりも、ユーザーのシステムとの対話を観察する方がよい場合があります。
AdobeXDを使用してマルチモーダルインターフェイスを作成する方法
マルチモーダルインターフェイスとは何か、およびそれらを設計するときに覚えておくべきルールについてしっかりと理解したので、マルチモーダルインターフェイスのプロトタイプを作成する方法について説明します。
プロトタイピングは、設計プロセスの基本的な部分です。 アイデアを実現し、他の人と共有できることは非常に重要です。 これまで、プロトタイピングに音声を組み込みたいと考えていた設計者には、信頼できるツールがほとんどなく、その中で最も強力なのはフローチャートでした。 ユーザーがシステムとどのように対話するかを描くには、フローチャートを見ている誰かから多くの想像力が必要でした。 Adobe XDを使用すると、デザイナーは音声の媒体にアクセスして、プロトタイプで使用できるようになります。 XDは、1つのアプリで画面と音声のプロトタイピングをシームレスに接続します。
新しい経験、同じプロセス
音声は視覚とはまったく異なる媒体ですが、Adobe XDでの音声のプロトタイピングのプロセスは、GUIのプロトタイピングとほとんど同じです。 Adobe XDチームは、どのデザイナーにとっても自然で直感的な方法で音声を統合します。 設計者は、音声トリガーと音声再生を使用して、プロトタイプを操作できます。
- 音声トリガーは、ユーザーが特定の単語またはフレーズ(発話)を発声したときにインタラクションを開始します。
- 音声再生により、設計者はテキスト読み上げエンジンにアクセスできます。 XDは、デザイナーが定義した単語や文章を話します。 音声再生は、さまざまな目的に使用できます。 たとえば、確認応答(ユーザーを安心させるため)またはガイダンス(ユーザーが次に何をすべきかを知るため)として機能できます。
XDの優れている点は、各音声プラットフォームの複雑さを学ぶ必要がないことです。
十分な言葉—実際にどのように機能するか見てみましょう。 以下に示すすべての例では、AmazonAlexa用のAdobeXD UIキットを使用して作成されたアートボードを使用しました(これはキットをダウンロードするためのリンクです)。 キットには、AmazonAlexaのエクスペリエンスを作成するために必要なすべてのスタイルとコンポーネントが含まれています。
次のアートボードがあるとします。
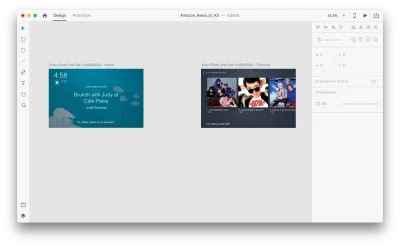
いくつかの音声対話を追加するために、プロトタイピングモードに入りましょう。 音声トリガーから始めます。 タップアンドドラッグなどのトリガーに加えて、音声をトリガーとして使用できるようになりました。 別のアートボードにつながるハンドルがあれば、音声トリガーに任意のレイヤーを使用できます。 アートボードをつなぎましょう。
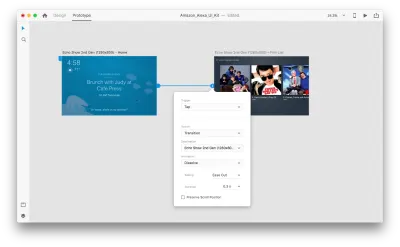
これを行うと、「トリガー」の下に新しい「音声」オプションが表示されます。 このオプションを選択すると、発話を入力するために使用できる「コマンド」フィールドが表示されます。これは、XDが実際にリッスンするものです。 トリガーをアクティブにするには、ユーザーはこのコマンドを話す必要があります。
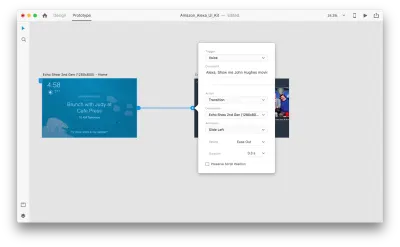
それで全部です! 最初の音声対話を定義しました。 これで、ユーザーは何かを言うことができ、プロトタイプがそれに応答します。 ただし、音声再生を追加することで、この対話をさらに強力にすることができます。 前に述べたように、音声再生により、システムはいくつかの単語を話すことができます。
2つ目のアートボード全体を選択し、青いハンドルをクリックします。 遅延のある「時間」トリガーを選択し、0.2秒に設定します。 アクションの下に、「音声再生」があります。 バーチャルアシスタントが私たちに話しかける内容を書き留めます。
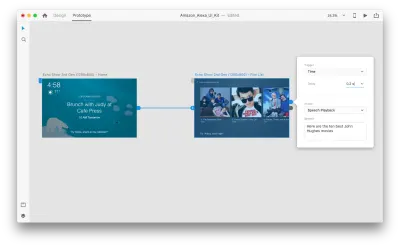
プロトタイプをテストする準備ができました。 最初のアートボードを選択し、右上の再生ボタンをクリックするとプレビューウィンドウが起動します。 音声プロトタイピングを操作するときは、マイクがオンになっていることを確認してください。 次に、スペースバーを押したまま音声コマンドを話します。 この入力により、プロトタイプの次のアクションがトリガーされます。
自動アニメーションを使用して、エクスペリエンスをより動的にします
アニメーションは、UIデザインに多くの利点をもたらします。 次のような明確な機能目的を果たします。
- オブジェクト間の空間的関係を伝達する(オブジェクトはどこから来たのか?それらのオブジェクトは関連しているのか?);
- アフォーダンスの伝達(次に何ができますか?)
