
2022年の15の機械学習インタビューの質問と回答
公開: 2021-01-08あなたは機械学習で成功したキャリアを作りたいと思っている人ですか? もしそうなら、あなたにとって素晴らしいです!
ただし、最初に、砕氷船(MLインタビュー)の準備をする必要があります。
面接の準備プロセスは大変な作業になる可能性があるため、私たちは介入することにしました。これは、機械学習の面接で最もよく聞かれる15の質問の厳選されたリストです。
- ディープラーニングと機械学習の違いは何ですか?
機械学習では、高度なアルゴリズムを適用してデータを解析し、データ内の隠れたパターンを明らかにしてそこから学習し、最後に学習した洞察を適用して、情報に基づいたビジネス上の意思決定を行います。 ディープラーニングに関しては、人間の脳のニューラルネット構造からインスピレーションを得た人工ニューラルネットの使用を含む機械学習のサブセットです。 ディープラーニングは、特徴の検出に広く使用されています。
- 定義–適合率と再現率。
精度または正の予測値は、モデルが実際に主張する陽性の数と比較して、モデルによって主張される真の陽性の数を測定するか、より正確に予測します。
RecallまたはTruePositiveRateは、データ全体に存在する実際の陽性の数と比較した、モデルによって主張された陽性の数を指します。

世界のトップ大学(修士、エグゼクティブ大学院プログラム、ML&AIの高度な証明書プログラム)からオンラインで機械学習コースに参加して、キャリアを早急に進めましょう。
- 「バイアス」および「分散」という用語を説明します。 '
トレーニングプロセス中に、学習アルゴリズムの予想されるエラーは、一般に、バイアスと分散の2つの部分に分類または分解されます。 「バイアス」は学習アルゴリズムでの単純な仮定の使用によって引き起こされるエラー状況ですが、「分散」はデータ分析におけるその学習アルゴリズムの複雑さによって引き起こされるエラーを示します。 バイアスは、学習アルゴリズムによって作成された平均分類器のターゲット関数への近さを測定し、分散は、学習アルゴリズムの予測がさまざまなトレーニングデータセットに対してどの程度変化するかによって測定されます。
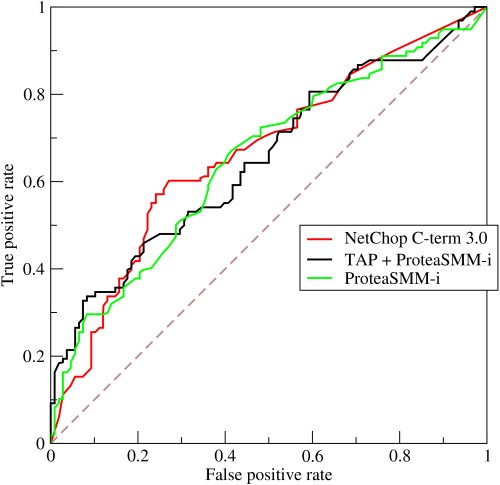
- ROC曲線はどのように機能しますか?
ROCまたは受信者動作特性曲線は、さまざまなしきい値での真陽性率と偽陽性率の間の変動をグラフで表したものです。 これは、診断テスト評価の基本的なツールであり、モデルの感度(真陽性)と誤警報をトリガーする確率(偽陽性)の間のトレードオフの表現としてよく使用されます。
ソース
- 曲線は、感度と特異性の間のトレードオフを示しています。感度が高くなると、特異性は低下します。
- 曲線がROCスペースの左側の軸と上部に向かってより境界を接している場合、通常、テストはより正確です。 ただし、曲線がROC空間の45度の対角線に近づくと、テストの精度や信頼性が低下します。
- カットポイントでの接線の傾きは、テストのその特定の値の尤度比(LR)を示します。
- 曲線の下の領域は、テストの精度を測定します。
- タイプ1とタイプ2のエラーの違いを説明してください。
タイプ1の過誤は、実際には何も発生していないのにインシデントが発生したと「主張」する誤検知エラーです。 誤検知エラーの最も良い例は、誤火災警報です。火災がないときに警報が鳴り始めます。 これとは対照的に、タイプ2のエラーは、何かが確実に起こったときに何も起こらなかったと「主張する」偽陰性エラーです。 妊娠中の女性に赤ちゃんを産んでいないことを伝えるのはタイプ2のエラーです。
- ベイズが「ナイーブベイズ」と呼ばれるのはなぜですか?
ナイーブベイズは「ナイーブ」と呼ばれます。これは、多くの実用的なアプリケーションがありますが、実際のデータでは見つけることが不可能であるという仮定に基づいているためです。データセットのすべての機能は重要で、独立しており、同等です。 ナイーブベイズアプローチでは、条件付き確率は個々のコンポーネントの確率の純粋な積として計算されるため、機能が完全に独立していることを意味します。 残念ながら、この仮定は実際のシナリオでは実現できません。
- 「過剰適合」という用語はどういう意味ですか? あなたはそれを避けることができますか? もしそうなら、どのように?
通常、トレーニングプロセス中に、モデルに大量のデータが供給されます。 プロセスの過程で、データは、サンプルデータセットに存在する不正確な情報やノイズからでも学習を開始します。 これにより、新しいデータに対するモデルのパフォーマンスに悪影響が生じます。つまり、モデルは、トレーニングセットのものとは別に、新しいインスタンス/データを正確に分類できません。 これは過剰適合として知られています。
はい、過剰適合を回避することは可能です。 方法は次のとおりです。
- (異なるソースから)より多くのデータを収集して、さまざまなサンプルでモデルをトレーニングします。
- バギングアプローチを使用するアンサンブル手法(ランダムフォレストなど)を適用して、データセットの異なるユニットに複数の決定木の結果を並置することにより、予測の変動を最小限に抑えます。
- 必ず相互検証手法を使用してください。
- 教師あり学習でキャリブレーションに使用される2つの方法に名前を付けます。
教師あり学習の2つのキャリブレーション方法は、プラットキャリブレーションと等張回帰です。 これらの方法は両方とも、二項分類用に特別に設計されています。
- なぜディシジョンツリーを剪定するのですか?