しかし、アニメーションの利点は機能的な目的だけではありません。 アニメーションはまた、体験をより生き生きとダイナミックにします。 そのため、UIアニメーションはマルチモーダルインターフェイスの自然な部分である必要があります。
Adobe XDで利用可能な「自動アニメーション」を使用すると、没入型のアニメーショントランジションを使用したプロトタイプの作成がはるかに簡単になります。 Adobe XDはあなたのためにすべての大変な仕事をするので、あなたはそれについて心配する必要はありません。 2つのアートボード間でアニメーション化されたトランジションを作成するために必要なのは、アートボードを複製し、クローン内のオブジェクトプロパティ(サイズ、位置、回転などのプロパティ)を変更し、自動アニメーション化アクションを適用することだけです。 XDは、各アートボード間のプロパティの違いを自動的にアニメーション化します。
それが私たちのデザインでどのように機能するか見てみましょう。 Amazon Echo Showに既存のショッピングリストがあり、音声を使用してリストに新しいオブジェクトを追加するとします。 次のアートボードを複製します。
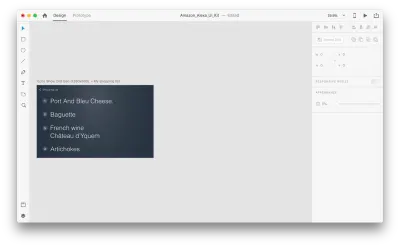
レイアウトにいくつかの変更を導入しましょう:新しいオブジェクトを追加します。 ここでは制限がないため、テキスト属性、色、不透明度、オブジェクトの位置などのプロパティを簡単に変更できます。基本的に、変更を加えると、XDはそれらの間でアニメーションを作成します。
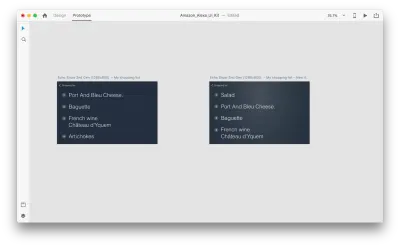
「アクション」で自動アニメーションを使用してプロトタイプモードで2つのアートボードを一緒に配線すると、XDは各アートボード間のプロパティの違いを自動的にアニメーション化します。
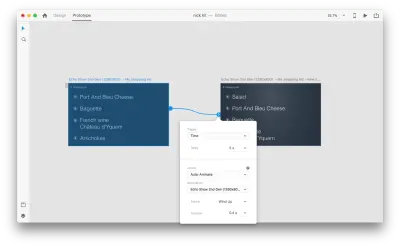
そして、インタラクションがユーザーにどのように見えるかを次に示します。

言及する必要がある重要なことの1つは、すべてのレイヤーの名前を同じに保つことです。 そうしないと、AdobeXDは自動アニメーションを適用できません。
結論
私たちは、ユーザーインターフェイス革命の夜明けにいます。 新世代のインターフェース(マルチモーダルインターフェース)は、ユーザーにより多くのパワーを与えるだけでなく、ユーザーがシステムと対話する方法も変更します。 We will probably still have displays, but we won't need keyboards to interact with the systems.
At the same time, the fundamental requirements for designing multimodal interfaces won't be much different from those of designing modern interfaces. Designers will need to keep the interaction simple; focus on the user and their needs; design, prototype, test and iterate.
And the great thing is that you don't need to wait to start designing for this new generation of interfaces. You can start today.
この記事は、アドビが後援するUXデザインシリーズの一部です。 Adobe XDツールは、アイデアからプロトタイプへの移行を高速化できるため、高速で流動的なUXデザインプロセス向けに作成されています。 設計、プロトタイプ作成、共有—すべてを1つのアプリで。 Adobe XD on Behanceで作成されたより刺激的なプロジェクトをチェックしたり、Adobeエクスペリエンスデザインニュースレターにサインアップして、UX / UIデザインの最新のトレンドや洞察に関する最新情報を入手したりできます。