予測能力の弱い枝を取り除くには、決定木を剪定する必要があります。 これは、ディシジョンツリーモデルの複雑さの商を最小限に抑え、その予測精度を最適化するのに役立ちます。 剪定は、トップダウンまたはボトムアップのいずれかで実行できます。 エラープルーニングの削減、コストの複雑さのプルーニング、エラーの複雑さのプルーニング、および最小エラーのプルーニングは、最もよく使用されるディシジョンツリーのプルーニング方法の一部です。

- F1スコアとはどういう意味ですか?
簡単に言うと、F1スコアはモデルのパフォーマンスの尺度であり、モデルの適合率と再現率の平均であり、1に近い結果が最高で、0に近い結果が最低です。 F1スコアは、真のネガティブを重要視しない分類テストで使用できます。
- 生成アルゴリズムと識別アルゴリズムを区別します。
生成アルゴリズムはデータのカテゴリを学習しますが、識別アルゴリズムはデータの異なるカテゴリ間の区別を学習します。 分類タスクに関しては、識別モデルは通常、生成モデルを上回ります。
- アンサンブル学習とは何ですか?
アンサンブル学習は、学習アルゴリズムの組み合わせを使用して、モデルの予測パフォーマンスを最適化します。 この方法では、分類器やエキスパートなどの複数のモデルが戦略的に生成され、モデルの過剰適合を防ぐために組み合わされます。 これは主に、モデルの予測、分類、関数近似、パフォーマンスなどを強化するために使用されます。
- 「カーネルトリック」を定義します。
カーネルトリック法は、その次元内の点の座標を明示的に計算する必要なしに、より高次元の暗黙の特徴空間で動作できるカーネル関数の使用を含みます。 カーネル関数は、特徴空間に存在するデータのすべてのペアの画像間の内積を計算します。 この手順は、座標の明示的な計算に比べて計算コストが低く、カーネルトリックとして知られています。
- データセット内の欠落または破損したデータをどのように処理する必要がありますか?
データセット内の欠落/破損したデータを見つけるには、行と列を削除するか、他の値に置き換える必要があります。 Pandasライブラリには、欠落/破損したデータを見つけるための2つの優れたメソッドがあります。isnull()とdropna()です。 これらの関数は両方とも、データが欠落している/破損しているデータの行/列を見つけて、それらの値を削除するのに役立つように特別に設計されています。
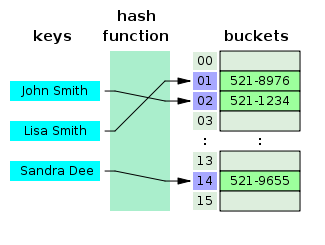
- ハッシュテーブルとは何ですか?
ハッシュテーブルは、連想配列を作成するデータ構造であり、ハッシュ関数を使用してキーが特定の値にマップされます。 ハッシュテーブルは、主にデータベースのインデックス作成で使用されます。
ソース
この質問のリストは、機械学習の基本を紹介することだけを目的としています。率直に言って、これらの20の質問はほんの一滴です。 機械学習は私たちが話すにつれて進歩しているため、時間の経過とともに新しい概念が出現します。 したがって、ML面接を釘付けにするための鍵は、学び、スキルアップしたいという絶え間ない衝動を抱くことにあります。 ですから、始めてインターネットを調べ、ジャーナルを読み、オンラインコミュニティに参加し、ML会議やセミナーに参加してください。学ぶ方法はたくさんあります。
大規模な組織に入るには、評判の高い機関からの証明書が不可欠です。 機械学習とAIに関するIIIT-BのエグゼクティブPGプログラムをチェックして、MLとAIのトップ企業からの就職支援を受けてください。
アンサンブル学習の制限は何ですか?
アンサンブルアプローチは、分散の減少とより堅牢なモデルの開発に役立ちます。 ただし、説明性やパフォーマンスの欠如など、アンサンブル手法を使用することには特定の欠点があります。 さらに、アンサンブルの有効性は、問題のさまざまな側面に焦点を当てた複数のモデルを集約する能力に由来することに注意してください。 ただし、数百のモデルからの予測が必要になる可能性があるため、予測期間は長くなります。 より良い予測があったとしても、精度の向上はそれだけの価値がないかもしれません。
機械学習を学ぶのにどれくらいの時間が必要ですか?
機械学習に関して言えば、機械学習に利用されている複雑なテクノロジーは、人々を簡単に怖がらせる可能性があります。 しかし、少しずつ理解することは難しくありません。 統計や高度な数学などの経験は、間違いなくすべての概念をすばやく理解するのに役立ちます。 ただし、学歴やスキルは人によって異なるため、1人の個人が3週間でMLを学び、別の個人が1年かかる場合があります。
機械学習は私たちの日常生活でどのように使用されていますか?
Gmailは、機械学習を使用してメールをプライマリ、プロモーション、ソーシャル、更新に分類することで、メールを必須として分類します。 企業はニューラルネットワークを利用して、最新の取引頻度、取引金額、販売者の種類などのデータに基づいて不正取引を検出しています。 盗用検出器も機械学習を利用します。 MLエンジニアリングに関しては、完了するまでに約6か月かかります。